深度学习的分布式训练与集合通信(二)

深度学习的分布式训练与集合通信(二)
本专题介绍常见的深度学习分布式训练的并行策略和背后使用到的集合通信操作,希望能帮助读者理解分布式训练的原理,以及集合通信之于分布式训练的重要性和必要性。鉴于篇幅限制,将拆分成三个部分展开讲述:
- 第一部分:介绍模型训练的大体流程,以及集合通信操作的基本类型,然后介绍分布式训练中基础的数据并行(DP)的概念以及其通信模式。详情请参见LINK
- 第二部分:介绍分布式训练中的常见的三种模型并行(MP),即流水并行(PP)张量并行(TP)和专家并行(EP)的概念以及通信模式。
- 第三部分:介绍进阶版的并行模式,如序列并行(SP),完全分片数据并行(FSDP)和Zero系列并行的概念以及通信模式。
下面进入第二部分的介绍,详细讨论模型并行及相关通信模式。
流水并行(Pipeline Parallelism,PP)
对于分布式训练,当模型规模太大而无法存放在单个计算节点上时,可以使用流水并行。在流水并行中,模型被逐层拆分成几个阶段,每个计算节点仅存储并执行其中的一个阶段(一个阶段可以是一层,也可以是相邻的多层)。这样可以有效减轻每个节点内的存储压力。
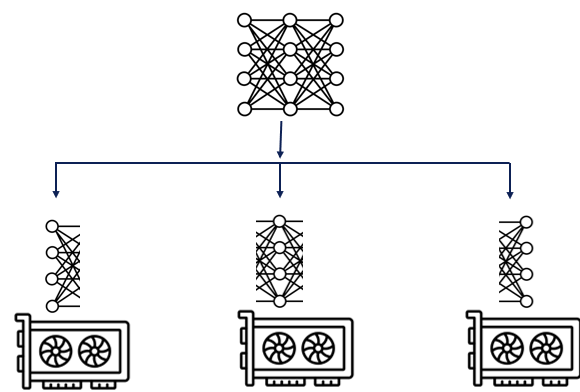
(图片来源:https://medium.com/@aruna.kolluru/model-parallelism-390d32145a5a)
当每个计算节点执行达到阶段的边界时,会与相邻的阶段节点之间传递数据。具体来说,前向传播时,每个节点会在接收到上一阶段节点传递过来的激活值后,计算出本阶段的激活值,然后将其传递到模型下一阶段的节点中;反向传播时,每个节点会在接收到下一阶段节点传递回来的梯度信息后,计算出本阶段的梯度,然后将之传递到模型上一阶段的节点中。
流水并行不像数据并行可以轻易做到高的节点并行度,由于阶段间存在数据依赖关系,流水并行的并行度会受到一定的限制,由此可能导致节点利用率低,系统吞吐率上不去的问题。如何更好地规划调度方案以达到较高的节点利用率,是流水并行一个关键优化点。
下面我们来简要分析一下流水并行中几种提高节点利用率的调度方案。先从基线开始看,在下图这个简单的顺序调度方案中,每个时间点上都只有一个小批次数据在运行,除了一个阶段节点之外,其他所有节点都处于闲置状态。待顺序执行完一个完整的批次后,权重得到更新,然后进入到下一批次数据的训练。这种调度方案显然无法充分利用多节点的硬件资源,导致训练效率低下。


可以让小批量数据的训练流水起来,使不同的阶段节点能够同时处理不同的小批量数据,由此来提高硬件利用率,这也是流水并行的基本思想。
在下面两张示意图里,展示了两种流水并行的批次拆分情况:在第一张图中,一轮流水包含了4小批次的数据,即完成一个4小批次数据的前向和反向传播后,进入下一组4小批次的训练;而在第二张图中,一轮流水里包含了所有的小批次的数据,即等所有小批次完成前向传播后,才开始反向传播的过程。

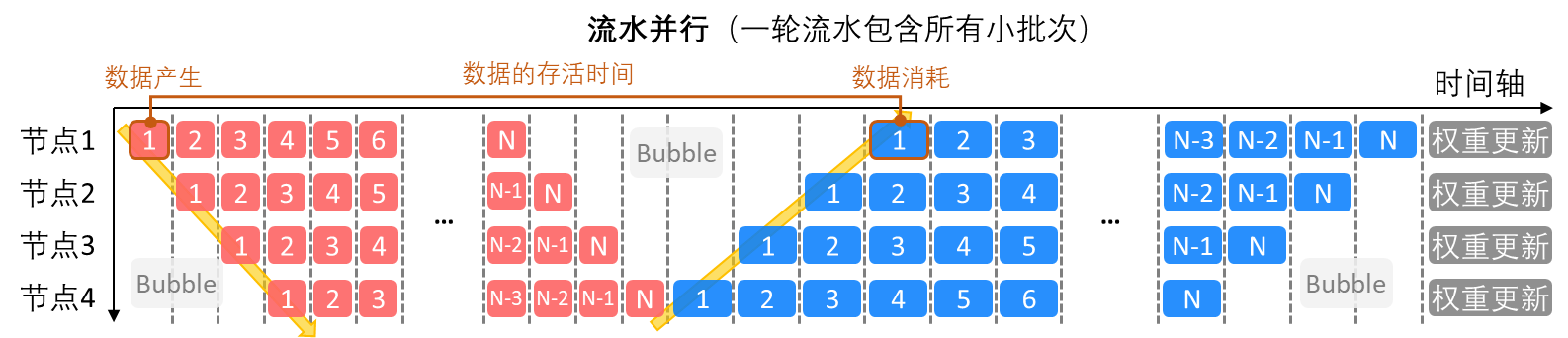
可以看到,第二张图里的节点空闲期(又称流水线泡沫,Bubble)是明显少于第一张图的,这说明提高一轮流水中包含的小批次的数量可以提高流水并行的节点利用率,原因是小批次间无数据依赖性,更多的小批次可以提供更多的并行度。
上面是从计算并行的角度来说的,如果从存储的角度来看,故事就反过来了——更多的小批次的数据进入流水,意味着从一个数据的产生到消耗之间,更多的与之无关的计算被插入进来,这些计算也会产生需要存储的中间数据。这样一来,数据的存活时间变长了,数据的存储需求也就增加了。因此,计算的并行度和存储的需求量似乎成了一对需要取舍难题。
有没有其他的调度方案既可以保证高的计算并行度,又能尽可能控制存储的需求呢?下面介绍两种改善版流水并行的方案,一个是分组流水并行,一个是交替流水并行。
分组流水并行的调度排布如下图所示,在稳定期,所有的阶段节点会统一交替进行前向传播和反向传播。这样做,可以在保证稳定期的节点利用率为100%的同时,缩短数据存活时间,降低了存储需求。
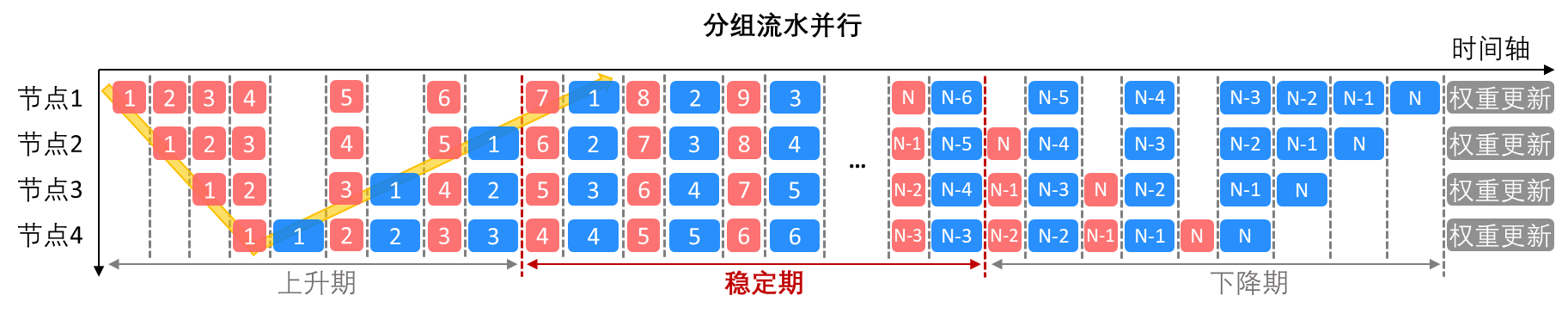
另一种改善的方法是交错流水并行,它的调度排布如下图所示。在稳定期,一半的阶段节点执行前向传播,另一半执行反向传播。交错流水并行的上升期和下降期较短,从而可以更快地实现最大的节点利用率,并进一步降低了存储需求。但由于阶段前向传播和反向传播在完成时间可能有差别(一般反向传播延时会高一些),交错流水并行在稳定期可能引入一些等待数据同步的节点空档期。
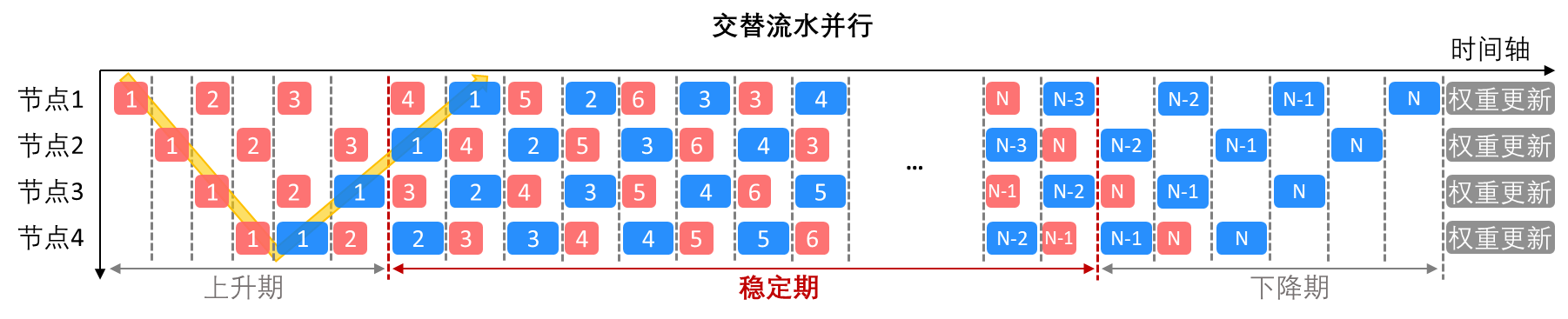
下面来看一下流水并行涉及到的通信方式。对于上面所介绍的各种流水并行,它们的通信通常都发生在每一个阶段计算完成以后,流水线相邻阶段节点之间,通信操作是在第一部分文章中介绍的一对一的Send和Receive;单次通信数据量少但是通信较频繁。
将流水并行的通信操作总结成表格如下:
|
通信操作 |
通信数据 |
发生时间 |
通信次数 |
每次通信数据量 |
HCCL API |
|
Send /Receive |
激活值 |
前向传播每个阶段结束时 |
每个Epoch通信 [前/反向传播次数* (流水阶段数-1)*小批量数] 次 |
阶段边界层激活值的数量 |
|
|
梯度 |
反向传播每个阶段结束时 |
阶段边界层激活值梯度的数量 |
详细接口介绍请参考:LINK
张量并行(Tensor Parallelism,TP)
如果单层/单阶段的模型依然太大而无法放在单个节点上怎么办?那就将它的参数进一步切分到多个节点上,每个节点计算部分结果,再通过通过节点间的通信获取到最终结果,这就是张量并行。简言之,流水并行是模型的层间切割,而张量并行是模型的层内切割。这两种模型并行的方式是可以同时存在的。
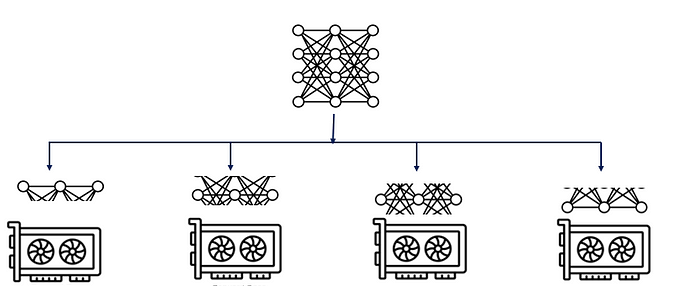
(图片来源:https://medium.com/@aruna.kolluru/model-parallelism-390d32145a5a)
张量并行的底层逻辑是矩阵乘法的拆分计算。下面分别介绍矩阵乘法中列并行与行并行这两种张量并行的方式,以及它们在前向传播和反向传播中的区别。
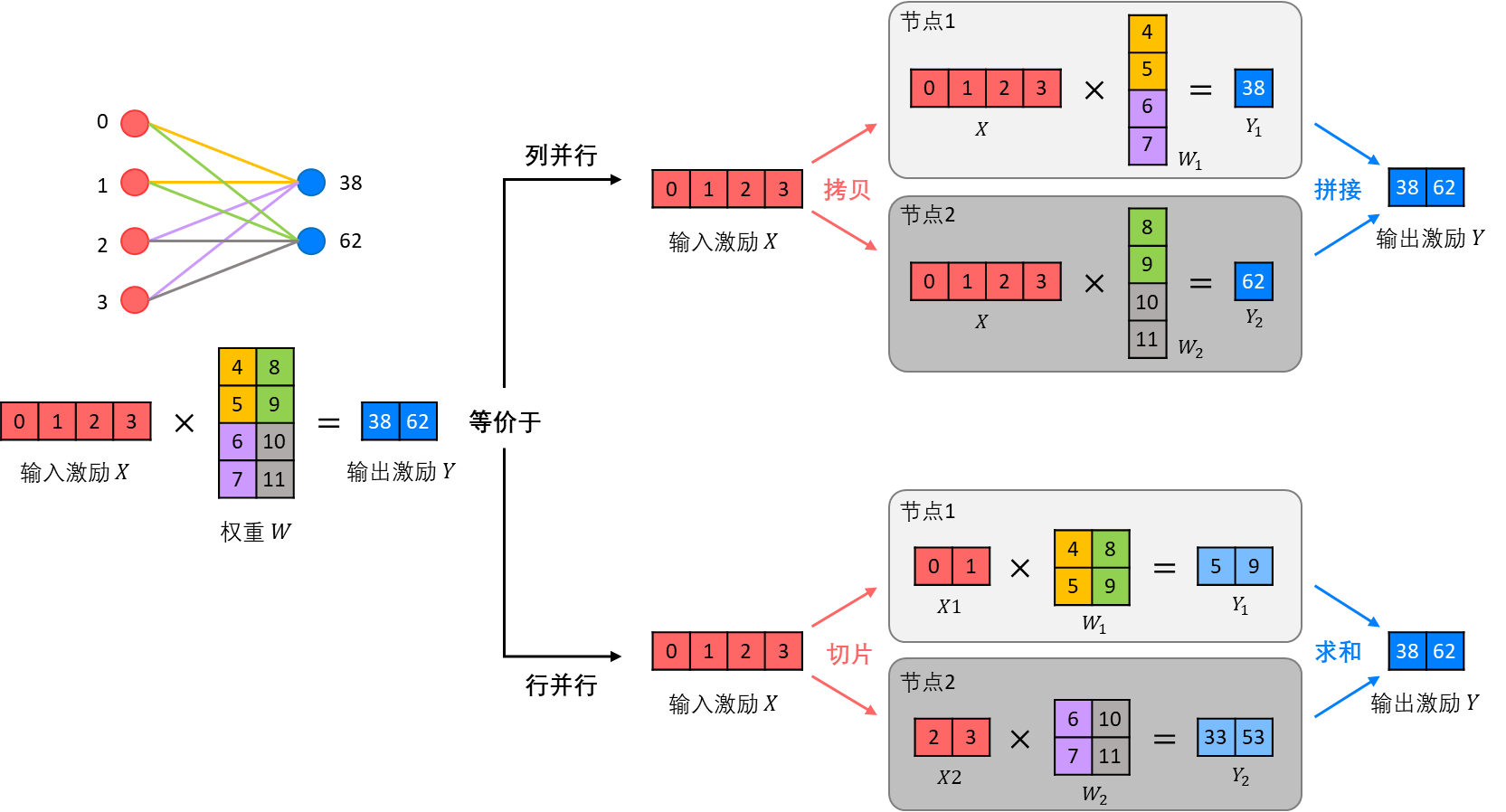
这里,在前向传播中,假设对于网络的一层,要计算X · W = Y, X、Y分别是网络中这一层的输入和输出激励,W是这一层对应的模型权重参数。
列并行就是把参数矩阵W按照列的维度分开,存放在两个(或多个)计算节点上分别计算对应部分的矩阵乘法。此时对于输入激励X,需要将其整个拷贝到这两个节点上;对于输出激励Y,需要将这两个节点的输出Y1、Y2拼接在一起来获得。
行并行就是把参数矩阵W按照行的维度分开,存放在两个(或多个)计算节点上分别计算。此时对于输入激励X,也将其按照对应维度切分到这两个节点上;而要得到完整的输出激励Y,需要将这两个节点的输出Y1、Y2点对点的加起来。


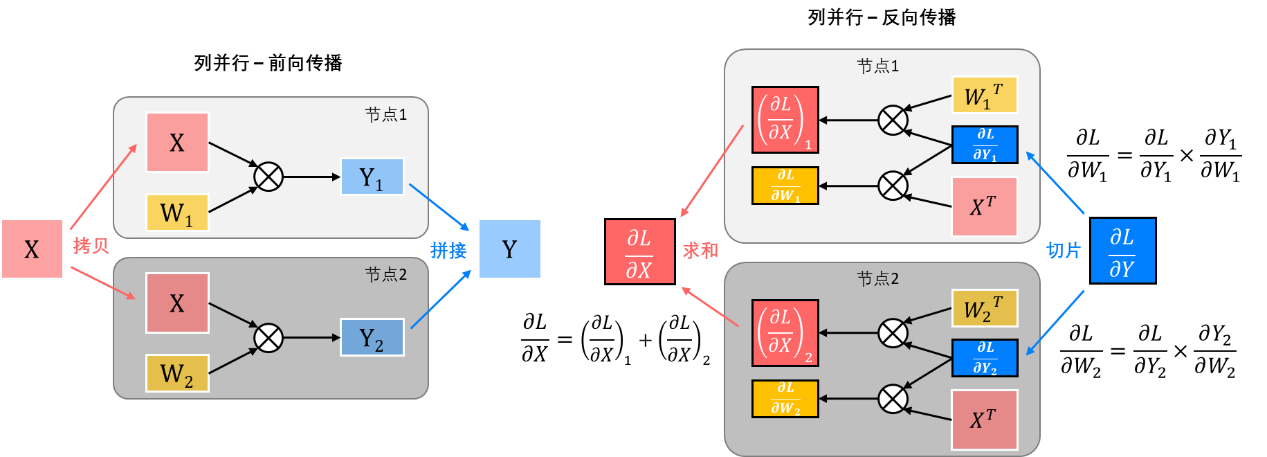

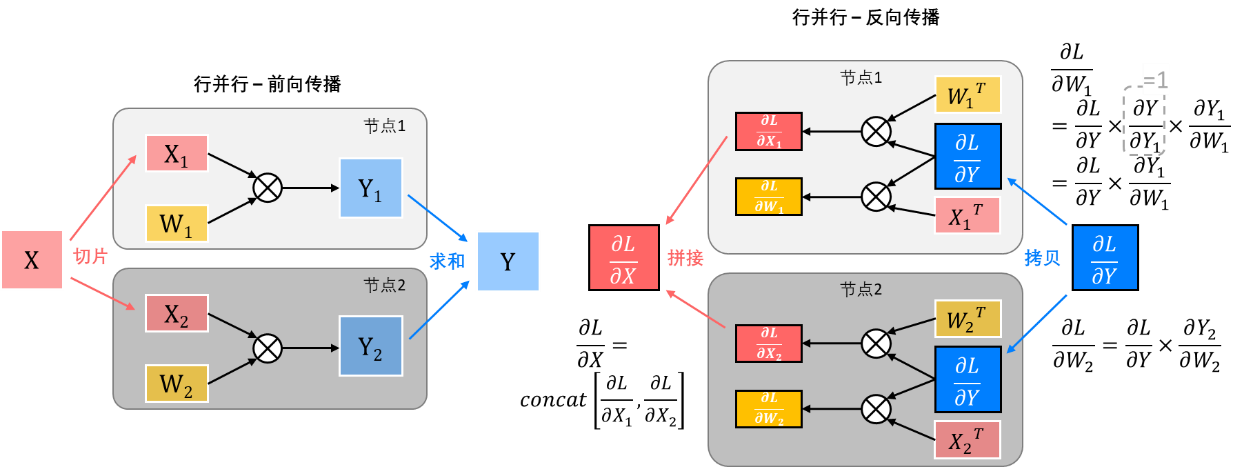
由此可见,在不同的张量并行的前向和反向传播中,输入输出数据在并行节点间的流动方式是截然不同的,总结如下表所示:

可能读者会很自然的将这些数据流动方式与上一回中介绍的集合通信操作联系起来:
- 整份拷贝到各节点 à一到多的Broadcast
- 切片分发到各节点 à一到多的 Scatter
- 拼接各节点的数据 à多到一的Gather
- 求和各节点的数据 à多到一的Reduce
然而,这并不是张量并行所呈现出来的典型的通信模式。在上述的讨论中,我们是将一个行/列并行的矩阵乘法单独拿出来看它的数据流动——假设这个矩阵乘的输入是从一个节点上来,输出需要被完整收集到一个节点上去。但其实,在实际模型训练中,张量并行往往会被跨层部署,级联使用。对于一段位于级联中间层的张量并行计算来说,它的输入的来源,输出的去向,以及输入输出的数据形态,是受到前后级张量并行形态影响的。所以,要了解张量并行典型的通信模式,需要在上面单例讨论的基础上,进一步分析级联状态下的情况。
下面以前向传播为例,具体分析在不同行/列并行级联的情形下,张量并行的典型通信模式。
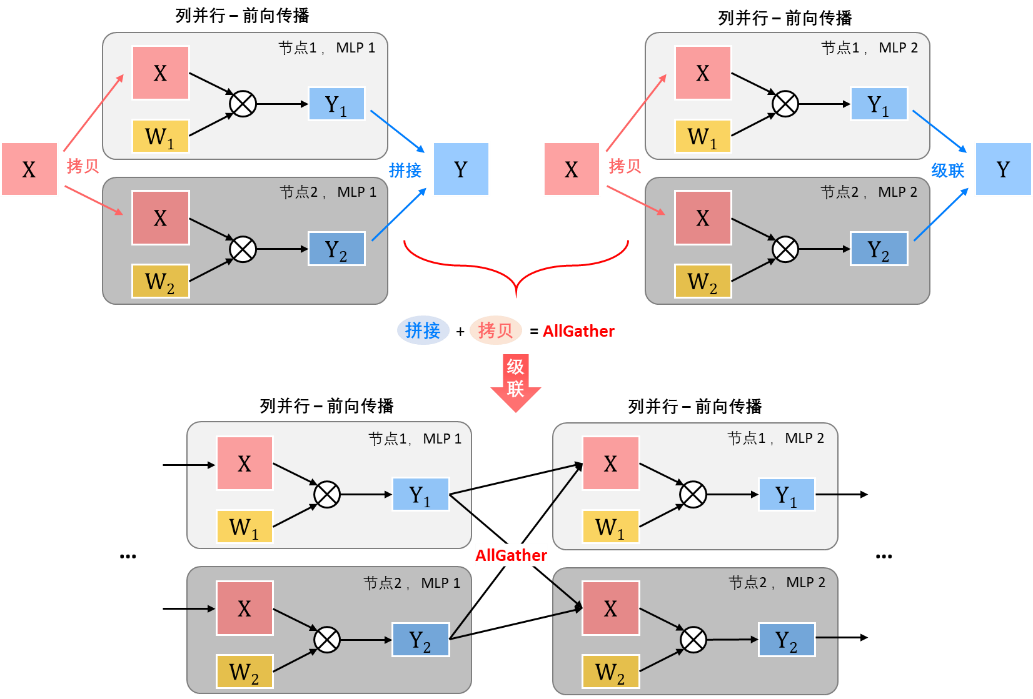
列并行+列并行:当列并行被级联起来使用时,前级输出所需的拼接操作与后级输入所需的拷贝操作可以被结合成集合通信操作中多对多的AllGather操作,即每个节点将自己的数据发送到其他节点上,使得所有节点都拥有一份完整的前级的输出数据,以便开始后一级的列并行计算。
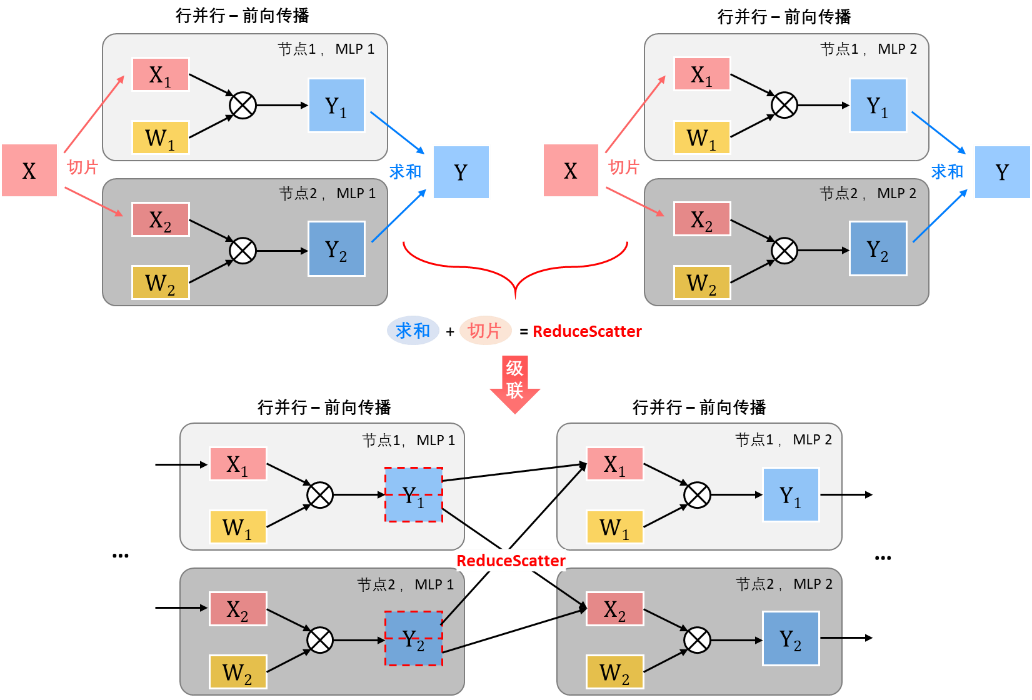
行并行+行并行:当行并行被级联起来使用时,前级输出所需的求和操作与后级输入所需的切片操作可以被结合成集合通信操作中多对多的ReduceScatter操作,即每个节点将自己的数据按维度切片发送到其他节点上并进行数据的求和,使得所有节点都拥有一部分前级的输出数据,以便开始后一级的行并行计算。
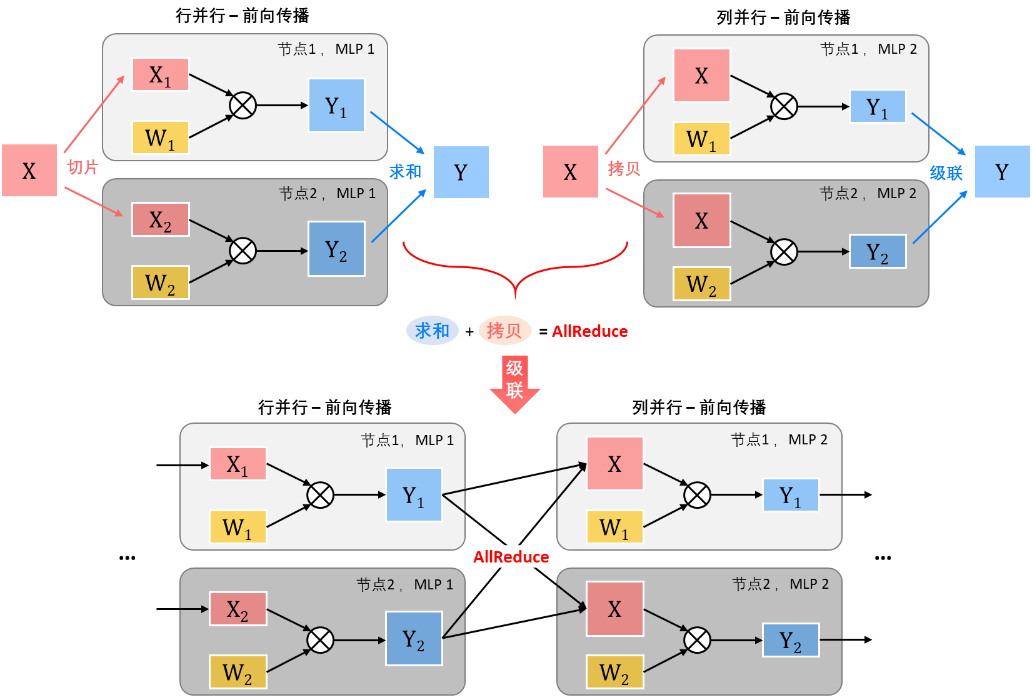
行并行+列并行:当行并行与列并行被级联起来使用时,前级输出所需的求和操作与后级输入所需的拷贝操作可以被结合成集合通信操作中多对多的AllReduce操作,即每个节点将自己的数据发送到其他节点上并进行数据的求和,使得所有节点都拥有一份完整的前级的输出数据,以便开始后一级的列并行计算。
列并行+行并行:当列并行与行并行被级联起来使用时,情况与前面三种级联方式不同——因为前级输出所需的拼接操作与后级输入所需的切片操作可以相互抵消,所以列+行的这种级联方式中间不需要任何集合通信操作,即列并行的每个节点天然会产生前一级的部分输出,这个部分输出可以作为后一级所需的部分输入,直接开始后一级的行并行计算,无需节点间通信。
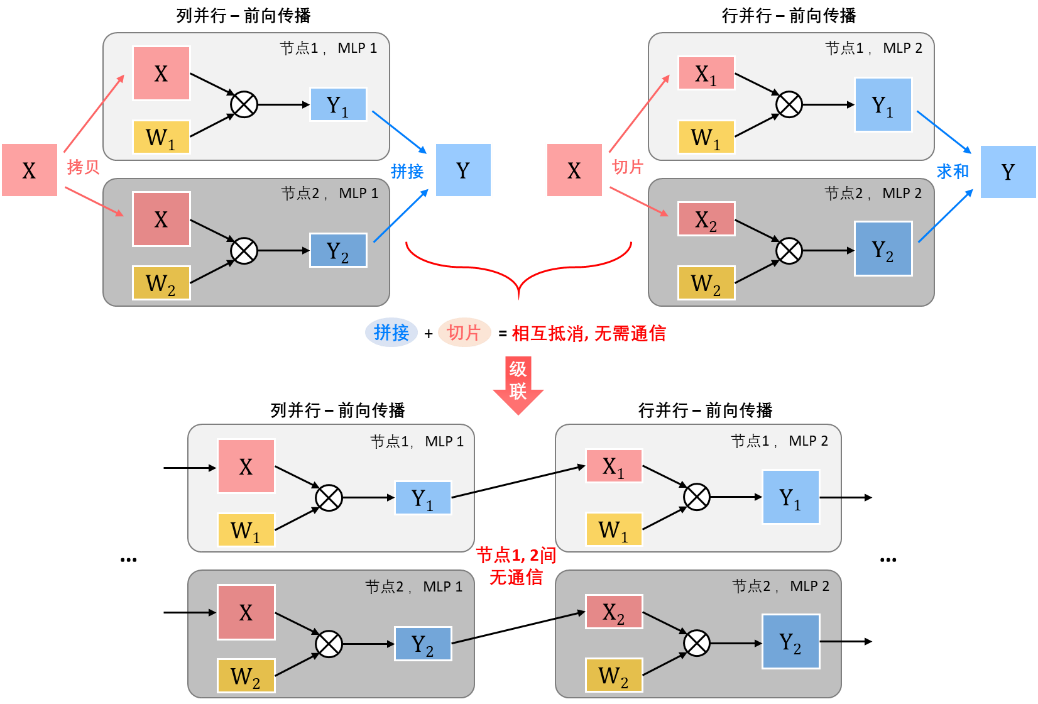
鉴于其在通信方面的优越表现,列+行的这种级联方式是张量并行中的一种常见的连招玩法。举个例子, Transformer模型中的FFN层(即Feed Forward Network),是两层全连接层(MLP)级联起来的结构,就多用上面介绍的列并行级联行并行的并行方式进行分布式训练。
值得指出的是,列+行并行的这种级联方式只是中间无需通信操作,它的前面和后面一定是与其他并行方式连接使用的,会使用到前面介绍的各种集合操作。
下面来总结下张量并行涉及到的通信方式。对于张量并行,通信发生在前向和反向传播的过程中,发生在每一层的内部。基于不同并行形态的级联方式,其通信模式会有不同,可能是对输入输出数据进行聚合或是规约操作;单次通信数据量较大且通信非常频繁。
将张量并行的通信操作总结成表格如下:
|
通信操作 |
通信数据 |
发生时间 |
通信次数 |
每次通信数据量 |
HCCL API |
|
AllGather |
激活值和梯度 |
列+列并行 |
每个Epoch通信 [前/反向传播次数* (相应并行级联层数-1)] 次 |
当前层激励 |
|
|
ReduceScatter |
行+行并行 |
||||
|
AllReduce |
行+列并行 |
详细接口介绍请参考:LINK
专家并行(Experts Parallelism,EP)
要说明白专家并行,首先要理解混合专家(Mixture-of-Experts,MoE)的概念。
混合专家的本质思想很简单,说白了就是“术业有专攻”。试想如果要解决一个涉及了多个领域知识的问题,一种可能是把这个问题当作一个问题,找到一个精通所有这些领域的人去解决;另一种可能则是把这个问题按领域拆分开,当作多个问题,找到各自对应领域内的专家去集体解决,最后再汇总。
如果把上面这个比喻映射到神经网络中的话,前者对应的可能是一个大的全连接模块,一股脑的把所有输入读进来,处理,输出,这个全连接模块需要学习的内容很多也很杂,所以引入的参数量和计算量都会很大;而后者对应的则是MoE层,它有点像把这个大的全连接层打散成很多可以并行运作的小的全连接单元,每个单元称之为一个专家,通过在训练中对不同专家进行有导向有分工的学习,同时训练一个输入数据进入专家模块之前的路由选择机制,MoE就可以在保证神经网络效果的同时大大减少网络的计算量。
近年来,随着模型学习任务的复杂化和多样化,模型规模不断趋于大型化。MoE被越来越多的应用起来。下面两张图分别体现了MoE在LSTM和Transformer网络结构中的应用。
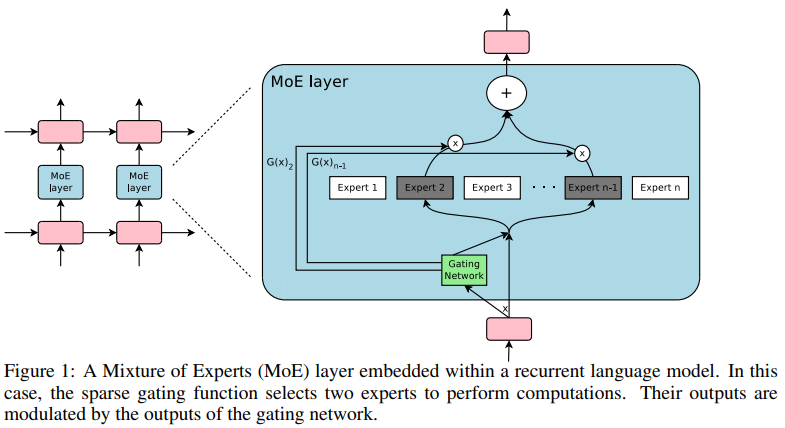
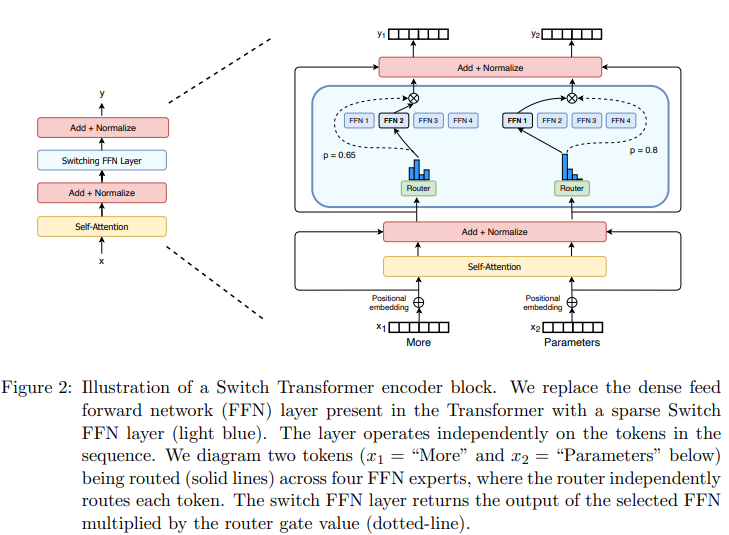
介绍完MoE,专家并行就很好理解了。
专家并行是在分布式学习中专门针对MoE场景的并行策略,其主要思想就是将不同专家放在不同计算节点上进行并行计算。专家并行与之前所有的并行相比,最大的不同在于,输入数据需要通过一个动态的路由选择机制分发给相应专家,此处会涉及到一个所有节点上的数据重分配的动作,然后在所有专家处理完成后,又需要将分散在不同节点上的数据按原来的次序整合起来。这样的跨片通信模式称为AlltoAll(或All2All),在第一部分的文章中有介绍到。
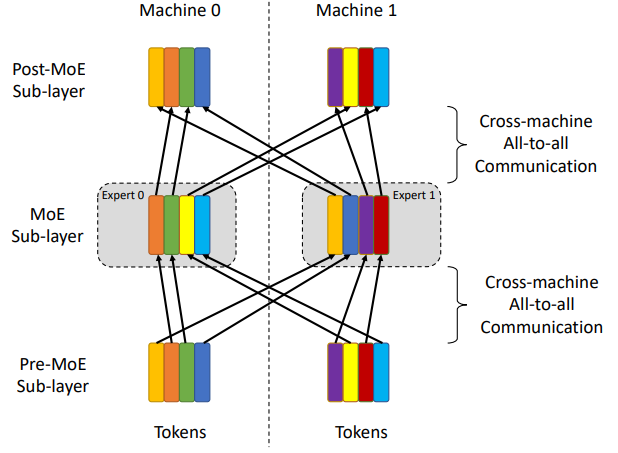
专家并行可能存在的最会影响其效率乃至正确性的问题就是负载不均衡的问题。举个例子来说,在下面的左图中,专家1所接收到的输入数据大于了其所能接收的范围(红色虚线),可能导致蓝色Tokens不被处理或不能被按时处理,成为瓶颈;在右图中,当给专家1扩容后,虽然蓝色Tokens可以被很好处理,但是专家2,3又都出现了资源浪费的情况(白色方块),这也是我们不希望看到的。另外,站在通信的角度来看,这种不均匀且动态变化的数据分配也会大幅度的增加通信开销。这样的通信模式称为AlltoAllV(见文章第一部分的介绍)。所以,对于存在MoE结构的网络,如何尽可能的做到MoE阶段负载均衡,是确保专家并行高效实施的关键。
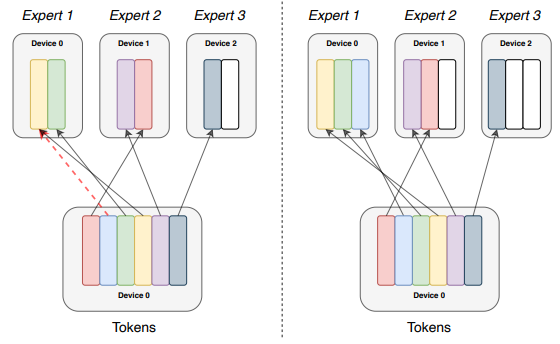
下面来看一下专家并行涉及到的通信方式。对于专家并行,通信发生在每一个MoE模块之前和之后,用于在所有节点之间进行数据的交换;单次通信数据量较大且可能动态变化,通信较频繁。
将专家并行的通信操作总结成表格如下:
|
通信操作 |
通信数据 |
发生时间 |
通信次数 |
每次通信数据量 |
HCCL API |
|
AlltoAll / |
激活值(Tokens) |
前向传播时 |
每个Epoch通信 |
MoE输入/输出激活值的量 |
|
|
梯度 |
反向传播时 |
MoE输入/输出激活值梯度的量 |
详细接口介绍请参考:LINK
关于模型并行的介绍就到这里,下期,将为大家介绍更高阶的并行方式,如序列并行,完全分片数据并行,Zero系列并行优化等。并在下期的最后,会对所有介绍过的并行方式、以及它们的通信模式进行对比和总结,感谢关注。
参考材料
https://medium.com/@aruna.kolluru/model-parallelism-390d32145a5a
https://afmck.in/posts/2023-02-26-parallelism/
https://docs.graphcore.ai/projects/porting-tf2-models-quick-start/en/latest/main.html
https://insujang.github.io/2022-06-11/parallelism-in-distributed-deep-learning/
LLM分布式训练 --- Megatron-LM-CSDN博客
图解大模型训练之:张量模型并行(TP),Megatron-LM - 知乎 (zhihu.com)
大模型的研究新方向:混合专家模型(MoE) - 知乎 (zhihu.com)
https://arxiv.org/abs/2205.14336
https://developer.huawei.cn/consumer/cn/forum/topic/0201144946719090690
集合通信用户指南:https://hiascend.com/document/redirect/CannCommercialHcclUg

- 点赞
- 收藏
- 关注作者
评论(0)