深度强化学习原理--Actor-Critic(演员-评论家架构)

1.概述
在REINFORCE算法中,使用基于神经网络建模的价值函数作为基线,这个算法叫做Actor-Critic。这个算法通过价值函数控制基线,调整回报期望的梯度。

2. Actor-Critic的数学定义
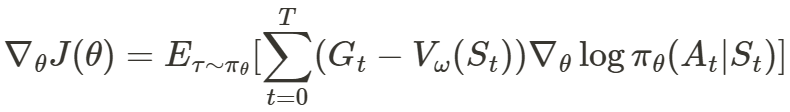

当 t 时刻,回报大于状态价值期望时,给予策略正梯度,回报小于状态价值期望时,给予策略负梯度。回报等于状态价值期望时,不需要更新策略函数参数。所以价值函数的训练目标是接近 J(θ) 最大值时的Gt 。但是公式中存在一个问题,J(θ) 没有达到最大值,就无法确定 𝐺𝑡 的值。也就是说,在抵达目标之前,无法更新策略和价值函数。
3. 时序差分法(TD方法,Time Difference Method)
贝尔曼期望方程:𝑉𝜔 (𝑆𝑡)=𝔼𝜋 [𝑅𝑡+𝛾𝑉𝜔(𝑆𝑡+1)|𝑆𝑡],所以可以使用𝔼𝜋 [𝑅𝑡+𝛾𝑉𝜔(𝑆𝑡+1)|𝑆𝑡] 来近似Gt。使用神经网络对价值函数建模时,以接近 𝑅𝑡+𝛾𝑉𝜔(𝑆𝑡+1) 为目标训练𝑉𝜔(𝑆𝑡) 函数。具体来说就是将 𝑉𝜔(𝑆𝑡) 和 𝑅𝑡+𝛾𝑉𝜔(𝑆𝑡+1) 的均方差作为损失函数,通过梯度下降法更新神经网络的权重。
使用TD方法训练价值函数时,使用1个时间步(或𝑛个时间步)后的结果就能进行更新。

![]()
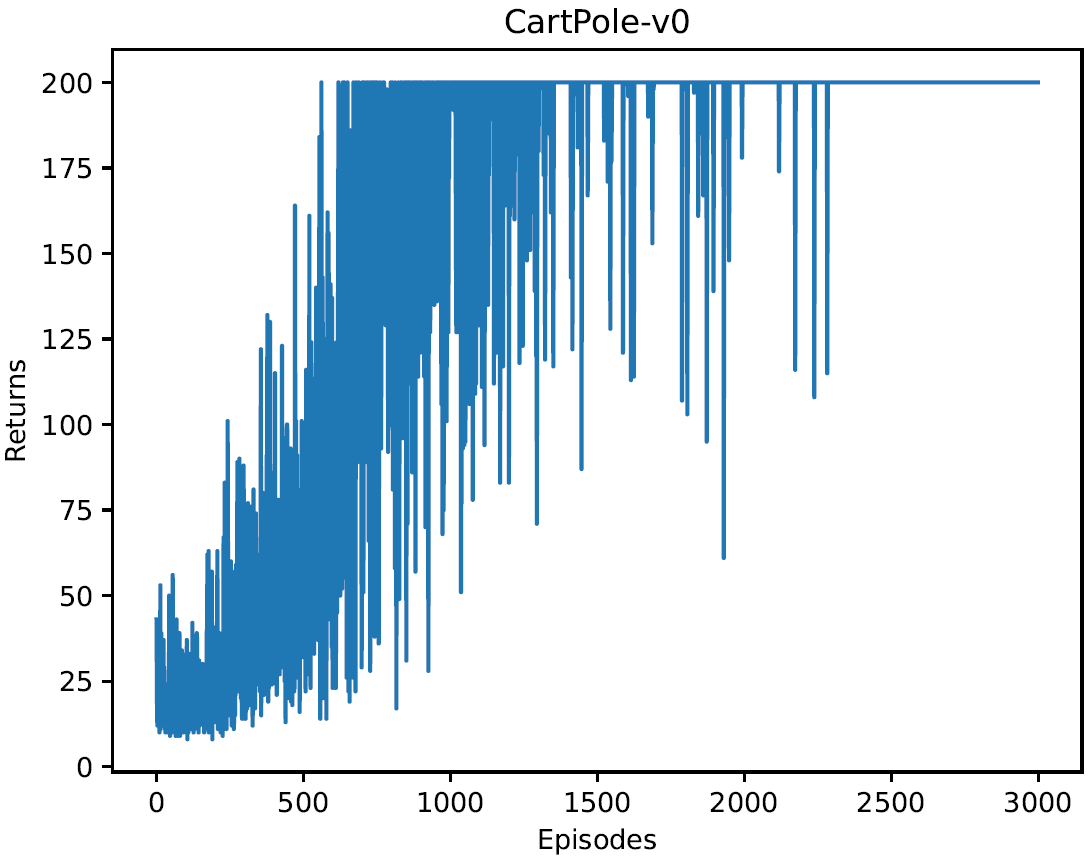
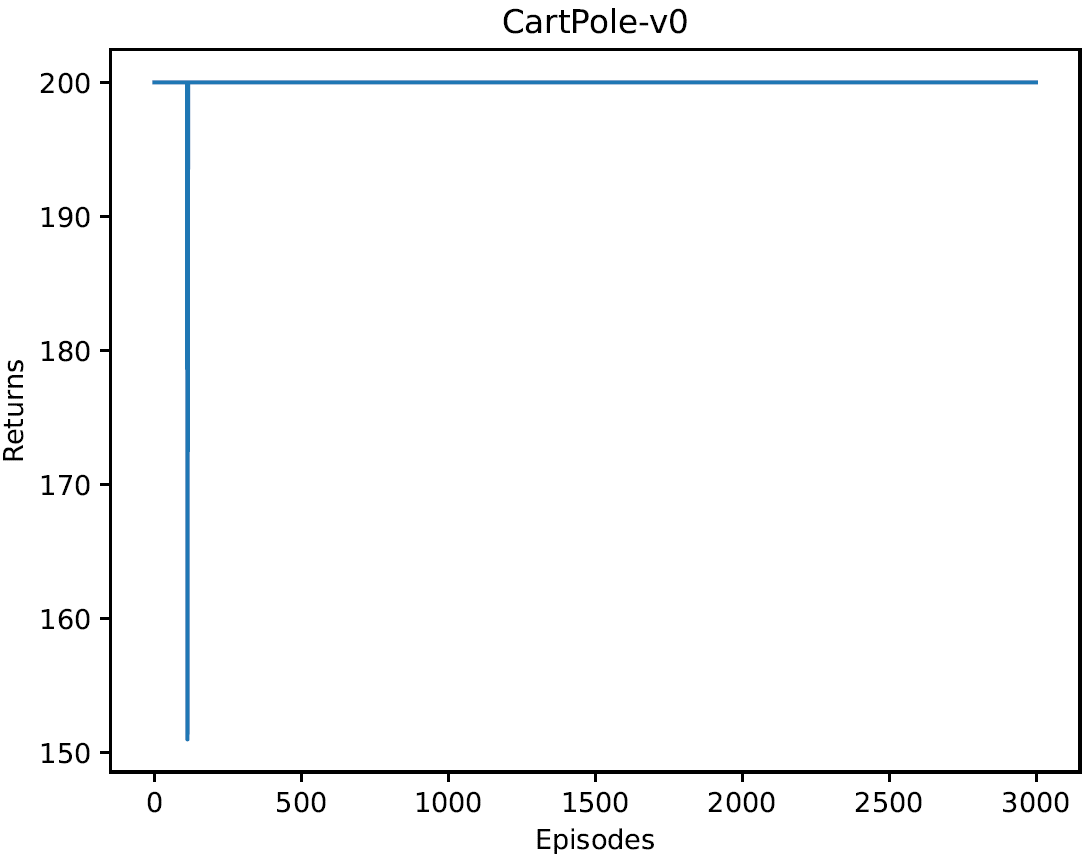
3.1 使用1步时序差分法进行3000次倒立摆游戏,每次回报情况如下图。相比REINFORCE算法,回报有明显提升。模型训练稳定性提高很多。
①训练过程中每条轨迹回报
②测试过程中每条轨迹回报
4. 广义优势估计(Generalized Advantage Estimation,GAE)
4.1 1步TD误差表示为:𝛿 = 𝑅𝑡 + 𝛾𝑉𝜔(𝑆𝑡+1) − 𝑉𝜔(𝑆𝑡) 。在很多强化学习文献中,这个叫做优势𝐴(Advantage),表示1步TD目标 𝑅𝑡 + 𝛾𝑉𝜔(𝑆𝑡+1) 相对于基线 𝑉𝜔(𝑆𝑡) 的优势是多少。现在常用的一种方法是通过多步TD误差的计算,结合指数加权平均的方式来估算优势,也就是广义优势估计。
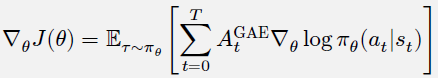
4.2 广义优势估计的数学推导

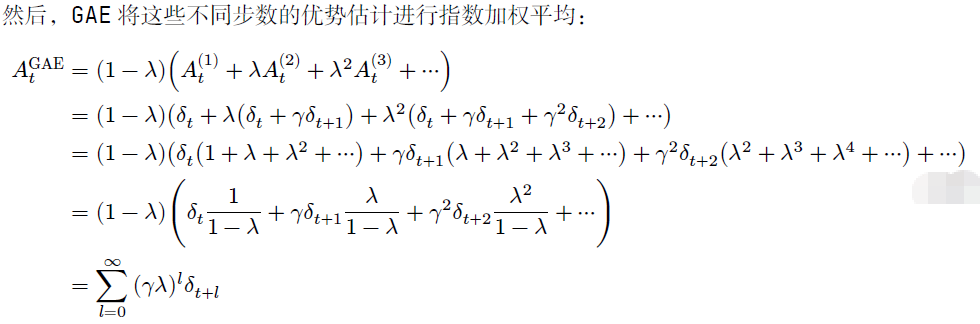
其中,𝜆∈[0,1] 是在 GAE 中额外引入的一个超参数。当 𝜆=0,从狭义角度看时,![]() = 𝛿𝑡 = 𝑅𝑡 + 𝛾𝑉(𝑠𝑡+1) − 𝑉(𝑠𝑡) ,一步差分得到的优势;当𝜆=1,从广义角度看时,
= 𝛿𝑡 = 𝑅𝑡 + 𝛾𝑉(𝑠𝑡+1) − 𝑉(𝑠𝑡) ,一步差分得到的优势;当𝜆=1,从广义角度看时,![]()
![]() ,是每一步差分得到的优势的完全平均值。
,是每一步差分得到的优势的完全平均值。
所以可以得到递推公式:
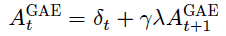
下面是计算GAE的过程,给定 𝛾 和 𝜆 以及每个时间步的 𝛿𝑡 之后,根据公式直接进行优势估计:

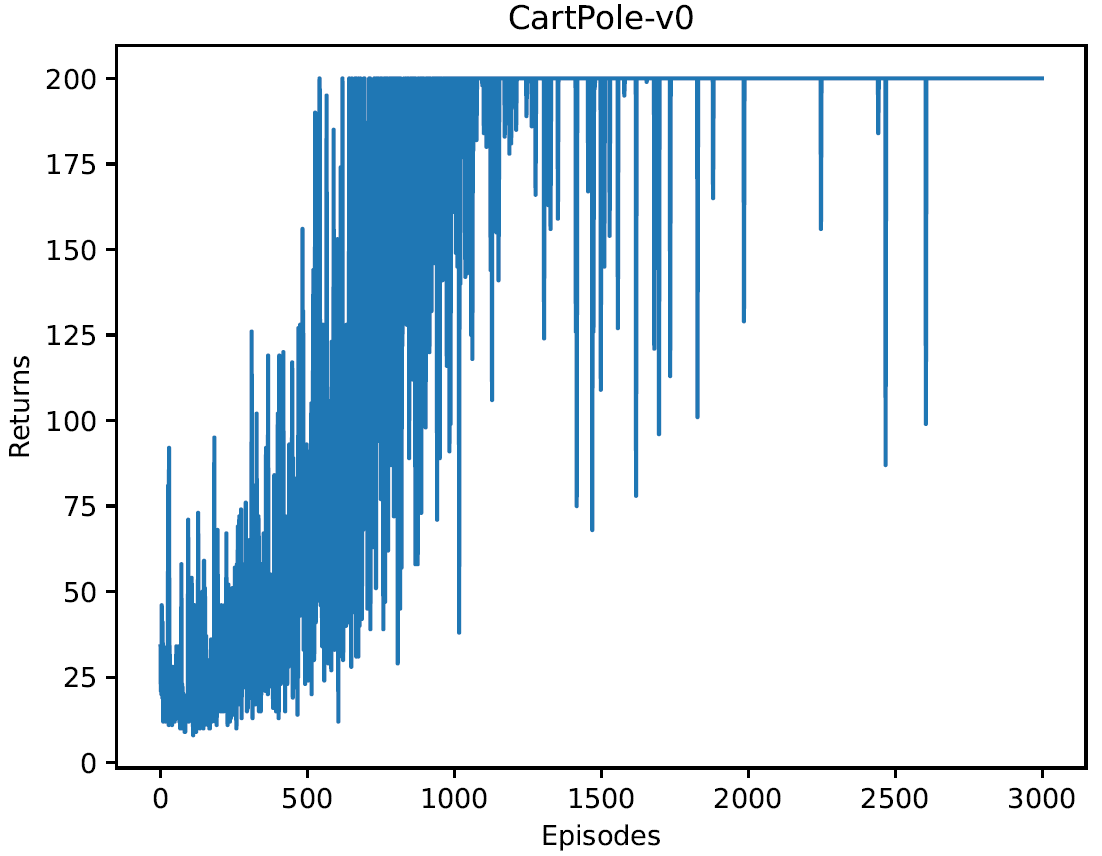
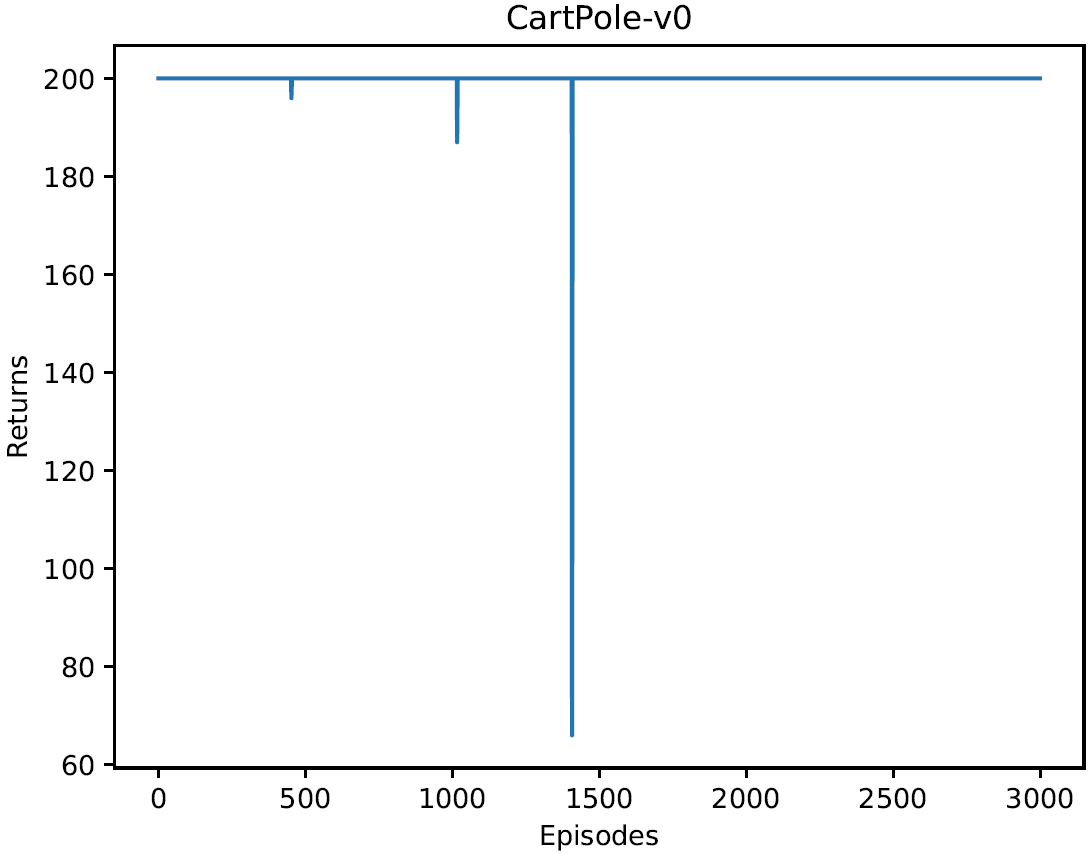
4.3 使用广义优势估计,进行3000次倒立摆游戏,每次回报情况如下图。相比REINFORCE算法,回报有明显提升。模型训练稳定性提高很多。
①训练过程中每条轨迹回报
②测试过程中每条轨迹回报
5. 总结
通过优势算法解决了轨迹的质量参差不齐对参数更新的影响。但是在强化学习中很难找到合适的策略函数参数更新步长,使期望回报稳步上升。在训练过程中,每次策略函数参数更新的步长如果太大,容易发生训练崩溃。如果步长太小,模型学习速度就会太慢,并且如果策略函数参数更新的方向错了,也会训练崩溃。训练崩溃后就需要重新探索,需要很长时间才能恢复。

- 点赞
- 收藏
- 关注作者
评论(0)