大模型原理--多头自注意力在推理效率上的进化

1.概述
基于Decoder-only的大模型在自回归生成过程中,模型的输出使逐token。每一个新token,模型都会与上下文的所有token进行注意力计算,这将造成巨大的重复计算。随着模型越来越大,上下文越来越长,传统注意力机制的问题逐渐暴露出来。为了解决问题,业界提出了一系列结构的改进,在保持模型能力的同时显著提升了推理效率。
2.在MHA(Multi-Head Attention)架构引入KV Cache
MHA是Transformer最初采用的注意力机制,其结构在大模型时代逐渐暴露出明显的工程瓶颈。首先研究下生成token的Attention的计算过程:
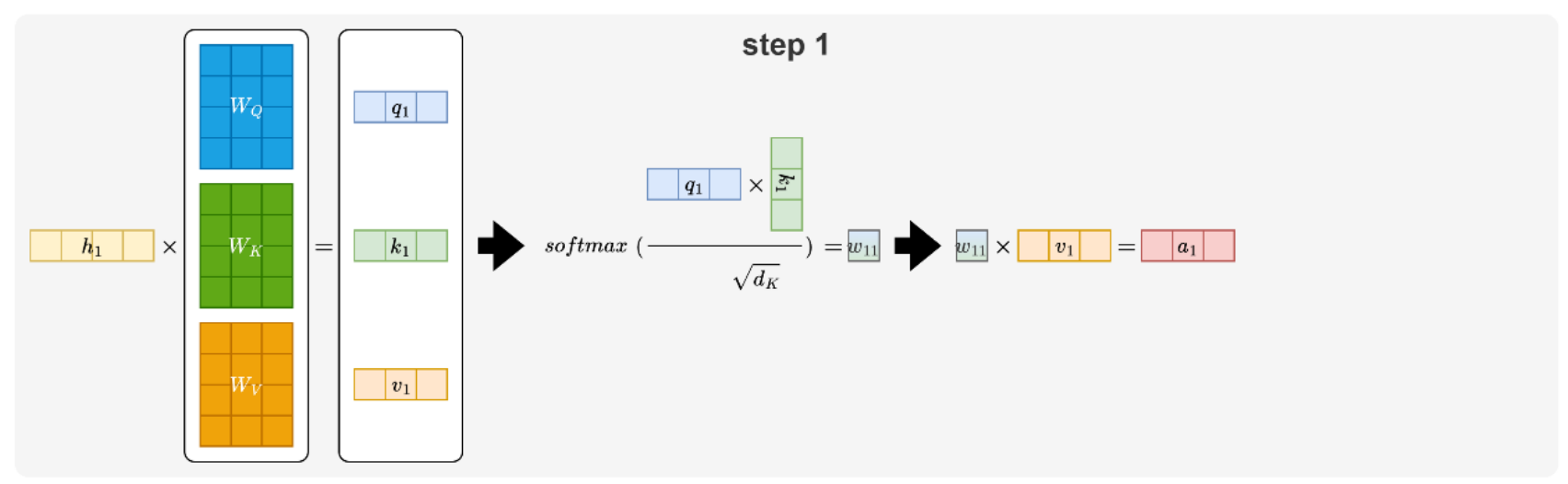
在step1中,在生成a1向量,需要计算生成的向量有q1,k1,v1,w11。
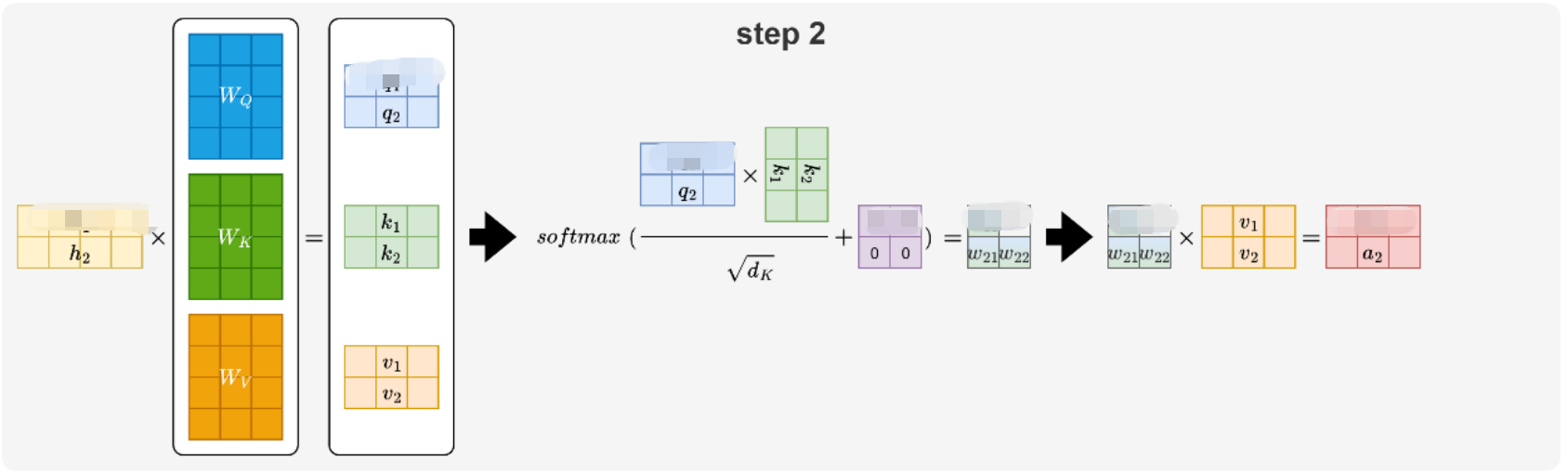
在step2中,在生成a2向量,需要计算生成的向量q2,k1,k2,v1,v2,w21,w22。其中k1,v1可以从step1中获得,不需要计算生成。
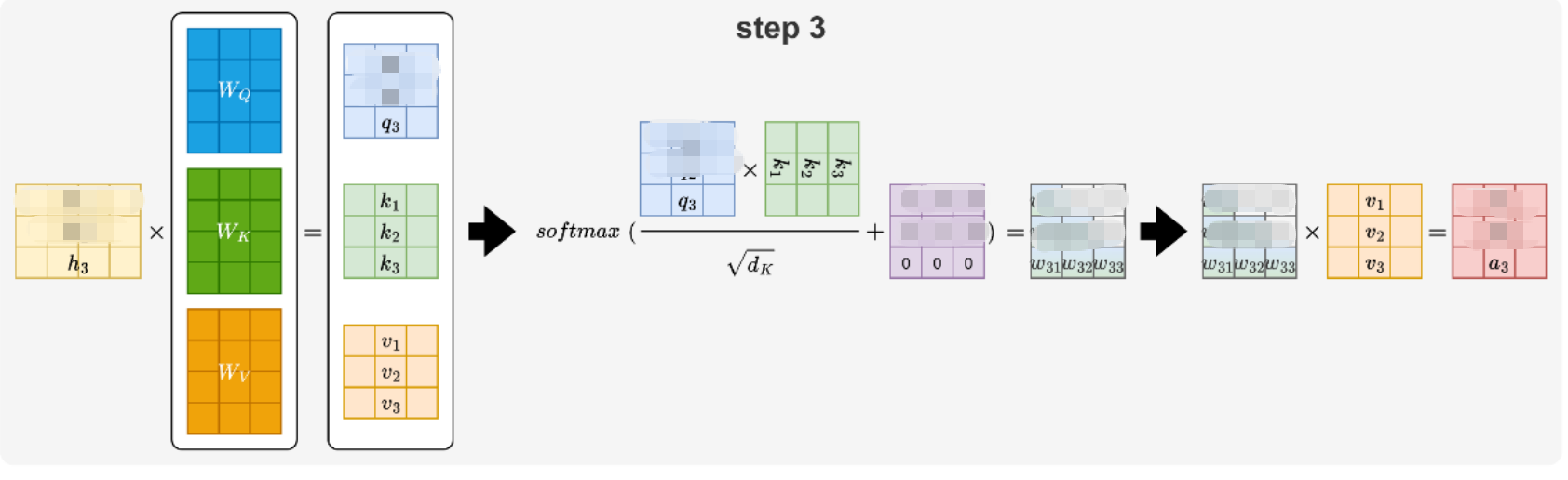
在step3中,在生成a3向量,需要计算生成的向量q3,k1,k2,k3,v1,v2,v3,w31,W32,W33。其中k1,k2和v1,v2可以从step2中获得,不需要计算生成
为了避免这种重复计算,在推理阶段将历史 token 的 Key 和 Value 缓存下来,供后续步骤直接使用。这一机制就是 KV Cache。
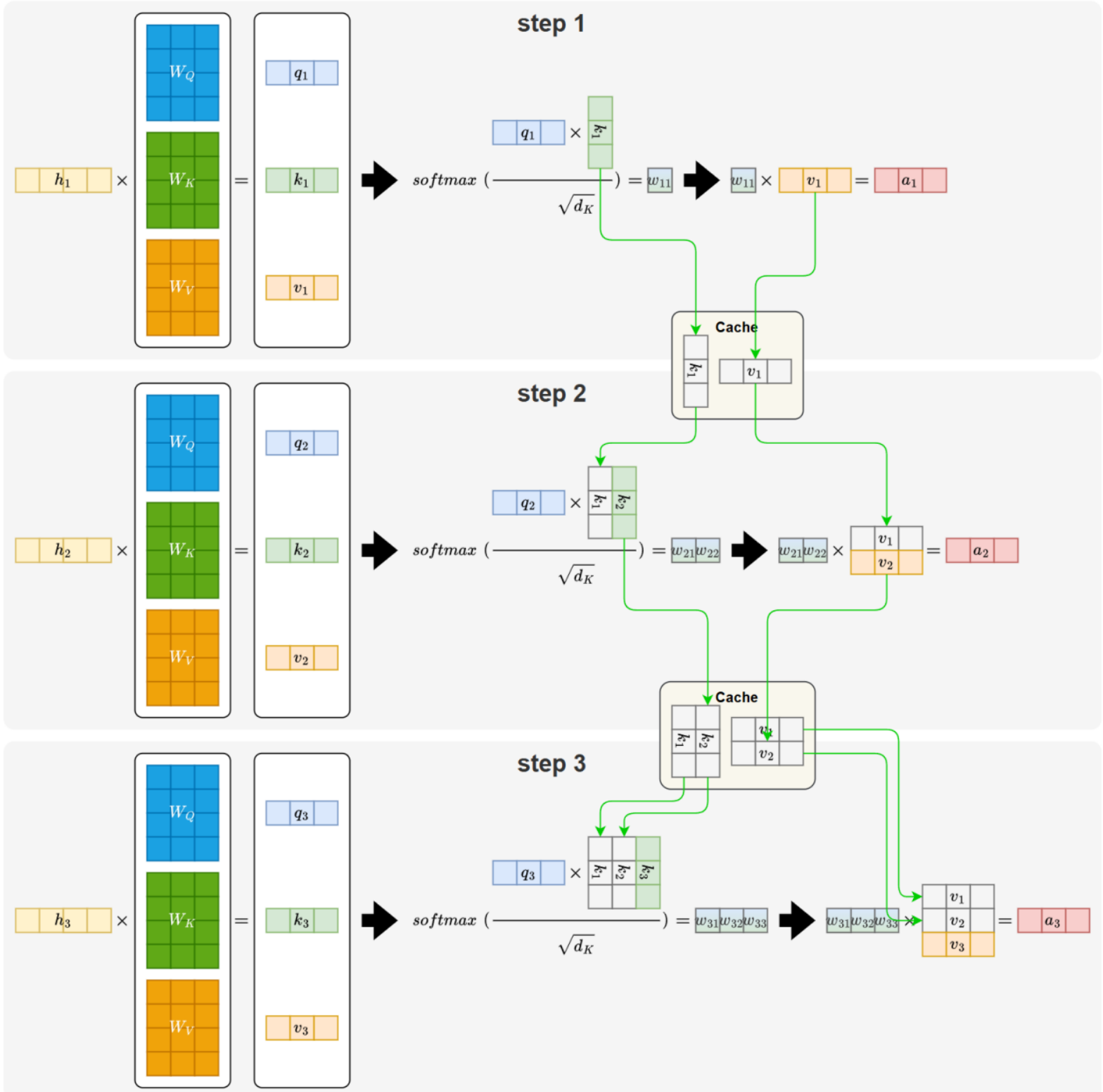
优点:减少重复计算。
不足:影响KV Cache显存占用的因素有大模型的层数、MHA中的头数、kv向量的长度、数字表示的精度、上下文长度以及推理请求的个数。其中上下文长度,推理请求的个数会动态的影响KV Cache,会造成KV Cache缓存规模成倍的增加,显存带宽的大小会影响计算效率。
3. MQA(Multi-Query Attention)
MQA 的核心思想是让多个注意力头共享同一套 Key 和 Value,而不是像传统 MHA 那样为每个头分别维护独立的 k/v。
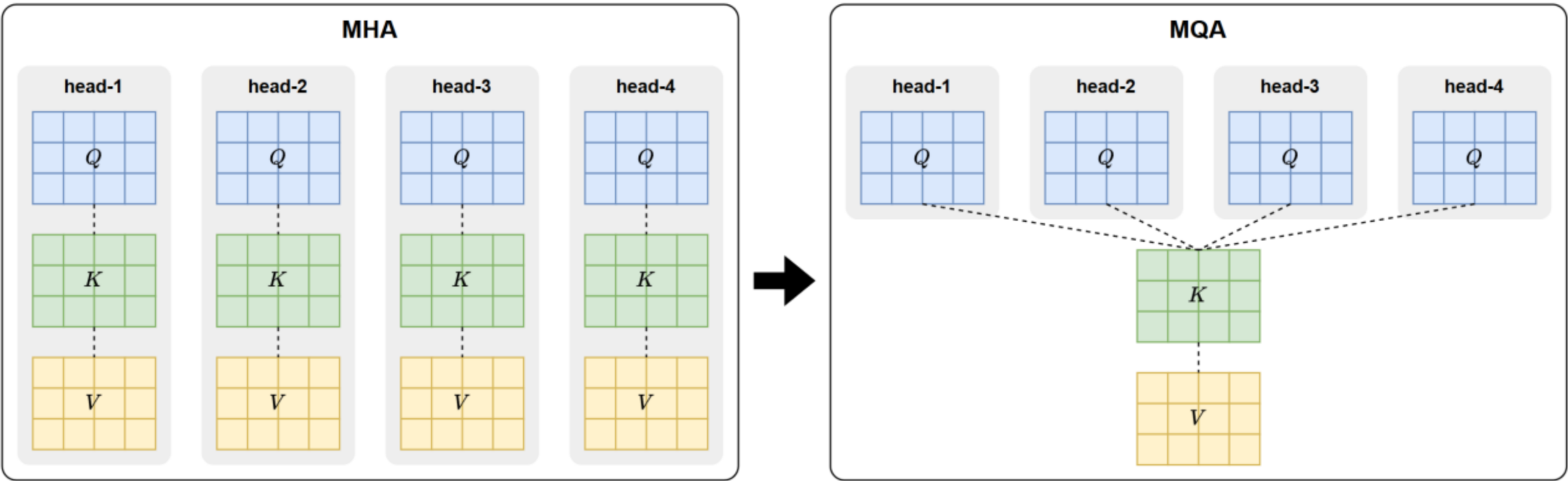
优点:这种共享方式大幅减少了需要缓存和读取的 K/V 张量量级,显著降低存储需求与内存带宽压力,从而大幅提升了推理速度。
不足:这种共享机制会削弱注意力头的表达能力,使其精度逊于传统 MHA。
4. GQA(Group-Query Attention)
GQA 的核心思想是:将注意力头划分为多个组(Group),每组内部的多个 Query 共享同一套 Key 和 Value,而不同组之间则使用独立的 K/V.
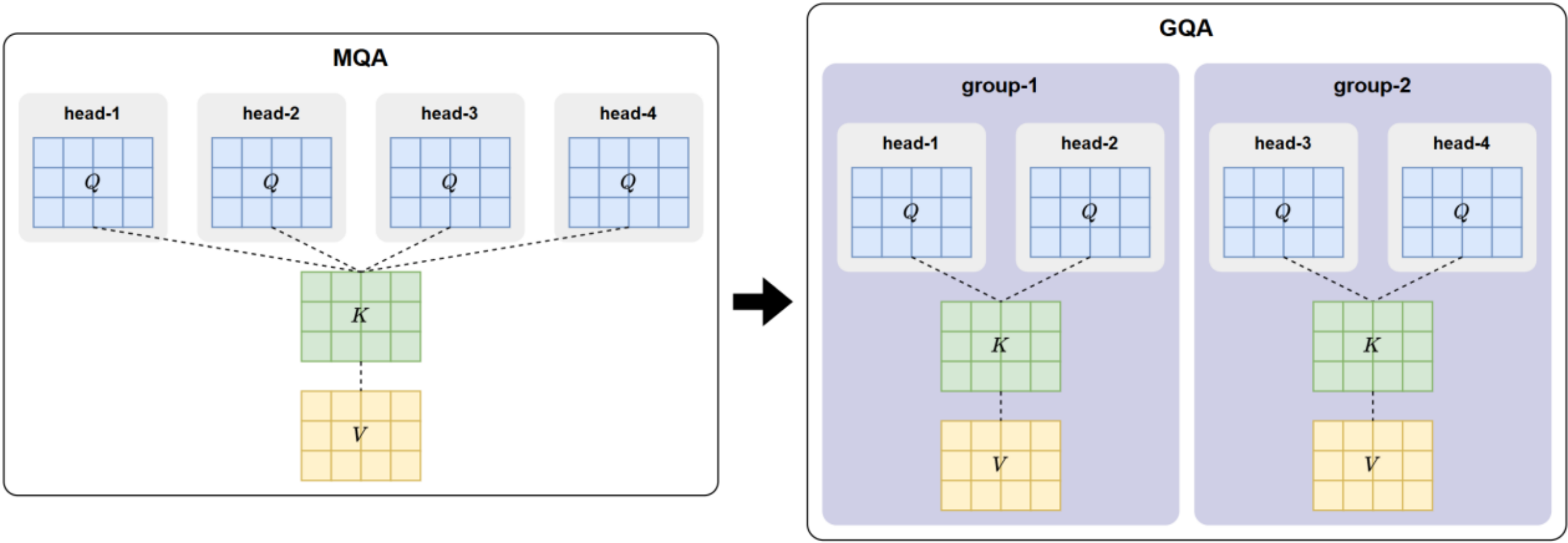
优点:GQA 在 推理效率和表达能力之间实现了更优平衡。因此被主流大模型所采用,在长序列推理和高并发场景中表现极为出色。
不足:依然会削弱注意力头的表达能力。
5. MLA(Multi-Head Latent Attention)
MLA的核心思想是不再直接缓存多头 K/V,而是先把它们压缩到一个共享的低维“潜在向量”里,只缓存这个低维向量,再在需要算注意力时从中恢复出各头的 K/V。
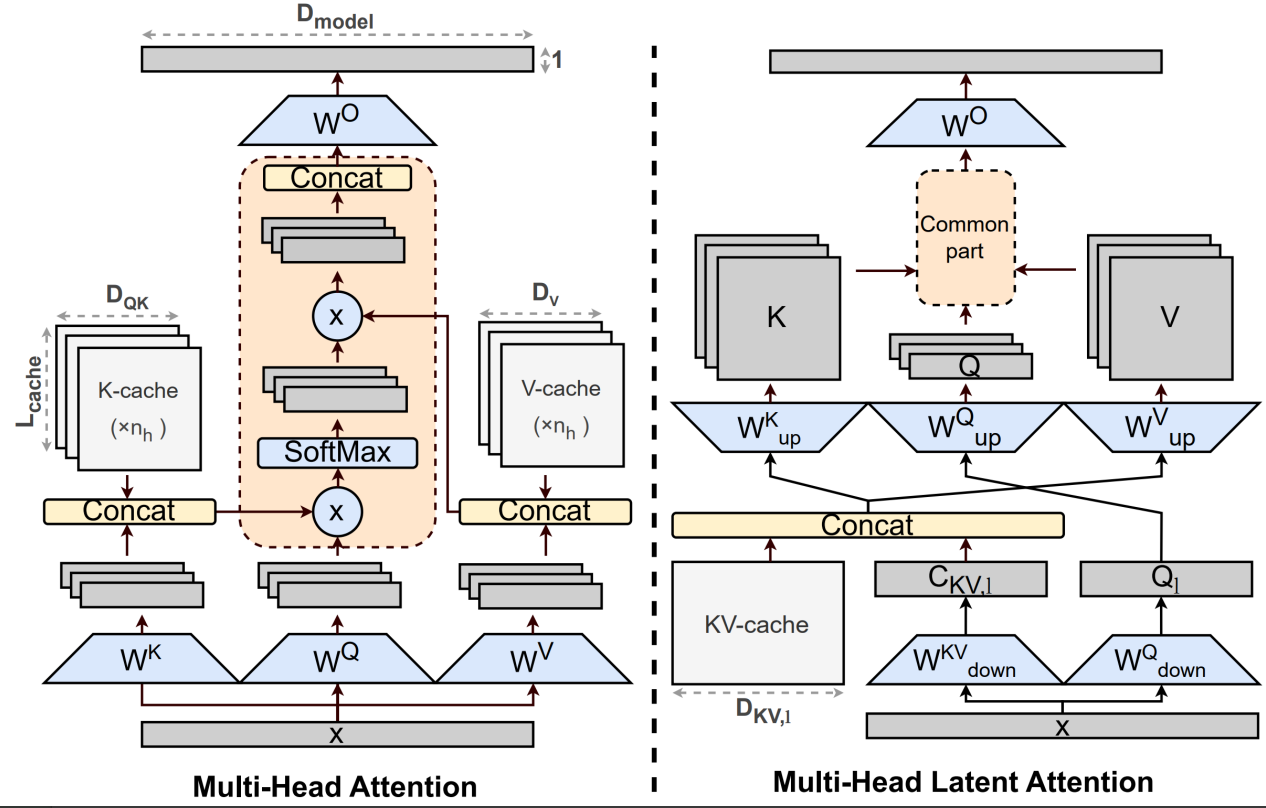
优点:MLA 能显著减少推理阶段的 KV Cache,同时保持多头注意力的表达多样性。

- 点赞
- 收藏
- 关注作者
评论(0)