实现一个基于LangChain 的 RAG 智能问答Agent实践

概述
本文基于本项目的实际实现,介绍基于langchain框架,从文档导入到向量存储、再到多轮检索问答的端到端RAG实践。使用Langfuse实现LLMOps监控,自动捕获链中每一步的输入输出。
整体架构
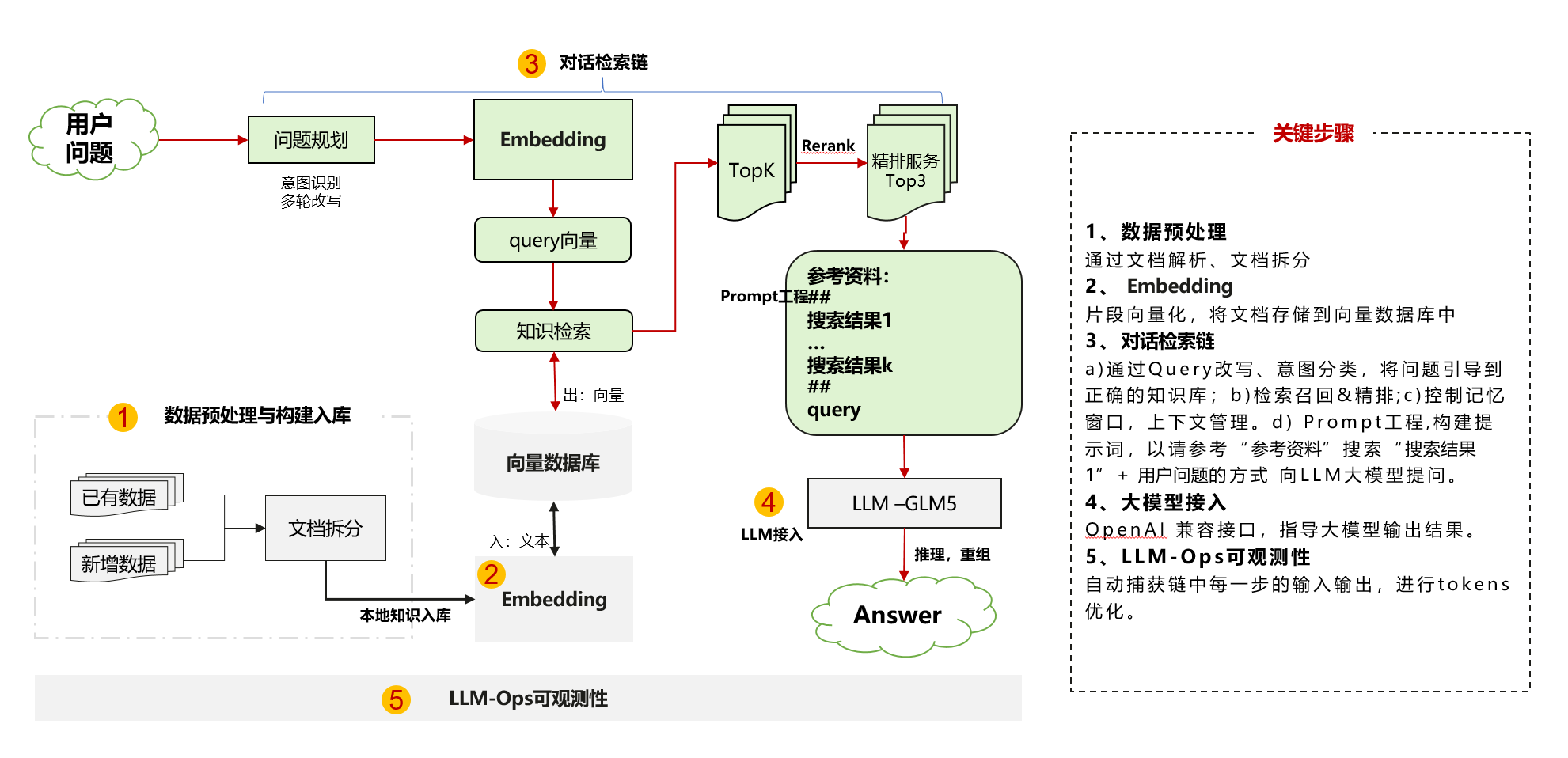
应用程序
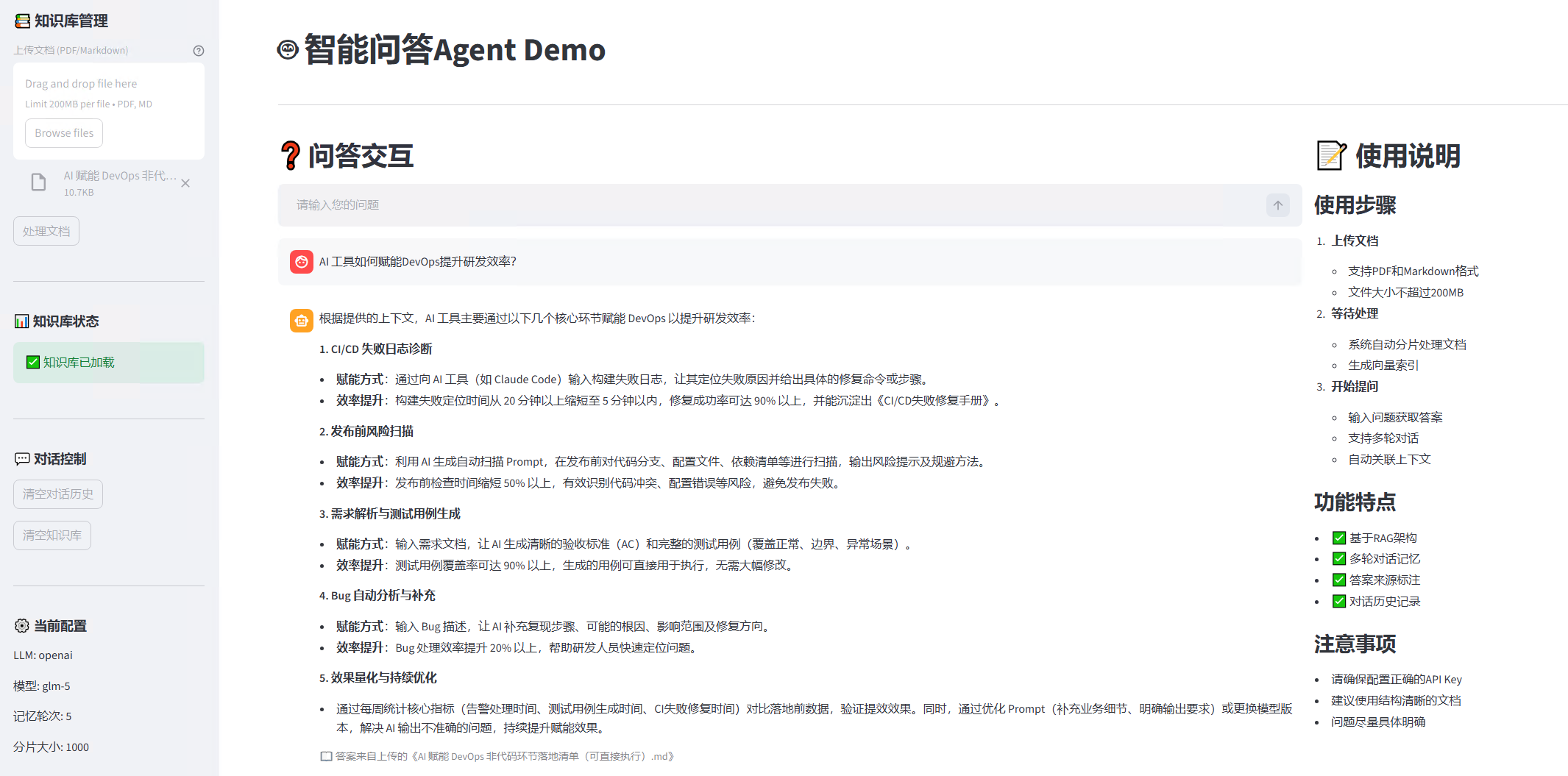
程序跑起来的样子:
一、文档加载与切分
1.1 多格式加载
针对不同文档格式使用对应的 Loader,保留原始结构与元数据(如页码、来源路径):
# document_processor.py
from langchain_community.document_loaders import PyPDFLoader, UnstructuredMarkdownLoader
def load_document(file_path: str):
ext = os.path.splitext(file_path)[1].lower()
if ext == ".pdf":
loader = PyPDFLoader(file_path) # 逐页加载,自动提取页码到 metadata
elif ext == ".md":
loader = UnstructuredMarkdownLoader(file_path) # 保留 Markdown 结构
else:
raise ValueError(f"不支持的文件格式: {ext}")
return loader.load()说明:
- PDF 使用
PyPDFLoader,每页生成一个Document,metadata["page"]自动记录页码 - Markdown 使用
UnstructuredMarkdownLoader,可保留标题层级语义 - 始终验证返回列表非空,避免空文档流入后续流程
1.2 递归文本切分
文本切分是影响检索质量的关键环节。使用 RecursiveCharacterTextSplitter 按语义边界(段落→句子→词)逐级尝试切分:
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每块最大字符数
chunk_overlap=100, # 相邻块重叠字符数,保留上下文连续性
)
chunks = splitter.split_documents(docs)
# 过滤纯空白块,避免噪声进入向量库
chunks = [c for c in chunks if c.page_content.strip()]关键参数权衡:
| 参数 | 偏小 | 偏大 |
|---|---|---|
chunk_size |
语义不完整,上下文丢失 | 噪声增多,检索精度下降 |
chunk_overlap |
块边界处信息断裂 | 冗余数据增加,向量库膨胀 |
说明:
- 中文技术文档推荐
chunk_size=800~1200,chunk_overlap=80~150 - 对结构化文档(表格、列表为主)可适当降低
chunk_size - 切分后务必过滤空白块,否则会引入无意义的零向量污染检索结果
二、向量化与存储
2.1 Embeddings 选型
本项目使用 text-embedding-v3 模型:
# config.py
from langchain_community.embeddings import DashScopeEmbeddings
def get_embeddings():
return DashScopeEmbeddings(
model="text-embedding-v3",
dashscope_api_key=DASHSCOPE_API_KEY,
)说明:
- Embeddings 模型与 LLM 的语言偏好应保持一致(中文文档 → 中文 Embeddings)
- 不同 Embeddings 模型生成的向量不可混用;更换模型后必须重建整个向量库
2.2 FAISS 向量库
# vector_store.py
from langchain_community.vectorstores import FAISS
def create_vector_store(documents):
embeddings = get_embeddings()
vector_store = FAISS.from_documents(documents, embeddings)
return vector_store
def get_retriever(vector_store, k=3):
return vector_store.as_retriever(search_kwargs={"k": k})FAISS 在内存中构建索引,适合中小规模知识库(万级以内文本块)。as_retriever(search_kwargs={"k": 3}) 表示每次检索返回相似度最高的 3 个文档块。
最佳实践:
k值推荐 3~5;过小会漏掉关键片段,过大则引入噪声,稀释 LLM 的注意力- 生产环境中需要将向量库持久化到磁盘,避免重启后重新构建:
vector_store.save_local("faiss_index") # 保存 FAISS.load_local("faiss_index", embeddings) # 加载 - 文档更新时,用
vector_store.add_documents(new_chunks)增量追加,而非全量重建
三、对话检索链
3.1 链的工作流程
ConversationalRetrievalChain 将多轮对话与向量检索结合,分两步执行:
用户提问 + 对话历史
│
▼ Step 1: 问题改写
[Condense Question LLM]
将追问改写为独立的完整问题
│
▼ Step 2: 检索 + 生成
[Retriever] → 相关文档块
│
[QA LLM] → 最终回答3.2 Prompt 设计
问题改写 Prompt:
_CONDENSE_QUESTION_PROMPT = PromptTemplate.from_template(
"""根据以下对话历史和后续问题,将后续问题改写为一个独立的问题。
对话历史:
{chat_history}
后续问题: {question}
独立问题:"""
)QA 回答 Prompt:
说明:
- QA Prompt 中明确禁止编造是防止幻觉的关键约束
- 要求 LLM 注明来源,使结果可追溯、可验证
- 提供明确的兜底回复("未查询到相关信息"),避免 LLM 在无关文档中强行拼凑答案
3.3 链的组装
# qa_chain.py
def create_qa_chain(retriever):
llm = get_llm()
memory = ConversationBufferWindowMemory(
k=5, # 保留最近 5 轮对话
memory_key="chat_history",
return_messages=True, # 以消息对象格式返回,兼容 Chat 模型
output_key="answer", # 只将 answer 字段写入记忆,排除 source_documents
)
chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=retriever,
memory=memory,
condense_question_prompt=_CONDENSE_QUESTION_PROMPT,
combine_docs_chain_kwargs={"prompt": _QA_PROMPT},
return_source_documents=True, # 返回检索到的原始文档,用于来源标注
)
return chain说明:
output_key="answer"配合return_source_documents=True时是必填项,否则记忆模块无法识别应写入哪个输出字段return_messages=True使记忆以ChatMessage对象列表返回,与 Chat 类型 LLM(如ChatOpenAI)原生兼容;若使用文本补全模型则应设为Falsek=5控制记忆窗口;过大会使 Prompt 超过 LLM 上下文长度限制,推荐 3~8
3.4 来源标注
检索完成后,从 source_documents 中提取文件名附加在回答末尾:
def ask(chain, question: str) -> str:
result = chain({"question": question}, callbacks=callbacks)
answer = result["answer"]
source_docs = result.get("source_documents", [])
sources = set()
for doc in source_docs:
source = doc.metadata.get("source", "未知来源")
sources.add(source)
if sources:
source_text = "、".join(sources)
if source_text not in answer:
answer += f"\n\n📄 来源: {source_text}"
return answer说明:
- 使用
set()对来源去重,避免同一文件被多个 chunk 命中时重复显示 - 在追加来源前检查 LLM 是否已自行引用,避免重复(
if source_text not in answer)
四、LLM 接入
4.1 OpenAI 兼容接口(推荐)
使用 ChatOpenAI + 自定义 base_url,可无缝接入任何兼容 OpenAI 协议的大模型(如华为云 GLM-5等):
# config.py
from langchain_openai import ChatOpenAI
def get_llm():
return ChatOpenAI(
model=LLM_MODEL_NAME, # 如 "glm-5"
api_key=LLM_API_KEY,
base_url=LLM_API_BASE, # 如 "https://api.modelarts-maas.com/openai/v1"
)说明:
- 优先使用
ChatOpenAI(Chat 模型)而非LLM(文本补全模型),因为前者原生支持消息格式,与ConversationalRetrievalChain的多轮记忆机制兼容性更好 - 通过环境变量管理凭证,永远不要将 API Key 硬编码进源码
- 若需要切换模型,只需修改
.env中的三个变量,无需改代码
五、可观测性:Langfuse 集成
5.1 为什么需要 RAG 可观测性
RAG 系统的质量问题往往难以定位,常见问题包括:
- 检索阶段返回了不相关文档
- 改写后的独立问题语义发生偏移
- LLM 忽略检索结果、产生幻觉
Langfuse 通过 LangChain CallbackHandler 自动捕获链中每一步的输入输出,在 Dashboard 中可视化展示完整的 Span 树。
5.2 集成方式(Langfuse 3.x)
Langfuse 3.x 通过环境变量自动配置,只需传入 CallbackHandler:
# config.py — 环境变量自动读取 LANGFUSE_PUBLIC_KEY / SECRET_KEY / HOST
from langfuse.langchain import CallbackHandler
def get_langfuse_handler():
if not LANGFUSE_ENABLED:
return None
return CallbackHandler(update_trace=True)
# qa_chain.py — 将 handler 注入 chain 调用
handler = get_langfuse_handler()
callbacks = [handler] if handler else None
result = chain({"question": question}, callbacks=callbacks)必须在 .env 中配置:
LANGFUSE_PUBLIC_KEY=pk-lf-xxx
LANGFUSE_SECRET_KEY=sk-lf-xxx
LANGFUSE_HOST=http://your-langfuse-host:3000最佳实践:
- 通过
LANGFUSE_ENABLED标志(当 key 缺失时自动为False)实现零侵入降级,不影响无 Langfuse 的部署环境 - Langfuse 3.x 基于 OpenTelemetry,不需要手动调用
flush(),trace 由后台线程异步上报 update_trace=True会将链的输入/输出自动写入 trace 根节点,方便在 Dashboard 直接查看 Q&A 对
六、配置管理最佳实践
所有运行参数通过环境变量集中管理,代码中无任何硬编码值:
# config.py
load_dotenv() # 从 .env 文件加载
CHUNK_SIZE = int(os.getenv("CHUNK_SIZE", "1000")) # 带默认值
CHUNK_OVERLAP = int(os.getenv("CHUNK_OVERLAP", "100"))
TOP_K = int(os.getenv("TOP_K", "3"))
MEMORY_ROUNDS = int(os.getenv("MEMORY_ROUNDS", "5"))完整 .env 配置示例:
# LLM(必填)
LLM_API_KEY=your_api_key
LLM_API_BASE=https://api.modelarts-maas.com/openai/v1
LLM_MODEL_NAME=glm-5
# 嵌入向量配置
# 使用 'modelarts' 表示华为云 ModelArts bge-m3 嵌入向量
EMBEDDINGS_PROVIDER=modelarts
# 嵌入向量 API 配置
EMBEDDINGS_API_BASE=https://api.modelarts-maas.com/v1
EMBEDDINGS_MODEL=bge-m3
# 文档处理(可选,有默认值)
CHUNK_SIZE=1000
CHUNK_OVERLAP=100
TOP_K=3
MEMORY_ROUNDS=5
# Langfuse 可观测性(可选)
LANGFUSE_PUBLIC_KEY=pk-lf-xxx
LANGFUSE_SECRET_KEY=sk-lf-xxx
LANGFUSE_HOST=http://localhost:3000
- 点赞
- 收藏
- 关注作者
评论(0)