华为大咖说 | AI Agent大热背后的冷思考:技术理想与业务落地的鸿沟如何跨越?

该文章来自于时习知公众号
2023年,以大模型为基座的AI Agent成为全球科技领域的焦点。而2025年,更是被业界誉为AI Agent的元年,各大科技巨头纷纷竞相推出自家的AI Agent产品。AI Agent承载着“颠覆生产力”的厚望,它仿佛拥有智慧,能够精准理解人类意图,自主拆解复杂任务,灵活调用各类工具,最终高效完成任务闭环。资本和媒体为之沸腾,技术社区涌现出大量实验性Demo,仿佛通用人工智能(AGI)的雏形已触手可及。
然而,当视角转向企业级(ToB)市场时,发现客户/内部商业领袖对AI表现出强烈兴趣,提出的需求基本是:“能否用AI解决我的核心业务问题?比如替代50%的重复性人工决策,E2E内部效率提升30%,工单问题减半”——这些需求往往涉及复杂业务流程、高可靠性要求和垂直领域知识,而实际上AI Agent当前应用的现状:
✦ 技术尚未成熟:AI Agent在复杂业务场景中的稳定性、可解释性和可靠性仍不足;
✦ 落地周期长:从PoC(概念验证)到规模化应用,往往需要数月甚至更久的迭代;
✦ ROI(投资回报率)难以短期兑现:AI的价值需要数据积累、模型优化和业务适配,而非立竿见影。
矛盾点:企业对AI的“速胜期待”与技术演进的“渐进现实”
当前,企业在AI Agent的落地过程中,普遍存在两种矛盾心态:
1. “既要快,又要好”:希望AI能快速上线并带来显著业务提升,但不愿接受技术早期的不完美;
2. “高预期,低容忍”:对AI的长期潜力充满信心,但对短期试错成本缺乏耐心。
这种矛盾其实导致许多AI项目陷入困境:
✦ 过早放弃:企业在PoC阶段发现效果未达预期,便直接叫停,错失优化机会;
✦ 过度追求短期ROI:仅关注“能立刻赚钱”的场景,忽视更具战略价值的长期AI能力建设;
✦ 缺乏技术培育环境:AI需要持续的数据反馈和算法迭代,但企业往往希望“一次部署,终身受益”。
Agent繁荣下的虚假繁荣:我们真的在构建智能,还是仅仅在“套壳”?
这种情况应该比较普遍,“既要又要还要”下势必会带来大量的套壳Agent(90%以上),以历史积累的大量工具通过Prompt/Function Call/MCP调度形成一个个定制化的烟囱Agent,工具的输入输出都没有变化,只在工具的使用门槛/便捷性上有所增益,LLM+MCP形成的LUI到底有何帮助?大多数Agent本质上仍是“旧酒装新瓶”——LLM(大语言模型)仅仅充当了一个更友好的交互层(LUI),而真正的业务逻辑、数据处理、决策流程仍由工程师“手动编排”,AI并未真正“理解”或“解决”问题:
1. “套壳Agent”的典型模式
“套壳Agent”大致可归类为以下几种形态:
(1) “Prompt+Function Call/MCP”型Agent:通过自然语言解析用户意图,但实际执行仍依赖固定工具链,LLM仅作“路由分发”。
例如:用户说“帮我分析上周销售数据”,Agent只是调用了现成的数据分析工具,输出格式甚至未优化。
(2) “伪调度型Agent”:利用流程引擎编排工具,LLM仅生成参数或触发节点,业务逻辑完全硬编码。
例如:预测Agent仅是按固定规则调用历史模型,LLM未参与实际决策。
(3) “问答包装型Agent”:将原有知识库/文档接口套上LLM的问答交互,但答案质量仍取决于底层数据,未实现真正的推理。
例如:客服Agent能回答标准问题,但遇到复杂案例仍需人工介入。
这些Agent的共同点是:工具未进化,交互更友好——本质上是用LLM降低了工具使用门槛,但未触及业务核心。
2. LLM沦为“语言UI层”(LUI)的三大表现
(1) 输入输出无变化,仅交互方式升级
· 传统方式:用户填写表单 → 工具返回表格。
· “智能”方式:用户用自然语言描述需求 → 工具仍返回相同表格,只是多了几句LLM生成的“解释”。
(2) 工程师仍是“人肉调度中枢”
· Agent无法自主处理边界情况(如数据缺失、冲突规则),仍需工程师写规则补丁。
(3) 工具间未形成“智能协同”
· 现有Agent多为单点工具封装,跨系统协作依赖预先编排的流程。
3. 为何会陷入“套壳陷阱”?
✦ 业务压力:追求“快速上线”,只能复用现有工具,放弃深度改造。
✦ 技术妥协:LLM在复杂业务中可靠性不足,被迫退守“安全区”(如仅做文本生成)。
✦ 评估偏差:用“交互体验提升”掩盖“业务逻辑未进化”的事实。
关键问题:我们是否在用AI逃避真正的智能化?
当前AI应用看似遍地开花,实则暗藏隐患:我们正用"AI包装"掩盖业务数字化进程中的本质问题。当技术团队疲于将现有工具套上LLM外壳,业务团队满足于"能用自然语言操作旧系统"的伪升级时,真正的智能化转型正在被系统性延误。

AI Agent实践建议:短期做薄,长期做厚—一名技术落地者的实践思考
当前AI Agent在业务落地中面临的核心矛盾,本质上是 “技术渐进性”与“业务紧迫性” 之间的天然冲突——技术的成熟需要时间迭代,而业务需要快速看到价值。这一矛盾短期内难以彻底解决,但AI从业者,我们可以在现有约束下找到一些可能共赢的更优路径。
个人分享两点关键思考,供大家探讨:
1. 短期数据+技术应用线:围绕工程师旅程做厚知识底座,做薄应用层,为Agent储备“口粮”
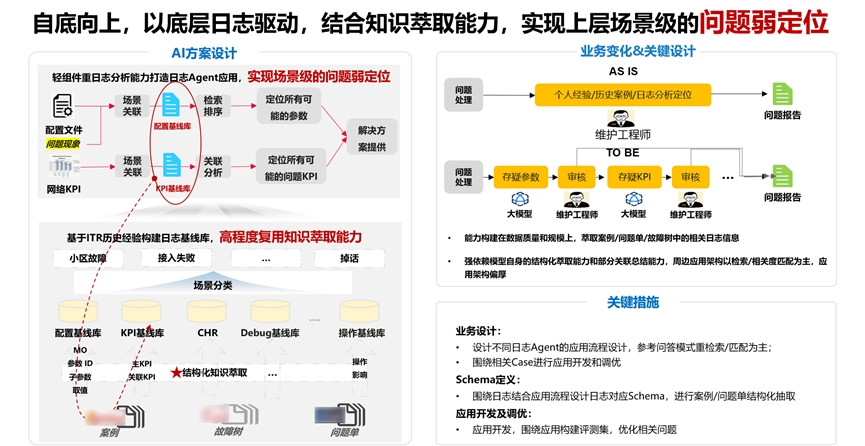
以在无线问题处理领域的实践和探索为例,维护工程师本质的个人壁垒还是在知识与经验的积累,是一个以经验作为壁垒的职业,传统模式依赖工程师个人经验积累,存在知识碎片化、传承效率低等痛点。随着大模型技术发展,所以一个可以缓解的方式是,不追求颠覆式的"万能Agent",先打造坚实的知识基础设施,让AI成为领域知识的"集大成者"。
一)知识底座构建
✦ 结构化萃取:将散落的故障案例、处理手册、专家笔记转化为标准化知识单元(无线可以以日志维度构建日志基线库)。
✦ 关系网络构建:通过因果分析建立问题间的关联图谱(可能潜在方向)。
✦ 动态演进机制:设置知识置信度评分,随实际处理结果反馈持续优化(可能潜在方向)
二)智能分析层(以检索/匹配/聚类等传统相对稳定的形式)
模式识别引擎:基于历史日志自动检索/匹配聚类典型问题模式(如"某型号设备在低温下的共性故障特征")
整套方案还是以做厚知识底座,形成日志定位的基线库,上层调用这些基线库可以以问答/匹配/聚类/关联分析等传统的ML类相对成熟的技术路线去辅助维护域的工程师进行问题定位,但是本质还是“问答包装型Agent”,在维护领域可能会有一定的业务成效,因为工程师的问题定位模式可能会从依赖个人经验匹配转变为有迹可循。更为关键的是,此方案在底层数据层面创造了真正的价值,它是历史知识萃取工作的延续。
从架构设计上看,这其实也是一种"反脆弱"架构:
1)即使模型能力暂时不足,扎实的知识库仍能提供基础价值;
2)当模型升级时,已有知识体系能立即释放更大效能;
3)在AI技术波动期,确保大家的投入不会"归零"
2. 长期创新技术线:坚持“真Agent”方向,避免陷入“套壳陷阱”
长期主义来看,我们可以围绕端到端强化学习的理念持续进行模型和外系统的rollout(尽管这个技术方向和学界交流来看还很初步,但整体学术界和工业界的热情度很大,奇点的来临应该比想象的要快),在问题处理场景下则是领域推理模型结合外部的日志获取工具,基于日志工具反复探寻最终定位根因。
在ToC场景其实已经能看到比较惊人的效果,但ToB领域的数据复杂性/工具多样性/以及研究算法本身的不确定性带来的Agent Model训练复杂度也是极高,需要真正的领域专家+算法专家实现1+1>>2的效果;
结语:AI Agent的落地是一场马拉松,而非冲刺
AI Agent的潜力毋庸置疑,但它的成熟需要给予更多耐心和包容度以及宽约束下的切实投入,围绕上下文工程在推理界面的目标态搭建也是策略之一,历史经验表明,颠覆性技术(如云计算、移动互联网)的规模化应用往往需要5-10年,而AI Agent仍处于早期阶段。
我们还是要能以更长远的视角看待AI,摒弃套壳思维,深耕价值创造,允许技术试错、持续投入并建立适应性的管理机制,才能真正抓住AI Agent带来的变革机遇。

- 点赞
- 收藏
- 关注作者
评论(0)