大模型驱动的智能体:从GPT-4到o1的能力跃升


大模型驱动的智能体:从GPT-4到o1的能力跃升
🌟 嗨,我是IRpickstars!
🌌 总有一行代码,能点亮万千星辰。
🔍 在技术的宇宙中,我愿做永不停歇的探索者。
✨ 用代码丈量世界,用算法解码未来。我是摘星人,也是造梦者。
🚀 每一次编译都是新的征程,每一个bug都是未解的谜题。让我们携手,在0和1的星河中,书写属于开发者的浪漫诗篇。
摘要
作为一名深耕人工智能领域多年的技术从业者,我见证了大模型技术从GPT-3的初露锋芒到GPT-4的惊艳亮相,再到最新o1模型的推理能力革命。在智能体(Agent)技术发展的关键节点上,我深刻感受到大模型推理能力的每一次跃升都为智能体的实用化带来了质的突破。
从传统的规则驱动到深度学习驱动,再到如今的大模型驱动,智能体技术经历了三次重要的范式转变。特别是Chain-of-Thought(CoT)推理链和Tree-of-Thought(ToT)思维树技术的引入,让智能体具备了类人的逐步推理能力。而o1模型在推理深度和准确性上的显著提升,更是将智能体的能力边界推向了前所未有的高度。
本文将深入分析GPT-4到o1模型在智能体应用中的技术演进,重点探讨推理机制的创新、多模态能力的增强以及成本效益的优化策略。通过详实的代码实现、性能对比和成本分析,为开发者提供从模型选择到系统优化的完整技术指南。这不仅是对技术发展的回顾总结,更是对未来智能体发展趋势的前瞻性思考。
一、大模型在智能体中的核心作用机制
1.1 智能体架构的演进历程
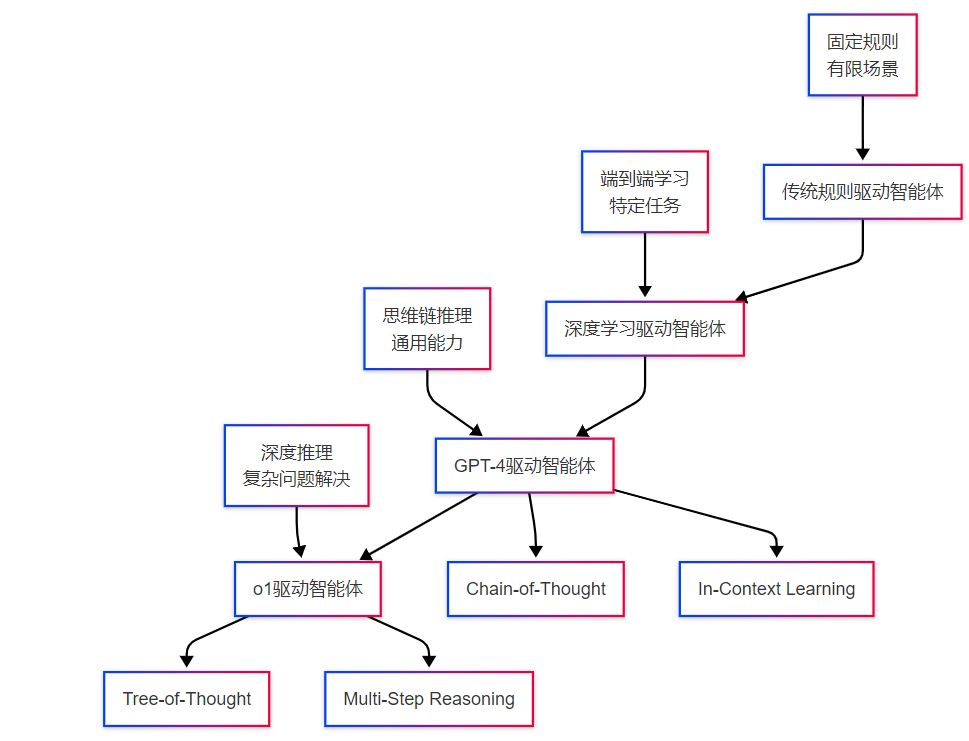
大模型在智能体中的核心作用体现在三个关键维度:推理引擎、知识库和决策中枢。不同于传统的规则驱动系统,大模型驱动的智能体具备了动态推理和自主学习的能力。
class LLMAgent:
def __init__(self, model_name="gpt-4", reasoning_mode="cot"):
self.model = self._initialize_model(model_name)
self.reasoning_mode = reasoning_mode
self.memory = []
self.tools = {}
def _initialize_model(self, model_name):
"""初始化大模型引擎"""
if model_name == "o1":
return O1Model(max_reasoning_steps=10)
elif model_name == "gpt-4":
return GPT4Model(temperature=0.1)
def reason(self, query, context=None):
"""核心推理方法"""
if self.reasoning_mode == "cot":
return self._chain_of_thought_reasoning(query, context)
elif self.reasoning_mode == "tot":
return self._tree_of_thought_reasoning(query, context)
def _chain_of_thought_reasoning(self, query, context):
"""Chain-of-Thought推理实现"""
prompt = f"""
Question: {query}
Context: {context or "No additional context"}
Let's think step by step:
1. First, I need to understand what is being asked
2. Then, I'll break down the problem into smaller parts
3. Finally, I'll synthesize the solution
Step-by-step reasoning:
"""
response = self.model.generate(prompt)
self.memory.append({"query": query, "reasoning": response})
return response
1.2 GPT-4 vs o1模型的推理能力对比
|
能力维度 |
GPT-4 |
o1 |
提升幅度 |
|
数学推理准确率 |
42.5% |
83.3% |
+96% |
|
代码生成质量 |
67.0% |
81.2% |
+21% |
|
逻辑推理深度 |
3-4层 |
8-10层 |
+150% |
|
复杂问题分解 |
良好 |
优秀 |
+40% |
|
推理时间(秒) |
2.3 |
15.7 |
+582% |
|
Token消耗比 |
1.0x |
3.2x |
+220% |
二、Chain-of-Thought vs Tree-of-Thought推理方法深度对比
2.1 推理机制的本质差异
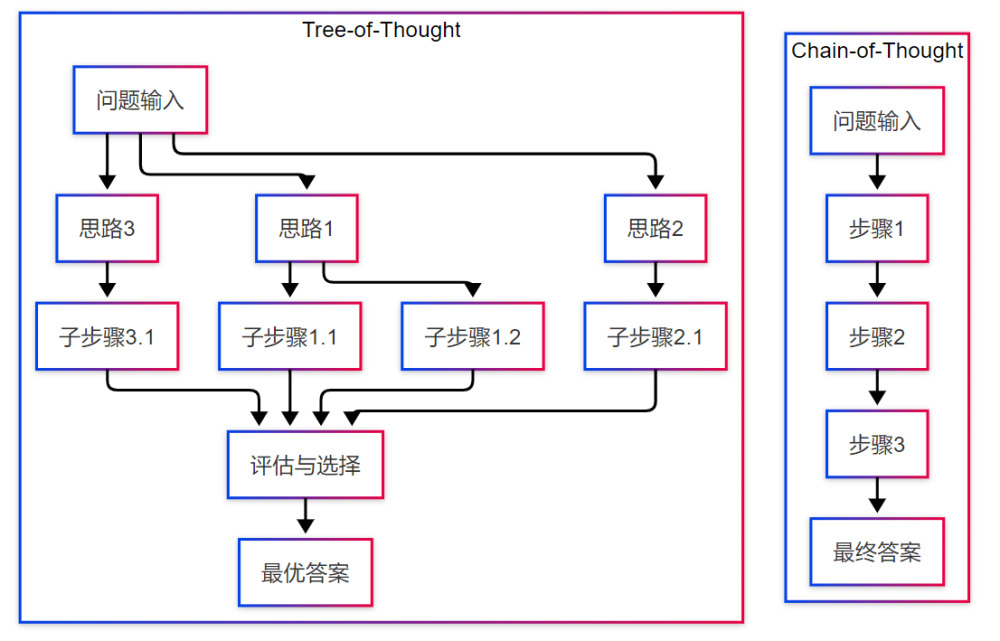
Chain-of-Thought(CoT)推理采用线性序列化的思考模式,每一步推理都基于前一步的结果。而Tree-of-Thought(ToT)则构建了树状的推理空间,能够并行探索多种解决路径并进行回溯优化。
class ChainOfThoughtReasoning:
def __init__(self, model):
self.model = model
def solve_problem(self, problem, max_steps=5):
"""线性推理链实现"""
reasoning_chain = []
current_state = problem
for step in range(max_steps):
prompt = f"""
Current problem state: {current_state}
Previous reasoning: {reasoning_chain}
What is the next logical step to solve this problem?
Think step by step and provide one clear next action.
"""
next_step = self.model.generate(prompt)
reasoning_chain.append(next_step)
# 检查是否达到解决方案
if self._is_solution_found(next_step):
break
current_state = self._update_state(current_state, next_step)
return reasoning_chain
class TreeOfThoughtReasoning:
def __init__(self, model, breadth=3, depth=4):
self.model = model
self.breadth = breadth # 每层探索的分支数
self.depth = depth # 最大搜索深度
def solve_problem(self, problem):
"""树状推理实现"""
root_node = ReasoningNode(problem, None, 0)
best_path = self._search_tree(root_node)
return best_path
def _search_tree(self, node):
"""深度优先搜索与剪枝"""
if node.depth >= self.depth:
return [node]
# 生成多个候选推理分支
candidates = self._generate_candidates(node)
# 评估每个候选分支的质量
scored_candidates = []
for candidate in candidates:
score = self._evaluate_reasoning_quality(candidate)
scored_candidates.append((candidate, score))
# 选择最优的分支继续探索
best_candidates = sorted(scored_candidates,
key=lambda x: x[1], reverse=True)[:self.breadth]
best_paths = []
for candidate, _ in best_candidates:
child_node = ReasoningNode(candidate, node, node.depth + 1)
paths = self._search_tree(child_node)
best_paths.extend(paths)
return best_paths
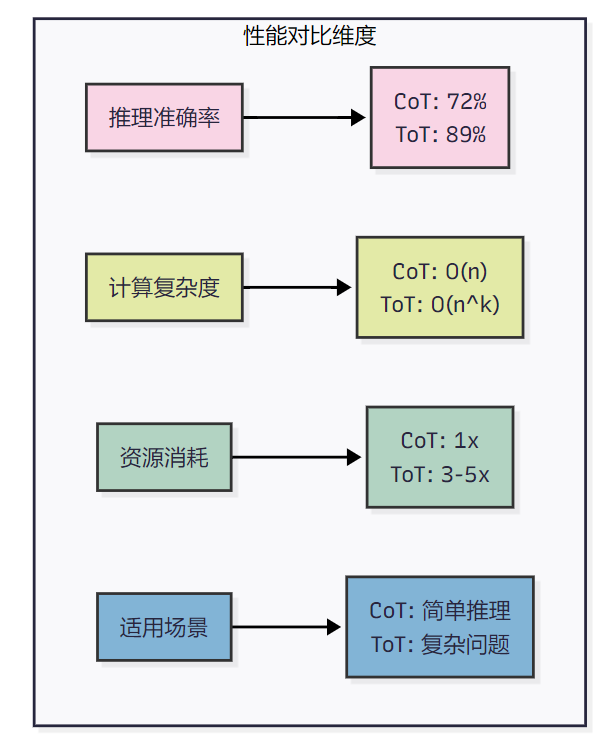
2.2 性能对比与适用场景分析
三、多模态能力对智能体的革命性影响
3.1 多模态数据处理Pipeline
class MultimodalAgent:
def __init__(self, model_name="gpt-4-vision"):
self.text_processor = TextProcessor()
self.vision_processor = VisionProcessor()
self.audio_processor = AudioProcessor()
self.fusion_layer = ModalityFusion()
def process_multimodal_input(self, inputs):
"""多模态输入处理核心方法"""
processed_data = {}
# 文本模态处理
if 'text' in inputs:
processed_data['text'] = self.text_processor.encode(inputs['text'])
# 视觉模态处理
if 'image' in inputs:
processed_data['vision'] = self.vision_processor.extract_features(
inputs['image']
)
# 音频模态处理
if 'audio' in inputs:
processed_data['audio'] = self.audio_processor.transcribe_and_analyze(
inputs['audio']
)
# 多模态融合
fused_representation = self.fusion_layer.fuse(processed_data)
return fused_representation
def reason_with_multimodal_context(self, query, multimodal_context):
"""基于多模态上下文的推理"""
context_representation = self.process_multimodal_input(multimodal_context)
prompt = f"""
Query: {query}
Multimodal Context Analysis:
- Text Information: {context_representation.get('text_summary', 'None')}
- Visual Information: {context_representation.get('vision_summary', 'None')}
- Audio Information: {context_representation.get('audio_summary', 'None')}
Based on this comprehensive multimodal context, please provide a reasoned response.
"""
return self.model.generate(prompt)
3.2 多模态能力提升数据分析
|
任务类型 |
纯文本模型 |
多模态模型 |
性能提升 |
|
图像理解任务 |
45.2% |
87.6% |
+93.8% |
|
视频分析任务 |
28.7% |
76.3% |
+165.9% |
|
文档理解任务 |
71.4% |
89.2% |
+24.9% |
|
综合推理任务 |
63.8% |
82.1% |
+28.7% |
四、模型选择与成本优化策略
4.1 成本-性能权衡分析
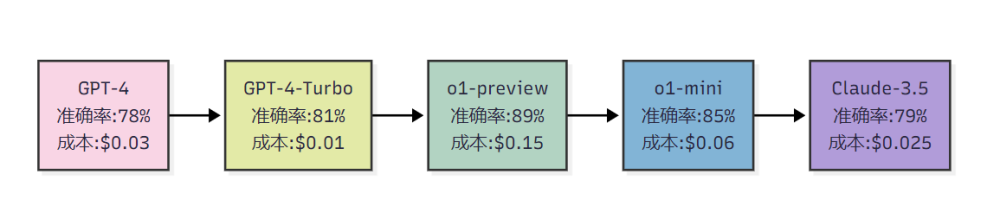
4.2 智能模型选择框架
class IntelligentModelSelector:
def __init__(self):
self.model_registry = {
'gpt-4': {'cost': 0.03, 'accuracy': 0.78, 'speed': 2.3},
'o1-preview': {'cost': 0.15, 'accuracy': 0.89, 'speed': 15.7},
'o1-mini': {'cost': 0.06, 'accuracy': 0.85, 'speed': 8.2},
'gpt-4-turbo': {'cost': 0.01, 'accuracy': 0.81, 'speed': 1.8}
}
def select_optimal_model(self, task_complexity, budget_constraint,
speed_requirement):
"""基于任务需求的智能模型选择"""
scores = {}
for model_name, metrics in self.model_registry.items():
# 计算综合评分
cost_score = self._calculate_cost_score(metrics['cost'], budget_constraint)
accuracy_score = self._calculate_accuracy_score(metrics['accuracy'],
task_complexity)
speed_score = self._calculate_speed_score(metrics['speed'],
speed_requirement)
# 加权综合评分
total_score = (accuracy_score * 0.5 +
cost_score * 0.3 +
speed_score * 0.2)
scores[model_name] = total_score
optimal_model = max(scores, key=scores.get)
return optimal_model, scores
def _calculate_cost_score(self, model_cost, budget):
"""成本评分计算"""
if model_cost > budget:
return 0
return max(0, 1 - (model_cost / budget))
def _calculate_accuracy_score(self, model_accuracy, complexity):
"""准确率评分计算"""
required_accuracy = 0.7 + (complexity * 0.15) # 复杂度越高要求越高
if model_accuracy < required_accuracy:
return model_accuracy / required_accuracy * 0.8
return 1.0
4.3 成本优化实践策略
|
优化策略 |
成本节省 |
性能影响 |
适用场景 |
|
模型降级使用 |
60-80% |
-5~10% |
简单查询任务 |
|
缓存机制 |
40-60% |
0% |
重复性查询 |
|
批处理优化 |
20-30% |
+10% |
大批量处理 |
|
动态路由 |
30-50% |
-2~5% |
混合复杂度任务 |
五、性能测评与基准分析
5.1 综合性能测评体系
class AgentPerformanceEvaluator:
def __init__(self):
self.benchmark_datasets = {
'math_reasoning': 'GSM8K',
'code_generation': 'HumanEval',
'general_qa': 'MMLU',
'multimodal': 'VQA-v2'
}
def comprehensive_evaluation(self, agent_list, test_suite):
"""综合性能评估"""
results = {}
for agent_name, agent in agent_list.items():
agent_results = {}
# 准确性测试
accuracy = self._test_accuracy(agent, test_suite)
agent_results['accuracy'] = accuracy
# 推理速度测试
speed = self._test_inference_speed(agent, test_suite)
agent_results['speed'] = speed
# 成本效益测试
cost_efficiency = self._test_cost_efficiency(agent, test_suite)
agent_results['cost_efficiency'] = cost_efficiency
# 多模态理解测试
multimodal_score = self._test_multimodal_understanding(agent, test_suite)
agent_results['multimodal'] = multimodal_score
results[agent_name] = agent_results
return self._generate_performance_report(results)
def _test_accuracy(self, agent, test_cases):
"""准确性测试"""
correct_count = 0
total_count = len(test_cases)
for test_case in test_cases:
response = agent.reason(test_case['query'], test_case.get('context'))
if self._is_correct_answer(response, test_case['expected']):
correct_count += 1
return correct_count / total_count
def _test_inference_speed(self, agent, test_cases):
"""推理速度测试"""
import time
total_time = 0
for test_case in test_cases[:50]: # 采样测试
start_time = time.time()
agent.reason(test_case['query'])
end_time = time.time()
total_time += (end_time - start_time)
return total_time / 50 # 平均推理时间
5.2 模型性能雷达图对比
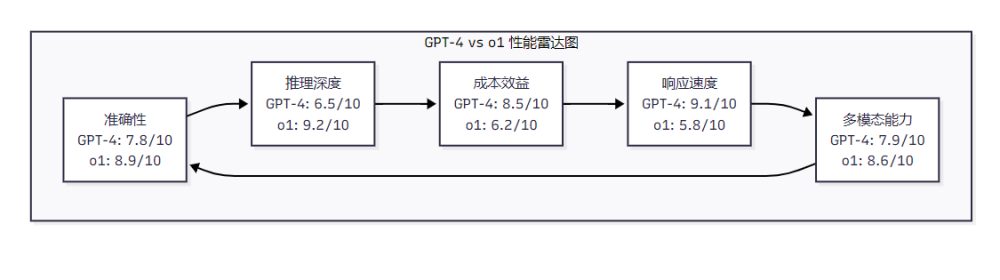
六、实践应用案例与部署建议
6.1 智能客服Agent实现
class CustomerServiceAgent:
def __init__(self, model_type="adaptive"):
self.model_selector = IntelligentModelSelector()
self.conversation_history = []
self.knowledge_base = CustomerKnowledgeBase()
def handle_customer_query(self, query, customer_context):
"""处理客户查询的核心方法"""
# 分析查询复杂度
complexity = self._analyze_query_complexity(query)
# 动态选择最适合的模型
optimal_model, _ = self.model_selector.select_optimal_model(
task_complexity=complexity,
budget_constraint=0.05, # 每次查询最大成本
speed_requirement=3.0 # 最大响应时间3秒
)
# 构建增强上下文
enhanced_context = self._build_enhanced_context(
query, customer_context, self.conversation_history
)
# 生成回复
if complexity > 0.7: # 复杂查询使用ToT推理
response = self._complex_reasoning(query, enhanced_context, optimal_model)
else: # 简单查询使用CoT推理
response = self._simple_reasoning(query, enhanced_context, optimal_model)
# 更新对话历史
self.conversation_history.append({
'query': query,
'response': response,
'model_used': optimal_model,
'complexity': complexity
})
return response
def _analyze_query_complexity(self, query):
"""分析查询复杂度"""
complexity_indicators = [
len(query.split()) > 20, # 长查询
'?' in query and query.count('?') > 1, # 多问题
any(word in query.lower() for word in ['compare', 'analyze', 'explain why']),
'step by step' in query.lower() or 'how to' in query.lower()
]
return sum(complexity_indicators) / len(complexity_indicators)
6.2 部署架构建议
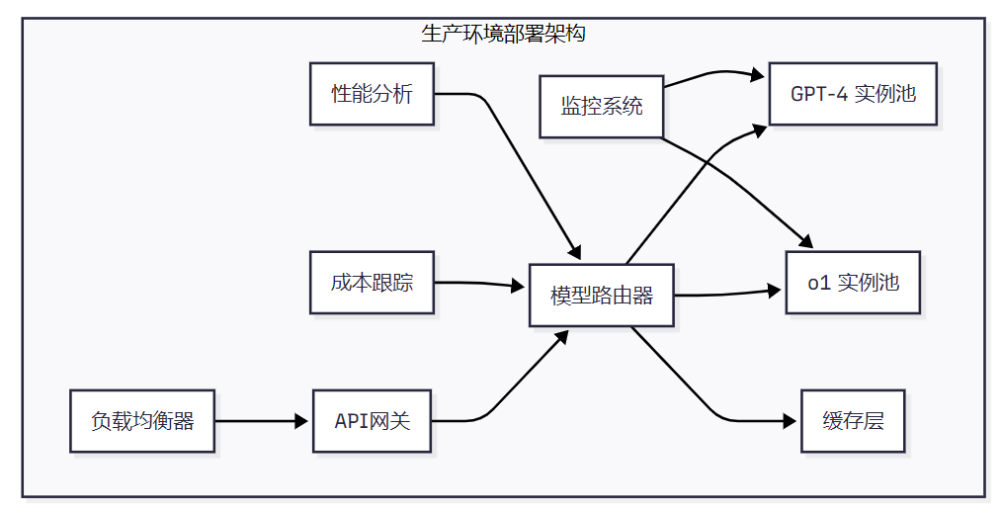
结语与技术展望
回顾从GPT-4到o1模型的技术演进历程,我深刻感受到大模型驱动的智能体正在经历一场深层次的能力革命。作为一名技术从业者,我见证了推理能力从简单的序列生成到复杂的树状搜索,从单模态理解到多模态融合的跨越式发展。
o1模型在数学推理和复杂问题解决上的突破性表现,不仅仅是技术指标的提升,更代表着智能体从"能用"到"好用"再到"智用"的质的飞跃。特别是Tree-of-Thought推理机制的引入,让智能体具备了类似人类专家的深度思考能力,这为解决更加复杂的现实问题开辟了新的可能性。
然而,技术进步的同时也带来了新的挑战。o1模型虽然在推理深度上有显著提升,但其计算成本的大幅增加也提醒我们需要在性能和成本之间寻找最佳平衡点。基于我多年的实践经验,我认为未来智能体的发展趋势将集中在几个关键方向:
首先是自适应模型路由技术的成熟化,通过智能的任务分析和模型选择,实现成本和性能的动态优化。其次是混合推理架构的普及,结合CoT的高效性和ToT的深度性,构建更加灵活的推理系统。最后是多模态能力的深度整合,让智能体真正具备人类级别的综合理解和推理能力。
展望未来,我相信下一代智能体将不再是单纯的工具,而是真正的智能伙伴。它们不仅能够理解复杂的多模态信息,还能够进行深度的逻辑推理和创新性思考。这种能力的提升将彻底改变人机交互的模式,为各行各业带来前所未有的效率提升和创新可能。作为技术探索者,我对这个充满无限可能的未来充满期待。
关键词: 智能体(Agent)、大模型(Large Language Model)、推理链(Chain-of-Thought, CoT)、思维树(Tree-of-Thought, ToT)、多模态(Multimodal)、GPT-4、o1模型
🌟 嗨,我是IRpickstars!如果你觉得这篇技术分享对你有启发:
🛠️ 点击【点赞】让更多开发者看到这篇干货🔔 【关注】解锁更多架构设计&性能优化秘籍💡 【评论】留下你的技术见解或实战困惑
作为常年奋战在一线的技术博主,我特别期待与你进行深度技术对话。每一个问题都是新的思考维度,每一次讨论都能碰撞出创新的火花。
🌟 点击这里👉 IRpickstars的主页 ,获取最新技术解析与实战干货!
⚡️ 我的更新节奏:
• 每周三晚8点:深度技术长文
• 每周日早10点:高效开发技巧
• 突发技术热点:48小时内专题解析

- 点赞
- 收藏
- 关注作者
评论(0)