CCE集群中使用ollama框架一键部署deepseek-r1

【摘要】 此文章介绍CCE集群中使用ollama框架一键部署deepseek-r1
一 背景介绍
人工智能正以前所未有的速度改变着我们的生活和工作方式。随着技术的进步,未来的人工智能系统将更加智能化、个性化,并且能够更好地服务于人类社会的需求。而像“DeepSeek”这样的创新应用,则是这一发展趋势中的一个重要组成部分。
大型语言模型(LLM)成为了自然语言处理领域的明星技术。然而,LLM的高昂计算资源和复杂的运行环境成为了限制其普及的瓶颈。为了解决这个问题, 个名为Ollama的本地大模型运行框架应运而生,它让大型语言模型在本地运行变得简单、高效和可扩展。Ollama的核心理念是将LLM的权重、配置和数据捆绑到一个包中,形成一个Modelfile。这种设计使得用户只需通过一条命令就能在本地运行大型语言模型,无需繁琐的安装和配置过程。此外,Ollama还优化了设置和配置细节,包括GPU使用情况,从而提高了运行效率,降低了对计算资源的需求。
此文章介绍CCE集群中使用ollama框架一键部署deepseek-r1
不同参数deepseek应对的场景:

二 操作步骤
-
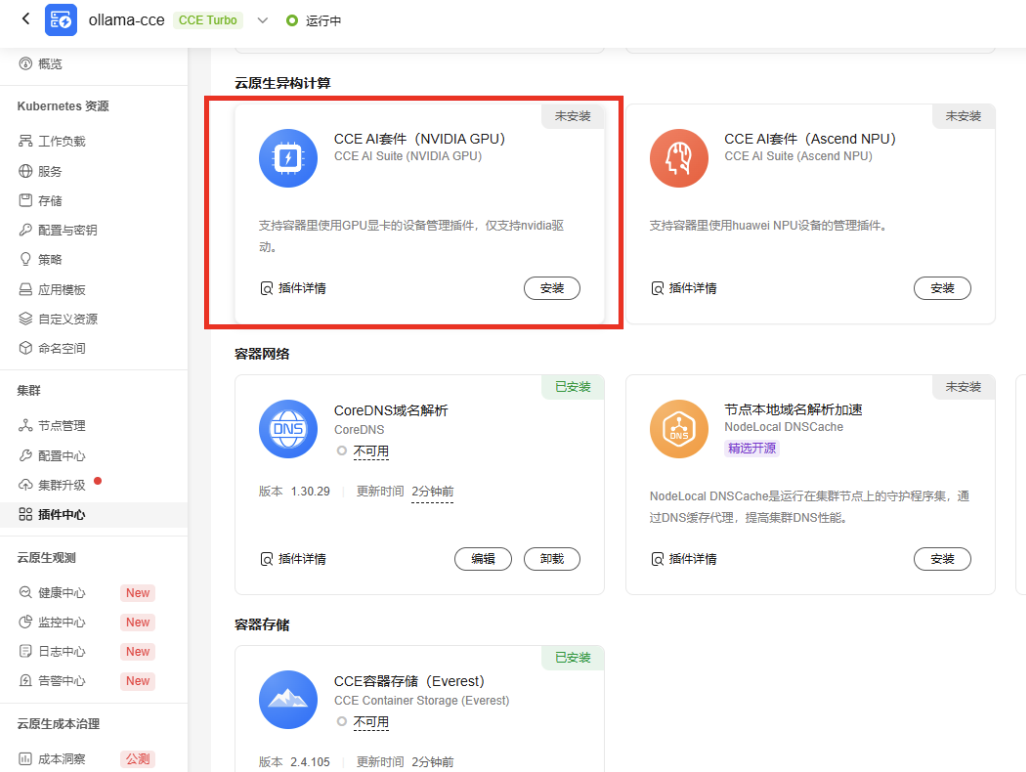
CCE安装GPU插件
插件如下:

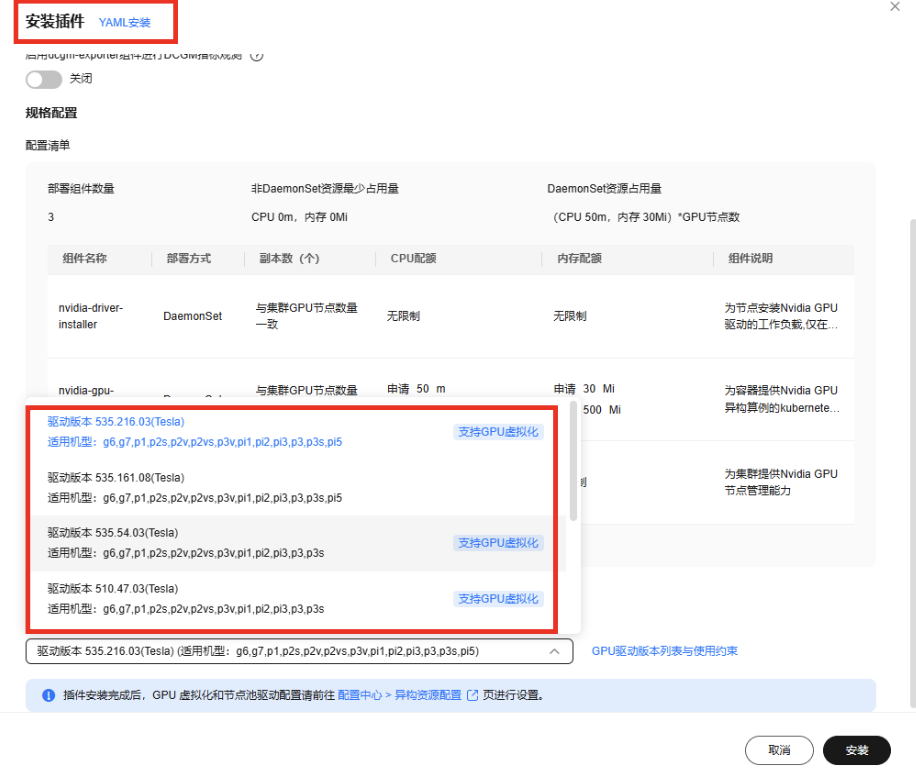
配置GPU驱动
-
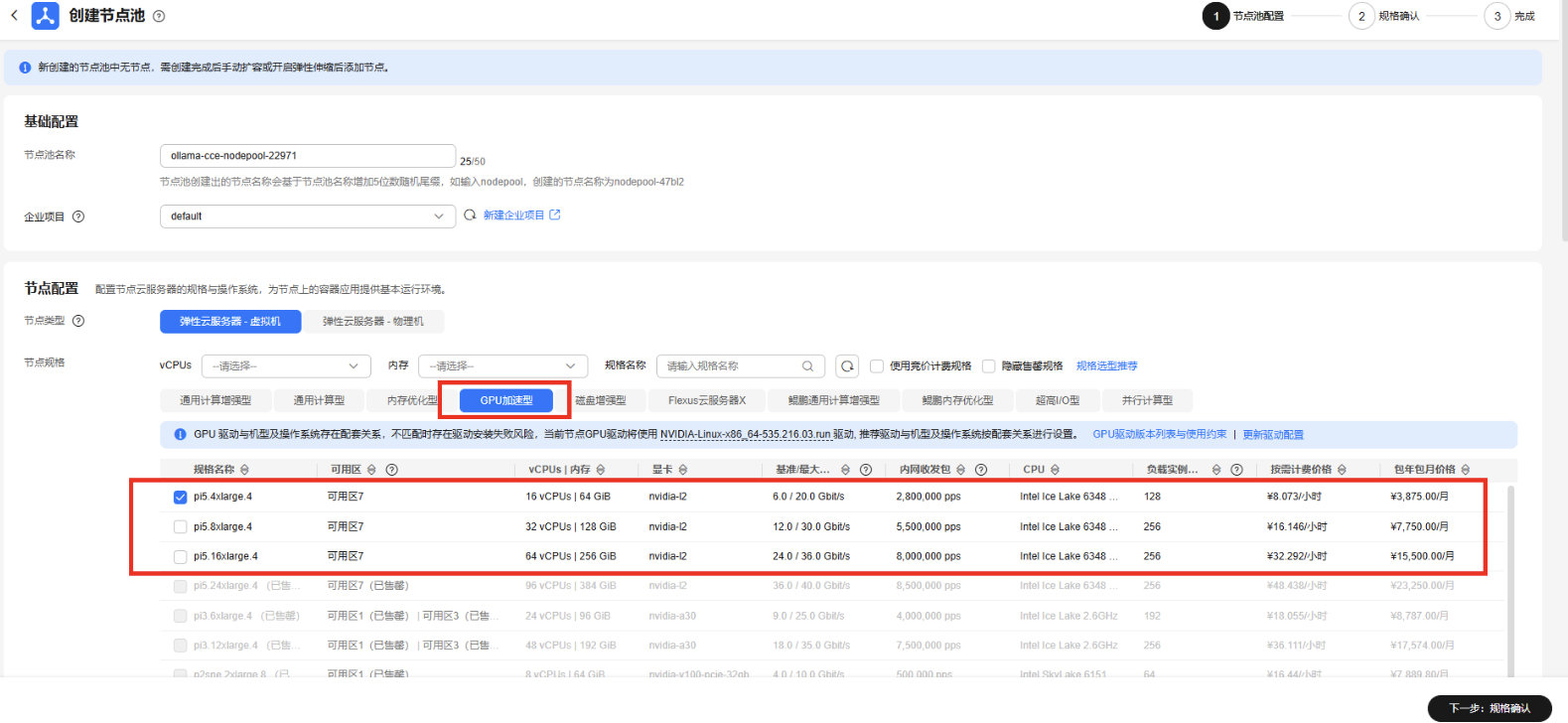
购买GPU节点
规格选择
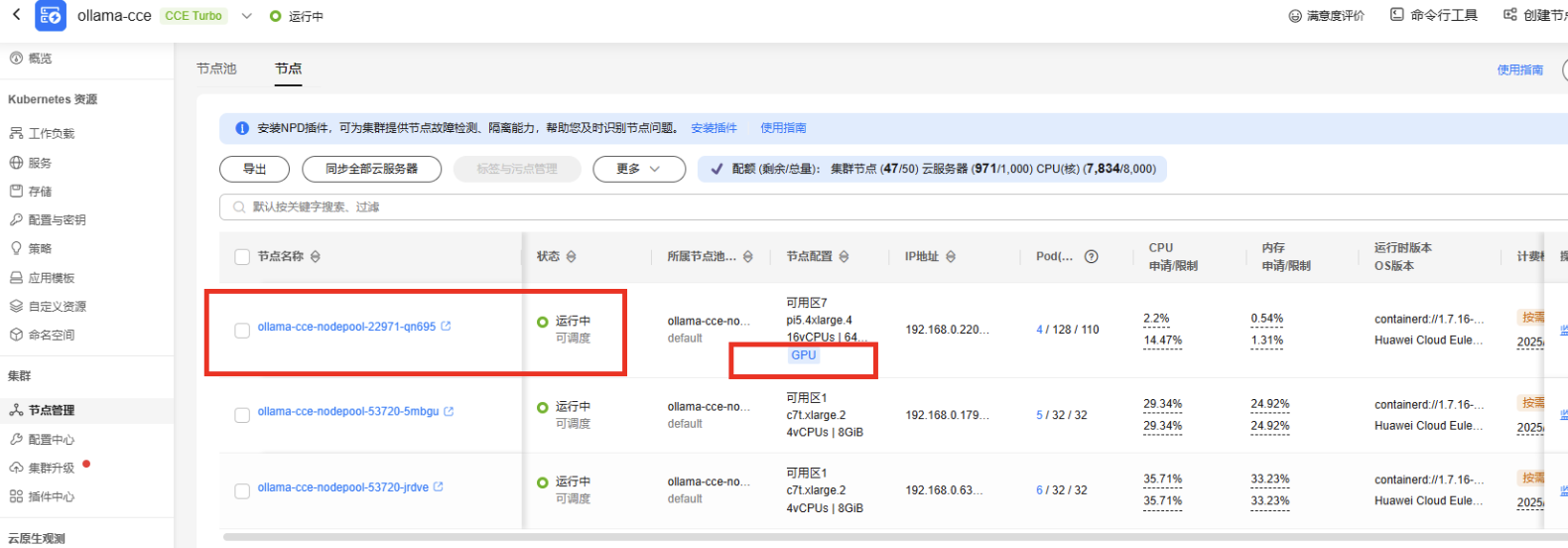
等待GPU节点就绪
-
使用ollama命令下载和运行deepseek-r1(也可以使用使用知识库连接ollama)
ollama list # 查看当前拥有的模型 ollama pull deepseek-r1:1.5b # 下载模型1.1GB #ollama pull deepseek-r1:7b # 下载模型4.7G #ollama run deepseek-r1:14b #运行deepseek 模型的磁盘大小9G #ollama run deepseek-r1:32b #运行deepseek 模型的磁盘大小20G -
创建ollama负载使用GPU设备
重要环境变量说明(OLLAMA_HOST 暴露给全部访问。
OLLAMA_MODELS 配置模型的路径):- name: OLLAMA_HOST value: 0.0.0.0:11434 - name: OLLAMA_MODELS value: /root/models完整yaml如下:
kind: StatefulSet apiVersion: apps/v1 metadata: name: ollama namespace: default labels: appgroup: '' version: v1 annotations: description: '' workload.cce.io/swr-version: '[{"version":"Private Edition"}]' spec: replicas: 1 selector: matchLabels: app: ollama version: v1 template: metadata: labels: app: ollama version: v1 annotations: pod.alpha.kubernetes.io/initialized: 'true' yangtse.io/static-ip: 'false' spec: containers: - name: container-1 image: ollama/ollama:0.5.8 #swr.cn-north-4.myhuaweicloud.com/testapp/ollama:0.5.8 env: - name: PATH value: /usr/local/nvidia/bin:/usr/local/cuda/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin - name: OLLAMA_HOST value: 0.0.0.0:11434 - name: OLLAMA_MODELS value: /root/models resources: requests: cpu: 250m memory: 512Mi nvidia.com/gpu: 1 limits: nvidia.com/gpu: 1 volumeMounts: - name: models readOnly: false mountPath: /root/models subPath: '' terminationMessagePath: /dev/termination-log terminationMessagePolicy: File imagePullPolicy: IfNotPresent restartPolicy: Always terminationGracePeriodSeconds: 30 dnsPolicy: ClusterFirst securityContext: {} imagePullSecrets: - name: default-secret schedulerName: default-scheduler tolerations: - key: node.kubernetes.io/not-ready operator: Exists effect: NoExecute tolerationSeconds: 300 - key: node.kubernetes.io/unreachable operator: Exists effect: NoExecute tolerationSeconds: 300 serviceName: headless-zazizn volumeClaimTemplates: - apiVersion: v1 kind: PersistentVolumeClaim metadata: name: models namespace: default annotations: everest.io/disk-volume-type: GPSSD everest.io/disk-volume-tags: '{}' everest.io/enterprise-project-id: '0' spec: accessModes: - ReadWriteOnce resources: requests: storage: 40Gi storageClassName: csi-disk-topology podManagementPolicy: OrderedReady updateStrategy: type: RollingUpdate revisionHistoryLimit: 10 persistentVolumeClaimRetentionPolicy: whenDeleted: Retain whenScaled: Retain -
登录ollama运行大模型进行对话
kubectl exec -it ollama-0 bash ollama run deepseek-r1:1.5b # #ollama run deepseek-r1:32b #运行deepseek 20Gpod状态如下:
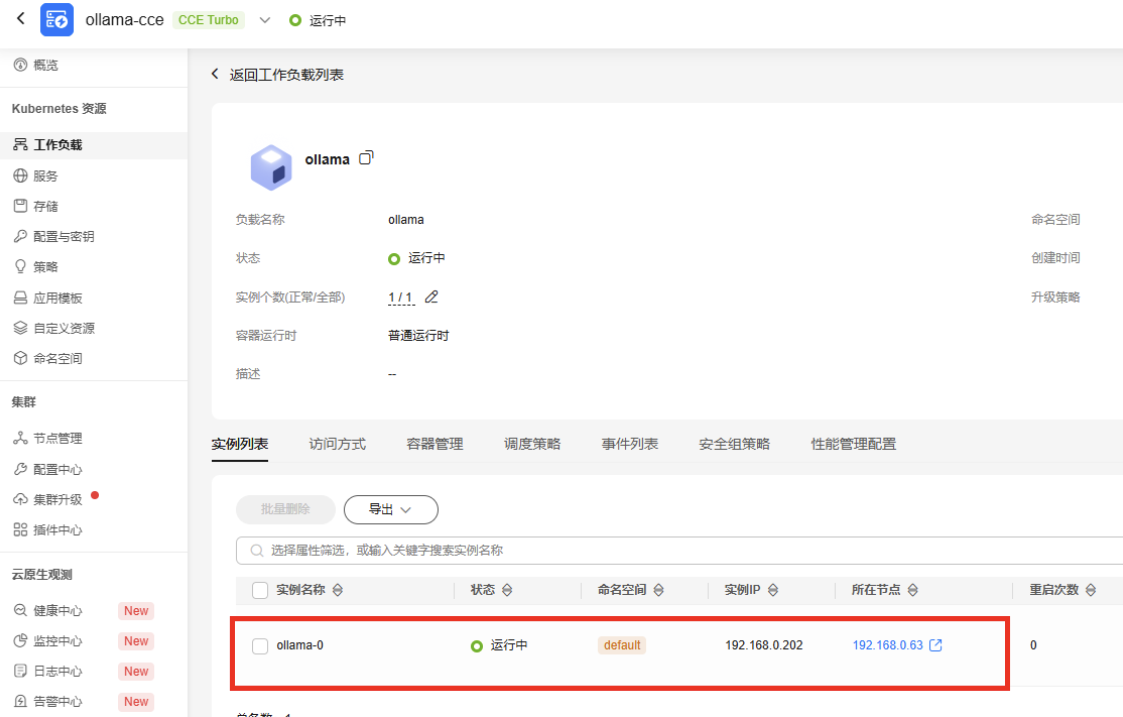
推荐使用极速文件存储SFS turbo作为模型存储挂载到容器中(当前测试用例使用的是云硬盘),性能如下:

三 验证结果
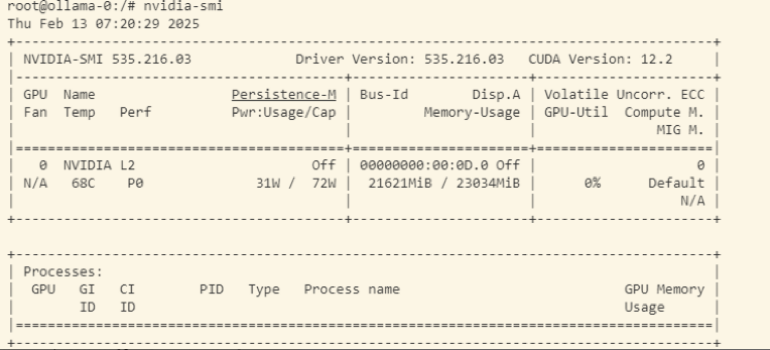
ollama deepseek-r1对话情况

负载正在使用GPU设备加速

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)