项目迁移至鲲鹏服务器 EulerOS 和GaussDB 集中式版 使用体验

前言
Java作为企业级开发的主力语言,一直以丰富的生态而著称,是移动互联网时代造就了它。但随着人工智能的时代即将到来,它却丧失了人工智能领域的生态。所以为了解决这个问题,EasyAi应运而生,它的出现对于Java的意义,等同于在JavaWeb领域spring出现的意义一样——做一个开箱即用,让每一个开发者都可以使用EasyAi,来开发符合自己人工智能业务需求的小微模型,这就是它的使命!
EasyAi介绍
EasyAi无任何依赖,它是一个原生Java人工智能算法框架。首先,它可以Maven一键丝滑引入我们的Java项目,无需任何额外的环境配置与依赖,做到开箱即用。再者,它既有一些我们已经封装好的图像目标检测及人工智能客服的模块,也提供各种深度学习,机器学习,强化学习,启发式学习,矩阵运算,求导函数,求偏导函数等底层算法工具。开发者可以通过简单的学习,就能完成根据自身业务,深度开发符合自己业务的小微模型。
sayOrder介绍
sayOrder是依赖EasyAI开发的本地部署的智能客服系统,它主要分为两个功能,一个是语义理解接口,一个是智能问答接口。我们首先简单介绍一下,语义理解的接口的算法模型,如下图所示:
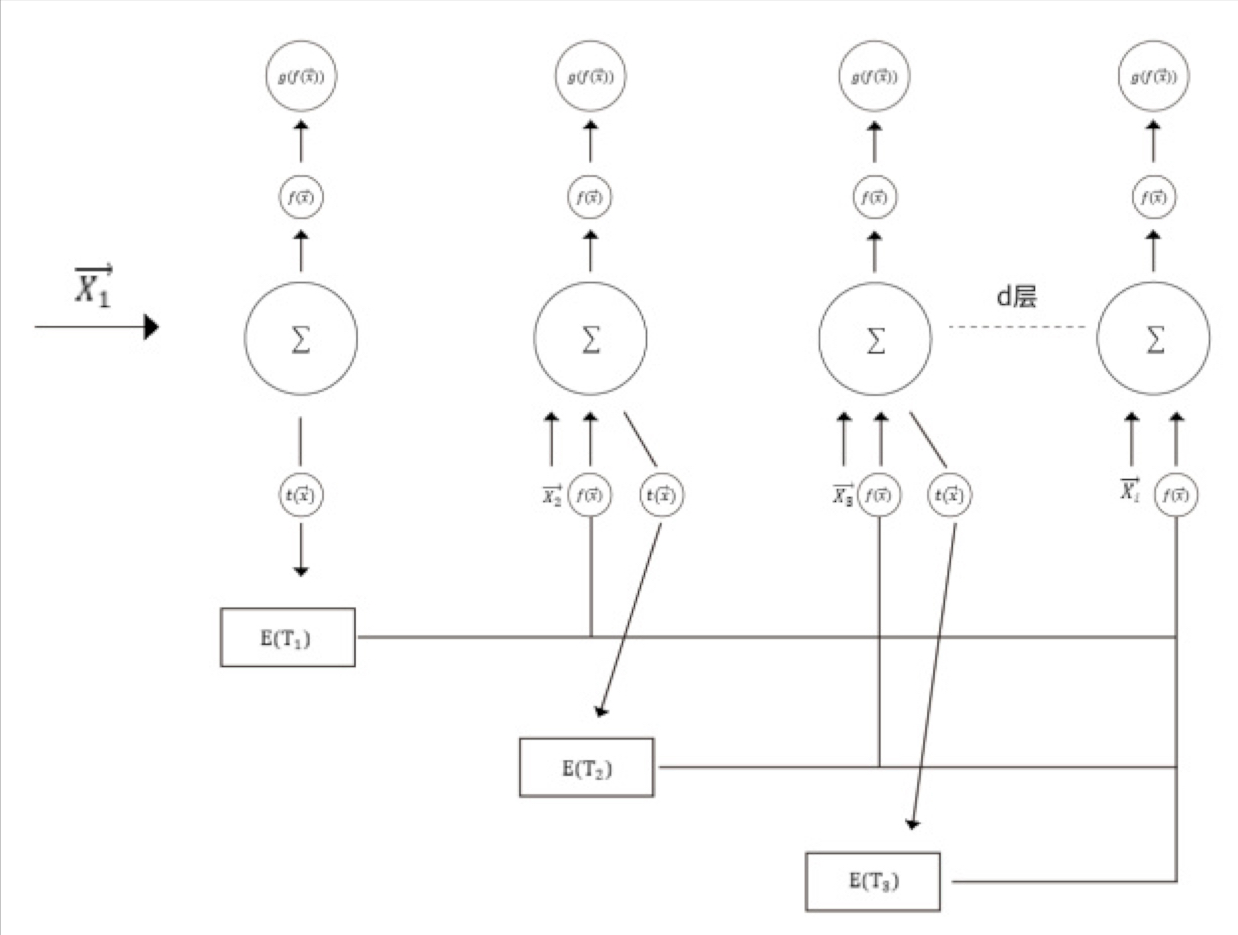
该网络模型,将词向量每一个下标位置的特征值输入到对应的神经元下标当中,在向前传播的途中,每一层深度对应每个字的时间序列,每一层深度的隐层神经元对应该时间序列字符的词向量对应位置下标的特征值。
这里的向前传播与传统的神经网络向前传播的区别是,它并不是依次向前传播的,而是进行一定次数的随机跳层。也就是说它一次传播可能经过的层数是(1,3,4,6,8,14...)等等,最后停在哪一层神经元就在哪一层对应的输出层进行输出。在这里我认为在一句话中,不同时间序列的字之间依然存在某种线性关系。因为在不同序列之间,中间的字符可能对该句话的语义并没有决定性影响,而相互间隔若干字符的序列,可能影响要远远大于一些中间的修饰性语句。
所以在进行一定次数的随机跳层的训练,它能学会这句话的很多关键重要的线性关联信息,进而降低模型的复杂度而提升性能。在实际生产中,尤其在客服交互中(通常与客服交互的语句都不会太长),短交流判断用户语义所展现的效果非常优秀,且因为简化了参数模型的关系,使得速度非常快速,普通的cpu即可满足服务器运算性能的要求!
sayOrder问答模型是基于transFormer进行开发,并对transFormer的训练期望进行一些简单的改造:
1,我们知道训练时tranFromer最后线性层softMax的输出是一个预测矩阵,不同的行向量负责预测不同的序列的字符,我们对训练时预测矩阵进行如下改造:

假设上图是我们训练时线性层输出的矩阵,而此时我们的期望输出是(e1,e2,e3,e4)。那么此时我们期望输出改造为 softMax(R1*t^0)=e1,softMax(R1*t^1+R2*t^0)=e2, softMax(R1*t^2+R2*t^1+R3*t^0)=e3,softMax(R1*t^3+R2*t^2+R3*t^1+R4*t^0)=e4其中(0<t<1)。
我们将预测序列前的所有序列向量的和作为预测特征,其中对于每个向量再乘一个时间乘法的贴现因子t,越靠近预测序列的行向量惩罚越低(很明显最小的惩罚是1),这里的理解是,我们认为我们当前预测下个序列的字符,是当前序列前所有向量共同决定的,但是不同序列的向量权重不一样,越靠近预测序列的行向量,权重越大,约远则越小,所以不断的给他们的权重施加一个惩罚,最有得出我们想要预测的结果,其中t设置的大小,代表惩罚的大小。该数值越大,则越小的序列影响越大惩罚力度越小,权重占比也越高,会更偏向远序列对当前序列的影响力。反之则更倾向近序列对当前的影响力。
华为全套配置:
1、鲲鹏通用计算增强型 | 4vCPUs | 16GiB | kc2.xlarge.4 Huawei Cloud EulerOS 2.0 标准版 64位 ARM版
2、GaussDB V2.0-8.201.0 gaussdb.bs.s6.xlarge.x864.ha | 4 vCPUs | 16 GB 欧拉 集中式版 1主2备
项目适配清单:
- mysql替换为gaussdb,
- centeros替换为鲲鹏欧拉服务器
GuassDB和Mysql区别:
性能表现:
GaussDB:拥有超高性能,可达到百万级 QPS,性能是开源 MySQL 的 7 倍。在复杂查询场景,支持将提取列、条件过滤、聚合运算等操作向下推给存储层处理,性能相比传统架构提升数十倍 1。
MySQL:也能处理大量数据和高并发访问,对于一般的中小型网站开发等场景性能表现良好,但在性能上限方面相对 GaussDB 较低。例如,在处理大规模数据和高并发请求时,可能会面临性能瓶颈。
扩展性:
GaussDB:具有高扩展性,支持分钟级添加只读节点,最大支持 15 个只读节点。由于采用共享存储,添加只读节点所需时间与数据量大小无关,且无需增加额外存储。存储可根据数据容量自动弹性伸缩,最大支持 128TB,能很好地应对海量数据问题和性能扩展需求 1。
MySQL:扩展性相对有限,最多可添加 5 个只读节点,添加只读节点所需时间与数据量大小相关,并且需要增加一份存储。存储自动扩容最大支持 4TB 1。
架构特点:
GaussDB:采用存算分离架构,计算节点共享一份数据,无需通过 binlog 同步数据。这种架构使得数据库在处理大规模数据和高并发请求时具有更好的性能和可扩展性,同时也方便了数据的管理和维护。
MySQL:通常采用传统主备架构,主备通过 binlog 同步数据。这种架构在一定程度上保证了数据的可靠性和可用性,但在性能和扩展性方面可能会受到一些限制,特别是在处理大规模数据和高并发请求时。
可用性:
GaussDB:主节点和只读节点无需通过 binlog 进行数据同步,延时更低,故障自动切换,RTO(Recovery Time Objective,恢复时间目标)通常小于 10 秒,具有较高的可用性。
MySQL:故障自动倒换,RTO 通常小于 30 秒,可用性也较高,但相对 GaussDB 来说,在故障切换的速度和延时方面可能稍逊一筹。
备份恢复:
GaussDB:通过全量备份(快照)+ redo 回放实现任意时间点回滚,备份恢复速度更快。
MySQL:通过全量备份 + binlog 回放实现任意时间点回滚。
兼容性:
GaussDB:具有高兼容性,100% 兼容 MySQL,应用上云无须改造,这使得现有基于 MySQL 开发的应用可以较为容易地迁移到 GaussDB 上,降低了迁移成本和风险。
MySQL:作为广泛使用的数据库,其本身具有良好的兼容性,但对于一些特定的功能或语法,可能与其他数据库存在差异。
成本:
GaussDB:具有超低成本,约为十分之一的商用数据库成本,这对于对成本敏感的企业或项目来说是一个重要的优势。
MySQL:分为社区版和商业版,社区版是免费的,可用于许多中小型项目;商业版则提供更多的功能和技术支持,相应的成本也会更高。对于一些大型企业或对数据库有较高要求的项目,可能需要购买商业版的 MySQL 并承担相应的费用。
应用场景:
GaussDB:广泛应用于金融、车联网、政企、电商、能源、电信等对数据安全、可靠性、性能和扩展性要求较高的多个领域。例如,金融行业对数据安全和可靠性有非常严格的要求,GaussDB 既拥有商业数据库的稳定可靠性,又拥有开源数据库的灵活性和低成本;互联网行业的发展经常呈爆发性增长,业务波动变化频繁,流量高峰难以预测,GaussDB 凭借其强大的弹性能力特别契合这一行业特点 2。
MySQL:适用于各种规模的项目,尤其是中小型网站、Web 应用程序、小型企业的内部系统等。由于其成本低、性能较强、简单实用且对初学者友好,在这些场景中得到了广泛应用。例如,对于一些个人站点、初创公司、小型内部系统,考虑到成本、更新频率、系统重要性等问题,系统只依赖一个单例 MySQL 数据库提供服务,基本上已经满足需求
非常幸运,EasyAI应华为官方邀请,体验GussDB和鲲鹏欧拉服务器,在这非常感谢华为官方的人员,专业性服务意识都是超一流。对接过程十分顺利。大大的赞
一:Mysql表迁移到GuassDB
报错:执行失败,失败原因The utf8mb3 is not a valid encoding name.ERROR Position:113
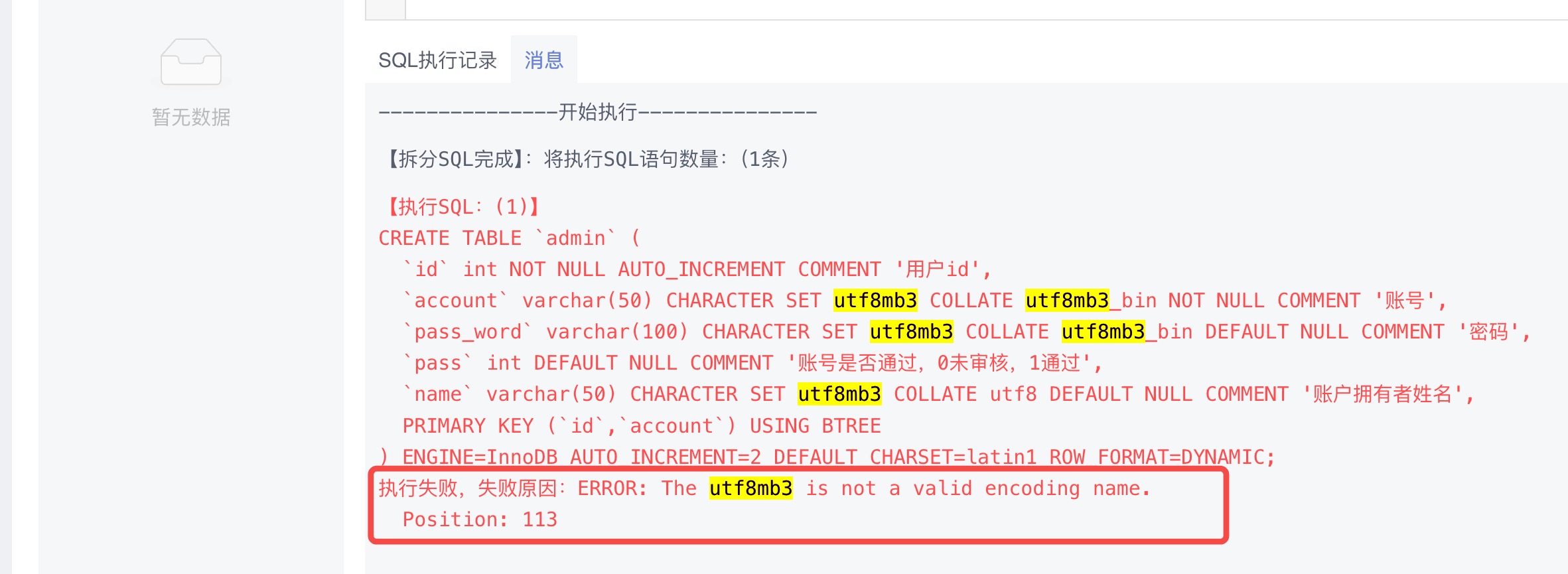
原因:
mb3是MYSQL特有的,建表语句不要设置字符集,默认就是utf8。
具体可以详见官方文档:https://support.huaweicloud.cn/centralized-devg-v8-gaussdb/gaussdb-42-0038.html
原有建表语句
CREATE TABLE `admin` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '用户id',
`account` varchar(50) CHARACTER SET utf8mb3 COLLATE utf8mb3_bin NOT NULL COMMENT '账号',
`pass_word` varchar(100) CHARACTER SET utf8mb3 COLLATE utf8mb3_bin DEFAULT NULL COMMENT '密码',
`pass` int DEFAULT NULL COMMENT '账号是否通过,0未审核,1通过',
`name` varchar(50) CHARACTER SET utf8mb3 COLLATE utf8mb3_bin DEFAULT NULL COMMENT '账户拥有者姓名',
PRIMARY KEY (`id`,`account`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=latin1 ROW_FORMAT=DYNAMIC;新建表语句
CREATE TABLE `admin` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '用户id',
`account` varchar(50) NOT NULL COMMENT '账号',
`pass_word` varchar(100) DEFAULT NULL COMMENT '密码',
`pass` int DEFAULT NULL COMMENT '账号是否通过,0未审核,1通过',
`name` varchar(50) DEFAULT NULL COMMENT '账户拥有者姓名',
PRIMARY KEY (`id`,`account`)
) AUTO_INCREMENT=2 ;替换点:ENGINE=InnoDB DEFAULT CHARSET=latin1 ROW_FORMAT=DYNAMIC; CHARACTER SET utf8mb3 COLLATE utf8mb3_bin
主要是字符集和引擎的替换,其他无缝链接。
二:spring boot项目适配gaussdb
增加maven依赖
目前使用的是opengaussjdbc,一定要看清楚是opengaussjdbc还是huaweigaussjdbc,下面的driver-class-name是不一样的
<dependency>
<groupId>com.huaweicloud.gaussdb</groupId>
<artifactId>opengaussjdbc</artifactId>
<version>503.2.T35</version>
</dependency>spring-配置文件修改
url: jdbc:opengauss://你的host:8000/sentence_data?currentSchema=public
driver-class-name: com.huawei.opengauss.jdbc.Driver
在这需要注意的点建表需要Schema下的public下面的,否则会报
### Error querying database. Cause: com.huawei.opengauss.jdbc.util.PSQLException: [127.0.0.1:51441/.0.0.0/0.0.0.0:8000] ERROR: Relation "keyword_type" does not exist on dn_6001_6002_6003.
鲲鹏服务器适配(无需额外适配)
没有需要注意的地方,命令和linux对比更快,相同项目相同配置从启动来看快30%左右,还是一整套的适配的非常好!!!!
git地址
https://gitcode.com/fushoujiang/sayOrder/overview?ref=dev-huawei

- 点赞
- 收藏
- 关注作者
评论(0)