VLLM适配昇腾开源体验任务心得

VLLM适配昇腾开源体验任务心得
1 项目介绍
VLLM是一个开源的高性能大语言模型推理库,旨在实现大规模语言模型的快速推理。本任务的主要目的是帮助开源开发者体验开源for Huawei的过程,并使用和了解昇腾的开发能力。开发者需要基于昇腾资源,在demo的基础上,完成vllm的模型推理流程。
- 源码地址:https://github.com/vllm-project/vllm
- 官网主页:https://github.com/vllm-project
- 主要开发语言:python
- LICENSE:Apache License 2.0
- 维护者:Woosuk Kwon
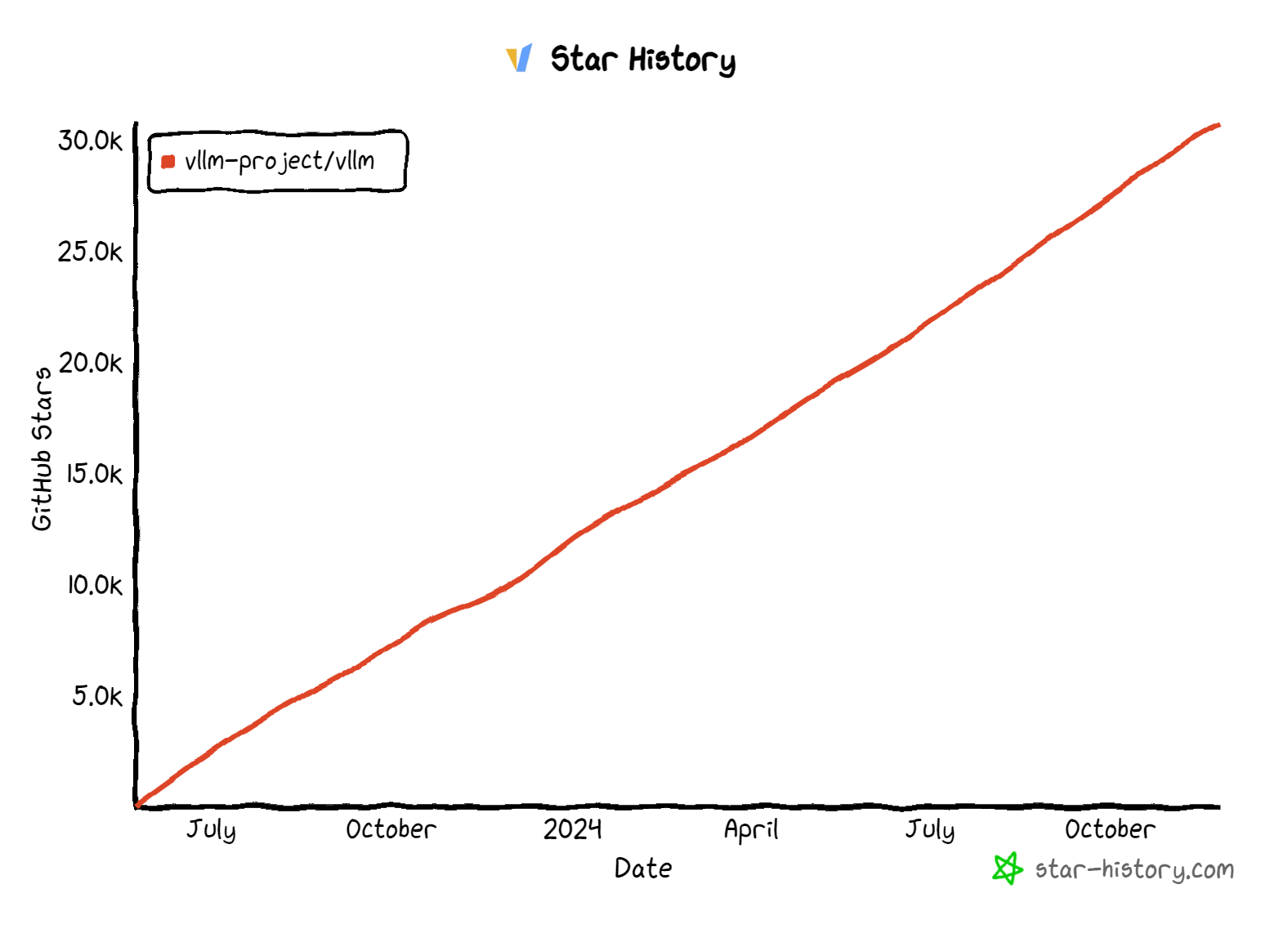
- 项目数据:Fork 4.7k,Star 30.7K,Contributor 706,最近一次提交:2024-11-24
star历史(https://star-history.com/):
2 Demo验证思路
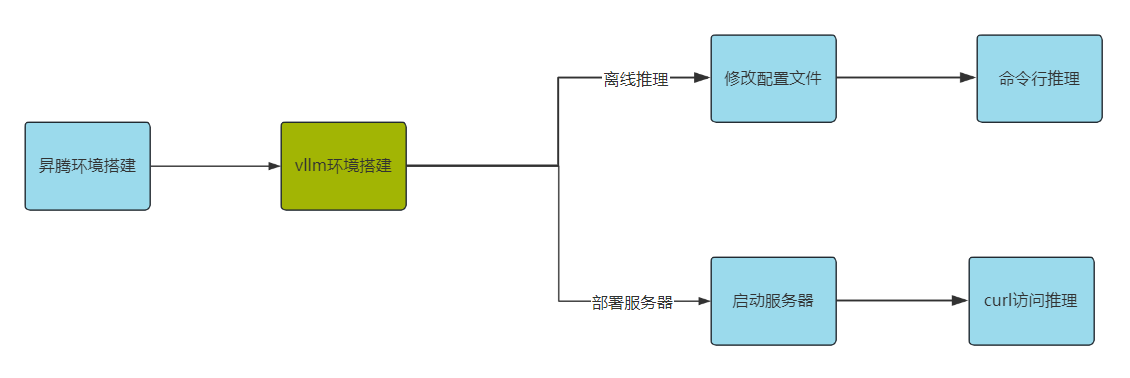
3 准备工作
开始之前,开发者可以下载 开源for Huawei Wiki(https://gitcode.com/HuaweiCloudDeveloper/OpenSourceForHuaweiWiki/overview) 了解详细的开发步骤,技术准备,以及开发过程需要的各种资源。
3.1 资源准备和配置
- 资源规格信息:
|
产品名称 |
NPU架构 |
CPU架构 |
操作系统 |
|
云堡垒机 |
Ascend 910B3
|
鲲鹏计算Kunpeng-920 |
Huawei Cloud EulerOS 2.0 (aarch64) |
- Miniconda:
1.下载软件包:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh
2.赋上可执行权限:
chmod +x Miniconda3-latest-Linux-aarch64.sh
3.执行安装:
./Miniconda3-latest-Linux-aarch64.sh
4.配置环境变量:
export PATH="/root/miniconda3/bin:$PATH"
source ~/.bashrc
4 开发过程
4.1 搭建项目环境
以下步骤是基于具备基础裸机环境之上
1、昇腾环境
- 安装昇腾依赖包
NPU上需要CANN、torch_npu、pytorch
CANN的安装参考: ` https://www.hiascend.com/zh/developer/download/community/result?module=cann
- torch_npu的安装参考:
https://github.com/Ascend/pytorch/blob/master/README.zh.md`
2、vllm环境
- 创建虚拟环境 vllm310并激活
Conda create -n vllm310 python=3.10 -y Conda activate vllm310
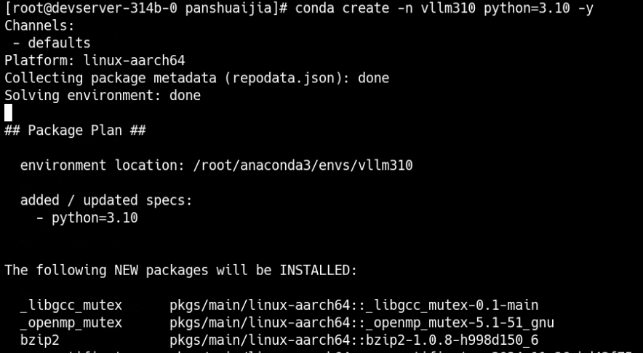
注:python版本为3.10
- 拉取代码仓库
git clone -b npu_support https://github.com/wangshuai09/vllm.git

注:clone仓库,不要拉取最新的代码,否则安装会失败。下载支持npu安装的源码。
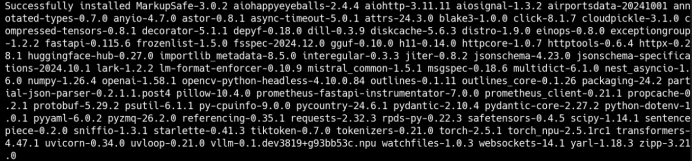
- 安装vllm
VLLM_TARGET_DEVICE=npu pip install -e .

安装完成回显
**补充:
执行“安装vllm时”会默认安装torch_npu 2.5.1,需降低torch_npu、torch版本为2.4.1
pip install torch torch_npu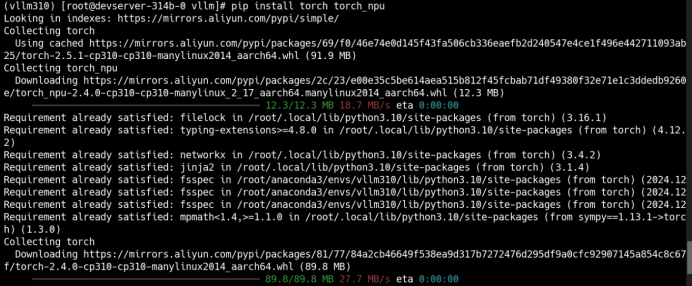

4.2 离线推理
修改 examples/offline_inference_npu.py 第29行,选择Qwen1.5-4B-Chat模型
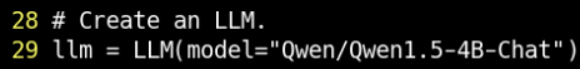
可能报错modelscope找不到
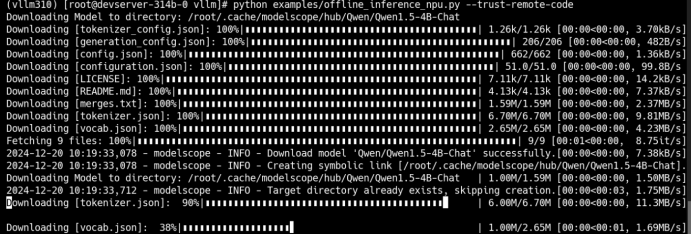
解决方法:
pip install modelscope运行程序:自动下载模型 Qwen1.5-4B-Chat
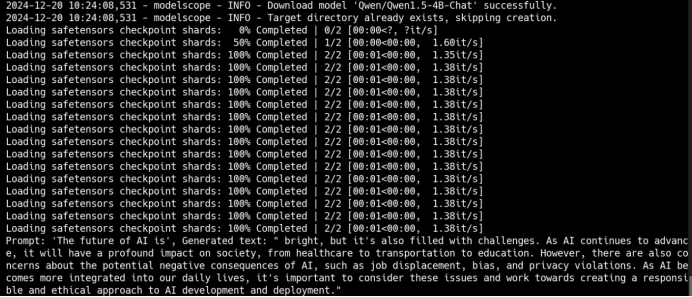
推理结果
4.3 推理部署
项目提供了一个兼容 OpenAI 接口的 API 服务器,使得开发者可以像使用 OpenAI 服务一样,轻松地集成 VLLM 的能力。 在这里我们直接将vLLM部署为模仿 OpenAI API协议的服务器,这使得vLLM可以用作使用OpenAI API的应用程序的直接替代品。
通过命令启动服务器:
python -m vllm.entrypoints.openai.api_server--help 加上此参数可查看命令行参数的详细信息。
开始部署
1.输入以下命令启动服务器
python -m vlLm.entrypoints.openai.api_server --model "/root/.cache/ Modelscope /hub/Qwen/Qwen1 .5- 4B-Chat”-- served-model-name " openchat "--model为本地模型的路径,--served-model-name是模型在服务器中的别名,这里我们取名简称openchat,其他都是默认值,当然也可以自己设置。

显示以下信息,服务已经启动成功

2.通过API访问
OpenAI 提供了 Completions 和 ChatCompletions 两个相关的 API,两个API很相似,你可以使用其中的任意一个,在这里我们选择Completions。
Completions说明:服务器启动成功后,我们可以在shell中发送一个请求进行测试,该请求使用了OpenAIChat API查询模型,请求内容如下:
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "openchat",
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'说明:
-d 里面是请求的参数,可以自己设置;
temperature 为 0,代表每次模型的回答都相同,不具有随机性,你可以自由调整参数来满足你的需求;
Promote封装你输入的问题;
如下:可以看到返回了结果,其中红色框中的是模型为我们续写的内容。


- 点赞
- 收藏
- 关注作者
评论(0)