Haystack基于昇腾环境的问答系统体验任务

【摘要】 一、任务需求
首先看了一下任务计划书:https://bbs.huaweicloud.cn/blogs/441501 ,主要目的是让haystack能够在Ascend NPU和Kunpeng CPU上高效运行,确保项目在平台上具备良好的兼容性和性能,以显著提高企业的信息检索和问答系统的效率。即验证haystack能不能在 Ascend(昇腾)和 Kunpeng(鲲鹏)处理器中运行。
Haystack基于昇腾环境的问答系统体验任务
一、任务需求
首先看了一下任务计划书:https://bbs.huaweicloud.cn/blogs/441501 ,主要目的是让haystack能够在Ascend NPU和Kunpeng CPU上高效运行,确保项目在平台上具备良好的兼容性和性能,以显著提高企业的信息检索和问答系统的效率。即验证haystack能不能在 Ascend(昇腾)和 Kunpeng(鲲鹏)处理器中运行。
二、过程
1.首先创建一个haystack的虚拟环境:
conda create -n haystack python=3.9
conda activate haystack
2.获取数据文件
(1)获取haystack源码,在 https://github.com/deepset-ai/haystack/tree/v1.x 中下载1.x版本的haystack代码,并上传堡垒机。官方文档教程是进行的英文问答,然后需要替换为中文问答,以更好的进行应用。在 https://github.com/mc112611/haystack-chinese 中获取txt.py和preprocess.py文件,这两个文件在以下路径中进行替换
haystack-1.x/haystack/nodes/preprocessor/preprocessor.py和haystack-1.x/haystack/nodes/file_converter/txt.py
(2)获取数据集
使用
git clone https://gitee.com/duan-bichong_admin/haystack-data.git
命令获取数据集,并放到运行路径下。
(3)获取权重文件
在 https://github.com/15340807762/demo/tree/main/model 上获取权重文件,在haystack-1.x下新建一个model文件夹,用来存放需要使用到的权重文件,然后将从github上获取的权重文件或者huggingface获取的权重文件存放到model文件夹下将。huggingface获取权重的命令如下:
huggingface-cli download --resume-download shibing624/text2vec-base-chinese --local-dir /dev/shm/dbc/haystack-1.x/model/shi
huggingface-cli download --resume-download uer/roberta-base-chinese-extractive-qa --local-dir /dev/shm/dbc/haystack-1.x/model/qa
进行下载.
3.安装依赖
(1)安装npu
因为要在npu上进行部署,所以需要安装npu的一些依赖,在 https://www.hiascend.com/document/detail/zh/Pytorch/60RC3/configandinstg/instg/insg_0001.html 中快速安装所需要的包,之后需要安装一些依赖,
pip3 install attrs
pip3 install numpy
pip3 install decorator
pip3 install sympy
pip3 install cffi
pip3 install pyyaml
pip3 install pathlib2
pip3 install psutil
pip3 install protobuf
pip3 install scipy
pip3 install requests
pip3 install absl-py
这里需要注意的是numpy的版本不要超过2.0以上,安装成功以后使用
python3 -c "import torch;import torch_npu; a = torch.randn(3, 4).npu(); print(a + a);"
进行验证,输出是矩阵则说明安装成功。
(2)安装haystack所需要的包
pip install farm-haystack[all]
之后会缺少ntlk包,在 https://pan.baidu.com/s/1puh4XihywBxvsTW0XkPfyg?pwd=1234 获取ntlk包,新建一个page文件夹用来存放ntlk包。
4.创建一个中文问答的text.py文件并修改
(1)创建test.py文件
import os
import logging
import time
logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
logging.getLogger("haystack").setLevel(logging.INFO)
# 写入库
from haystack.document_stores import FAISSDocumentStore
from haystack.pipelines.standard_pipelines import TextIndexingPipeline
#创建库以及索引
document_store =FAISSDocumentStore(faiss_index_factory_str="Flat",embedding_dim=768)
#加载已有的
document_store# document_store = FAISSDocumentStore.load(index_path="wiki_faiss_index.faiss", config_path="wiki_faiss_index.json")
doc_dir = 'F:\MC-PROJECT\CUDA_Preject/test_haystack\wiki\data_test'
# 对文档进行预处理
files_to_index = [doc_dir + "/" + f for f in os.listdir(doc_dir)]
indexing_pipeline = TextIndexingPipeline(document_store)
indexing_pipeline.run_batch(file_paths=files_to_index)
# 查看切分后的文档
# print(document_store.get_all_documents())
from haystack.nodes import EmbeddingRetriever
# 对文档进行中文相似度embedding,并更新faiss库
retriever = EmbeddingRetriever(
document_store=document_store,
embedding_model="shibing624/text2vec-base-chinese",)#shi权重文件路径修改
document_store.update_embeddings(retriever)
# 将faiss库索引进行持久化存储document_store.save(index_path="wiki_faiss_index.faiss")
# 使用中文的QA模型进行问答,对检索出的结果和用户输入的问题,生成回答,该回答基本是言简意赅,这个部分可以替换为大模型解析
from haystack.nodes import FARMReader
reader = FARMReader(model_name_or_path="uer/roberta-base-chinese-extractive-qa", use_gpu=True,context_window_size=300,max_seq_len=512)#qa权重文件修改路径
from haystack.utils import print_answers
from haystack.pipelines import ExtractiveQAPipeline
# 将检索器,阅读器插入进抽取式问答管道。
pipe = ExtractiveQAPipeline(reader, retriever)
# 提问while True:
q = input('输入问题吧:')
st_time = time.time()
prediction = pipe.run(
query=q,
params={
"Retriever": {"top_k": 8},
"Reader": {"top_k": 2}
}
)
# 打印结果
# print(prediction)
print_answers(prediction, details="all")
end_time = time.time()
print("计算时间为:{}".format(end_time - st_time))
(2)添加自动迁移代码
在代码中添加以下代码,能够从gpu自动迁移到npu上
import torch
import torch_npu
from torch_npu.contrib import transfer_to_npu
(3)修改权重文件路径
在上面新建的test.py代码中,需要修改一些路径,添加自动迁移代码。修改数据集路径,修改为代码实际路径。

对文档进行中文相似度enbedding

使用qa权重文件进行问答。

三、结果
在NPU上运行test.py
运行之前,先配置nltk_data环境变量,
export NLTK_DATA=/dev/shm/dbc/haystack-1.x/page
#具体路径同nltk包一致。
然后运行命令:
python test.py
运行命令前可使用,
npu-smi info
查看npu使用情况
运行之前npu没有使用
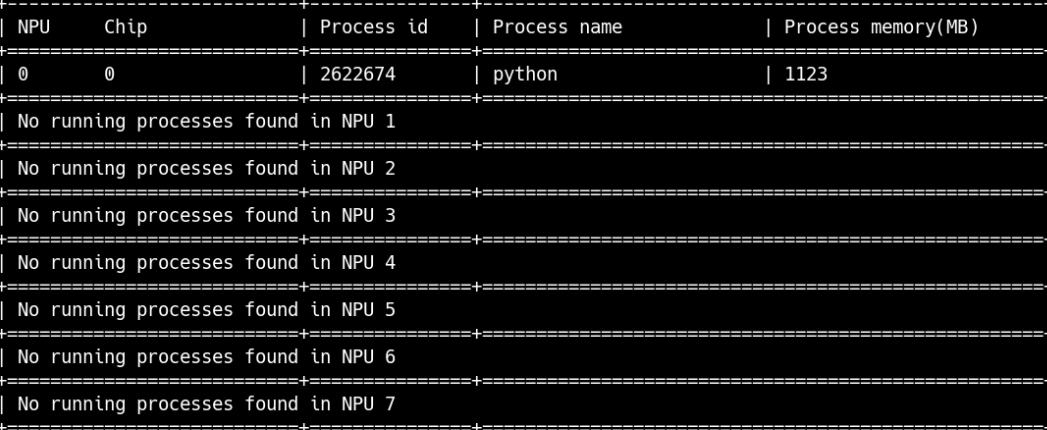
运行之后,会显示npu0在运行
运行之后会跳出这些界面
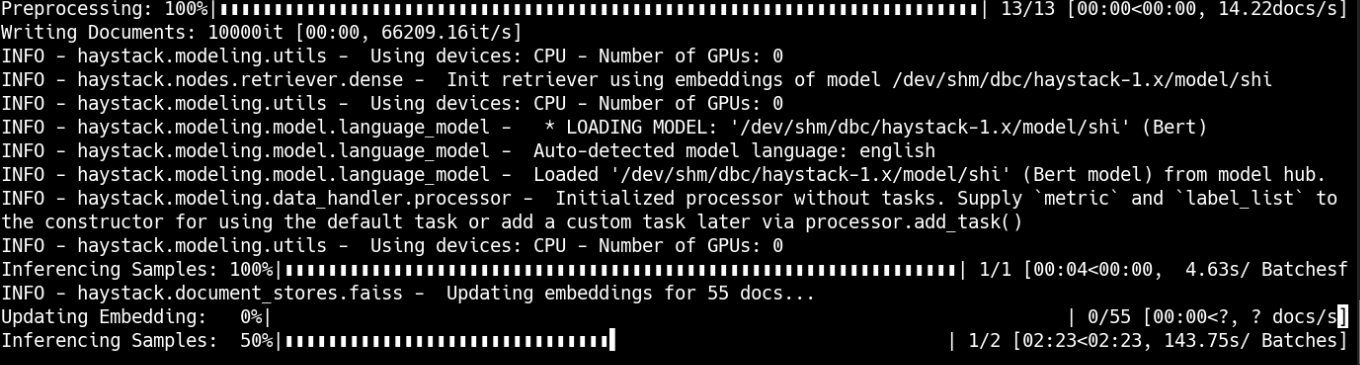
加载权重进行推理,推理完成后进行提问
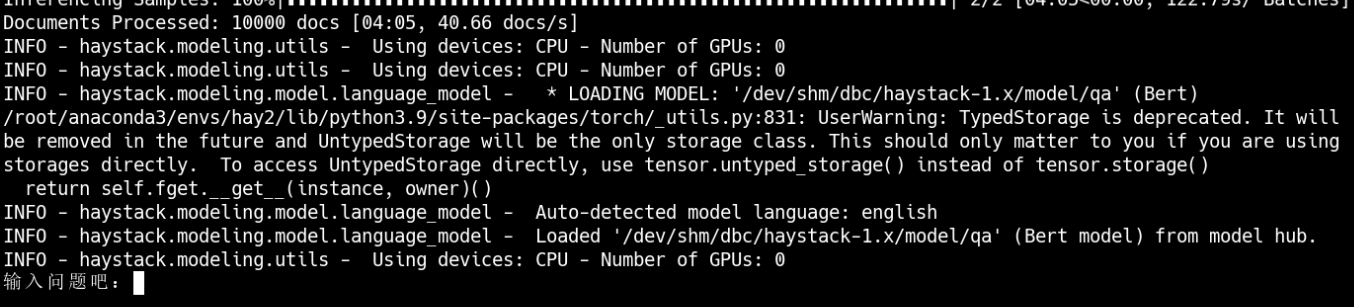
进行提问之后的结果是这样的
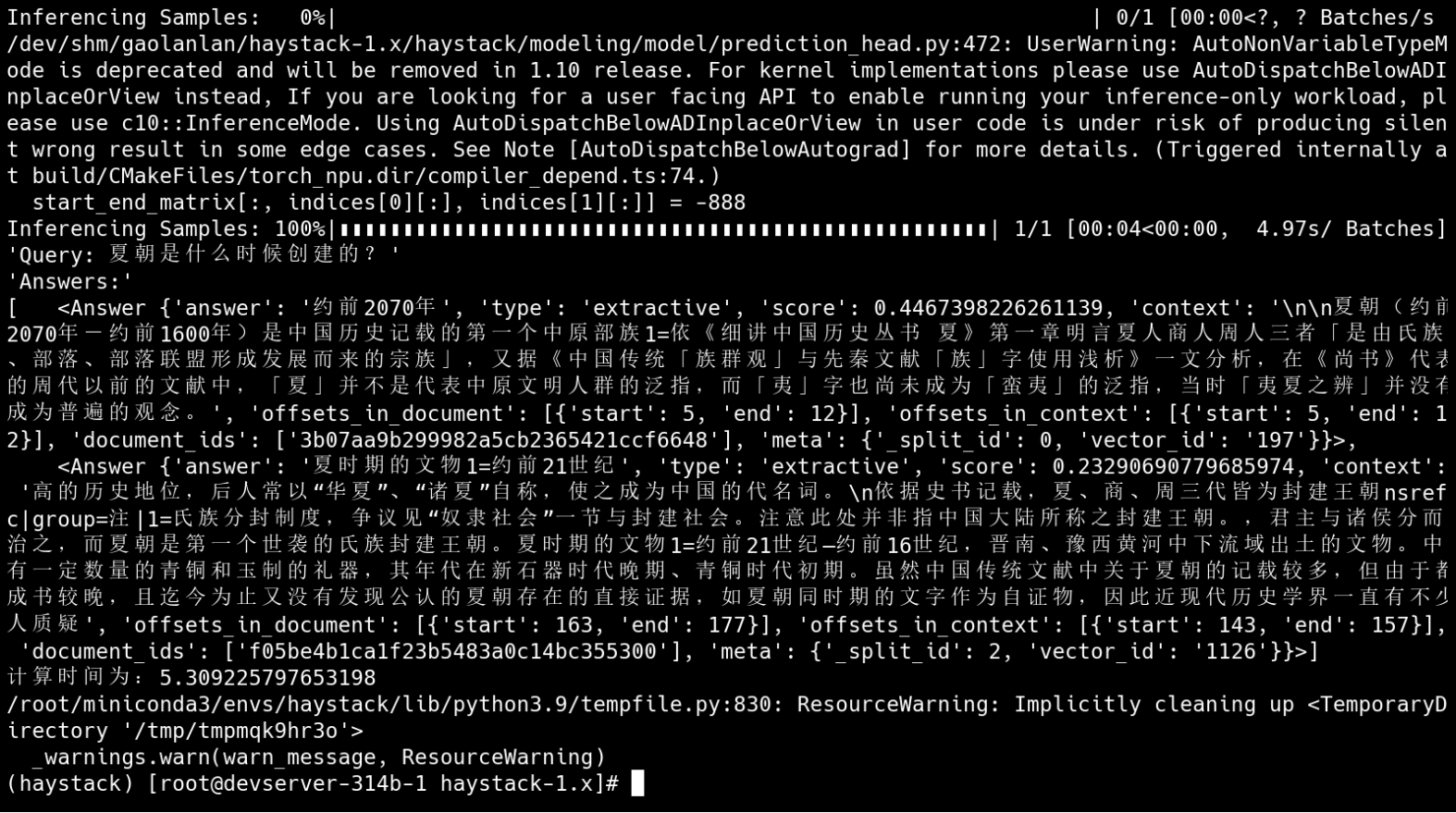
最后结果是这样的,提问的东西必须是数据集内包含的内容,还有一个需要注意的是,每次运行都会生成这三个文件,所以想要重新运行就必须把这三个删除之后重新运行,这三个文件会在test.py同一目录下生成。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)