混沌演练识别业务架构风险,提升系统韧性

文章来源:《确定性运维2.0案例集第3期》
一、业务背景
G公司是一家巨型国有企业,在国内航空运输市场占据重要地位。鉴于航空运输业务的特殊性和复杂性,该公司对系统的稳定性和可靠性有着极高的要求。系统性能问题直接影响旅客出行体验及货物运输的安全性和时效性,进而影响其在市场中的竞争力。随着数字化转型的不断深入,G公司逐渐将线下业务迁移至华为云。为了更好地保障业务的持续运行,并验证业务上云后的系统韧性,G公司急需一种技术手段来主动发现系统潜在问题和风险。
G公司经过对华为云专业服务深入调研后发现,COC(统一运维中心)混沌演练可具备提供一站式自动化演练功能,系统性地覆盖从风险识别到复盘改进的整个端到端演练流程,能够满足业务诉求。
二、业务现状
G公司业务规模庞大,业务量呈现持续增长态势,应用架构错综复杂,涉及多个系统与服务之间的协同作业。这对系统韧性提出了极高的要求,需要不断优化和完善相关的技术架构与管理策略,以确保各项业务的高效、稳定运行。当前G公司主要面临以下4大业务挑战。
1. 系统复杂性高:应用架构由众多微服务组成,且微服务之间的依赖关系错综复杂,如同一张难以捉摸的网。这使得运维团队难以全面了解系统行为和潜在风险,增加了故障排查和预防难度。
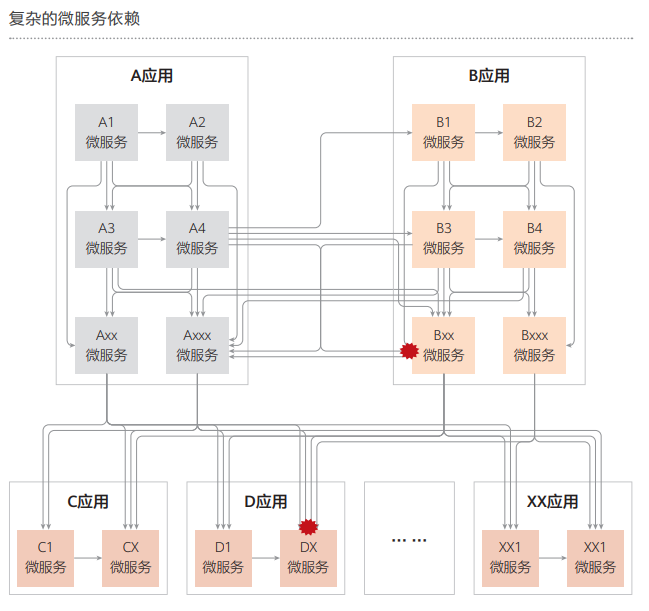
2. 传统测试方法局限性:传统的测试方法主要针对已知场景和故障测试,无法触及系统在未知状况下的潜在问题,且难以模拟复杂的实际运行场景。
3. 快速迭代衍生隐患:为了更好契合市场需求,业务系统需要快速迭代更新,但频繁引入的新功能也会带来新的隐患。这些隐患对系统原本的稳定性和可靠性有一定程度的冲击。
4. 故障爆炸半径大:在航空业中,由于业务的重要性以及广泛的关联性,系统故障可能会导致大量旅客无法正常出行。同时可能会引发航班延误、取消等情况,会造成严重的经济损失和声誉损害。
三、 方案实践
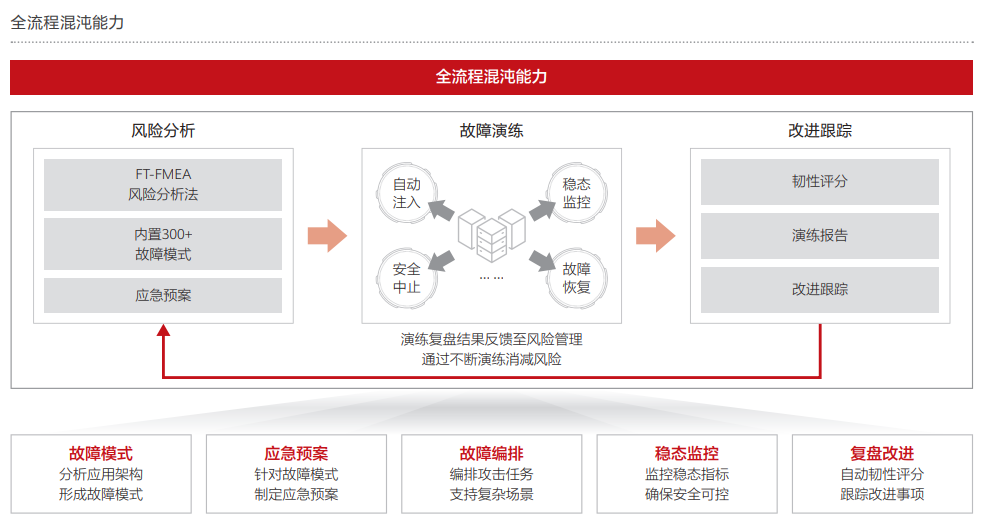
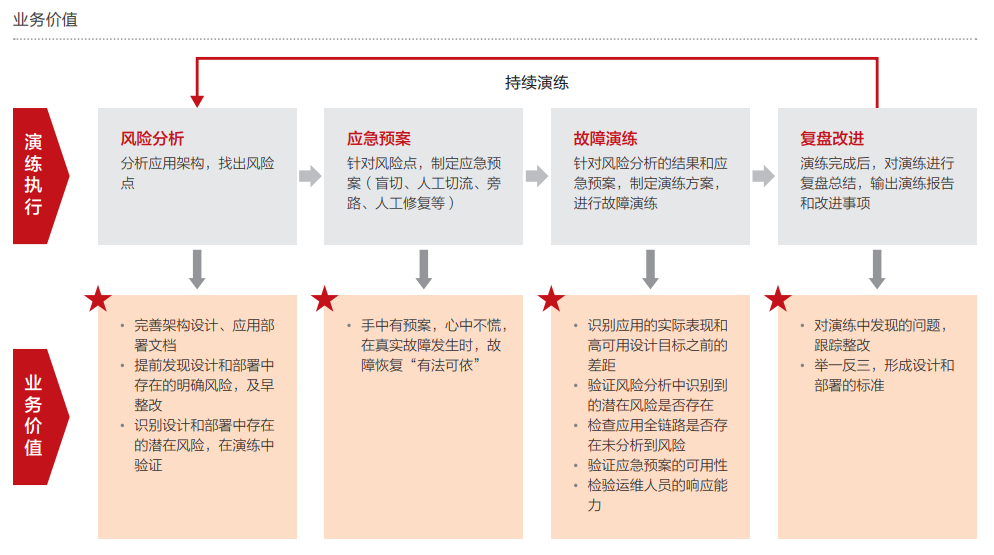
面对业务挑战,COC承载的华为云确定性运维场景化能力可满足G公司的业务诉求。其中,华为云的一站式自动化演练功能,通过全面的风险识别,可提前知晓云上应用可能面临的各类风险冲击;应急预案管理为应对突发情况提供了有力的保障;故障注入模拟真实场景下的各种故障,可提前发现系统的薄弱点并加以改进。
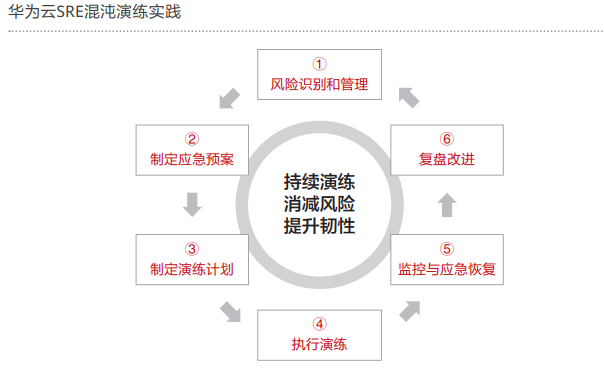
1. 应用架构分析和风险识别
1) 与华为云展开深入交流,依据实际业务流量以及架构设计目标,聚焦关键性能指标,对容量需求进行预测。同时清晰界定系统功能与业务之间的关联关系。
2) 对需求、设计、接口等文档进行审查,明确系统内外接口相关信息。同时结合代码的静态分析、走查以及集成测试、运行指标监控和日志分析等手段观测系统内外接口的实际交互状况及潜在问题。
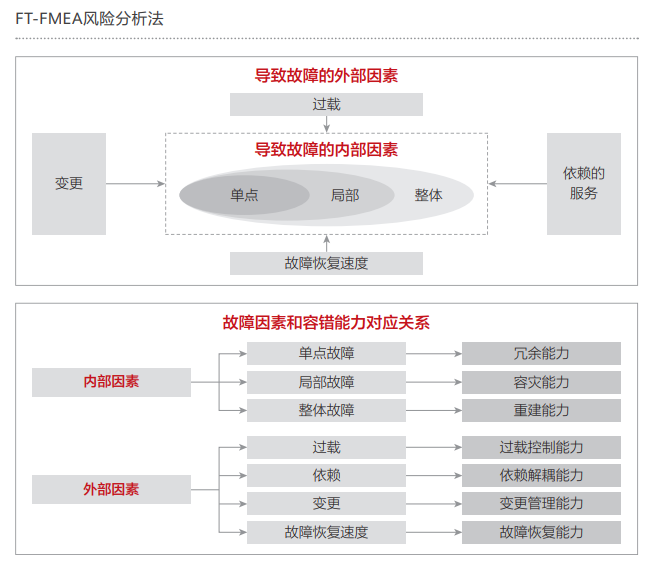
3) 通过华为云的FT - FMEA 风险分析法,从业务容错的角度出发,依据应急手段进行正、逆向分析,构建涵盖单点、局部、整体、过载、依赖、变更、故障恢复速度这 7 种故障类型的容错视角故障模式库,进而生成故障应急预案。
2. 混沌演练场景设计
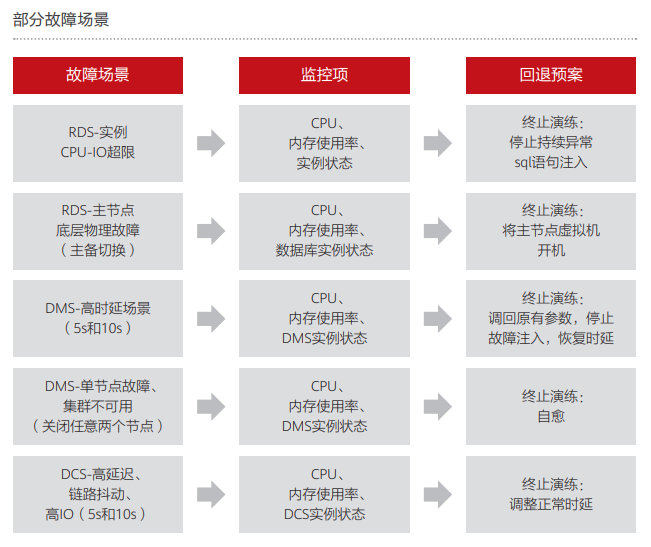
为验证公司云上服务的高可用能力,COC从故障发现、故障定位、故障影响、预期恢复时长、处理思路、故障恢复和恢复确认等7个方面对G公司业务进行演练验证,重点演练场景如下:
- RDS主节点故障:模拟误操作将RDS主节点宿主机下线使实例异常。该故障将导致业务访问数据库出现闪断,验证RDS主备切换是否正常,并评估业务的实际受损情况。
- DMS单节点网卡高时延故障:模拟业务量增加时,DMS节点网卡由于性能不足导致网络时延过高,验证DMS单节点高时延故障时实例的可用性。
- DCS进程重启:模拟业务量剧增,DCS负载打满,导致节点故障,验证DCS服务在主节点不可用时的主备切换能力。
- CCE-Node节点CPU突增导致节点过载:模拟业务流量增加、请求堆积,导致Node节点异常,验证业务是否进行了高可用部署。
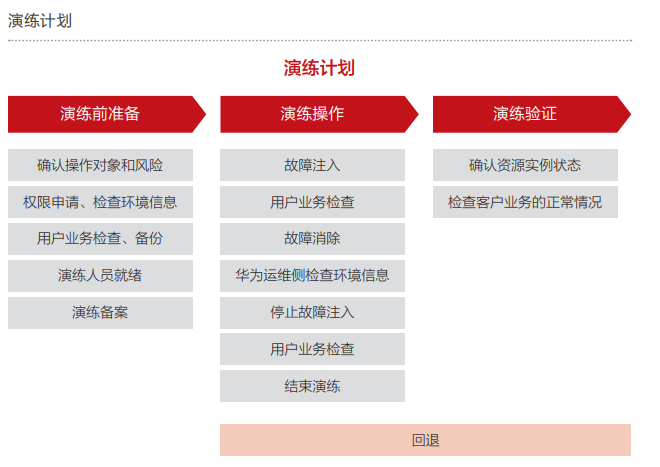
3. 确定演练计划
1) 做好每个场景的演练计划,包括演练前的准备工作(权限申请、环境检查、业务检查),演练操作的具体步骤、演练结束后的验证和回退计划。
2) 确定演练组人员:华为侧为操作人,G公司侧为配合人、监控责任人、业务验证人等。
4. 演练任务的执行与监控
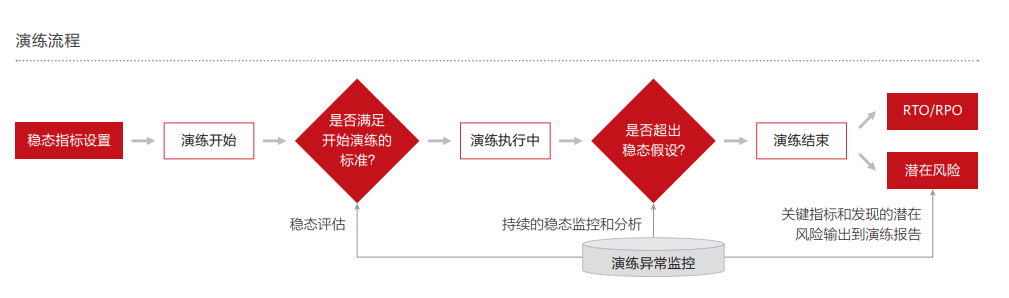
1) 执行前:鉴于混沌演练旨在充分暴露系统潜在风险,故需为每个故障场景精准匹配特定应急预案,并设定相应稳态指标与监控指标,确保在实验过程中,即便遭遇不可预见问题,亦能有条不紊地应对,保障系统稳定性与可靠性,有效达成混沌演练预期目标。
2) 执行中:演练组以预先确定的故障模式为基准,精准发起演练任务,同时妥善配置与之匹配的监控指标,针对系统的关键性能指标及运行状态,涵盖响应时间、吞吐量、错误率等指标,展开全方位实时监测。一旦系统运行出现异常状况,演练执行人员可通过页面的立即停止按钮,迅速终止演练流程,并即刻执行故障回退相关操作,确保系统在混沌演练期间的稳定性与可恢复性,充分彰显混沌演练对于系统风险探测与应急处置能力检验的重要价值与严谨性。
5. 结果分析与改进
演练结束后,演练组对演练结果从故障发现、故障定位、故障恢复、业务爆炸半径、运维团队配合等方面进行了深入分析,寻找系统中潜在问题和薄弱环节,重点如下:
在DCS高延迟演练场景中,发现部分业务出现访问报错。华为云专家团队建议公司在多实例和多副本部署的情况下,进行业务降级设计,降低对Redis的依赖。
在ELB后端云服务器异常的场景中,发现业务侧配置的健康检查探测次数过多,等待恢复检测时间较长等问题。建议运维人员减少健康检查次数或缩短检查时间。
本次演练发现G公司业务系统4处潜在的高危风险点,占演练场景25%。同时华为云演练组针对发现的问题,输出详细的演练报告,提供对应的优化建议。
四、 业务提升
本次混沌演练实施支持服务,有效提升了G公司云上业务的韧性。具体如下:
系统韧性提升:系统的容错能力和故障恢复机制得到了有效验证和优化。在面对各种实际故障情况时,系统能够快速地恢复正常运行,减少业务中断的时间和损失。
风险意识提高:公司开发和运维团队通过本次演练更加深入地了解了系统的潜在风险,提高风险意识,并验证了日常运维应急预案的可行性。
五、 案例总结
G公司作为国内航空运输市场的巨型国有企业,因业务特殊性对系统稳定性要求极高。在数字化转型中将业务迁移至华为云后,保障业务运行稳定和验证系统韧性成为当前重点工作。此次演练涵盖从风险识别到复盘改进全流程,通过此次演练,G公司的系统容错和故障恢复机制得以优化,团队风险意识提高,日常运维预案的可行性也得到检验。

- 点赞
- 收藏
- 关注作者
评论(0)