基于Pytorch Gemotric在昇腾上实现GraphSage图神经网络

本文主要介绍了如何在昇腾上,使用pytorch对经典的图神经网络GraphSage在论文引用CiteSeer数据集上进行分类训练的实战讲解。内容包括GraphSage创新点分析、GraphSage算法原理、GraphSage网络架构剖析与GraphSage网络模型代码实战分析等等。
本实验的目录结构安排如下所示:
- GraphSage创新点分析
- GraphSage算法原理
- GraphSage网络架构剖析
- GraphSage网络用于CiteSeer数据集分类实战
GraphSage创新点分析
- 提出了一种归纳式学习模型,可以得到新点/新图的表征。
- 模型通过学习一组函数来得到点的表征。之前的随机游走方式则是先随机初始化点的表征,然后通过模型的训练更新点的表征来获取点的表征,这样无法进行归纳式学习。
- 采样并汇聚点的邻居特征与节点的特征拼接得到点的特征。
- GraphSAGE算法在直推式和归纳式学习均达到最优效果。
GraphSage算法原理
GCN网络每次学习都需要将整个图送入显存/内存中,资源消耗巨大。另外使用整个图结构进行学习,导致了GCN的学习的固化,图中一旦新增节点,整个图的学习都需要重新进行。这两点对于大数据集和项目实际落地来说,是巨大的阻碍。
我们知道,GCN网络的每一次卷积的过程,每个节点都是只与自己周围的信息节点进行交互,对于单层的GCN网络而言,每个节点只能够接触到自己一跳以内的节点信息,两层的话则是两跳,通过一跳邻居间接传播过来。
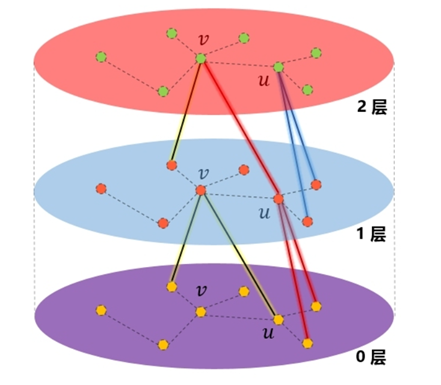
假设需要图中一个点的卷积的结果,并且只使用了一层GCN,那么实际上我只需要这个节点和它的全部邻居节点,图中的其他节点是没有意义的;如果使用了两层GCN,那么我只需要这个节点和它的两跳以内的全部邻居,以此类推。因为更远节点的信息根本无法到达这个节点。
此外,当图中的某些节点是有几百上千个邻居的超级节点,对于这种节点,哪怕只进行一跳邻居采样,仍然会导致计算困难。GraphSage网络采用抽取出一部分待训练节点和它们的N跳内邻居可以完成这些节点的训练,与此同时对于超级节点的情况,提出了采样的思路,即只对目标节点的邻居进行一定数量的采样,然后通过这次被采样出来的节点和目标节点进行计算,从而逼近完全聚合的效果。
GraphSAGE模型,是一种在图上的通用的归纳式的框架,利用节点特征信息(例如文本属性)来高效地为训练阶段未见节点生成embedding。该模型学习的不是节点的embedding向量,而是学习一种聚合方式,即如何通过从一个节点的局部邻居采样并聚合顶点特征,得到节点最终embedding表征。 当学习到适合的聚合函数后,可以迅速应用到未见过的图上,得到未见过的节点embedding。
因此采样与聚合是GraphSage网络的两大主要工作,通过随机采样的方式从整张图中抽出一张子图近似替换原始图,然后在该子图上进行聚合计算提取信息特征。
/*** 算法流程解读 ***/
第一个 for循环针对层数进行遍历,表示进行多少层的GraphSAGE, 第二个for循环用于遍历Graph中的所有节点, 针对每个节点, 对邻居进行采样得到邻居节点集合,然后遍历该集合使用对邻居节点信息进行聚合得到,最后,通过对邻居节点的及目标节点上衣节点信息进行拼接, 经过非线性变换后赋得到v节点在当前k层的节点权重值。

GraphSage网络架构剖析
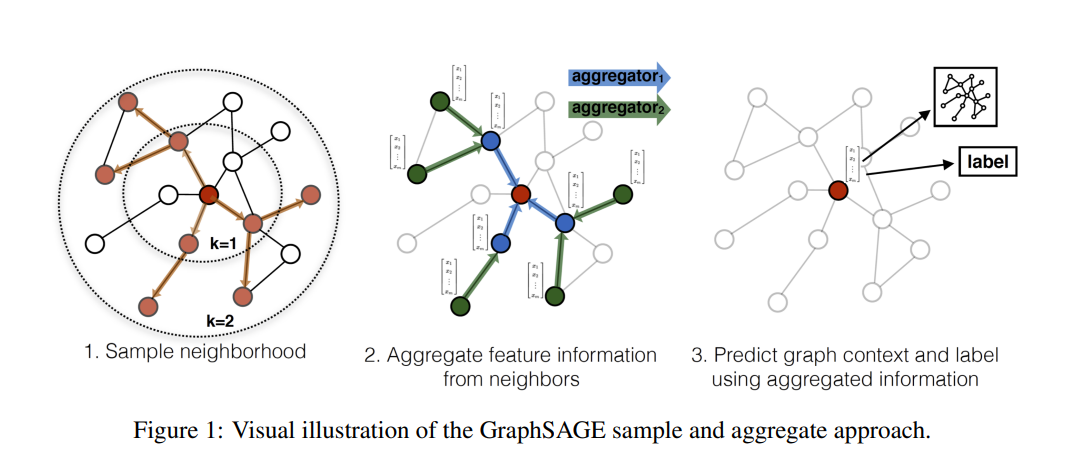
GraphSAGE不是试图学习一个图上所有node的embedding,而是学习一个为每个node产生embedding的映射。 GraphSage框架中包含两个很重要的操作:Sample采样和Aggregate聚合。这也是其名字GraphSage(Graph SAmple and aggreGatE)的由来。GraphSAGE 主要分两步:采样、聚合。GraphSAGE的采样方式是邻居采样,邻居采样的意思是在某个节点的邻居节点中选择几个节点作为原节点的一阶邻居,之后对在新采样的节点的邻居中继续选择节点作为原节点的二阶节点,以此类推。
文中不是对每个顶点都训练一个单独的embeddding向量,而是训练了一组aggregator functions,这些函数学习如何从一个顶点的局部邻居聚合特征信息。每个聚合函数从一个顶点的不同的hops或者说不同的搜索深度聚合信息。测试或是推断的时候,使用训练好的系统,通过学习到的聚合函数来对完全未见过的顶点生成embedding。
上图包含下述三个步骤:
- 对图中每个顶点邻居顶点进行采样,因为每个节点的度是不一致的,为了计算高效, 为每个节点采样固定数量的邻居
- 根据聚合函数聚合邻居顶点蕴含的信息
- 得到图中各顶点的向量表示供下游任务使用
GraphSage网络用于CiteSeer数据集分类实战
导入torch相关库,'functional’集成了一些非线性算子函数,例如Relu等。
import torch
import torch.nn.functional as F
由于torch_geometric中集成了单层的SAGEConv模块,这里直接进行导入,若有兴趣可以自行实现该类,注意输入与输出对齐即可。此外,数据集用的是CiteSeer,该数据集也直接集成在Planetoid模块中,这里也需要将其import进来。
# 导入GraphSAGE层
from torch_geometric.nn import SAGEConv
from torch_geometric.datasets import Planetoid
本实验需要跑在Npu上,因此将Npu相关库导入,'transfer_to_npu’可以使模型快速的迁移到Npu上进行运行。
#导入Npu相关库
import torch_npu
from torch_npu.contrib import transfer_to_npu
/home/pengyongrong/miniconda3/envs/AscendCExperiments/lib/python3.9/site-packages/torch_npu/dynamo/init.py:18: UserWarning: Register eager implementation for the ‘npu’ backend of dynamo, as torch_npu was not compiled with torchair.
warnings.warn(
/home/pengyongrong/miniconda3/envs/AscendCExperiments/lib/python3.9/site-packages/torch_npu/contrib/transfer_to_npu.py:164: ImportWarning:
*************************************************************************************************************
The torch.Tensor.cuda and torch.nn.Module.cuda are replaced with torch.Tensor.npu and torch.nn.Module.npu now…
The torch.cuda.DoubleTensor is replaced with torch.npu.FloatTensor cause the double type is not supported now…
The backend in torch.distributed.init_process_group set to hccl now…
The torch.cuda.* and torch.cuda.amp.* are replaced with torch.npu.* and torch.npu.amp.* now…
The device parameters have been replaced with npu in the function below:
torch.logspace, torch.randint, torch.hann_window, torch.rand, torch.full_like, torch.ones_like, torch.rand_like, torch.randperm, torch.arange, torch.frombuffer, torch.normal, torch._empty_per_channel_affine_quantized, torch.empty_strided, torch.empty_like, torch.scalar_tensor, torch.tril_indices, torch.bartlett_window, torch.ones, torch.sparse_coo_tensor, torch.randn, torch.kaiser_window, torch.tensor, torch.triu_indices, torch.as_tensor, torch.zeros, torch.randint_like, torch.full, torch.eye, torch._sparse_csr_tensor_unsafe, torch.empty, torch._sparse_coo_tensor_unsafe, torch.blackman_window, torch.zeros_like, torch.range, torch.sparse_csr_tensor, torch.randn_like, torch.from_file, torch._cudnn_init_dropout_state, torch._empty_affine_quantized, torch.linspace, torch.hamming_window, torch.empty_quantized, torch._pin_memory, torch.Tensor.new_empty, torch.Tensor.new_empty_strided, torch.Tensor.new_full, torch.Tensor.new_ones, torch.Tensor.new_tensor, torch.Tensor.new_zeros, torch.Tensor.to, torch.nn.Module.to, torch.nn.Module.to_empty
*************************************************************************************************************
warnings.warn(msg, ImportWarning)
CiteSeer数据集介绍

CiteSeer是一个学术论文数据集,主要涉及计算机科学领域。它由NEC研究院开发,基于自动引文索引(ACI)机制,提供了一种通过引文链接来检索文献的方式。
CiteSeer数据集由学术论文组成,每篇论文被视为一个节点,引用关系被视为边,总共包含6个类别,对应图中6种不同颜色的节点。
包含3327篇论文也就是3327个节点,每个节点有一个3703维的二进制特征向量,用来表示论文的内容,其中特征向量采用词袋模型(Bag of Words)表示,即每个特征维度对应一个词汇表中的词,值为1表示该词在论文中出现,为0表示未出现。在这些论文中共组成4732条边表示论文与论文的引用关系。6个类别分别是Agents、Artificial、Intelligence、Database、Information Retrieval、Machine Learning与Human-Computer Interaction。
加载数据集,root为下载路径的保存默认保存位置,若下载不下来可手动下载后保存在指定路径即可。
print("===== begin Download Dadasat=====\n")
dataset = Planetoid(root='/home/pengyongrong/workspace/data', name='CiteSeer')
print("===== Download Dadasat finished=====\n")
print("dataset num_features is: ", dataset.num_features)
print("dataset.num_classes is: ", dataset.num_classes)
print("dataset.edge_index is: ", dataset.edge_index)
print("train data is: ", dataset.data)
print("dataset0 is: ", dataset[0])
print("train data mask is: ", dataset.train_mask, "num train is: ", (dataset.train_mask ==True).sum().item())
print("val data mask is: ",dataset.val_mask, "num val is: ", (dataset.val_mask ==True).sum().item())
print("test data mask is: ",dataset.test_mask, "num test is: ", (dataset.test_mask ==True).sum().item())
===== begin Download Dadasat=====
===== Download Dadasat finished=====
dataset num_features is: 3703
dataset.num_classes is: 6
dataset.edge_index is: tensor([[ 628, 158, 486, …, 2820, 1643, 33],
[ 0, 1, 1, …, 3324, 3325, 3326]])
train data is: Data(x=[3327, 3703], edge_index=[2, 9104], y=[3327], train_mask=[3327], val_mask=[3327], test_mask=[3327])
dataset0 is: Data(x=[3327, 3703], edge_index=[2, 9104], y=[3327], train_mask=[3327], val_mask=[3327], test_mask=[3327])
train data mask is: tensor([ True, True, True, …, False, False, False]) num train is: 120
val data mask is: tensor([False, False, False, …, False, False, False]) num val is: 500
test data mask is: tensor([False, False, False, …, True, True, True]) num test is: 1000
/home/pengyongrong/miniconda3/envs/AscendCExperiments/lib/python3.9/site-packages/torch_geometric/data/in_memory_dataset.py:300: UserWarning: It is not recommended to directly access the internal storage format data of an ‘InMemoryDataset’. If you are absolutely certain what you are doing, access the internal storage via InMemoryDataset._data instead to suppress this warning. Alternatively, you can access stacked individual attributes of every graph via dataset.{attr_name}.
warnings.warn(msg)
搭建两层GraphSAGE网络,其中sage1与sage2分别表示第一层与第二层,这里如果有需要可以搭建多层的GraphSage,注意保持输入链接出大小相互匹配即可。
class GraphSAGE_NET(torch.nn.Module):
def __init__(self, feature, hidden, classes):
super(GraphSAGE_NET, self).__init__()
self.sage1 = SAGEConv(feature, hidden)
self.sage2 = SAGEConv(hidden, classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.sage1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.sage2(x, edge_index)
return F.log_softmax(x, dim=1)
定义设备跑在Npu上,这里如果需要替换成Gpu或Cpu,则替换成’cuda’或’cpu’即可。
device = 'npu'
定义GraphSAGE网络,中间隐藏层节点个数定义为16,'dataset.num_classes’为先前数据集中总的类别数,这里是7类。'to()‘的作用是将该加载到指定模型设备上。优化器用的是’optim’中的’Adam’。
model = GraphSAGE_NET(dataset.num_node_features, 16, dataset.num_classes).to(device)
data = dataset[0].to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
开始训练模型,指定训练次数200次,训练后采用极大似然用作损失函数计算损失,然后进行反向传播更新模型的参数,训练完成后,用验证集中的数据对模型效果进行验证,最后打印模型的准确率为0.665。
model.train()
for epoch in range(200):
optimizer.zero_grad()
out = model(data)
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
model.eval()
_, pred = model(data).max(dim=1)
correct = int(pred[data.test_mask].eq(data.y[data.test_mask]).sum().item())
acc = correct / int(data.test_mask.sum())
print('GraphSAGE Accuracy: {:.4f}'.format(acc))
GraphSAGE Accuracy: 0.6650
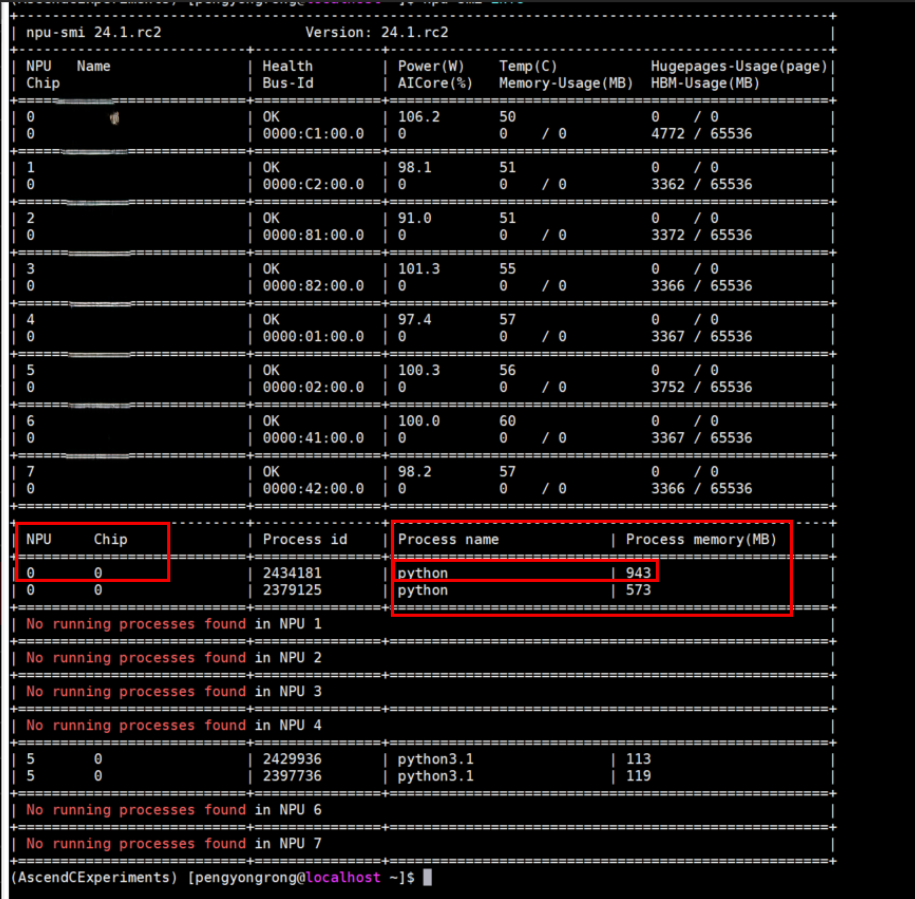
显存使用情况: 整个训练过程的内存使用情况可以通过"npu-smi info"命令在终端查看,因此本文实验只用到了单个npu卡(也就是chip 0),内存占用约943M,对内存、精度或性能优化有兴趣的可以自行尝试进行优化。
Reference
[1] Hamilton, William L , R. Ying , and J. Leskovec . “Inductive Representation Learning on Large Graphs.” (2017).

-
826.87KB 下载次数:0次
- 点赞
- 收藏
- 关注作者
评论(0)