Faiss适配昇腾开源验证任务心得

一、背景介绍
Faiss是一个高效的相似性搜索和密集向量聚类库。本项目致力于实现Faiss在华为昇腾NPU、鲲鹏CPU和EulerOS操作系统上的部署演示. 主要目的是通过不同的索引类型,探索在给定查询和评估准则下的最佳性能点,本文将介绍在华为的Ascend NPU上配置Faiss项目的详细开发步骤、遇到的问题和解决方案, 以及心得总结。
项目源地址: https://github.com/facebookresearch/faiss/tree/main
二、开发步骤
一、进行鲲鹏CPU适配
1.购买华为云虚拟私有云VPC和弹性云服务器ECS
详解教程参考链接:https://support.huaweicloud.cn/qs-ecs/ecs_01_0103.html 已有忽略
2.环境搭建
python版本为: 3.9
代码拉取:
git clone https://github.com/facebookresearch/faiss.git
cd faiss.git
安装faiss向量数据库
使用Anaconda安装使用faiss是最方便快速的方式,facebook会及时推出faiss的新版本conda安装包,在conda安装时会自行安装所需的libgcc, mkl, numpy模块。
pip install faiss-cpu
从源码安装 : Faiss可以使用CMake来源地构建。
cmake版本为 3.24.0
#下载faiss源码
git clone https://github.com/facebookresearch/faiss.git
#进入faiss目录,建立build文件夹
cd faiss
mkdir build
#开始编译,不编译GPU
cmake -B build . -DFAISS_ENABLE_GPU=OFF -DBUILD_SHARED_LIBS=ON
make -C build -j faiss
sudo make -C build install
运行官方验证代码 官方验证代码地址: https://github.com/facebookresearch/faiss/wiki/Getting-started
若出现以下结果,恭喜你,faiss的基本安装已经完成!
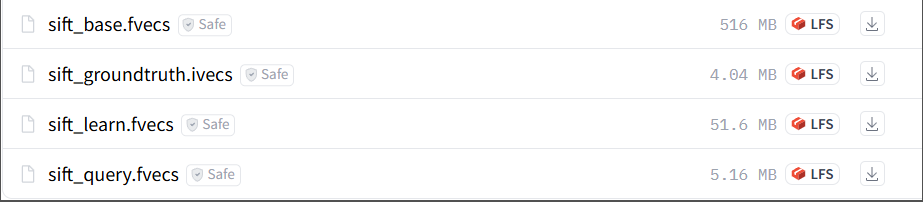
3.下载数据集
数据集地址: https://huggingface.co/datasets/qbo-odp/sift1m/tree/main 下载下面四个数据集
4. 准备测试
鲲鹏环境部署:
运行如下命令
python demo_auto_tune.py
官方文档地址:
https://github.com/facebookresearch/faiss/blob/main/demos/demo_auto_tune.py
运行测试文件:python demo_auto_tune.py
运行结果:
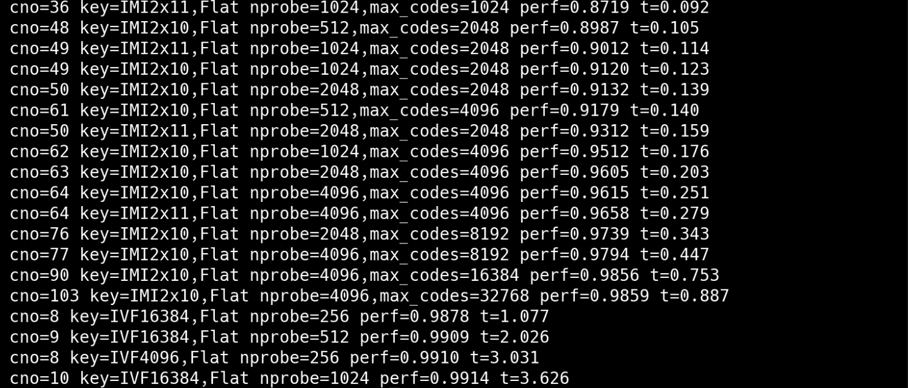
1. 打印load data、 load GT、prepare criterion等提示信息, 表明数据加载和评价准则准备等阶段的开始,针对每个索引配置进行处理时,============key<索引配置的信息>,提示正在处理的索引配置。
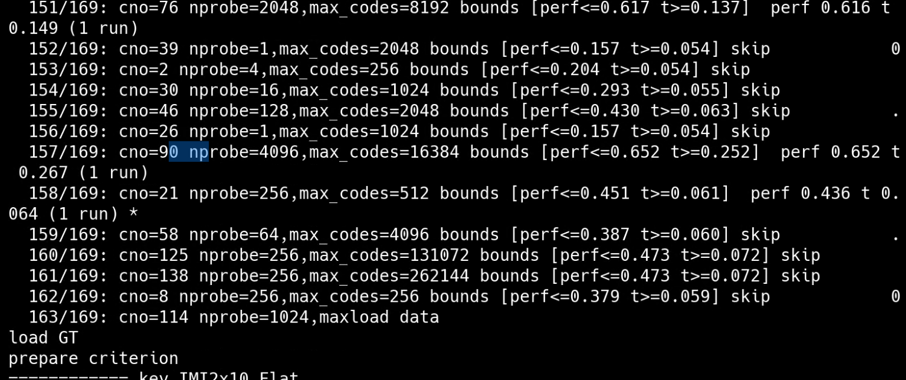
2. 展示训练与添加数据、探索操作点以及展示结果操作点这些步骤花费的时间,时间精度到小数点后3位,有助于了解各步骤的耗时情况。
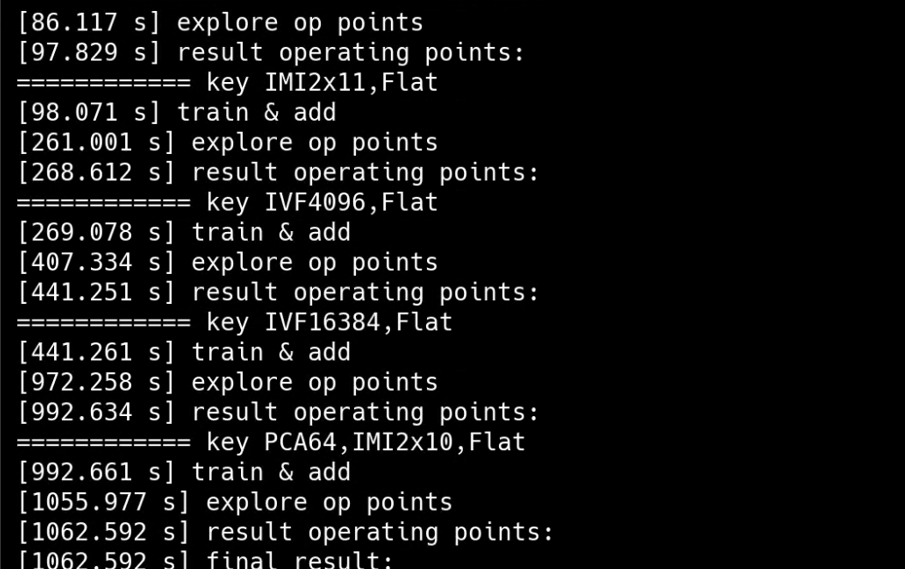
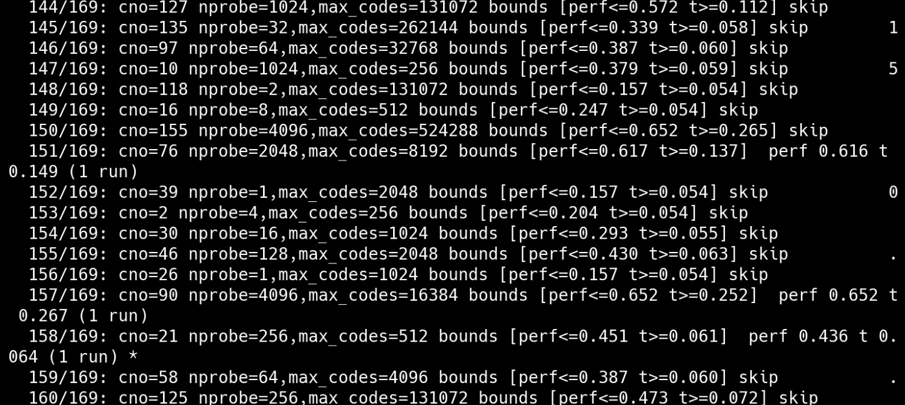
3. 每个索引配置探索操作点后, 展示该索引配置对应的操作点详细信息,包括召回率、搜索时间等指标的具体数值,展示该索引在不同设置下的性能表现。
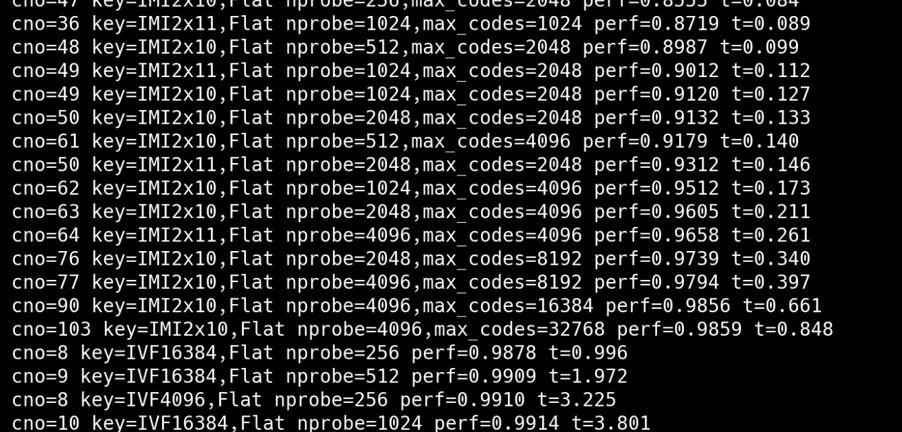
4. 展示综合所有已测试索引配置后得到的最终最佳操作点信息,从整体上对比不同索引配置下的最优性能情况。
二、进行昇腾npu适配
npu环境
昇腾环境: 芯片类型:昇腾910B3 CANN版本:CANN 7.0.1.5 驱动版本:23.0.6 操作系统:Huawei Cloud EulerOS 2.0
1. 查看npu硬件信息
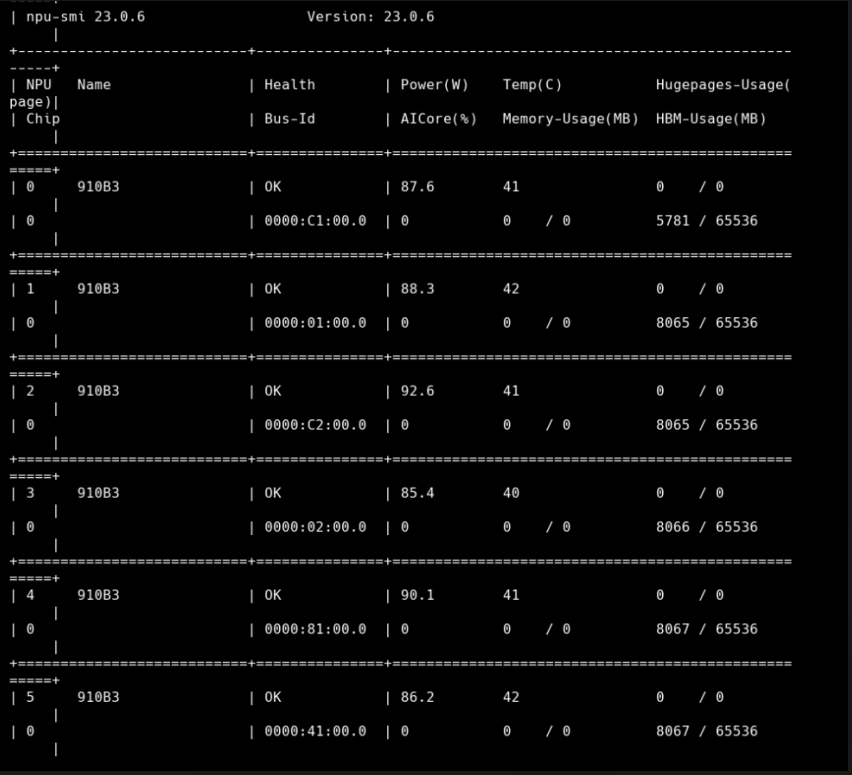
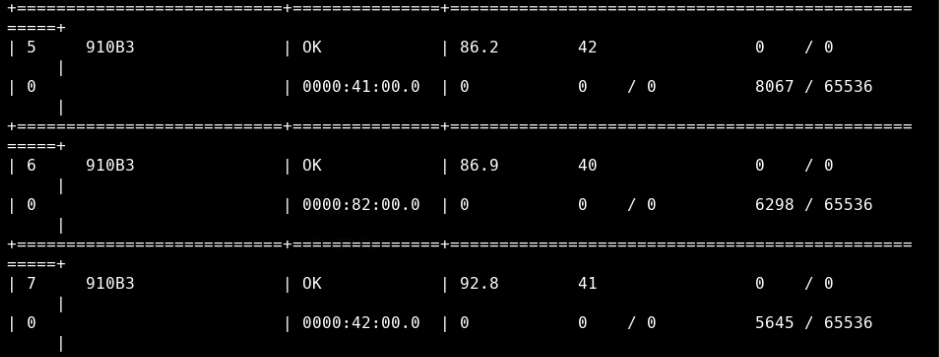
如果 Health 状态为 OK,说明 NPU 和 CANN 正常运行。
2. 在 demo_auto_tune.py 中加入
官方文档地址:
https://github.com/facebookresearch/faiss/blob/main/demos/demo_auto_tune.py
import torch
import torch_npu
from torch_npu.contrib import transfer_to_npu
3. 准备测试
然后编译运行指令不指定运行设备, 这个会自动使用NPU运行, 这个是因为代码中默认使用cuda运行, 但是使用了自动迁移, 所以会从cuda迁移到NPU上。 运行命令: python demo_auto_tune.py
运行结果:
1. 打印load data、 load GT、prepare criterion等提示信息, 表明数据加载和评价准则准备等阶段的开始,针对每个索引配置进行处理时,============key<索引配置的信息>,提示正在处理的索引配置。
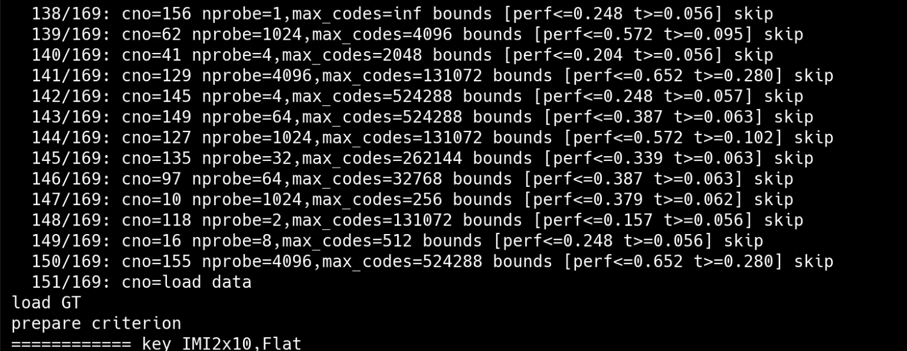
2. 展示训练与添加数据、探索操作点以及展示结果操作点这些步骤花费的时间,时间精度到小数点后3位,有助于了解各步骤的耗时情况。
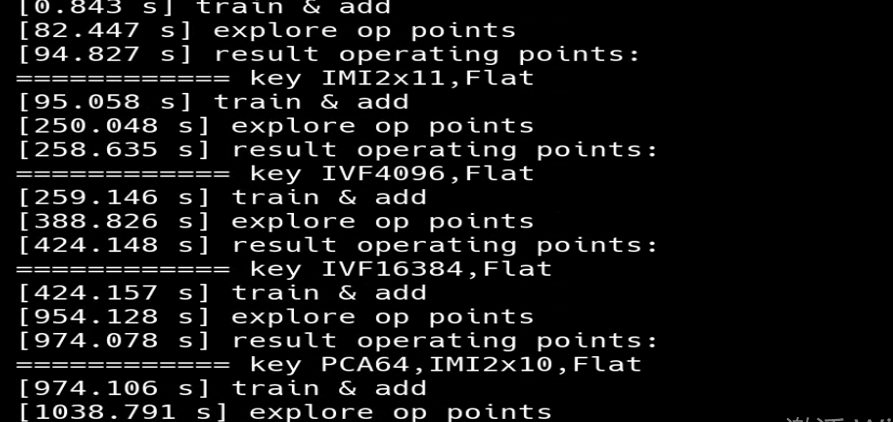
3. 每个索引配置探索操作点后, 展示该索引配置对应的操作点详细信息,包括召回率、搜索时间等指标的具体数值,展示该索引在不同设置下的性能表现。
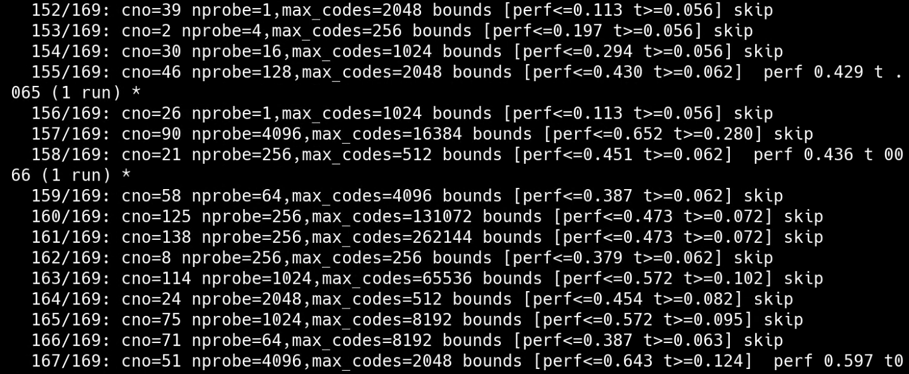
4. 展示综合所有已测试索引配置后得到的最终最佳操作点信息,从整体上对比不同索引配置下的最优性能情况。
三、遇到的问题和解决方法
问题1: 运行轮次较多, 且每次运行都会对每种索引执行 索引创建 训练索引 添加数据 参数探索 操作点记录 导致运行时间较长, 报错点不易查找。
解决方法: 运行测试命令时, 添加打印日志命令, 可以在日志文件中查找到具体的报错信息,并加以修改。
问题2: cmake-3.19.3版本过低, 算子尚未兼容, 提高cmake版本
解决方法: 下载预编译的CMake二进制包cmake-3.24.0.tar.gz, 解压包文件 tar -xvf cmake-3.24.0
问题3: torch版本过高, 算子尚未兼容, 降低torch版本
解决方法: pip install torch==2.1.0 torch_npu==2.1.0
四、心得总结
在整个适配过程中, 遇到了多个技术挑战, 主要问题还是环境配置相关问题, 通过根据报错信息理解和做出相应的修改、打印日志等方法去解决。以上主要是围绕faiss库进行向量索引的构建、训练、操作点的探索及结果展示,对比不同索引配置在给定数据集和评价准则下的性能优劣,帮助用户选择合适的索引方案用于实际的向量检索任务。希望这些经验可以帮助到其他开发者在类似环境中顺利部署和运行Faiss项目。

- 点赞
- 收藏
- 关注作者
评论(0)