新能源汽车可视化大屏数据展示系列之四数据存储

任务:
将数据存放到temp.csv
1、 将数据存储到[]列表中
#循环遍历,代码演示中,只写了打印!其他没有写!
for index,car in enumerate(pageJson):
carData = []
print('正在爬取第%d'%(index+1)+'数据')
#品牌名 print(car['brand_name'])
carData.append(car['brand_name'])
#车名 print(car['series_name'])
carData.append(car['series_name'])
#打印图片链接print(car['image'])
carData.append(car['image'])
#销量
carData.append(car['count'])
#价格,需要拼接最低价格和最高价格;
price=[]
price.append(car['min_price'])
price.append(car['max_price'])
carData.append(price)
carData.append(car['sub_brand_name'])
carData.append(car['rank'])2、 查看汽车排行数据
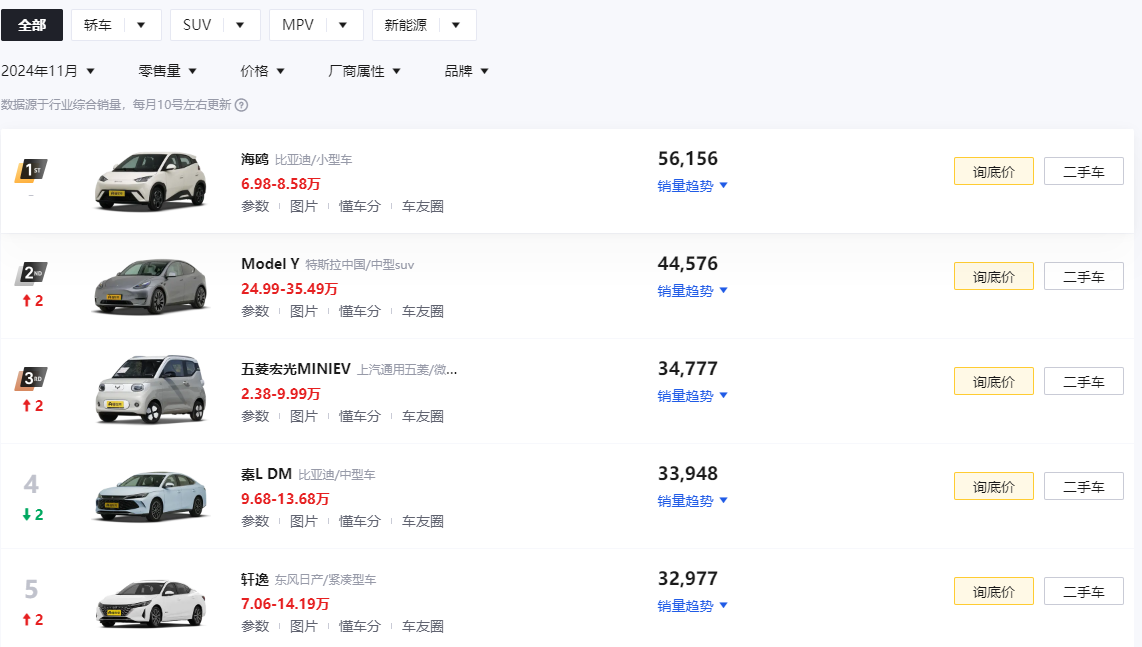
对比temp.csv数据发现少几条数据,需要点击“参数”链接
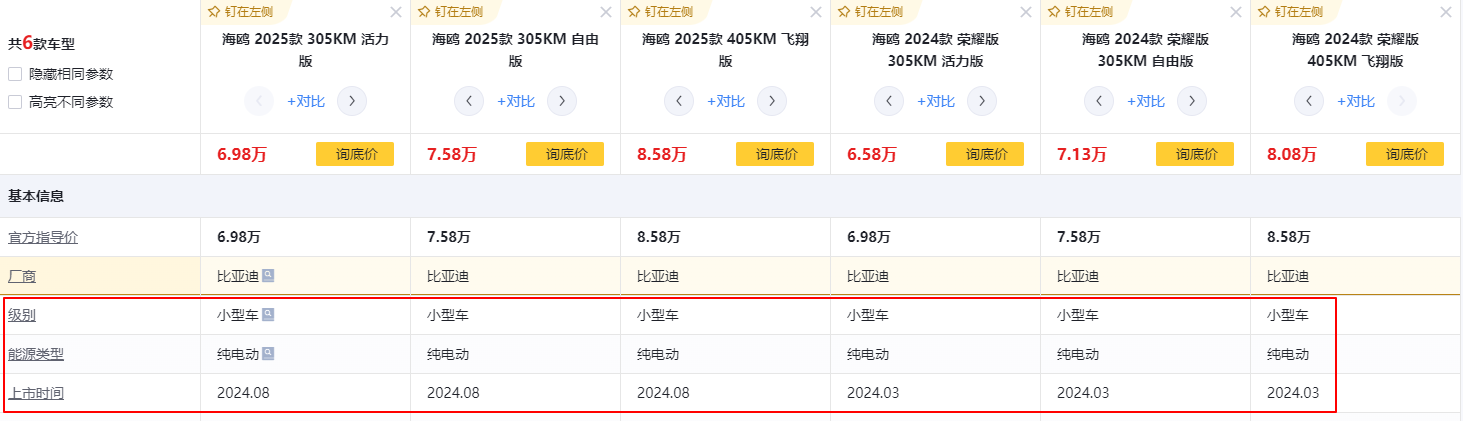

3、 利用xpath来分析网页
xpath的语法格式
表达式 描述
nodename 选取此节点的所有子节点。
/ 从根节点选取(取子节点)。
// 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置(取子孙节点)。
. 选取当前节点。
.. 选取当前节点的父节点。
@ 选取属性。
路径表达式 结果
/bookstore/book[1] 选取属于 bookstore 子元素的第一个 book 元素。
/bookstore/book[last()] 选取属于 bookstore 子元素的最后一个 book 元素。
/bookstore/book[last()-1] 选取属于 bookstore 子元素的倒数第二个 book 元素。
/bookstore/book[position()<3] 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。
//title[@lang] 选取所有拥有名为 lang 的属性的 title 元素。
//title[@lang='eng'] 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。
/bookstore/book[price>35.00] 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。
/bookstore/book[price>35.00]//title 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。
调试技巧:
检查表达式:确保XPath表达式正确无误,包括使用正确的轴(例如 child::、descendant::)、节点测试(例如 element()、text())和谓语(例如 [1]、[@id='example'])。
逐步构建:从简单的 XPath 开始,逐步添加条件,直到定位到目标元素。
使用浏览器的元素面板:在元素面板中,你可以右键点击一个元素,选择“Copy”然后“Copy XPath”,这通常会给出一个可以参考的XPath表达式。在需要编辑内容,右键“检查”(或F12),然后在Elements下右键“copy”,选择“Copy Path”
可以出来如下内容
//*[@id="__next"]/div/div/div/div[2]/div[2]/div[2]/div[4]
//*[@id="__next"]/div/div/div/div[2]/div[2]/div[2]/div[4]/div[2]/div/text()
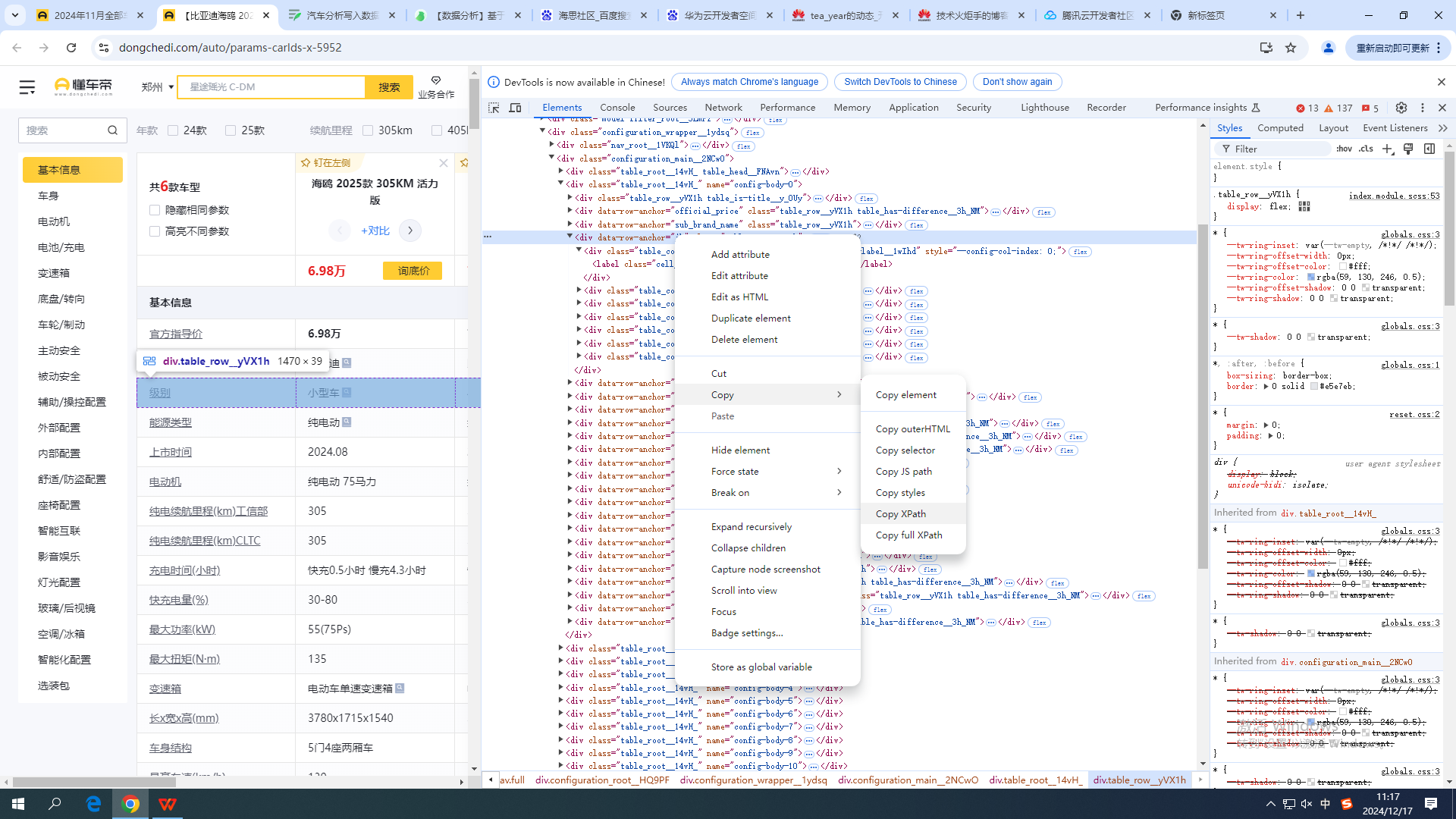
4、 Xpath的基本语法
在键盘上按下Ctrl+F,在下面输入框输入“//div[@data-row-anchor="jb"]/div[2]/div/text()”,发现既可定位到“中型车”。
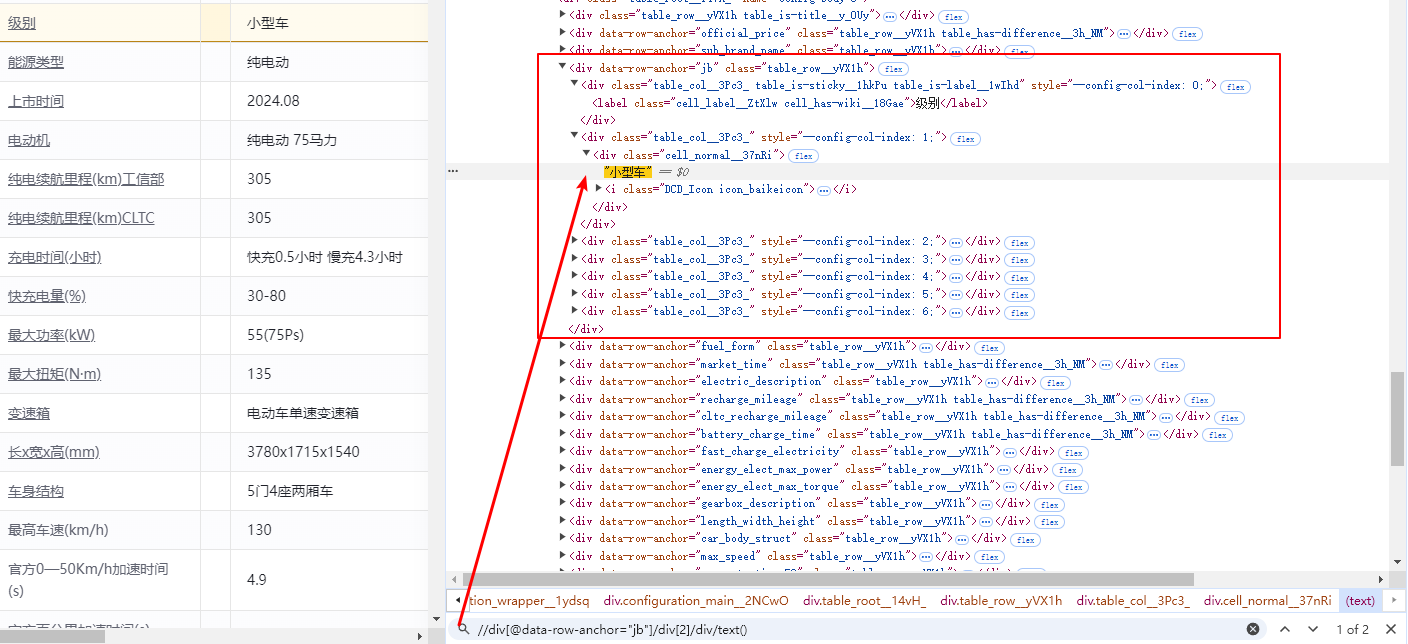
5、 上述操作的代码实践
#排名 https://www.dongchedi.com/auto/params-carIds-x-5952
# print(car['rank'])
carData.append(car['rank'])
infoHTML=requests.get('https://www.dongchedi.com/auto/params-carIds-x-5952')
#print(infoHTML.text)
infoHTMLPath=etree.HTML(infoHTML.text)
#carModel
carModel=infoHTMLPath.xpath('//div[@data-row-anchor="jb"]/div[2]/div/text()')[0]
print(carModel)5.少4个参数,在参数页
5.1 请求参数页;
5.2 解析
使用etree.HTML(html_string, parser=None)解析网络html字符串
html_string :要解析的HTML字符串
parser:(可选):默认情况下etree.HTML()使用etree.HTMLparser()进行解析
返回值:etree.HTML()返回一个ELement对象,表示HTML文档的根元素,可以通过该对象访问文档各个节点
#请求参数页
carNumber=car['series_id']
infoHTML=requests.get('https://www.dongchedi.com/auto/params-carIds-x-%s'%carNumber,headers=self.headers)
# print(infoHTML)<Response [200]> 是一个响应对象,<>就是html;
#print(infoHTML.text) #源码;这些源码,太多了;咱需要的是div下面的数据;用xpath获取div需要的数据;
infoHTMLPath=etree.HTML(infoHTML.text)
# print(infoHTMLPath) # <Element html at 0x8f21908> 元素;可以适用xpath对元素进行过滤;
#汽车车型
carModel=infoHTMLPath.xpath('//div[@data-row-anchor="jb"]/div[2]/div/text()')[0]
carData.append(carModel) #直接修改之前的print(carModel)为carData.append(carModel)
#新能源类型
energyType=infoHTMLPath.xpath('//div[@data-row-anchor="fuel_form"]/div[2]/div/text()')[0]
carData.append(energyType)
#上市时间
marketTime=infoHTMLPath.xpath('//div[@data-row-anchor="market_time"]/div[2]/div/text()')[0]
carData.append(marketTime)
#保养日期
insure=infoHTMLPath.xpath('//div[@data-row-anchor="period"]/div[2]/div/text()')[0]
carData.append(insure)
#测试:打印列表内容,看下顺序是否和temp.csv字段一致;
print(carData)
#调用保存到csv文件的函数
self.save_to_csv(carData)6、 将死的数据,升级为活的数据。
carNumber=car['series_id']
infoHTML=requests.get('https://www.dongchedi.com/auto/params-carIds-x-%s'%carNumber,headers=self.headers)7、 爬取数据写入csv文件
def save_to_save(self,resultData):
with open('./temp.csv','a',newline='', encoding='utf-8') as f:
writer=csv.writer(f)
writer.writerow(resultData)在下面窗口查看

效果达成,注意操作步骤。
总结
1. 数据获取
通过Python的requests库成功获取了目标网站的HTML内容。使用lxml库解析HTML,并通过XPath精准定位所需数据,实现了对多种车型的价格、配置、评价等信息的自动化收集。这不仅提高了数据抓取的效率,也保证了数据的准确性和完整性。
2. 数据解析
利用XPath表达式对HTML内容进行解析,提取出车型名称、价格、配置等关键信息。例如,通过//div[@class='car-info']/h2/text()提取车型名称,通过//div[@class='car-info']/p[@class='price']/text()提取价格信息。数据解析过程中,还进行了数据清洗,去除了噪音和不必要的信息,确保了数据的高质量。
3. 数据存储
解析后的数据被存储为CSV文件,便于后续的数据分析和处理。同时,提供了将数据存储到数据库中的方案,可以根据实际需求选择适合的存储方式。CSV文件的生成使得数据可以方便地进行共享和进一步分析。

- 点赞
- 收藏
- 关注作者
评论(0)