DataNucleus jpa适配华为云&Gaussdb

DataNucleus 和 JPA 介绍
1. DataNucleus
概述
DataNucleus 是一个开源的 Java 数据持久化框架,支持多种持久化 API 和数据存储,具有极高的灵活性和扩展性。它是 Java 持久化生态的一部分,主要用来管理应用程序与数据存储之间的交互。
主要特性
1. 支持多种 API:
• JPA (Java Persistence API):用于对象关系映射 (ORM)。
• JDO (Java Data Objects):Java 数据对象的规范。
• REST 和 JSON:支持通过 REST API 持久化数据。
2. 支持多种数据存储:
• 关系型数据库:MySQL、PostgreSQL、Oracle、SQL Server 等。
• NoSQL 数据库:MongoDB、Cassandra、HBase 等。
• 文件系统、Excel 文件和其他非传统存储。
3. 增强机制:
• 提供代码增强(Enhancement),用于优化字节码,以提高延迟加载和代理性能。
4. 灵活的配置:
• 支持 XML 配置和注解的混合使用。
• 可扩展性强,可根据需求添加自定义插件。
优点
• 支持多种数据库类型,适合复杂项目。
• 提供对 JPA 和 JDO 的完整实现,兼容性强。
• 允许开发者在一个框架中同时使用关系型和 NoSQL 数据存储。
缺点
• 社区相对较小,问题解决可能需要更多时间。
• 相比 Hibernate 或 EclipseLink,学习曲线较高。
2. JPA (Java Persistence API)
概述
JPA 是 Java 的官方持久化标准,定义了对象与关系数据库之间的映射。它是一种规范,没有具体实现,需要通过实现框架(如 Hibernate、EclipseLink 或 DataNucleus)来工作。
核心概念
1. Entity(实体):
• Java 类通过注解(如 @Entity)被映射为数据库表。
2. EntityManager:
• 核心接口,用于管理实体的生命周期(如增删改查)。
3. Persistence Unit:
• 定义数据源和 JPA 配置的单元,通常在 persistence.xml 文件中配置。
4. JPQL(Java Persistence Query Language):
• 类似于 SQL,但面向对象,用于查询和操作实体。
常用实现
1. Hibernate:
• 最流行的 JPA 实现之一,功能强大,支持广泛。
2. EclipseLink:
• Oracle 提供的 JPA 参考实现,功能全面。
3. DataNucleus:
• 支持 JPA 的完整实现,适合多数据存储场景。
优点
• 简化了持久化操作,屏蔽了数据库差异。
• 提供标准化 API,提高了框架的可移植性。
• 支持多种查询方式(JPQL、Criteria API)。
缺点
• 依赖具体的实现框架。
• 需要对 ORM 和数据库映射有一定的理解。
DataNucleus 和 JPA 的关系
• DataNucleus 是 JPA 的实现之一:它提供了对 JPA 标准的完整支持,并在此基础上扩展了对非关系型存储的支持。
• JPA 是一个规范,DataNucleus 是实现:类似于 Java Servlet 规范与 Tomcat 的关系。
使用场景对比
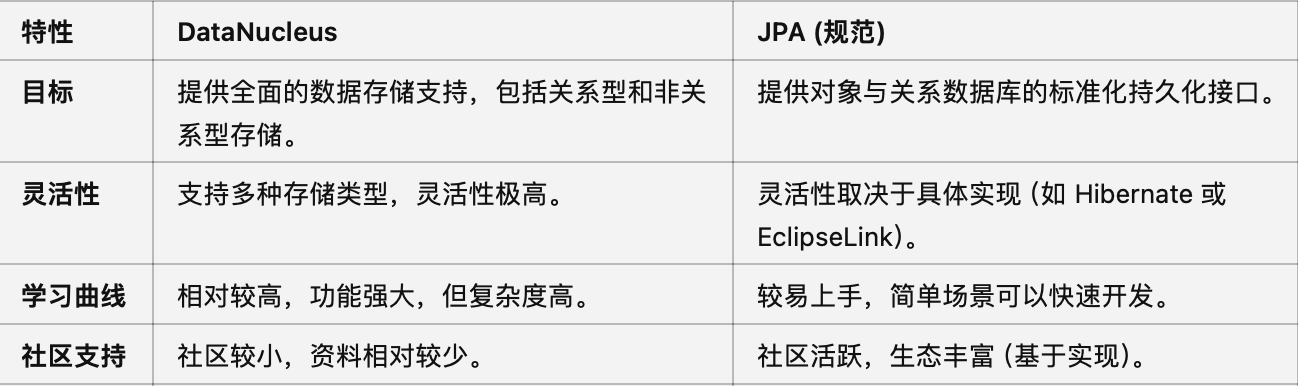
特性 DataNucleus JPA (规范)
目标 提供全面的数据存储支持,包括关系型和非关系型存储。 提供对象与关系数据库的标准化持久化接口。
灵活性 支持多种存储类型,灵活性极高。 灵活性取决于具体实现(如 Hibernate 或 EclipseLink)。
学习曲线 相对较高,功能强大,但复杂度高。 较易上手,简单场景可以快速开发。
社区支持 社区较小,资料相对较少。 社区活跃,生态丰富(基于实现)。
性能优化 提供增强功能,适合性能调优。 优化取决于具体实现。
步骤1:fork 仓库
本次任务是使用jpa规范和datanucleus在欧拉os上测试否则正常运行。
fork demo的仓库,demo中有基于servicecomb实现的完整的微服务脚实例,仓库信息如下:
https://gitcode.com/HuaweiCloudDeveloper/OpenSourceForHuaweiDemoJava/overview
步骤2:本地编译并运行
主要步骤:
- 执行mvn clean install -DskipTests
步骤3:适配思路
集成datanucleus和jpa相关的jar包,在demo上增加一个查询接口,测试是否可行。
官方文档如下:https://www.datanucleus.org/products/accessplatform/jdo/tutorial.html#step4
我的适配项目:https://gitcode.com/chenzhida/opensource-demo-datanucleus-jpa-241209/overview
分支:dev_datanucleus_jpa
步骤3:适配过程的问题
与jdo不同的是,jdo需要执行mvn datanucleus:enhance进行增强,而通过jpa只是部分需要增强。
增强的常见场景
1. 字段级延迟加载(Lazy Loading):如果你在实体类中配置了 @Basic(fetch = FetchType.LAZY) 或 @OneToMany(fetch = FetchType.LAZY) 等延迟加载策略,增强是必须的。
2. JDO 使用场景:如果你使用的是 JDO 而不是纯 JPA,也需要增强。
3. 提升性能:DataNucleus 的增强机制可以减少运行时代理的开销,提升性能。
问题1:这个错误 org.hibernate.LazyInitializationException 是一个典型的 Hibernate 懒加载异常,表示在尝试访问懒加载的属性时,Session 已经关闭或者不可用。这里的关键问题是:在 Student 实体的 age 属性被 Jackson 序列化时,Hibernate 试图延迟加载数据,但没有有效的 Session。
Caused by: org.hibernate.LazyInitializationException: could not initialize proxy [org.apache.servicecomb.fence.resource.Student#1] - no Session
at org.hibernate.proxy.AbstractLazyInitializer.initialize(AbstractLazyInitializer.java:165) ~[hibernate-core-6.5.2.Final.jar:6.5.2.Final]
at org.hibernate.proxy.AbstractLazyInitializer.getImplementation(AbstractLazyInitializer.java:314) ~[hibernate-core-6.5.2.Final.jar:6.5.2.Final]解决:避免直接返回实体,使用 DTO 或 VO 映射需要的数据:
public class StudentDTO {
private String name;
private int age;
public StudentDTO(String name, int age) {
this.name = name;
this.age = age;
}
}
@Transactional
public StudentDTO getStudentDTO(Long id) {
Student student = studentRepository.findById(id).orElseThrow();
return new StudentDTO(student.getName(), student.getAge());
}步骤4:购买华为云Gaussdb和ECS,上云测试
购买华为云Gaussdb,并且购买公网IP,不然无法访问。配置如下:
|
产品名称 |
产品类型 |
数据库引擎版本 |
性能规格 |
实例类型 |
部署形态 |
备注 |
|
云数据库 GaussDB |
基础版 |
8.201 |
独享型1:4 |
集中式 |
1主2备 |
推荐 |
| 产品名称 | CPU架构 | 实例类型 | 公共镜像 | 镜像版本 | 备注 |
|---|---|---|---|---|---|
| 弹性云服务器 | 鲲鹏计算 | 鲲鹏通用计算增强型 | Huawei Cloud EulerOS | Huawei Cloud EulerOS 2.0 标准版 64位 ARM版(10GiB) | 推荐 |
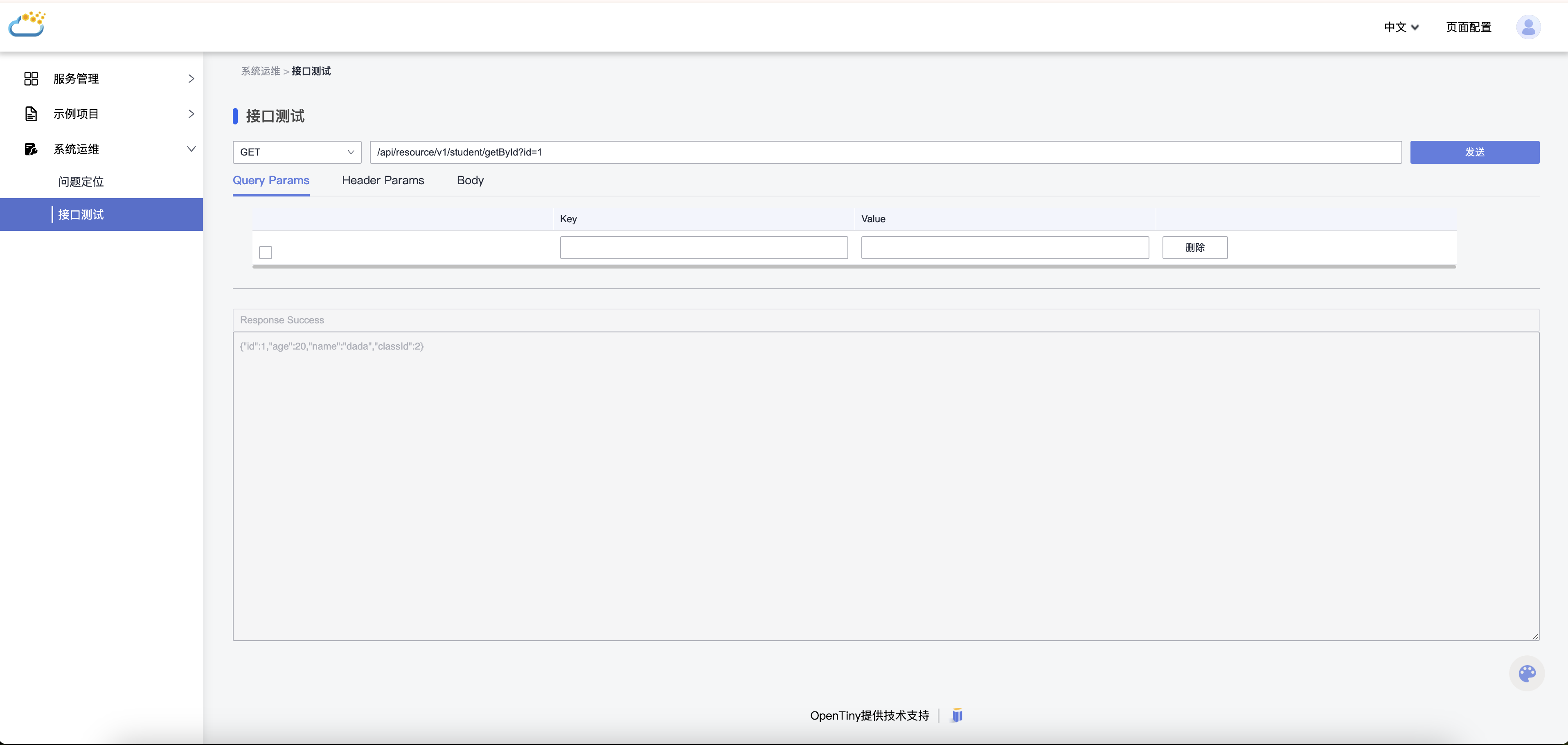
步骤5:部署并访问
结果如下:

- 点赞
- 收藏
- 关注作者
评论(0)