Baichuan2适配昇腾开源验证任务开发心得

从任务计划书(https://bbs.huaweicloud.cn/blogs/441212 )上了解任务内容,任务主要目的是将Baichuan2大模型适配至华为的Ascend Npu(昇腾)上,基于昇腾硬件完成模型训练推理。本次开发过程选择baichuan2-13B-chat模型。
1 开发过程
1.1 拉取仓库安装依赖:
git clone https://gitee.com/ascend/MindSpeed-LLM.git
git clone https://github.com/NVIDIA/Megatron-LM.git
cd Megatron-LM
git checkout core_r0.7.0
cp -r megatron ../MindSpeed-LLM/
cd ..
cd MindSpeed-LLM
mkdir logs
mkdir model_from_hf
mkdir dataset
mkdir ckpt
安装pytorch、torch_npu:
wget https://download.pytorch.org/whl/cpu/torch-2.1.0-cp38-cp38-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
wget https://gitee.com/ascend/pytorch/releases/download/v6.0.rc2-pytorch2.1.0/torch_npu-2.1.0.post6-cp38-cp38-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
pip3 install torch-2.1.0-cp38-cp38-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
pip3 install torch_npu-2.1.0.post6-cp38-cp38-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
其他依赖:
pip install torchvision==0.16.0
pip install apex-0.1_ascend*-cp38-cp38m-linux_aarch64.whl
source /usr/local/Ascend/ascend-toolkit/set_env.sh
source /usr/local/Ascend/nnal/atb/set_env.sh
# 安装加速库
cd ModelLink
git clone https://gitee.com/ascend/MindSpeed.git
cd MindSpeed
# checkout commit from MindSpeed core_r0.7.0 in 2024.11.04
git checkout f3332571
pip install -r requirements.txt
pip3 install -e .
cd ..
# 安装其余依赖库
pip install -r requirements.txt
1.2 下载权重并转换
从hunggingface找到Baichuan2-13b-chat的模型权重地址:https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat/tree/main,利用huggingface_hub下载权重。
mkdir ./model_from_hf/Bai2-13b/
pip install -U huggingface_hub
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download --resume-download baichuan-inc/Baichuan2-13B-Chat --loal-dir ./model_from_hf/Bai2-13b/
在ModelLink文件目录下运行脚本完成权重转换:
python convert_ckpt.py \
--model-type GPT \
--load-model-type hf \
--save-model-type mg \
--target-tensor-parallel-size 2 \
--target-pipeline-parallel-size 4 \
--num-layer-list 10,10,10,10 \
--model-type-hf baichuan2 \
--load-dir ./model_from_hf/cnm/ \
--save-dir ./model_weights/bai2-13-v1/ \
--tokenizer-model ./model_from_hf/cnm/tokenizer.model
传入参数中要注意:确保--num-layer-list中的层数与--target-pipeline-parallel-size设置大小一致。num-layer-list的每个值表示每个管道并行部分的层数,pipeline-parallel-size表示并行大小。
1.3 数据集
继续使用huggingface-cli下载数据集
mkdir dataset
cd dataset/
huggingface-cli download tatsu-lab/alpaca –revision main –filename data/train-00000-of-00001-a09b74b3ef9c3b56.parquet
cd ..
处理数据集:
python ./preprocess_data.py \
--input ./dataset/train-00000-of-00001-a09b74b3ef9c3b56.parquet \
--tokenizer-name-or-path ./model_from_hf/cnm/ \
--output-prefix ./dataset/Baichuan2-13B/alpaca \
--workers 4 \
--log-interval 1000 \
--tokenizer-type PretrainedFromHF
1.4 分布式训练
打开examples/legacy/baichuan2/pretrain_baichuan2_ptd_13B.sh完成路径配置:
CKPT_SAVE_DIR="./ckpt/bai2-13b/" #权重保存路径
CKPT_LOAD_DIR="./model_weights/bai2-13-v1" #权重加载路径
TOKENIZER_MODEL="./model_from_hf/cnm/tokenizer.model" #词表路径
DATA_PATH="./dataset/Baichuan2-13B/alpaca_text_document" #数据集路径
另外,分布式训练需要从权重转换到训练、推理TP、PP保持一致,确保 --num-layer-list 中的层数与 --pipeline-model-parallel-size 配置的并行数量一致。即修改脚本中的TP和PP为:TP = 8 PP = 4。
完成后运行:bash examples/legacy/baichuan2/pretrain_baichuan2_ptd_13B.sh即可开启训练,在8×npus上需要训练需花费12个小时左右。
1.5 分布式推理
配置推理脚本examples/legacy/baichuan2/generate_baichuan2_13b_ptd.sh:
CHECKPOINT = “./ckpt/bai2-13-v1/”
TOKENIZER_PATH=”./model_from_hf/cnm/”
并将脚本中的参数--tensor-model-parallel-size 和--pipeline-model-parallel-size 分别设置为8和4,同权重转换的TP、PP切分大小保持一致。
完成后运行:bash examples/legacy/baichuan2/generate_baichuan2_13b_ptd.sh即可开启推理,在线对话。
2 验收材料
2.1 验收说明
本文提供的验收材料按照《Baichuan2开源项目 For Huawei任务规划》任务计划书的要求提供,没有偏离。
2.2 资源清单
|
产品名称 |
芯片类型 |
CANN版本 |
驱动版本 |
操作系统 |
|
堡垒机 |
昇腾910B3 |
CANN 8.0.RC2 |
23.0.6 |
Huawei Cloud EulerOS 2.0 |
2.3 验证截图
(1)权重转换:
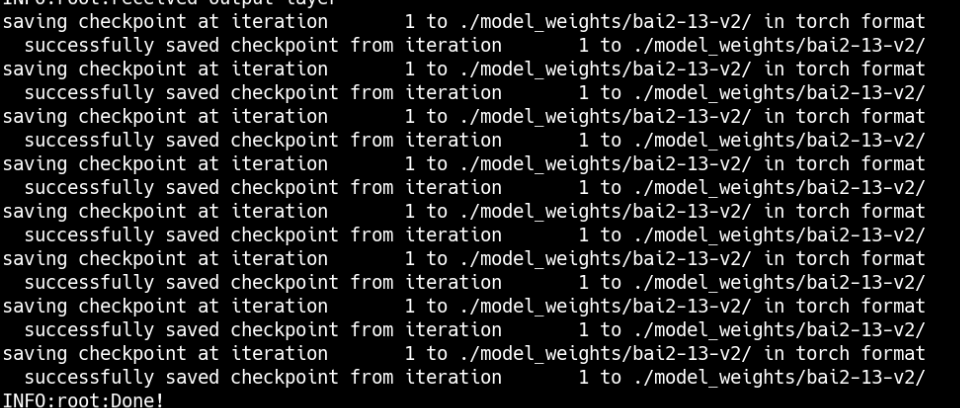
(2)数据集处理:

(3)训练:
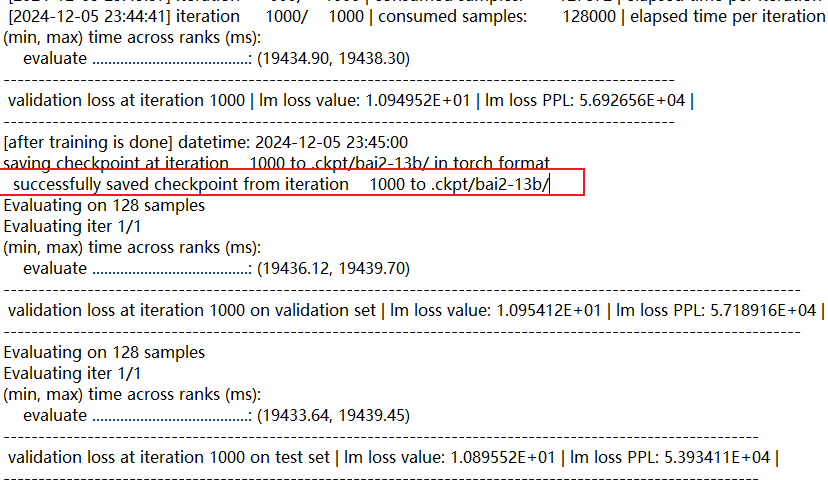
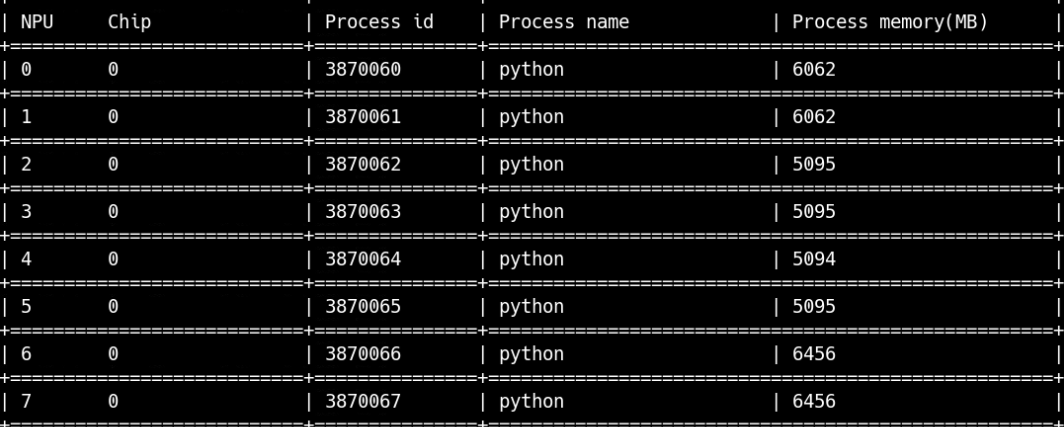
npu运行状态:
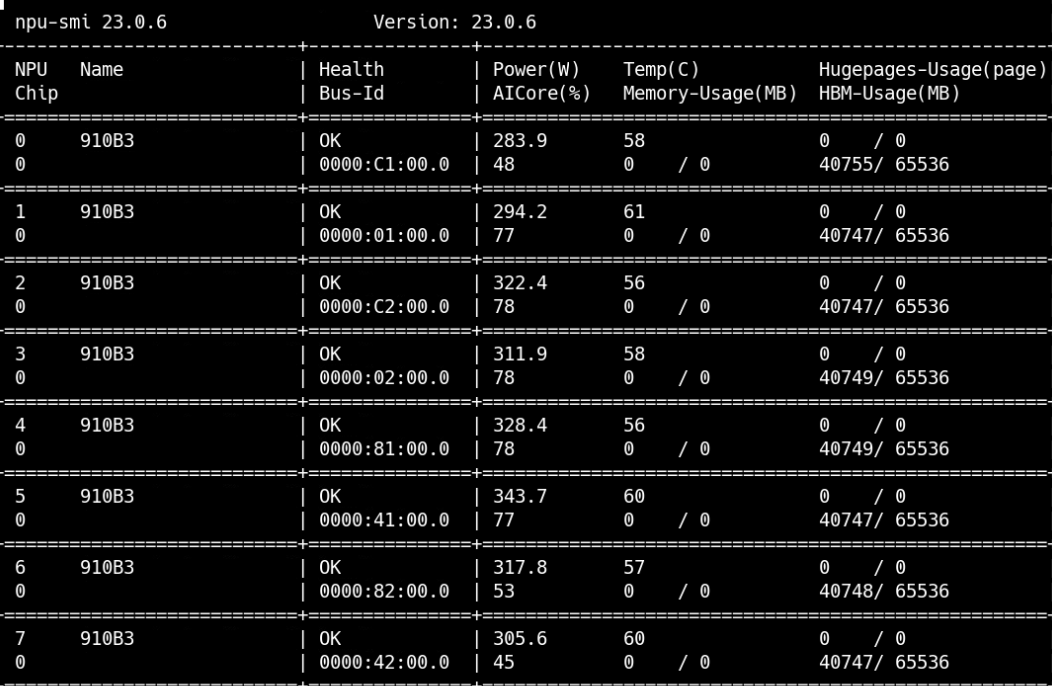
(4)推理:
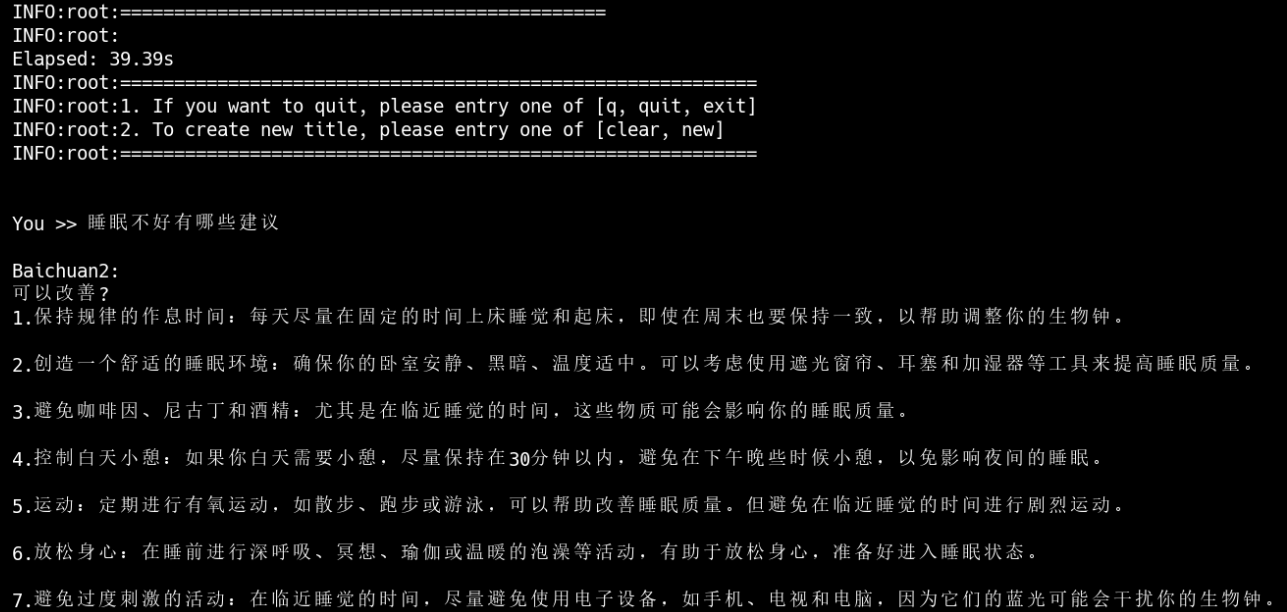
npu运行前:
npu运行后:

- 点赞
- 收藏
- 关注作者
评论(0)