haystack适配昇腾开源验证任务心得

haystack适配昇腾开源验证任务心得
一、任务需求
首先看了一下任务计划书:https://bbs.huaweicloud.cn/blogs/441501 ,主要目的是让haystack能够在Ascend NPU和Kunpeng CPU上高效运行,确保项目在平台上具备良好的兼容性和性能,以显著提高企业的信息检索和问答系统的效率。即验证haystack能不能在 Ascend(昇腾)和 Kunpeng(鲲鹏)处理器中运行。
二、开发过程
明确任务目的和demo要求后,先获取源码,haystack的github网址: https://github.com/deepset-ai/haystack 。官方文档的教程是英文问答,想要获得中文应答对话,要使用1.x版本的代码进行,并对代码进行修改。在https://github.com/mc112611/haystack-chinese 中获取txt.py和preprocess.py文件,然后替换掉1.x原来的这两个文件,然后新建一个test.py文件,输入以下代码:
import os
import logging
import time
logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
logging.getLogger("haystack").setLevel(logging.INFO)
# 写入库
from haystack.document_stores import FAISSDocumentStore
from haystack.pipelines.standard_pipelines import TextIndexingPipeline
#创建库以及索引
document_store = FAISSDocumentStore(faiss_index_factory_str="Flat",embedding_dim=768)
#加载已有的document_store
# document_store = FAISSDocumentStore.load(index_path="wiki_faiss_index.faiss", config_path="wiki_faiss_index.json")
doc_dir = 'F:\MC-PROJECT\CUDA_Preject/test_haystack\wiki\data_test'
# 对文档进行预处理
files_to_index = [doc_dir + "/" + f for f in os.listdir(doc_dir)]
indexing_pipeline = TextIndexingPipeline(document_store)
indexing_pipeline.run_batch(file_paths=files_to_index)
# 查看切分后的文档
# print(document_store.get_all_documents())
from haystack.nodes import EmbeddingRetriever
# 对文档进行中文相似度embedding,并更新faiss库
retriever = EmbeddingRetriever(
document_store=document_store,
embedding_model="shibing624/text2vec-base-chinese",
)
document_store.update_embeddings(retriever)
# 将faiss库索引进行持久化存储
document_store.save(index_path="wiki_faiss_index.faiss")
# 使用中文的QA模型进行问答,对检索出的结果和用户输入的问题,生成回答,该回答基本是言简意赅,这个部分可以替换为大模型解析
from haystack.nodes import FARMReader
reader = FARMReader(model_name_or_path="uer/roberta-base-chinese-extractive-qa", use_gpu=True,context_window_size=300,max_seq_len=512)
from haystack.utils import print_answers
from haystack.pipelines import ExtractiveQAPipeline
# 将检索器,阅读器插入进抽取式问答管道。
pipe = ExtractiveQAPipeline(reader, retriever)
# 提问
while True:
q = input('输入问题吧:')
st_time = time.time()
prediction = pipe.run(
query=q,
params={
"Retriever": {"top_k": 8},
"Reader": {"top_k": 2}
}
)
# 打印结果
# print(prediction)
print_answers(prediction, details="all")
end_time = time.time()
print("计算时间为:{}".format(end_time - st_time))
需要获取数据集,在https://pan.baidu.com/share/init?surl=0HPre8BcaUZDyZ3_wsakMg&pwd=znx6 中获取(解压 1234),然后在源码下新建一个data文件将数据集解压后放入,然后获取两个权重文件,uer/roberta-base-chinese-extractive-qa 和shibing624/text2vec-base-chinese ,在源码下新建一个model,将两个权重加载进去。
1.鲲鹏CPU、OpenEuler 验证推理
(1)安装依赖
首先安装haystack包,pip install farm-haystack[all],运行代码后会报错没有nltk包,在https://pan.baidu.com/share/init?surl=0-qUv_n9yh4MukwcHYuTOA 中(提取码 1234)获取包放在指定位置。
(2)运行推理代码
运行代码之前,先配置nltk_data环境变量,export NLTK_DATA=和nltk包同一路径,然后修改test.py中的3个路径,首先是数据集的路径,需要替换为自己存放数据集的具体位置。

还需要修改两个权重的位置,


修改完成之后就可以运行代码了,python test.py命令云即可。
2.NPU验证推理
(1)安装依赖包
进行NPU推理和鲲鹏CPU一样都在云堡垒机上进行。首先查看云堡垒机上已安装的CANN的版本和python版本,然后根据版本安装配套的torch_npu等,在https://www.hiascend.com/document/detail/zh/Pytorch/60RC3/configandinstg/instg/insg_0001.html,代码和权重和鲲鹏CPU推理一样的操作,然后安装一些必要的依赖。
注:numpy版本建议安装1.23左右的,不要安装2.0及以上的,会有兼容问题。
(2)运行推理代码
进行NPU的推理,在CPU代码的基础上加入3行代码,新建一个test_npu.py文件,复制代码
import torch
import torch_npu
from torch_npu.contrib import transfer_to_npu
这里需要注意的是,每次运行代码在test同目录下会生成
这3个文件,因为document_store会存储文档,所以需要删除。如果想要重新运行,每次运行都需要把这三个文件删除后再运行,否则会报错。然后运行python test_npu.py命令即可。
三、结果
1验证截图
Haystack是一个开源框架,主要用于构建和部署文档搜索引擎和问答系统,测试推理是问答系统,在数据集范围内可以进行问答。
1.1 CPU推理
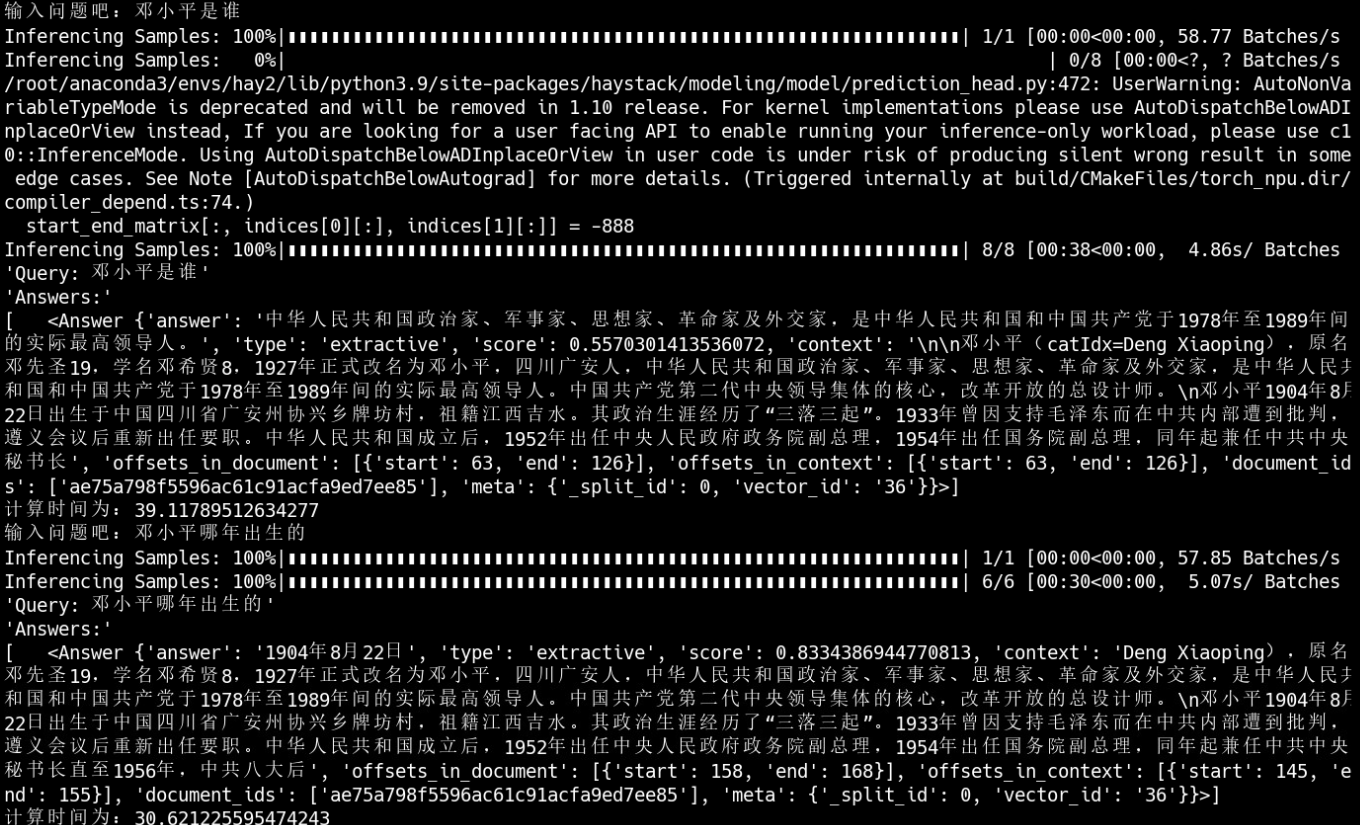
在堡垒机上执行运行命令后,会在终端显示问答模式,然后输入自己想要询问的问题,因为是基于数据集推理的,所以问题必须是数据集中相关的。
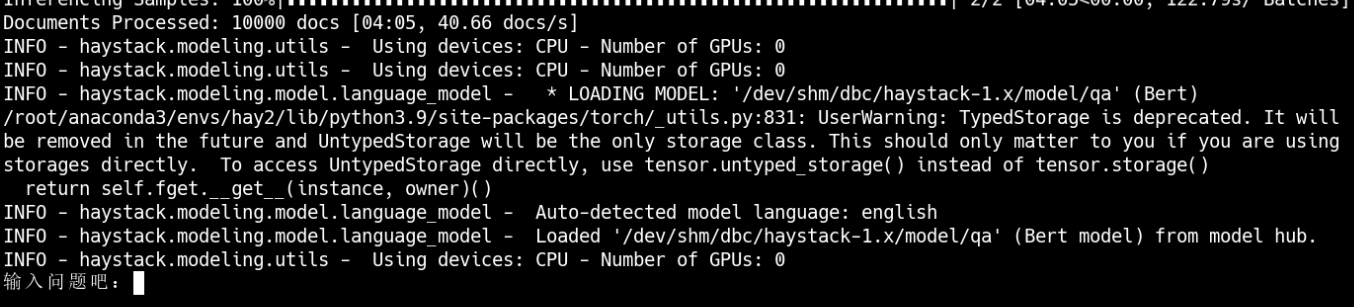
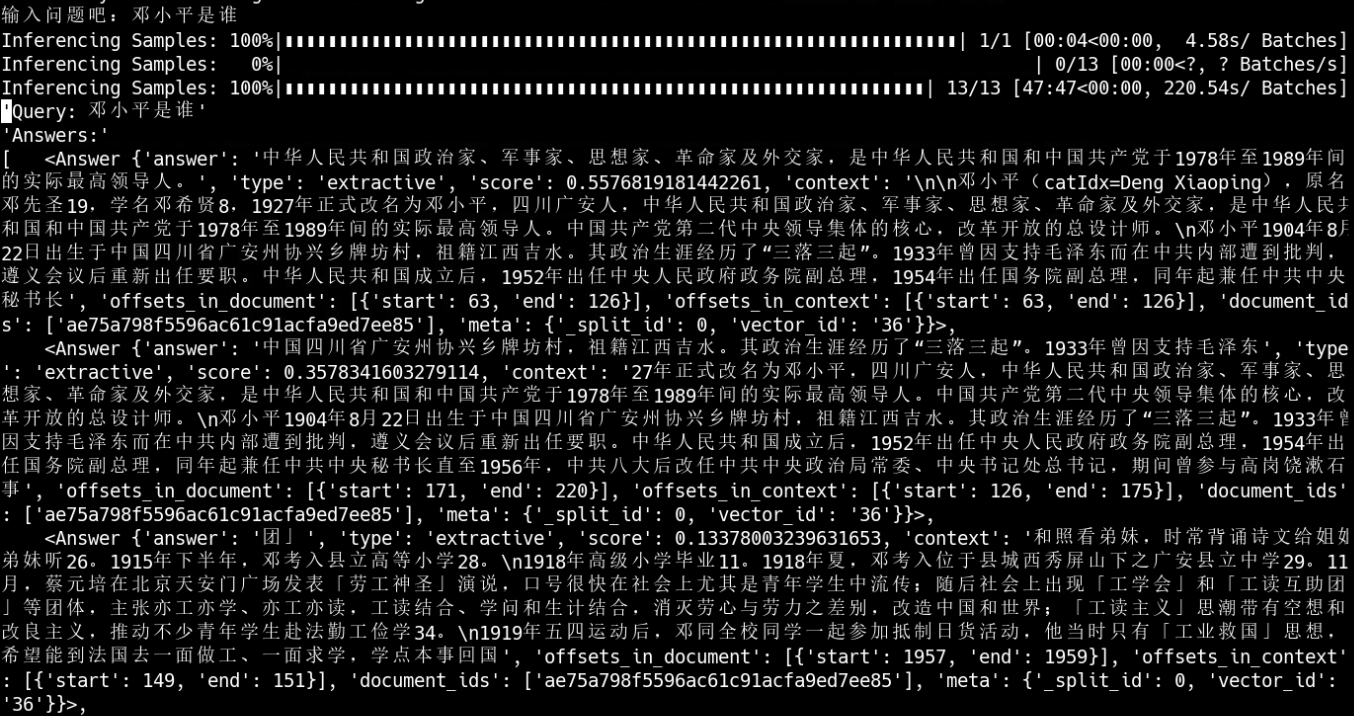
从图中可以看出,使用的是CPU进行推理,然后会进行问题输入,输入问题后会获得推理答案。
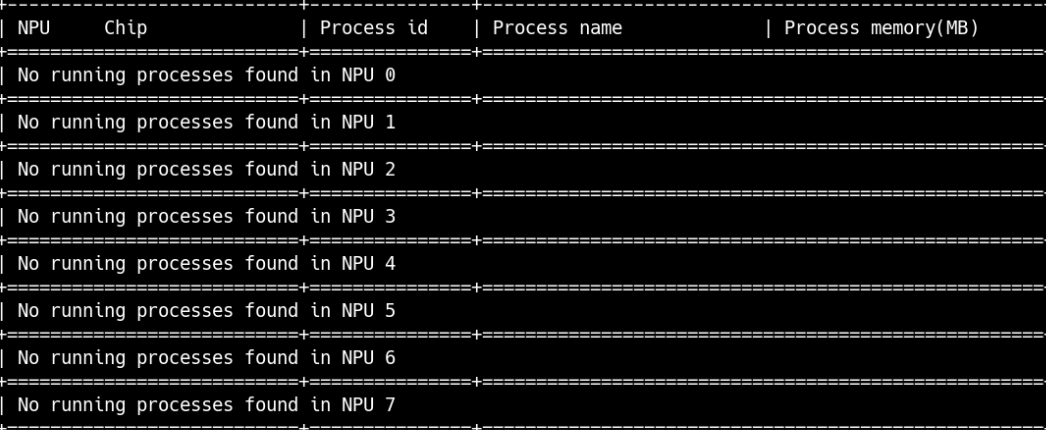
1.2 NPU推理
NPU和CPU推理流程一样,但是需要在运行前后查看一下NPU使用情况,运行程序前
运行程序后
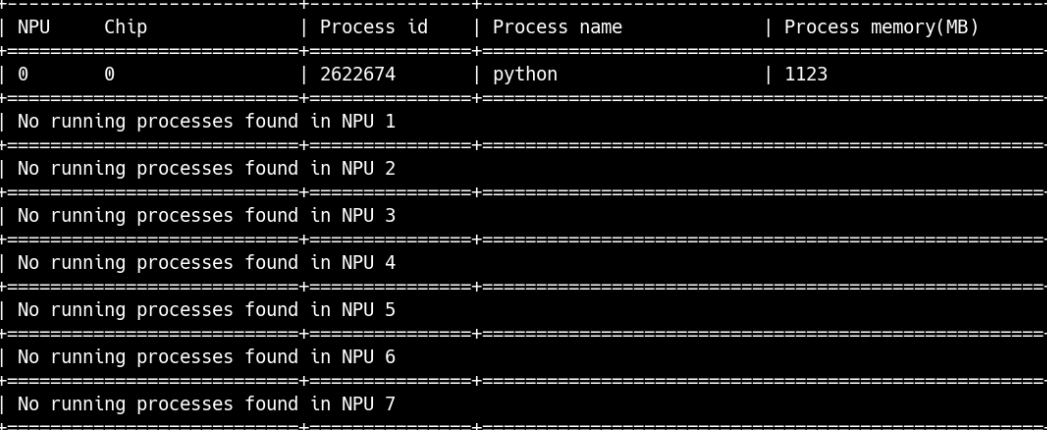
运行之后的结果图为:

- 点赞
- 收藏
- 关注作者
评论(0)