【强化学习】元强化学习(Meta Reinforcement Learning)

📢本篇文章是博主强化学习RL领域学习时,用于个人学习、研究或者欣赏使用,并基于博主对相关等领域的一些理解而记录的学习摘录和笔记,若有不当和侵权之处,指出后将会立即改正,还望谅解。文章分类在👉强化学习专栏:
【强化学习】(6)---《元强化学习(Meta Reinforcement Learning, MRL)》
元强化学习(Meta Reinforcement Learning)
目录
1.元强化学习(Meta Reinforcement Learning, MRL)
基于梯度的元学习(Gradient-based Meta-Learning)
基于递归和记忆的元学习(Memory-based Meta-Learning)
基于概率推断的元学习(Probabilistic Meta-Learning)
1.元强化学习(Meta Reinforcement Learning, MRL)
元强化学习是一种提升智能体适应新任务能力的技术,它让智能体不仅能学习完成当前的任务,还能在面对新的任务或环境时更快地学会新的策略。与传统的强化学习不同,元强化学习关注如何学习得更快、更高效,即学习如何学习。它让智能体在多种任务之间迁移经验,以应对任务变化或环境变化。
核心思想
元强化学习的核心思想是通过一个“元层”对多个任务进行学习和优化。该元层不是直接学习如何执行任务,而是学习如何在给定的任务下快速学会执行该任务的最佳策略。这样,当一个新的任务或环境出现时,智能体能够利用之前的经验,以较少的训练数据和时间快速适应新任务。
元强化学习可以类比为一个学生不仅学会了做数学题(特定任务),还学会了如何快速掌握不同种类的数学题(新任务),从而加快学习新问题的速度。
元强化学习的一个早期开创性工作是 "Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks" (MAML) 这篇文章,发表于2017年,由 Chelsea Finn, Pieter Abbeel, and Sergey Levine 提出。MAML 提出了一种基于梯度的元学习方法,能够让深度学习模型通过少量训练样本快速适应新任务。
这篇文章虽然广泛应用于监督学习和强化学习中,但其核心思想可以被直接应用到元强化学习。具体的文章信息如下:
- 文章标题: Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
- 作者: Chelsea Finn, Pieter Abbeel, Sergey Levine
- 发表年份: 2017
- 链接:
这篇文章中的MAML框架成为了元强化学习的基础方法之一,之后许多元强化学习的研究和技术都是在此基础上进一步发展而来的。
想了解更多也可以阅读下:
虽然"元学习"的概念较早被提出,但元强化学习的现代应用和技术趋势是从类似MAML的方法开始广泛探索和推广的
2.元强化学习的主要方法
-
基于梯度的元学习(Gradient-based Meta-Learning)
基于梯度的元学习是元强化学习中的经典方法之一。其主要思路是通过在多个任务上迭代优化,使得模型能够快速适应新的任务。一个广泛使用的算法是MAML(Model-Agnostic Meta-Learning)。MAML 的目标是通过元训练集优化模型的初始参数,使得这些参数可以通过少量的梯度更新迅速适应新任务。
-
MAML的步骤:
- 元训练阶段:在多个任务上训练模型,通过梯度下降学习一个“好的初始参数”。
- 任务适应阶段:当遇到一个新任务时,利用少量的数据进行几次快速梯度更新,使得模型快速适应新任务。
- 元优化阶段:根据新任务的表现,进一步调整初始参数,使它在未来的任务中能更快适应。
-
示例:假设有一组无人机在进行各种任务(如搜索、救援、侦察),MAML可以帮助无人机群快速适应不同的任务场景。即使面对从未见过的新任务,模型通过少量任务数据进行微调后,也能迅速完成任务。
-
-
基于递归和记忆的元学习(Memory-based Meta-Learning)
该方法主要通过递归神经网络(RNN)或长短时记忆网络(LSTM)来存储和处理任务信息,使智能体能够利用记忆中的经验快速适应新的任务。这种方法通过让模型记住之前的任务历史,并在新任务到来时利用这些记忆来加速学习过程。
- 示例:在动态环境中执行任务的机器人可以通过记住过去的任务和环境变化的模式,迅速适应新环境下的挑战。
-
基于概率推断的元学习(Probabilistic Meta-Learning)
该方法将元学习问题视为一个概率推断问题。模型通过推断任务的分布,学习在不同任务之间的转移。一个著名的算法是PEARL(Probabilistic Embeddings for Actor-Critic RL)。PEARL通过学习任务的潜在表示,使得模型能够在任务之间迁移经验并加速适应新任务。
-
PEARL的特点:
- 任务表示学习:PEARL通过推断每个任务的潜在表示,基于这一表示来推断出如何执行该任务的最佳策略。
- 任务推断与快速适应:模型能够快速推断出新的任务表示,并基于少量新数据进行快速调整。
-
示例:在多个不同城市执行物流任务的无人机集群,可以通过PEARL的任务表示学习,在面对新的城市地形和任务要求时,快速找到高效的飞行和路径规划策略。
-
3.元强化学习的应用
-
机器人控制:元强化学习可以帮助机器人在不同环境或任务中迅速适应。例如,一个机器人在完成工厂内装配任务后,可能需要在新的工厂执行类似但有所不同的任务,元强化学习能让它通过少量数据快速适应新的环境。
-
无人机集群:在无人机智能集群中,元强化学习可以帮助无人机群在不同的任务和地形中快速调整和适应。例如,一组无人机执行森林火灾监控时,当任务从侦察火情转变为协调灭火时,元强化学习能够加快无人机群在新任务中的反应速度。
-
自动驾驶:元强化学习可以用于自动驾驶系统中,帮助车辆在不同道路和交通条件下迅速调整驾驶策略。当车辆从城市道路切换到乡村道路时,元强化学习能够帮助其快速适应新的驾驶环境。
-
游戏AI:在游戏AI中,元强化学习能够帮助游戏智能体快速学习新的关卡或对手策略,从而提升游戏体验和难度调整的适应性。
-
医疗诊断:在医疗AI领域,元强化学习可以帮助诊断系统在面对不同的病患数据时迅速学习新的诊断模型,以适应不同病种或医疗数据的差异。
4.元强化学习的优势和挑战
优势
- 快速适应:元强化学习的最大优势在于能够在新任务或新环境中快速调整模型,以少量的训练数据快速学到新的策略。
- 泛化能力强:通过在多个任务上训练,元强化学习模型具有更强的任务间泛化能力,能够应对从未见过的任务。
- 效率高:与传统强化学习方法相比,元强化学习在面对新任务时减少了大量的试错过程,因而在训练成本上更加高效。
挑战
- 任务分布依赖性:元强化学习依赖于不同任务之间的相关性,若新任务与训练任务差别过大,元强化学习的效果会显著下降。
- 计算开销大:由于元学习涉及多个任务的训练和优化,计算资源的需求较高。
- 模型设计复杂:元强化学习的算法设计和实现相对复杂,特别是在不同领域中的应用需要针对具体问题进行调整。
5.总结
元强化学习通过学习如何更快地学习,提升了模型在新任务中的适应能力。它不仅能够在多个任务之间共享经验,还能够快速适应从未见过的任务,这使得它在无人机集群、自动驾驶、机器人控制等领域具有广泛的应用前景。
[Python] 元学习pytorch实现
以下是一个简单的 元强化学习(Meta Reinforcement Learning, MRL) 实现的示例代码,基于经典的 Model-Agnostic Meta-Learning (MAML) 框架。该代码应用于强化学习环境,如 OpenAI Gym 中的
CartPole环境。这个例子展示了如何实现基于梯度的元学习,用以适应不同的任务(在这个例子中是不同的
CartPole任务变种)。(效果可能一般,简单了解一下元学习)
测试代码
🔥若是代码复现困难或者有问题,欢迎评论区留言;需要以整个项目形式的代码,请在评论区留下您的邮箱📌,以便于及时分享给您(私信难以及时回复)。
[Results] 运行结果
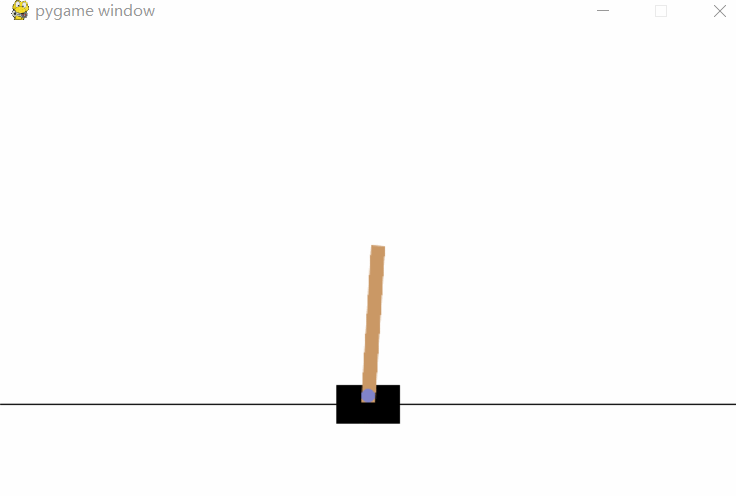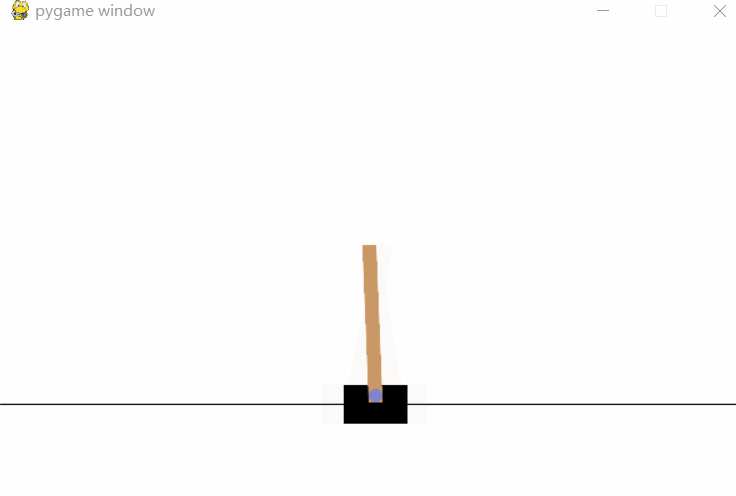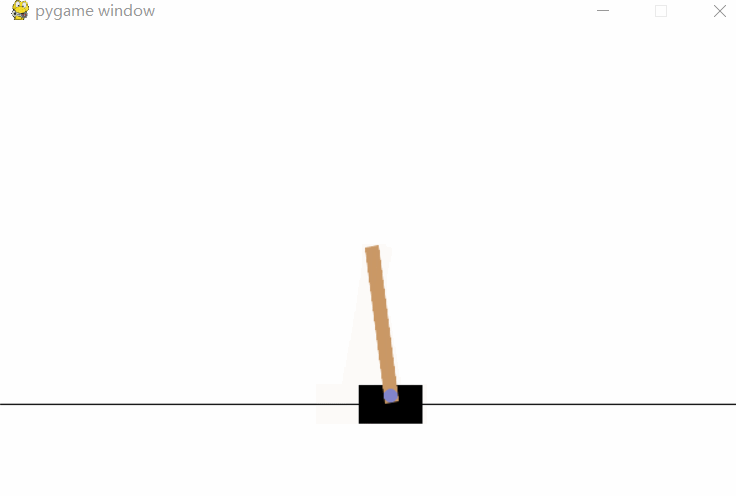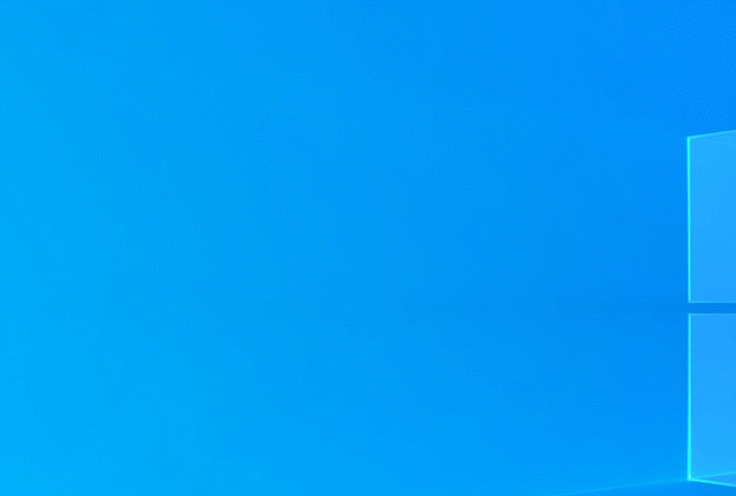
[Notice] 代码说明
训练代码说明
- PolicyNetwork:这是一个简单的三层全连接神经网络,用于决策动作策略。
- select_action:该函数根据当前状态选择动作,使用策略梯度进行动作选择。
- run_episode:执行环境中的一集,记录每一步的日志概率和奖励。
- compute_loss:使用策略梯度方法计算损失函数,包含折扣奖励。
- meta_train:元训练过程,包括多个任务的学习。每个任务都会使用从主模型复制出来的快速策略网络进行任务学习。最后,所有任务的梯度被聚合到一起,更新主模型。
执行流程
- meta_train 函数模拟了多个任务,每个任务基于当前策略模型进行快速学习,并对快速学习的结果计算梯度。这些任务的梯度最终被聚合,用来更新全局的元策略。
- 通过这种方式,元策略可以适应新的任务,并在未来快速适应未见过的新任务。
测试代码说明
-
test_policy函数:该函数用来测试训练好的策略在多个回合中的表现。每个回合由智能体与环境交互,智能体执行动作并观察相应的奖励。 -
渲染环境:调用
env.render()来可视化当前的环境状态。此函数将展示每一步的状态,通常在命令行或窗口中进行动态展示(例如在CartPole环境中,可以看到小车保持平衡的效果)。 -
动作选择:使用训练好的策略网络来选择动作。通过调用
select_action(policy, state)来获得每个状态下的最佳动作。 -
显示结果:在每个回合结束时,打印该回合的总奖励,用于衡量智能体的表现。
执行流程
- 在元训练完成后,你可以运行此测试代码,它将通过可视化的方式展示智能体如何在环境中与任务交互,并展示训练后的策略的效果。
test_policy将执行多个回合(默认5个回合),每个回合执行智能体在环境中的决策,并计算并显示总奖励。
文章若有不当和不正确之处,还望理解与指出。由于部分文字、图片等来源于互联网,无法核实真实出处,如涉及相关争议,请联系博主删除。如有错误、疑问和侵权,欢迎评论留言联系作者,或者添加VX:Rainbook_2,联系作者。✨

- 点赞
- 收藏
- 关注作者
评论(0)