Whisper基于昇腾的环境配置及应用部署心得

一、任务需求
首先了解熟悉任务计划书(https://bbs.huaweicloud.cn/blogs/439894),目的需求是将 Whisper 项目适配至华为的 Ascend(昇腾)和 Kunpeng(鲲鹏)处理器,确保模型能在这些硬件平台上的高效运行,需要注意系统架构是aarch64。
二、过程
明确需求后开始熟悉模型,了解其需要的配置和环境要求
拉取镜像,参考http://mirrors.cn-central-221.ovaijisuan.com/detail/143.html;此镜像torch和torch_npu版本为2.1,需升级到2.2,pip install 安装升级版本
- docker环境:
Python版本:3.9
torch和torch_npu:2.2
CANN版本:8.0.RC2
CPU:kupeng-920
操作系统版本:Euler2.0(SP8)
NPU:Ascend 910B3
在github上gitclone项目代码(https://github.com/openai/whisper);可以提前在魔塔或者huggingface社区手动下载好预训练模型,也可推理时运行测试文件自动下载。本文采用了自动下载。
创建容器并进入容器(进如前把测试代码文件传输进docker的某个路径下,测试文件包含音频文件和test.py文件)
具体步骤:
使用yum更新下环境包:yum update -y
#编译安装yasm
mkdir -p ~/yasm_sources
cd ~/yasm_sources
curl -LO https://www.tortall.net/projects/yasm/releases/yasm-1.3.0.tar.gz
tar -xzf yasm-1.3.0.tar.gz
cd yasm-1.3.0
./configure
make
sudo make install
#安装相关依赖
sudo yum install -y gcc gcc-c++ make cmake git pkg-config libtool automake autoconf nasm
# 下载并编译 x264:
mkdir -p ~/ffmpeg_sources
cd ~/ffmpeg_sources
git clone https://code.videolan.org/videolan/x264.git
cd x264
./configure --enable-shared --enable-pic
make
sudo make install
export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig:$PKG_CONFIG_PATH
pkg-config --libs x264
find /usr/local/lib /usr/lib -name "libx264.so.164"
echo "/usr/local/lib" | sudo tee /etc/ld.so.conf.d/x264.conf
sudo ldconfig
#下载和编译 ffmpeg
mkdir -p ~/ffmpeg_sources
cd ~/ffmpeg_sources
git clone https://git.ffmpeg.org/ffmpeg.git ffmpeg
cd ffmpeg
./configure --enable-gpl --enable-nonfree --enable-libx264
make
sudo make install
修改推理代码:
进入源文件whisper/whisper/__init__目录下,在load_model函数下指定npu(需要在一开始导入import torch_npu)
device = 'npu:0'
torch_npu.npu.set_device(device)
print('===== load medel =====', device)
重新进入源文件whisper内,安装相关环境
pip install .
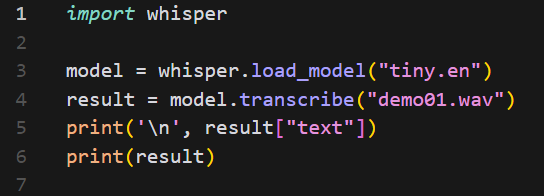
进入测试文件夹,运行test.py,可使用不同模型,即可得到推理结果
------------------------------------------------------------------------------------------------------------------
昇腾NPU和鲲鹏CPU部署整体过程类似,NPU需要将cpu核心换成npu,运行时可能会提醒缺少相关依赖,根据提示安装即可
三、结果
使用whisper进行语音转文本
短文本结果
长文本结果
npu运行结果

四、心得
- 系统是arrch64架构,不同于常见的x86,很多配置没有相应版本需要重新编译。
- 昇腾官网有公开的镜像可以直接用,但是具体的版本需要甄别,镜像内所涵盖的torch版本不一定满足需求,可编写脚本重复使用。
- whisper官方建议给的torch版本是1.11,但是2.2也可以,2.1反而不行。官方给的环境在昇腾下跑不起来,需要多装别的依赖,直接安装ffmpeg会报错。
- Whisper 不直接支持.m4a 格式的音频文件,它主要支持 .wav、.mp3、.flac 等常见格式,可根据需要用ffmpeg转换格式。ffmpeg -i input.m4a output.wav #确保原始文件路径和输出文件路径正确
- 国外模型网站不是经常能访问到,有需要可设置国内镜像源。

- 点赞
- 收藏
- 关注作者
评论(0)