StableDiffusionXL粘土风格图生图

黏土画风太火了!以至于我打开社交媒体平台大家都在晒,我自助用Stable Diffusion也做了几个好有趣的黏土风格,快来看看吧!


我用AI生成的帅哥来试试,丑萌丑萌的挺好玩的,再看看穿旗袍的美女!

用户只需上传一张个人照片,即可借助AI技术变成有趣的黏土动画风格图像,这种风格的反差感迅速吸引了大家的注意。
在社交媒体如小红书、微博、抖音及朋友圈中,这个应用的黏土风格作品风靡一时,各种吃瓜群众的评价是“丑得迷人”,“超级可爱”,相关帖子热的发烫。
怎么做自己的黏土动画风格图像?今天我介绍一个StableDiffusionXL粘土风格图生图案例,欢迎大家来ModelArts体验
1 实验介绍
本实验基于云原生Notebook,使用Stable Diffusion作为基础模型,并结合Lora、ControlNet等模型,让开发者可以基于自己的图片快速生成粘土风格的图片。Stable diffusion是一个基于Latent Diffusion Models(潜在扩散模型,LDMs)的文图生成模型,可以根据输入文字图片等条件,快速生成新的图片。ControlNet是一个控制预训练图像扩散模型(例如 Stable Diffusion)的神经网络。它允许输入调节图像,然后使用该调节图像来操控图像生成。Lora是一种用于微调大模型的技术,可以用于控制图片生成的风格。Stable Diffusion与Lora、ControlNet相结合,就可以基于原始的图片,生成和原始图片背景人物相似的粘土风格图片
2 实验目的
本实验所有操作都基于华为云 ModelArts平台CodeLab,通过本实验,用户能够掌握在ModelArts云上开发环境中进行代码开发与调测。
实验资源一旦购买就开始计费,请合理安排时间进行实验,并注意以下几点:
- 本实验预计 30 分钟完成,实验结束后请一定释放资源;
- 若实验中途离开或中断,建议释放实验资源,否则将会按照购买的资源继续计费;
- 资源释放步骤请根据实验指导进行。
3 前提条件
本实验需在华为云上进行,所以用户需要使用华为云账号进行登录;没有华为云账号的用户请先注册华为云账号并完成实名认证,实验过程中请使用 Chrome浏览器完成相关操作。
华为云账号注册步骤请参考:
https://support.huaweicloud.cn/intl/zh-cn/usermanual-account/account_id_001.html
实名认证操作步骤请参考:
https://support.huaweicloud.cn/intl/zh-cn/usermanual-account/zh-cn_topic_0119621533.html
4 操作指导
4.1 案例说明
1.本案例使用环境: Python 3.9.15
2.本案例使用硬件: [限时免费]GPU:1*P100|CPU:8核64GB (新版本界面显示为[限时免费]GPU: 1*Pnt1|CPU: 8核 64GB)
3.运行代码方法: 点击代码块之前的三角形运行按钮、本页面顶部菜单栏的三角形运行按钮或按Ctrl+Enter键 运行每个方块中的代码
4.JupyterLab的详细用法:请参考《ModelAtrs JupyterLab使用指导》
5.碰到问题的解决办法: 请参考《ModelAtrs JupyterLab常见问题解决办法》
4.2 进入开发环境
打开StableDiffusionXL粘土风格图生图案例,网址如下:https://pangu.huaweicloud.cn/gallery/asset-detail.html?id=f35e04de-997a-43dc-81ff-4c8219318b60,点击页面右侧按钮ModelArts中运行,进入开发环境。
4.3 连接资源
跳转到Notebook开发环境,需要等待一会儿,如果出现弹窗点击确定,等待右上角连接中倒计时结束并初始化完成,提示剩余时间即可。
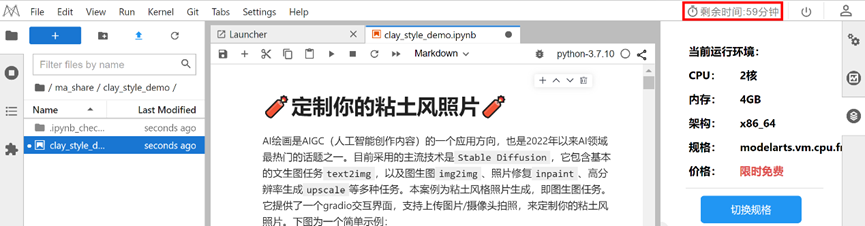
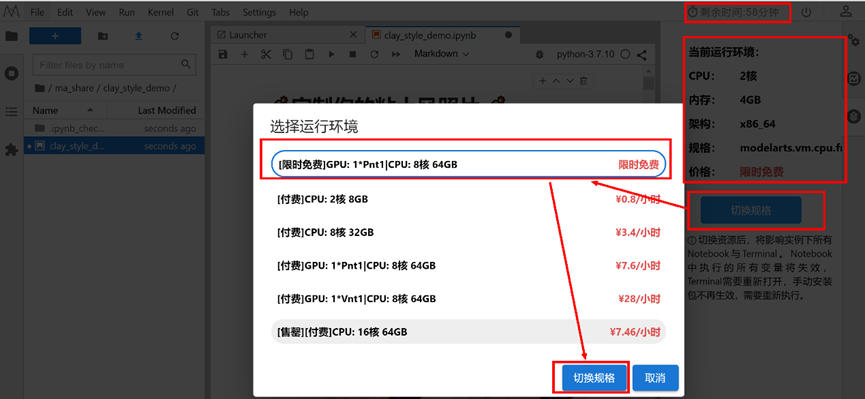
4.4 切换资源规格
进入notebook页面,默认是CPU规格资源,需要手动将资源切换为【限时免费】的GPU规格资源
注:如若免费的GPU规格资源售罄,您可以等待,或使用收费的GPU规格资源。
4.5 环境准备
步骤1 下载模型权重和代码
鼠标往下滚动页面到步骤1 下载模型权重和代码,开始运行代码,运行需要一段时间;
首先确认使用的镜像为python-3.7.10(右上角所示),如不是,可以点击此处切换为python-3.7.10。
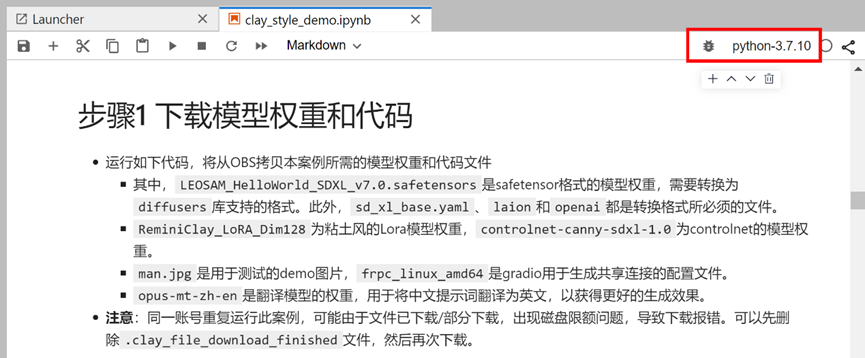
再依次运行步骤1、步骤2的每个cell,点击每处代码左侧三角形逐个运行即可。
import os
import moxing as mox
def remove_clay_files():
work_dir = "/home/ma-user/work/ma_share/clay_style_demo"
exclude_file = "clay_style_demo.ipynb"
os.system(command=f"cd {work_dir} && rm -rf $(ls {work_dir} | grep -v {exclude_file})")
if os.path.exists(".clay_file_download_finished"):
print("Files Already Downloaded.")
print("You can run `rm -f .clay_file_download_finished`, then redownload files.")
else:
remove_clay_files()
for f in [
"LEOSAM_HelloWorld_SDXL_v7.0.safetensors",
"convert_original_stable_diffusion_to_diffusers.py",
"sd_xl_base.yaml", "laion", "openai",
"ReminiClay_LoRA_Dim128",
"controlnet-canny-sdxl-1.0",
"man.jpg", "frpc_linux_amd64",
"opus-mt-zh-en"
]:
mox.file.copy_parallel(f"obs://modelarts-labs-bj4-v2/case_zoo/clay_style_demo/{f}", f)
os.system(command="touch .clay_file_download_finished")
注:此处出现红色不用关心,属于提示信息。
步骤2 准备推理环境
1. conda虚拟环境
- 本案例需要
Python3.9以上版本,因此需要先创建conda虚拟环境,然后将notebook的kernel切换为Python3.9,再执行后续代码
- 运行如下代码,将创建名为
python-3.9.15的虚拟环境,并为其安装ipykernel:!/home/ma-user/anaconda3/bin/conda clean -i !/home/ma-user/anaconda3/bin/conda create -n python-3.9.15 python=3.9.15 -y --override-channels --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main !/home/ma-user/anaconda3/envs/python-3.9.15/bin/pip install ipykernelimport json import os PYTHON_VERSION="3.9.15" PATH=os.environ.get("PATH") data = { "display_name": f"python-{PYTHON_VERSION}", "env": { "PATH": f"/home/ma-user/anaconda3/envs/python-{PYTHON_VERSION}/bin:/home/ma-user/anaconda3/envs/python-3.7.10/bin:/home/ma-user/anaconda3/envs/PyTorch-1.8/bin:/usr/local/openmpi/bin:/usr/local/nvidia/bin:/usr/local/cuda/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/modelarts/authoring/notebook-conda/bin:/home/ma-user/modelarts-dev/ma-cli/bin:/modelarts/authoring/script/entrypoint/deps/ssh/bin" }, "language": "python", "argv": [ f"/home/ma-user/anaconda3/envs/python-{PYTHON_VERSION}/bin/python", "-m", "ipykernel", "-f", "{connection_file}" ] } jupyter_kernel_dir = f"/home/ma-user/anaconda3/share/jupyter/kernels/python-{PYTHON_VERSION}" if not os.path.exists(jupyter_kernel_dir): os.mkdir(jupyter_kernel_dir) with open(os.path.join(jupyter_kernel_dir, "kernel.json"), "w") as f: json.dump(data, f, indent=4)

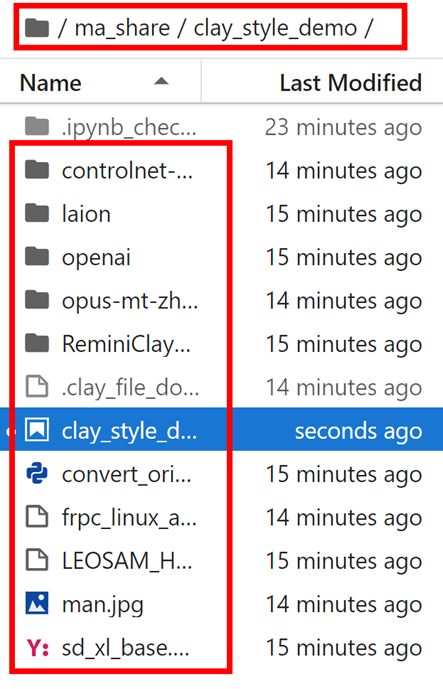
通过环境准备,我们安装了本次案例所需要依赖库,并下载案例所需文件到“/home/ma-user/work/ma_share/clay_style_demo”目录中,即当前目录,可以点击界面左侧的文件夹按钮查看。
4.6 切换镜像
完成上述步骤后,稍等片刻,或刷新页面,点击右上角kernel选择python-3.9.15(有时候会出现在左上角,同样操作即可)。
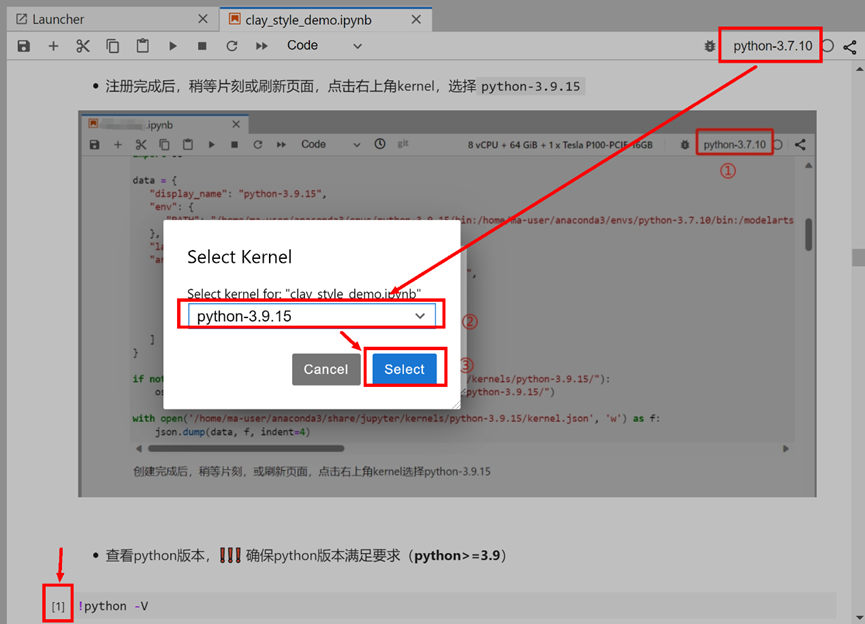
切换完成后,可以继续运行下方代码,查看切换后的Python版本
!python -V
Python 3.9.154.7 安装依赖库
运行2章节安装运行依赖环境,并拷贝gradio共享链接的配置文件。
!cp ./frpc_linux_amd64 /home/ma-user/anaconda3/envs/python-3.9.15/lib/python3.9/site-packages/gradio/frpc_linux_amd64_v0.2
!chmod +x /home/ma-user/anaconda3/envs/python-3.9.15/lib/python3.9/site-packages/gradio/frpc_linux_amd64_v0.2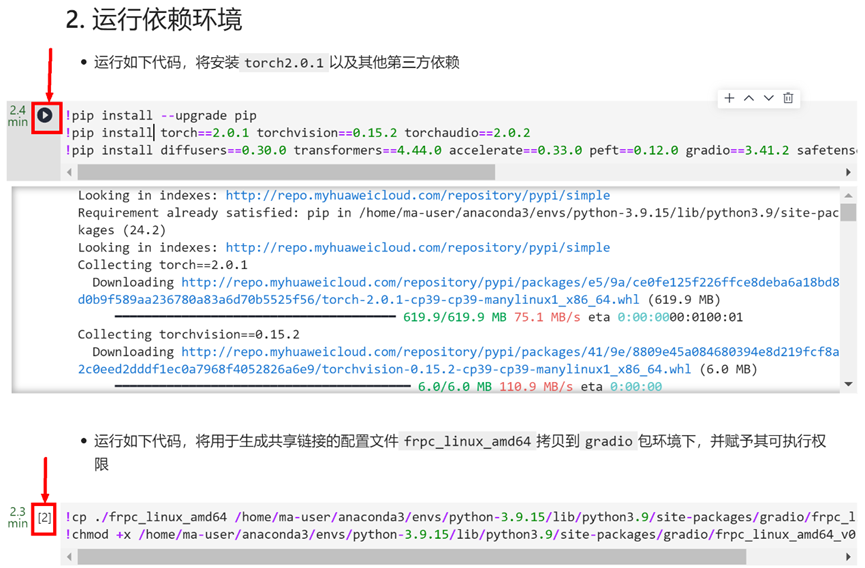
4.8 功能测试
4.8.1 模型权重转换
继续步骤3代码,进行模型权重转换,用于后续模型加载。
!python convert_original_stable_diffusion_to_diffusers.py \
--checkpoint_path LEOSAM_HelloWorld_SDXL_v7.0.safetensors \
--original_config_file sd_xl_base.yaml \
--dump_path LEOSAM_HelloWorld_SDXL_v7.0 \
--from_safetensors \
--to_safetensors
!echo "Convert Success!"
4.8.2 本地测试
继续运行下方代码,本地测试粘土风格图片的生成
from PIL import Image
import torch
from diffusers import StableDiffusionXLImg2ImgPipeline
import matplotlib.pyplot as plt
%matplotlib inline
model_id = "LEOSAM_HelloWorld_SDXL_v7.0"
pipe = StableDiffusionXLImg2ImgPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
device = "cuda"
pipe = pipe.to(device)
pipe.load_lora_weights("ReminiClay_LoRA_Dim128",
weight_name="ReminiClay_SDXL_LoRA_Dim128.safetensors",
adapter_name="clay")
init_image = Image.open('man.jpg').convert("RGB")
prompt = "Clay World,best quality,masterpiece,real"
negative_prompt = "bad hand,bad anatomy,worst quality,ai generated images,low quality,average quality,bad eye"
generator = torch.Generator(device=device).manual_seed(0)
image = pipe(prompt=prompt,
image=init_image,
negative_prompt=negative_prompt,
generator=generator,
num_inference_steps=20,
strength=0.5, guidance_scale=7,
).images[0]
plt.axis("off")
plt.imshow(image)
image.save("demo.jpg")
# free GPU for running gradio_demo.py
del pipe
torch.cuda.empty_cache()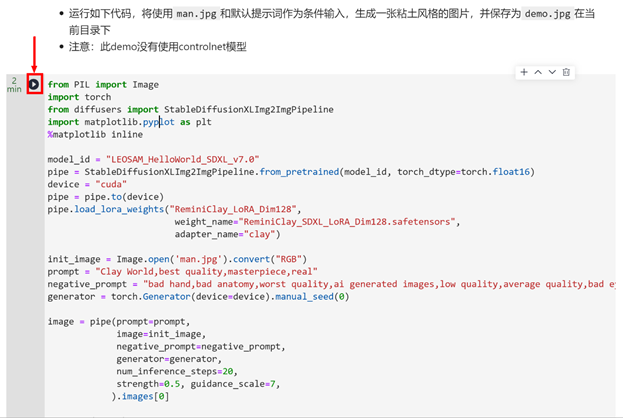
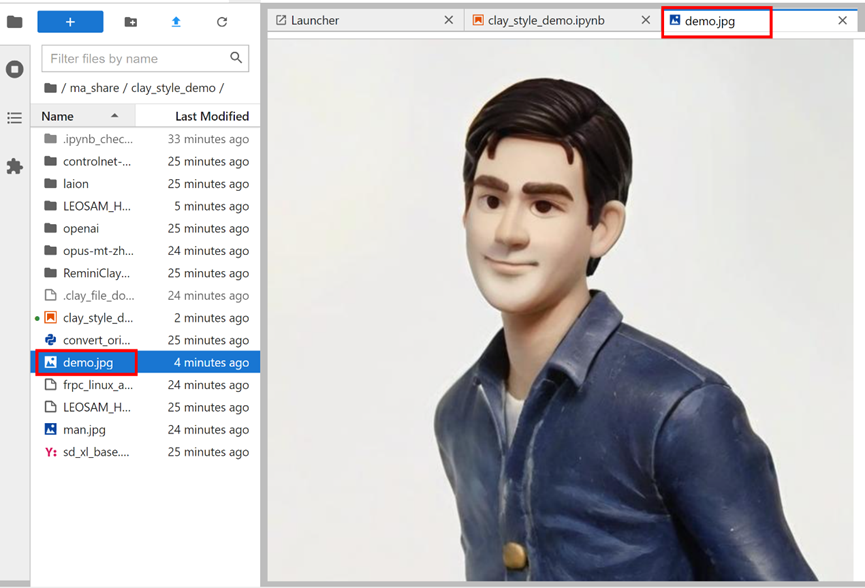
生成的图片,位于左侧文件夹内,可以双击打开查看:
4.8.3 gradio测试
继续运行下方代码,先生成gradio交互代码文件
%%writefile gradio_demo.py
import random
import re
import gradio as gr
import numpy as np
import torch
from controlnet_aux import CannyDetector
from PIL import Image
from diffusers import (ControlNetModel,
StableDiffusionXLControlNetImg2ImgPipeline,
UniPCMultistepScheduler)
def preprocess_images(input_image: Image, resolution: int=512) -> Image:
H = input_image.height
W = input_image.width
ratio = float(resolution) / min(H, W)
H_resize = int(round(H * ratio / 64)) * 64
W_resize = int(round(W * ratio / 64)) * 64
image = input_image.resize((W_resize, H_resize), Image.LANCZOS)
return image
@torch.inference_mode()
def sample(init_image: Image,
prompt: str, negative_prompt: str,
seed: int, strength: float, guidance_scale: float, num_inference_steps: int,
lora_scale: float, controlnet_scale: float, controlnet_start: float, controlnet_end: float,
):
global MAX_SEED, DEVICE, PIPELINE
if seed == -1:
seed = random.randint(0, MAX_SEED)
generator = torch.Generator(device=DEVICE).manual_seed(seed)
init_image = preprocess_images(init_image)
canny_image = CannyDetector()(init_image)
if 0.0 < lora_scale <= 1.0:
PIPELINE.enable_lora()
cross_attention_kwargs = {"scale": lora_scale}
else:
PIPELINE.disable_lora()
cross_attention_kwargs = {} # scale does not work, after `disable_lora`
image = PIPELINE(image=init_image,
prompt=prompt, negative_prompt=negative_prompt,
control_image=canny_image,
controlnet_conditioning_scale=controlnet_scale,
control_guidance_start=controlnet_start,
control_guidance_end=controlnet_end,
generator=generator,
strength=strength,
guidance_scale=guidance_scale,
num_inference_steps=num_inference_steps,
cross_attention_kwargs=cross_attention_kwargs,
).images[0]
# torch.cuda.empty_cache() # IMPORTANT for OOM
return image, seed
@torch.inference_mode()
def translate_zh2en(source: str):
if not source: return ""
global TRANSLATOR, DEVICE
if "TRANSLATOR" not in globals():
import transformers
TRANSLATOR = transformers.pipeline(task="translation", model="opus-mt-zh-en",
device=DEVICE)
regex_content = re.compile(r'([\u4e00-\u9fa5,?!。]+)(.*)')
match_results_list = [] # [(english, chinese), (...)]
current_source = source
while True:
match = regex_content.search(current_source)
if not match: # current_source = "" or "only_english_words"
if current_source:
match_results_list.append([current_source, ""])
break
if match.start() > 0:
english_words = "".join(list(current_source)[:match.start()])
else:
english_words = ""
match_results_list.append([english_words, match.group(1)])
current_source = match.group(2)
translate_results = []
for english_words, chinese_words in match_results_list:
if english_words != "":
translate_results.append(english_words.strip(','))
if chinese_words == "" or chinese_words == ",":
continue
target = TRANSLATOR(chinese_words)[0].get("translation_text")
translate_results.append(target.rstrip("."))
return ",".join(translate_results) + "."
MAX_SEED = np.iinfo(np.int32).max
IMAGE_HEIGHT = 512
with gr.Blocks() as gui_demo:
gr.HTML("""<h1 align="center">粘土风格图生图</h1>""")
with gr.Accordion("帮助文档", open=False):
gr.Markdown(
"""
# 模型信息
- 基础模型:LEOSAM_HelloWorld_SDXL_v7.0
- Lora模型:ReminiClay_LoRA_Dim128
- controlnet模型:controlnet-canny-sdxl-1.0
# 功能说明
- 输入图片,支持上传/摄像头拍照
- 正/负面提示词支持中英文混用,并返回提示词的翻译结果
- 注意:在当前英文提示词后面,直接添加中文即可,否则中英混翻不准确
# 参数说明
1. prompt:建议给短语而非长句,negative-prompt同理,可参考默认值
2. negative-prompt:如果生成的图片中有您看到不想要的内容,请将其置于负提示词中
3. seed:值为-1表示随机生成,并返回当前随机种子,方便复现结果
4. strength:表示降噪强度,值越大生成图片与输入图片关联性越弱
5. guidance-scale:生成的图像与提示词的紧密程度,值越大与提示词关联性越强
6. inference-steps:扩散步数,值越大耗时越久图片越精细,反之越粗糙
7. lora-scale:控制LoRA模型对生成图片的影响程度,值为0表示不使用Lora模型
8. 注意:controlnet参数,controlnet-end不得小于或等于controlnet-start
""")
with gr.Tab("upload"):
with gr.Row():
init_image_upload = gr.Image(source="upload", type="pil", image_mode="RGB", height=IMAGE_HEIGHT)
result_upload = gr.Image(label="result", show_label=True, height=IMAGE_HEIGHT)
run_button_upload = gr.Button("生成", scale=0, size="lg")
with gr.Tab("camera"):
with gr.Row():
init_image_camera = gr.Image(source="webcam", type="pil", image_mode="RGB", height=IMAGE_HEIGHT)
result_camera = gr.Image(label="result", show_label=True, height=IMAGE_HEIGHT)
run_button_camera = gr.Button("生成", scale=0, size="lg")
with gr.Accordion("更多参数", open=True):
with gr.Row():
prompt = gr.Textbox(label="prompt", max_lines=1,
value="Clay World,best quality,masterpiece,real")
translate_button_prompt = gr.Button("翻译", scale=0, size="lg")
with gr.Row():
# negative_prompt reference: https://www.liblib.art/modelinfo/506c46c91b294710940bd4b183f3ecd7
negative_prompt = gr.Textbox(label="negative prompt", max_lines=1,
value="bad hand,bad anatomy,worst quality,ai generated images,low quality,average quality,bad eye")
translate_button_neg_prompt = gr.Button("翻译", scale=0, size="lg")
with gr.Row():
seed = gr.Slider(
label="seed",
minimum=-1, maximum=MAX_SEED, step=1, value=0,
)
strength = gr.Slider(
label="strength",
minimum=0.0, maximum=1.0, step=0.01, value=0.45,
)
guidance_scale = gr.Slider(
label="guidance scale",
minimum=0.0, maximum=10.0, step=0.1, value=7,
)
num_inference_steps = gr.Slider(
label="inference steps",
minimum=1, maximum=50, step=1, value=20,
)
with gr.Row():
lora_scale = gr.Slider(
label="lora scale",
minimum=0.0, maximum=1.0, step=0.01, value=1.0,
)
controlnet_scale = gr.Slider(
label="controlnet scale",
minimum=0.01, maximum=1.0, step=0.01, value=0.5,
)
controlnet_start = gr.Slider(
label="controlnet start",
minimum=0.0, maximum=1.0, step=0.01, value=0.0,
)
controlnet_end = gr.Slider(
label="controlnet end",
minimum=0.01, maximum=1.0, step=0.01, value=0.8,
)
run_button_upload.click(
fn=sample,
inputs=[init_image_upload, prompt, negative_prompt, seed, strength, guidance_scale, num_inference_steps, lora_scale, controlnet_scale, controlnet_start, controlnet_end],
outputs=[result_upload, seed],
queue=False
)
run_button_camera.click(
fn=sample,
inputs=[init_image_camera, prompt, negative_prompt, seed, strength, guidance_scale, num_inference_steps, lora_scale, controlnet_scale, controlnet_start, controlnet_end],
outputs=[result_camera, seed],
queue=False
)
translate_button_prompt.click(fn=translate_zh2en, inputs=[prompt], outputs=[prompt], queue=False)
translate_button_neg_prompt.click(fn=translate_zh2en, inputs=[negative_prompt], outputs=[negative_prompt], queue=False)
def memory_efficient_pipeline():
global PIPELINE
# PIPELINE.enable_vae_slicing() # batch
# PIPELINE.enable_vae_tiling()
PIPELINE.enable_xformers_memory_efficient_attention()
# PIPELINE.enable_model_cpu_offload() # 2G, inference-slow
if __name__ == "__main__":
DEVICE = "cuda"
model_id = "LEOSAM_HelloWorld_SDXL_v7.0"
PIPELINE = StableDiffusionXLControlNetImg2ImgPipeline.from_pretrained(
model_id, torch_dtype=torch.float16,
controlnet=ControlNetModel.from_pretrained(
"controlnet-canny-sdxl-1.0", torch_dtype=torch.float16)
)
PIPELINE.scheduler = UniPCMultistepScheduler.from_config(PIPELINE.scheduler.config)
PIPELINE = PIPELINE.to(DEVICE)
PIPELINE.load_lora_weights("ReminiClay_LoRA_Dim128",
weight_name="ReminiClay_SDXL_LoRA_Dim128.safetensors",
adapter_name="clay")
memory_efficient_pipeline()
gui_demo.launch(share=True)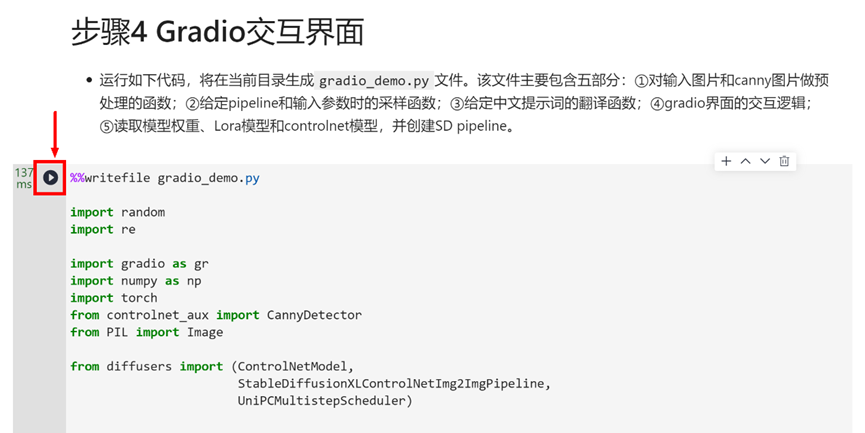
接着继续往下运行,点击Running on public URL后面的链接,即可打开gradio交互界面
!python gradio_demo.py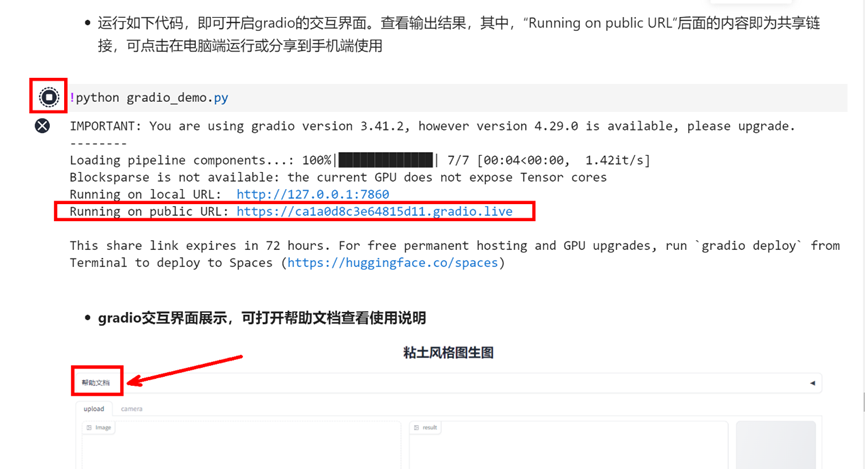
具体gradio交互界面如何使用,可以查看界面的帮助文档,同时案例的最后也给出了相关的示例。
🧨使用示例参考🧨
粘土风格生成提示
| 相关参数 | 描述 | |
|---|---|---|
| LoRA模型 | lora scale |
使得生成的人物更贴近粘土风格 |
| ControlNet模型 | controlnet scale |
使得生成的人物衣物、动作更贴合输入图片 |
| 基础模型 | strength |
值越接近1,生成的人物更贴合提示词,而远离输入图片 |
| 正/负提示词 | prompt、negative_prompt |
推荐使用英文提示词,推荐使用短语而非长句 |
| 随机种子 | seed |
当生成图片不符合预期可以调整参数或改变随机种子 |
❗❗❗ 推荐使用默认参数直接生成,不符合预期可以优先改变随机种子,然后再调整参数
❗❗❗ 下面我们将以三张不同的输入图片为例,展示如何使用粘土风格生成,并分别给出原图(左)、默认参数下(中)和修改参数后(右)的生成图片对比。
示例一
-
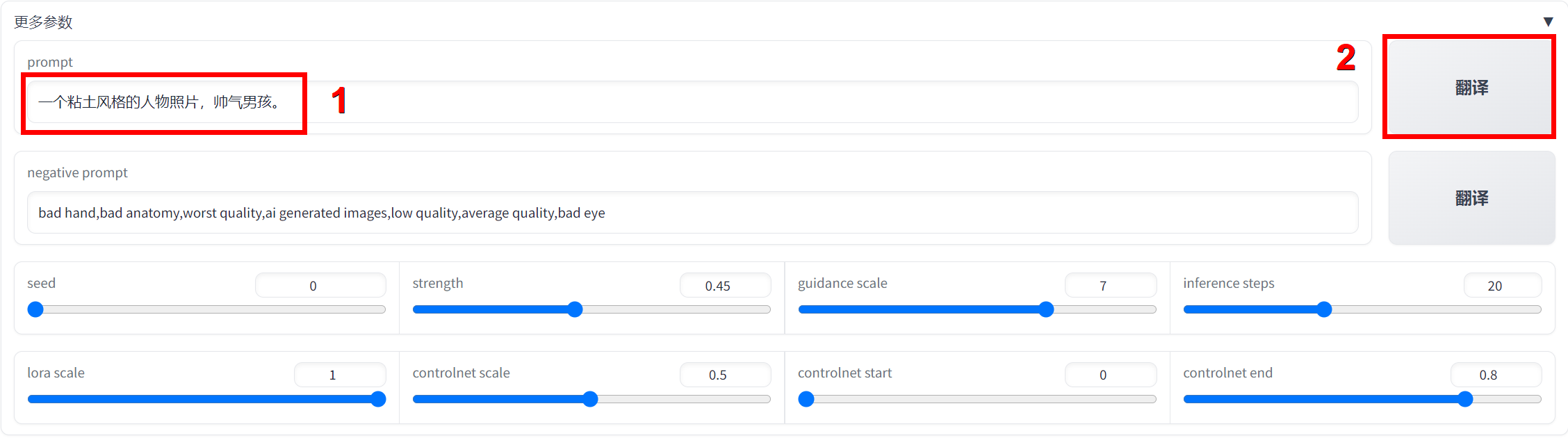
输入
一个粘土风格的人物照片,帅气男孩。,点击翻译,得到提示词翻译结果A clay-style photo of people, handsome boy.,点击生成。 -
注意:可以在英文提示词基础上,追加中文提示词,再点击翻译。
 原图 |
 默认参数 |
 修改参数后 |
示例二
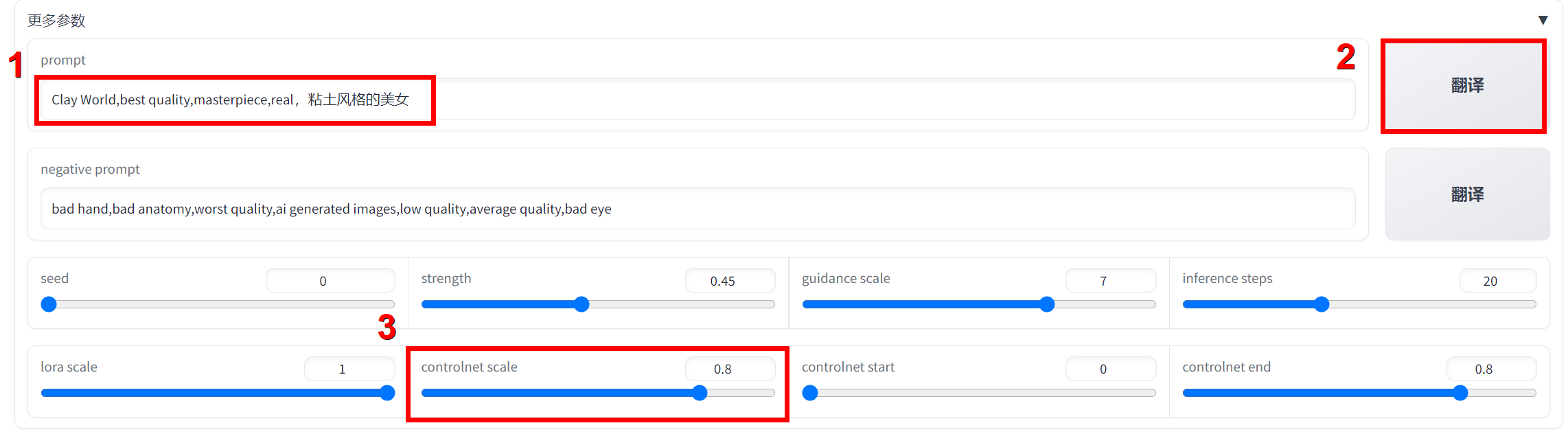
- 在英文提示词基础上,追加提示词
粘土风格的美女,点击翻译,得到提示词翻译结果Clay World,best quality,masterpiece,real,It's a clay-like beauty.。并调整controlnet scale值为0.8,点击生成。
 原图 |
 默认参数 |
 修改参数后 |
- 可以看到,在增强ControlNet作用后,衣服纹理与原图更接近且额头没有多余的头发。
示例三
-
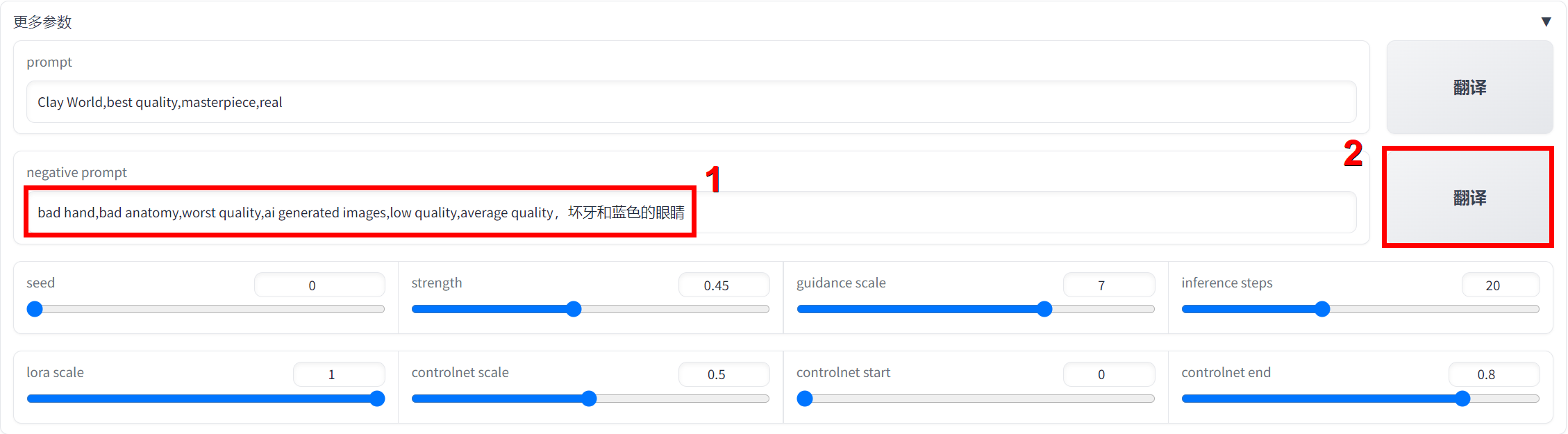
在默认参数下,生成的人物牙齿有点异常且眼睛是蓝色,如果这时我不希望人物是蓝色眼睛,该怎么解决呢?把“蓝色眼睛”加入负提示词!!
-
在负提示词后追加
坏牙和蓝色的眼睛,点击翻译,得到提示词翻译结果bad hand,bad anatomy,worst quality,ai generated images,low quality,average quality,Bad teeth and blue eyes.,点击生成。
 原图 |
 默认参数 |
 修改参数后 |
- 可以看到,生成的人物更自然且眼睛不再是蓝色
😉按照示例修改参数,定制你的粘土风照片吧😉
> 模型版权声明: > > HelloWorld系列模型(以下简称“本模型”)是由我(以下简称“所有者”)在LiblibAI平台支持下开发,并在LiblibAI平台上独家首发的XL大模型。除LiblibAI平台和Civitai平台外,任何个人或实体在其他平台所发布本模型均未经所有者授权。 > > 所有者授权个人或机构可免费使用本模型所生成的图像用于非商业性质的教育或信息传播目的,并且: > > - 遵守相关法律规定,不侵犯本模型或任何第三方的合法权益。 > > - 在使用图像时需注明图像来源为“由LEOSAM's HelloWorld大模型生成”。 > > 对于商业目的的使用,必须先与所有者签署商用授权协议。有关商业授权和模型定制事宜,请通过所有者在LiblibAI平台的主页信息联系。 > > SDXL模型的训练和开源分享是一项耗时耗力、具有挑战性的工作。所有者将持续为个人玩家免费提供HelloWorld模型的更新,以此表达对社区开源贡献者的支持和感谢。商业用户的有偿合作是推动本模型开发和持续改进的重要动力。感谢每一位用户的理解与支持。 >
请注意,任何未经授权的使用行为都可能违反相关法律规定,并可能承担法律责任。本声明的最终解释权归所有者所有,并受中华人民共和国相关法律法规的约束。
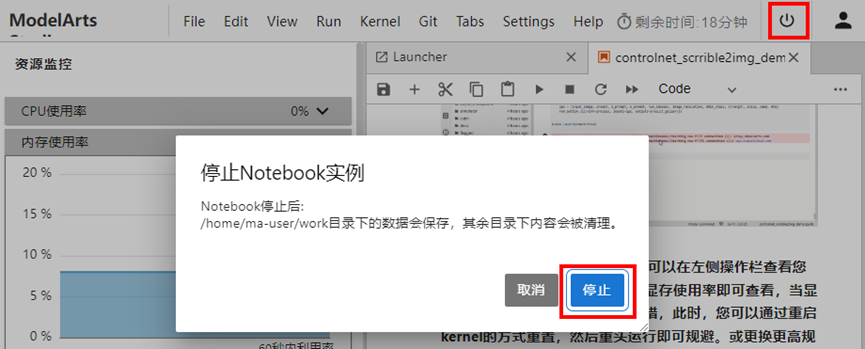
4.9 释放资源
实验完成后,点击右上角停止Notebook实例按钮,选择停止,释放资源。
5 常见问题FAQ
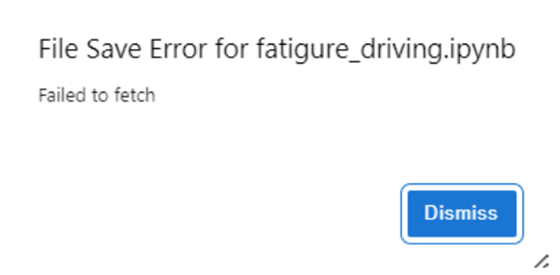
1.出现 File Save Error fatigue_driving.ipynb,为内网问题,点击 Dismiss 即可。不用关心。
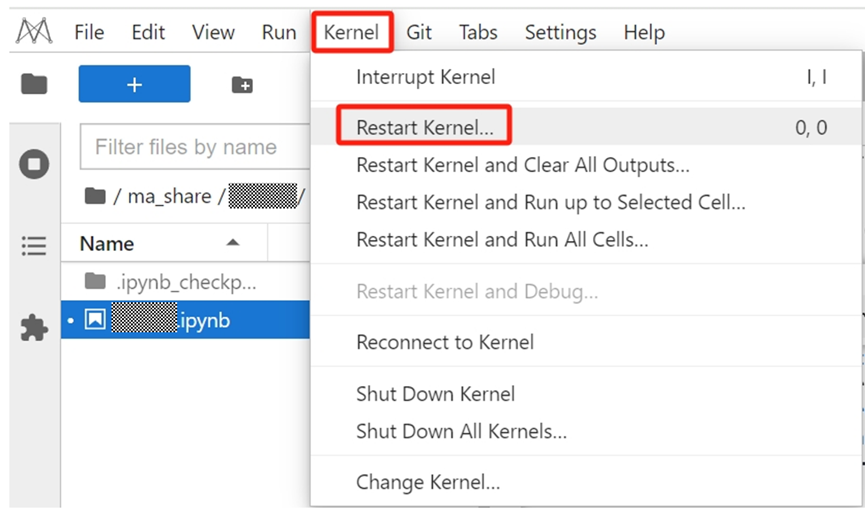
2.案例运行出现异常,无法往下执行,可以重启kernel,再重新依次运行案例解决。
重启Kernel方式:点击左上工具栏中的Kernel->Restart Kernel,如下图所示

- 点赞
- 收藏
- 关注作者
评论(0)