openGemini@KubeCon China大会演讲精彩回顾

2024年8月21日,KubeCon + CloudNativeCon + 开源峰会+ AI_Dev China 2024 大会正式在香港举办,openGemini作为CNCF社区新晋开源项目,携车联网解决方案再次登上了演讲台。接下来,我们将重点介绍openGemini社区联合发起人 & openGemini核心研发团队成员李伟琪在本次大会上的精彩分享。

车联网行业痛点和技术挑战
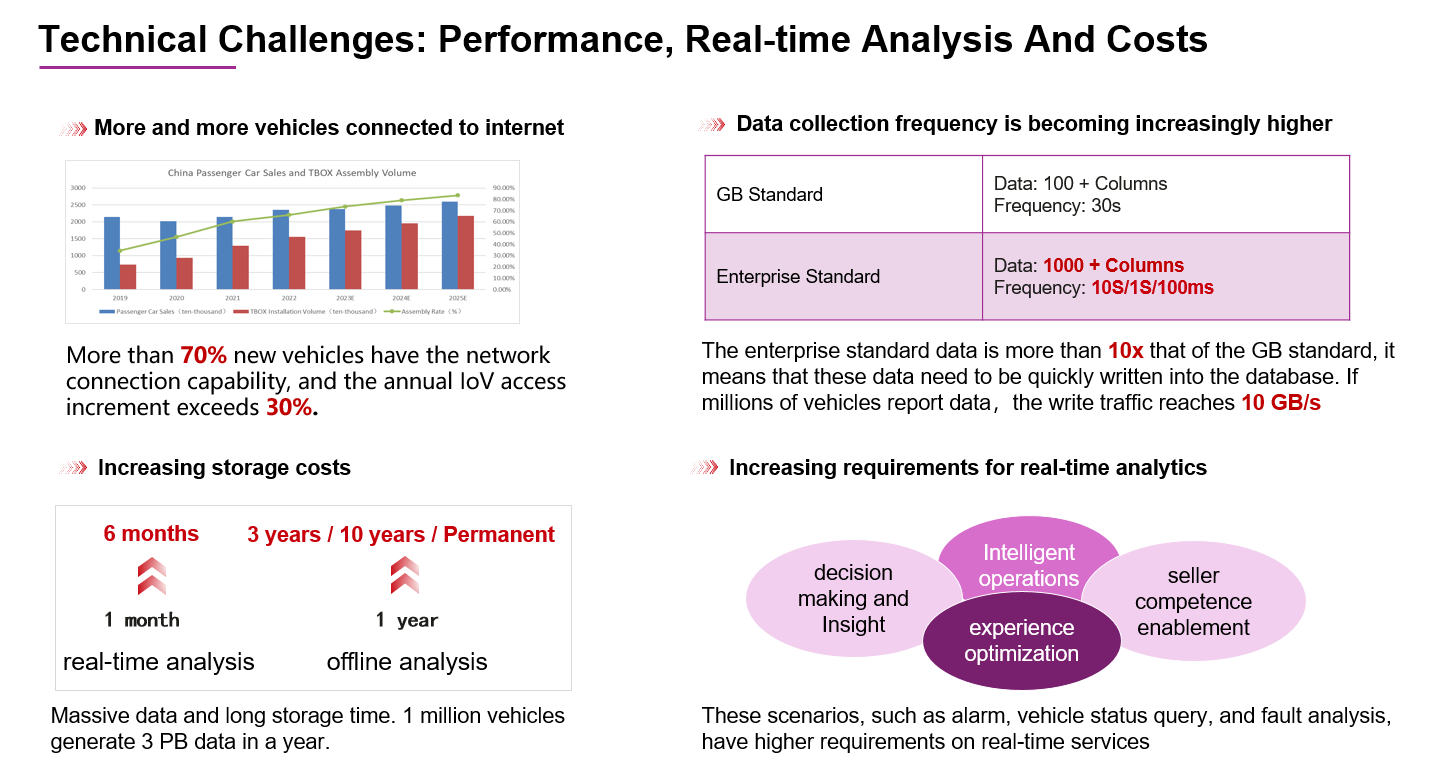
数据写入难:企标数据的采集量是国标的10倍以上,其采集频率普遍达到每秒一次,部分甚至达到毫秒级别。在处理百万级车辆规模的数据时,写入流量可高达每秒10GB,这对数据库的写入性能提出了极为严格的挑战。
数据处理成本不可控:面对如此庞大的数据入库流量,增加计算节点是一种普遍的解决策略。然而,如果单个节点的处理能力不足,可能需要部署更多的节点,这不仅会导致集群规模的急剧扩张,也会相应增加维护成本。此外,随着接入车辆数量的增加、数据量的激增以及数据存储时间的延长,据调查,100万辆车辆一年内上报的数据量可达到3PB,这进一步推高了数据存储的成本,使得预算控制变得困难。因此,支持快速数据写入并具备高效数据压缩功能的时序数据库,在当下车联网场景显得尤为重要。
数据分析难:随着用户对服务的期望日益增长,他们对车辆告警、详单查询、故障快速分析等实时性服务的需求也在不断提升。这种趋势迫使厂商不断进行系统技术升级,以确保能够及时响应并满足用户的需求。这种升级的压力也传递到了数据库层面,要求数据库进行技术创新,在面对海量数据和高并发请求时仍能保持快速响应。
早期车联网技术架构需要尽快升级
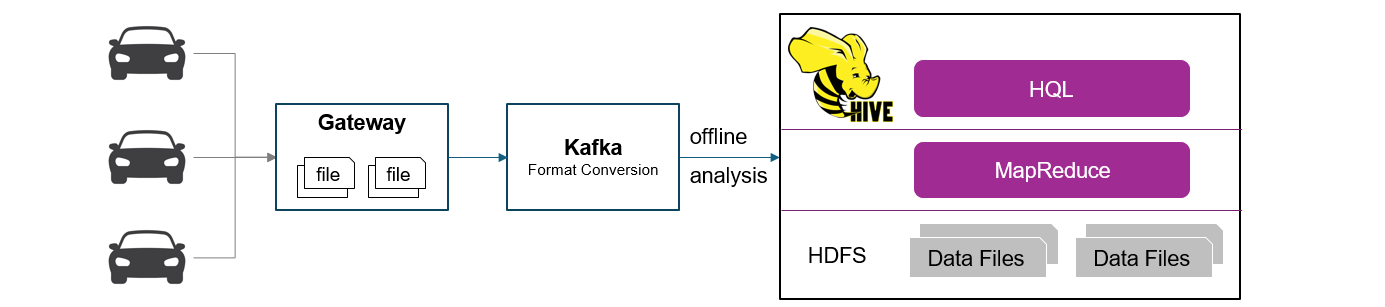
早期车联网不具备实时分析能力,广泛采用支持大规模分析的分布式数据仓库Hive,但从数据采集、存储和分析整个流程来看,离线处理时间太长,通常是天级别,效率低。
现代车联网技术架构在处理海量数据时感到力不从心
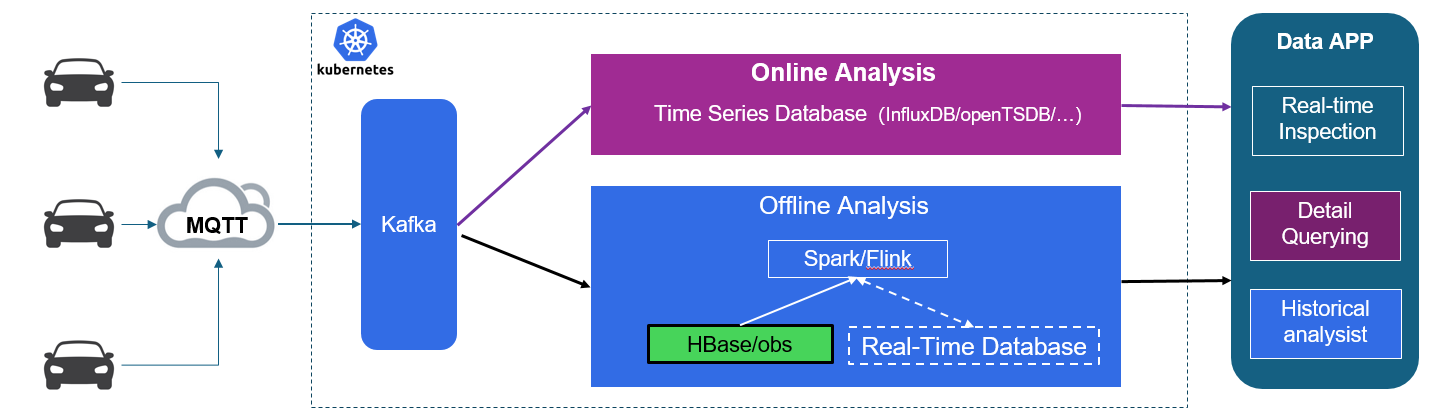
在现代车联网典型技术架构中,数据接入端采用了MQTT、Kafka等技术,显著提升了数据采集的实时性。为了进一步优化实时数据分析,引入了时序数据库,并结合了Spark、Flink等高性能大数据处理工具,使得离线分析效率得到了显著提升。整个业务架构构建在Kubernetes(K8s)之上,有效提高了计算资源的利用效率。
尽管如此,在处理大规模数据时,例如需要处理每秒10GB和1000+列的指标时,InfluxDB、OpenTSDB以及其他时序数据库在读写性能上仍然面临重大挑战。此外,对于离线数据存储,虽然HBase被广泛用作底层存储系统,但其数据压缩效率有限,随着数据的长期积累,存储成本也在持续快速增加。
openGemini具备高性能、低成本优势,给车联网一个更优选择
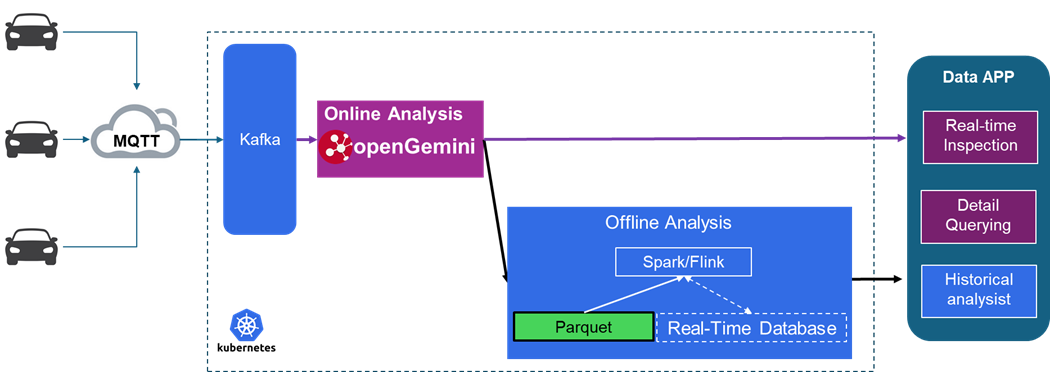
车联网技术架构引入openGemini之后,借助openGemini的高吞吐能力,数据全量进入openGemini,可以提供实时的数据分析和详单查询。在实际应用中,48节点的openGemini集群就可以轻松处理每秒10GB的数据流量,粗略统计,4天共写入3000TB数据,但实际磁盘空间占用仅为60TB。
此外,为了进一步降低存储成本,新架构允许完全摒弃HBase的使用,直接将openGemini的数据格式转换为广泛认可的大数据通用格式Parquet,并存储于对象存储服务(obs)中(该能力已在华为云GeminiDB云服务上通过了用户的实践检验,未来会在社区提供)。通过这种方式,可以利用大数据分析工具进行高效的数据离线分析处理。
openGemini部分关键技术
多值数据模型:多值数据模型对于openGemini来说更加友好,读写性能更优,这一点与车联网数据的特点—指标列众多—非常契合。对应到物理数据模型,相同时间线数据被聚簇在一起,可以更高效处理和查询具有多个值的列。
乱序数据处理策略:在面对高写入流量时,openGemini采取了一种策略,将有序和乱序数据分开存放,以减少写入时的冲突和延迟。随后,系统会在适当的时机对这些数据进行合并,以保持数据的一致性和有序性。
索引检索:采openGemini采用了Global-Local缓存架构,这种架构设计提升了缓存命中率,有效降低了内存占用。此外,内核还使用了布隆过滤器,这是一种高效的数据结构,用于快速判断一个元素是否在一个集合中,从而减少了索引检查的成本和提高了检索速度。
Cahce使用和管理:为了进一步提升查询性能,openGemini在不同层级大量使用缓存技术,例如Plan Cache、Schedule Cache、Index Cache、MetaData Cache和Data Cache等。系统会根据数据访问模式和频率动态调整缓存大小和分配,确保热点数据快速访问,同时定期清理和优化缓存内容,避免资源浪费,保持系统的响应速度和稳定性。
结束
在这次演讲中,openGemini有幸结识了众多来自光伏和新能源领域的企业开发者。我们深感欣慰,因为openGemini能够为他们解决众多实际业务中遇到的难题。此外,我们还观察到,在人工智能时代,AI模型训练过程中的故障率高且问题定位困难,这表明可观测性数据库可能即将迎来其发展的黄金时期。
令人振奋的是,openGemini已经在这一领域进行了长时间深入的研究和开发,并且积累了丰富的经验。我们坚信,在全世界开发者的共同努力下,openGemini将不断进步,迈向更加辉煌的未来。
开源地址:https://github.com/openGemini
官网地址:https://opengemini.org

- 点赞
- 收藏
- 关注作者
评论(0)