volcano结合开源prometheus实现负载感知调度

一 背景
原生Kubernetes调度器只能基于资源的申请值进行调度,然而Pod的真实资源使用率,往往与其所申请资源的Request/Limit差异很大,这直接导致了集群负载不均的问题。
- 集群中的部分节点,资源的真实使用率远低于资源申请值的分配率,却没有被调度更多的Pod,这造成了比较大的资源浪费。
- 集群中的另外一些节点,其资源的真实使用率事实上已经过载,却无法为调度器所感知到,这极大可能影响到业务的稳定性。
二 方案简介
Volcano提供基于真实负载调度的能力,在资源满足的情况下,Pod优先被调度至真实负载低的节点,集群各节点负载趋于均衡。

三 实践操作
3.1 前提准备
-
CCE集群安装prometheus监控系统,本文以开源prometheus-operator为例进行讲解。

必备组件:prometheus、prometheus-adapter、node-exporter,需要node-exporter提供kubernetes 集群中node的相关指标,然后prometheus进行指标的抓取和存储,最后需要prometheus-adapter进行指标规则的转换以及custom metricsAPI的注册实现。
-
CCE集群安装volcano插件
注意需要volcano插件版本大于1.11.14
3.2 prometheus-adapter添加指标转换规则
-
确认APIService是否存在
如果使用开源kube-prometheus方式进行安装,v1beta1.custom.metrics.k8s.ioAPIService不会自动创建,需要手动创建。详细yaml如下:apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: annotations: labels: name: v1beta1.custom.metrics.k8s.io spec: group: custom.metrics.k8s.io groupPriorityMinimum: 100 insecureSkipTLSVerify: true service: name: prometheus-adapter namespace: monitoring port: 443 version: v1beta1 versionPriority: 100
-
编辑自定义指标采集规则
kubectl -n monitoring edit configmap adapter-config
默认安装时只有资源指标转换规则(resourceRules),需要添加自定义指标规则,即rules。规则如下:rules: - seriesQuery: '{__name__=~"node_cpu_seconds_total"}' resources: overrides: instance: resource: node name: matches: node_cpu_seconds_total as: node_cpu_usage_avg metricsQuery: avg_over_time((1 - avg (irate(<<.Series>>{mode="idle"}[3m])) by (instance))[5m:30s]) - seriesQuery: '{__name__=~"node_memory_MemTotal_bytes"}' resources: overrides: instance: resource: node name: matches: node_memory_MemTotal_bytes as: node_memory_usage_avg metricsQuery: avg_over_time(((1-node_memory_MemAvailable_bytes/<<.Series>>))[5m:30s])○ CPU平均利用率采集规则
■ node_cpu_usage_avg:表示节点的CPU平均利用率,该指标名不可修改。
■ metricsQuery: avg_over_time((1 - avg (irate(<<.Series>>{mode=“idle”}[3m])) by (instance))[5m:30s]):为节点CPU平均利用率的查询语句。
当前metricsQuery表示查询所有节点最近5分钟的CPU平均利用率,该时间范围可自行根据实际情况进行修改。
○ Memory平均利用率采集规则
■ node_memory_usage_avg:表示节点的Memory利用率,该指标名不可修改。
■ metricsQuery: avg_over_time(((1-node_memory_MemAvailable_bytes/<<.Series>>))[5m:30s]):为节点Memory平均利用率的查询语句。
当前metricsQuery表示查询所有节点最近5分钟的Memory平均利用率,该时间范围可自行根据实际情况进行修改。
-
重启prometheus-adapter 实例,加载新添加的指标规则。
-
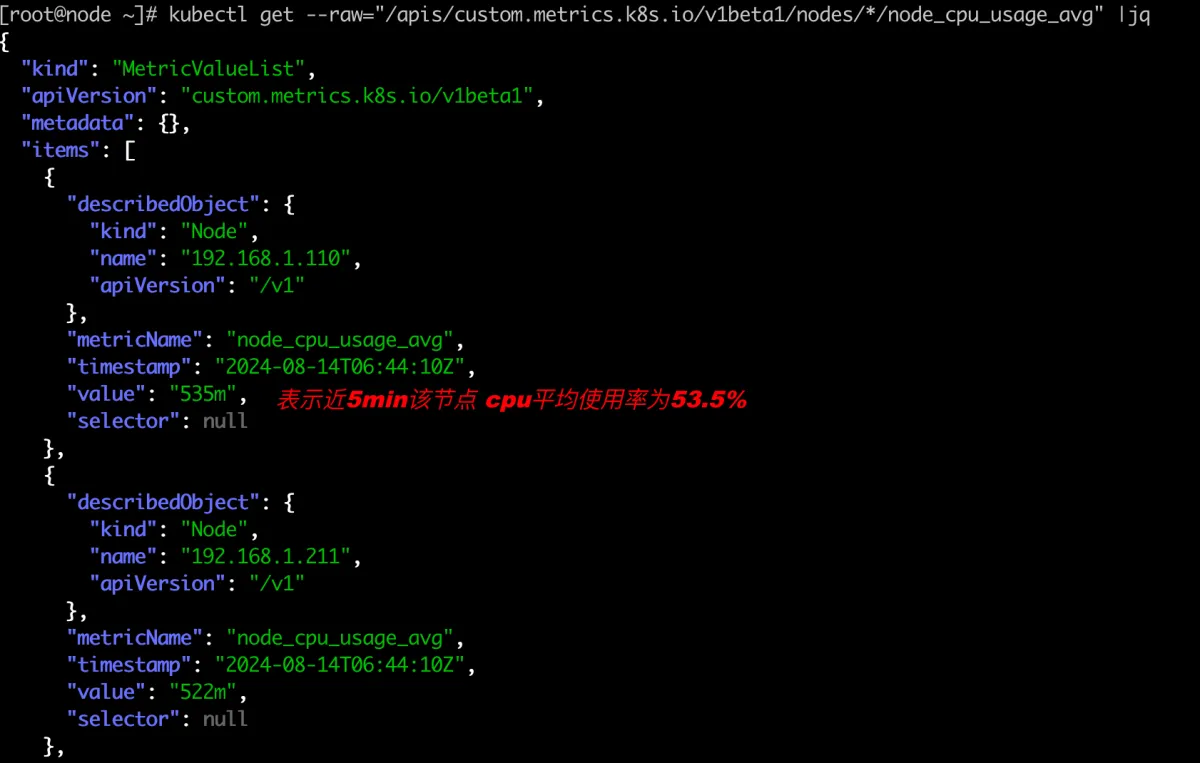
确认自定义指标是否生效
kubectl get --raw="/apis/custom.metrics.k8s.io/v1beta1/nodes/*/node_cpu_usage_avg" |jq
volcano-scheduler会调用该custom metricsAPI查看node的资源实际使用情况进行调度决策。
如果查询报错、没有结果,需要通过prometheus-adapter的日志查看详细请求信息。大部分情况为自定义指标规则书写不规范导致。

3.3 volcano开启负载感知调度
-
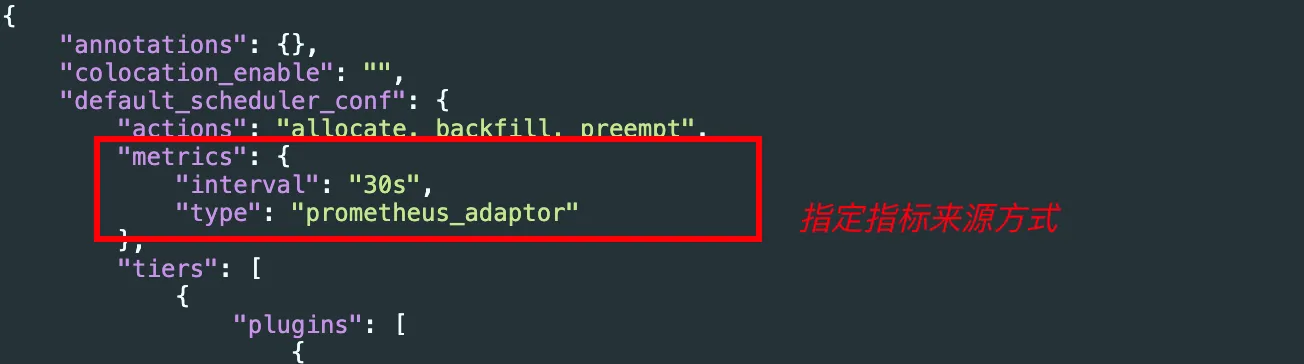
修改volcano-scheduler的配置文件,主要是添加metrics_type为
prometheus_adapter,然后添加usage plugin进行打分
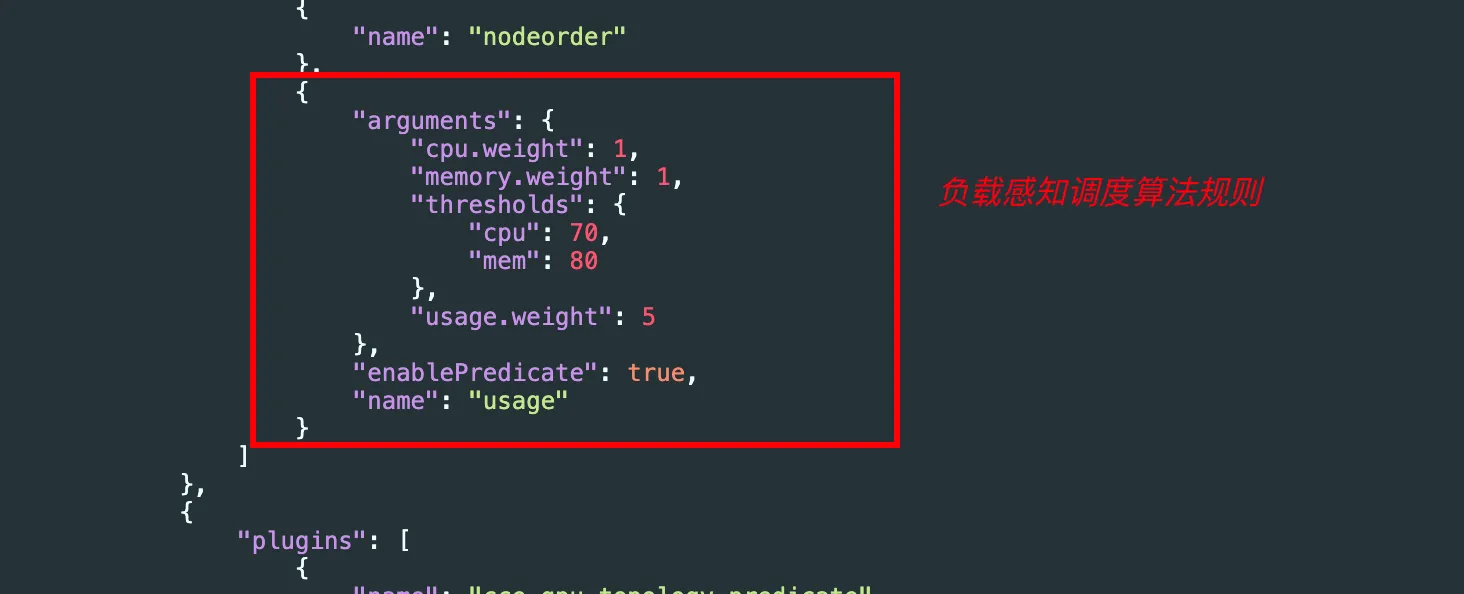
kubectl -n kube-system edit configmap volcano-scheduler-configmapapiVersion: v1 data: default-scheduler.conf: |- actions: "allocate, backfill, preempt" tiers: - plugins: - name: priority - name: gang enableJobStarving: false enablePreemptable: false - name: conformance - plugins: - name: drf enablePreemptable: false - name: predicates - name: nodeorder - name: usage arguments: cpu.weight: 1 memory.weight: 1 thresholds: cpu: 70 mem: 80 usage.weight: 5 enablePredicate: true - plugins: - name: cce-gpu-topology-predicate - name: cce-gpu-topology-priority - name: xgpu - plugins: - name: nodelocalvolume - name: nodeemptydirvolume - name: nodeCSIscheduling - name: networkresource arguments: NetworkType: eni-neutron metrics: type: "prometheus_adaptor" interval: 30s kind: ConfigMap metadata: annotations: meta.helm.sh/release-name: cceaddon-volcano meta.helm.sh/release-namespace: kube-system labels: app.kubernetes.io/managed-by: Helm release: cceaddon-volcano name: volcano-scheduler-configmap namespace: kube-system其中: 新增配置为
- name: usage #资源使用率plugin arguments: cpu.weight: 1 memory.weight: 1 thresholds: cpu: 70 #CPU 真实负载阈值 mem: 80 #mem 真实负载阈值 usage.weight: 5 enablePredicate: true # 硬约束:节点 CPU、内存真实负载达到阈值后,该节点不允许调度新的任务。metrics: type: "prometheus_adaptor" #指定指标获取方式 interval: 30s #获取指标间隔注意:是
prometheus_adaptor,不是prometheus-adaptor。注意连接符,此处容易写错,kubernetes yaml命名规范和者开源prometheus-adaptor都是中划线-,volcano 此处用的是下划线_。参考代码:
-
重启volcano-scheduler 实例加载新配置
-
如果不想修改configmap,也可用过CCE控制台进行配置。
前往插件中心,选择volcano插件,进行编辑。

3.4 验证调度行为
验证逻辑: 使用stress 进程进行cpu的压测,将节点cpu使用率提升至75%,然后下发负载实例,观察调度行为是否符合预期。
-
部署带有stress命令的容器,进行压测
-
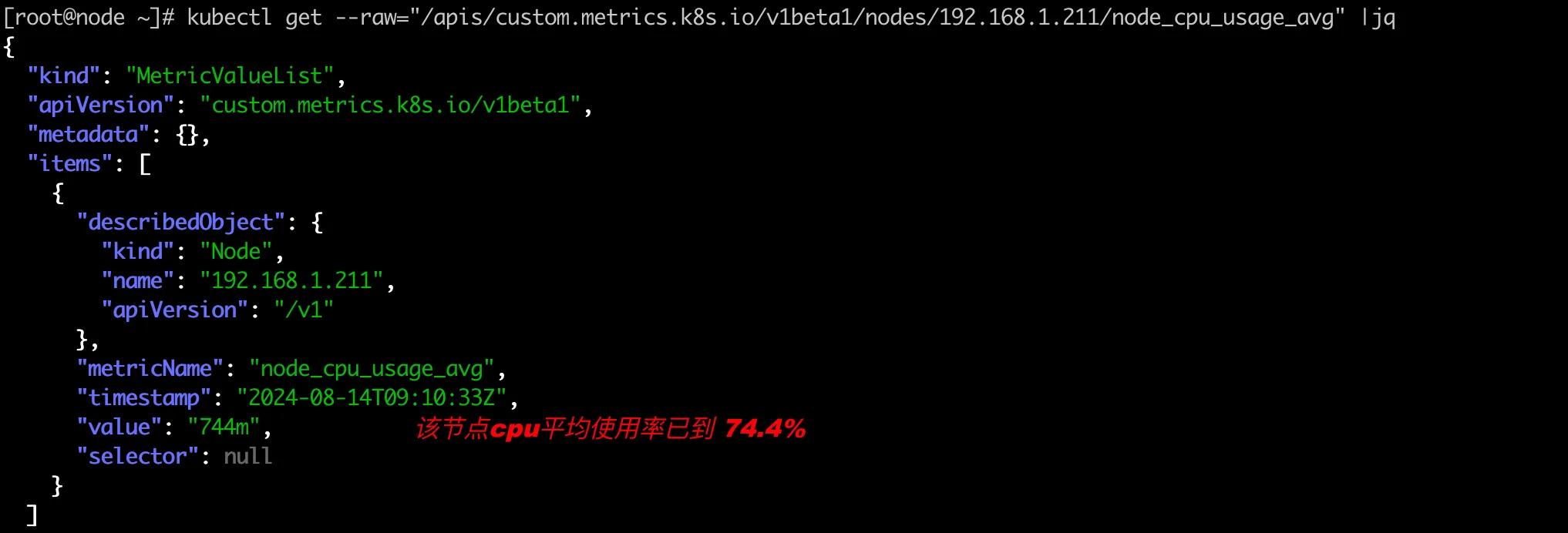
调用custom metricsAPI查看节点192.168.1.211 的cpu使用率
-
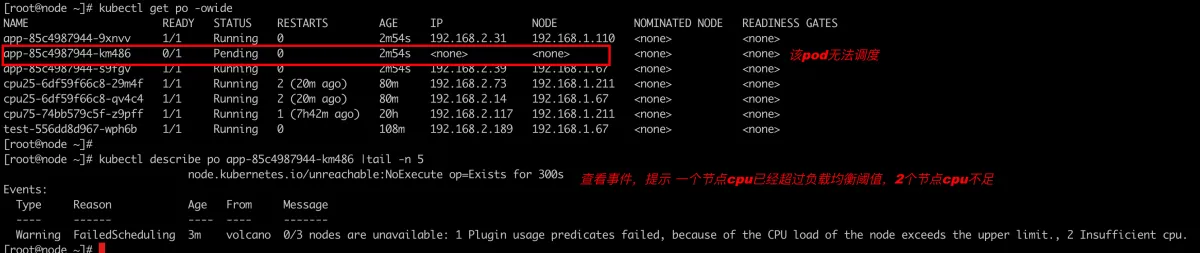
下发业务pod 观察调度结果
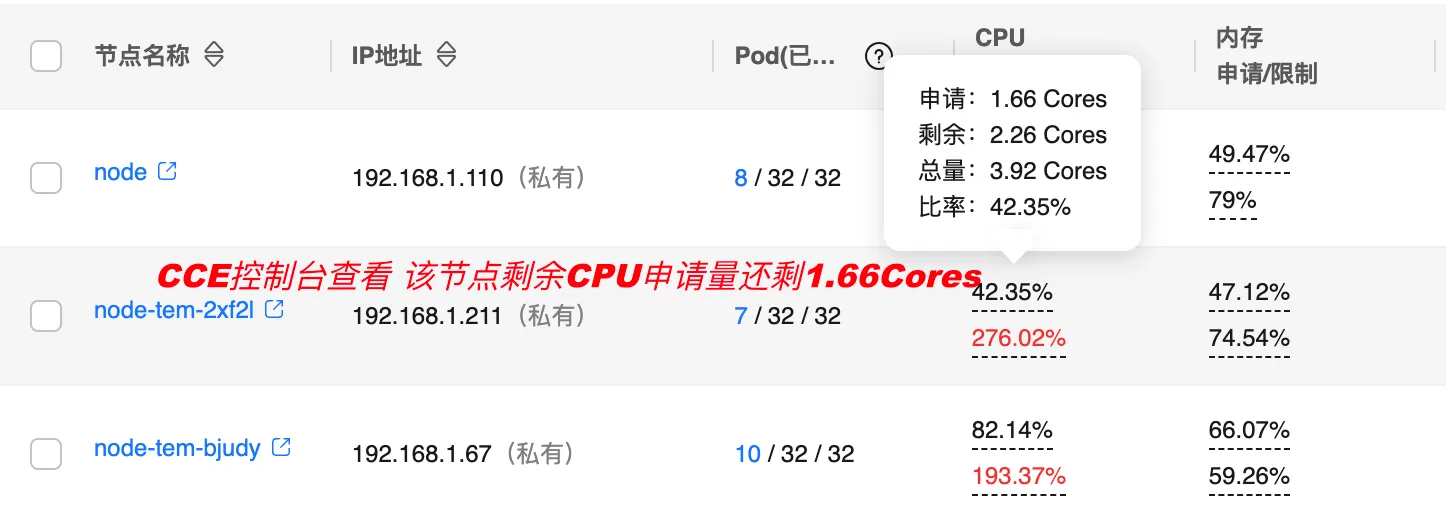
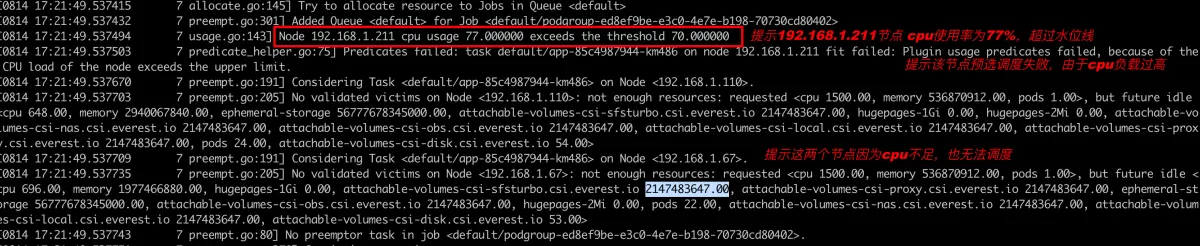
发现部分Pod调度失败,因为节点cpu使用率已经过载,符合预期
-
查看volcano-scheduler调度日志
可以发现日志提示192.168.1.211节点在预选调度就被排除在外不参与调度
-
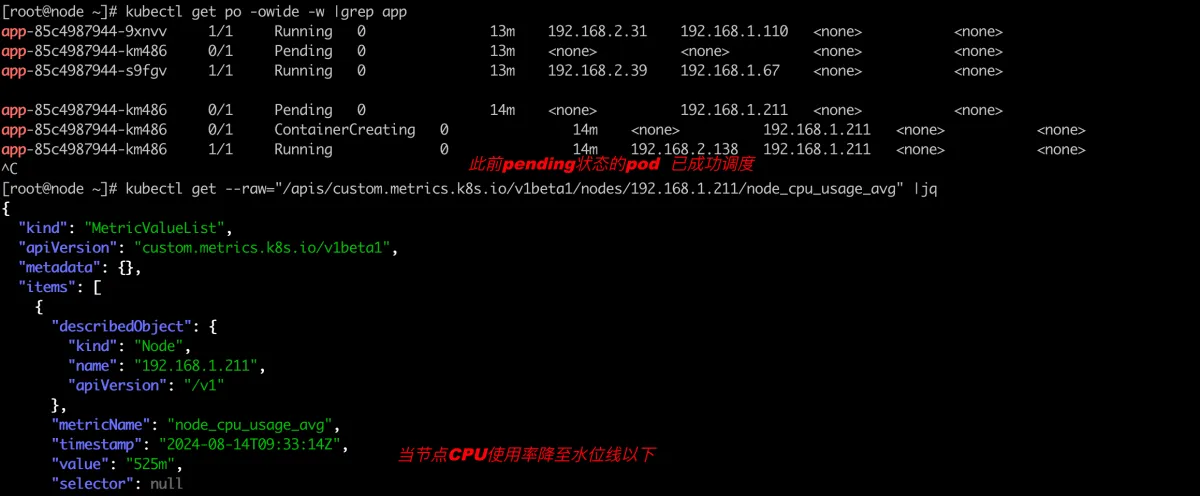
停止对节点192.168.1.211的压测
可以发现此前pending的pod已经成功调度192.168.1.211节点上。

四 备注
鉴于部分用户自建监控系统,本文以CCE集群中安装开源prometheus-operator为例进行操作。但是强烈建议各用户使用CCE提供的监控插件kube-prometheus-stack进行负载感知调度的指标提供方,省却了自行维护监控系统的烦恼,同时CCE console也提供了一键开启负载感知调度的功能。


- 点赞
- 收藏
- 关注作者
评论(0)