人工智能|RAG 检索增强生成

【摘要】 简介现有的 ChatGPT 的大语言模型中,虽然它本身的功能已经非常强悍了,但是它依然存在一些致命的问题:偏见:大语言模型没有分辨好坏的能力,所以在回答问题的时候,如果不做任何调整,可能会返回一些不好的内容,比如性别歧视,种族歧视。幻觉:大语言模型有时候并不那么靠谱,返回的内容会让人觉得驴唇不对马嘴。包括信息也无法完全可信。信息过时:因为没有联网能力,那么代表着从 2023 年 x 月 x...
简介
现有的 ChatGPT 的大语言模型中,虽然它本身的功能已经非常强悍了,但是它依然存在一些致命的问题:
- 偏见:大语言模型没有分辨好坏的能力,所以在回答问题的时候,如果不做任何调整,可能会返回一些不好的内容,比如性别歧视,种族歧视。
- 幻觉:大语言模型有时候并不那么靠谱,返回的内容会让人觉得驴唇不对马嘴。包括信息也无法完全可信。
- 信息过时:因为没有联网能力,那么代表着从 2023 年 x 月 x 日之后所有的信息,它都是不了解的。
那么大模型 LLM 如何解决这些问题,使其生成的内容质量更高,就成了一个难题。
而 RAG(Retrieval-Augmented Generation),通过将检索模型和生成模型(LLM)结合在一起,即可提高了生成内容的相关性和质量。
RAG 的优点
- 外部知识的利用。
- 数据及时更新。
- 高度定制能力。
- 减少成本。
RAG 的应用场景
RAG 技术的主要应用场景为:
- 问答系统(QA Systems):RAG 可以用于构建强大的问答系统,能够回答用户提出的各种问题。它能够通过检索大规模文档集合来提供准确的答案,无需针对每个问题进行特定训练。
- 文档生成和自动摘要 (Document Generation and Automatic Summarization):RAG 可用于自动生成文章段落、文档或自动摘要,基于检索的知识来填充文本,使得生成的内容更具信息价值。
- 智能助手和虚拟代理(Intelligent Assistants and Virtual Agents):RAG 可以用于构建智能助手或虚拟代理,结合聊天记录回答用户的问题、提供信息和执行任务,无需进行特定任务微调。
- 信息检索(Information Retrieval):RAG 可以改进信息检索系统,使其更准确深刻。用户可以提出更具体的查询,不再局限于关键词匹配。
- 知识图谱填充(Knowledge Graph Population):RAG 可以用于填充知识图谱中的实体关系,通过检索文档来识别和添加新的知识点。
RAG 检索增强的原理
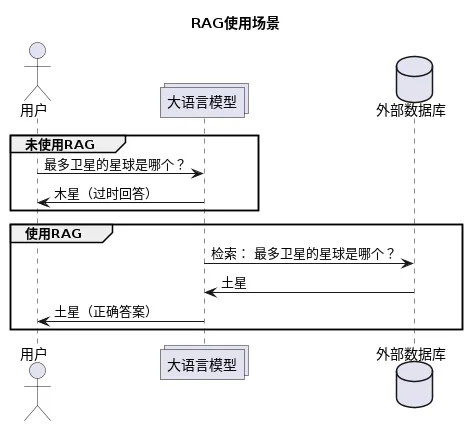
从上图可能很多同学非常好奇,大模型是如何与“外挂”数据库进行交互的。不是说大模型不能联网吗?其实大模型和数据库的交互,也是通过提示词完成的。
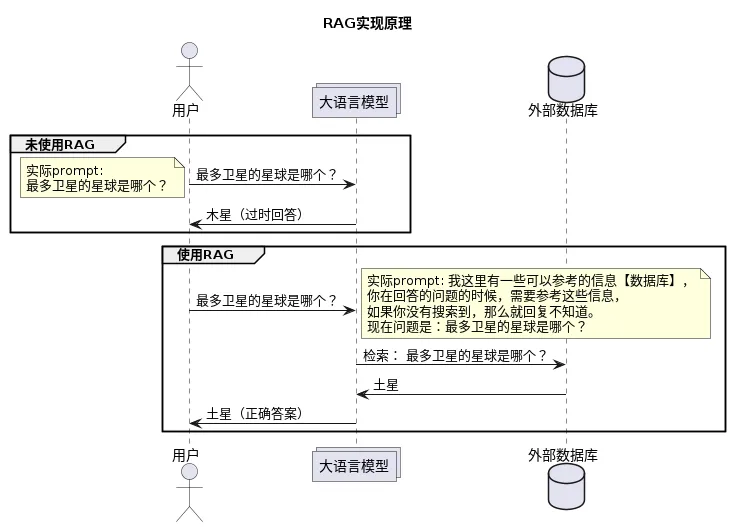
当然在以上实现过程中,可能会有数据信息极为庞大,而且冗余,如果直接发给大模型,上下文也会极为庞大。所以通常在这种情况下,会对数据库内的数据做一个预处理。让其变的易检索。这个预处理的过程,就使用了向量数据库以及embedding。
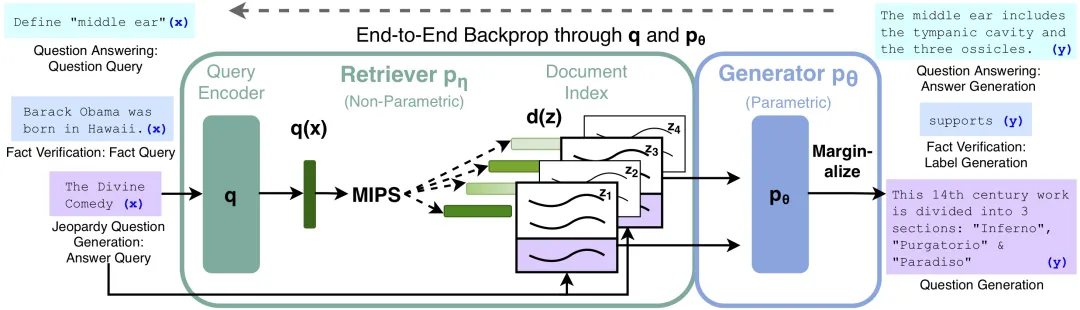
如下这张图便是 RAG 的完整过程:
RAG 实践应用
LangChain 包括 ChatGPT 的官方 assistant 的 Retrieval 其实都利用了 RAG 的原理。在后续的课程中会有更深入的实战应用。比如打造垂直领域内容的问答机器人。
相关资料
- RAG 官方文档说明
总结
- 理解什么是 RAG 检索增强。
- 理解 RAG 检索增强应用场景。
- 了解 RAG 检索增强有哪些相关的使用方法。
- 在后续的学习过程中,会结合 LangChain 与 assistant 完成 RAG 相关的实战练习。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)