GaussDB:基于 GaussDB 迁移、智能管理构建应用解决方案【华为云GaussDB:与数据库同行的日子】

文章目录
- 前言
- 一、数据库生态与技术发展
- 1.1、云数据库市场的高速增长
- 1.2、华为云 Stack+GaussDB
- 1.3、华为云打造 GaussDB 全场景云服务
- 二、何为 GaussDB(for openGauss)?
- 2.1、GaussDB 应用场景
- 2.2、GaussDB 核心优势
- 2.3、GaussDB 分布式核心架构
- 三、GaussDB 提供金融级高可用
- 3.1、GaussDB 实现全场景容灾
- 3.2、跨 AZ/Region 容灾技术
- 3.3、并行回放实现极致 RT0
- 3.4、全面 + 增量备份
- 四、GaussDB 极致性能如何实现?
- 4.1、分布式并行执行框架
- 4.2、GTM-Lite 技术
- 4.3、基于 NUMA-Aware 实现高性能事务处理
- 五、Scale Out 在线横向扩展
- 六、GaussDB 开放能力清单
- 七、华为云数据库迁移整体解决方案
- 7.1、数据库和应用迁移 UGO
- 7.2、UGO 核心能力之数据库结构迁移
- 7.3、数据库评估任务
- 7.4、数据库对象迁移任务
- 八、华为云数据复制服务 DRS
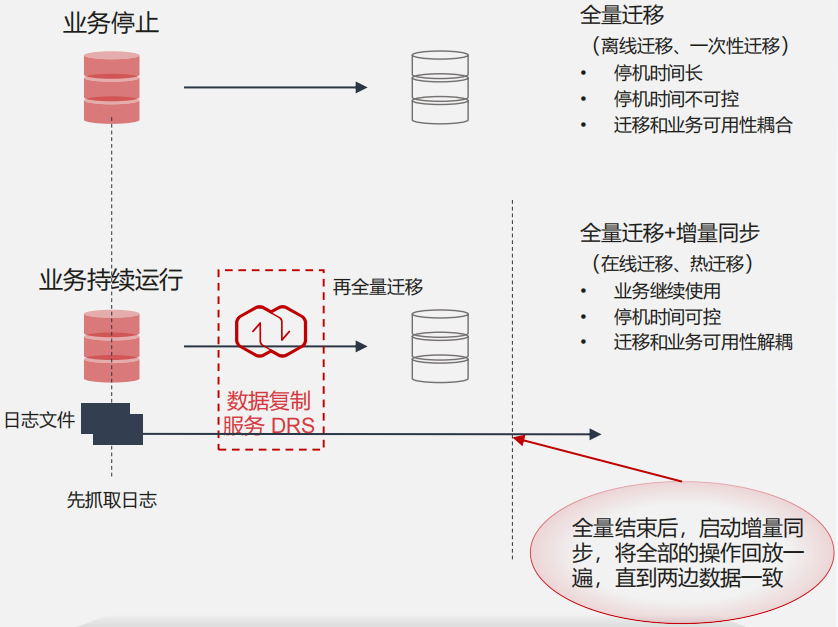
- 8.1、数据库迁移不影响业务
- 8.2、华为云 DRS 为千行百业提供平滑迁移体验
- 8.3、DRS 在线迁移示意图
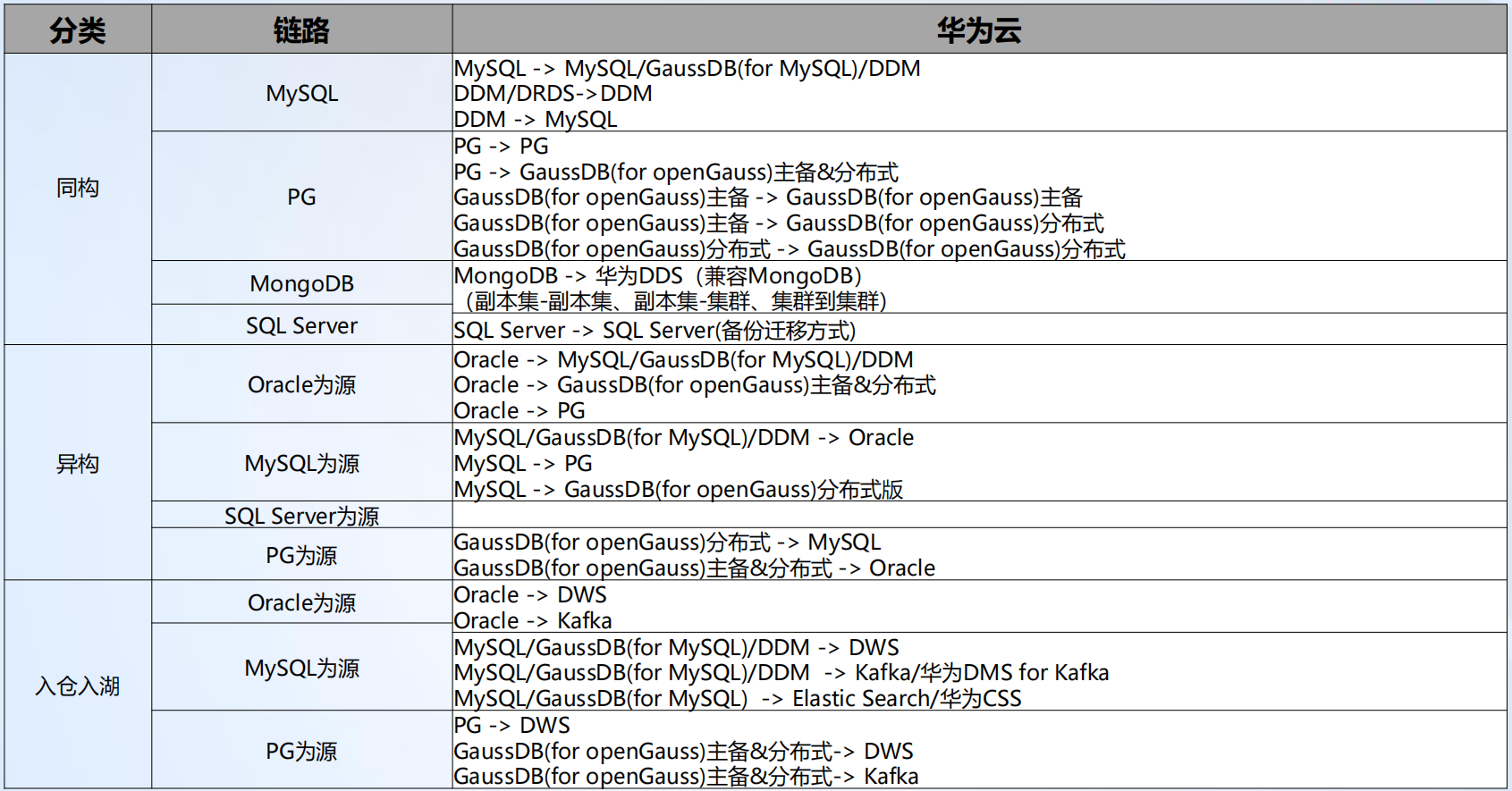
- 8.4、华为云 DRS 当前迁移能力
- 九、DRS 技术原理
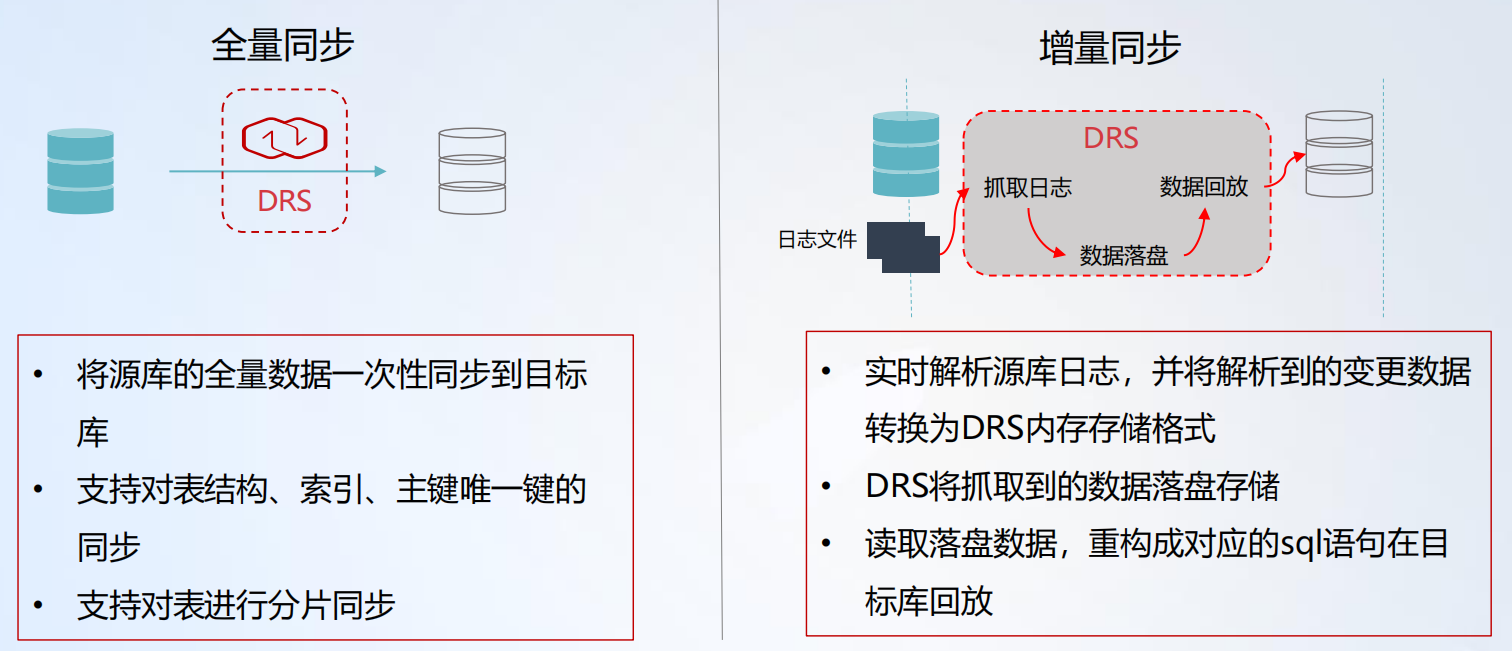
- 9.1、全量同步技术实现
- 9.2、增量并行回放技术实现
- 9.3、基于默克尔树的快速比对算法
- 9.4、生态工具开放能力清单
- 总结

大中型金融政企的应用加速云化,将主导云数据库市场高速增长。
- 大中型金融政企客户预计在 2025 年将占据 3/4 以上的市场空间,具体如下图所示:
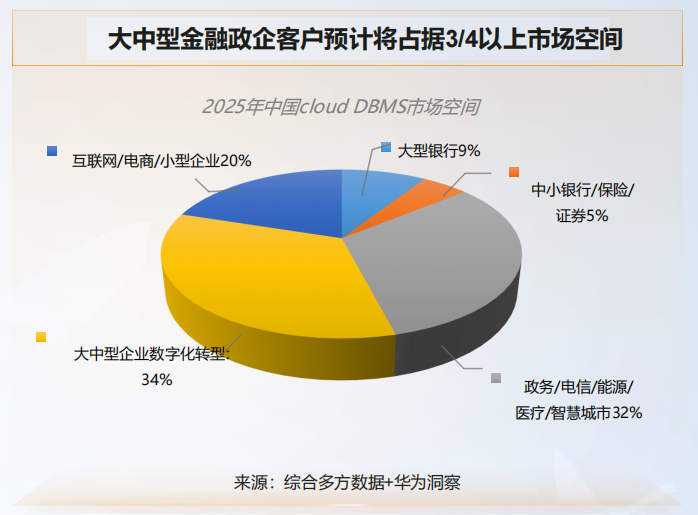
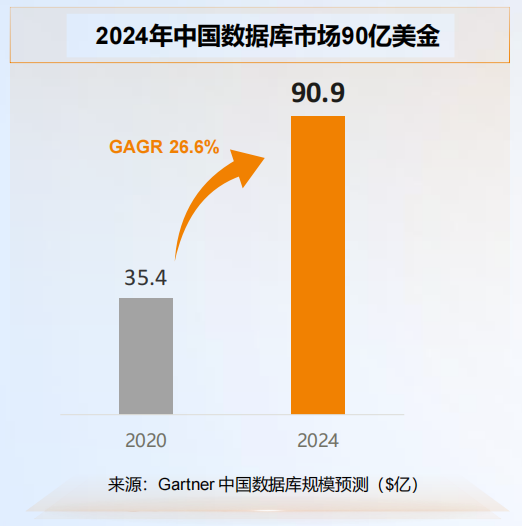
- 据 Gartner 中国数据库规模预测,截止 2024 年中国数据库市场将达到 90 亿美金,具体如下图所示:
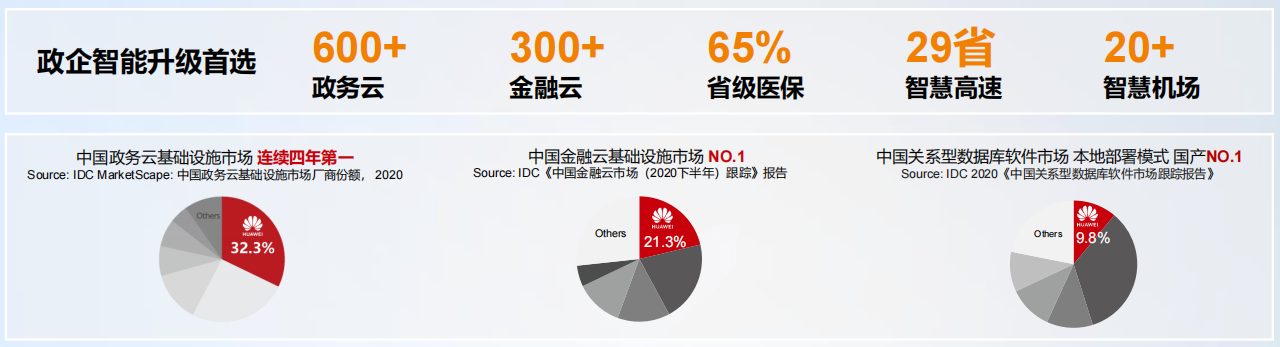
华为云 Stack+GaussDB,面向金融政企,提供本地部署和公有云一致体验的云服务,12 类 80+ 云服务为您提供统一 API、统一体验、统一生态的优势,具体如下图所示:
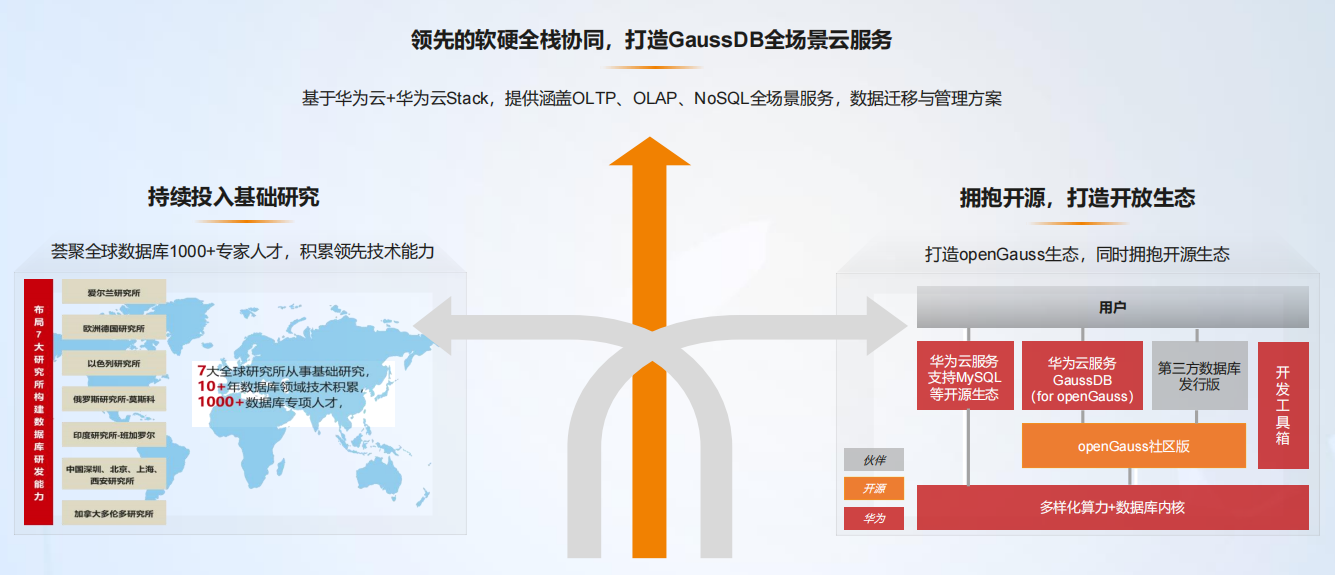
华为针对市场的高速发展与需求的倍增,定制了发挥软硬全栈优势,共建开放生态,打造 GaussDB 全场景云服务的战略,在基于华为云 + 华为云 Stack,提供涵盖 OLTP、OLAP、NoSQL 全场景服务,数据迁移与管理方案的基础上多管齐下,一方面持续投入基础研究,荟聚全球数据库 1000+ 专家人才,积累领先技术能力,另一方面打造 openGauss 生态,同时拥抱开源生态,具体如下图所示:
GaussDB(for openGauss)为华为自研旗舰产品,华为开放生态,企业高性能数据库,定位为企业级云分布式数据库,架构上着重构筑传统数据库的企业级能力和互联网分布式数据库的高扩展和高可用能力。
GaussDB(for openGauss)应用场景可覆盖运营商、金融、电力、政府、安平等千行百业,具体如下图所示:

GaussDB(for openGauss)具备五大核心优势,具体如下:
- 高可用:场景化容灾部署;平均交易响应时间 <60ms。同城 RPO=0,ROT<60s;异地 RPO<10s,RTO<10min。
- 极致性能:支持高吞吐强一致性事务能力,日均业务量 10w+。单节点:处理能力达 150 万 tpmC;分布式强一致:32 节点 1500 万 tpmC。
- 高扩展:容量和性能按需水平扩展。性能容量按需水平扩展到 1000+ 节点,线性比达 0.85。
- 数据安全:业界首个纯软全密态数据库技术。实现数据从传输、计算到存储的全程加密,解决数据库云上隐私及第三方信任问题。
- 搬迁工具:DRS+UGO 实现高效数据迁移。评估并转换异构数据库语法、实现变化数据捕捉、增量数据实时校验。
GaussDB(for openGauss)分布式核心架构介绍具体如下图所示:
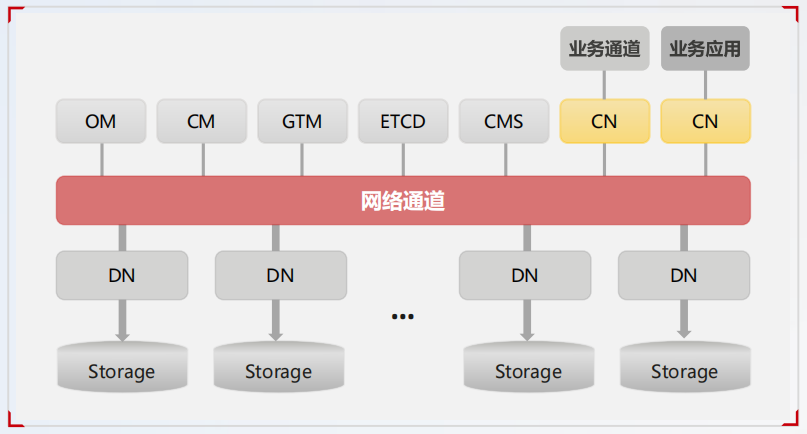
对于上图中的管理面感知角色介绍如下:
- DN:数据节点。
- CN:路由节点。
- GTM:全局事务。
- ETCD:一致性组件。
- CMS:做集群管理,主备切换控制,高可用相关。
管理面感知角色及其对应的描述具体如下表所示:
| 名称 | 描述 |
|---|---|
| OM | 运维管理模块(Operation Manager)。提供集群日常运维、配置管理的管理接口、工具。 |
| CM | 集群管理模块(Cluster Manager)。管理和监控分布式系统中各个功能单元和物理资源的运行情况,确保整个系统的稳定运行。 |
| GTM | 全局事务管理器(Global Transaction Manager),负责生成和维护全局事务 ID,确保全局事务一致性。 |
| CN | 协调节点(Coordinator Node)。负责接收来自应用的访问请求,并向客户端返回执行结果;负责分解任务,并调度任务分片在各 DN 上并行执行。 |
| DN | 数据节点(Data Node)。负责存储业务数据、执行数据查询任务以及向 CN 返回执行结果。 |
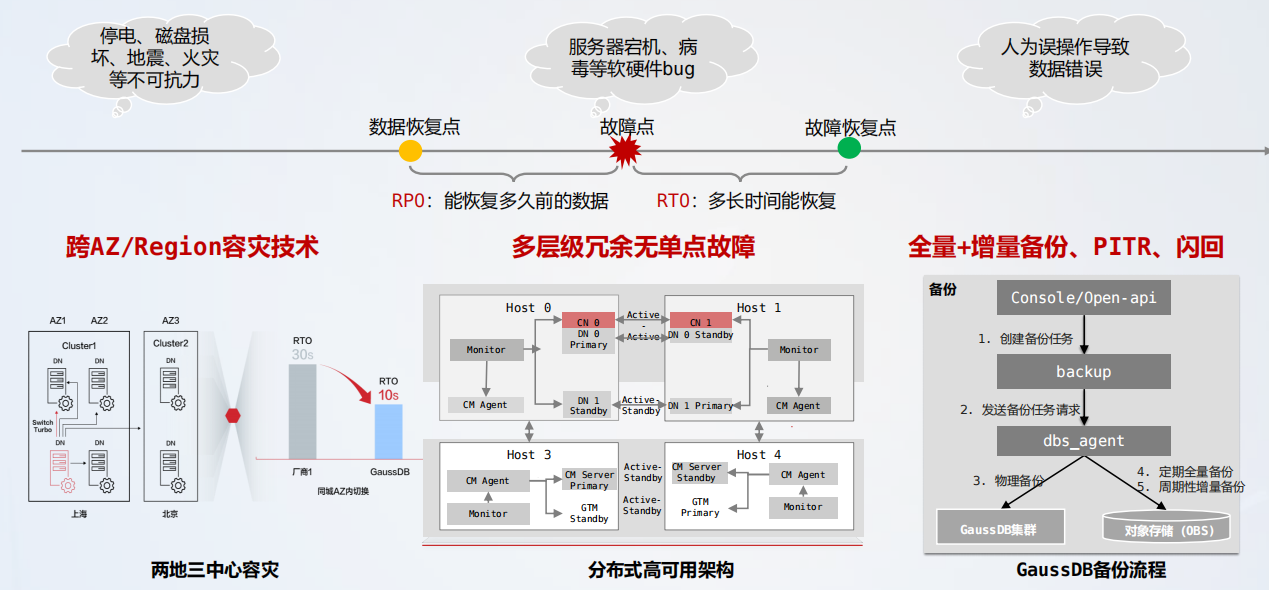
GaussDB(for openGauss)提供金融级高可用,通过两地三中心容灾、分布式高可用架构、GaussDB 备份流程的设计在极端环境下均可实现实现全场景容灾,具体如下图所示:
GaussDB(for openGauss)通过跨 AZ/Region、同城跨 3AZ 的容灾技术实现高可用,具体如下图所示:
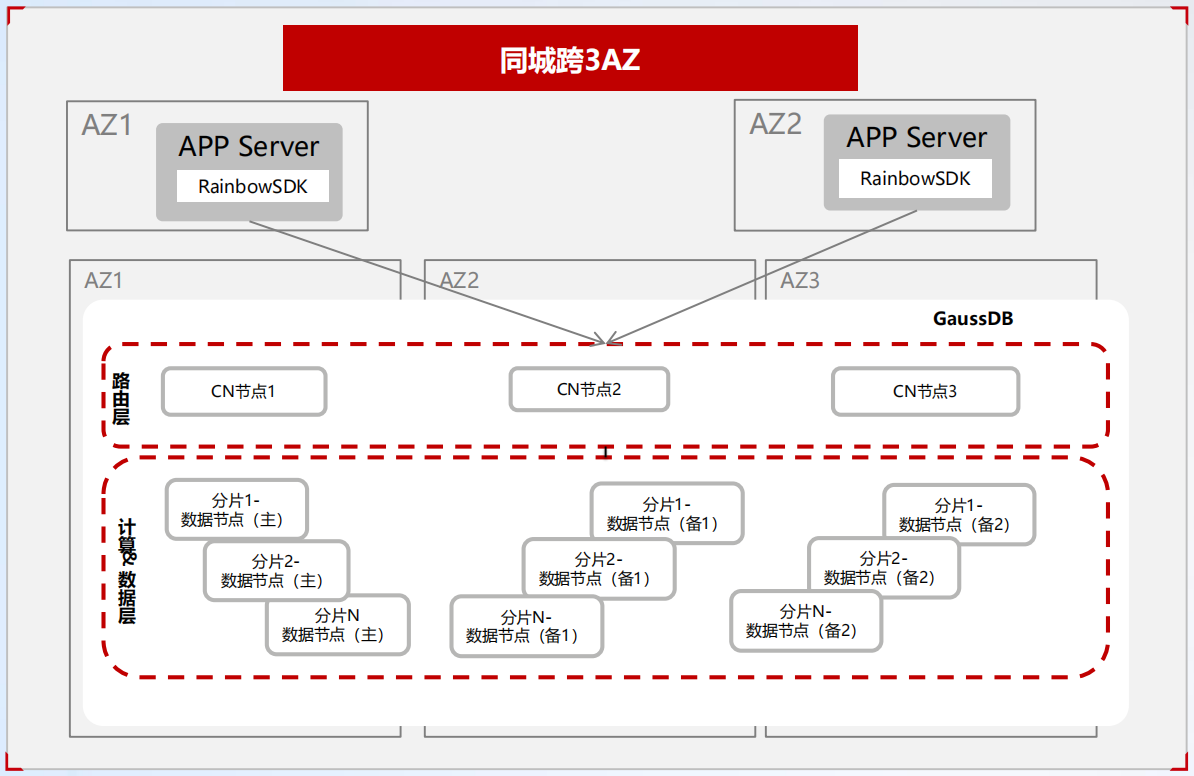
其主要特征为:
- 跨 3AZ 部署,对外提供 3 个 CN 节点 IP。业务做双 AZ 部署,通过 CN 节点 IP 连接 GaussDB,进行数据读写操作。
- GaussDB 服务内部实现 CN 和计算&数据节点的故障切换。
- GaussDB 负责对业务的读写请求进行负载均衡,根据业务压力动态扩容,且对业务透明。
其关键技术为:
- DN shard 内高可用:多个副本之间采用 Quorum 或 paxos 日志复制。
- CN 高可用:多活全对等。
并行回放实现极致 RT0,多层级冗余无单点故障,分布式高可用架构具体如下图所示:
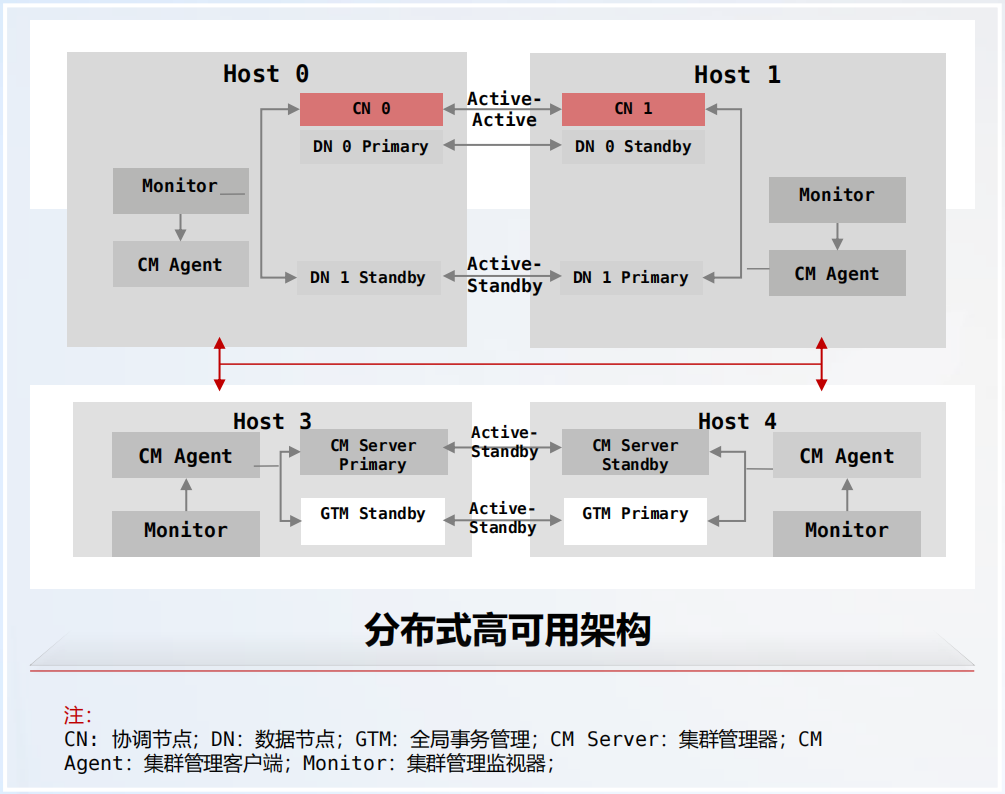
- 并行回放实现极致 RT0:通过日志流水线、批量回放和 Block 级物理并行恢复等关键技术,日志回放效率大幅提升,实现大压力下 RT0<10s 的极致高可靠。
- 多层级冗余无单点故障:所有故障场景可检测、可恢复,通过硬件冗余、实例冗余、数据冗余,实现整个系统无单点故障。
在硬件高可用和软件高可用方面的详情具体如下图所示:

全面 + 增量备份,保障多层次备份恢复,具体如下图所示:
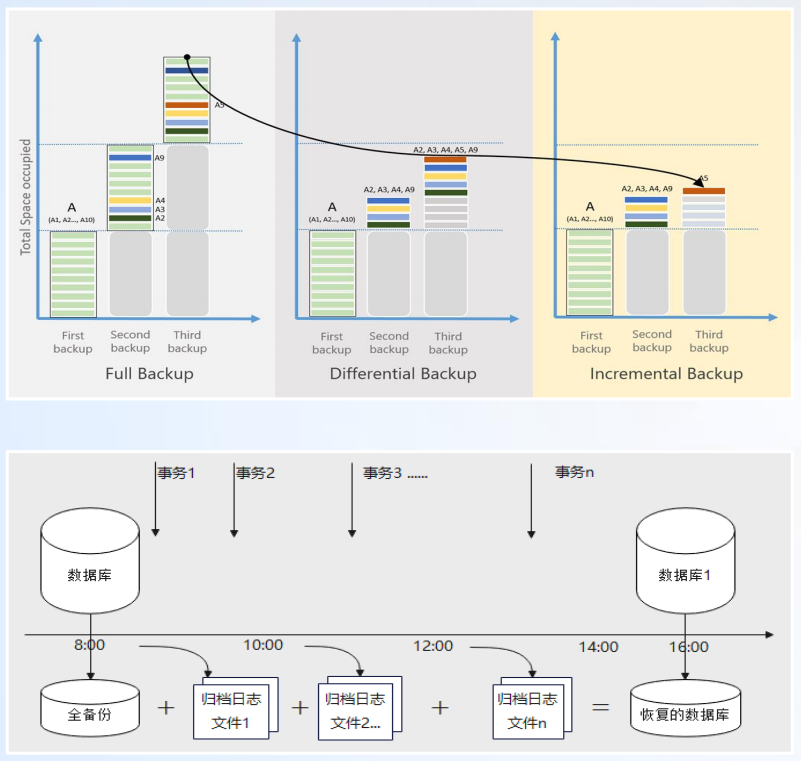
在关键技术方面:
- 支持 PITR,可以恢复到任意时间点。
- 支持闪回,防止误操作。
- 支持备机可读。
- 支持流式容灾。
在备份策略方面:
- 全量备份:一周一次。
- 增量备份:默认自动每 30 分钟一次。
- 保留期限 3 个月。
- 备份执行任务状态可查。
在恢复策略方面:
- 指定增量备份点恢复。
- 恢复任务状态可查。
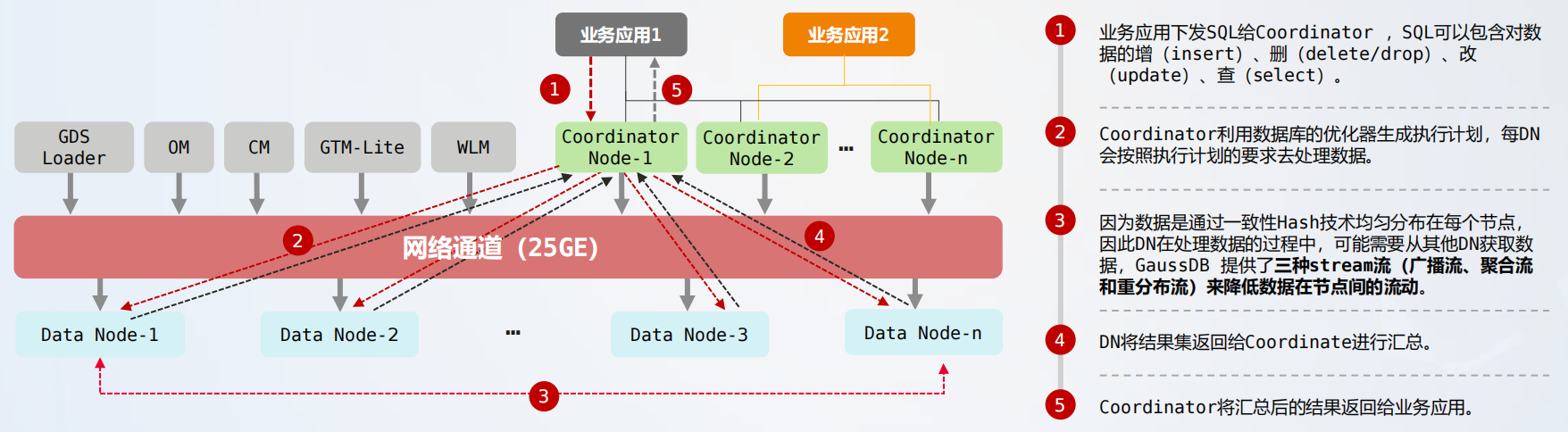
分布式执行框架会根据业务 SQL 生成最优执行计划,通过算子下推、并行执行等技术,提升分布式执行效率:
- 算子下推:完美 sharding 的单节点执行,点查、增删改等不需要 DN 间数据交互的场景下,CN 将 SQL 直接下发至 DN 执行。跨节点分布式执行,关联查询等需要 DN 间数据交互的场景下,CN 将执行计划下发给 DN,DN 间通过 Streaming 算子完成数据聚合。
- 并行执行:节点间支持 DDL、DML 等 SQL 语句并行执行;节点内支持基于数据页的并行查询。
GaussDB 分布式并行执行框架业务流程具体如下图所示:
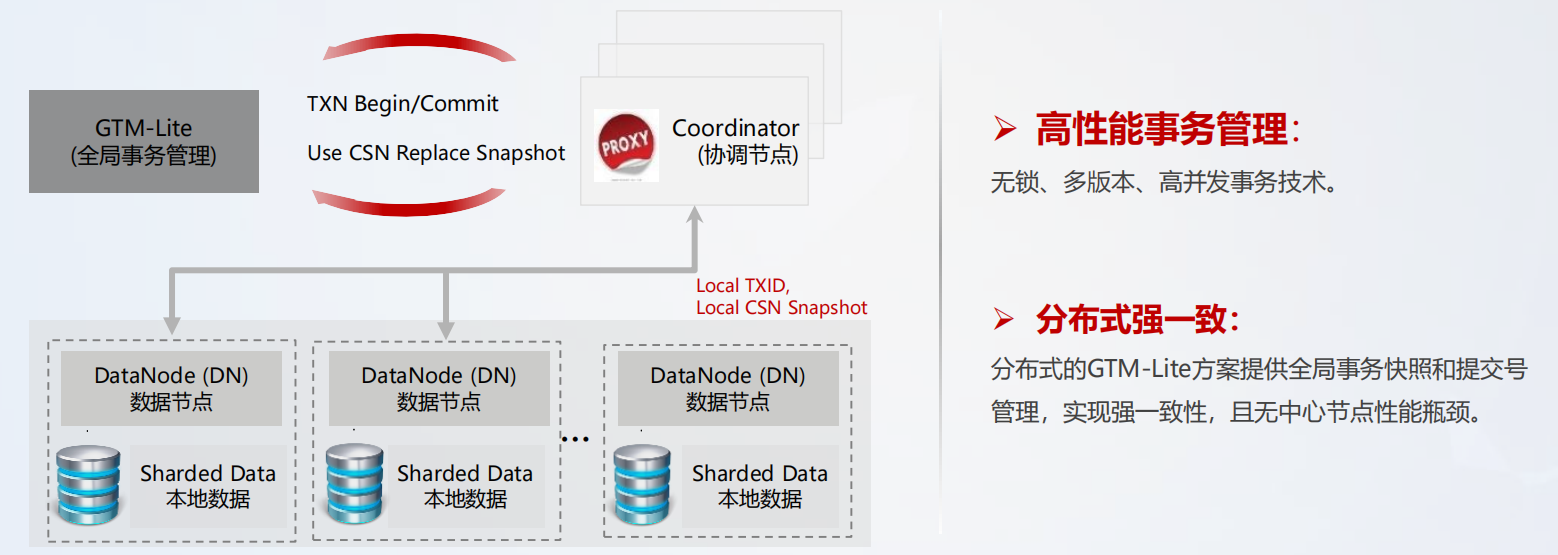
分布式事务处理性能,GTM-Lite 技术,在保证事务全局强一致的同时,提供高性能的事务处理能力,避免了单 GTM 的性能瓶颈,其具备的优势如下:
- CSN 提交序列号代替活跃事务列表进行可见性判断,无需遍历事务列表,提升了事务可见性判断效率。
- 事务管理节点 GTM,通过无锁原子操作提供 CSN 序号,不存全局单点瓶颈。
- 节点间事务交互仅需要一个 CSN,大大降低各节点间事务状态同步的网络开销。
GTM-Lite 技术业务流程具体如下图所示:
基于 NUMA-Aware 实现高性能事务处理,典型鲲鹏多核 CPU 架构具体如下图所示:
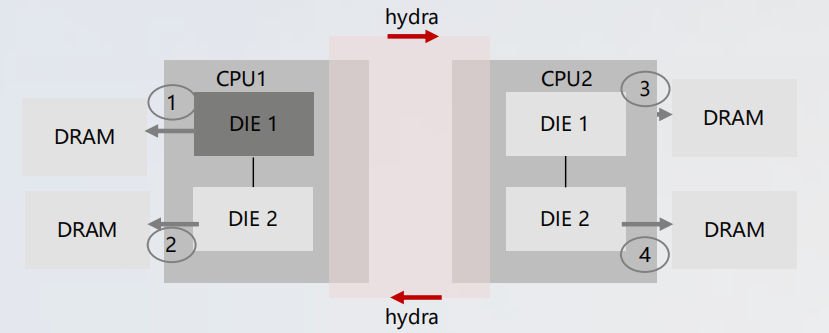
通过全局数据结构 NUMA 化改造,实现如下关键优化点:
- 工作进程 NUMA 绑核、全局数据结构(ProcArray/Buffer/B-Tree 等)NUMA 分区化改造,减少跨核、跨处理器竞争冲突。
- WAL 和 Clog 等日志从串行改为多核并行,消除串行瓶颈。
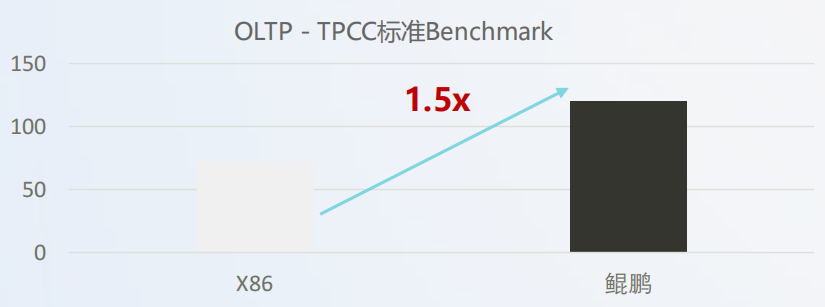
而据 OLTP - TPCC 标准 Benchmark,鲲鹏相较于传统的 X86 实现了 1.5x 的提升,具体如下图所示:
通过多核原生指令级优化,实现如下关键优化点:
- 鲲鹏原生 Atomic_LSE 实现 NUMA-Aware 自旋锁,四个指令→一个指令,提升指令效率。
- cache-line padding 技术,将 WAL 等组件保护全局位置索引的两个 cache-line 原子操作→一个,提升指令和数据效率。
Scale Out 在线横向扩展实现 GaussDB(for openGauss)的高扩展,其在线扩容的业务流程具体如下图所示:
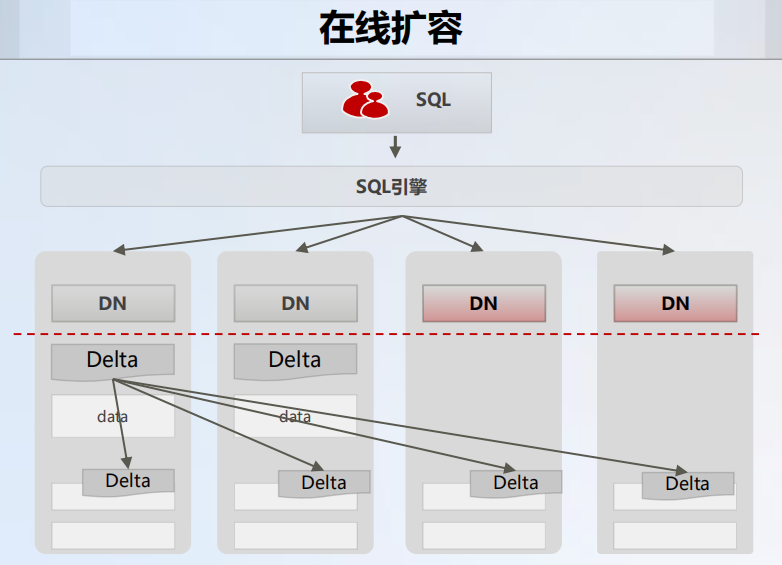
在线扩容机制为:
- 基线数据搬迁:通过 hashbucket 聚集存储,快速识别需要搬迁的数据文件,进行整个文件迁移。
- 增量数据追平:多轮追增,减少锁表时间;满足阈值(可配置)后锁表,完成最后一轮追增量及元数据切换。
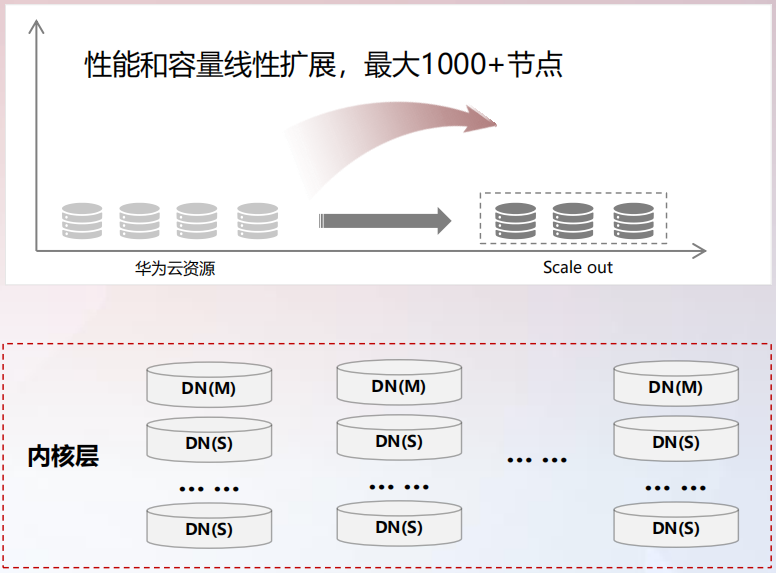
在性能、容量方面,通过增加 X86 服务器,实现系容量和性能的线性 Scale Out,具体如下图所示:
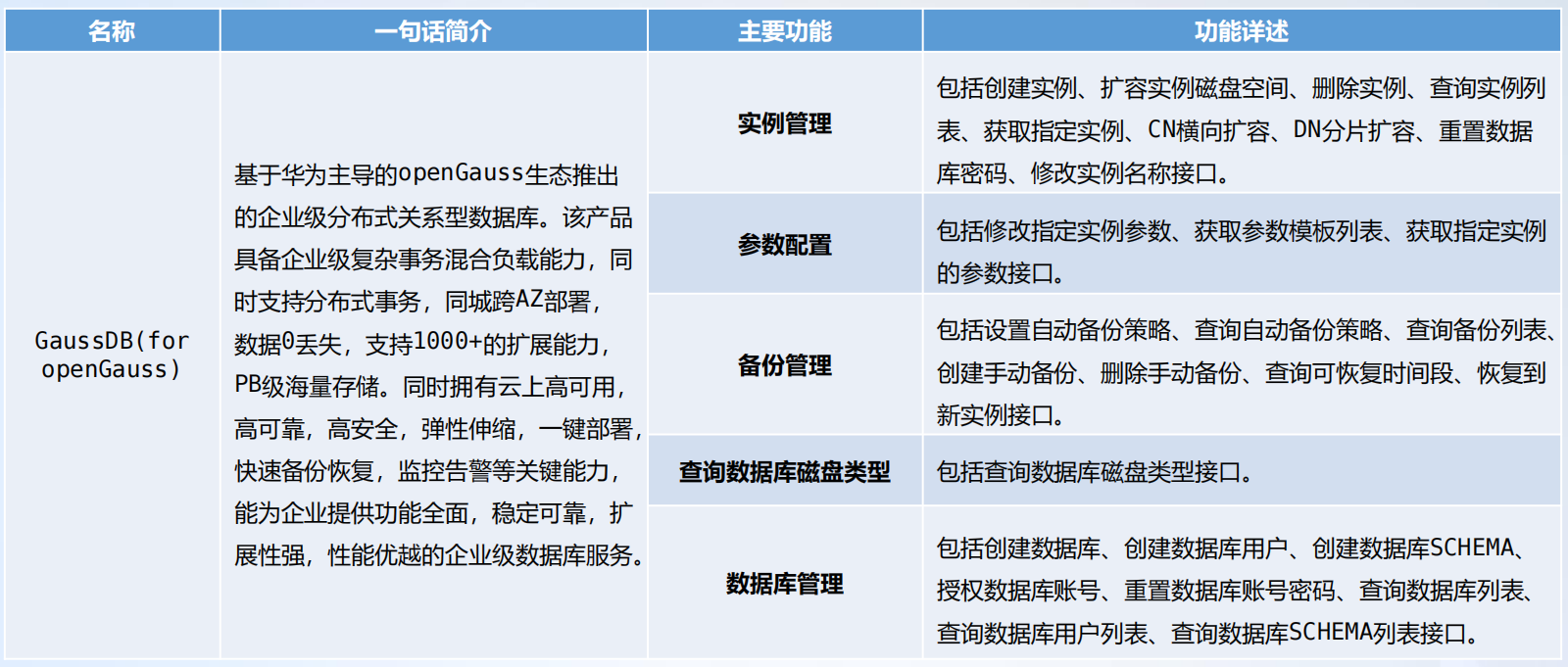
GaussDB(for openGauss)开放能力清单具体如下表所示:
为您提供GaussDB(for openGauss)相关参考链接:
华为云数据库迁移整体解决方案业务流程具体如下图所示:
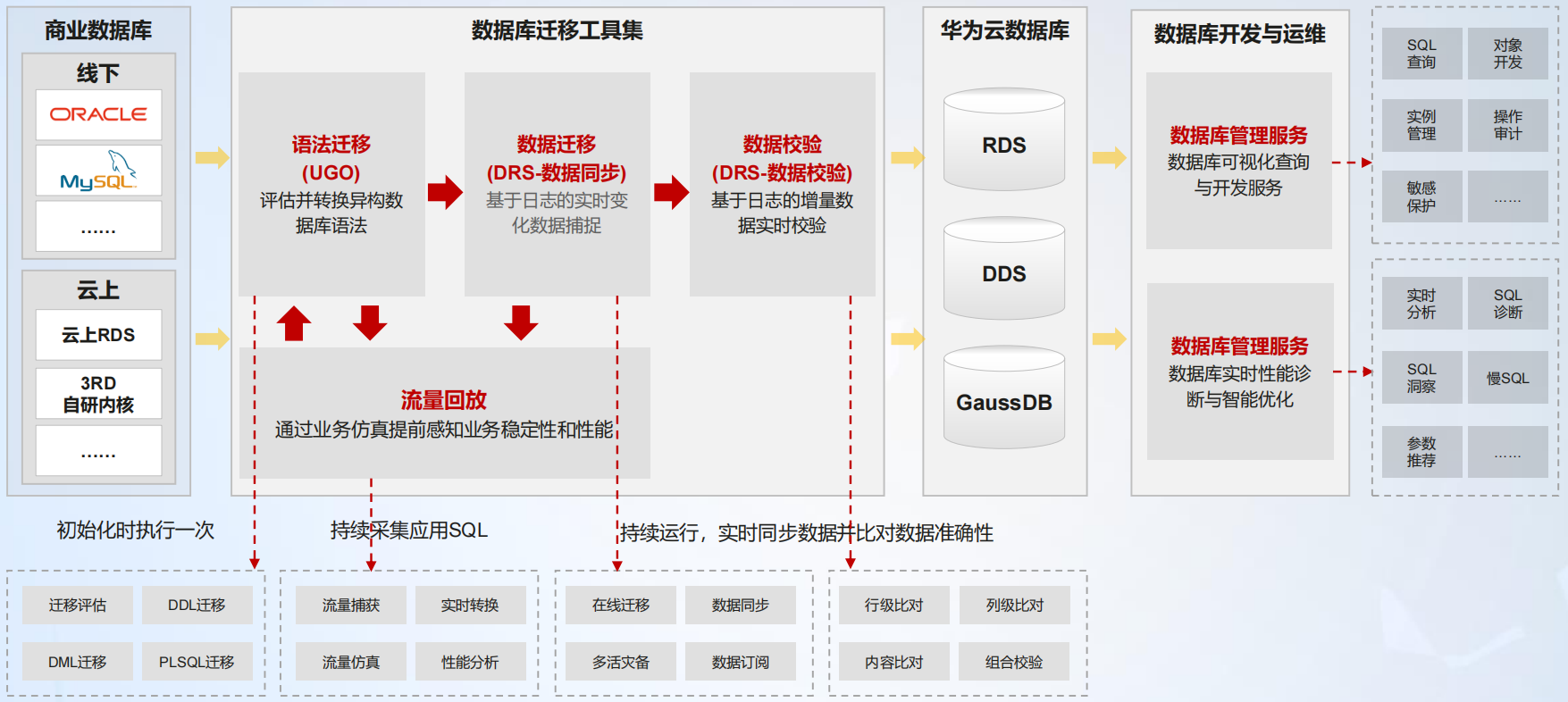
数据库和应用迁移 UGO(Database and Application Migration UGO,简称为 UGO),是专注于异构数据库对象迁移和应用迁移的专业化工具。通过预迁移评估、结构迁移二大核心功能,实现主流商用数据库到华为云数据库的自动化搬迁,助力用户轻松实现一键上云、一键切换数据库的目的,此项华为云获得了信通院迁移最高级评级。
从源端到目标端的支持场景具体如下图所示:

UGO 核心能力之数据库结构迁移分为迁移评估和迁移实施两个阶段,具体如下图所示:
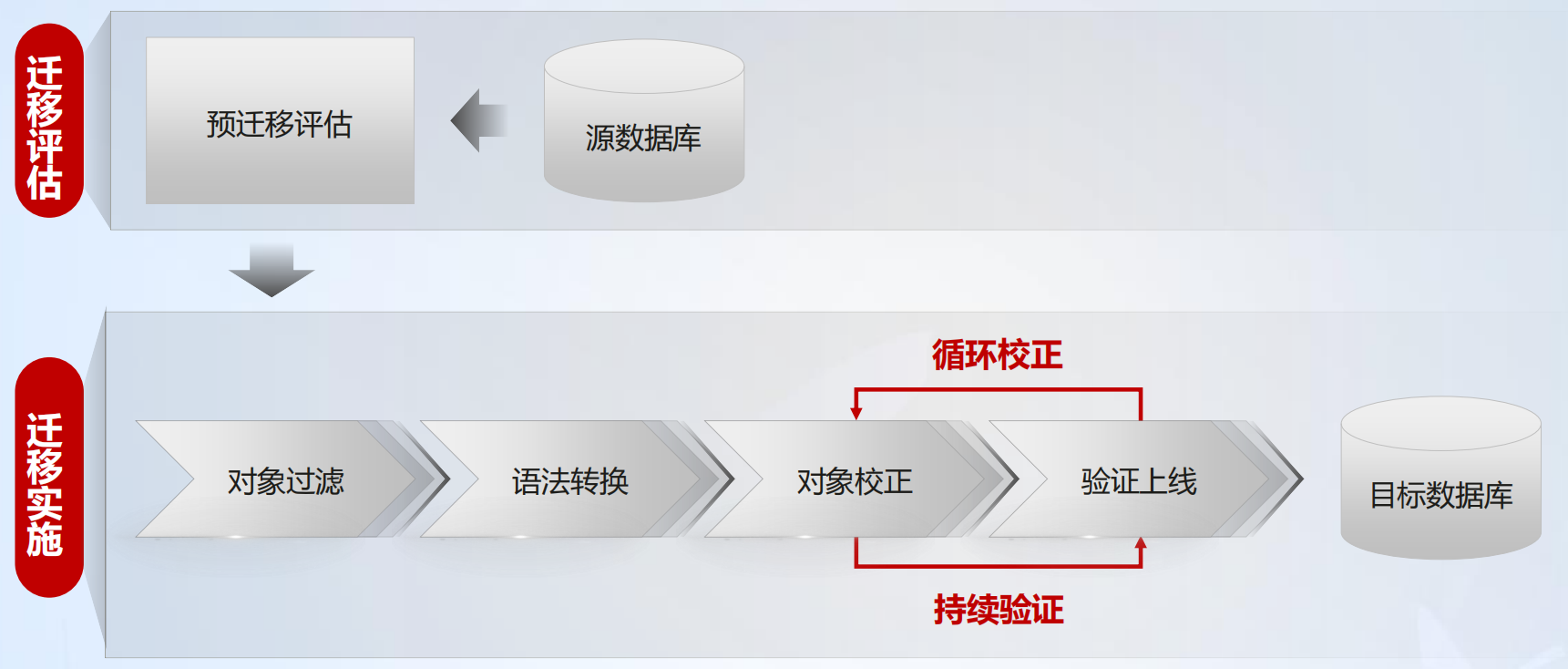
创建数据库评估任务,连接源库进行基本信息采集、性能数据采集,以及特定对象类型的源库对象 SQL 采集,基于采集的数据进行源库画像、数据库特性分析、到各个目标数据库的语法兼容性评估。综合兼容性、性能、对象复杂度、使用场景等为用户智能化推荐目标数据库选型与规格,工作量评估以及迁移风险评估,帮助客户决策与工作规划。
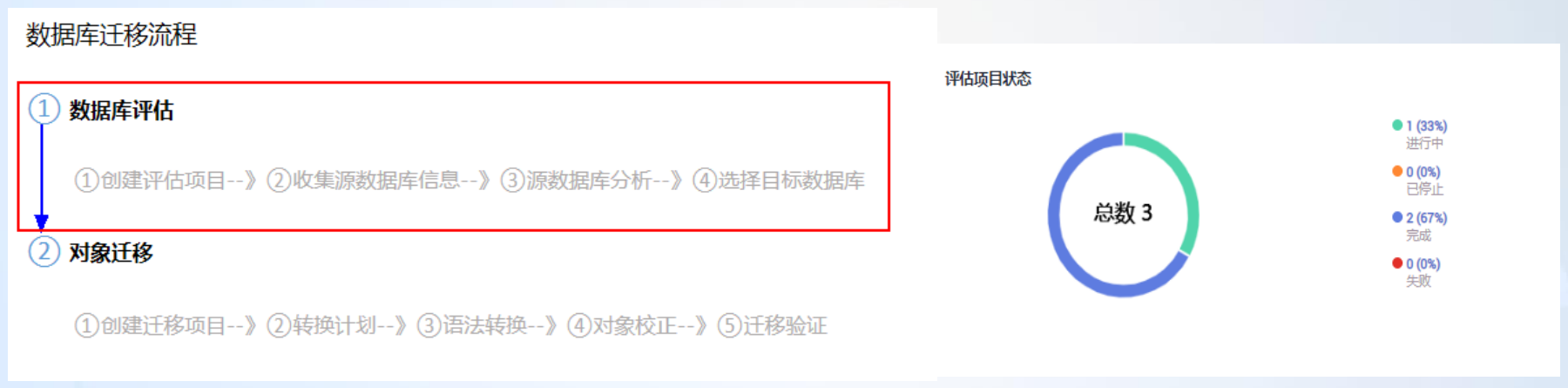
评估详细流程:创建评估项目→收集源数据库信息→源数据库分析→选择目标数据库,具体如下图所示:
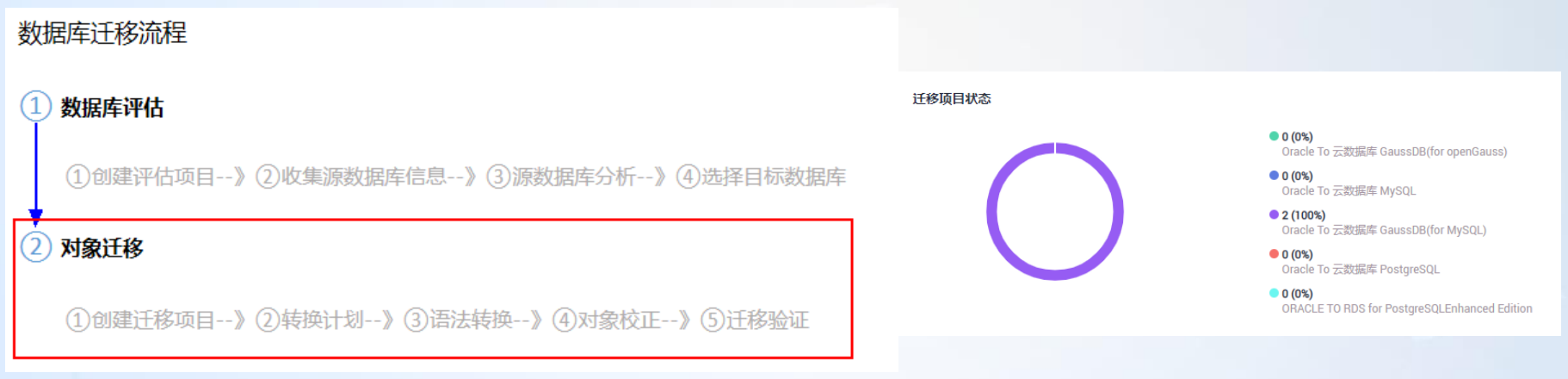
创建数据库对象迁移任务,选择需要迁移的评估任务,连接目标数据库,针对一些有风险的迁移场景,用户参与迁移方案的配置,然后在进行自动化的迁移,将源库 SQL 转换为目标库 SQL,最后将转换的 SQL 在目标库进行验证&应用,帮助客户实现异构数据库之间的自动化搬迁。
迁移详细流程:创建迁移项目→转换计划→语法转换→对象校正→迁移验证,具体如下图所示:
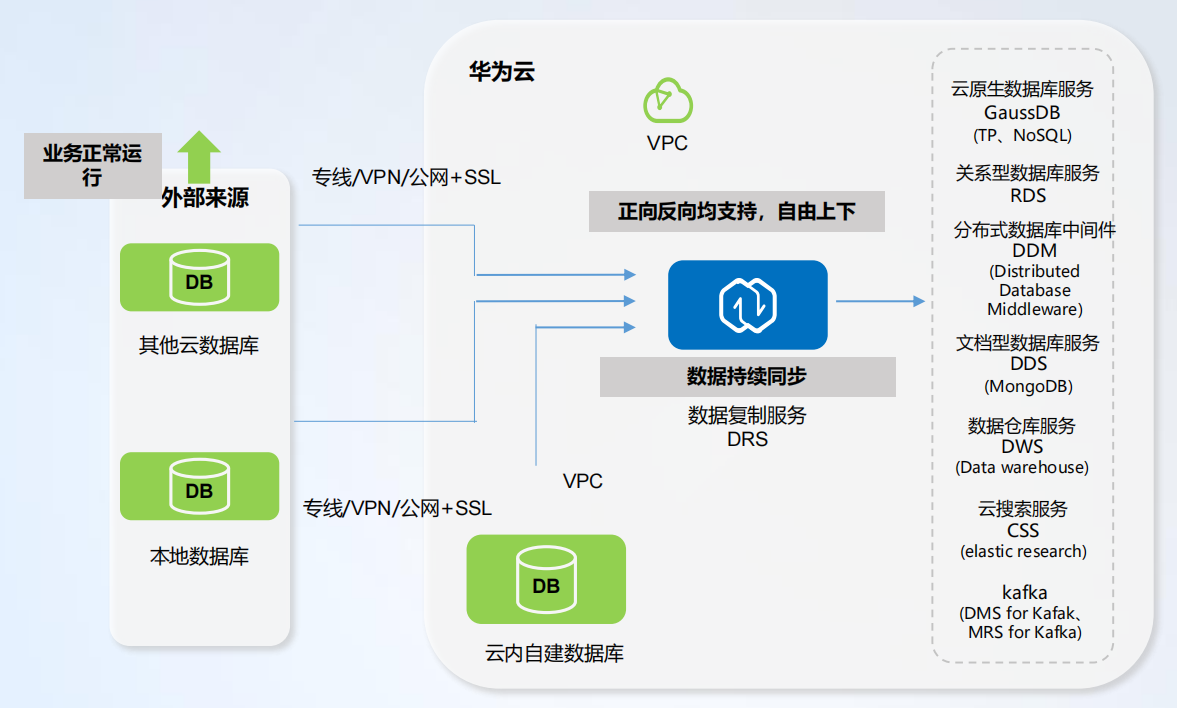
数据复制服务(Data Replication Service,简称为 DRS)是一种易用、稳定、高效,用于数据库在线迁移和数据库实时同步的云服务。DRS 围绕云数据库,降低了数据库之间数据 流通的复杂性,有效地帮助您减少数据传输的成本,具体如下图所示:

数据库迁移不影响业务,安心 + 省心 + 信心!
有上云担忧?
- 云数据库架构先进,更低成本,但是担心迁移影响业务,选择继续隐忍机房高成本,业务浪涌的担忧?
- 数据库迁移技术门槛太高,很多细节和坑点我们公司没人懂,怎么迁?
- 数据绝对不能丢,业务现状虽不尽如人意,但迁之后业务表现怎么样,如何预知?
担心数据来源?
- 数据仅来源于其他云厂商、本地机房、云内自搭建 DB。
上云成功之后为您提供:
- DRS 保障业务安心:先进的增量数据同步技术,业务运行中持续搬迁 数据库,迁移不影响业务。
- DRS 高质量迁移省心:华为上万案例提炼,百项检查自动识别问题,跟随指引操作,秒变专家,人人都能干好迁移。
- DRS 让业务切换有信心:提供数据对比,提供业务流量云上试运行,上云数据和性能提前可知可见,业界独有。
数据同步黑科技加持,保证全场景安心迁移,具体如下图所示:
硕果累累,普惠千行百业,包括但不限于以下客户,具体如下图所示:

- 全球 2000+ 企业规模商用:覆盖金融、政府、电信、互联网等行业。
- 全球 15000+ 任务:同城 ms、异地 s 级同步速度。
企业级端到端数据实时流转平台级产品,集在线迁移、多活灾备、实时同步能力为一体,并荣获 2019DTCC 大奖、信通院迁移最高级评级。
DRS 在线迁移示意图具体如下图所示:
华为云 DRS 当前迁移能力具体如下表所示:
DRS 技术原理包括全量同步和增量同步两个方面,详情具体如下图所示:
全量同步技术实现业务流程具体如下图所示:
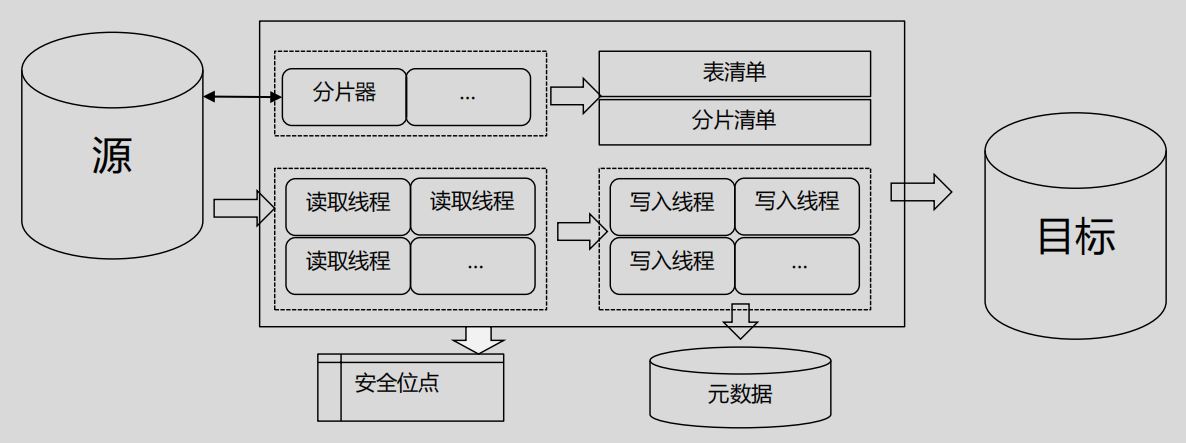
- 分片器:对要同步的表进行分片。无主键表不进行分片;分区表按分区进行同步,不再对每个分区进行分片;有主键表按主键(第一列)进行分片。
- 读取线程:从原库通过 select 的方式读取数据。
- 写入线程:将读取的数据写入到目标库,openGauss 采用 copy 高速接口进行写入。
- 安全位点:记录同步的断点,重启可以继续同步上次未完成的分区。
- 元数据:管理原库和目标库元数据信息,并进行映射转换。
增量并行回放技术实现业务流程具体如下图所示:
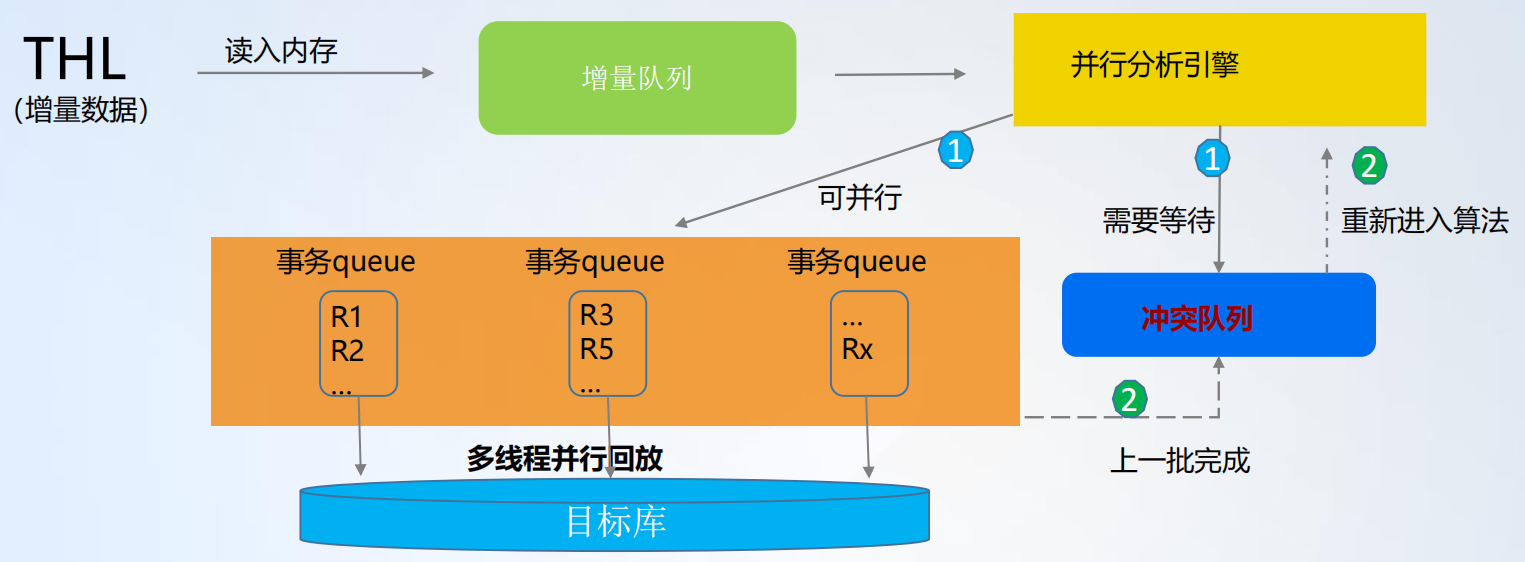
- 并行分析引擎根据主键或唯一键信息检查记录之间是否存在冲突,将没有冲突的记录分发到多个线程的队列中,多线程并行将这些记录写入到目标库。
- 对于有冲突的记录,则放入冲突队列等待上一批无冲突数据执行完成,上一批数据执行完成后,再将冲突队列的数据重新放回并行分析引擎重新分析。
基于默克尔树的快速比对算法,让对比结果不再漫长等待。
第一步:默克尔树比对,具体如下图所示:
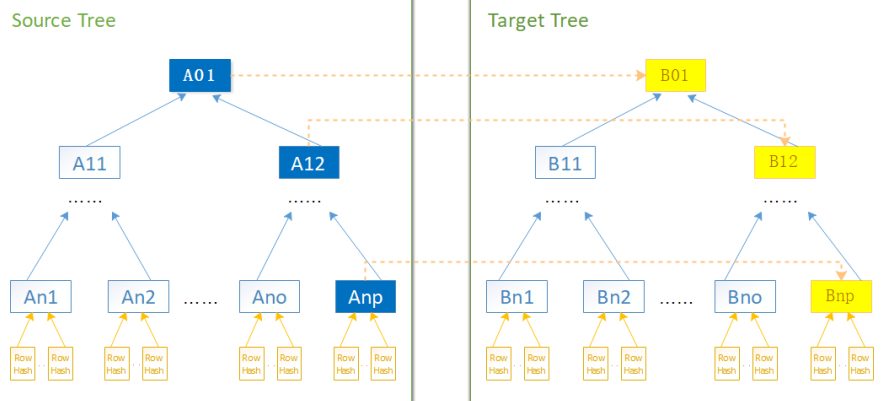
进行数据比对时,从默克尔树的根节点开始进行比对,如果根节点一样,则表示两个副本目前是一致的,不再需要任何处理;如果不一样,则遍历默克尔树,定位到不一致的节点。
第二步:不一致行数据定位,具体如下图所示:
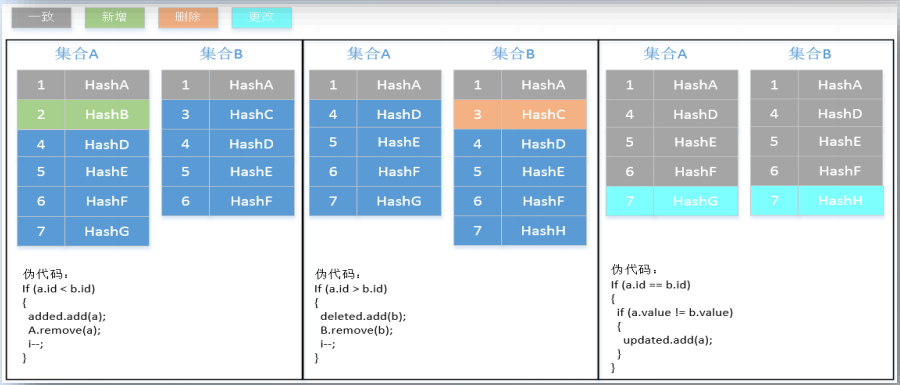
默克尔树的叶子节点是一系列行数据的聚合,采用异或得到该哈希值。因此定位到不一致的节点后,还需要进一步定位到不一致的行。先对该叶子节点下的数据行按照主键进行排序,然后对比两边的值,直到找到不一致的行数据。
生态工具开放能力清单可以查询生态工具的主要功能和描述,具体如下表所示:
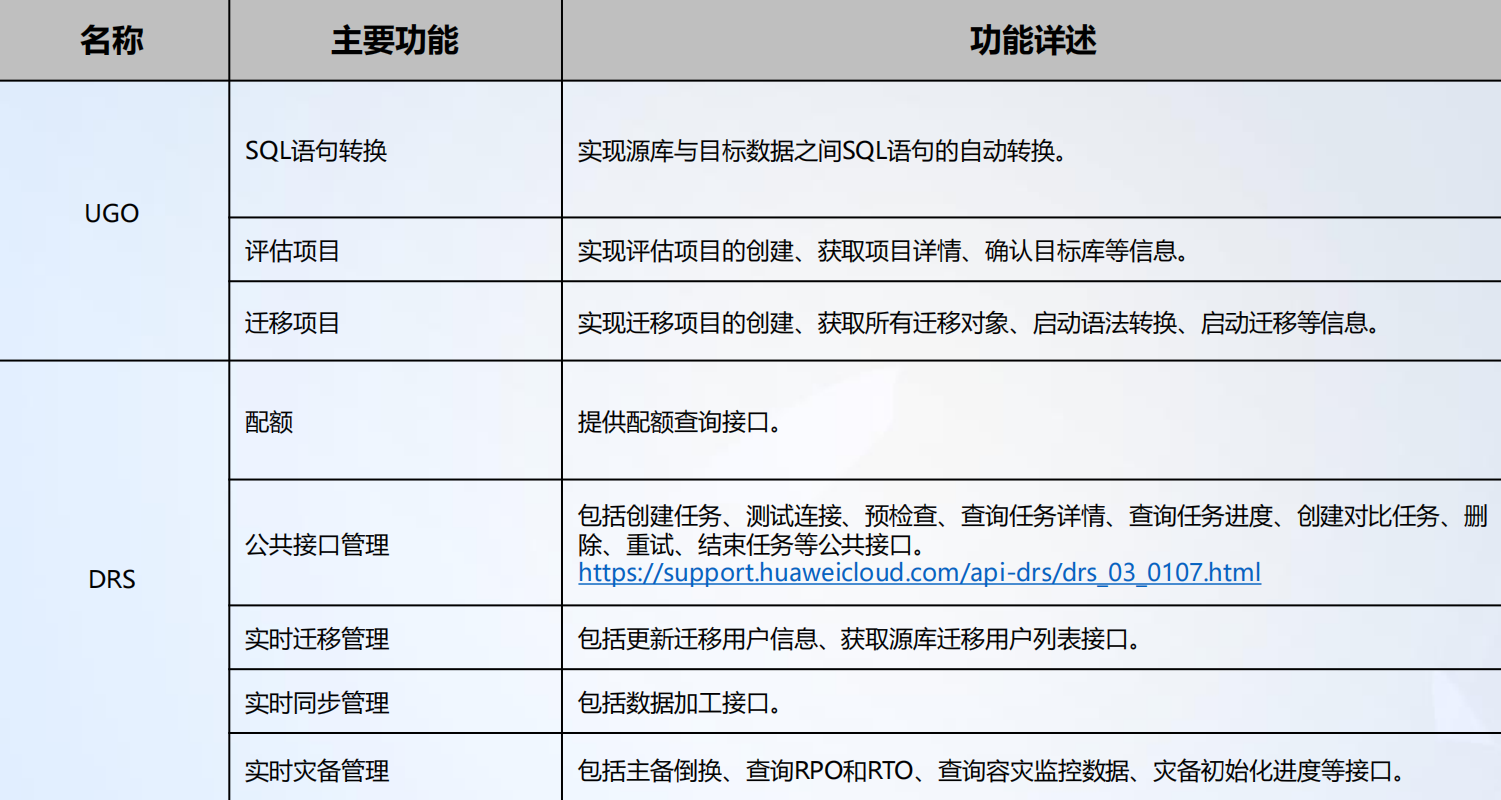
DRS OpenAPi 调度流程示意:https://support.huaweicloud.cn/api-drs/drs_03_0127.html


- 点赞
- 收藏
- 关注作者
评论(0)