DTSE Tech Talk | 3招解决时序数据高基数难题,性能多维度提升!

本期《openGemini全新列存引擎,为您解决时序数据高基数难题》的主题直播中,华为云开源DTSE技术布道师&数据库创新Lab技术专家黄飞腾,与开发者朋友们分享了时序数据库的特点和遥测数据应用场景下的优势,通过解析openGemini的框架引出了数据库行业长期存在的一大痛点—由于高基数导致的性能大幅下降,并向大家介绍了openGemini时序数据库针对这一难题而开发的列存引擎是如何有效改善高基数带来的不利影响。
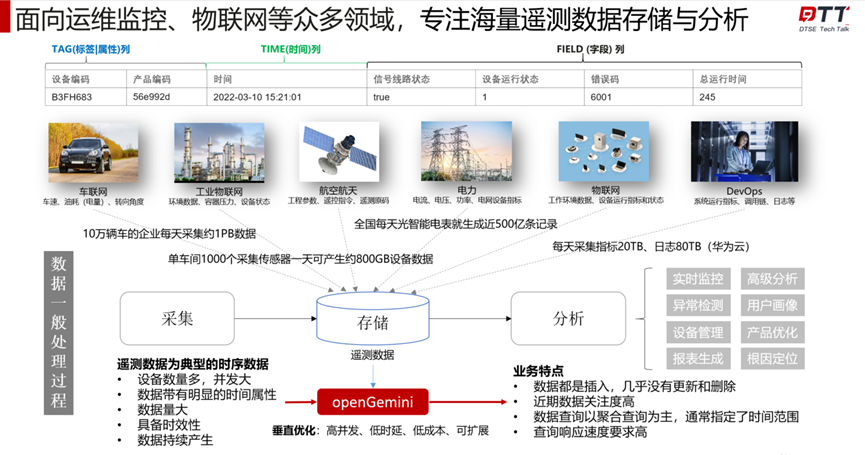
为什么面对海量遥测数据,时序数据库才是更佳选择?
市面上有很多不同类型的数据存储系统,它们在不同场景具有不同的优势和局限性。那海量遥测数据场景下,我们应该选择什么类型的数据库呢?先感受一下遥测数据的庞大,全国每天光智能电表就能生成500亿条记录,10万辆车的企业每天采集约1PB数据。海量的数据产生后给存储带来了巨大的压力,传统数据库已不能满足如今的实际业务需求。因此,面向运维监控、物联网等众多领域,专注海量遥测数据存储与分析的时序数据库应运而生。
以openGemini时序数据库为例,它具有高并发、低时延、低成本的特性,完美契合企业的需要。更重要的是,openGemini框架中自带全新开发的“列存引擎”,重点解决时序高基数问题,为性能保驾护航。
高基数会带来什么样的问题?
首先了解一下基数是什么,基数:表示某一列数据中唯一值的个数。
那高基数就可以理解为一个列中不同值的数量很大。不同的标签或者列有不同的基数,如 ip 地址基数可能达到亿级,时间戳则与采样频率相关,采样频率越高则基数越高。
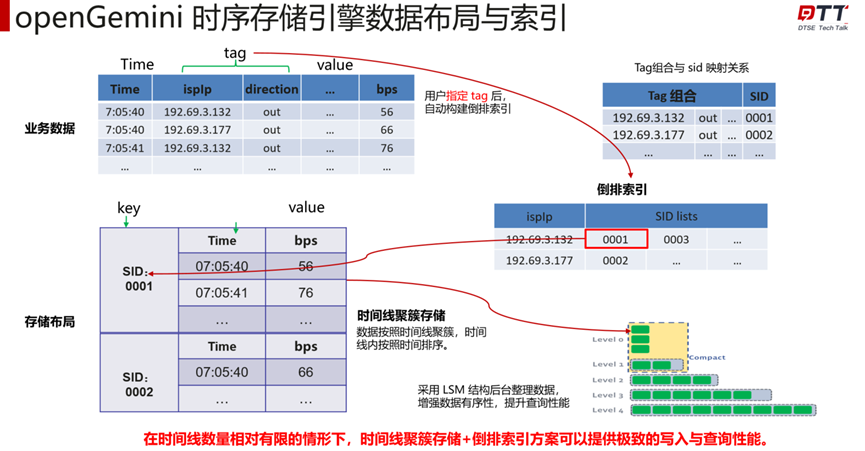
在高基数的场景下,tag组合数量、SID数量会急剧膨胀,倒排索引中的 SID lists 膨胀,导致倒排索引的维护与查询开销增大。
最终,对外表现的性能会急剧下降,那高基数给时序引擎带来的具体问题为:
- 内存资源
- 读写性能下降
openGemini如何应对高基数问题?
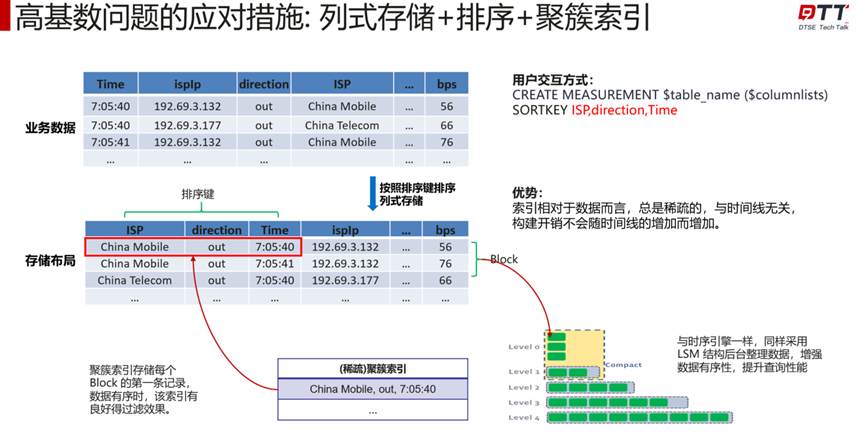
openGemini目前解决该问题应对措施为:列式存储+排序+聚簇索引。
简单来说,我们把时间线的约束去掉,采取部分的标签和列做排序,排序完成后会按照排序键排序列示存储,存储之后再构造一个稀疏(聚簇)索引,这样的优势是:索引相对于数据而言,总是稀疏的,与时间线无关,构建开销不会随时间线的增加而增加。聚簇索引存储每个 Block 的第一条记录,数据有序时,该索引有良好得过滤效果。
列存引擎和时序引擎最主要的差别是数据排序的方式和索引方式的不同。时序引擎是按照时间线力度来做聚簇,然后再按时间做排序。而高基数列存引擎是按照特定的列做排序,跟时间线无关。时序引擎采用倒排索引,时间线膨胀会导致倒排索引的开销变大,列存引擎的构建与时间线无关。继而以上的列存引擎设计思路可以大大提升数据库的读写性能。
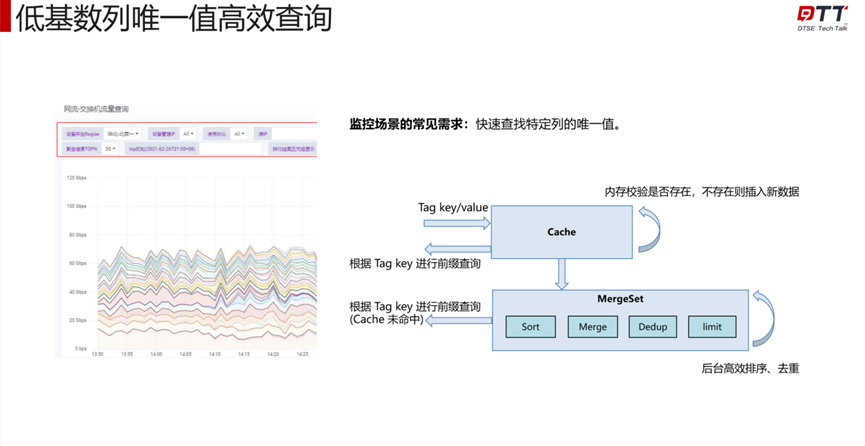
时序引擎的倒排索引,本质上存储了一个 kv 对,其中 key 对应到所有的 tag 列名 + tag 值,value 对应该 tag 值所对应的所有时间线,所以通过倒排索引可以快速查找到特定 tag 列的所有唯一值。如果没有倒排索引,则需要完全扫描该列数据,并进行去重,查询开销与数据量成正比,在数据量较大的情形,开销非常大。新引入的列式存储方案,基于现有倒排索引对 key 的去重能力,直接存储了该列的唯一值。
手把手教你轻松使用列存引擎
openGemini 从 v1.1.0 版本开始支持列存引擎以及 Arrow 协议。
文档:https://docs.opengemini.org/zh/guide/features/high_series_cardinality.html
Arrow Flight 配置

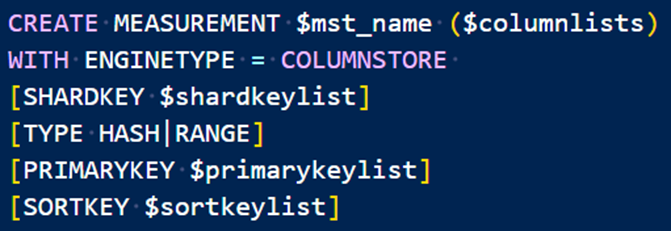
创表
接下来请查看实操演示视频,复制链接查看直播完整版:https://bbs.huaweicloud.cn/live/DTT_live/202311151630.html
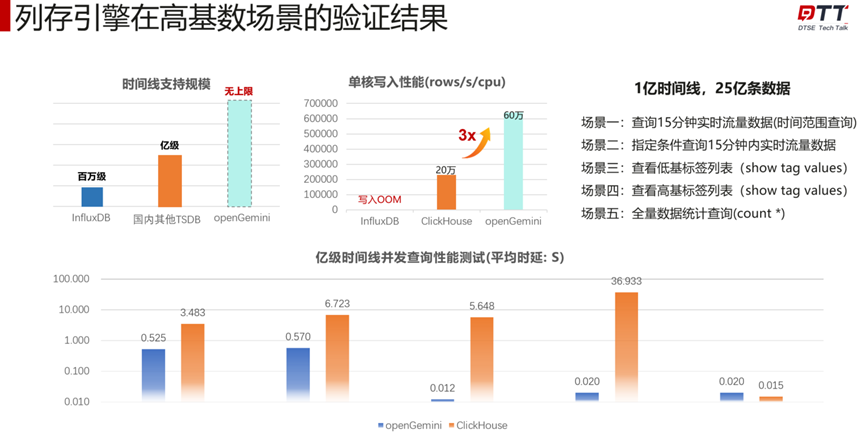
列存引擎在高基数场景的验证结果
如下图所示,与其他数据库做测试对比,从时间线支持规模来看,openGemini达到无上限;单核写入性格提升到60万rows/s/cpu;
在特定4个场景下,亿级时间线并发查询时延都远远低于测试产品,最低时延为0.012s。在全量数据统计查询场景下,openGemini与对比产品基本相当,整体时延都非常低。总体看,openGemini不论是写入还是查询,性能都十分优秀。
欢迎大家加入openGemini社区
openGemini社区旨在打造开放、合作、包容的全球性技术社区,社区正在快速发展中,接下来会聚焦于开发更多功能,对性能进行调优。社区尚有理想未达,在此诚邀大家参与openGemini的建设(不限于代码、文档、生态贡献),同社区一起成长,彼此携手方能到达远方。


- 点赞
- 收藏
- 关注作者
评论(0)