21.10 Python 使用CRC32校验文件

CRC文件校验是一种用于验证文件完整性的方法,通过计算文件的CRC值并与预先计算的CRC校验值进行比较,来判断文件是否发生变化,此类功能可以用于验证一个目录中是否有文件发生变化,如果发生变化则我们可以将变化打印输出,该功能可用于实现对特定目录的验证。
首先实现文件与目录的遍历功能,递归输出文件或目录,在Python中有两种实现方式,我们可以通过自带的os.walk函数实现,也可以使用os.listdir实现,这里笔者依次封装两个函数,函数ordinary_all_file使用第一种方式,函数recursion_all_file使用第二种,这两种方式都返回_file列表,读者可使用列表接收输出数据集。
import os,hashlib,time,datetime
from zlib import crc32
import argparse
# 递归版遍历所有文件和目录
def recursion_all_file(rootdir):
_file = []
root = os.listdir(rootdir)
for item in range(0,len(root)):
path = os.path.join(rootdir,root[item])
if os.path.isdir(path):
_file.extend(recursion_all_file(path))
if os.path.isfile(path):
_file.append(path)
for item in range(0,len(_file)):
_file[item] = _file[item].replace("\\","/")
return _file
# 通过自带OS库中的函数实现的目录遍历
def ordinary_all_file(rootdir):
_file = []
for root, dirs, files in os.walk(rootdir, topdown=False):
for name in files:
_file.append(os.path.join(root, name))
for name in dirs:
_file.append(os.path.join(root, name))
for item in range(0,len(_file)):
_file[item] = _file[item].replace("\\","/")
return _file
针对计算方法此处也提供两种,第一种Calculation_md5sum使用hashlib模块内的md5()方法计算特定文件的MD5特征,第二种Calculation_crc32则使用zlib库中的crc32方法计算特定文件的CRC32值,如下所示。
# 通过hashlib模块读取文件并计算MD5值
def Calculation_md5sum(filename):
try:
fp = open(filename, 'rb')
md5 = hashlib.md5()
while True:
temp = fp.read(8096)
if not temp:
break
md5.update(temp)
fp.close()
return (md5.hexdigest())
except Exception:
return 0
# 计算目标CRC32
def Calculation_crc32(filename):
try:
with open(filename,"rb") as fp:
crc = crc32(fp.read())
while True:
temp = fp.read(8196)
if not temp:
break
return crc
except Exception:
return 0
return 0
在主函数中,我们通过argparse解析库传入参数,并分别实现三个功能,其中使用dump功能可以保存特定目录内文件的hash值到dump.json文件中,其次check功能可用于根据dump.json中的内容检查文件是否被改动过,最后的set则可用于批量设置文件的时间戳,这三类功能都属于较为常用的。
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--mode",dest="mode",help="指定需要使用的方法名称,(set/dump/check)")
parser.add_argument("-d","--dir",dest="dir",help="指定一个需要遍历的文件目录(非文件)")
parser.add_argument("-f","--files",dest="files",help="指定一个本地快照文件,或转储的文件名称")
parser.add_argument("-t","--time",dest="time",help="指定需要统一修改的文件时间")
args = parser.parse_args()
# 保存快照: main.py --mode=dump -d "D:/lyshark" -f dump.json
if args.mode == "dump" and args.dir and args.files:
file = recursion_all_file(args.dir)
fp = open(args.files,"w+")
for item in file:
Single = []
Single.append(Calculation_crc32(item))
Single.append(item)
fp.write(str(Single) + "\n")
print("[+] CRC: {} ---> 路径: {}".format(Single[0],Single[1]))
fp.close()
# 检查文件完整性: main.py --mode=check -d "D:/lyshark" -f dump.json
elif args.mode == "check" and args.dir and args.files:
fp = open(args.files,"r")
for item in fp.readlines():
_list = eval(item)
# 取出json文件里的目录进行MD5计算
_md5 = Calculation_crc32(_list[1])
# 如果该文件的md5与数据库中的记录不一致,说明被修改了
if _list[0] != _md5 and _md5 != 0:
print("[-] 异常文件: {}".format(_list[1]))
elif _md5 == 0:
print("[x] 文件丢失: {}".format(_list[1]))
# 设置文件修改时间: main.py --mode=set -d "D:/lyshark" -t "2019-01-01 11:22:30"
elif args.mode == "set" and args.dir and args.time:
_list = ordinary_all_file(args.dir)
_time = int(time.mktime(time.strptime(args.time,"%Y-%m-%d %H:%M:%S")))
for item in _list:
os.utime(item,(_time, _time))
print("[+] 时间戳: {} ---> 路径: {}".format(str(_time),item))
else:
parser.print_help()
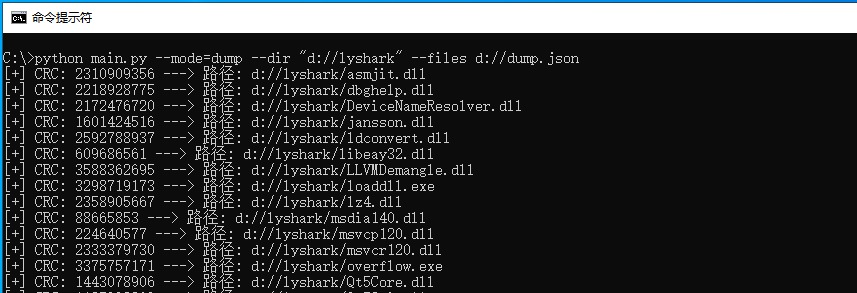
指定mode模式为dump用于实现将特定文件计算CRC特征,并将该特征保存至dump.json文件内,如下图所示;
指定mode模式为check并指定转存之前的dump.json文件,则可用于验证当前目录下是否存在异常文件,如果文件特征值发生了变化则会提示异常文件,而如果文件被删除或被重命名则会输出文件丢失,如下图所示;

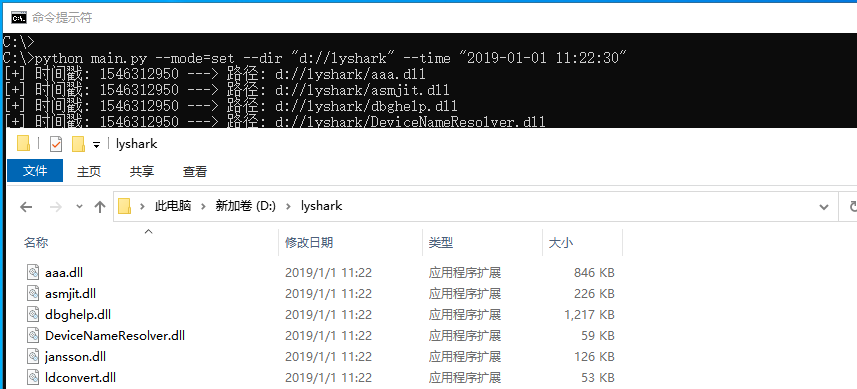
指定mode模式为set则可实现对特定目录内特定文件修改时间参数,例如将d://lyshark目录内的文件全部重置时间戳为2019-01-01 11:22:30则可执行如下命令,执行后读者可自行观察文件时间变化,如下图所示;
文件与目录遍历功能,不仅可以用于对文件的特征扫描,还可以与fopen等函数实现对特定文件内特定内容的扫描,如下是一段实现对文件内特定目录的关键字扫描,运行后读者通过传入需要扫描的路径,扫描的关键字,以及需要扫描文件类型即可。
import os,re
import argparse
def spider(script_path,script_type):
final_files = []
for root, dirs, files in os.walk(script_path, topdown=False):
for fi in files:
dfile = os.path.join(root, fi)
if dfile.endswith(script_type):
final_files.append(dfile.replace("\\","/"))
print("[+] 共找到了 {} 个 {} 文件".format(len(final_files),script_type))
return final_files
def scanner(files_list,func):
for item in files_list:
fp = open(item, "r",encoding="utf-8")
data = fp.readlines()
for line in data:
Code_line = data.index(line) + 1
Now_code = line.strip("\n")
#for unsafe in ["system", "insert", "include", "eval","select \*"]:
for unsafe in [func]:
flag = re.findall(unsafe, Now_code)
if len(flag) != 0:
print("函数: {} ---> 函数所在行: {} ---> 路径: {} " .\
format(flag,Code_line,item))
if __name__ == "__main__":
# 使用方式: main.py -p "D://lyshark" -w eval -t .php
parser = argparse.ArgumentParser()
parser.add_argument("-p","--path",dest="path",help="设置扫描路径")
parser.add_argument("-w","--word",dest="func",help="设置检索的关键字")
parser.add_argument("-t","--type",dest="type",default=".php",help="设置扫描文件类型,默认php")
args = parser.parse_args()
if args.path and args.func:
ret = spider(args.path, args.type)
scanner(ret, args.func)
else:
parser.print_help()
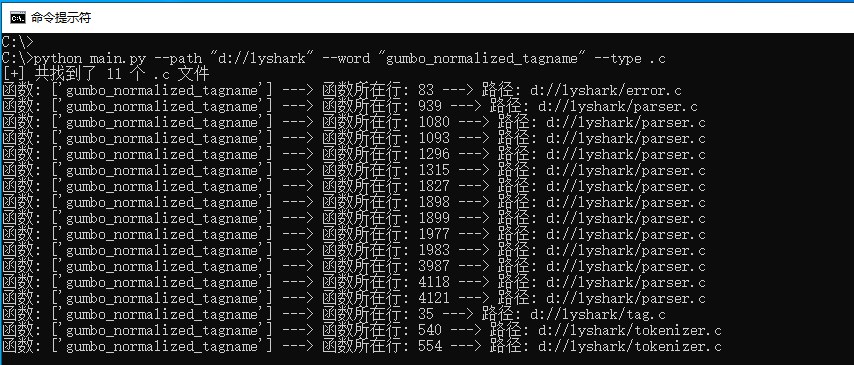
如下图所示,我们通过传入d://lyshark以及关键字gumbo_normalized_tagname并设置扫描后缀类型*.c当程序运行后,即可输出该目录下所有符合条件的文件,并输出函数所在行,这有利于我们快速跳转并分析数据。

- 点赞
- 收藏
- 关注作者
评论(0)