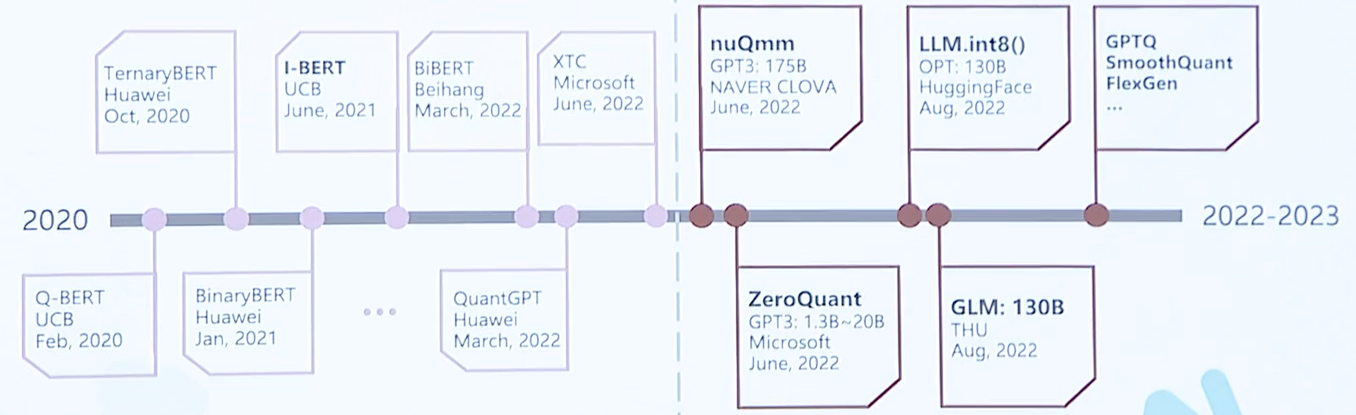
【云驻共创】盘古基础模型能力解密

背景和趋势
LLM推理趋势
- 模型大、推理慢、成本高
- 长序列
- 多模态
- Cache, Embeddings,和向量数据库
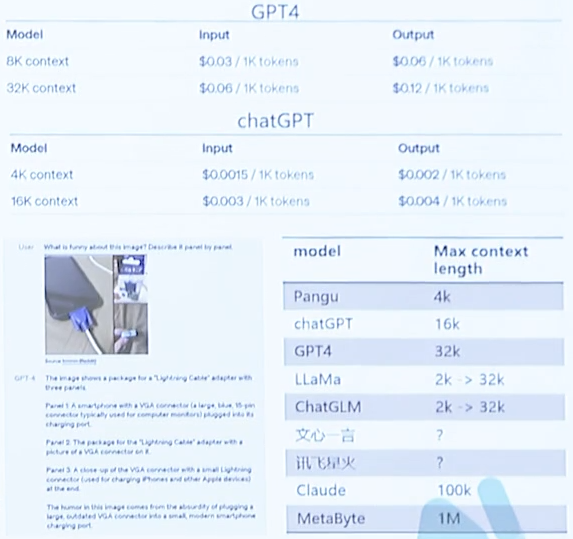
三种典型部署场景及解决方案
- 低时延(用户给定一个prompt希望更快得到答复):更多机器,模型并行,batch size=1
- 长序列(例如新闻摘要业务):全面推理计算瓶颈,增加推理内存瓶颈
- 高吞吐:降低生成每个token的成本,提升batch size
生成式模型的原理
生成式模型的推理过程主要包含两部分:
- 全量推理:这个过程中,用户给一个query,然后输出第一个token。
- 增量推理:这个过程要反复执行多次,一般生成多少个token就要执行多少次减一。

这两个过程所面临的难点是不一样的
- 全量推理:计算密集(每次计算一个token;一个大的权重矩阵 * 一个小的输入向量)
- 增量推理:访存密集(加载大的权重矩阵;加载大的kv cache和序列长度成正比)

大模型的核心三要素
- 模型表现强烈依赖于模型规模,弱依赖于架构
- 模型表现随着计算量(Compute)、数据量(Dataset Size)、和参数量(Parameters)提升

- 模型表现随着训练数据量和参数量的提升是可以预测的

训练超大规模模型三大挑战
大模型训练难点
- 训练资源需求大:假设一万参数训练至少需要静态内存+动态内存4万GB(1250卡)
- 模型能力要求强:客户行业/任务分散,算力/人力成本高,模型必须具备三种能力
- 服务成本高:万亿参数模型服务至少需要3000GB(95卡)
盘古大模型面临的设计难点
- 对于“训练资源需求大”要解决:如何在有限资源(如512卡D910)高效训练
- 对于“模型能力要求强”要解决:如何提高算法精度、多任务学习、终生学习
- 对于“服务成本要求高”要解决:如何在单Server内(8卡)提供有效服务
盘古-Sigma架构诞生
因此,盘古大模型在设计的时候,除了要考虑如何应对上述挑战,还要考虑如何设计才能让模型有更好的延展性,可以基于该模型底座持续的研发和迭代更新。
针对上述问题与挑战,盘古大模型设计了Sigma体系,它采用了存算分离的稀疏架构,通过不断的代码优化,实现了最优算法效率和最优系统效率,一举解决了三大难题
盘古-∑架构设计理念
从稠密到稀疏的模块化扩展
华为云最早设计的是盘古α这种稠密的架构。盘古∑架构是基于盘古α进行演进的一种更先进的架构。
盘古∑模型首先继承了盘古α稠密模型的权重,同时高效扩展了模型的transformer层,将其中的部分用稀疏模型进行扩展。总所周知,神经网络中越高层级的学习到的是一些越具体的知识,越下层的学习的是一些越抽象的知识。而由于上层主要用来存储知识,这项改动能大大提升了模型知识存储的容量。而稀疏模型的推理成本仅仅相当于稠密的Num_Expert分之一,有绝对的优势

模块化终生学习
- FFN2MOE:继承盘古alpha的知识,加速收敛
- 两级分层随机专家路由:任务-专家细粒度控制;专家负载均衡;分组All-to-All通信节约
- 专家编辑:支持任意新增、修改、删除专家;分组专家裁剪,单领域模型极致部署
- 领域Embedding扩增技术:单语言到多语言扩增;单领域到多领域扩增

高性能异构训练-最优系统效率
传统训练仅采用GPU或CPU(GPU比CPU快很多,所以绝大部分训练都是采用GPU)
而盘古Sigma模型采用CPU+GPU的方式进行训练,采用存算分离+稀疏模型的方式,每次技术的时候只将其中的一部分子图给抽象出来,然后前向后向的时候只计算某个网络中的一部分,并且只传输这一部分的梯度值,这样就可以大大提高了模型的算力和计算效率。

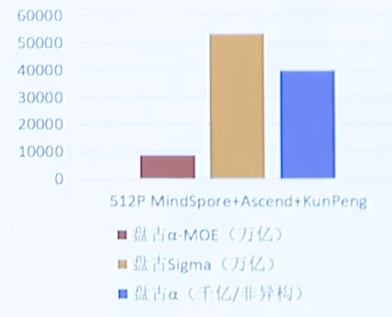
这是1.085万亿参数盘古Sigma西安超算吞吐性能(Tokens/s)(使用了存算分离+稀疏模型后,吞吐量大概提升了6倍)
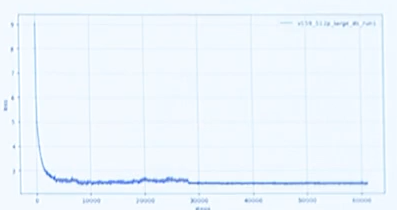
以及1.085万亿参数盘古Sigma收敛曲线(持续稳定训练中)
中文基础任务精度-最优算法效率
下图是盘古Sigma与百度ERNIE3.0执行10个中文下游任务ZERO-SHOT测评的各项参数对比(可以看出盘古大模型中文子模型各项精度,都远超2600亿参数的百度ERNIE3.0)

压缩加速技术
针对上文提到的生成式模型推理的原理,盘古大模型采用了如下的加速方案
模型大、推理慢
主要是内存占用问题
- 模型:例如175B这种千亿模型需要占用350GB内存
- kv cache:显存占用和序列长度成正比,175B模型4k长度占用576G
解决方案
- 模型压缩:4/8-bit权重量化算法QuantGPT。昇腾亲和量化算子使得模型内存降低2倍,推理加速20-30%
- kv cache压缩:kv cache 8-bit量化之后内存占用降低50%+
长序列

长context length
- 全量推理的O(n^2)计算复杂度
- 内存高效的Attention算子:单算子支持256k长度
- 增量推理的O(n)内存复杂度
- kv cache多级多维度卸载
- Recomputation:kv部分缓存,部分计算
长decode length
- 对话历史cache:检索换计算
- 拷贝机制和投机小模型:检索与计算融合
高效部署
CPU高效解码
- 解码策略优化
- 并行编码
- 高效sort
- Sampling算子
- softmax算子

全量和增量分离部署
- 全量推理 -> batch size=1 改进时延
- 增量推理 -> 大 batch size 提升吞吐
动态batch:
- 解码完成的样本提前退出
- 及时补进新的样本
量化
LLM模型(例如BERT/GPT2)最早是采用低比特、高精度的这种方式,但随着模型规模到达百亿、千亿,慢慢演变为了后量化这种技术
生成式模型可以做很多种量化
- 权重量化:量化完之后模型就小了,模型所占用的内存就小了,增量推理需要加载的权重也少了,这样做以后就有一个整体的降低内存和加速的效果
- 权重量化 + 输入量化:这个技术在以前计算密集的,像BERT这种模型中用的最多的技术。但是在盘古模型上我们是不用的,因为增量推理主要是访存密集的,该方案在精度上会造成较大的损失
- 权重量化 + kv cache量化:主要是因为kv cache如果在长序列模型大的情况下,可能会占用非常大的内存。如果和权重一起使用的话,可以把整个推理系统的内存占用降下来,而且可以把整体通信降下来,达到一个加速的效果

权重量化: 8-bit量化模型权重内存占用降低一半,推理加速25%+
- Matrix-Vector单算子时延收益如下
- 伪量化算法(编辑距离)收益如下
- 时延收益如下

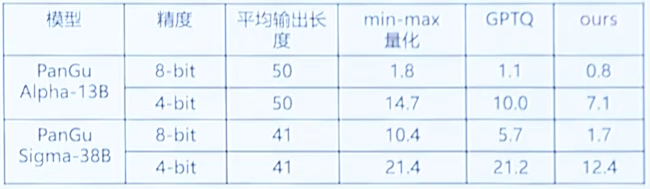

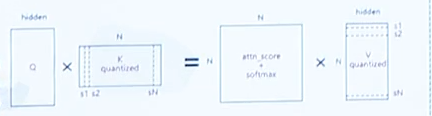
kv cache量化: 8-bit量化kv cache内存占用降低一半
- KV cache “per-channel” 量化
- 当前效果


搜索引擎
内部逻辑
LLM与搜索引擎的结合,作为搜索引擎的演进方向,可以较好地解决事实问题和时效性问题
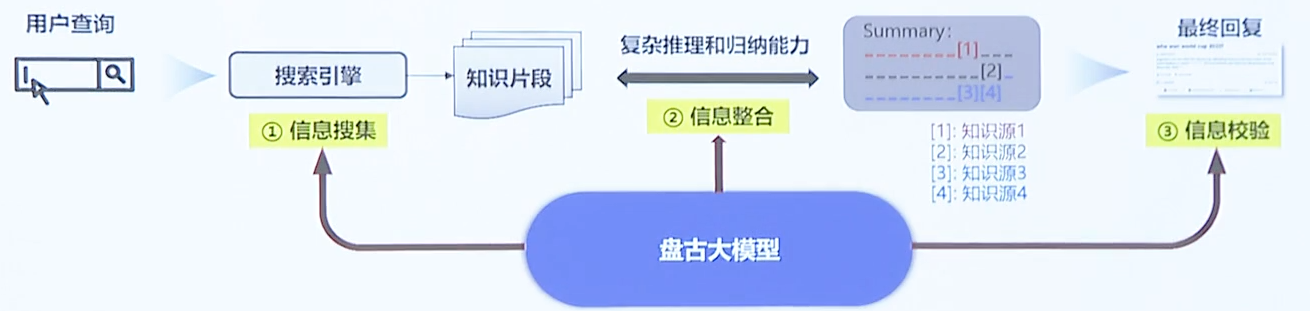
- 信息搜索:查询决策;查询语句生成;复杂查询语句分解;查询结果判别;查询结果摘要
- 信息整合:多文档总结与归纳;思维链推理;回复生成
- 信息校验:事实性校验;实时性校验;无害性校验
使用工具
- 在上下文学习能力较弱时:通过SFT实现外部工具调用
- 在上下文学习能力较强,但思维链能力还较弱时:通过自定义插件(只需提供插件的描述,无需SFT)实现插件调用(Plugin-in形式)
- 在思维链能力较强时:通过思维链进行任务分解,实现外部工具的规划、调用和搜索,以完成复杂任务(Agent形式,类AutoGPT形式)
通过SFT实现外部工具调用
例如:通过调用Python引擎完成常用数学计算和推理等日常任务
- 简单数学表达式
- 简单数学应用题
- 复杂数学应用题(鸡兔同笼:调用Sympy库)
- 表格处理(调用Pandas库)
- 日历查询(调用日历API)
- 单位换算
- 解微积分题
- 画函数曲线
通过插件形式调用工具
实现搜集很多插件,然后将每个插件写一个描述。盘古实现了一个类似搜索引擎的功能,根据用户描述然后去找一个插件,并调用该插件获取结果,最后整合并呈现出来

Agent形式通过调用外部工具解决复杂问题
通过类似思维链的技术,将任务进行分解,一步步的去求解,然后校验,全部解完后再将其进行整合

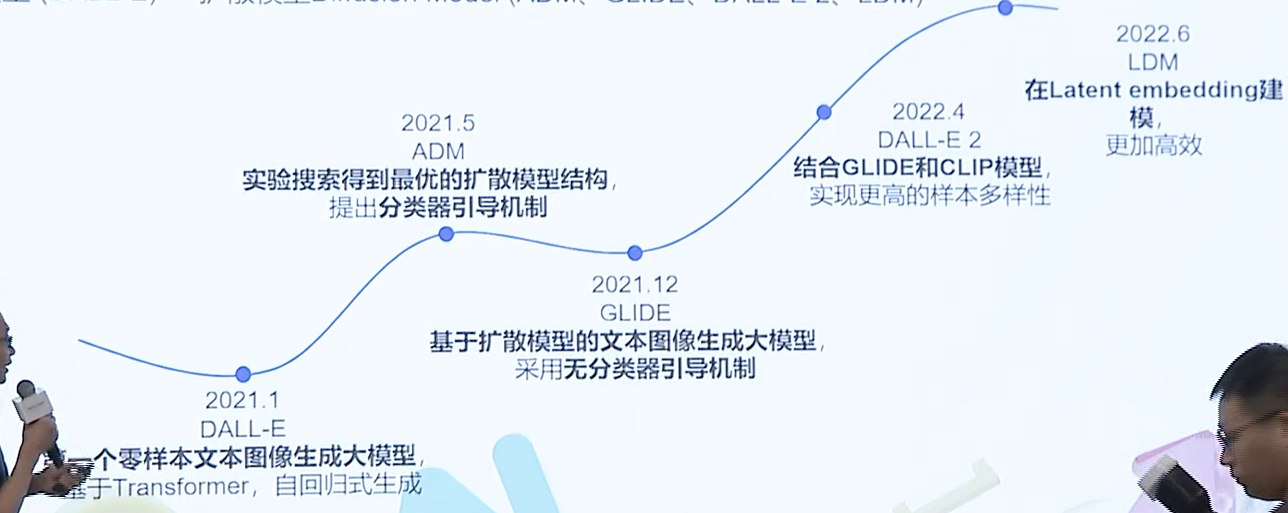
盘古画画文生图模型
发展历史
从自回归模型(DALL-E),慢慢演进到 扩展模型 Diffusion Model(ADM、GLIDE、DALL-E 2、LDM)
提升画质、艺术性、推理速度
盘古画画模型2.0在1.0的基础上,根据画质、图文匹配、艺术性及推理速度上多个方面进行尝试和更新,其中包括:
- 提升输出分辨率,支持原生768输出:512(v1)-> 768(v2)
- 提供两个版本服务:标准版以及艺术增强版。标准版更倾向于还原文本表达,艺术增强版能得到更好的艺术效果
- 基于A+M进行大规模多机多卡训练得到模型,全自研昇思平台和昇腾硬件910,训练相比N卡速度提升10%
- 自研Multistep-SED采样加速,50步采样降到20-30步,加速30-50%
- 采用自研RLAIF提升画质以及艺术性表达
- 训练数据扩充为原来盘古中文图文对数据的2倍+,并增加多种艺术数据

自研扩散模型的可控方差采样加速Multisetp-SED
DDIM一阶ODE求解器,最常用的采样方法,一般用迭代50步,使用新的采样技术Multistep-SDE,可以加速迭代至20-30步
Multistep-SED:使用Stochastic Linear Multi-step Methods进行Reverse SDE进行采样
- 引入随机性,提升生成图像的多样性,防止采样过程中陷入局部最优,提升采样质量
- 理论与实证计算得到采样算法最优的noise schedule,减少超参设置
效果:
- 采样步数较多(~20步)的情况下,可以生成高质量的图片
- 重点数据采集的采样性能上达到SoTA水平
自研基于RLAIF的Prompt自动优化功能(提高艺术性)
现有用户的实际输入往往是简短的,与盘古画画的训练输入(文本描述更全,且包含风格)不一致
因此我们基于RLAIF方案引入LLM(语言大模型)来对齐用户的实际输入与画画的所需输入

需要注意的是,prompt自动优化功能在端文本上效果会更加明显


基于多reward函数与RLAIF的文生图模型优化
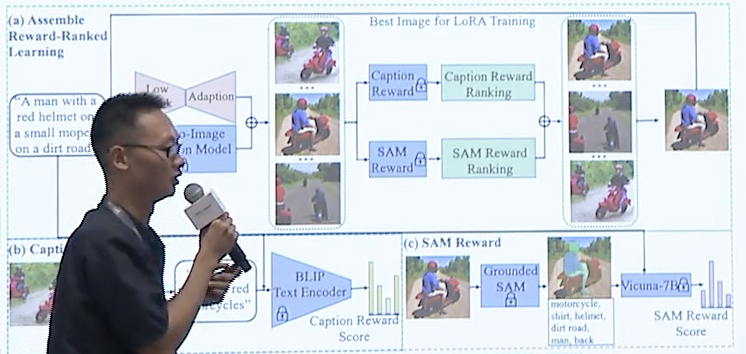
- 提出两种新的文图模型细粒度语义奖励Caption/SAM Reward
- Caption Reward:实验BLIP2模型为图像生成相应的详细标题,然后通过测量生成的标题与给定提示之间的相似度来计算奖励分数
- SAM Reward:使用Grounded-SAM模型将生成的图像分割成局部部分,并通过测量每个类别出现在提示场景中的可能来评分这些部分。这个可能性是通过大型语言模型(Vicuna-7B)计算得到的
- 提出联合多种奖励函数的组合排序优化策略来提升文图模型生成图片效果。
下面是细粒度语义奖励及组合优化排序策略图例
可视化及指标结果如下图
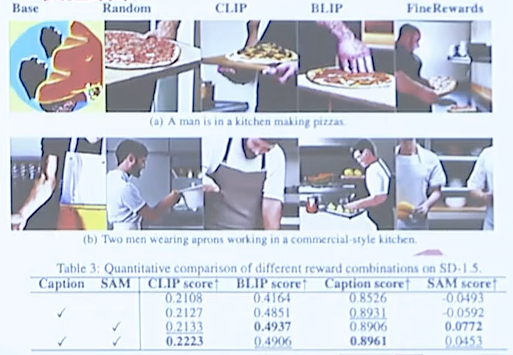
在全新技术的加持下,画画2.0在10k的中文MSCOCO-CN数据集上的FID、IS、CLIP score 评测中达到了最先进的性能,详细数据如下表所示:
基于扩散模型的文本-图像生成与对比学习模型DiffDis
- 提出基于DIffusion(扩散模型)架构的图文判别模型
- 统一多模态生成和判别预训练任务
生成/判别单一模型
生成和判别任务基于两套独立框架
- 生成模型:扩散模型
- 判别模型:多模态预训练对齐

生成判别统一模型
前向过程:类别文本/图像加噪->预测高斯噪声
逆向过程:基于文本条件的图像生成;基于图像条件的类别文本生成

实验结果
- 相对基准模型CLIP,DiffDis在12个数据集上的平均准确率提高了4.7%
- 在COCO上,DiffDis在12T检索和T2I检索的R@1方面分别优于CLIP-ViT-L/14,提高了11.6%和8.2%
- DiffDis模型与StableDiffusion相比在FID上取得了1.0的提升
下面是DiffDis与Stable Diffusion生成效果的对比图

新/旧两版画画效果对比
- 人像
- 传统任务
- 特定风格





总结
本文首先介绍了LLM(大语言模型)诞生的背景及其趋势,然后进一步讲解了现在的大模型面临技术难点及挑战,最终引出华为盘古大模型。在介绍盘古大模型的设计原理的同时,一步步给读者揭露盘古大模型是怎样处理并解决这些难题的,同时深入的介绍了盘古模型用到的压缩加速技术、搜索引擎技术、以及盘古画画文生图模型。通读全文,详细你对当今的AI技术,一定会有一个更深入的了解,同时期待华为盘古大模型上线的实际运用!
本文参与华为云社区【内容共创】活动第24期。
任务7:华为开发者大会2023(Cloud):盘古基础模型能力解密

- 点赞
- 收藏
- 关注作者
评论(0)