【云驻共创】昇思MindSpore2.0和模型开发实践

前言
昇腾AI基础软硬件平台包含华为Atlas系列硬件及伙伴自有品牌硬件、异构计算架构CANN、全场景AI框架昇思MindSpore、昇腾应用使能MindX和一站式开发平台ModelArts等。异腾AI基础软硬件平台,使能中国人工智能产业繁荣。
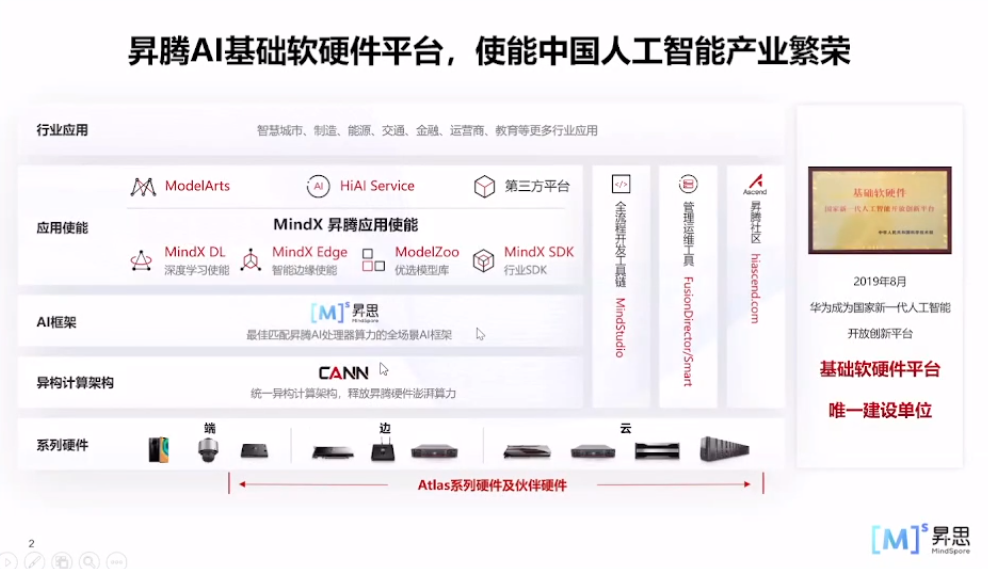
MindSpore是华为公司开发的一款开源AI计算框架,旨在为各种场景下的人工智能应用提供全面的解决方案。它具有灵活性、高性能和易用性的特点,适用于从边缘设备到云端的各种计算场景。
全场景AI框架昇思MindSpore,使能科研创新与产业应用。MindSpore的设计目标是让开发者可以更轻松地构建、训练和部署人工智能模型。它提供了一套完整的工具链,包括模型构建、训练算法、模型部署和推理推理等。

今天的主题主要有以下几个方面:深度学习训练原理简介,MindSpore函数式+面向对象融合编程范式,函数式自动微分,梯度操作,数据并行,模型迁移。
 一、深度学习训练原理简介
一、深度学习训练原理简介

1.1 深度学习全流程
1. 数据预处理:将图像、文本等数据处理为可以计算的Tensor。
2. 神经网络构建: 使用框架API,搭建神经网络。
3. 模型训练: 定义模型训练逻辑,遍历训练集进行训练。
4. 模型评估: 使用训练好的模型,在测试集评估效果。
5. 模型推理:将训练好的模型部署,新数据输入获得预测结果。

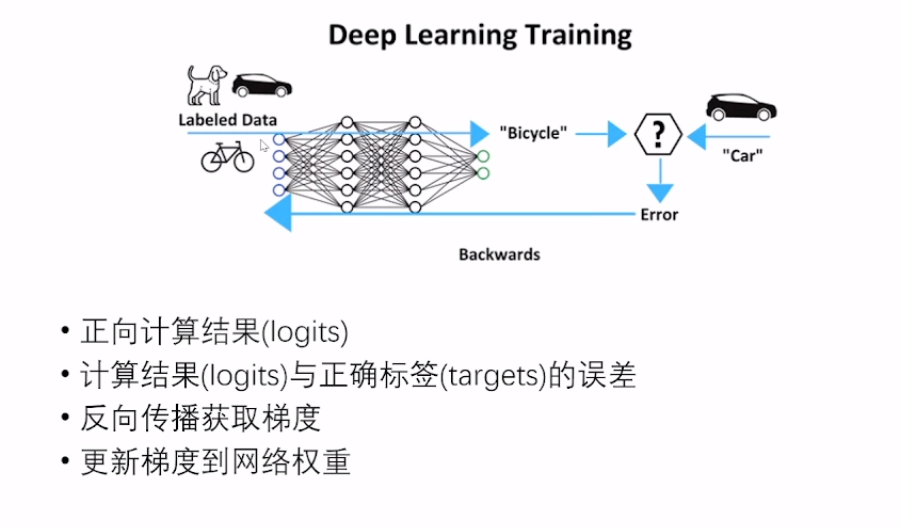
1.2 Deep Learning Training
二、MindSpore函数式+面向对象融合编程范式
2.1 面向对象(OOP)和函数式(FP)
面向对象编程(OOP)是一种编程范式,它将数据和操作数据的方法组合在一起,形成一个对象。在OOP中,对象是程序的基本单元,它们可以相互交互,执行各种操作。在编程中使用面向对象编程需要你定义类、创建对象、访问对象的属性和方法。

2.2 MindSpore2.0---OOP+FP混合编程
1. 用类构建神经网络。
2. 实例化Network对象。
3. Network+Loss直接构造正向函数。
4. 函数变换,获得梯度计算 (反向传播) 函数。
5. 构造训练过程函数。
6. 调用函数进行训练。

2.3 MindSpore模型训练以手写数字识别为例
接着,我们以MindSpore模型训练手写数字识别为例,来描述下此过程。

2.3.1 网络构建

2.3.2 Loss function
选择合适的损失函数,如手写数字识别任务是多分类问题,适合使用交叉熵损失。
2.3.3 Optimizer

模型优化(ModelOptimization)是在每个训练步骤中调整模型参数以减少模型误差的过程。
MindSpore提供多种优化算法的实现,称之为优化器 (Optimizer) 。优化器内部定义了模型的参数优化过程(即梯度如何更新至模型参数),所有优化逻辑都封装在优化器对象中。在这里,我们使用SGD (Stochastic Gradient Descent) 优化器。

2.3.4 Parameter and Hyper-parameter
模型参数(Parameter):神经网络需要从数据中学习和估计得到需要训练的参数矩阵或向量,在模型定义时采用随机初始化,通常是nn层内的weight/bias/gamma/beta等属性。超参数(Hyper-Parameter):需要人为设定的调优参数。如hidden size, learning rate, number of layers,epochs/steps。

2.3.5 训练逻辑—— 一个Step的训练

2.3.6 数据集遍历迭代

2.3.7 模型评估
2.3.8 模型保存与加载

在训练网络模型的过程中,实际上我们希望保存中间和最后的结果用于微调(fine-tune) 和后续的模型推理与部署。
2.3.9 计算图

动态图:其核心特点是计算图的构建和计算同时发生 (Define by run)。
原理:类似Python解释器,在计算图中定义一个Tensor时,其值就已经被计算且确定了。
优点: Pythonic语法,在调试模型时较为方便,能够实时得到中间结果的值。缺点:由于所有节点都需要被保存,导致难以对整个计算图进行优化。
静态图:将计算图的构建和实际计算分开 (Define and run)。
原理: 在构建阶段,根据完整的计算流程对原始的计算图进行优化和调整,编译得到更省内存和计算量更少的计算图。编译之后图的结构不再改变,所以称之为“静态图”。在计算阶段,根据输入数据执行编译好的计算图得到计算结果。
优点: 静态图相比起动态图,对全局的信息掌握更丰富,可做的优化也会更多。
缺点: 中间过程对于用户来说是个黑盒,无法像动态图一样实时拿到中间计算结果。

2.3.10 即时编译(Just In Time,JIT)

三、函数式自动微分
3.1 函数式自动微分
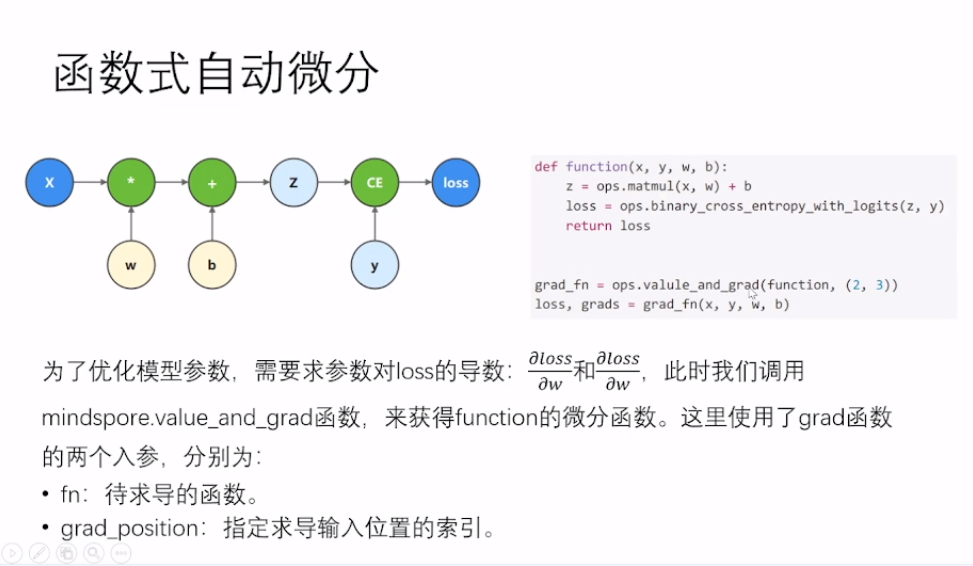
3.2 函数式自动微分一神经网络
由于使用Cell封装神经网络模型,模型参数为Cell的内部属性,此时我们不需要使用grad_position指定对函数输入求导,因此将其配置为None。对模型参数求导时我们使用weights参数,使用model.trainable_params()方法从Cell中取出可以求导的参数。

四、梯度操作
4.1 高阶梯度

4.2 梯度裁剪
常见的梯度裁剪有两种:
a)确定一个范围,如果参数的gradient超过了,直接裁剪;
b)根据若干个参数的gradient组成的vector的L2 Norm进行裁剪。

五、数据并行
数据并行是最常用的并行训练模式,在单机多卡场景经常使用,一般方式为将大批量数据平均分发到多个计算设备 (GPU/NPU) 上,每一步迭代完成后,多卡的梯度进行聚合,然后更新到各个设备上,达到多张卡并行训练同一个模型的目的。
六、模型迁移

6.1 动态图转静态图
• MindSpore的Pynative模式
• 动态图静态化操作
• 规避动态Shape
• 尽量剔除掺杂在模型代码里的非Tensor处理代码
6.2 MindSpore的Pynative模式

• 虽然可以类似Pytorch,灵活性很强,但是还是建议,按照静态图语法来写。
• 如果想要某个组件速度更快,用@ms.jit做JIT加速。

6.3 动态图静态化操作

6.4 MindSpore静态图语法支持
在Graph模式下,Python代码并不是由Pvthon解释器去执行,而是将代码编译成静态计算图,然后执行静态计算图。由于语法解析的限制,当前在编译构图时,支持的数据类型、语法以及相关操作并没有完全与Python语法保持一致,部分使用受限。

综上所述,本文主要介绍了以下内容: 1. MindSpore2.0优势特性详解;2.用MindSpore2.0深度学习训练全流程;3. 其他框架到MindSpore的模型迁移。
本文参与华为云社区【内容共创】活动第24期 。
任务28:2023华为开发者大赛 · 大赛大咖说系列直播:昇思MindSpore2.0和模型开发实践

- 点赞
- 收藏
- 关注作者
评论(0)