NPU上PyTorch模型训练问题案例

在昇腾AI处理器上训练PyTorch框架模型时,可能由于环境变量设置问题、训练脚本代码问题,导致打印出的堆栈报错与实际错误并不一致、脚本运行异常等问题,那么本期就分享几个关于PyTorch模型训练问题的典型案例,并给出原因分析及解决方法:
1、在训练模型时报错“Inner Error xxxx”,但打印的堆栈报错信息与实际错误无关
2、在模型训练时报错“terminate called after throwing an instance of 'c10::Error' what(): 0 INTERNAL ASSERT”
3、在模型训练时报错“MemCopySync:drvMemcpy failed.”
01 在训练模型时报错“Inner Error xxxx”,但打印的堆栈报错信息与实际错误无关
问题现象描述
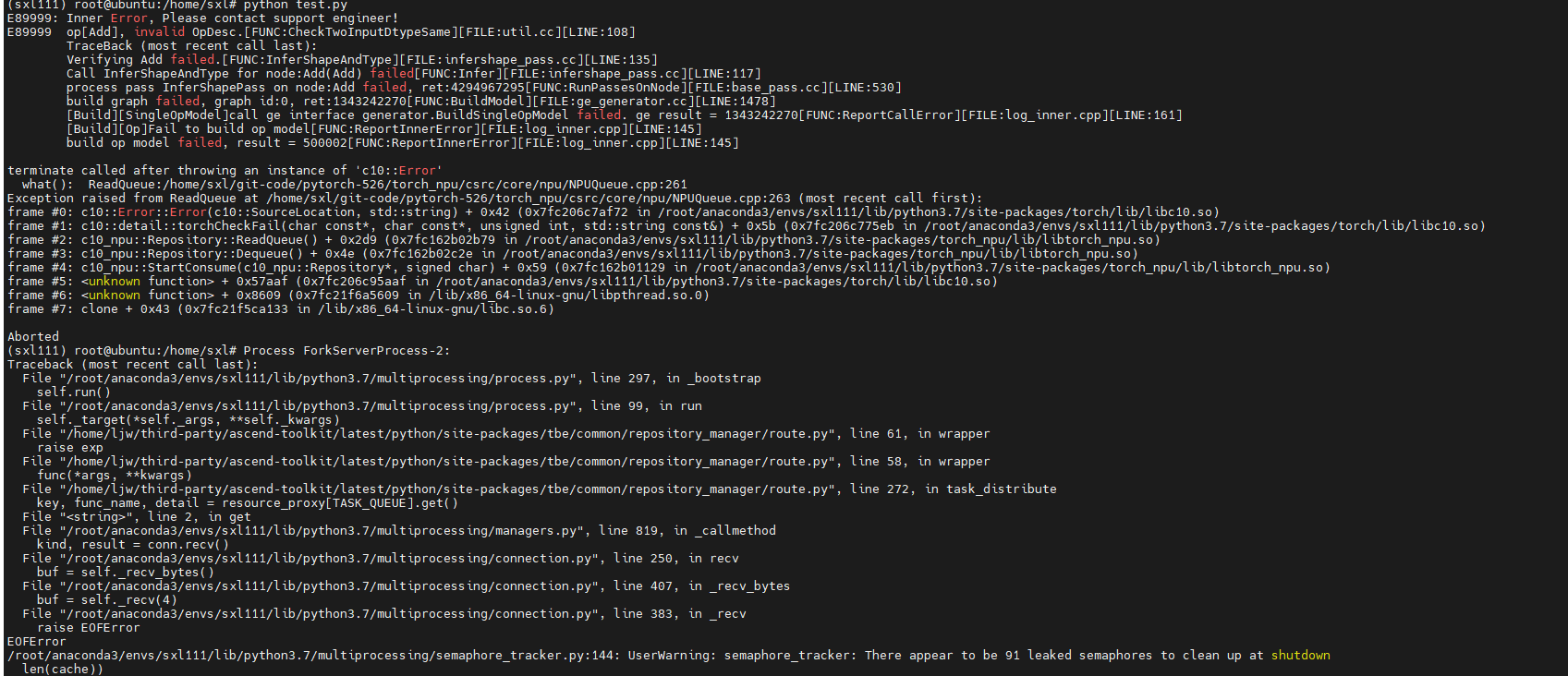
报错截图举例:
原因分析
NPU模型训练时默认为异步运行,因此打印出的堆栈报错与实际错误并不一致。如果想要打印出与实际错误相对应的堆栈报错信息,需要修改环境变量将运行模式改为同步运行。
解决措施
可以在以下方案中选择一种来解决该问题,然后再次运行模型,即可得到与实际错误一致的堆栈报错信息:
1、将环境变量TASK_QUEUE_ENABLE设置为0:
export TASK_QUEUE_ENABLE=0 2、若用户使用的PyTorch为2.1版本,也可将环境变量ASCEND_LAUNCH_BLOCKING修改为为1:
2、若用户使用的PyTorch为2.1版本,也可将环境变量ASCEND_LAUNCH_BLOCKING修改为为1:
02 在模型训练时报错“terminate called after throwing an instance of 'c10::Error' what(): 0 INTERNAL ASSERT”
问题现象描述
报错示例如下:
执行代码后出现报错。
解决措施
在运行backward运算前,通过set_decice()方法手动设置device。
原代码如下:
if __name__ == "__main__":
test_cpu()
torch_npu.npu.set_device("npu:0")
test_npu()
修改后代码如下:
if __name__ == "__main__":
torch_npu.npu.set_device("npu:0")
test_cpu()
test_npu()
03 在模型训练时报错“MemCopySync:drvMemcpy failed.”
问题现象描述
- shell脚本报错信息如下:
日志报错信息如下:
原因分析
样例脚本如下:
根据shell和日志报错信息,两者报错信息不匹配。shell报错是在同步操作中和AI CPU错误,而日志报错信息却是在min算子(内部调用ArgMinWithValue_tvmbin),二者报错信息不对应。一般这类问题出现的原因是由于日志生成的报错信息滞后。报错信息滞后可能是由于AI CPU算子的异步执行,导致报错信息滞后。
解决措施
对于该报错需要根据实际的错误来定位,可参考如下步骤进行处理:
1、通过关闭多任务算子下发后,发现结果不变,推断在shell脚本报错位置和日志报错算子之前就已出现错误。
2、根据报错加上stream同步操作,缩小错误范围,定位错误算子。stream同步操作的作用在于其要求代码所运行到的位置之前的所有计算必须为完成状态,从而定位错误位置。
3、通过在代码中加上stream同步操作,确定报错算子为stack。
4、打印stack所有参数的shape、dtype、npu_format,通过构造单算子用例复现问题。定位到问题原因为减法计算输入参数数据类型不同,导致a - b和b - a结果的数据类型不一致,最终在stack算子中报错。
5、将stack入参数据类型转换为一致即可临时规避问题。

- 点赞
- 收藏
- 关注作者
评论(0)