推或拉? rabbitMQ 消费模式该如何选择

在前面的选型对比中,我们提到了rabbitMQ同时支持推和拉的消息投递方式,那么什么是消息的推和拉?我们又该如何选择呢?今天我们就一起来看下吧
MQ 是一个非常重要的消息传递架构,它可以实现解耦并且提高系统的可靠性和吞吐量。 在很多MQ组件中,消息可以通过推和拉模式进行传递。
- 推模式
在推模式下,当一个生产者发布消息到队列时,队列会立即将这条消息发送给所有订阅了该队列的消费者。 - 拉模式
在拉模式下,当生产者发布消息到队列时,队列不会立即发送消息给消费者,而是等待消费者请求消息后才发送。
代码如下(示例):
package com.zhanfu.springboot.demo.mq;
import com.rabbitmq.client.*;
import java.io.IOException;
public class PushConsumer {
private final static String QUEUE_NAME = "myqueue";
public static void main(String[] args) throws Exception {
// 创建连接工厂
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
// 创建连接
Connection connection = factory.newConnection();
// 创建信道
Channel channel = connection.createChannel();
// 声明队列
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
// 定义消费者
Consumer consumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
String message = new String(body, "UTF-8");
System.out.println("Received '" + message + "'");
}
};
// 开始消费消息,第二个参数为是否自动ack
channel.basicConsume(QUEUE_NAME, true, consumer);
}
}
我们定义了一个consumer 消费者,然后把该消费者使用basicConsume方法来订阅某个队列的消息。当有消息到达队列时,consumer 里的handleDelivery方法就会被调用
- 优势:这种方式可以实现实时通信
- 劣势:如果消费者的处理能力跟不上生产者的速度,就会在消费者处造成消息堆积
代码如下(示例):
import java.io.IOException;
import java.util.concurrent.TimeoutException;
import com.rabbitmq.client.*;
public class RabbitMQPullConsumer {
private static final String QUEUE_NAME = "queue_name";
private static final String HOST_NAME = "host_name";
private static final String USERNAME = "username";
private static final String PASSWORD = "password";
public static void main(String[] args) throws IOException, TimeoutException {
// 创建连接和通道
ConnectionFactory factory = new ConnectionFactory();
factory.setHost(HOST_NAME);
factory.setUsername(USERNAME);
factory.setPassword(PASSWORD);
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
// 声明队列
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
channel.basicQos(1);
// 消费消息
while (true) {
// 手动从队列中获取一条消息,第二个参数为是否自动ack
GetResponse response = channel.basicGet(QUEUE_NAME, false);
if (response == null) {
// 没有消息,则等待一段时间再继续检查
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
String message = new String(response.getBody(), "UTF-8");
System.out.println("Received message: " + message);
channel.basicAck(response.getEnvelope().getDeliveryTag(), false); // 手动Ack
}
}
}
}
如果获取的GetResponse对象为null,则表示队列中没有消息。我们将等待一段时间(这里是1秒),然后再继续检查队列中是否有新消息。
如果获取的GetResponse对象不为null,则表示有新消息。我们将从GetResponse对象中提取消息内容,然后输出它。如果我们设置basicGet()方法的第二个参数为true,则表示自动ack,即在获取消息后直接将消息从队列中删除。
这是一个基本的拉模式的RabbitMQ消费者实现。当然,生产上如果采用拉模式,我们更推荐使用多个线程异步的方式处理,一个线程负责循环拉取消息后,存入一个长度有限的阻塞队列,另一个/一些线程从阻塞队列中取出消息,处理完一条则手动Ack一条,这样更有效率。
- 优势:消费端可以按照自己的处理速度来消费,避免产生在消费端产生消息堆积。
- 劣势:消息传递方面可能会有一些延迟,当处理速度长时间小于消息发布速度时,容易造成大量消息堆积在rabbitMQ服务器,一些时间敏感的队列,可能会使内部的消息失效
我们在上面的代码中,不难发现,不管是推模式还是拉模式,方法的入参中都有一个布尔变量
// 推模式,直接订阅
channel.basicConsume(QUEUE_NAME, true, consumer);
// 拉模式,一次拉取一条
channel.basicGet(QUEUE_NAME, true);
这个布尔变量其实就是是否自动Ack,其实我们在《RabbitMQ 能保证消息可靠性吗》一文中就提到过,这是一种消息确认机制:
- 自动ACK
即意味着,我们收到消息时就会通知RabbitMQ服务器,服务器就会将该消息已经被消费,进而删除。 - 手动ACK
-即意味着在某个我觉得可以通知RabbitMQ服务器时,我才会通知。
那么两种模式我们该怎么取舍?
从实际生产的角度,我强烈建议将Ack模式设置为手动,这样可以保证消费者处理消息失败时,消息不会立即从队列中删除,而是需要重新分配给其他消费者,增强了系统的容错性和可靠性。同时,建议在消费者处理消息时,对消息进行异常处理,确保消息能够正确地被处理
在rabbitMQ的API中,我们不难发现有一项叫做 Qos(quality of service—— 服务质量) 的参数设置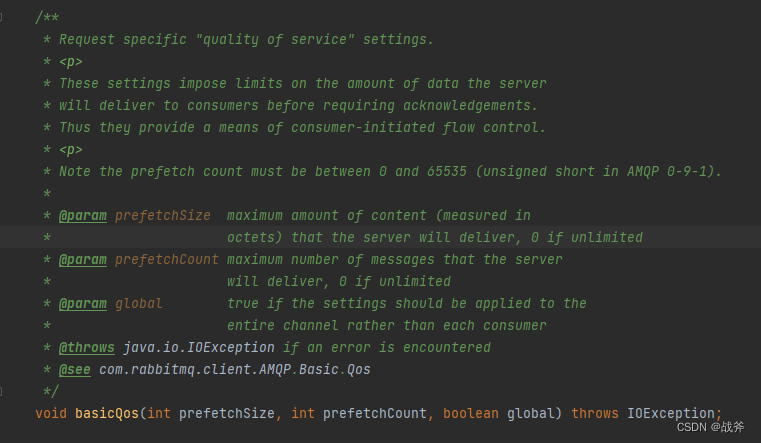
These settings impose limits on the amount of data the server will deliver to consumers before requiring acknowledgements.Thus they provide a means of consumer-initiated flow control.
这些设置对服务器在接收到Ack之前将传递给消费者的数据量进行了限制。因此,它们提供了一种由消费者发起的流量控制方式。
通俗的讲,这个Qos参数是配合Ack 用来控制消费端的流量的(即限流):自动ACK不需要设置Qos;手动ACK模式时,则可以设置Qo,控制消费者处理消息的速度,它拥有三个参数
- prefetchSize:服务器将传递的最大内容量(以八位字节为单位),如果不受限制,则为0
- prefetchCount:服务器将传递的最大消息条数,如果不受限制,则为0
- global:是否将该设置应用到整个信道,还是仅此一个消费者
在上面拉模式的代码中,我们就使用了一个 channel.basicQos(1); ,也是最常用的限制方法,即以消息条数为单位限制,其实设置的就是最大消息条数
/**
* Request a specific prefetchCount "quality of service" settings
* for this channel.
* <p>
* Note the prefetch count must be between 0 and 65535 (unsigned short in AMQP 0-9-1).
*
* @param prefetchCount maximum number of messages that the server
* will deliver, 0 if unlimited
* @throws java.io.IOException if an error is encountered
* @see #basicQos(int, int, boolean)
*/
void basicQos(int prefetchCount) throws IOException;
我们可以设置QoS,控制消费者处理消息的速度。通过合理设置预取计数或预取字节数,可以确保消费者处理消息的速度与RabbitMQ服务器发送消息的速度相匹配,避免队列中积压过多的未确认消息。需要注意的是,这个prefetchCount的取值是一个经验值,太大容易导致消费端内存消耗过高,太小则效率低下,一般建议在100以下。
综合来看,推模式适合实时通信且生产者和消费者的速度相当的场景,而且对于利于压榨出消费者端的处理潜力;拉模式适合大量数据的场景,并且可以更好地控制消息的消费进度。但是,实际应用中更多地是将两种模式结合使用,以达到更好的效果。

- 点赞
- 收藏
- 关注作者
评论(0)