【云驻共创】Android恶意软件检测及对抗样本生成

目录
1.研究背景
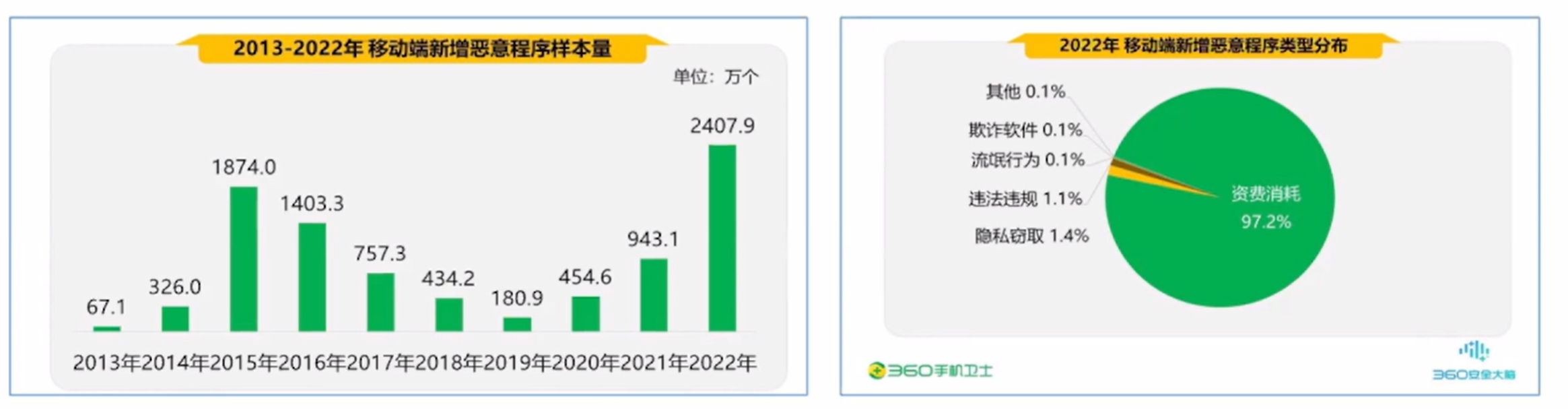
1.1Android恶意软件数量迅速增长
1.2基于静态分析的检测流程
2.研究挑战
2.1代码混淆
2.2对抗样本
2.3概念漂移
3.应对策略
3.1应对策略总述
3.2对抗样本——鲁棒的分类模型
4.对抗样本生成
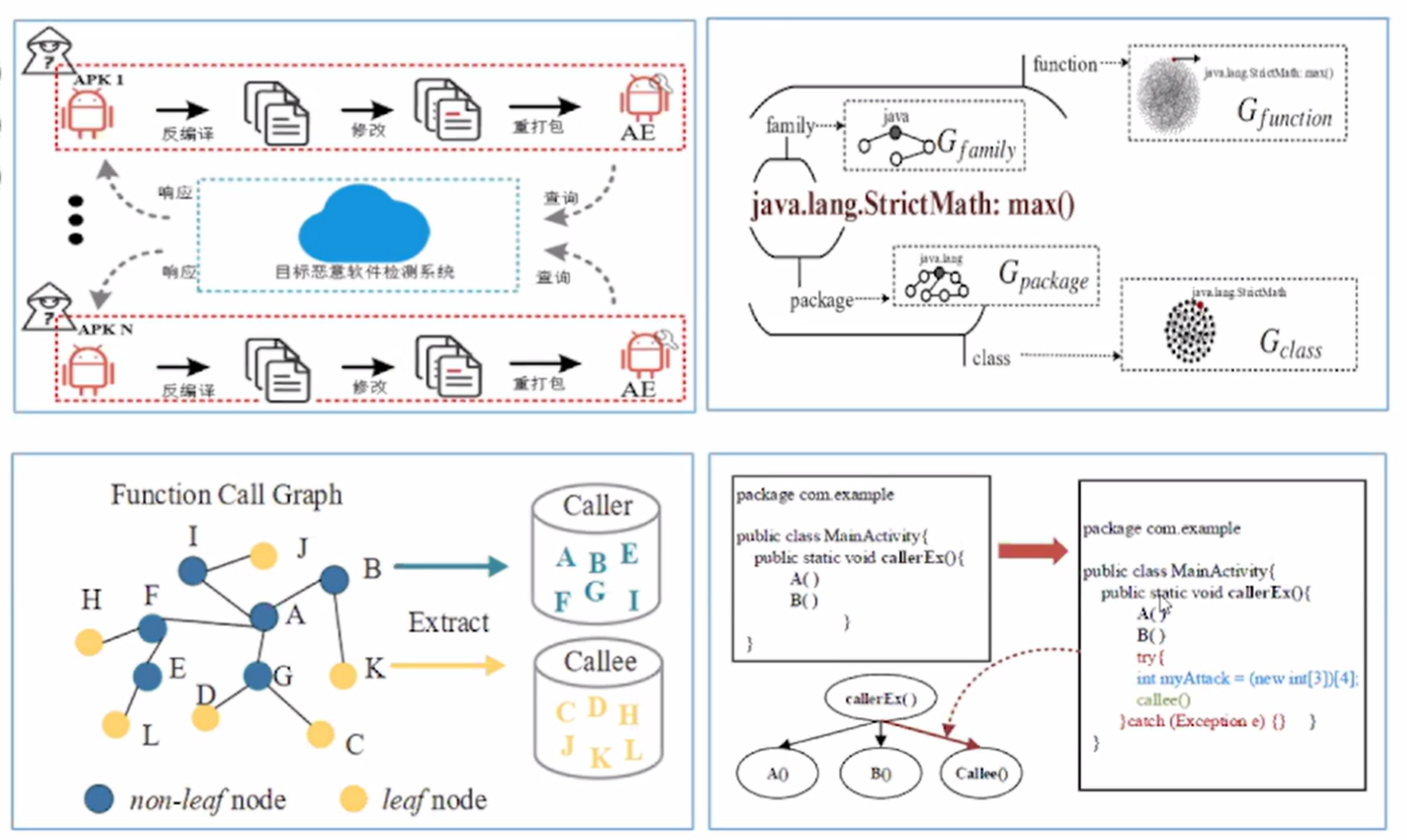
4.1安卓恶意软件对抗样本攻击——语义特征
4.2三个任务和挑战
5.技术难题攻关进展
6.总结
1.研究背景
1.1Android恶意软件数量迅速增长
Android占据87%动操作系统市场份额,其开源性以及流行性也使它成为了97%的移动端恶意软件的目标。2022年度,360 安全大脑共截获移动端新增恶意程序样本约2407.9万个,平均每天新增6.6万个。
1.2基于静态分析的检测流程
第一步:样本收集
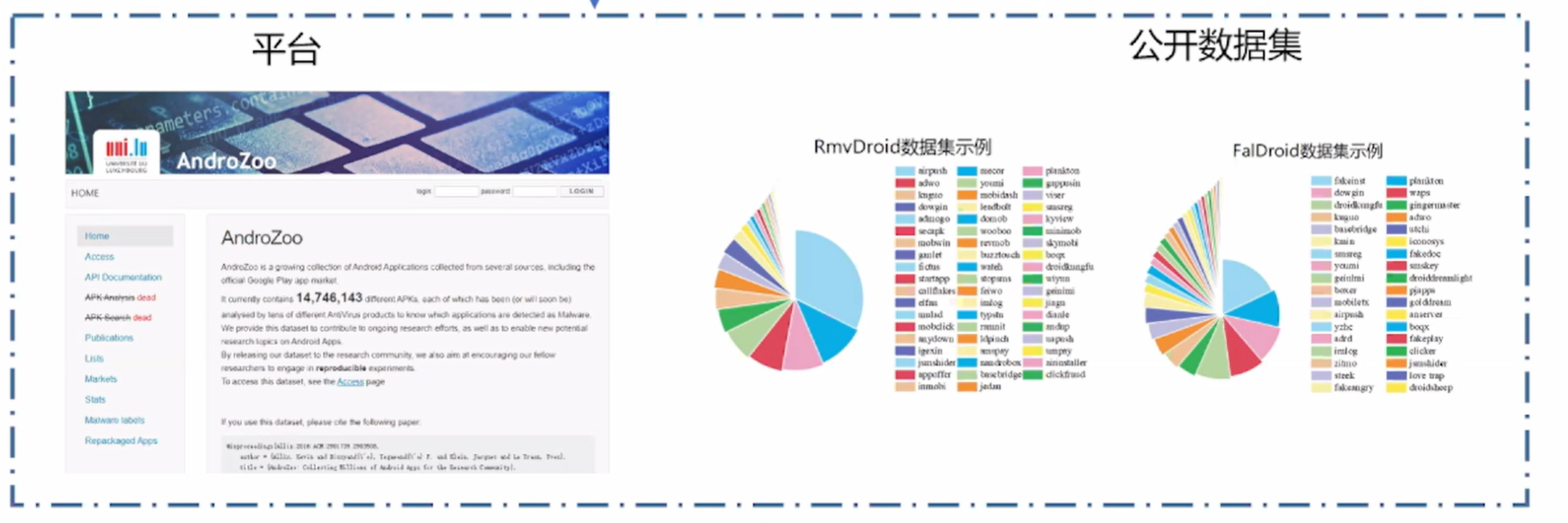
第二步:APK文件处理
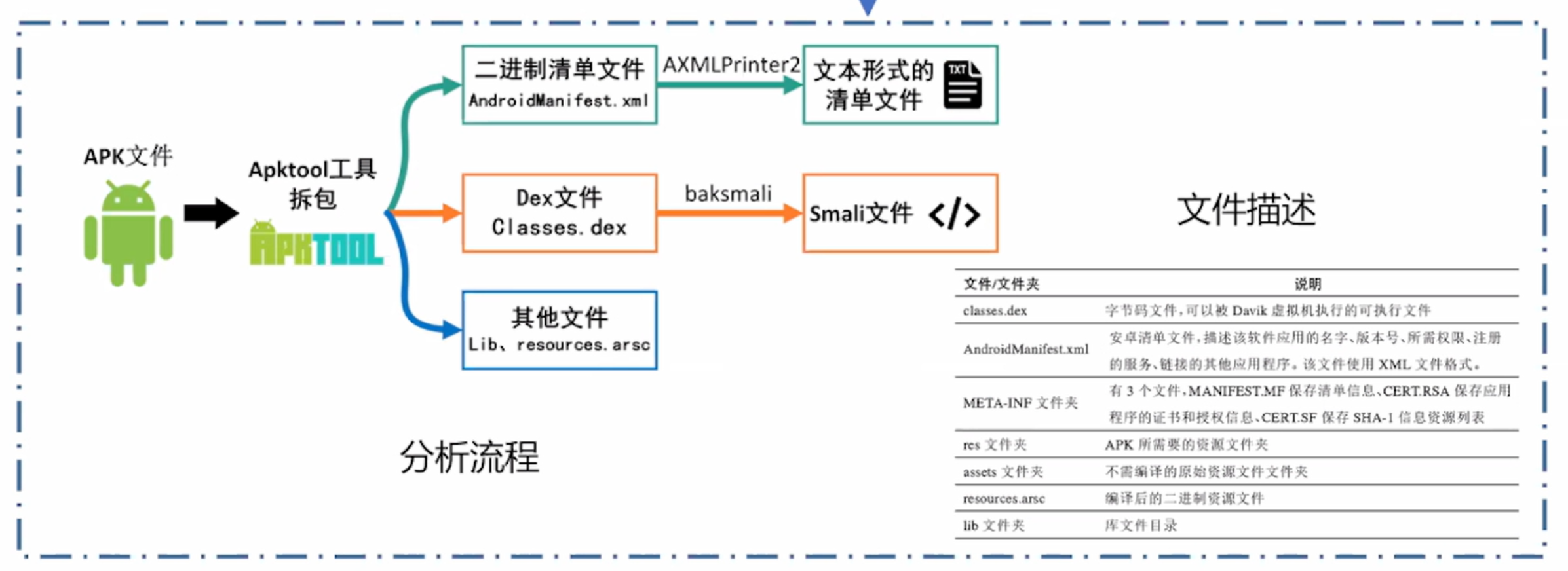
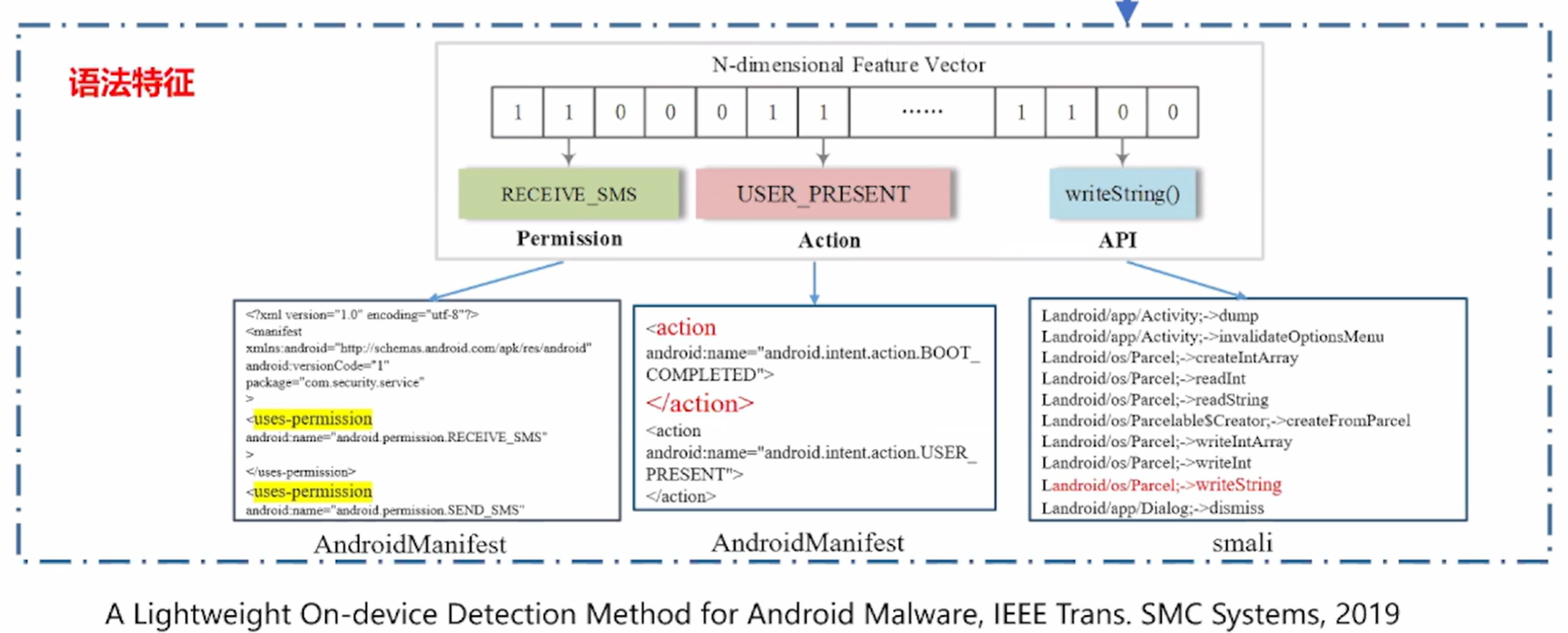
第三步:特征提取
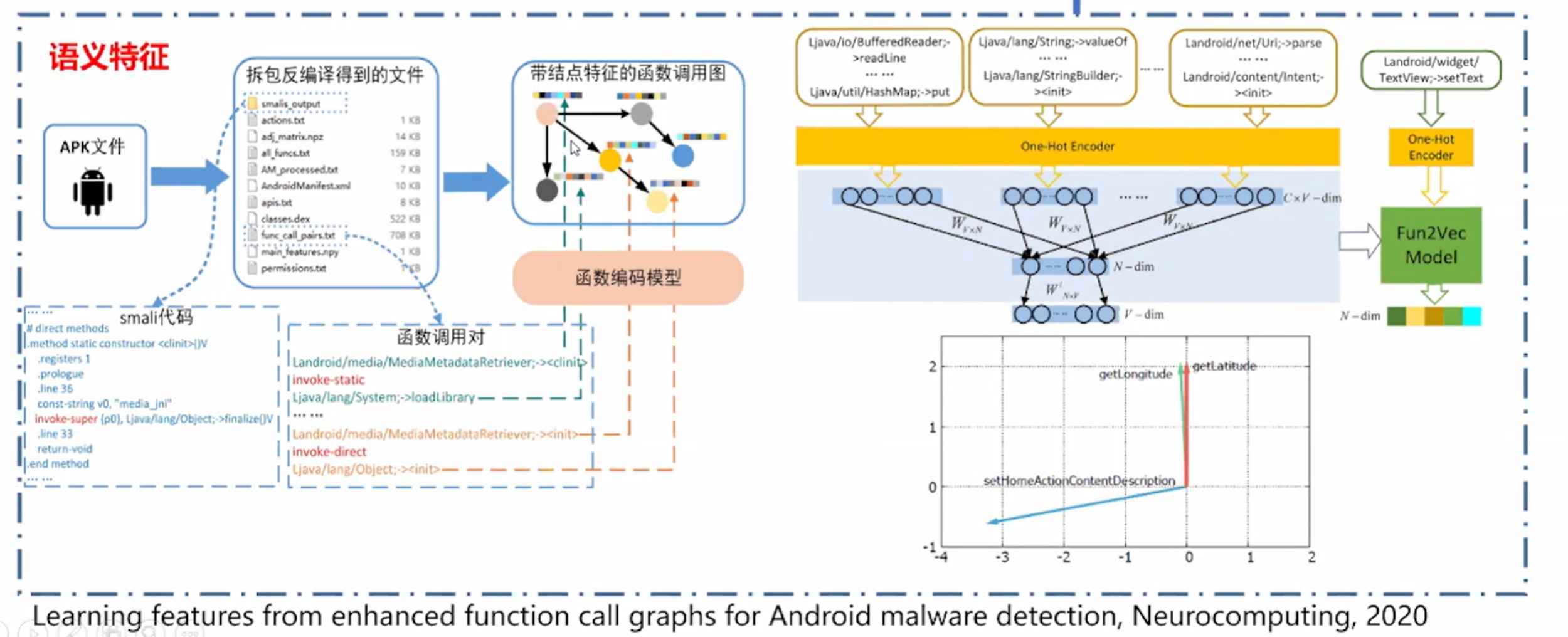
第四步:模型训练
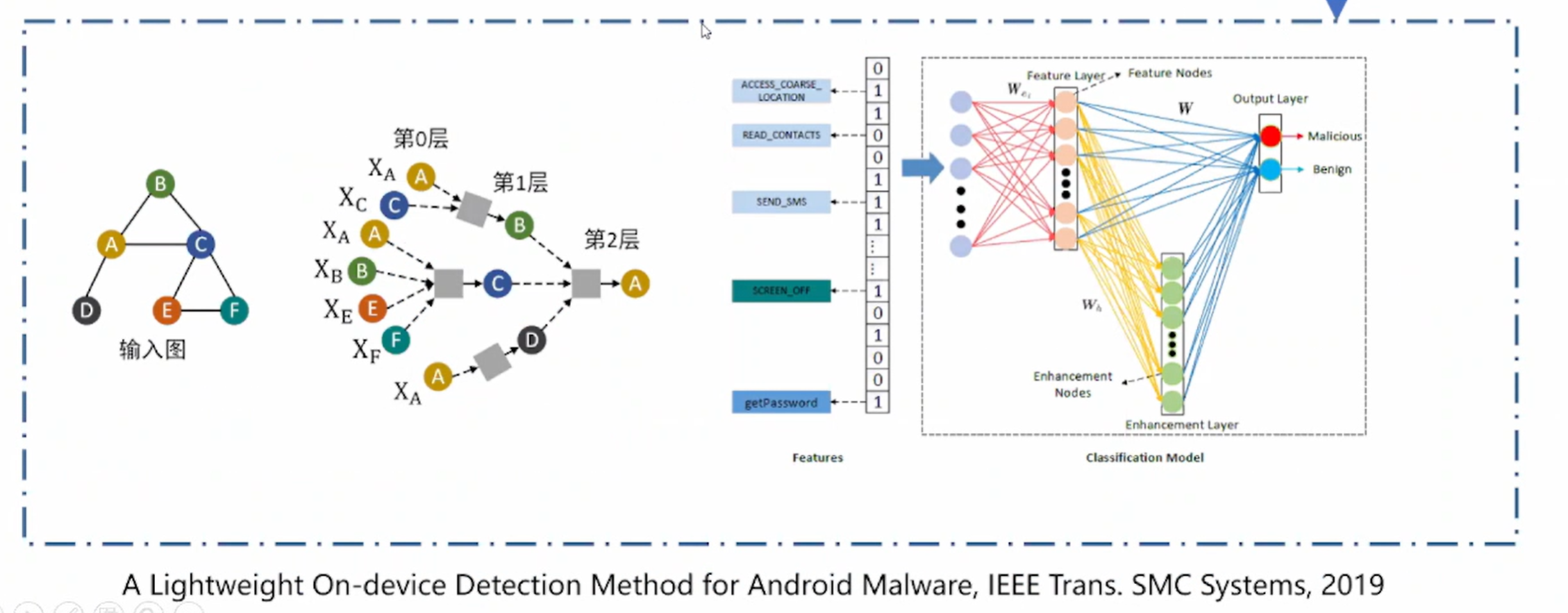
2.研究挑战
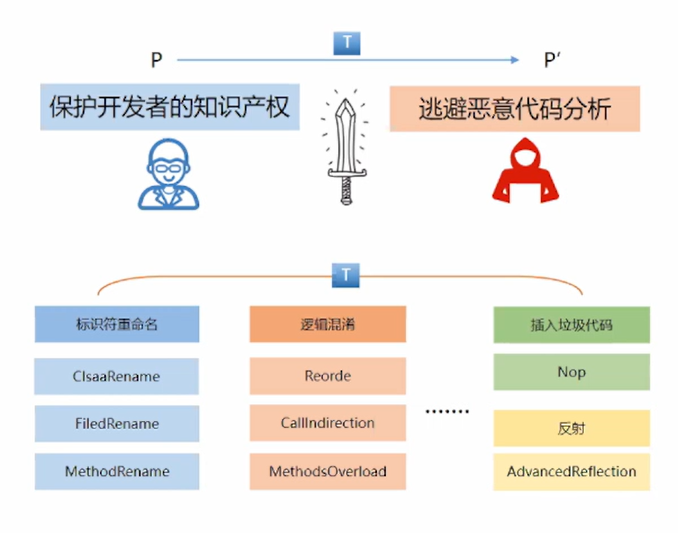
2.1代码混淆
代码混淆是一种成本低廉、应用广泛的恶意软件检测对抗技术。它将程序的代码,转换成一种功能上等价,但难以阅读与理解的形式,增加安全工作者分析恶意软件的难度并能逃避检测模型的检测。
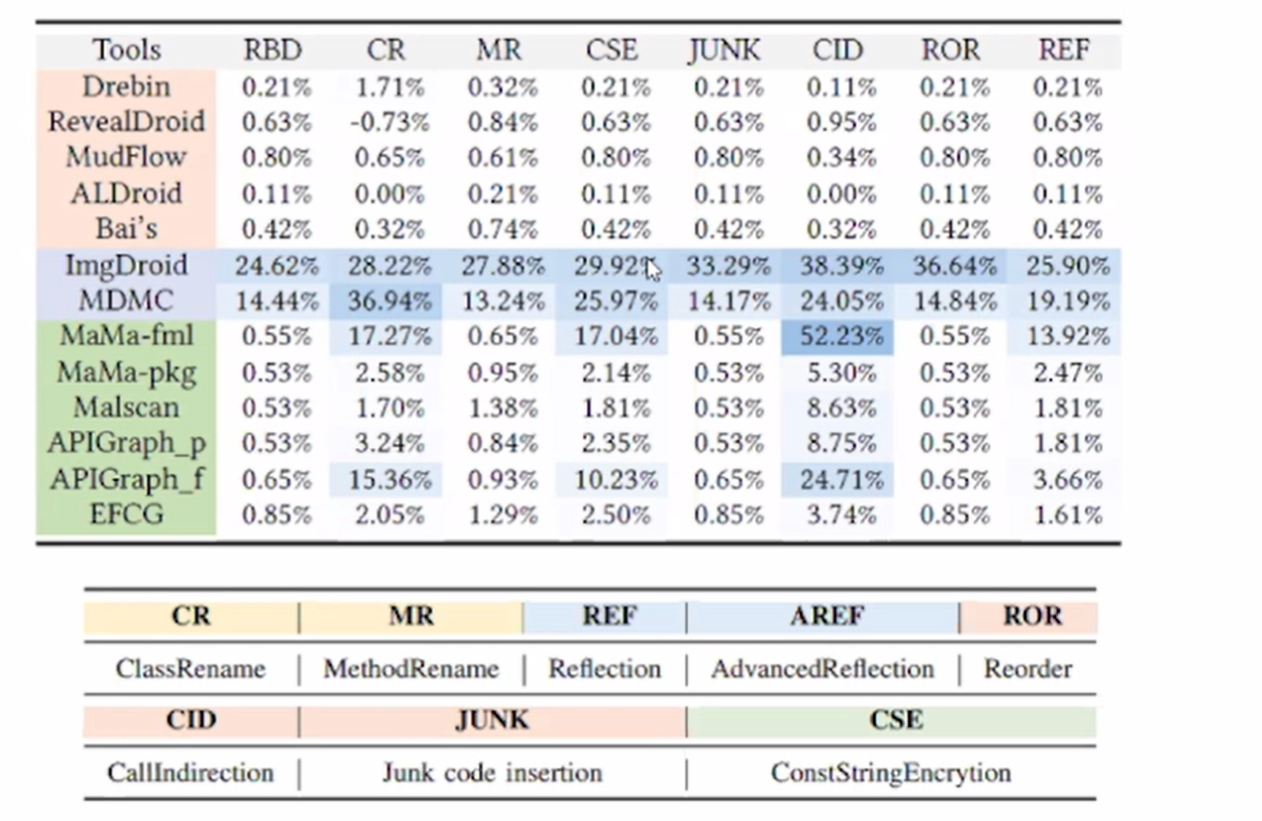
不同类型代码混淆对检测性能的影响(F1 score的降低比例),如下图:
2.2对抗样本
对抗样本是通过在正常样本(也称自然样本)中添加细微扰动而形成,它能导致机器学习模型以高置信度给出一个错误的分类结果。

安卓恶意软件对抗样本攻击——语法特征,如下图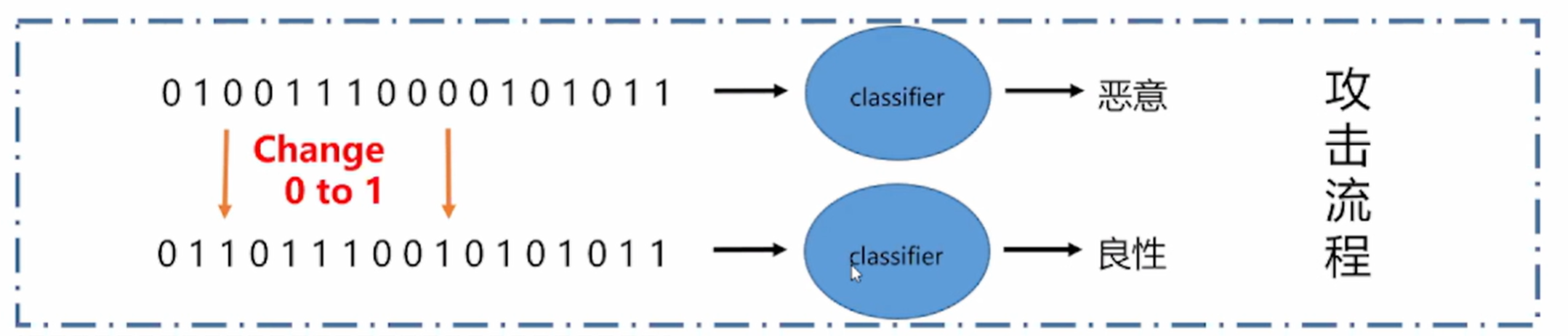
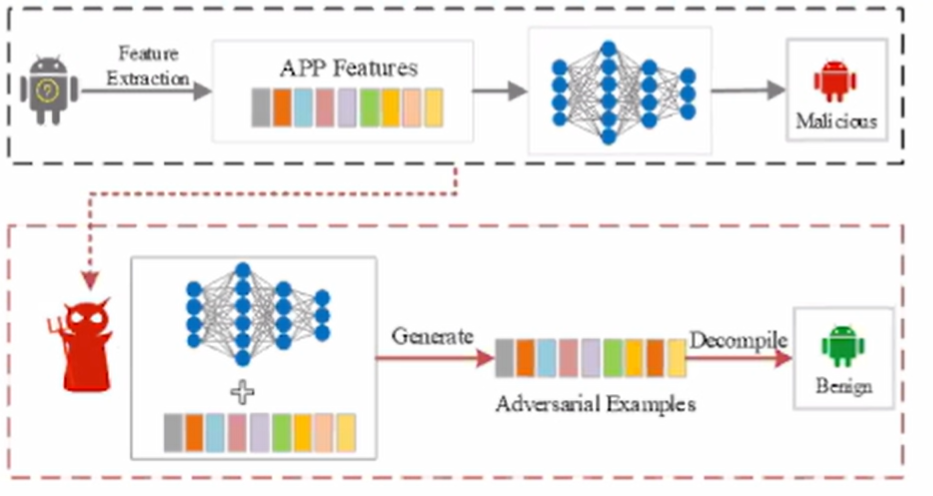
安卓恶意软件对抗样本攻击——攻击流程,如下图
- White-box :假设攻击者拥有包括训练数据、分类器类型和参数在内的知识
- Black-box :假设攻击者无法获取分类器的参数和训练数据等信息

2.3概念漂移
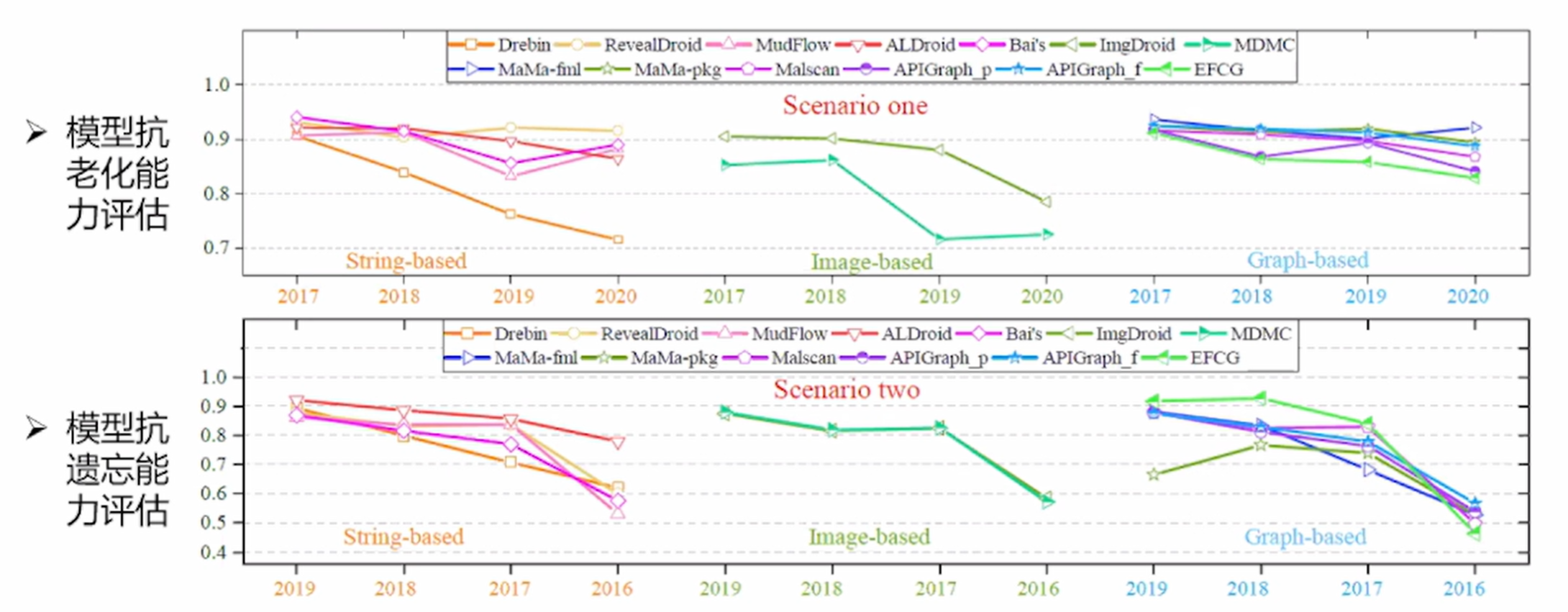
概念漂移指目标变量的统计特性随着时间推移以不可预见的方式发生变化的现象。在实际使用Android恶意软件检测模型时,训练和测试用的样本通常来自不同时段,它们的数据分布可能存在差异,即有发生概念漂移的可能。
训练集和测试集的时间间隔对恶意软件检测器性能的影响,如下图:
3.应对策略
3.1应对策略总述
面对代码混淆、对抗样本、概念漂移等诸多挑战,应对策略的总体是通过工具,进行特征选择,数据表征,分类模型这三个流程,然后分辨出是良性的还是恶意的安卓软件。
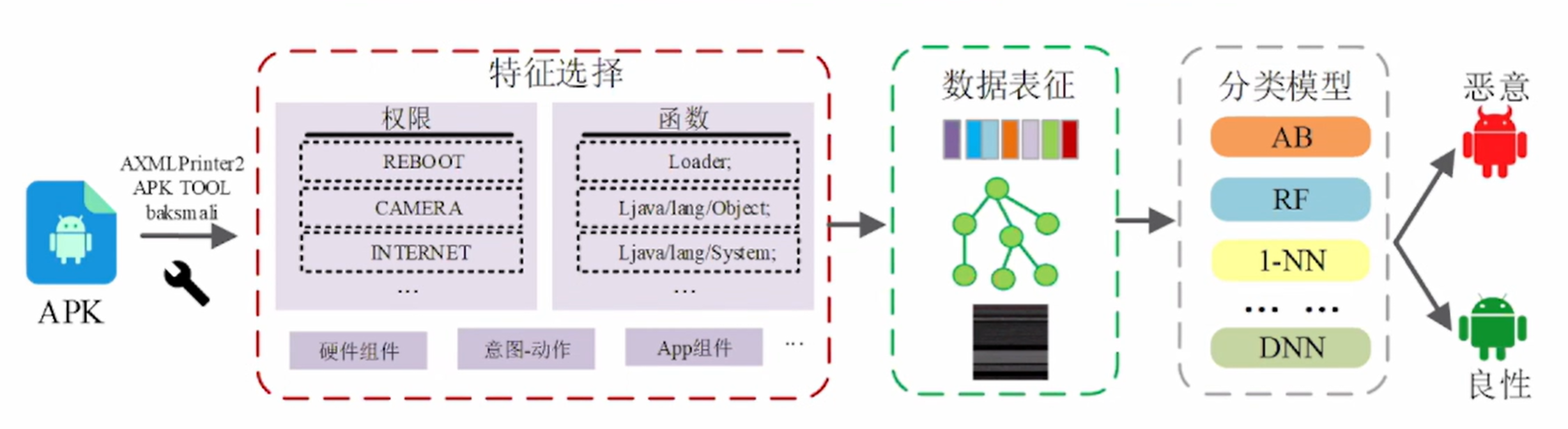
在特征选择流程中进行的应对策略:
- 代码混淆
多视角互补特征,增强抗混淆能力能力。 - 概念漂移
选取稳定的、不易”时变”的特征。
对特征进一步聚合。 - 对抗样本
选取不易扰动或不易精准篡改的特征形式。
选取鲁棒特征
在数据表征和分类模型流程中进行的应对策略:
- 代码混淆
融合不同视角特征下的检测结果 - 概念漂移
集成模型,通过模型更新更好地适应漂移后的数据。
让检测器自身对概念漂移不敏感 - 对抗样本
对抗训练
设计新型的鲁棒检测模型
3.2对抗样本——鲁棒的分类模型
难点与策略:
- 没有对抗样本数据或数据不具备代表性——>针对恶意软件检测和对抗性恶意软件防御的一类(one-class)分类模型。
- 对训练数据的依赖可能会削弱防御方法的泛化能力——>为了提高检测性能,提出了一种新的特征解缠损失函数。
- 模型需要检测恶意软件和防御对抗实例,复杂性可能很高——>提出一种降低模型复杂度的网络共享技术。
鲁棒的分类模型,如下图
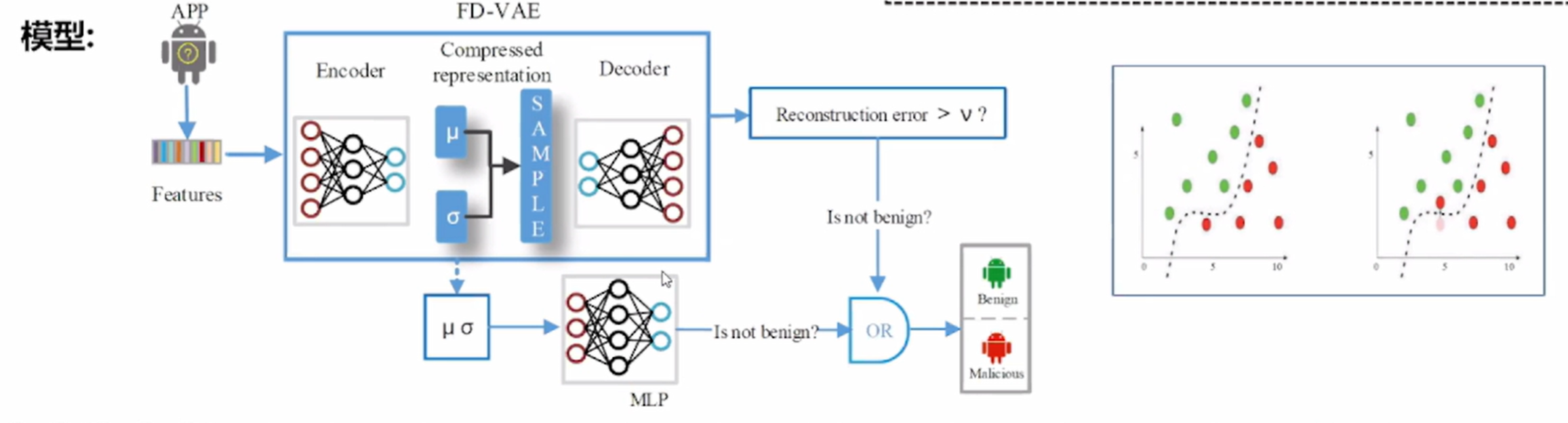
上面鲁棒的分类模型当中FD-VAE的详解,如下图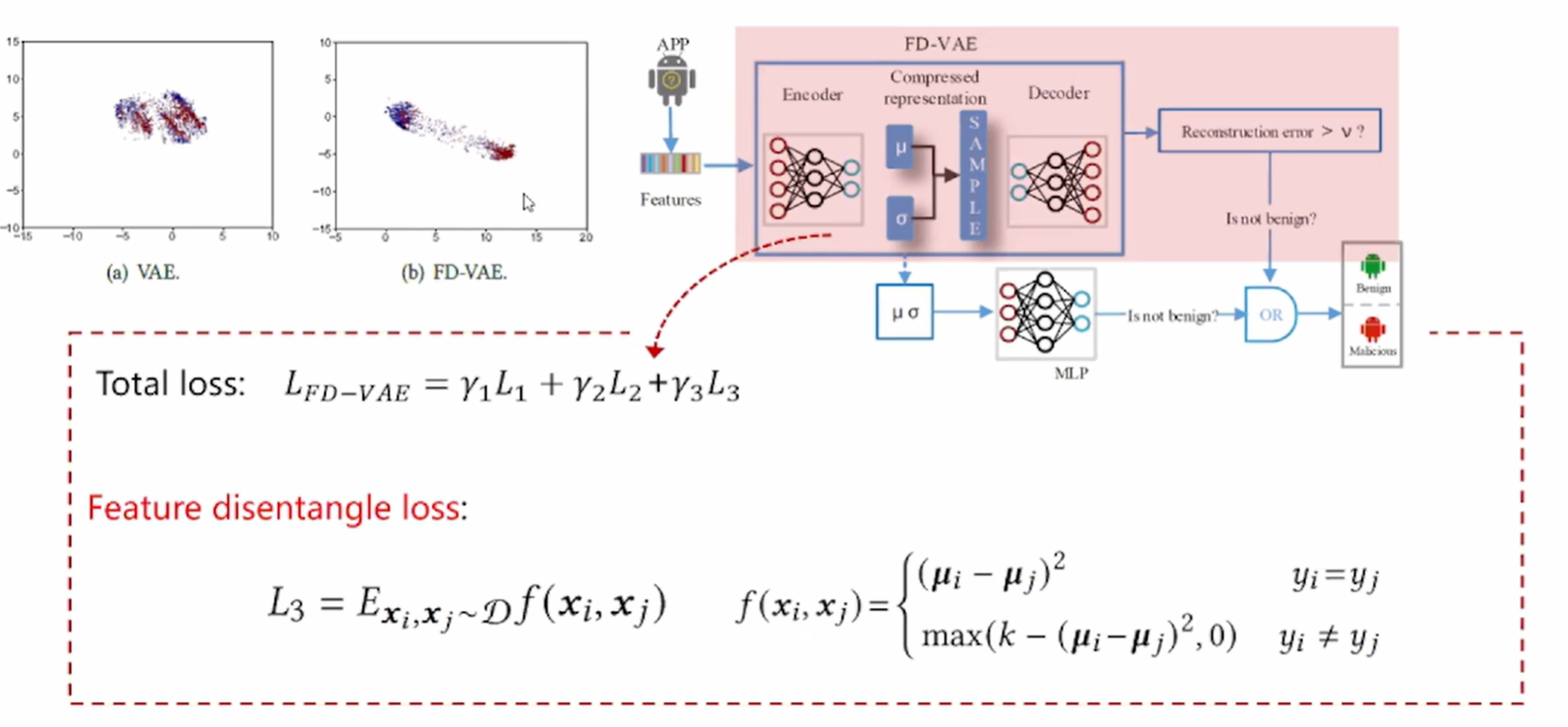
4.对抗样本生成
4.1安卓恶意软件对抗样本攻击——语义特征
- 问题空间攻击:修改APK源文件
- 特征空间攻击:修改提取的特征
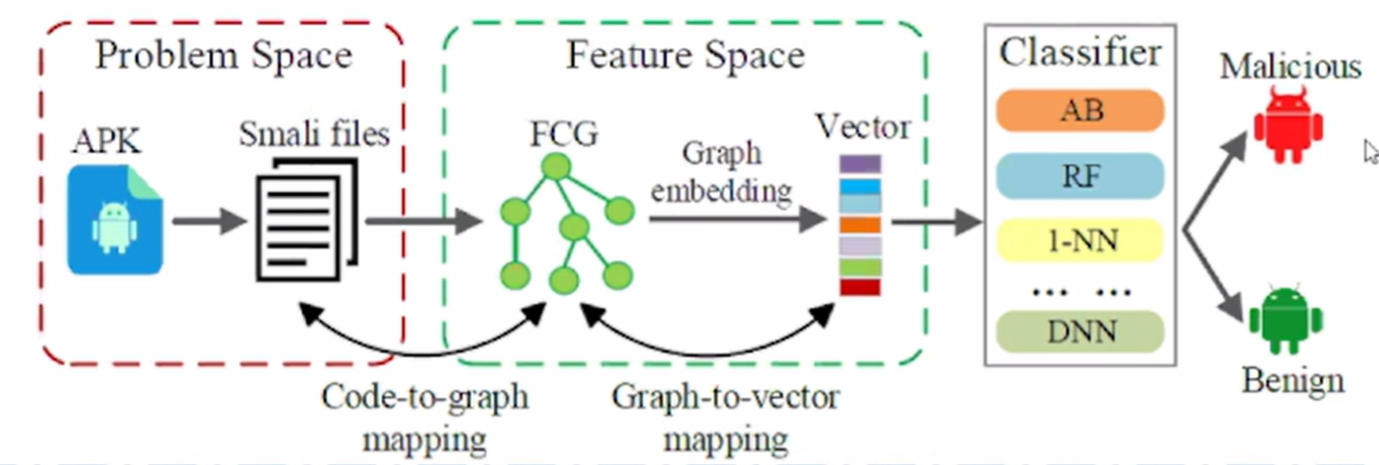
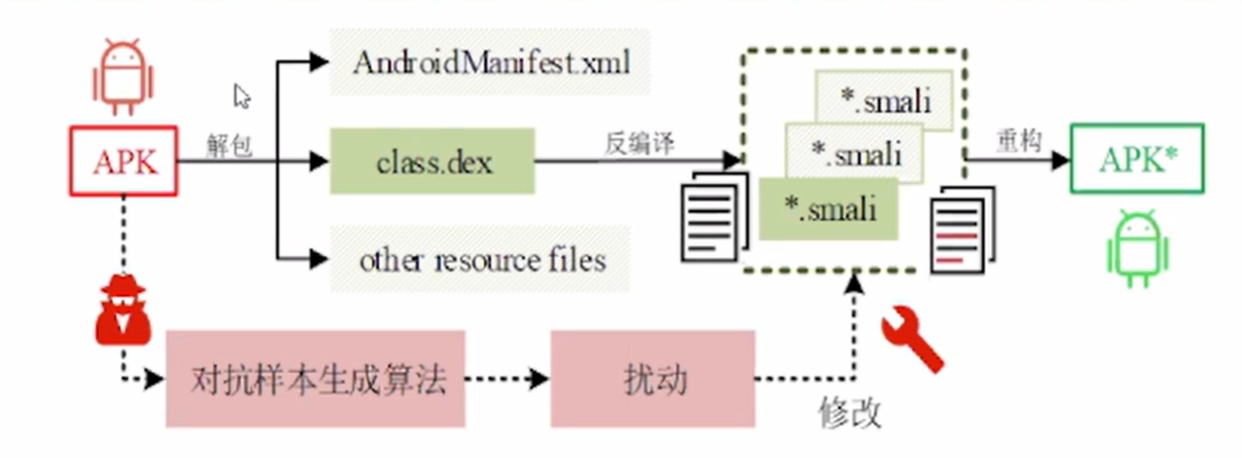
4.2三个任务和挑战
三个任务
- 怎么扰动特征(特征空间)
- 怎么生成扰动(特征空间)
- 怎么实现扰动(问题空间)
三个挑战
- 减少查询次数
- 不完全特征信息
- 不影响软件原有功能
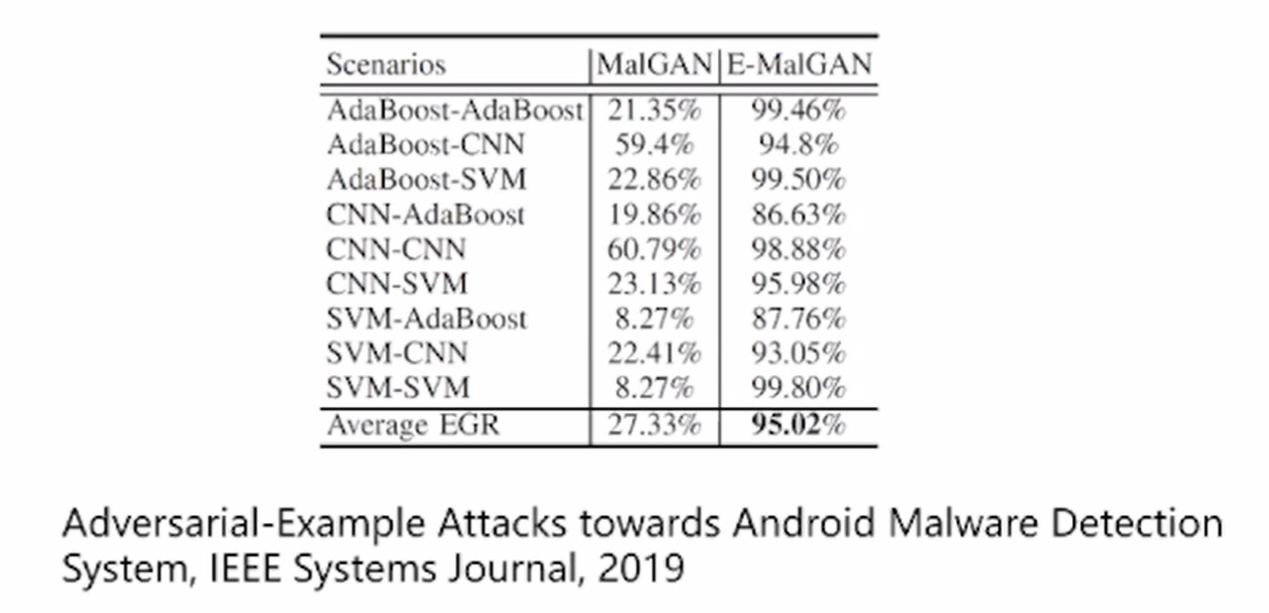
对抗扰动的生成模型(GAN=生成算法+替代模型),如下图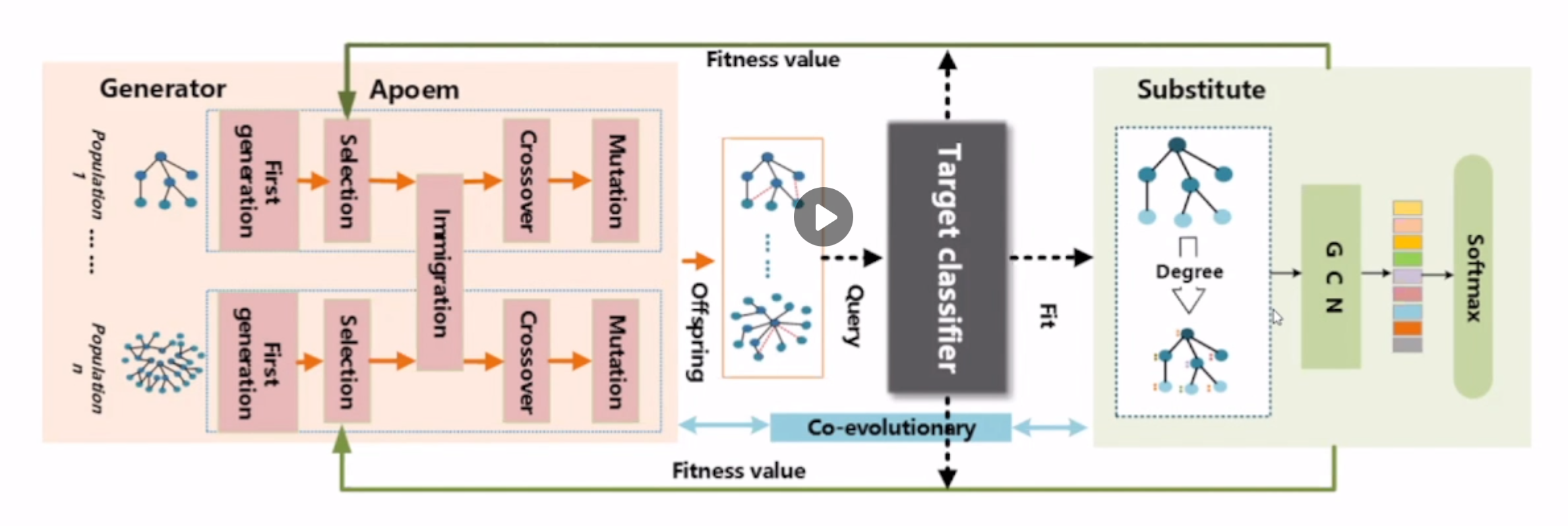
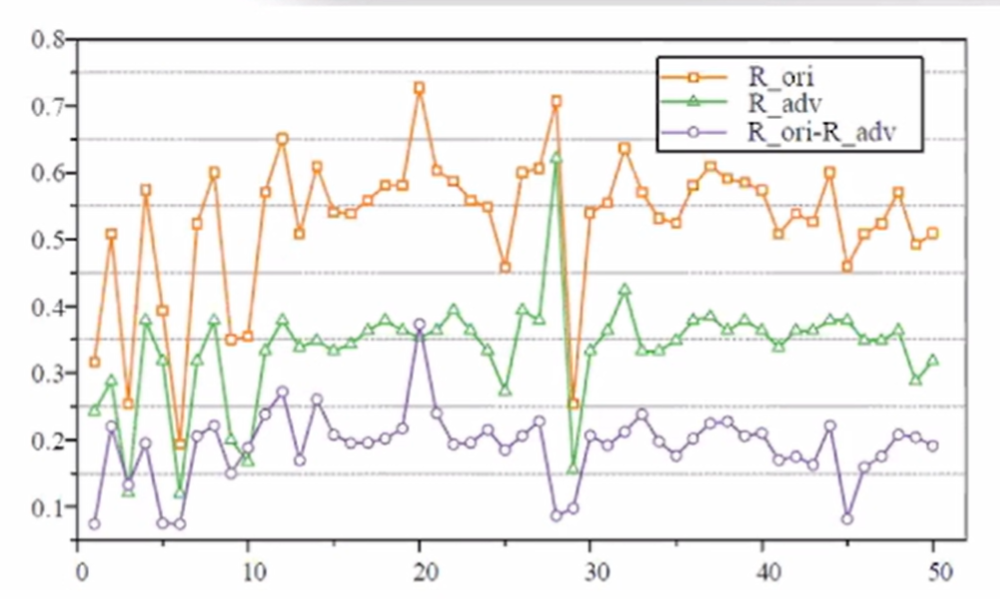
攻击Virus' Total检测成功率,详情如下图
攻击隐蔽性评估Try-catch数量,详情如下图
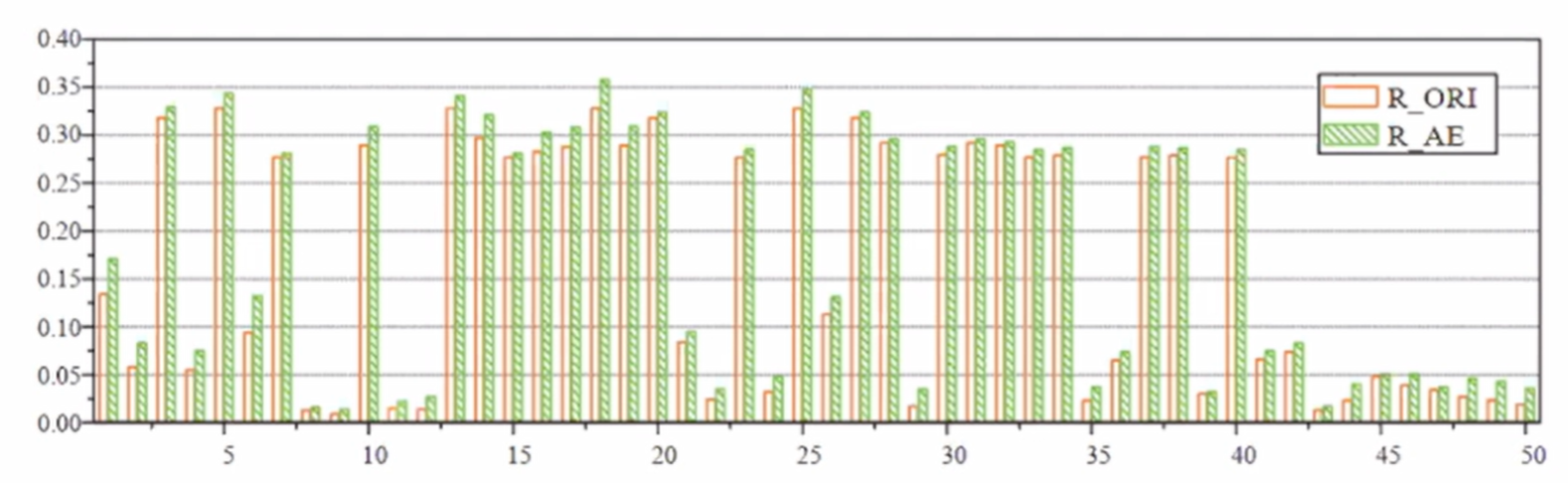
5.技术难题攻关进展
任务信息
- 通过已知网络流量数据训练模型,对未知流量数据判断其是否异常。
类别信息
- 数据分为四大类:误报、尝试攻击、成功攻击、确认风险。误报、尝试攻击两类数据作为正常数据。成功攻击、确认风险两类数据作为异常数据。
数据信息
- 每条数据拥有多个字段,包括attack_params、attack_source、 attack_type等 。
- attack_params表示的是疑似攻击行为的上报参数,拥有stack属性和params属性,其中params属性表示上传实参,内容不固定,且部分传入的参数内容进行过加密,而stack属性表示函数调用链,不同数据之间的stack具有较好的区分度。
数据处理
- 将每条数据的attackparams字段中的stack属性作为主要的判断依据。
- 将所有数据的stack提取出来,去重得到一个stack集合。
数据处理的运行结果,如下图
数据处理的详细数据,如下图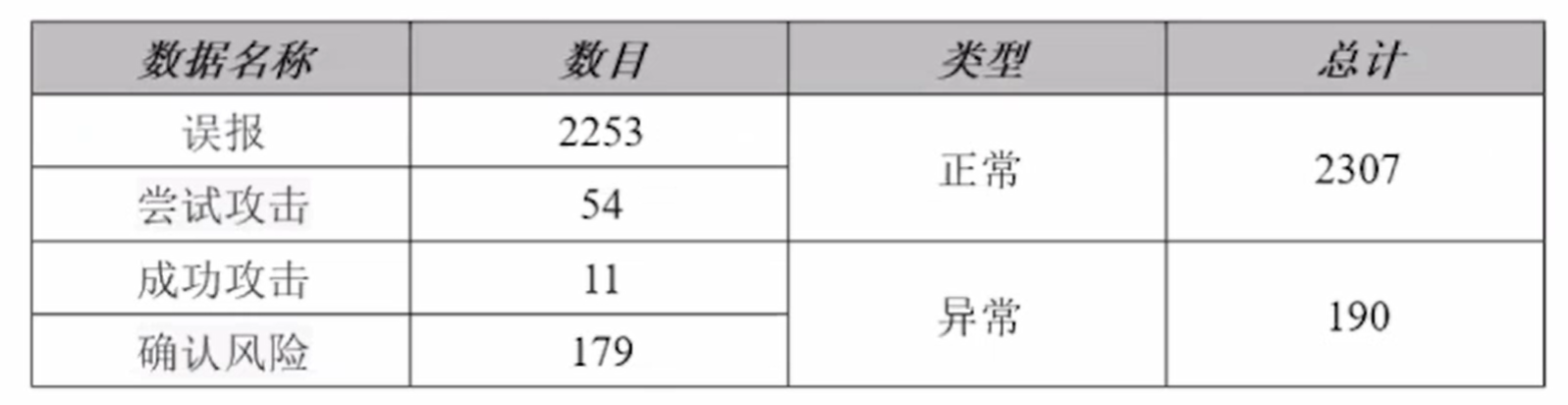
特征提取
- 把stack中用逗号分隔的函数视为“词”,使用Word2Vec这类方法得到其向量表示。
- 再对同一条数据中不同函数的向量表示进行聚合,得到每个函数调用栈stack的向量表示,即每条数据对应的特征向量。
检测性能
具体正常率和异常率具体数据,如下图
问题分析
- 某些正常样 本和异常样本的attack_ params中 的函数调用栈stack内容完全一样,这会误导分类模型,导致性能下降,这种样本有55条。
- 去除这些样本,即两类数据同时减去它们的交集部分,重新做实验。
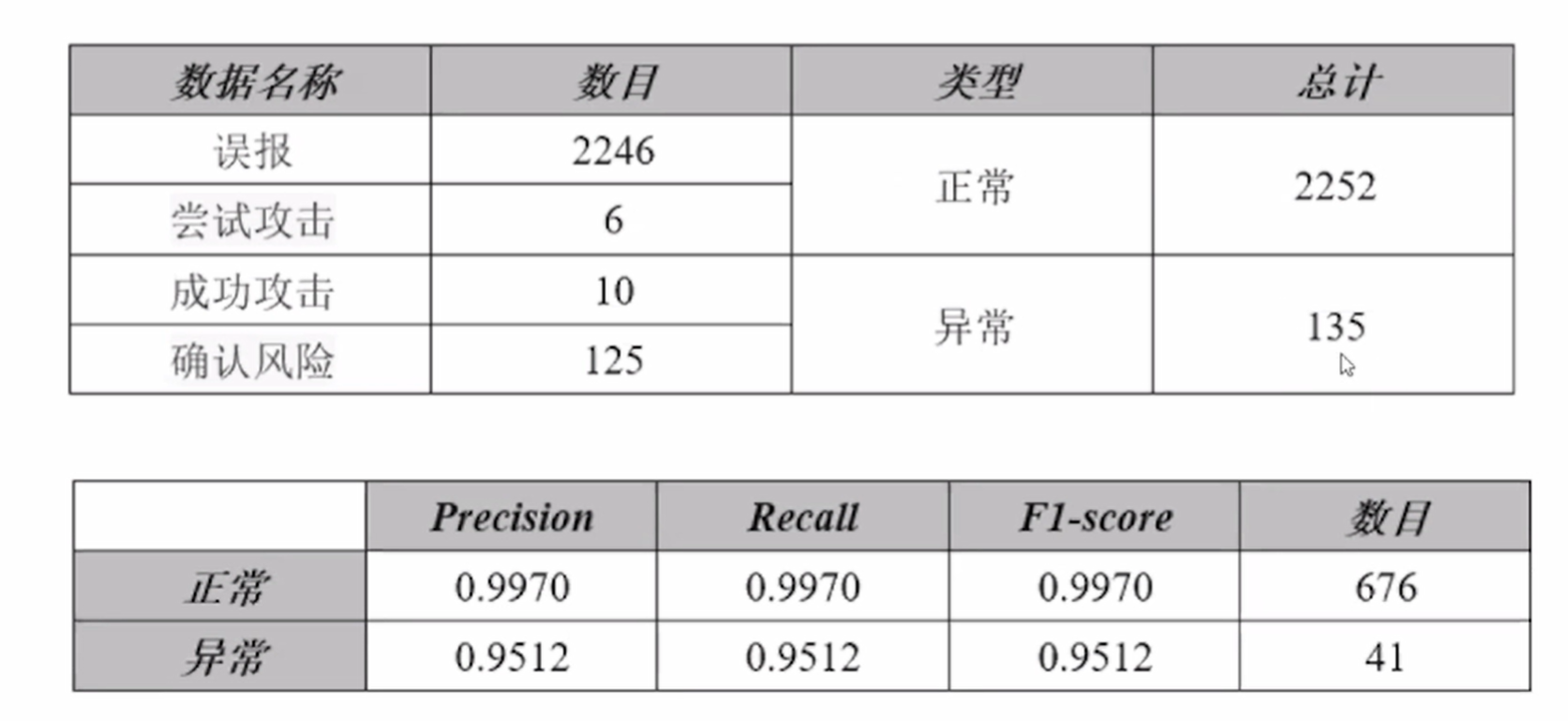
问题分析
- 总共有4条样本被错误分类,其中2条样本是异常数据的漏判。
- 被错分样本与同类别数据之间有较明显差异。
- 被漏判的某条数中,"com.huawei.his.jalor.helper.StoreHelper.retrieveStream(StoreHelper.java:263)"函数在异常数据的函数调用链中只出现过一次。
下一步计划
- 考虑更多的特征(比如params),进一步提升分类性能
- 考虑如何检测新型的异常数据(概念漂移,新类涌现)
6.总结
目前越来越多的Android恶意软件检测引擎使用了人工智能算法,因此就有攻击者开始尝试对Android恶意软件进行一定的修改,使得Android恶意软件可以在保留本身的功能的前提下绕过这些基于人工智能算法的检测模型。这就是Android恶意软件检测领域的对抗攻击。
本文大概梳理了目前存在的基于人工智能算法的Android恶意软件检测模型,概述了针对Android恶意软件检测模型的对抗攻击方法,并从特征和算法两方面总结了相应的增强模型安全性的防护手段。
对于Android恶意软件检测模型和对抗攻击的发展趋势,我相信是会越来越多元化,精确化,完整化。由于对抗攻击对Android恶意软件检测的影响,对抗攻击对人工智能算法的威胁性直接关系到使用人工智能算法的 Android 恶意软件检测算法的可用性,并且恶意软件检测在不同的应用场景下, 需要有不同的防御方法,这将会大大的影响后续的研究方向和思路。
本文参加华为云社区【内容共创】活动第23期

- 点赞
- 收藏
- 关注作者
评论(0)