AI编辑神奇DragGan火了:拯救手残党,拖拽实现精准P图

AI编辑神奇DragGan火了:拯救手残党,拖拽实现精准P图
🔹 本案例需使用 Pytorch-1.8 GPU-P100 及以上规格运行
🔹 点击Run in ModelArts,将会进入到ModelArts CodeLab中,这时需要你登录华为云账号,如果没有账号,则需要注册一个,且要进行实名认证,参考《ModelArts准备工作_简易版》 即可完成账号注册和实名认证。 登录之后,等待片刻,即可进入到CodeLab的运行环境
🔹 出现 Out Of Memory ,请检查是否为您的参数配置过高导致,修改参数配置,重启kernel或更换更高规格资源进行规避❗❗❗
DragGAN
DragGAN是由谷歌、麻省理工学院和马克斯普朗克研究所创建的一种新的人工智能模型。可以让你轻松通过点击拖动等简单的交互操作就能改变拍摄对象的姿势、形状和表情等。
DragDiffusion 进入了人们的视线。此前的 DragGAN 实现了基于点的交互式图像编辑,并取得像素级精度的编辑效果。但是也有不足,DragGAN 是基于生成对抗网络(GAN),通用性会受到预训练 GAN 模型容量的限制。
在新研究中,新加坡国立大学和字节跳动的几位研究者将这类编辑框架扩展到了扩散模型,提出了 DragDiffusion。他们利用大规模预训练扩散模型,极大提升了基于点的交互式编辑在现实世界场景中的适用性。
虽然现在大多数基于扩散的图像编辑方法都适用于文本嵌入,但 DragDiffusion 优化了扩散潜在表示,实现了精确的空间控制。

研究者表示,扩散模型以迭代方式生成图像,而「一步」优化扩散潜在表示足以生成连贯结果,使 DragDiffusion 高效完成了高质量编辑。
他们在各种具有挑战性的场景(如多对象、不同对象类别)下进行了广泛实验,验证了 DragDiffusion 的可塑性和通用性。相关代码也将很快放出、
下面是用DragGAN生成的几幅图,一起来看看吧👀

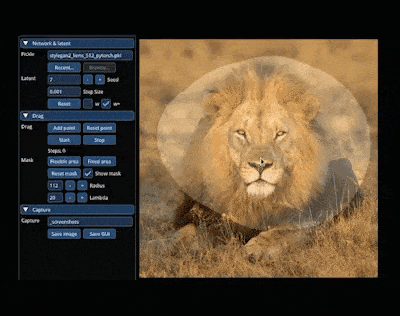
下面我们看看 DragDiffusion 效果如何。
首先,我们想让下图中的小猫咪的头再抬高一点,用户只需将红色的点拖拽至蓝色的点就可以了:

接下来,我们想让山峰变得再高一点,也没有问题,拖拽红色关键点就可以了:

还想让雕塑的头像转个头,拖拽一下就能办到:

让岸边的花,开的范围更广一点:

DragGAN是通过生成图像的3D模型来改变图片的,之后该模型可进行编辑。用户可以在不影响图像其余部分的情况下调整图像中物品的位置、形状、情感和布局。DragGAN首先使用卷积神经网络(CNN)从图像中提取特征。然后利用这些特征生成图像的3D表示。接着使用第二个CNN来修改3D模型。该CNN是使用已被人类修改过的图像数据集进行训练的。修改过的照片用于教导CNN如何修改3D模型。一旦训练完成,CNN就可以用于修改任何图片。

要使用DragGAN AI工具进行照片编辑,请按照以下步骤操作:
1.上传您想要修改的图像。
2.拖动图像中的点到所需的位置。
3.放开点后,DragGAN将自动修改图像以匹配您的修改。
4.继续拖动点并根据需要调整图像。
5.编辑完成后,单击“保存”按钮以保存更新后的图像。
以下是使用ModelArts 上的notebook实现的部分核心代码,仅供研究参考。
1.环境设置
check GPU & 拷贝代码及数据
!nvidia-smi
import os
import moxing as mox
parent = "/home/ma-user/work/DragGAN"
bfp = "/home/ma-user/work/DragGAN/openai/clip-vit-large-patch14/pytorch_model.bin"
sfp = "/home/ma-user/work/DragGAN/models/draggan_sd15_scribble.pth"
if not os.path.exists(parent):
mox.file.copy_parallel('obs://modelarts-labs-bj4-v2/case_zoo/scribble2img/DragGAN',parent)
if os.path.exists(parent):
print('Download success')
else:
raise Exception('Download Failed')
elif os.path.exists(bfp)==False or os.path.getsize(bfp)!=1710671599:
mox.file.copy_parallel('obs://modelarts-labs-bj4-v2/case_zoo/scribble2img/DragGAN/openai/clip-vit-large-patch14/pytorch_model.bin', bfp)
elif os.path.exists(sfp)==False or os.path.getsize(sfp)!=5710757851:
mox.file.copy_parallel('obs://modelarts-labs-bj4-v2/case_zoo/scribble2img/DragGAN/models/draggan_sd15_scribble.pth', sfp)
else:
print("Model Package already exists!")
Tue Apr 25 15:49:25 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.33.01 Driver Version: 440.33.01 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla P100-PCIE... Off | 00000000:00:0E.0 Off | 0 |
| N/A 27C P0 25W / 250W | 0MiB / 16280MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
INFO:root:Using MoXing-v2.1.0.5d9c87c8-5d9c87c8
INFO:root:Using OBS-Python-SDK-3.20.9.1
Model Package already exists!
安装库,大约耗时1min,请耐心等待。
%cd /home/ma-user/work/DragGAN
!pip uninstall torch torchtext -y
!pip install torch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1
!pip install omegaconf==2.1.1 einops==0.3.0
!pip install pytorch-lightning==1.5.0
!pip install transformers==4.19.2 open_clip_torch==2.0.2
!pip install gradio==3.32.0
!pip install translate==3.6.1
/home/ma-user/work/ControlNet
Found existing installation: torch 1.8.0
Uninstalling torch-1.8.0:
Successfully uninstalled torch-1.8.0
Found existing installation: torchtext 0.5.0
Uninstalling torchtext-0.5.0:
Successfully uninstalled torchtext-0.5.0
Looking in indexes: http://repo.myhuaweicloud.com/repository/pypi/simple
Collecting torch==1.12.1
Downloading http://repo.myhuaweicloud.com/repository/pypi/packages/b9/af/23c13cd340cd333f42de225ba3da3b64e1a70425546d1a59bfa42d465a5d/torch-1.12.1-cp37-cp37m-manylinux1_x86_64.whl (776.3 MB)
2. 加载模型
导包并加载模型,加载约40s,请耐心等待。
import numpy as np
from PIL import Image as PilImage
import cv2
import einops
import matplotlib.pyplot as plt
from IPython.display import HTML, Image
from base64 import b64decode
from translate import Translator
import torch
from pytorch_lightning import seed_everything
import config
from draggan.model import create_model, load_state_dict
from ldm.models.diffusion.ddim import DDIMSampler
from annotator.util import resize_image, HWC3
model = create_model('./models/draggan_v15.yaml')
model.load_state_dict(load_state_dict('./models/draggan_sd15_scribble.pth', location='cuda'))
model = model.cuda()
ddim_sampler = DDIMSampler(model)
INFO:matplotlib.font_manager:generated new fontManager
/home/ma-user/anaconda3/envs/PyTorch-1.8/lib/python3.7/site-packages/requests/__init__.py:104: RequestsDependencyWarning: urllib3 (1.26.12) or chardet (5.1.0)/charset_normalizer (2.0.12) doesn't match a supported version!
RequestsDependencyWarning)
INFO:torch.distributed.nn.jit.instantiator:Created a temporary directory at /tmp/tmp383fe77g
INFO:torch.distributed.nn.jit.instantiator:Writing /tmp/tmp383fe77g/_remote_module_non_scriptable.py
No module 'xformers'. Proceeding without it.
ControlLDM: Running in eps-prediction mode
DiffusionWrapper has 859.52 M params.
making attention of type 'vanilla' with 512 in_channels
Working with z of shape (1, 4, 32, 32) = 4096 dimensions.
3. 点击调节参数生成图像
调节参数生成图像函数
with torch.no_grad():
if type(input_image) is str:
input_image = np.array(PilImage.open(input_image))
img = resize_image(HWC3(input_image), image_resolution)
else:
img = resize_image(HWC3(input_image['mask'][:, :, 0]), image_resolution) # scribble
H, W, C = img.shape
# Initialize detection map
detected_map = np.zeros_like(img, dtype=np.uint8)
detected_map[np.min(img, axis=2) > 127] = 255
control = torch.from_numpy(detected_map.copy()).float().cuda() / 255.0
control = torch.stack([control for _ in range(num_samples)], dim=0)
control = einops.rearrange(control, 'b h w c -> b c h w').clone()
# Set random seed
if seed == -1:
seed = random.randint(0, 65535)
seed_everything(seed)
if config.save_memory:
model.low_vram_shift(is_diffusing=False)
cond = {"c_concat": [control], "c_crossattn": [model.get_learned_conditioning([prompt + ', ' + a_prompt] * num_samples)]}
un_cond = {"c_concat": None if guess_mode else [control], "c_crossattn": [model.get_learned_conditioning([n_prompt] * num_samples)]}
shape = (4, H // 8, W // 8)
if config.save_memory:
model.low_vram_shift(is_diffusing=True)
# Sampling
model.control_scales = [strength * (0.825 ** float(12 - i)) for i in range(13)] if guess_mode else ([strength] * 13) # Magic number.
samples, intermediates = ddim_sampler.sample(ddim_steps, num_samples,
shape, cond, verbose=False, eta=eta,
unconditional_guidance_scale=scale,
unconditional_conditioning=un_cond)
if config.save_memory:
model.low_vram_shift(is_diffusing=False)
# Post-processing
x_samples = model.decode_first_stage(samples)
x_samples = (einops.rearrange(x_samples, 'b c h w -> b h w c') * 127.5 + 127.5).cpu().numpy().clip(0, 255).astype(np.uint8)
results = [x_samples[i] for i in range(num_samples)]
return [255 - detected_map] + results
4.设置参数,生成图像
➡ 参数说明
🔸 模型:目前提供了10个模型(在web界面选择后会自动下载),不同模型输出图片分辨率,和对显存要求不一样。选择与上传图像最接近的模型。例如,为人脸选择 stylegan2-ffhq-config-f.pt 。 stylegan2-cat-config-f.pt 代表猫。
🔸 最大迭代步数:有些比较困难的拖拽,需要增大迭代次数,当然简单的也可以减少。
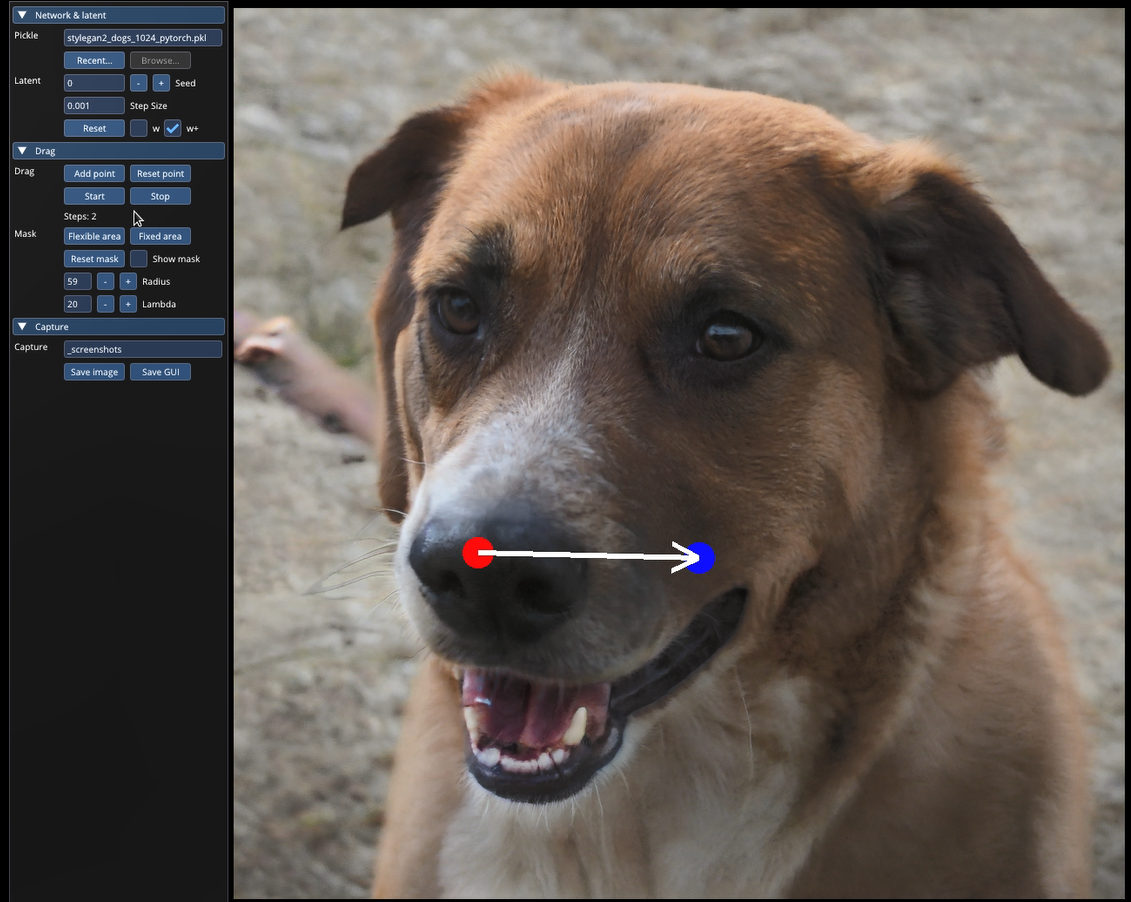
🔸 设置拖拽点对:模型会将蓝色的点拖拽到红色点位置。记住需要在 Setup handle points 设置拖拽点对。
🔸 设置可变化区域(可选):这部分是可选的,你只需要设置拖拽点对就可以正常允许。如果你想的话, 你可以在 Draw a mask 这个面板画出你允许模型改变的区域。注意这是一个软约束,即使你加了这个mask,模型还是有可能会改变超出许可范围的区域。
5. Gradio可视化部署
如果想进行可视化部署,可以继续以下步骤: Gradio应用启动后可在下方页面进行点击生成图像,您也可以分享public url在手机端,PC端进行访问生成图像。
📢DragGan扩展说明
🟪 模型:为人脸选择 stylegan2-ffhq-config-f.pt , stylegan2-cat-config-f.pt 代表猫。
🟪 最大迭代步数::20
🟪 设置拖拽点对: 记住需要在 Setup handle points 设置拖拽点对。
🟫 设置可变化区域(可选):这部分是可选的,你只需要设置拖拽点对就可以正常允许。如果你想的话, 你可以在 Draw a mask 这个面板画出你允许模型改变的区域。注意这是一个软约束,即使你加了这个mask,模型还是有可能会改变超出许可范围的区域。
请注意: 图像生成消耗显存,您可以在左侧操作栏查看您的实时资源使用情况,点击GPU显存使用率即可查看,当显存不足时,您生成图像可能会报错,此时,您可以通过重启kernel的方式重置,然后重头运行即可规避。或更换更高规格的资源
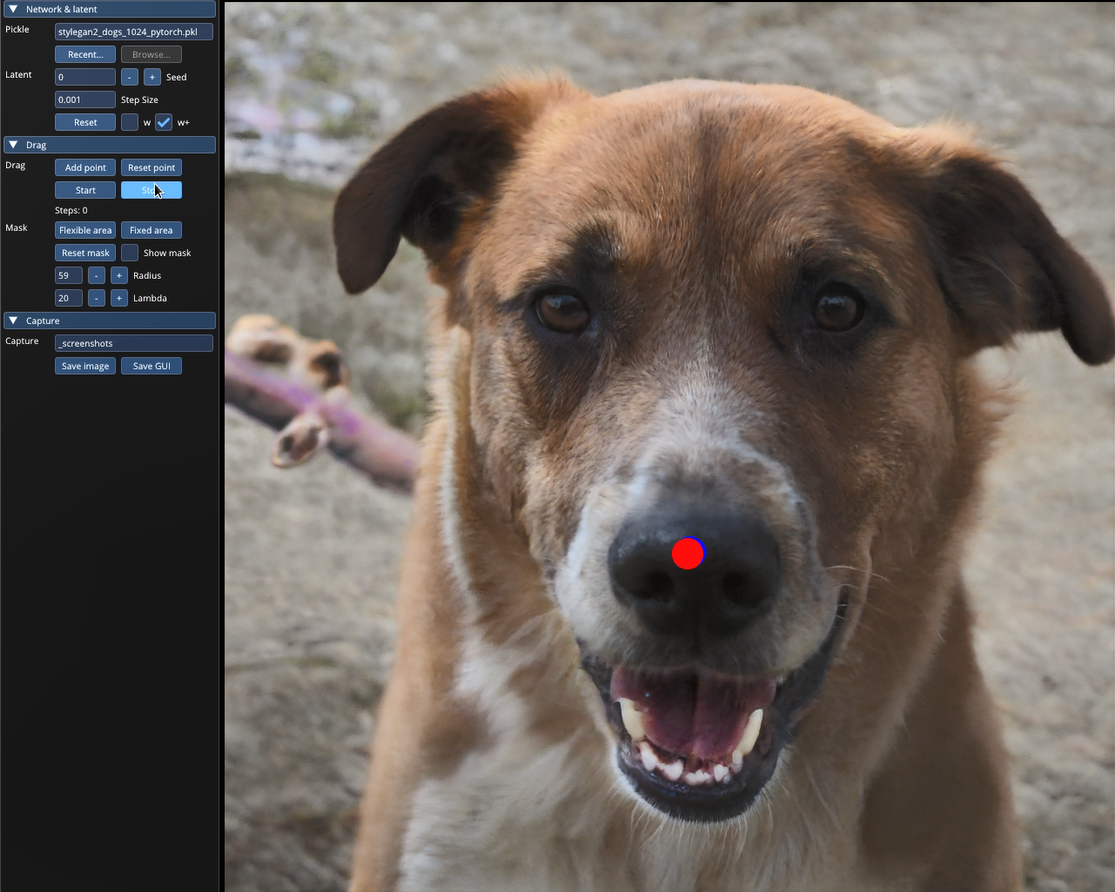
改变参数以后
import gradio as gr
# Function to create canvas
def create_canvas(w, h):
img = np.zeros(shape=(h-2, w-2, 3), dtype=np.uint8) + 255
im = cv2.copyMakeBorder(img,1,1,1,1,cv2.BORDER_CONSTANT)
return im
block = gr.Blocks().queue()
with block:
with gr.Row():
gr.Markdown("## 🎨Scribble to Image")
with gr.Row():
with gr.Column():
canvas_width = gr.Slider(label="Canvas Width", minimum=256, maximum=1024, value=512, step=1)
canvas_height = gr.Slider(label="Canvas Height", minimum=256, maximum=1024, value=512, step=1)
create_button = gr.Button(label="Start", value='Create Canvas!')
gr.Markdown(value='Click the little pencil icon below to change your brush width to make it finer (Gradio does not allow developers to set brush width, so it needs to be set manually) ')
input_image = gr.Image(source='upload', type='numpy', tool='sketch')
create_button.click(fn=create_canvas, inputs=[canvas_width, canvas_height], outputs=[input_image])
prompt = gr.Textbox(label="Prompt")
run_button = gr.Button(label="Run")
with gr.Accordion("Advanced Options", open=False):
num_samples = gr.Slider(label="Images", minimum=1, maximum=3, value=1, step=1)
image_resolution = gr.Slider(label="Image Resolution", minimum=256, maximum=768, value=512, step=64)
strength = gr.Slider(label="Control Strength", minimum=0.0, maximum=2.0, value=1.0, step=0.01)
ddim_steps = gr.Slider(label="Steps", minimum=1, maximum=30, value=20, step=1)
scale = gr.Slider(label="Guidance Scale", minimum=0.1, maximum=30.0, value=9.0, step=0.1)
seed = gr.Slider(label="Seed", minimum=-1, maximum=2147483647, step=1, randomize=True)
eta = gr.Number(label="eta (DDIM)", value=0.0)
a_prompt = gr.Textbox(label="Added Prompt", value='Best quality, very detailed')
n_prompt = gr.Textbox(label="Negative Prompt",
value='Cropped, worst quality, low quality')
with gr.Column():
result_gallery = gr.Gallery(label='Output', show_label=False, elem_id="gallery").style(grid=2, height='auto')
ips = [input_image, prompt, a_prompt, n_prompt, num_samples, image_resolution, ddim_steps, strength, scale, seed, eta]
run_button.click(fn=process, inputs=ips, outputs=[result_gallery])
block.launch(share=True)
INFO:botocore.vendored.requests.packages.urllib3.connectionpool:Starting new HTTP connection (1): proxy.modelarts.com
INFO:botocore.vendored.requests.packages.urllib3.connectionpool:Starting new HTTPS connection (1): www.huaweicloud.cn
Running on local URL: http://127.0.0.1:7861
Running on public URL: https://d6ad282fad59a417d6.gradio.live
This share link expires in 72 hours. For free permanent hosting and GPU upgrades (NEW!), check out Spaces: https://huggingface.co/spaces
参考
论文地址:https://arxiv.org/pdf/2306.14435.pdf
GitHub 地址:https://github.com/XingangPan/DragGAN

- 点赞
- 收藏
- 关注作者
评论(0)