军事领域关系抽取:UIE Slim最新升级版含数据标注、serving部署、模型蒸馏等教学,助力工业应用场景快速落地

军事领域关系抽取:UIE Slim最新升级版含数据标注、serving部署、模型蒸馏等教学,助力工业应用场景快速落地
本项目为UIE框架升级版本实体关系抽取,详细讲解了数据标注,以及医疗领域NER微调,同时完成基于SimpleServing的快速服务化部署,并考虑了在一些工业应用场景中对性能的要求较高,若不能有效压缩则无法实际应用。因此,将UIE模型的知识迁移到封闭域信息抽取小模型,同时使用FasterTokenizer进行文本预处理加速,整体提速7.6x倍。
项目效果预览:
- 小样本军事关系抽取数据集实验指标:
| 样本量 | Precision | Recall | F1 Score |
|---|---|---|---|
| 0-shot | 0.64634 | 0.53535 | 0.58564 |
| 5-shot | 0.89474 | 0.85000 | 0.87179 |
| 10-shot | 0.92793 | 0.85833 | 0.89177 |
| full-set | 0.92 | 0.92 | 0.92 |
- 性能对比
| 模型 | 推理耗时 | 提升倍数 |
|---|---|---|
| UIE+faster | 30.83 | 1 |
| uie+servering | 31.75 | 1- |
| UIE Slim | 5.90 | 5.23 |
- 可视化展示
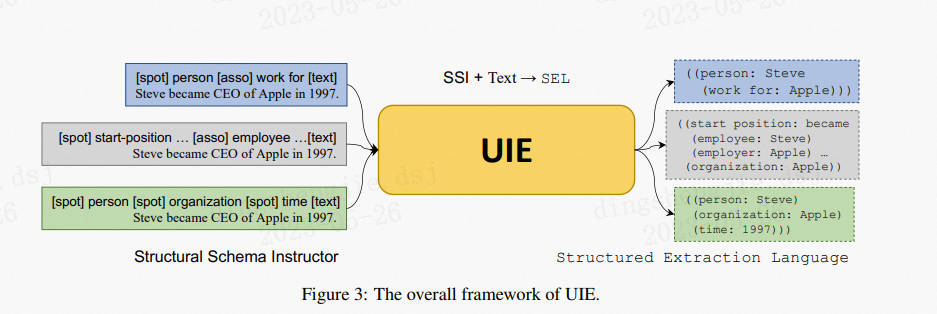
UIE(Universal Information Extraction):Yaojie Lu等人在ACL-2022中提出了通用信息抽取统一框架UIE。该框架实现了实体抽取、关系抽取、事件抽取、情感分析等任务的统一建模,并使得不同任务间具备良好的迁移和泛化能力。为了方便大家使用UIE的强大能力,PaddleNLP借鉴该论文的方法,基于ERNIE 3.0知识增强预训练模型,训练并开源了首个中文通用信息抽取模型UIE。该模型可以支持不限定行业领域和抽取目标的关键信息抽取,实现零样本快速冷启动,并具备优秀的小样本微调能力,快速适配特定的抽取目标。
- 框架升级:预训练模型参数配置统一,自定义参数配置的保存和加载无需额外开发:
- Trainer API 新增 BF16 训练、Recompute 重计算、Sharding 等多项分布式能力,通过简单配置即可进行超大规模预训练模型训练;
- 模型压缩 API 支持量化训练、词表压缩等功能,压缩后的模型精度损失更小,模型部署的内存占用大大降低;
- 数据增强API 全面升级,支持字、词、句子三种粒度数据增强策略,可轻松定制数据增强策略
项目链接以及码源见文末
#使用最新版本paddlenlp
!pip install -U paddlenlp
1. 基于Label Studio数据标注
1.1 Label Studio安装
以下标注示例用到的环境配置:
- Python 3.8+
- label-studio == 1.7.0
- paddleocr >= 2.6.0.1
在终端(terminal)使用pip安装label-studio:
pip install label-studio==1.7.0
安装完成后,运行以下命令行:
label-studio start
在浏览器打开http://localhost:8080/,输入用户名和密码登录,开始使用label-studio进行标注。
1.2 文本抽取标注教学
- 项目创建
点击创建(Create)开始创建一个新的项目,填写项目名称、描述,然后选择Object Detection with Bounding Boxes。
- 填写项目名称、描述

- 命名实体识别、关系抽取、事件抽取、实体/评价维度分类任务选择``Relation Extraction`。

- 添加标签(也可跳过后续在Setting/Labeling Interface中配置)

图中展示了实体类型标签的构建,其他类型标签的构建可参考
- 数据上传
先从本地上传txt格式文件,选择List of tasks,然后选择导入本项目。

- 标签构建
- Span类型标签

- Relation类型标签

Relation XML模板:
<Relations>
<Relation value="歌手"/>
<Relation value="发行时间"/>
<Relation value="所属专辑"/>
</Relations>
- 任务标注
- 实体抽取
标注示例:

该标注示例对应的schema为:
schema = [
'时间',
'选手',
'赛事名称',
'得分'
]
- 关系抽取

对于关系抽取,其P的类型设置十分重要,需要遵循以下原则
“{S}的{P}为{O}”需要能够构成语义合理的短语。比如对于三元组(S, 父子, O),关系类别为父子是没有问题的。但按照UIE当前关系类型prompt的构造方式,“S的父子为O”这个表达不是很通顺,因此P改成孩子更好,即“S的孩子为O”。合理的P类型设置,将显著提升零样本效果。
该标注示例对应的schema为:
schema = {
'作品名': [
'歌手',
'发行时间',
'所属专辑'
]
}
该标注示例对应的schema为:
schema = '情感倾向[正向,负向]'
- 数据导出
勾选已标注文本ID,选择导出的文件类型为JSON,导出数据:

- 数据转换
将导出的文件重命名为label_studio.json后,放入./data目录下。通过label_studio.py脚本可转为UIE的数据格式。
- 抽取式任务
python label_studio.py \
--label_studio_file ./data/label_studio.json \
--save_dir ./data \
--splits 0.8 0.1 0.1 \
--task_type ext
- 更多配置
label_studio_file: 从label studio导出的数据标注文件。save_dir: 训练数据的保存目录,默认存储在data目录下。negative_ratio: 最大负例比例,该参数只对抽取类型任务有效,适当构造负例可提升模型效果。负例数量和实际的标签数量有关,最大负例数量 = negative_ratio * 正例数量。该参数只对训练集有效,默认为5。为了保证评估指标的准确性,验证集和测试集默认构造全负例。splits: 划分数据集时训练集、验证集所占的比例。默认为[0.8, 0.1, 0.1]表示按照8:1:1的比例将数据划分为训练集、验证集和测试集。task_type: 选择任务类型,可选有抽取和分类两种类型的任务。options: 指定分类任务的类别标签,该参数只对分类类型任务有效。默认为[“正向”, “负向”]。prompt_prefix: 声明分类任务的prompt前缀信息,该参数只对分类类型任务有效。默认为"情感倾向"。is_shuffle: 是否对数据集进行随机打散,默认为True。seed: 随机种子,默认为1000.schema_lang:选择schema的语言,将会应该训练数据prompt的构造方式,可选有ch和en。默认为ch。separator: 实体类别/评价维度与分类标签的分隔符,该参数只对实体/评价维度分类任务有效。默认为"##"。
备注:
- 默认情况下 label_studio.py 脚本会按照比例将数据划分为 train/dev/test 数据集
- 每次执行 label_studio.py 脚本,将会覆盖已有的同名数据文件
- 在模型训练阶段我们推荐构造一些负例以提升模型效果,在数据转换阶段我们内置了这一功能。可通过
negative_ratio控制自动构造的负样本比例;负样本数量 = negative_ratio * 正样本数量。 - 对于从label_studio导出的文件,默认文件中的每条数据都是经过人工正确标注的。
- References
2.基于军事领域NER微调
2.1 加载数据数据标注
#加载数据集
!wget https://bj.bcebos.com/paddlenlp/datasets/military.tar.gz
!tar -xvf military.tar.gz
!mv military data
!rm military.tar.gz
--2023-05-30 14:54:45-- https://bj.bcebos.com/paddlenlp/datasets/military.tar.gz
正在解析主机 bj.bcebos.com (bj.bcebos.com)... 182.61.200.229, 182.61.200.195, 2409:8c04:1001:1002:0:ff:b001:368a
正在连接 bj.bcebos.com (bj.bcebos.com)|182.61.200.229|:443... 已连接。
已发出 HTTP 请求,正在等待回应... 200 OK
长度: 378880 (370K) [application/x-gzip]
正在保存至: “military.tar.gz”
military.tar.gz 100%[===================>] 370.00K 2.01MB/s in 0.2s
2023-05-30 14:54:46 (2.01 MB/s) - 已保存 “military.tar.gz” [378880/378880])
military/
military/unlabeled_data.txt
military/label_studio.json
!python label_studio.py \
--label_studio_file ./data/military/label_studio.json \
--save_dir ./data \
--splits 0.8 0.2 0 \
--negative_ratio 3 \
--task_type ext
2.2 模型微调
推荐使用 Trainer API 对模型进行微调。只需输入模型、数据集等就可以使用 Trainer API 高效快速地进行预训练、微调和模型压缩等任务,可以一键启动多卡训练、混合精度训练、梯度累积、断点重启、日志显示等功能,Trainer API 还针对训练过程的通用训练配置做了封装,比如:优化器、学习率调度等。
使用下面的命令,使用 uie-base 作为预训练模型进行模型微调,将微调后的模型保存至$finetuned_model:
单卡启动:
#单卡训练
!python finetune.py \
--device gpu \
--logging_steps 10 \
--save_steps 100 \
--eval_steps 100 \
--seed 1000 \
--model_name_or_path uie-base \
--output_dir ./checkpoint/model_best \
--train_path data/train.txt \
--dev_path data/dev.txt \
--max_seq_len 512 \
--per_device_train_batch_size 32 \
--per_device_eval_batch_size 32 \
--num_train_epochs 20 \
--learning_rate 1e-5 \
--do_train \
--do_eval \
--do_export \
--export_model_dir ./checkpoint/model_best \
--overwrite_output_dir \
--disable_tqdm True \
--metric_for_best_model eval_f1 \
--load_best_model_at_end True \
--save_total_limit 1
部分结果展示:
[2023-05-29 17:31:53,018] [ INFO] - eval_loss: 0.0008850682061165571, eval_precision: 0.92, eval_recall: 0.92, eval_f1: 0.92, eval_runtime: 0.8828, eval_samples_per_second: 113.271, eval_steps_per_second: 4.531, epoch: 20.0
[2023-05-29 17:31:53,018] [ INFO] - ***** eval metrics *****
[2023-05-29 17:31:53,018] [ INFO] - epoch = 20.0
[2023-05-29 17:31:53,019] [ INFO] - eval_f1 = 0.92
[2023-05-29 17:31:53,019] [ INFO] - eval_loss = 0.0009
[2023-05-29 17:31:53,019] [ INFO] - eval_precision = 0.92
[2023-05-29 17:31:53,019] [ INFO] - eval_recall = 0.92
[2023-05-29 17:31:53,019] [ INFO] - eval_runtime = 0:00:00.88
[2023-05-29 17:31:53,019] [ INFO] - eval_samples_per_second = 113.271
[2023-05-29 17:31:53,019] [ INFO] - eval_steps_per_second = 4.531
[2023-05-29 17:31:53,020] [ INFO] - Exporting inference model to ./checkpoint/model_best/model
[2023-05-29 17:31:59,117] [ INFO] - Inference model exported.
#多卡训练:GPU环境中使用,可以指定gpus参数进行多卡训练:
# !python -u -m paddle.distributed.launch --gpus "0,1" finetune.py \
# --device gpu \
# --logging_steps 10 \
# --save_steps 100 \
# --eval_steps 100 \
# --seed 1000 \
# --model_name_or_path uie-base \
# --output_dir ./checkpoint/model_best \
# --train_path data/train.txt \
# --dev_path data/dev.txt \
# --max_seq_len 512 \
# --per_device_train_batch_size 8 \
# --per_device_eval_batch_size 8 \
# --num_train_epochs 20 \
# --learning_rate 1e-5 \
# --do_train \
# --do_eval \
# --do_export \
# --export_model_dir ./checkpoint/model_best \
# --overwrite_output_dir \
# --disable_tqdm True \
# --metric_for_best_model eval_f1 \
# --load_best_model_at_end True \
# --save_total_limit 1
注意:如果模型是跨语言模型 UIE-M,还需设置 --multilingual。
该示例代码中由于设置了参数 --do_eval,因此在训练完会自动进行评估。
可配置参数说明:
model_name_or_path:必须,进行 few shot 训练使用的预训练模型。可选择的有 “uie-base”、 “uie-medium”, “uie-mini”, “uie-micro”, “uie-nano”, “uie-m-base”, “uie-m-large”,“uie-x-base”。multilingual:是否是跨语言模型,用 “uie-m-base”, “uie-m-large” 等模型进微调得到的模型也是多语言模型,需要设置为 True;默认为 False。device: 训练设备,可选择 ‘cpu’、‘gpu’、‘npu’ 其中的一种;默认为 GPU 训练。logging_steps: 训练过程中日志打印的间隔 steps 数,默认10。save_steps: 训练过程中保存模型 checkpoint 的间隔 steps 数,默认100。eval_steps: 训练过程中保存模型 checkpoint 的间隔 steps 数,默认100。seed:全局随机种子,默认为 42。output_dir:必须,模型训练或压缩后保存的模型目录;默认为None。train_path:训练集路径;默认为None。dev_path:开发集路径;默认为None。max_seq_len:文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为512。per_device_train_batch_size:用于训练的每个 GPU 核心/CPU 的batch大小,默认为8。per_device_eval_batch_size:用于评估的每个 GPU 核心/CPU 的batch大小,默认为8。num_train_epochs: 训练轮次,使用早停法时可以选择 100;默认为10。learning_rate:训练最大学习率,UIE-X 推荐设置为 1e-5;默认值为3e-5。label_names:训练数据标签label的名称,UIE-X 设置为’start_positions’ ‘end_positions’;默认值为None。do_train:是否进行微调训练,设置该参数表示进行微调训练,默认不设置。do_eval:是否进行评估,设置该参数表示进行评估,默认不设置。do_export:是否进行导出,设置该参数表示进行静态图导出,默认不设置。export_model_dir:静态图导出地址,默认为None。overwrite_output_dir: 如果True,覆盖输出目录的内容。如果output_dir指向检查点目录,则使用它继续训练。disable_tqdm: 是否使用tqdm进度条。metric_for_best_model:最优模型指标,UIE-X 推荐设置为eval_f1,默认为None。load_best_model_at_end:训练结束后是否加载最优模型,通常与metric_for_best_model配合使用,默认为False。save_total_limit:如果设置次参数,将限制checkpoint的总数。删除旧的checkpoints输出目录,默认为None。
2.3 模型评估
评估方式说明:采用单阶段评价的方式,即关系抽取、事件抽取等需要分阶段预测的任务对每一阶段的预测结果进行分别评价。验证/测试集默认会利用同一层级的所有标签来构造出全部负例。
可开启debug模式对每个正例类别分别进行评估,该模式仅用于模型调试:
!python evaluate.py \
--model_path ./checkpoint/model_best \
--test_path ./data/dev.txt \
--batch_size 16 \
--device gpu \
--max_seq_len 512
#对 UIE-M 进行模型评估:
# !python evaluate.py \
# --model_path ./checkpoint/model_best \
# --test_path ./data/dev.txt \
# --batch_size 16 \
# --max_seq_len 512 \
# --multilingual
#debug
!python evaluate.py \
--model_path ./checkpoint/model_best \
--test_path ./data/dev.txt \
--debug
部分结果展示:
[2023-05-29 17:32:09,124] [ INFO] - -----------------------------
[2023-05-29 17:32:09,124] [ INFO] - Class Name: all_classes
[2023-05-29 17:32:09,124] [ INFO] - Evaluation Precision: 0.92000 | Recall: 0.92000 | F1: 0.92000
[2023-05-29 17:32:18,145] [ INFO] - Class Name: 武器名称
[2023-05-29 17:32:18,145] [ INFO] - Evaluation Precision: 0.96000 | Recall: 0.96000 | F1: 0.96000
[2023-05-29 17:32:18,961] [ INFO] - -----------------------------
[2023-05-29 17:32:18,961] [ INFO] - Class Name: X的产国
[2023-05-29 17:32:18,961] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2023-05-29 17:32:19,762] [ INFO] - -----------------------------
[2023-05-29 17:32:19,762] [ INFO] - Class Name: X的研发单位
[2023-05-29 17:32:19,762] [ INFO] - Evaluation Precision: 0.81481 | Recall: 0.81481 | F1: 0.81481
[2023-05-29 17:32:20,554] [ INFO] - -----------------------------
[2023-05-29 17:32:20,554] [ INFO] - Class Name: X的类型
[2023-05-29 17:32:20,554] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
可配置参数说明:
device: 评估设备,可选择 ‘cpu’、‘gpu’、‘npu’ 其中的一种;默认为 GPU 评估。model_path: 进行评估的模型文件夹路径,路径下需包含模型权重文件model_state.pdparams及配置文件model_config.json。test_path: 进行评估的测试集文件。batch_size: 批处理大小,请结合机器情况进行调整,默认为16。max_seq_len: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为512。debug: 是否开启debug模式对每个正例类别分别进行评估,该模式仅用于模型调试,默认关闭。multilingual: 是否是跨语言模型,默认关闭。schema_lang: 选择schema的语言,可选有ch和en。默认为ch,英文数据集请选择en。
2.4 模型预测
paddlenlp.Taskflow装载定制模型,通过task_path指定模型权重文件的路径,路径下需要包含训练好的模型权重文件model_state.pdparams。
相关bug:KeyError: ‘sentencepiece_model_file’
同一个脚本先加载uie-x,再加载uie,报错KeyError: ‘sentencepiece_model_file’:https://github.com/PaddlePaddle/PaddleNLP/issues/5795
#加载过uiem之后不能加载uie模型:https://github.com/PaddlePaddle/PaddleNLP/issues/5615
- 修复加载最新版本paddlenlp重启内核即可
- 重启项目,先加载uie,再加在uie-x则不出错
# !pip install --pre --upgrade paddlenlp -f https://www.paddlepaddle.org.cn/whl/paddlenlp.html
from pprint import pprint
from paddlenlp import Taskflow
schema = {"武器名称": ["产国", "类型", "研发单位"]}
my_ie = Taskflow("information_extraction", schema=schema, task_path='./checkpoint/model_best')
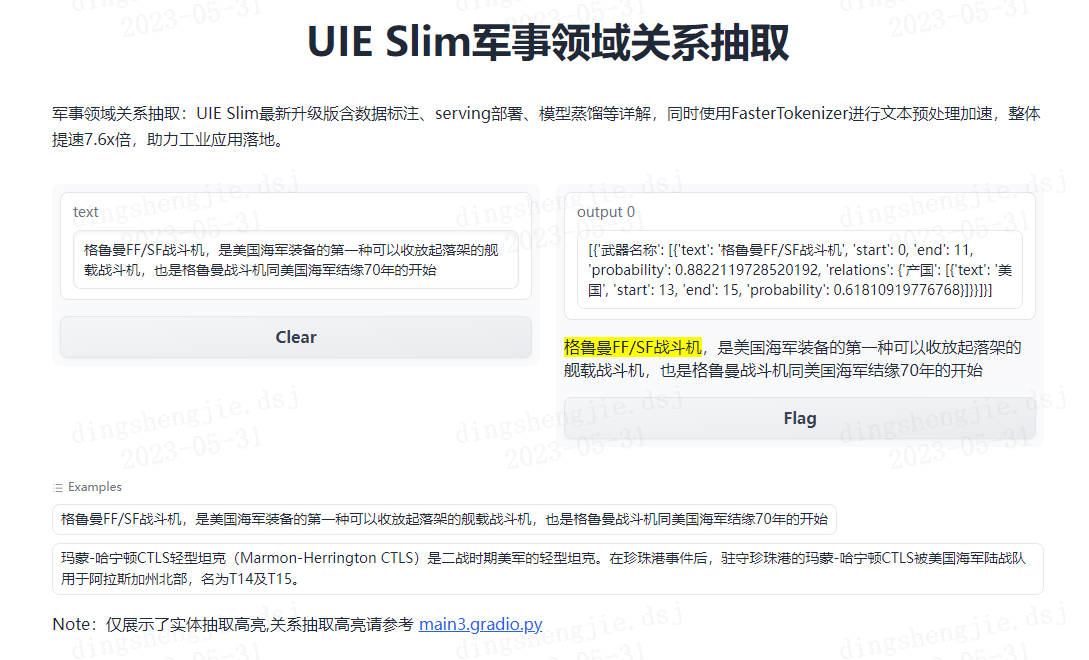
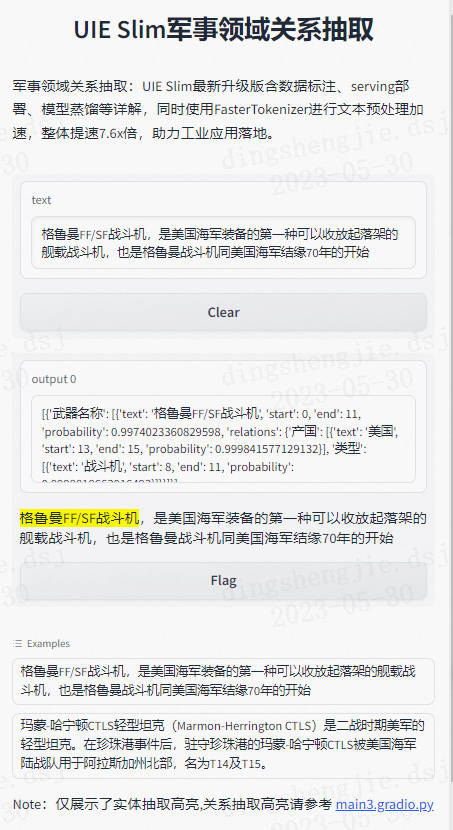
pprint(my_ie("格鲁曼FF/SF战斗机,是美国海军装备的第一种可以收放起落架的舰载战斗机,也是格鲁曼战斗机同美国海军结缘70年的开始。"))
[{'武器名称': [{'end': 11,
'probability': 0.9973600367608348,
'relations': {'产国': [{'end': 15,
'probability': 0.9998343059352948,
'start': 13,
'text': '美国'}],
'类型': [{'end': 11,
'probability': 0.9998778133542885,
'start': 8,
'text': '战斗机'}]},
'start': 0,
'text': '格鲁曼FF/SF战斗机'}]}]
2.5 模型快速服务化部署
在 UIE的服务化能力中提供基于PaddleNLP SimpleServing 来搭建服务化能力,通过几行代码即可搭建服务化部署能力。
- 环境准备
使用有SimpleServing功能的PaddleNLP版本(或者最新的develop版本)
pip install paddlenlp >= 2.5.0
- Server服务启动
进入文件当前所在路径
paddlenlp server server:app --workers 1 --host 0.0.0.0 --port 8190
- Client请求启动
python client.py
服务化自定义参数
Server 自定义参数
schema替换
#Default schema
schema = {"武器名称": ["产国", "类型", "研发单位"]}
* 设置模型路径
#Default task_path
uie = Taskflow('information_extraction', task_path='./checkpoint/model_best/', schema=schema)
* 多卡服务化预测
PaddleNLP SimpleServing 支持多卡负载均衡预测,主要在服务化注册的时候,注册两个Taskflow的task即可,下面是示例代码
uie1 = Taskflow('information_extraction', task_path='../../../checkpoint/model_best/', schema=schema, device_id=0)
uie2 = Taskflow('information_extraction', task_path='../../../checkpoint/model_best/', schema=schema, device_id=1)
service.register_taskflow('uie', [uie1, uie2])
- 更多配置
from paddlenlp import Taskflow
schema =
uie = Taskflow("zero_shot_text_classification",
schema=schema,
model="uie-base",
max_seq_len=512,
batch_size=1,
pred_threshold=0.5,
precision="fp32")
schema:定义任务标签候选集合。model:选择任务使用的模型,默认为utc-base, 可选有utc-xbase,utc-base,utc-medium,utc-micro,utc-mini,utc-nano,utc-pico。max_seq_len:最长输入长度,包括所有标签的长度,默认为512。batch_size:批处理大小,请结合机器情况进行调整,默认为1。pred_threshold:模型对标签预测的概率在0~1之间,返回结果去掉小于这个阈值的结果,默认为0.5。precision:选择模型精度,默认为fp32,可选有fp16和fp32。fp16推理速度更快。如果选择fp16,请先确保机器正确安装NVIDIA相关驱动和基础软件,确保CUDA>=11.2,cuDNN>=8.1.1,初次使用需按照提示安装相关依赖。其次,需要确保GPU设备的CUDA计算能力(CUDA Compute Capability)大于7.0,典型的设备包括V100、T4、A10、A100、GTX 20系列和30系列显卡等。更多关于CUDA Compute Capability和精度支持情况请参考NVIDIA文档:GPU硬件与支持精度对照表。- Client 自定义参数
#Changed to input texts you wanted
texts = ['格鲁曼FF/SF战斗机,是美国海军装备的第一种可以收放起落架的舰载战斗机,也是格鲁曼战斗机同美国海军结缘70年的开始。']
# %cd /home/aistudio/deploy
# !paddlenlp server server:app --workers 1 --host 0.0.0.0 --port 8190
#Error loading ASGI app. Could not import module "server".
#去终端执行即可
# %cd /home/aistudio/deploy
# !python client.py
在notebook如果不行,可以直接进入终端进行调试,需要注意的是要在同一个路径下不然会报错:

3.UIE Slim 数据蒸馏
在UIE强大的抽取能力背后,同样需要较大的算力支持计算。在一些工业应用场景中对性能的要求较高,若不能有效压缩则无法实际应用。因此,我们基于数据蒸馏技术构建了UIE Slim数据蒸馏系统。其原理是通过数据作为桥梁,将UIE模型的知识迁移到封闭域信息抽取小模型,以达到精度损失较小的情况下却能达到大幅度预测速度提升的效果。
Step 1: 使用UIE模型对标注数据进行finetune,得到Teacher Model。
Step 2: 用户提供大规模无标注数据,需与标注数据同源。使用Taskflow UIE对无监督数据进行预测。
Step 3: 使用标注数据以及步骤2得到的合成数据训练出封闭域Student Model。
- 数据集介绍
3.1 离线蒸馏
- 通过训练好的UIE定制模型预测无监督数据的标签
可配置参数说明:
data_path: 标注数据(doccano_ext.json)及无监督文本(unlabeled_data.txt)路径。model_path: 训练好的UIE定制模型路径。save_dir: 学生模型训练数据保存路径。synthetic_ratio: 控制合成数据的比例。最大合成数据数量=synthetic_ratio*标注数据数量。task_type: 选择任务类型,可选有entity_extraction,relation_extraction,event_extraction和opinion_extraction。因为是封闭域信息抽取,需指定任务类型。seed: 随机种子,默认为1000。
NOTE:schema需要根据标注数据在data_distill.py中进行配置,且schema需要包含标注数据中的所有标签类型。
!cp /home/aistudio/data/sample_index.json /home/aistudio/data/military
%cd data_distill
!python data_distill.py \
--data_path /home/aistudio/data/military \
--save_dir student_data \
--task_type relation_extraction \
--synthetic_ratio 10 \
--model_path /home/aistudio/checkpoint/model_best #已经训练好的模型
3.2 老师模型评估
UIE微调阶段针对UIE训练格式数据评估模型效果(该评估方式非端到端评估,不适合关系、事件等任务),可通过以下评估脚本针对原始标注格式数据评估模型效果
可配置参数说明:
model_path: 训练好的UIE定制模型路径。test_path: 测试数据集路径。label_maps_path: 学生模型标签字典。batch_size: 批处理大小,默认为8。max_seq_len: 最大文本长度,默认为256。task_type: 选择任务类型,可选有entity_extraction,relation_extraction,event_extraction和opinion_extraction。因为是封闭域信息抽取的评估,需指定任务类型。
!python evaluate_teacher.py \
--task_type relation_extraction \
--test_path ./student_data/dev_data.json \
--label_maps_path ./student_data/label_maps.json \
--model_path /home/aistudio/checkpoint/model_best
3.3 学生模型训练
可配置参数说明:
train_path: 训练集文件路径。dev_path: 验证集文件路径。batch_size: 批处理大小,默认为16。learning_rate: 学习率,默认为3e-5。save_dir: 模型存储路径,默认为./checkpoint。max_seq_len: 最大文本长度,默认为256。weight_decay: 表示AdamW优化器中使用的 weight_decay 的系数。warmup_proportion: 学习率warmup策略的比例,如果0.1,则学习率会在前10%训练step的过程中从0慢慢增长到learning_rate, 而后再缓慢衰减,默认为0.0。num_epochs: 训练轮数,默认为100。seed: 随机种子,默认为1000。encoder: 选择学生模型的模型底座,默认为ernie-3.0-mini-zh。task_type: 选择任务类型,可选有entity_extraction,relation_extraction,event_extraction和opinion_extraction。因为是封闭域信息抽取,需指定任务类型。logging_steps: 日志打印的间隔steps数,默认10。valid_steps: evaluate的间隔steps数,默认200。device: 选用什么设备进行训练,可选cpu或gpu。init_from_ckpt: 可选,模型参数路径,热启动模型训练;默认为None。
!python train.py \
--task_type relation_extraction \
--train_path student_data/train_data.json \
--dev_path student_data/dev_data.json \
--label_maps_path student_data/label_maps.json \
--num_epochs 200 \
--encoder ernie-3.0-mini-zh\
--device "gpu"\
--eval_steps 100\
--logging_steps 50\
--save_dir './checkpoint-mini'\
--batch_size 32
3.4 学生模型评估
!python evaluate.py \
--model_path /home/aistudio/data_distill/checkpoint-mini/model_best \
--test_path student_data/dev_data.json \
--task_type relation_extraction \
--label_maps_path student_data/label_maps.json \
--encoder ernie-3.0-mini-zh
- Evaluation precision: {'entity_f1': 0.90155, 'entity_precision': 0.93548, 'entity_recall': 0.87, 'relation_f1': 0.82517, 'relation_precision': 0.86765, 'relation_recall': 0.78667}
3.5 Taskflow部署学生模型
- 通过Taskflow一键部署封闭域信息抽取模型,
task_path为学生模型路径。
from pprint import pprint
from paddlenlp import Taskflow
ie = Taskflow("information_extraction",model="uie-data-distill-gp", task_path="/home/aistudio/data_distill/checkpoint-mini/model_best") # Schema is fixed in closed-domain information extraction
pprint(ie("格鲁曼FF/SF战斗机,是美国海军装备的第一种可以收放起落架的舰载战斗机,也是格鲁曼战斗机同美国海军结缘70年的开始。"))
3.6 服务化快速部署
#终端运行
# %cd /home/aistudio/data_distill/distill_deploy
#!paddlenlp server server:app --workers 1 --host 0.0.0.0 --port 8189
#!python client.py
4.性能提升测评(重点)
对比原模型、SimpleServing、以及蒸馏后的模型推理速度
5.可视化显示
代码见项目中gradio文件
6.总结
6.1 方案对比总结
- 小样本军事关系抽取数据集实验指标:
| 样本量 | Precision | Recall | F1 Score |
|---|---|---|---|
| 0-shot | 0.64634 | 0.53535 | 0.58564 |
| 5-shot | 0.89474 | 0.85000 | 0.87179 |
| 10-shot | 0.92793 | 0.85833 | 0.89177 |
| full-set | 0.92 | 0.92 | 0.92 |
- 性能对比
| 模型 | 推理耗时 | 提升倍数 |
|---|---|---|
| UIE+faster | 30.83 | 1 |
| uie+servering | 31.75 | 1- |
| UIE Slim | 5.90 | 5.23 |
本项目为UIE框架升级版本关系抽取,详细讲解了数据标注,以及军事领域RE微调,同时完成基于SimpleServing的快速服务化部署,并考虑了在一些工业应用场景中对性能的要求较高,若不能有效压缩则无法实际应用。因此,将UIE模型的知识迁移到封闭域信息抽取小模型,同时使用FasterTokenizer进行文本预处理加速,整体提速7.6x倍。
6.2 更多优质项目推荐
NLP专栏简介:数据增强、智能标注、意图识别算法|多分类算法、文本信息抽取、多模态信息抽取、可解释性分析、性能调优、模型压缩算法等:
[小样本文本分类应用:基于UTC的医疗意图多分类,训练调优部署一条龙]
[“中国法研杯”司法人工智能挑战赛:基于UTC的多标签/层次分类小样本文本应用]
[Paddlenlp之UIE模型实战实体抽取任务【打车数据、快递单】]
[Paddlenlp之UIE关系抽取模型【高管关系抽取为例】]
[UIE Slim满足工业应用场景,解决推理部署耗时问题,提升效能!]
[基于Labelstudio的UIE半监督智能标注方案(本地版),赶快用起来啦!]
[基于Labelstudio的UIE半监督深度学习的智能标注方案(云端版),提效!]
[基于ERNIELayout&PDFplumber-UIEX多方案学术论文信息抽取]
[基线提升至96.45%:2022 司法杯犯罪事实实体识别+数据蒸馏+主动学习]
[[信息抽取]基于ERNIE3.0的多对多信息抽取算法:属性关系抽取]
项目链接以及码源
- 参考链接

- 点赞
- 收藏
- 关注作者
评论(0)