【我与ModelArts的故事】AI小白的成长之路

记得2021年我还在上大学的时候,参与了导师的研究课题,需要训练一个目标检测模型,可是仅仅是安装环境就浪费了我一两天的时间都过不去。因为我们使用的是Pyhon语言,要想把程序跑起来,第一关就要把Python环境配置好,如果你没有很好的方法的话,环境配置可能要占据60%以上的时间,而且它还是建立在你最终能搞定的前提下,否则可能遇到各种各样的报错,就像下面这样: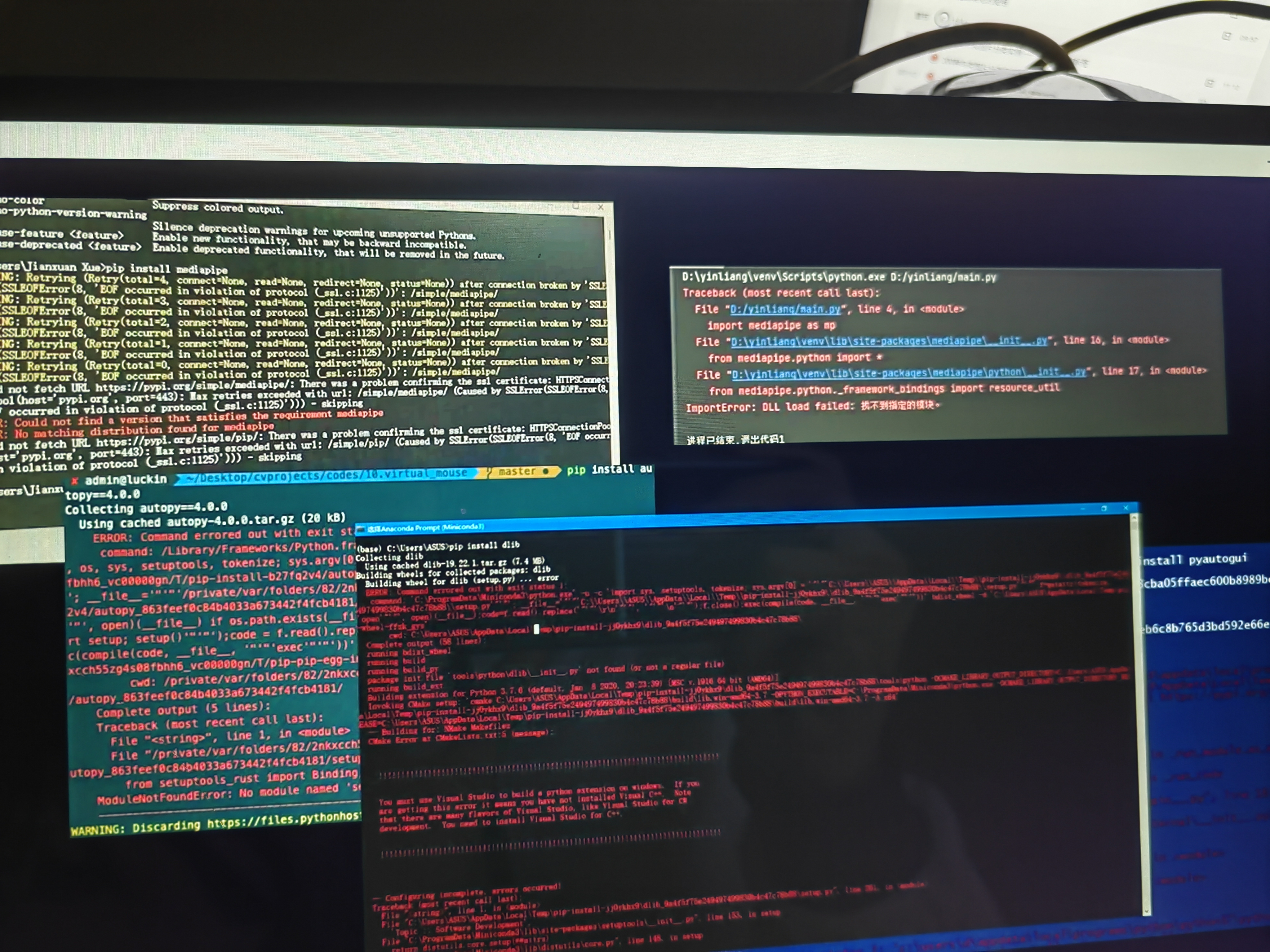
更麻烦的时候可能要来回切换不同版本的Python、包和AI框架,甚至从源码编译软件。重新配置环境浪费时间不说,更重要的是打击学习兴趣和自信心。机缘巧合下我在华为云上发现了ModelArts一站式AI开发平台,它内置了市面上的主流框架以及多种镜像,避免了环境冲突问题导致的各种报错,可以节约开发者大量的时间。
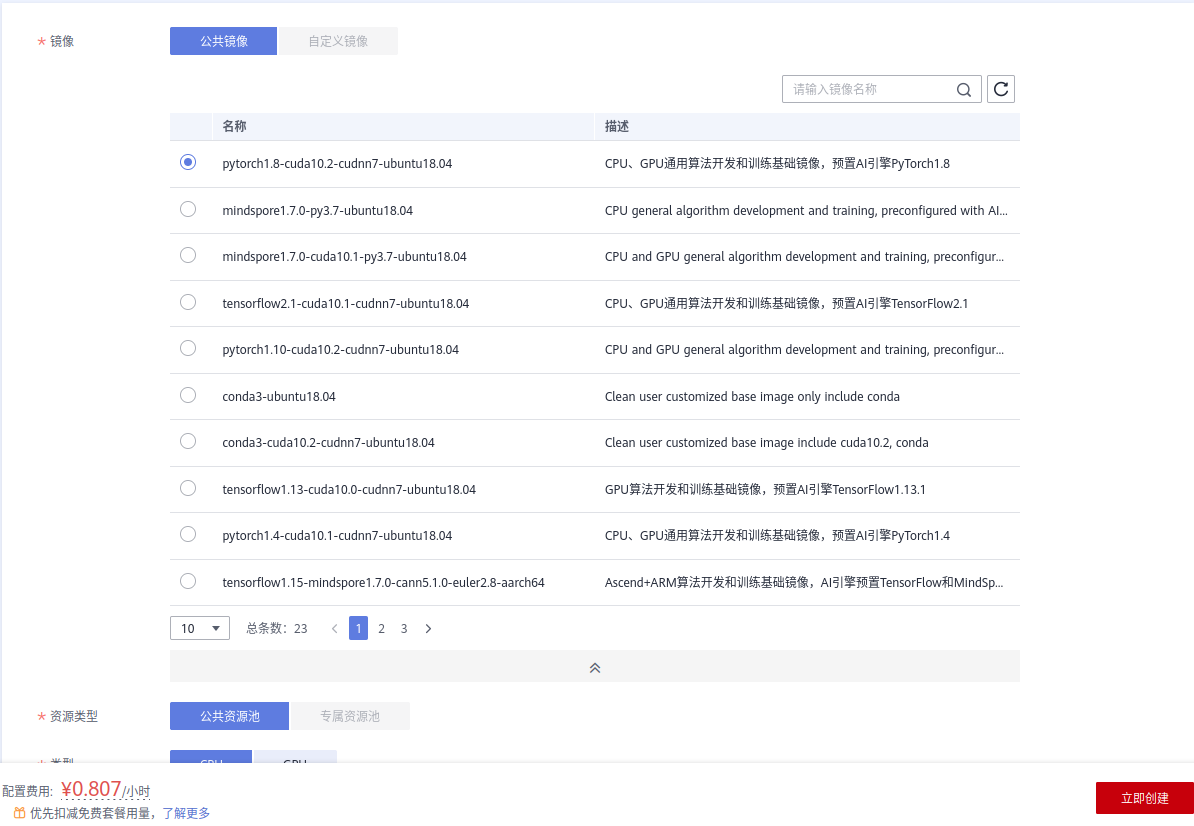
除此之外,训练模型还需要大量的标注图像,手工一张张标注不仅耗时耗力,还经常出现错误标注的现象。ModelArts数据集支持自动标注,只需要人工标注少量图像,智能标注就可以帮助你完成剩下的工作,接下来只需要手动确认即可,标注起来简直不要太轻松。
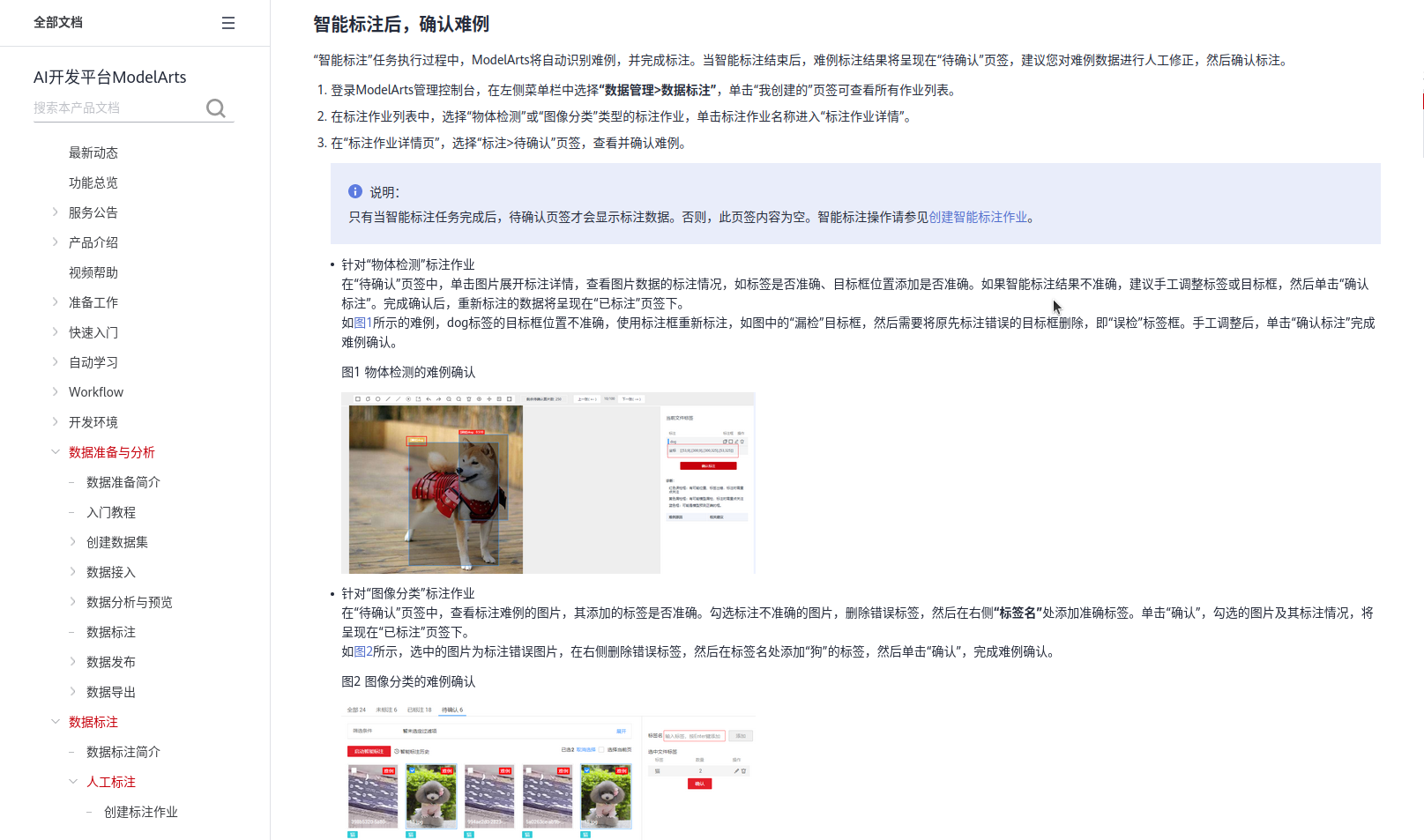
由于我本身学习的是软件专业,对于人工智能很多概念并不清除,急需要找到一条AI 的学习路径。我在网上花了很多钱买了各种各样的课程,但是它们的质量参差不其,我又花了很多时间用来试错,学习了很多知识但是却无法应用到项目里面。好多资料缺少复现的代码和文档,或者只是存在于理论层面无法凭借自己的能力复现,有些知识甚至严重落后于当前的社会。后来我在华为云上发现了AI专业学习路径,并且报名了华为云AI实战营,在华为云老师的带领下学习AI方面的基础知识,他们在我后来项目中的实际应用起到了至关重要的作用。
掌握了一些基础的AI知识,我又参与了2021华为云AI论文精读会,毕竟紧跟学术届最新论文才能保证不会落伍。为了进一步提高自己的动手实践能力,我使用华为云的AI Gallery中提供了丰富的模型和案例以及预置算法训练模型,加深我对不同算法的理解,从0到1掌握了使用ModelArts训练模型的基本流程。2022年我使用ModelArts训练自己的目标检测算法完成了人工智能的毕设,我想我的人工智能学习到此可能也要告一段落了。
此后的好多个夜晚,我都有些许不甘,脑海中总会闪过许多声音,仿佛在问自己:“少年,你要止步于此吗”?

也许是对AI的热爱,我一直未停下探索的脚步,在初秋某个百无聊赖的夜晚,微信群里面蹦出一个通知,我顺手点开了它的链接,上面写着ModelBox实战营,听起来和ModelArts好像,似乎是一个家族。或许是好奇心在作怪,于是抱着试一下的心态参加了,果然幸运女神再次降临。在此期间,我学习了很多和AI应用开发相关的知识,从模型训练到端-边-云模型部署。期间和很多优秀的小伙伴一起学习AI,认识了很多能力出众的华为云老师,厉害的大佬总是能向下兼容,也体会到一个产品的成功并非是偶然的,是有一群足够专业的人有条不紊的严格按照流程在研究和推进的,以及多部门协同作战最终拿到胜利的喜悦。慢慢的也就懂得一个人的能力再强,也不可能强得过一个团队,渐渐的思维和眼界就会不断的被打开,能看到不一样的风景。说了这么多,最后带大家亲身体验一下如何使用ModelArts进行模型的训练。
ModelArts是一站式AI应用开发平台,支持丰富的预置数据集、算法和模型、Notebook案例,以及端到端的开发模板,可以大大加速人工智能应用的生产效率。同时为了降低开发难度,ModelArts内置了高阶开发框架MoXing,其底层对接基础深度学习开发引擎或开发库,上层对多个基础模块进行抽象和适配,如高性能的优化器、数据读取和处理工具等,支持训练加速和超参搜索等功能,其逻辑框架图如下:
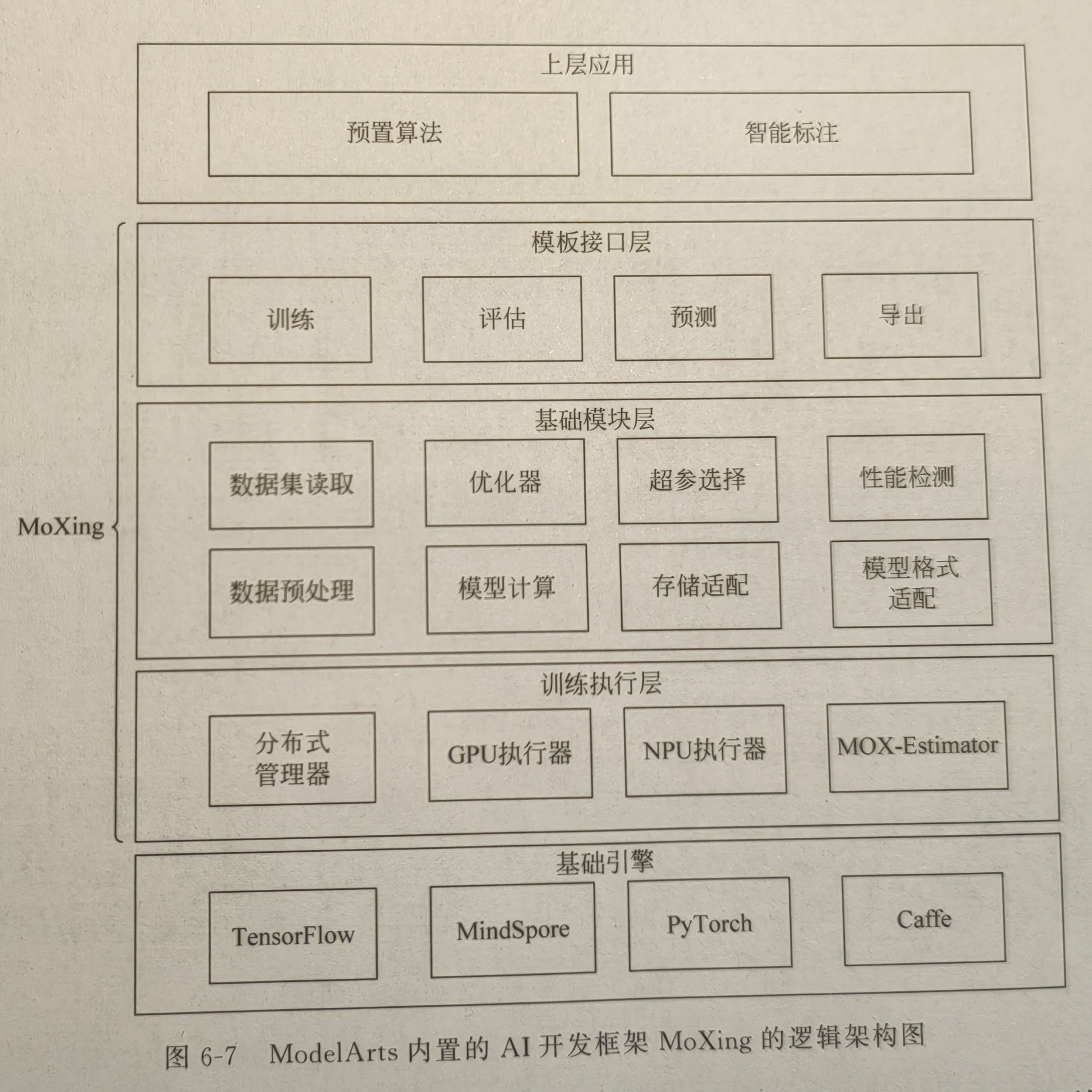
并且,MoXing对外提供了一套Template接口,对于常用算法可以大幅度减少算法开发工作量,具体可以参考MoXing开发指南。
俗话说的好,道路千万条,安全第一条,行车不规范,亲人两行泪!接下来小编就基于ModelArts训练一个SSD人脸手机检测模型,用于检测驾驶行为。

1、首先我们从AI Gallery中下载街道人车检测数据集到OBS桶中
2、之后使用Python和Opencv以每秒15帧将图像写入到视频文件
3、最后再使用ssdlite_movilenet_v2轻量化目标检测模型进行测试
SSD:Single Shot MultiBox Detector
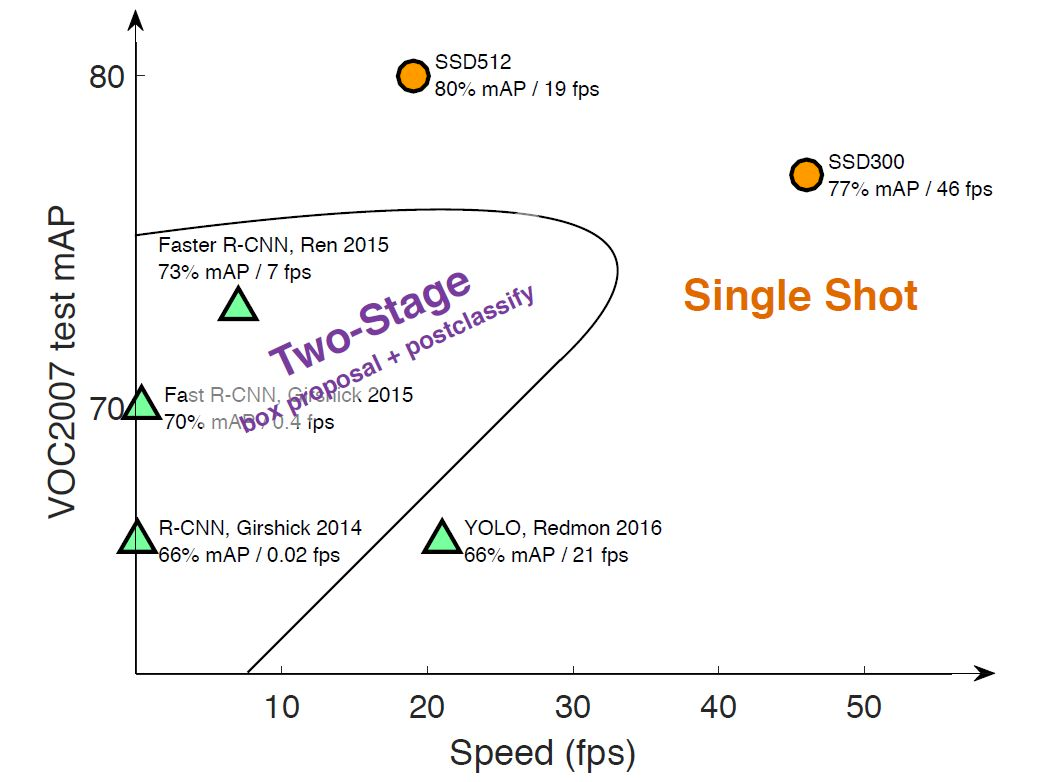
SSD使用one-stage的目标检测方法,与其对应的还有Yolo,相比于two-stage方法(如R-CNN系列算法)先产生候选框再进行分类回归速度更快,它利用CNN提取特征后直接进行分类与回归,整个过程只需要一步。
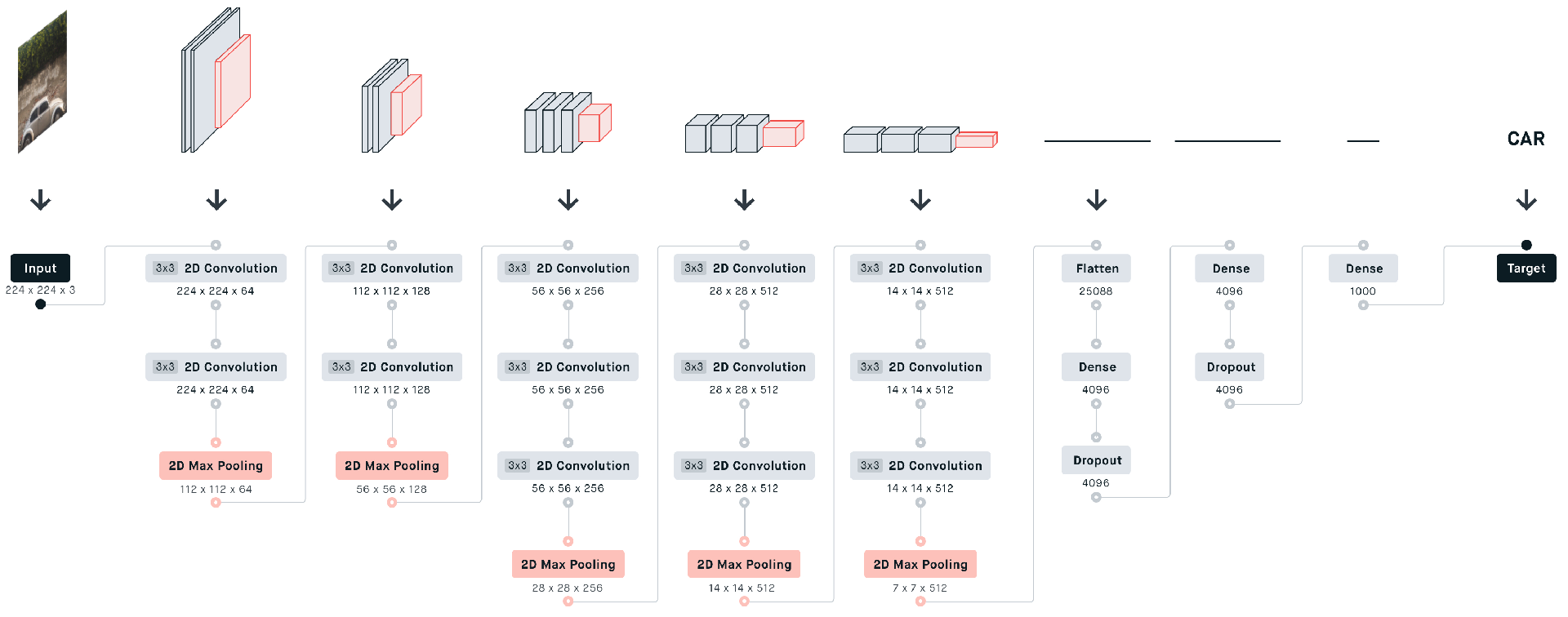
SSD前半部分使用VGG16提取特征,并对其进行了改进:
1、将输入图像的大小由224x224变为300x300
2、将第6个和第7个全连接层(FC6、FC7)变为卷积层(conv6、conv7)
3、修改了最后一个Pool层的大小并去掉了所有的Dropout层以及FC8层,在后面添加更多的卷积层
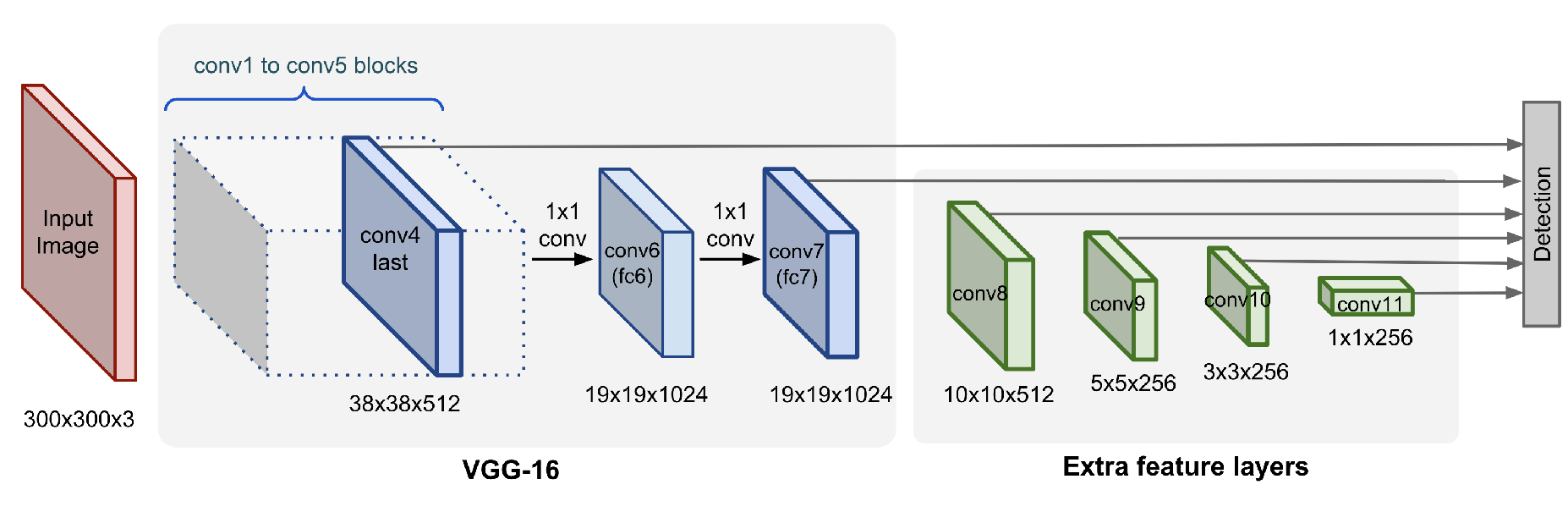
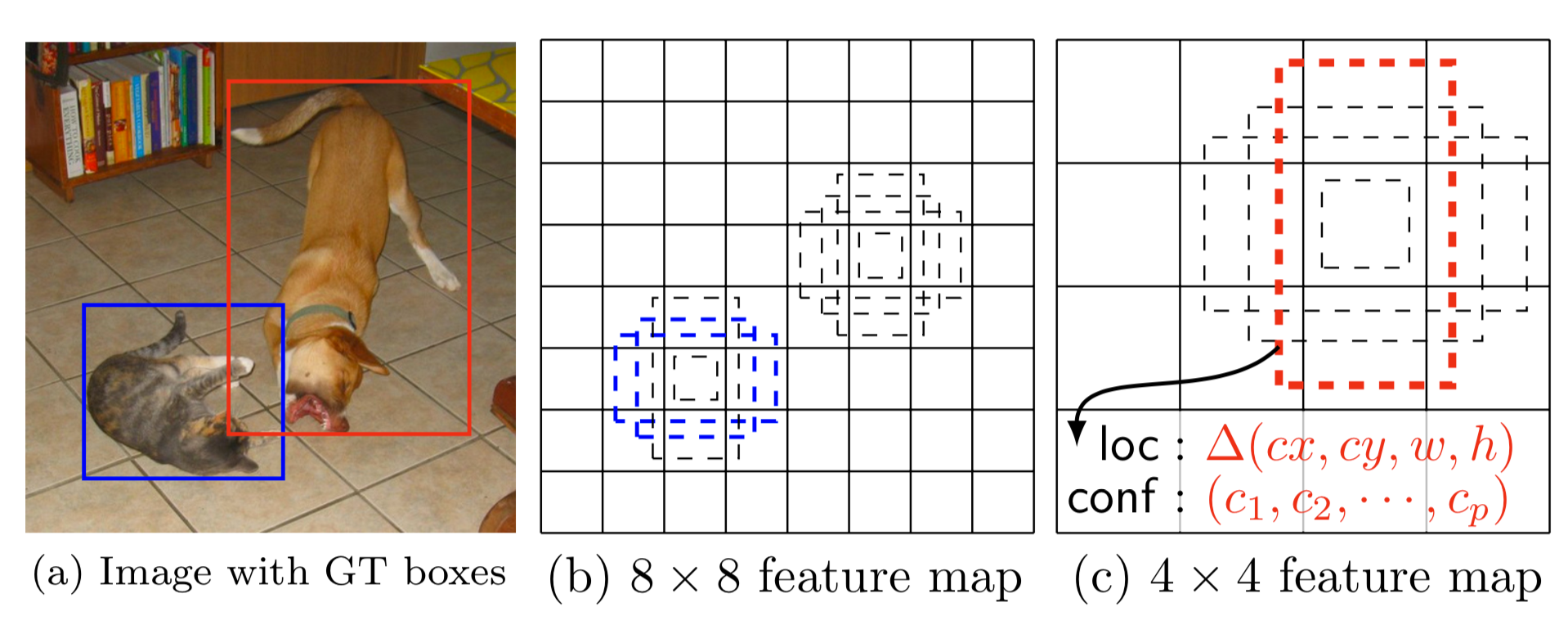
SSD用conv4、conv7、conv8、conv9、conv10、conv11这6个卷基层提取的不同尺度的特征图用来检测不同大小的目标,相比于Yolo将画面分成多小格子,SSD借鉴了Faster-RCNN中间的锚框anchor box的概念,在6个特征图上面使用了8732个先验框,在不同大小的特征图上面为每个小格子设置4个先验框来减少训练的难度,最终的检测流程如下:

ssdlite_movilenet_v2使用mobilenet对vgg16进行替换减少卷积参数的运算量提高运行速度,模型推理代码可以查看Notebook:

TensorFlow object detection:
由于小编本地算力有限,所以在ModelArts中安装TensorFlow object detection,训练ssdlite_mobilenet_v2_coco模型,可以点击我发布的Notebook一键运行。
中间启动TensorBoard页面崩溃了🥺

重新进入后才加载成功,但训练数据已经不在notebook更新了,我们使用TenorBoard对训练结果进行可视化:
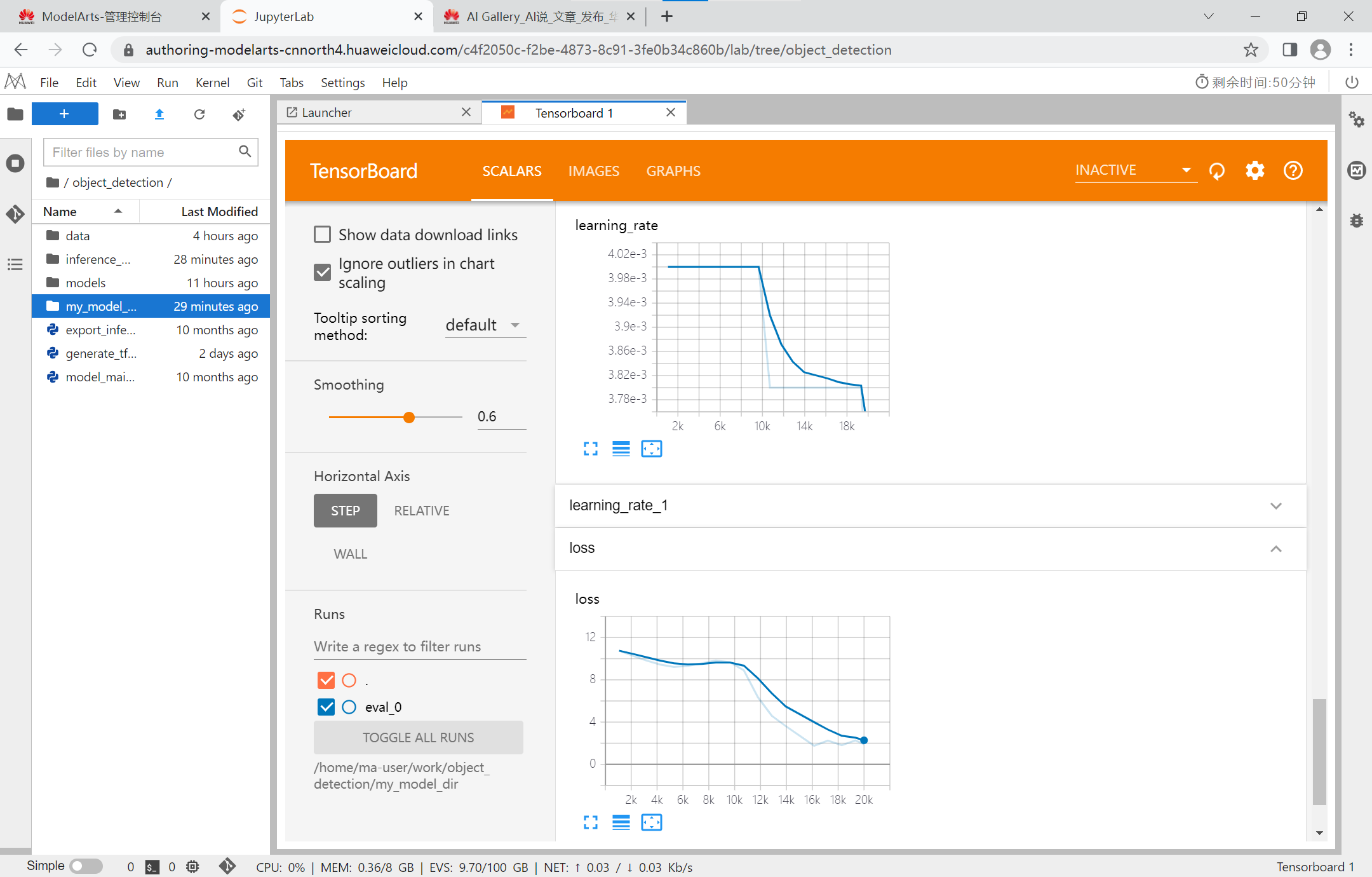
这里我设置每训练10000步学习率衰减95%,总共训练20000步。
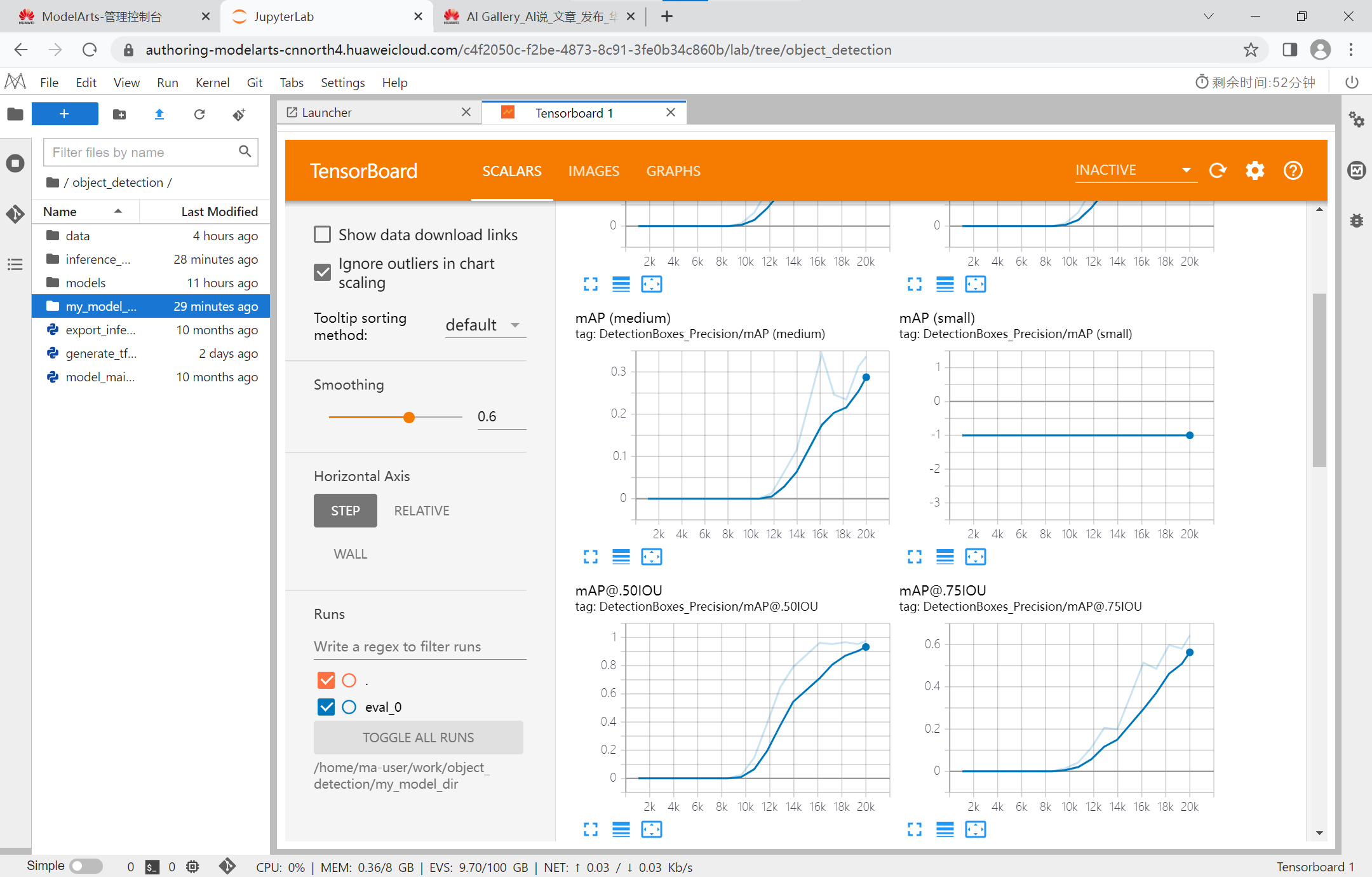

友情提示:建议使用GPU进行训练,ModelArts每天提供3个小时的免费GPU算力。
感兴趣的小伙伴也可以更换自己的数据集重新训练模型,增加训练步数可以取得更好的效果😜
我正在参加【有奖征文第21期】说说你和ModelArts的故事,输出优质产品体验文章,赢开发者大礼包!
https://bbs.huaweicloud.cn/blogs/395149

- 点赞
- 收藏
- 关注作者
评论(0)