nn.AdaptiveAvgPool2d和nn.AvgPool2d的区别

【摘要】 @[toc] nn.AdaptiveAvgPool2d功能:该函数与二维平均池化运算类似,区别主要体现在自适应上,对于任何输入大小,输出大小均为指定的H×W大小。nn.AdaptiveAvgPool2d(output_size)output_size:指定的输出大小,可以是元组(H,W),或者是单个的数,如果是单个的数,则表示输出的高和宽尺寸一样,output_size大小可以大于输入的图片...
@[toc]
nn.AdaptiveAvgPool2d
功能:该函数与二维平均池化运算类似,区别主要体现在自适应上,对于任何输入大小,输出大小均为指定的H×W大小。
nn.AdaptiveAvgPool2d(output_size)
output_size:指定的输出大小,可以是元组(H,W),或者是单个的数,如果是单个的数,则表示输出的高和宽尺寸一样,output_size大小可以大于输入的图片尺寸大小。
例子:
import torch # target output size of 5x7
import torch.nn as nn
m = nn.AdaptiveAvgPool2d((5,7))
input = torch.randn(1, 64, 8, 9)
output = m(input)
print(output.shape)
# target output size of 7x7 (square)
m = nn.AdaptiveAvgPool2d(7)
input = torch.randn(1, 64, 10, 9)
output = m(input)
print(output.shape)
# target output size of 10x7
m = nn.AdaptiveAvgPool2d((None, 7))
input = torch.randn(1, 64, 10, 9)
output = m(input)
print(output.shape)
m = nn.AdaptiveAvgPool2d(1)
input = torch.randn(1, 64, 10, 9)
output = m(input)
print(output.shape)
运行结果:
torch.Size([1, 64, 5, 7])
torch.Size([1, 64, 7, 7])
torch.Size([1, 64, 10, 7])
torch.Size([1, 64, 1, 1])
应用
用在SE注意力机制上,代码如下:
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x)
y=y.view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
输入大小是b×c×h×w经过avg_pool后变成了b×c×1×1。
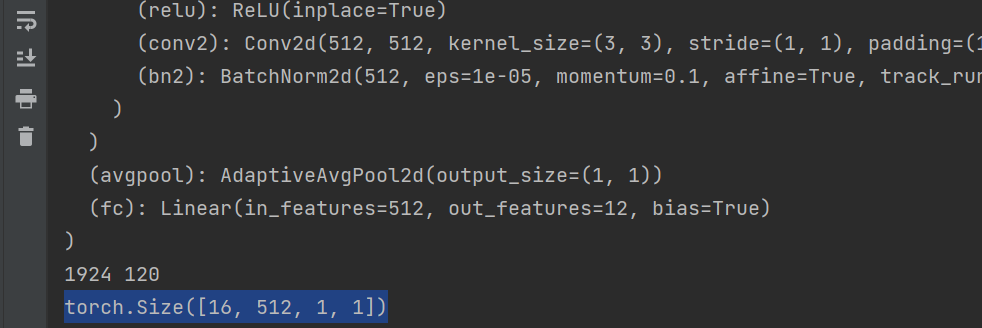
还有用到的地方是在网络的Block后面,例如ResNet:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
输出的结果为:
nn.AvgPool2d
功能:在由多个平面组成的输入信号上应用2D平均池化操作。
重要参数:
kernel_size:池化核的尺寸大小
stride:窗口的移动步幅,默认与kernel_size大小一致
padding:在两侧的零填充宽度大小
注:这三个参数既可以是整数也可以是元组
整数,这种情况下,高和宽尺寸相同
元组,包含两个整数,第一个用于高度维度,第二个用于宽度维度
应用
和AdaptiveAvgPool2d用法相似,比如用在SE模块里使用,代码如下:
class SqueezeAndExcite(nn.Module):
def __init__(self, in_channels, out_channels,se_kernel_size, divide=4):
super(SqueezeAndExcite, self).__init__()
mid_channels = in_channels // divide
self.pool = nn.AvgPool2d(kernel_size=se_kernel_size,stride=1)
self.SEblock = nn.Sequential(
nn.Linear(in_features=in_channels, out_features=mid_channels),
nn.ReLU6(inplace=True),
nn.Linear(in_features=mid_channels, out_features=out_channels),
HardSwish(inplace=True),
)
def forward(self, x):
b, c, h, w = x.size()
out = self.pool(x)
out = out.view(b, -1)
out = self.SEblock(out)
out = out.view(b, c, 1, 1)
return out * x
想要把b×c×h×w经过avg_pool后变成了b×c×1×1,就要先知道输入的h和w大小,将其赋值给se_kernel_size,如果写成固定的,将来改变图片的尺寸就会出现问题。
同理ResNet也有这样的问题,如果图片是224×224的,经过block后,h和w都是7,这时候,设置如下:
self.avgpool = nn.AvgPool2d(7, stride=1)
但是如果改变图片的尺寸就会出现问题,比如将尺寸扩大了一倍,这时候经过block之后的尺寸是14×14,这个时候就要更改网络才行,但是如果使用AdaptiveAvgPool2d则没有这个烦恼。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)