关于智能运维中算法落地的一些思考——复旦大学教授、博导王鹏

来源:华为云SRE确定性运维专刊(第二期)

作者简介:王鹏,复旦大学计算机科学技术学院教授、博导,主要研究兴趣包括:工业物联网大数据、智能运维等;2012年获得教育部自然科学二等奖(第三完成人)。主持或主要参与科技部重点研发计划、国家青年973、自然科学重点/面上基金、上海市科委、上海市经信委的多个项目,以及华为、微软、IBM等企业的资助项目。在数据库领域顶级国际期刊和会议SIGMOD、VLDB、ICDE、TKDE等发表论文40多篇。担任众多国际学术会议的程序委员会委员,包括SIGKDD、ICDE、DASFAA、WAIM等。国际学术期刊VLDB Journal、TKDE、KIS等的审稿人。

本篇文章对智能运维的现状进行深度剖析,总结了智能运维在算法落地遇到的主要问题,以及关于智能运维算法落地的探索。
智能运维的现状
近些年,在广大智能运维业内人士与爱好者共同努力下,算法日益丰富,效果也在不断提升,下面针对几个关键场景展开分析。

1、指标异常检测
指标异常检测是当前落地最多的智能运维场景,该场景下数据容易准备、效果容易验证。对某大规模指标进行异常检测(10000、100000、……)。
研究者们提出了大量异常检测算法,包括单指标、多指标;基于统计模型或深度学习;无监督、有监督。目前多个公司和机构开源了异常检测数据集和异常检测算法。
指标异常检测在真实环境中应用的效果还有如下主要问题:
1)误报太多
» 阈值紧,为了消除漏报,往往造成大量的误报;
» 异常多,运维人员不得不忽略所有的指标异常告警。
2)模型/参数难以设置
» 不同类型的指标,往往适合不同类型的模型和参数。
3)缺乏有效的反馈和修正机制
» 缺乏问题发现能力:监测5万个指标,一天内报了2000个异常,难以对这些异常进行展示和分析,类型、主机、时间段、业务?
» 缺乏基于反馈的模型调整能力,难以应对“这个不是异常,后续检测中不要再报了”的个性化需求

2、日志/告警智能分析
当前,很多企业上线了日志/告警相关算法,有如下困难:
» 人工难以处理,基于规则的方法维护性差
» 典型场景:模板提取,场景挖掘,基于日志的异常检测
» 变量取值异常、模板数量异常、语义异常等
也有研究者提出了大量的算法,比如:
» 模板提取:Drain、Spell、LogCluster
» 场景挖掘:OAS
» 日志异常检测:DeepLog、LogAnomaly
» 公开的数据集:Loghub
当前,日志智能分析实践存在若干问题,如下:
1)模板质量难以有效评估
» 模板数量大(几百上千),逐个人工判断耗时太长
2)缺乏有效的反馈和修正机制
» 缺乏客观评判
» 缺乏基于反馈的模板调整能力,难以应对“这种模板应该根据这个变量拆分”、“这个变量应该被泛化”之类的个性化需求
3)根因定位效果欠佳
» CMDB普遍质量不高
» 可能真正的故障原因不存在与告警数据中
» 标签数据缺失
3、智能问答系统的现状差强人意
当前众多研究者在对智能问答系统进行研究,提出了许多算法和技术,Google Scholar上可以搜索到近35万篇相关文章,但实际上,智能问答系统,回答的结果时常是差强人意,远没有达到真正的智能。
问题分析
造成目前状况的主要问题是哪些?
从战术层面看:
问题1:难以对数据和算法结果进行深入分析
由于数据探索是算法研究的前提,算法结果分析是算法优化的必要步骤,但是由于以下两点难以进行深入分析:
1)被监测对象规模庞大
数据达到十万/百万个指标,每天上TB的日志;导致每天上千个异常,上千/上万个日志模板;难以进行可视化数据探索能力弱。
2)可选算法多,参数搜索空间大
主要表现为异常检测:不同指标适合的模型不同、参数不同;搜索空间巨大:指标规模 × 模型个数 × 参数取值个数。
问题2:算法的自适应能力和反馈修正能力弱
1)算法普遍缺乏反馈修正能力
表现为如下几点:这个“异常”我不需要,后续检测中不要再报了;这两个“模板”应该合并掉,这个“变量”不能被泛化;目前的算法缺乏基于反馈的自动修正的能力
2)标签数据获取困难
主要因为:算法团队与运维专家沟通成本高;异常/故障本身就是小样本事件。
问题3:全局算法能力弱
1)缺乏异构数据的协同分析(横向)
主要原因:指标、日志、调用链中的异常都可能反映故障相关征兆;缺乏统一的异常评估机制;缺乏不同数据的分析结果之间相互印证的能力。
2)缺乏不同阶段的协同分析(纵向)
主要原因:从数据采集到根因定位存在多个数据处理环节;异常/故障本身就是小样本事件。
3)缺乏有效的异构数据处理工具
这样会导致我们花很多时间进行数据查询和分析。
从战略层面看:
问题1:算法和领域知识结合较差
1)数据、算法和知识的融合是AI的研究热点
包括AI 3.0,数据模型和机理的融合,可解释AI,等等。
2)运维本身是一个强知识领域
运维老兵的重要性体现在经验和知识的丰富性,然而当前的现状是AIOps算法对运维知识的利用较少。
问题2:对智能运维中算法作用的认识存在偏差
1)论文中的算法与真实场景需要的算法还是有差异的
以日志模板提取为例:
由于大量的离线、在线日志模板提取算法;真实场景中的模板提取;受POC过程在线或离线影响;受生产环境的在线或离线影响。
因此需要更为合理的日志提取算法,包括小批量测试数据上的离线算法和基于模板集合,流式数据上的在线算法。
我们还需要别的算法吗?比如:长日志模板提取算法;多行日志模板提取算法;特殊日志模板提取算法;反馈算法;参数自动设置算法……
2)“完全依靠算法实现自动化运维”现实吗?
更现实的目标:算法做为一种辅助手段,让运维更高效。
有很多场景需要,比如:
» 数据量太大,用算法来提高效率,对每天几百TB的日志自动提取模板和变量,对上万的指标自动进行异常检测;
» 用算法来提高运维工具的易用性。
» 做为一种定位故障过程的辅助手段,灵活快速的查询和探索数据。
» 算法做为一种积累知识的方式,构建知识图谱。
智能运维三要素
包括:算法的设计能力、运维知识的理解能力和数据平台的工程化能力。
» 算法设计能力:客户需求是个性化的,需要设计针对性的算法;并且数据是个性化的,受参数调整的复杂性和反复性影响。
» 运维知识的理解能力:算法只是手段,运维才是目标。
» 数据平台的工程化能力:数据管理和探索能力是设计算法有效的前提;需要数据平台和算法的高效结合。
探索工作
一、拟定目标:
1、提高算法应用效果。
2、支持反馈,融合专家知识和经验。
3、提高运维过程中的数据探索能力,从而提升运维工具的易用性。
二、首先是异常检测:
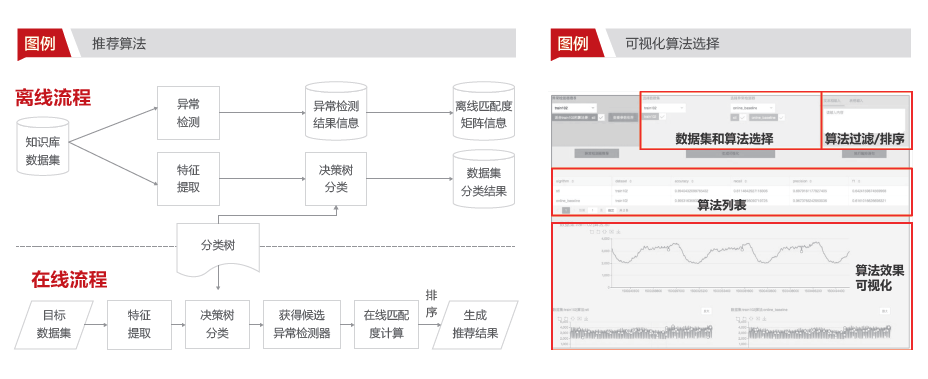
做好算法和参数推荐(如图),以实现上万个指标的自动模型和参数推荐。首先构建指标和异常的知识库,然后进行基于可视化的算法比较、过滤、选择(如图)。
三、然后是告警压缩
这是算法和专家经验的有效融合;将专家经验也做为一种算法,实现和真正算法同样的输入输出接口;充分体现专家经验的重要性。
四、其次是告警精细管理
业务理解和数据的深层次分析对于智能运维至关重要!
我们将告警场景化为四类:高频事件(历史出现次数多,多天多次发生);周期性事件(出现天数很多,并且集中在指定的时间段);新增事件(某时间点才开始出现的事件);阶段性事件(某时间点后不再发生)。
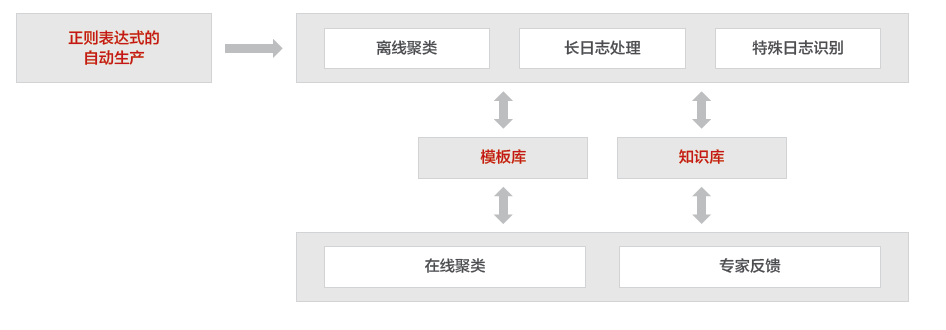
五、再进行日志聚类:我们的方法是多算法融合(如图)
六、使用数据探索工具:作为辅助手段的数据探索技术让运维人员也能灵活的分析数据
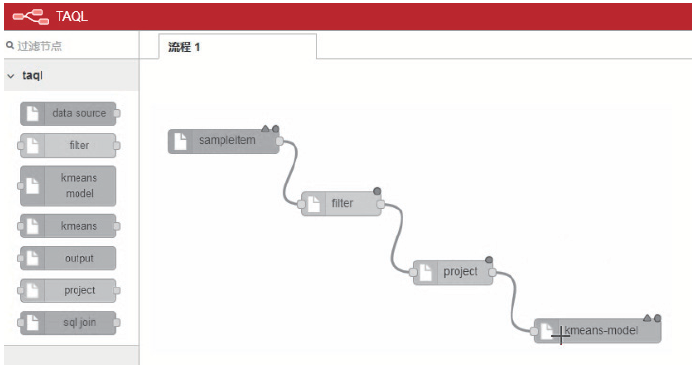
1、基于拖拽式的分析流程实现,有如下好处:
» 1)便于领域专家结合不同分析算法搭建分析流程
» 2)融合了异常检测、聚类、场景挖掘等多种算法
» 3)支持不同语言开发的算法
» 4)支持输入数据格式的智能学习
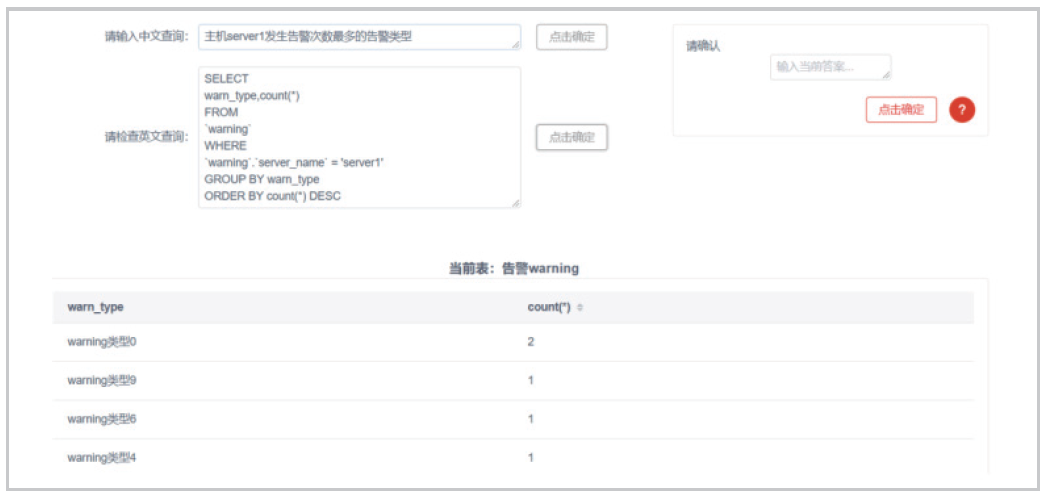
2、基于自然语言的问题系统,高易用性,便于运维人员进行个性化数据探索
3、面向时间关联的复杂查询
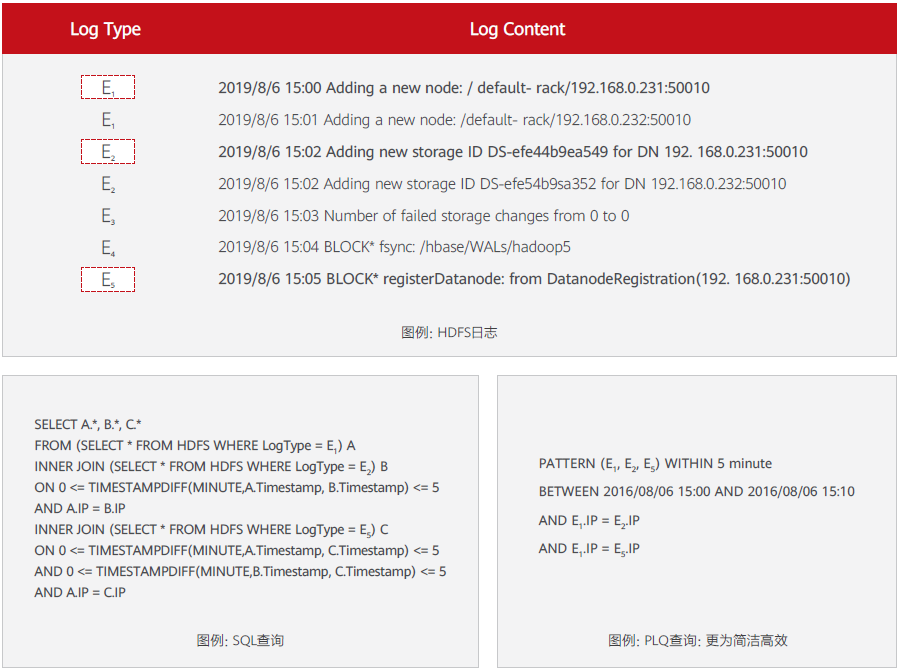
如下图所示的HDFS日志,当我们想查询其中三个模板是否经常一起出现时,SQL查询较为复杂,PLQ查询更加简洁高效。
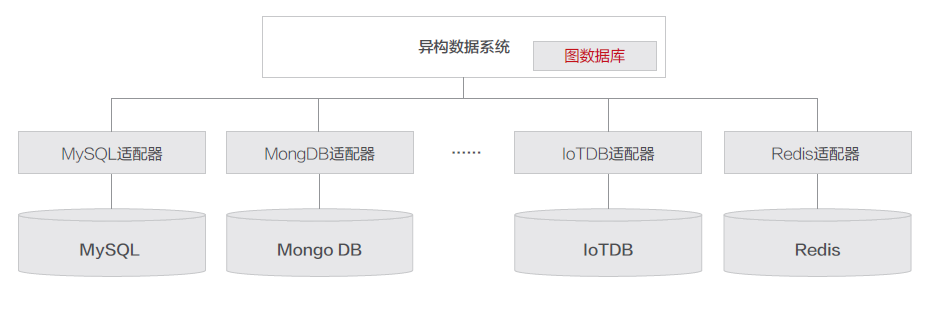
4、异构数据统一查询系统
该系统融合了指标数据(时间序列)、日志数据(文本序列)、CMDB数据及调用链图数据,实现四种类型数据的统一查询。
总结
1、智能运维中的算法发挥越来越大的作用;
2、智能运维中的算法落地仍有大量问题需要解决;
3、算法不能一蹴而就,需要有持续优化的能力;
4、算法作为一种运维的辅助手段。

拓展阅读:华为云SRE确定性运维专刊(第二期)

- 点赞
- 收藏
- 关注作者
评论(0)