【云驻共创】华为云AI之《情感专家》在线分析影评情感基调

前言
本文所讲的《情感专家》在线分析影评情感基调主要有以下几个部分:
- Word Embedding
- BERT原理
- Transformer原理
- Project:BERT中文电影评论正负情感分析
- 使用ModelArts Pro快速上手自定义主题情感分析
一、Word Embedding
Word2vec,是一群用来产生词向量的相关模型。这些模型为浅而双层的神经网络,用来训练以重新建构语言学之词文本。网络以词表现,并且需猜测相邻位置的输入词,在word2vec中词袋模型假设下,词的顺序是不重要的。训练完成之后,word2vec模型可用来映射每个词到一个向量,可用来表示词对词之间的关系,该向量为神经网络之隐藏层。–百度百科
Word2vec主要有两种模式:
-Skip-Gram:给定输入的文字预测上下文
-CBOW:给定上下文预测输入的文字

二、BERT原理
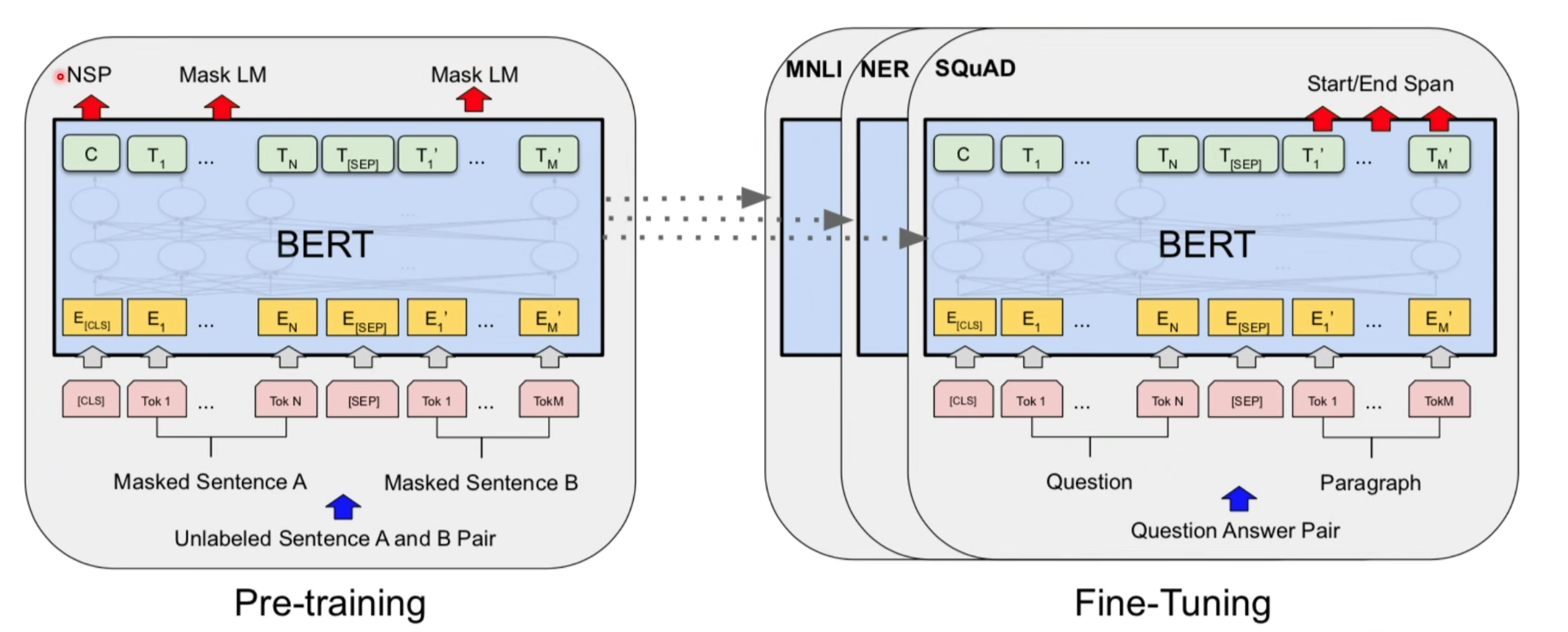
1.Pre-training预训练
确实存在通用的语言模型,先用文章预训练通用模型,然后再根据具体应用,用supervised训练数据,精加工(fine tuning)模型,使之适用于具体应用。
2.Deep Bidirectional Transformers
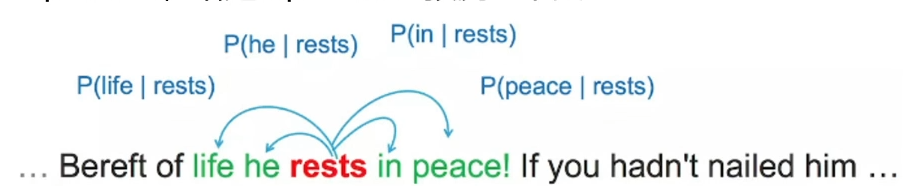
假如句子“能实现语言表征[mask]的模型”,遮盖住其中“目标”一词。从前往后预测[mask],也就是用“能/实现/语言/表征”,来预测[mask](从前往后);用“模型/的”,来预测[mask](从后往前)。
-------单向预测,不能完整地理解整个语句的语义。
双向预测bi-directional:用上下文全向来预测[mask],也就是用“能/实现/语言/表征/…/的/模型”,来预测[mask]。
3.BERT中的双向表示
- BERT的预训练模型中,预训练任务是一个mask LM,随机把句子中的单词替换成mask,然后对单词进行预测
- 对于模型,输入的是一个被挖了空的句子,由于Transformer的特性,它是会注意到所有的单词的
=>导致模型会根据挖空的上下文来进行预测,从而本身就实现了双向表示(BERT是一个双向的语言模型) - Transformer的核心是Attention机制,对于一个语句,可以同时启用多个聚焦点
4.BERT训练模型的参数,使用了两种策略,两个预训练任务
4.1 Mask LM
把一篇文章中,15%的词汇遮盖,让模型根据上下文全向地预测被遮盖的词。通过全向预测被遮盖住的词汇,来初步训练Transformer模型的参数。
3种mask的方式:
- 80%:用[MASK]标记替换单词
- 10%:用一个随机的单词替换该单词
- 10%:保持单词不变
4.2 预测下一句
因为涉及到问答(QA)和自然语言推理(NLI)任务,所以增加了第二个预训练任务。目的是让模型理解两个句子之间的联系。当选择句子A和B作为预训练样本时,B有50%的可能是A的下一个句子,也有50%的可能是来自语料库的随机句子。
比如:
S1:[CLS] the man went to [MASK] store [SEP]
S2: he bought a gallon [MASK] milk [SEP]
Label = IsNext
S1:[CLS] the man [MASK] to the store [SEP]
S3:penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
最终预训练模型的准确率在97-98%
4.BERT的输入表示
用WordPiece分词,一共30,000个token的词汇表。用##表示分词,用[CLS]分割样本, [SEP]分隔样本中的不同句子。
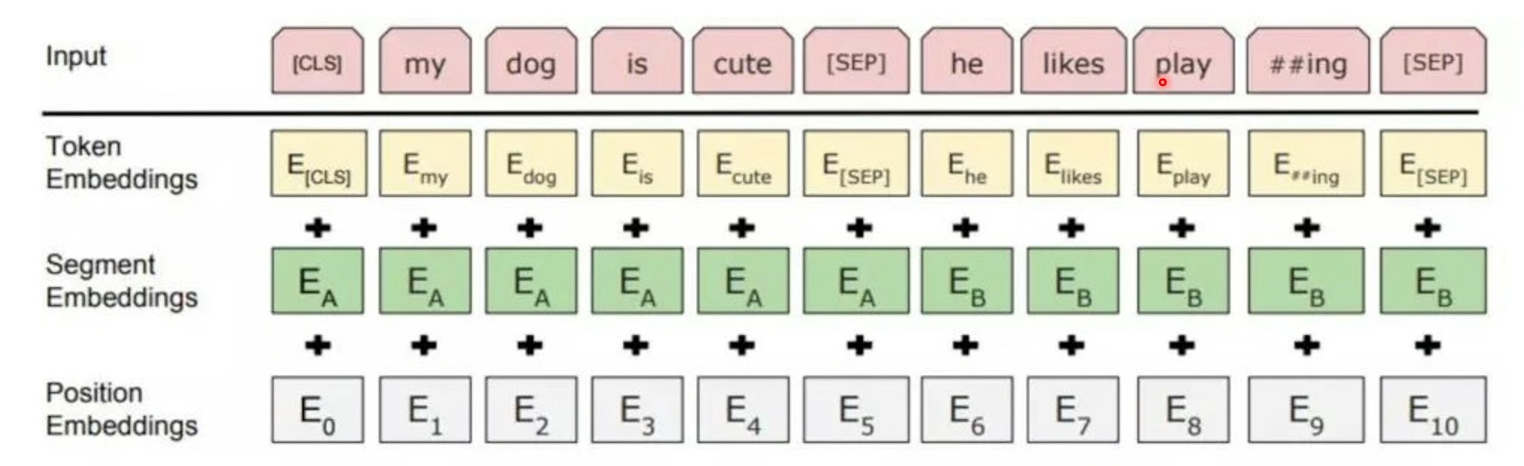
每一个token由三种向量相加而成,即
Input = Token Embeddings + Segmentation Embeddings + Position Embeddings
在海量语料上训练完BERT后,可以将它应用到NLP的各个任务中了=> 迁移学习,进行Fine-Tuning微调即可
三、Transformer原理
1.Transformer机制
Transformer是一个利用注意力机制来提高模型训练速度的模型。
Transformer由且仅由self-Attenion和Feed Forward Neural Network组成。
1.1 Attention机制
- 通过Attention机制,让模型可以集中在所有对于当前目标单词重要的输入信息上,预测效果大大提升。
- 通过观察attention权重矩阵的变化,可以更好了解哪部分翻译对应哪部分的原文文字。

2.Transformer本质
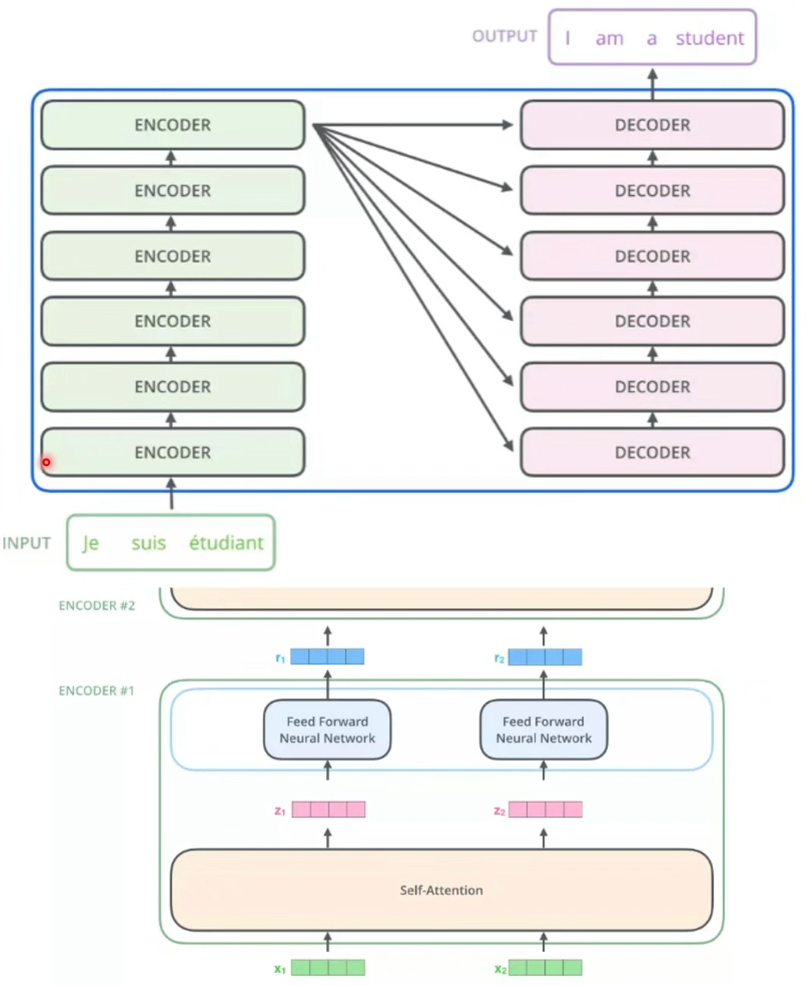
Transformer的本质上是一个Encoder-Decoder的结构
2.1 Encoder
- 首先使用embedding算法将输入的word转换为vector,输入给Encoder #1
- 在每个Encoder内部,输入向量经过self-attention,再经过feed-forward层
- 每个Encoder的输出向量是下一个Encoder的输入
- Transformer的一个关键性质,即每个位置的单词在Encoder中都有自己的路径,self-attention层中的这些路径之间存在依赖关系,然而在feed-forward层不具有那些依赖关系=>feed-forward层可以并行执行
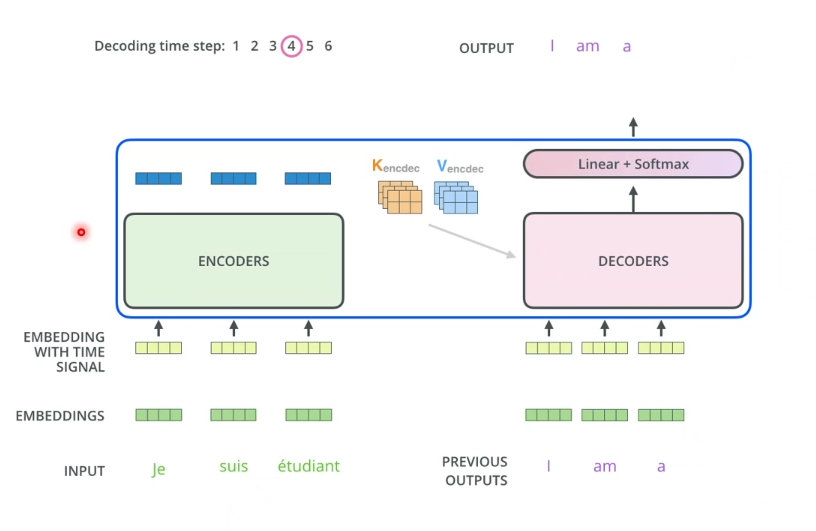
2.2 Decoder
- Encoder通过处理输入序列开始工作。最上端的Encoder的输出之后会被转化为一个包含向量K(键向量)和V(值向量)的注意力向量集
- 这些向量会用于每个decoder的encoder-decoder attention层,有助于解码器聚焦在输入序列中的合适位置
- Decoder阶段的每个步骤都会输出一个输出序列,直到到达一个特殊的终止符号,它表示transformer的解码器已经完成了它的输出
- 会在Encoder和Decoder的输入中添加位置编码,表示每个单词的位置
四、Project:BERT中文电影评论正负情感分析
1.数据样本
数据集(总共7360条语料)
pos.txt 3686正样本
neg.txt 3674负样本
TODO:
使用Bert进行中文电影评论正负情感分类
正样本:
电影的主线是形式上的长城,精神上的众志成城。第三次看了,明白了
故事的完整性,开头说到关于长城,有很多抵御战事和传说,电影要讲
的就是传说,并且这个传说,历史上有古可考,开始外国人崇尚个人英
雄主义,被战备精良的五影禁军相互协作舍身为国感化,加入一起打饕
餮,特效炸裂,场面恢弘
负样本:
今年看过最垃圾的电影,没有之一。浮夸到恶心又没任何意义,全程都
是槽点都不知该从哪吐槽了
2.分析步骤
- Step1:数据加载
- Step2:数据预处理
1)正负样本拼接
2)加载中文预训练BERT Tokenizer BertTokenizer.from_pretrained(‘bert-base-Chinese’)
3)将所有句子转换为token
4)建立mask,针对有文字的地方设置为1,其他补全的地方设置为0 - Step3:模型训练
1)训练集切分,比例为8:2
2)将训练集与测试集放到DataLoader中
3)加载预训练模型
BertForSequenceClassification.from_pretrained(“bert-base-chinese”,num_labels=2)
4)定义优化器AdamW
optimizer=AdamW(optimizer_grouped_parameters,Ir=LEARNING_RATE,eps=EPSILON)
5)模型训练 - Step4:模型评估
使用20%测试集进行accuracy评估 - Step5:模型预测
3.AdamW VS Adam
- 2014年提出的Adam优化器,相比于其他优化器训练速度提高200%
- 2017年底提出AdamW在训练CIFAR10时,使用30个epoch达到94%准确率,之前需要100个epoch=>超收敛(减少50%的epoch)

五、使用ModelArts Pro快速上手自定义主题情感分析
1.AI Gallery
1.1 AI Gallery简介
AI Gallery是在ModelArts的基础上构建的开发者生态社区,提供了Notebook代码样例、数据集、算法、模型、Workflow等AI数字资产的共享,为高校科研机构、AI应用开发商、解决方案集成商、企业级/个人开发者等群体,提供安全、开放的共享及交易环节,加速AI资产的开发与落地,保障AI开发生态链上各参与方高效地实现各自的商业价值。
AI Gallery文档:https://support.huaweicloud.cn/aimarket-modelarts/modelarts_18_0001.html

AI Gallery中的代码样例平台:https://developer.huaweicloud.cn/develop/aigallery/home.html
1.2 AI Gallery前提准备
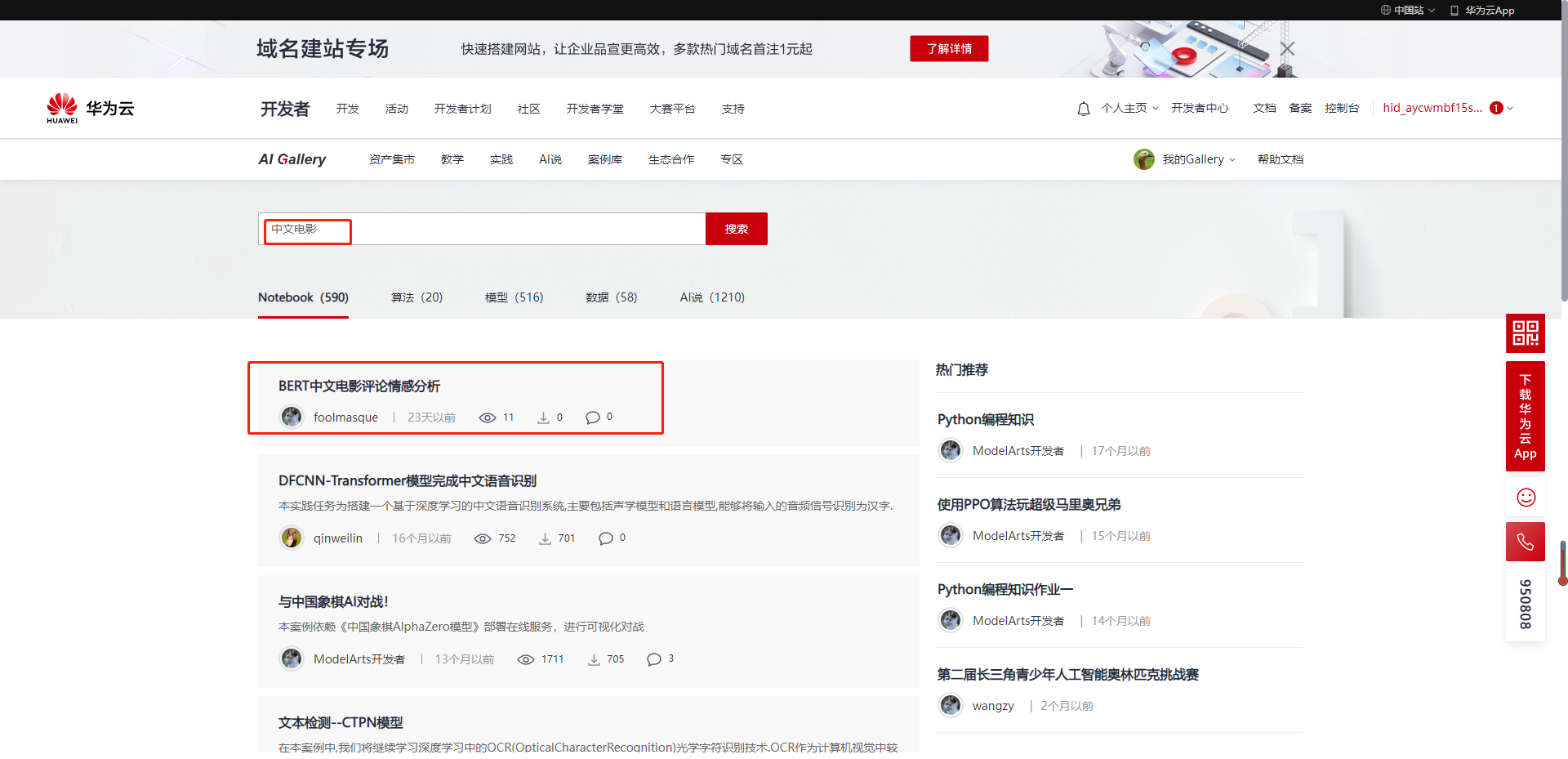
1.2.1 输入中文电影进行样例搜索
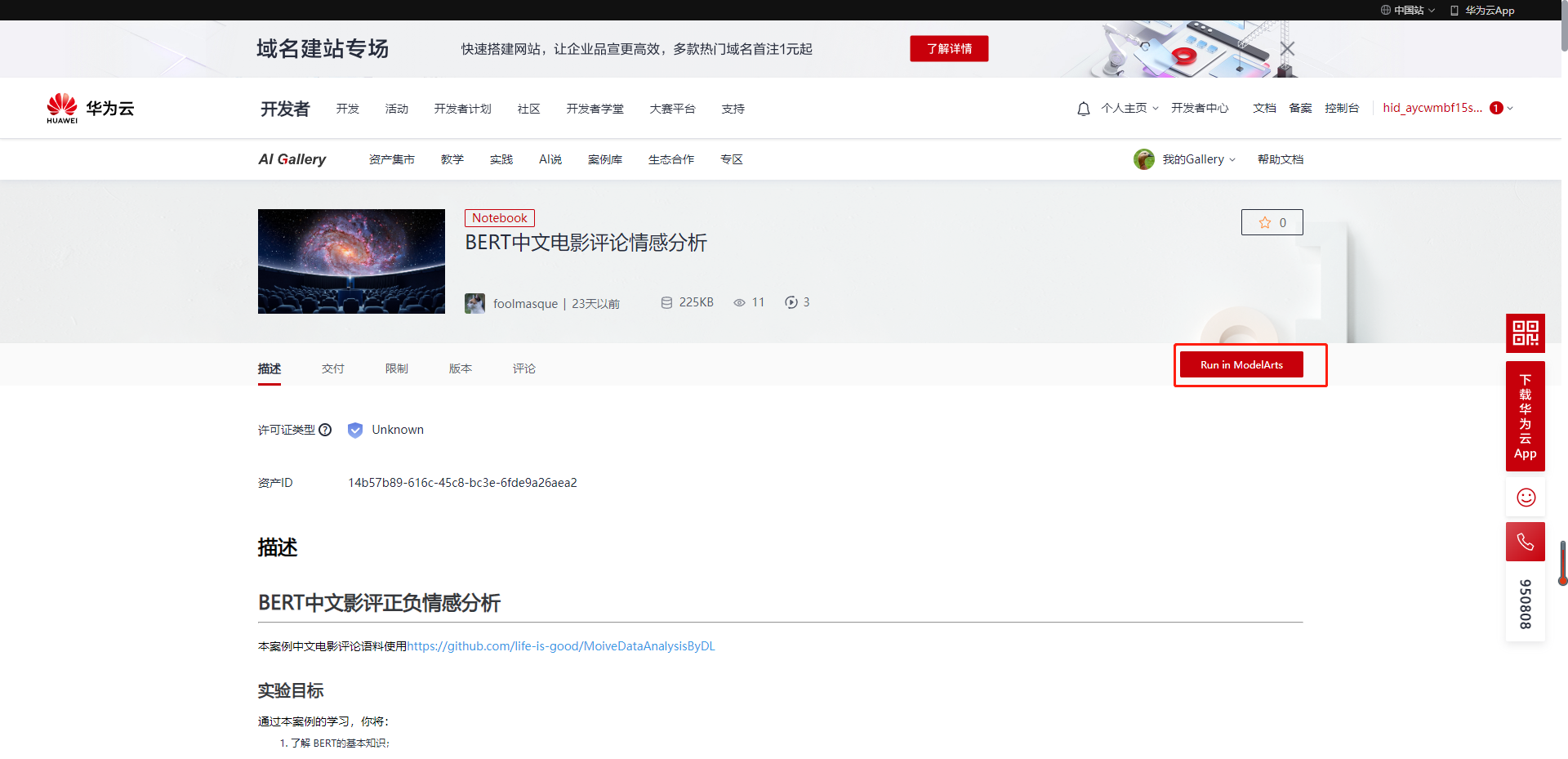
1.2.2 点击Run in ModelArts
1.2.3 选择环境
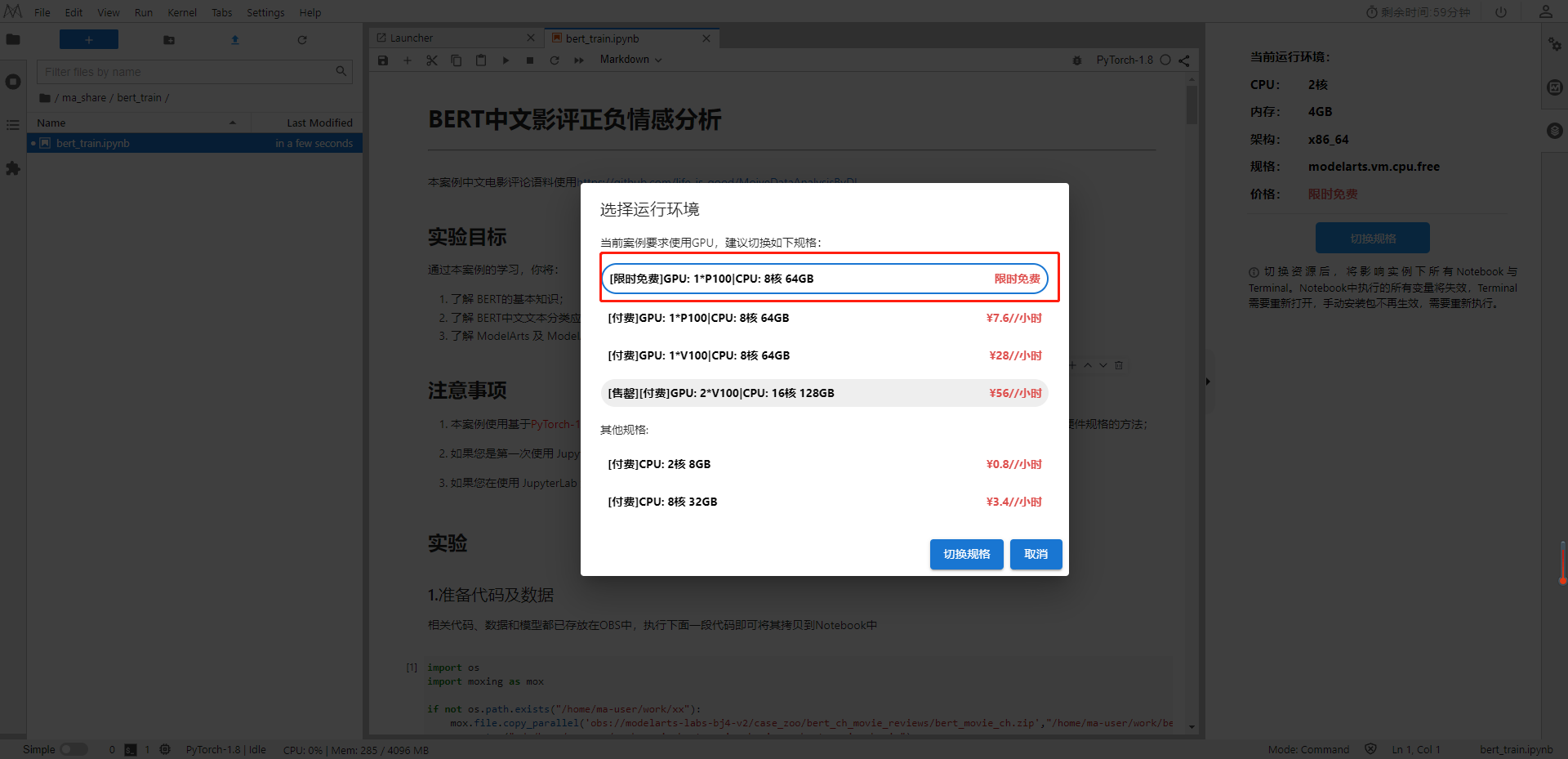
1.3 AI Gallery在线分析影评情感基调样例代码使用
1.3.1 准备代码和数据
相关代码、数据和模型都已存放在OBS中,执行下面一段代码即可将其拷贝到Notebook中
import os
import moxing as mox
if not os.path.exists("/home/ma-user/work/xx"):
mox.file.copy_parallel('obs://modelarts-labs-bj4-v2/case_zoo/bert_ch_movie_reviews/bert_movie_ch.zip',"/home/ma-user/work/bert_movie_ch.zip")
os.system("cd /home/ma-user/work;unzip bert_movie_ch.zip;rm bert_movie_ch.zip")
if os.path.exists("/home/ma-user/work/bert_movie_ch"):
print('Download success')
else:
raise Exception('Download Failed')
else:
print("Project already exists")
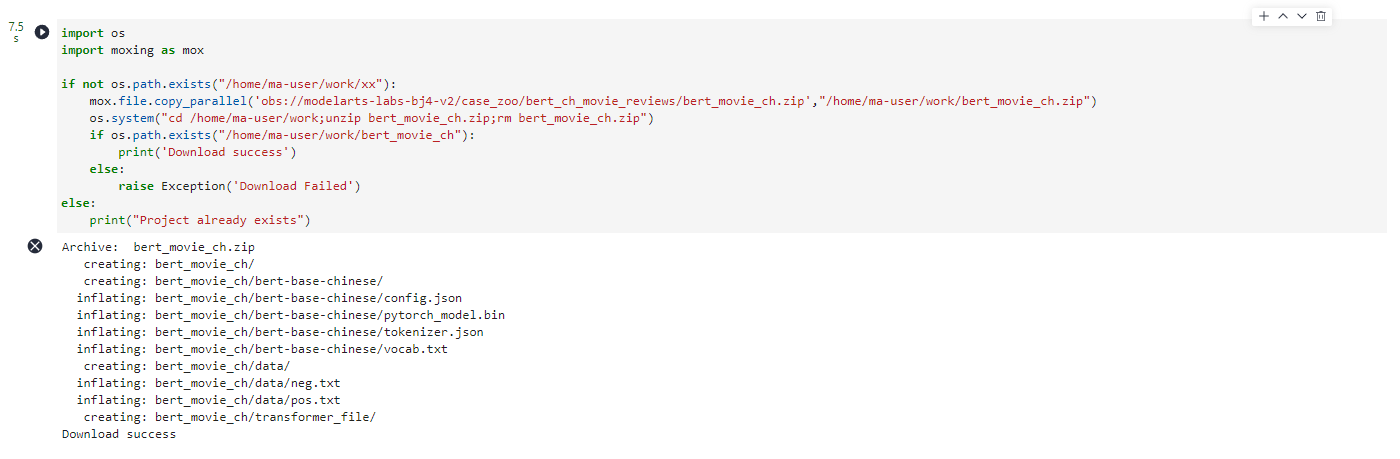
执行完成之后会出现Download success。
1.3.2 安装所需要的python模块
pip install transformers==4.21.1
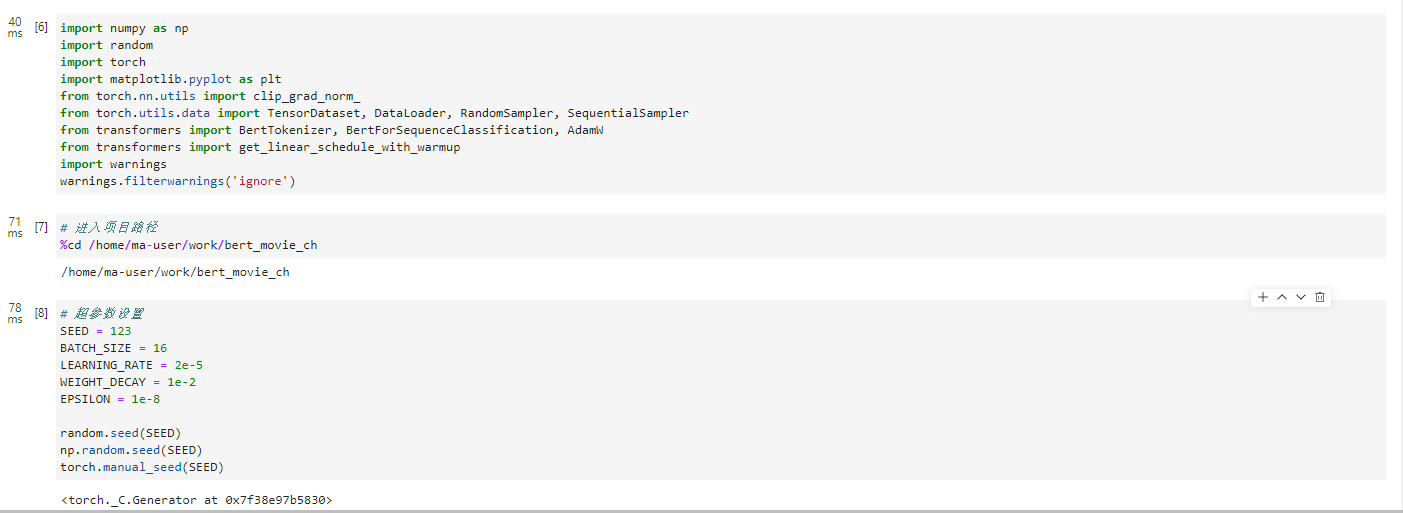
1.3.3 导包及超参设置
导包
import numpy as np
import random
import torch
import matplotlib.pyplot as plt
from torch.nn.utils import clip_grad_norm_
from torch.utils.data import TensorDataset, DataLoader, RandomSampler, SequentialSampler
from transformers import BertTokenizer, BertForSequenceClassification, AdamW
from transformers import get_linear_schedule_with_warmup
import warnings
warnings.filterwarnings('ignore')
切换路径
# 进入项目路径
%cd /home/ma-user/work/bert_movie_ch
超参数设置
# 超参数设置
SEED = 123
BATCH_SIZE = 16
LEARNING_RATE = 2e-5
WEIGHT_DECAY = 1e-2
EPSILON = 1e-8
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
1.3.4 数据处理
1.3.4.1 获取文本内容
# 读取文件,返回文件内容
def readfile(filename):
with open(filename, encoding="utf-8") as f:
content = f.readlines()
return content
# 正负情感语料
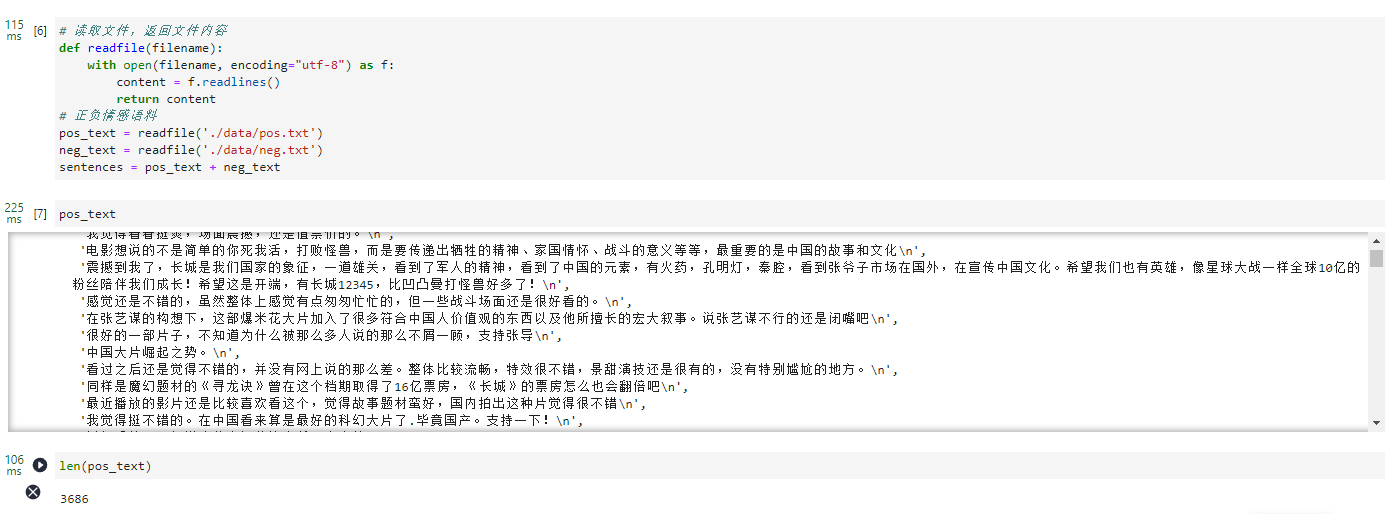
pos_text = readfile('./data/pos.txt')
neg_text = readfile('./data/neg.txt')
sentences = pos_text + neg_text
pos_text
len(pos_text)
1.3.4.2 转换成数组长度
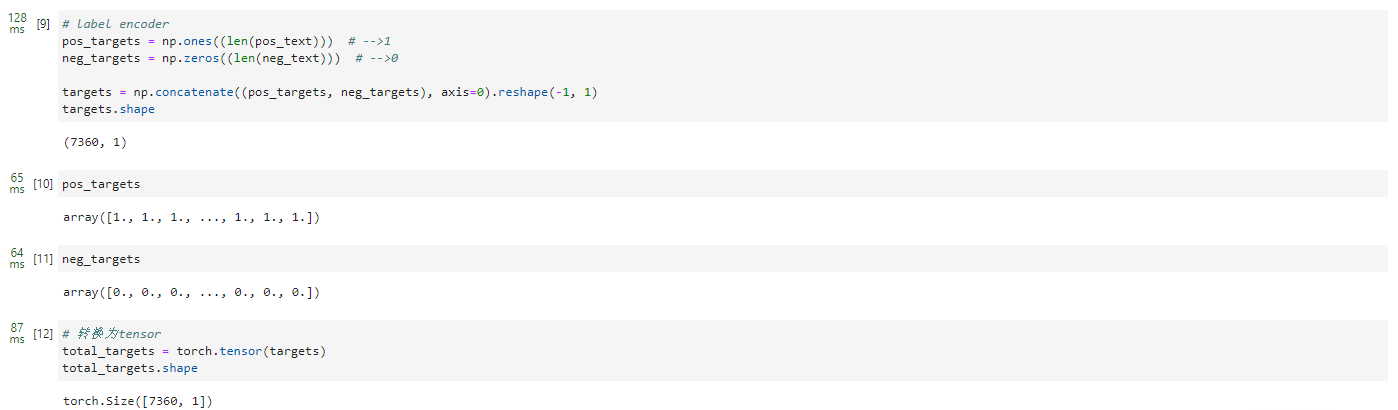
# label encoder
pos_targets = np.ones((len(pos_text))) # -->1
neg_targets = np.zeros((len(neg_text))) # -->0
targets = np.concatenate((pos_targets, neg_targets), axis=0).reshape(-1, 1)
targets.shape
pos_targets
neg_targets
# 转换为tensor
total_targets = torch.tensor(targets)
total_targets.shape
1.3.4.3 加载模型进行分词
# 从预训练模型中加载bert-base-chinese
# [UNK] 特征 [CLS]起始 [SEP]结束
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese', cache_dir="./transformer_file/")
tokenizer
print(pos_text[1])
# 进行分词
print(tokenizer.tokenize(pos_text[1]))
# bert编码,会增加开始[CLS]--101 和 结束[SEP]--102标记
print(tokenizer.encode(pos_text[1]))
# 将bert编码转换为 字
print(tokenizer.convert_ids_to_tokens(tokenizer.encode(pos_text[1])))
tokenizer.encode("我")

1.3.4.4 句子转数字进行编码
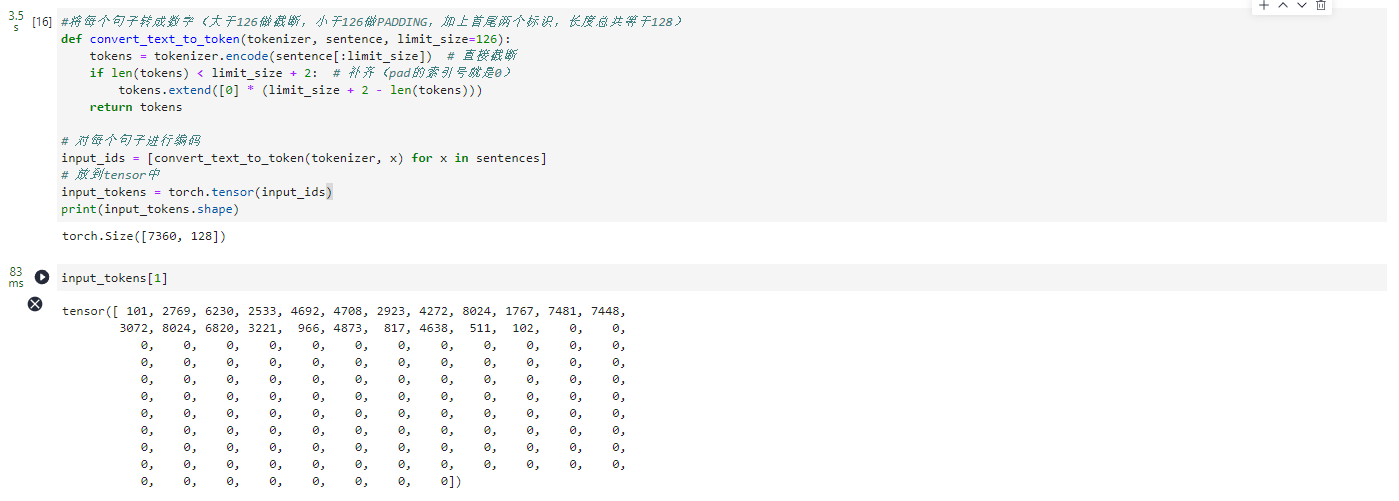
#将每个句子转成数字(大于126做截断,小于126做PADDING,加上首尾两个标识,长度总共等于128)
def convert_text_to_token(tokenizer, sentence, limit_size=126):
tokens = tokenizer.encode(sentence[:limit_size]) # 直接截断
if len(tokens) < limit_size + 2: # 补齐(pad的索引号就是0)
tokens.extend([0] * (limit_size + 2 - len(tokens)))
return tokens
# 对每个句子进行编码
input_ids = [convert_text_to_token(tokenizer, x) for x in sentences]
# 放到tensor中
input_tokens = torch.tensor(input_ids)
print(input_tokens.shape)
input_tokens[1]
1.3.4.5 建立mask
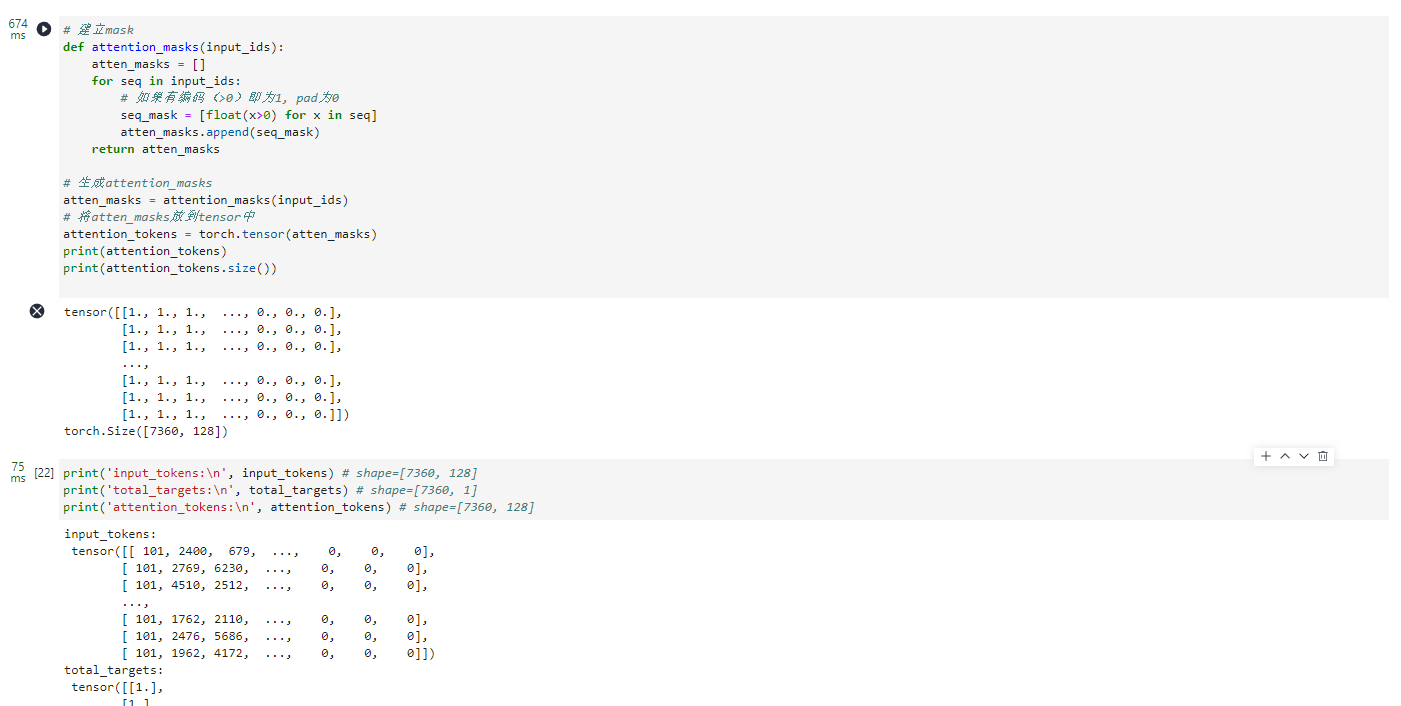
# 建立mask
def attention_masks(input_ids):
atten_masks = []
for seq in input_ids:
# 如果有编码(>0)即为1, pad为0
seq_mask = [float(x>0) for x in seq]
atten_masks.append(seq_mask)
return atten_masks
# 生成attention_masks
atten_masks = attention_masks(input_ids)
# 将atten_masks放到tensor中
attention_tokens = torch.tensor(atten_masks)
print(attention_tokens)
print(attention_tokens.size())
print('input_tokens:\n', input_tokens) # shape=[7360, 128]
print('total_targets:\n', total_targets) # shape=[7360, 1]
print('attention_tokens:\n', attention_tokens) # shape=[7360, 128]
1.3.4.6 切分
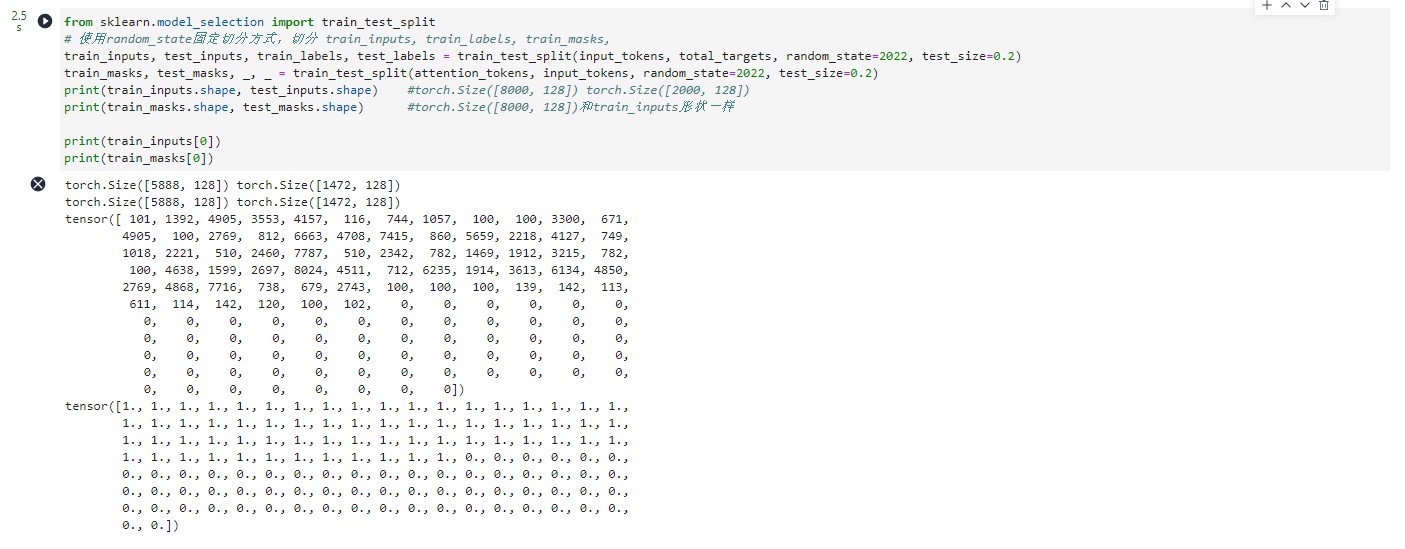
from sklearn.model_selection import train_test_split
# 使用random_state固定切分方式,切分 train_inputs, train_labels, train_masks,
train_inputs, test_inputs, train_labels, test_labels = train_test_split(input_tokens, total_targets, random_state=2022, test_size=0.2)
train_masks, test_masks, _, _ = train_test_split(attention_tokens, input_tokens, random_state=2022, test_size=0.2)
print(train_inputs.shape, test_inputs.shape) #torch.Size([8000, 128]) torch.Size([2000, 128])
print(train_masks.shape, test_masks.shape) #torch.Size([8000, 128])和train_inputs形状一样
print(train_inputs[0])
print(train_masks[0])
1.3.4.7 打包
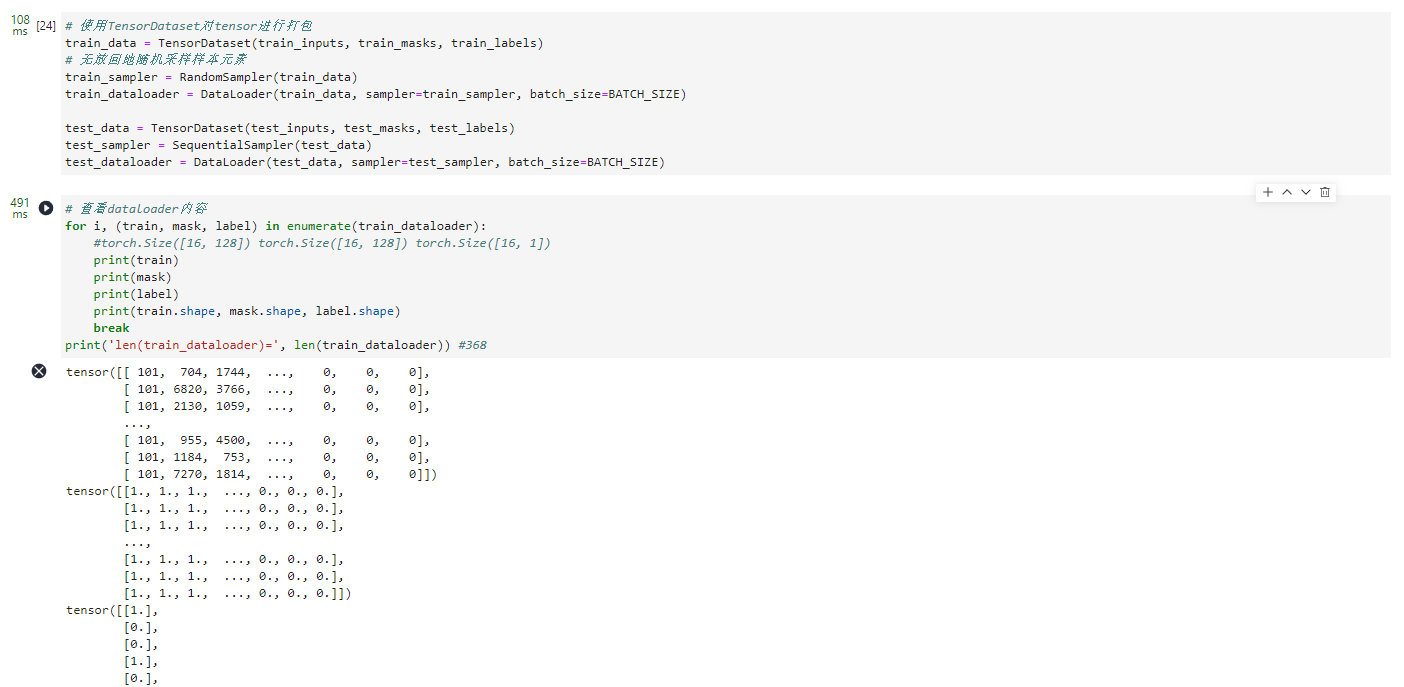
# 使用TensorDataset对tensor进行打包
train_data = TensorDataset(train_inputs, train_masks, train_labels)
# 无放回地随机采样样本元素
train_sampler = RandomSampler(train_data)
train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=BATCH_SIZE)
test_data = TensorDataset(test_inputs, test_masks, test_labels)
test_sampler = SequentialSampler(test_data)
test_dataloader = DataLoader(test_data, sampler=test_sampler, batch_size=BATCH_SIZE)
# 查看dataloader内容
for i, (train, mask, label) in enumerate(train_dataloader):
#torch.Size([16, 128]) torch.Size([16, 128]) torch.Size([16, 1])
print(train)
print(mask)
print(label)
print(train.shape, mask.shape, label.shape)
break
print('len(train_dataloader)=', len(train_dataloader)) #368
1.3.4.8 评估
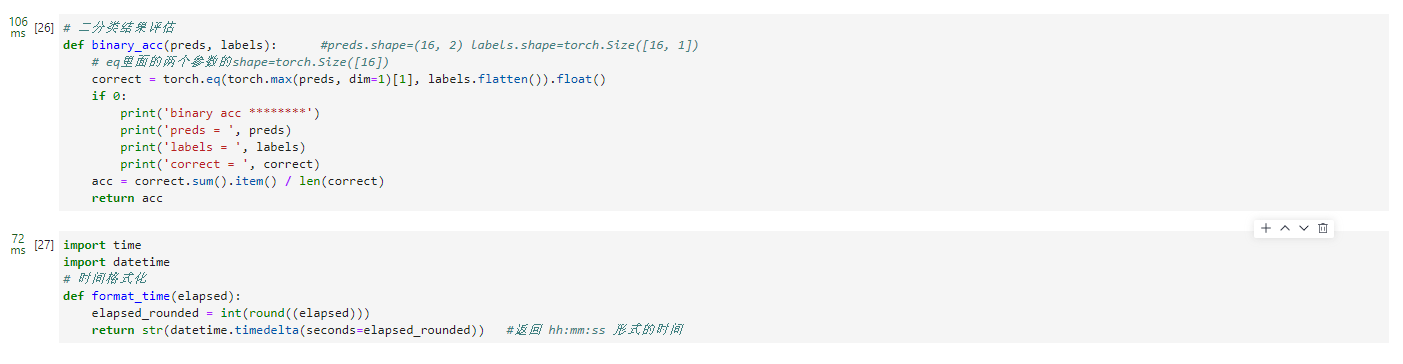
# 二分类结果评估
def binary_acc(preds, labels): #preds.shape=(16, 2) labels.shape=torch.Size([16, 1])
# eq里面的两个参数的shape=torch.Size([16])
correct = torch.eq(torch.max(preds, dim=1)[1], labels.flatten()).float()
if 0:
print('binary acc ********')
print('preds = ', preds)
print('labels = ', labels)
print('correct = ', correct)
acc = correct.sum().item() / len(correct)
return acc
import time
import datetime
# 时间格式化
def format_time(elapsed):
elapsed_rounded = int(round((elapsed)))
return str(datetime.timedelta(seconds=elapsed_rounded)) #返回 hh:mm:ss 形式的时间
1.3.5 训练和评估
1.3.5.1 加载预训练模型
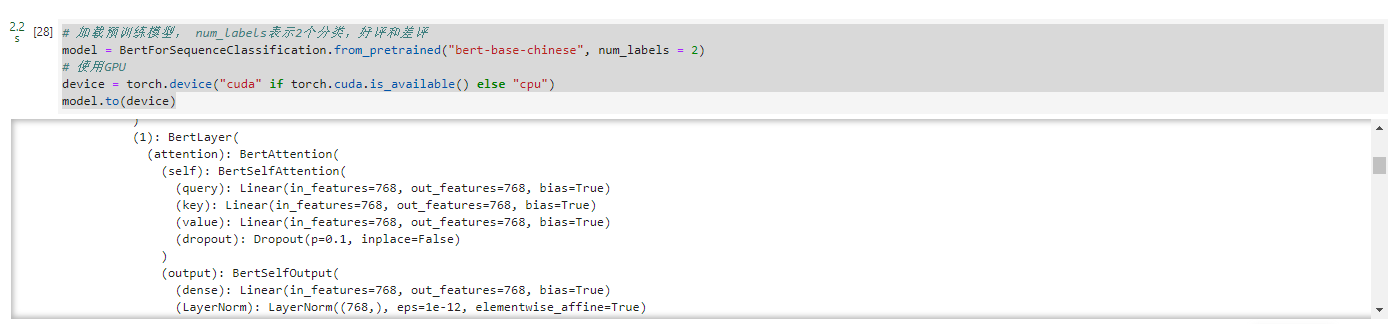
# 加载预训练模型, num_labels表示2个分类,好评和差评
model = BertForSequenceClassification.from_pretrained("bert-base-chinese", num_labels = 2)
# 使用GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
1.3.5.2 定义优化器
# 定义优化器 AdamW, eps默认就为1e-8(增加分母的数值,用来提高数值稳定性)
no_decay = ['bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': WEIGHT_DECAY},
{'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
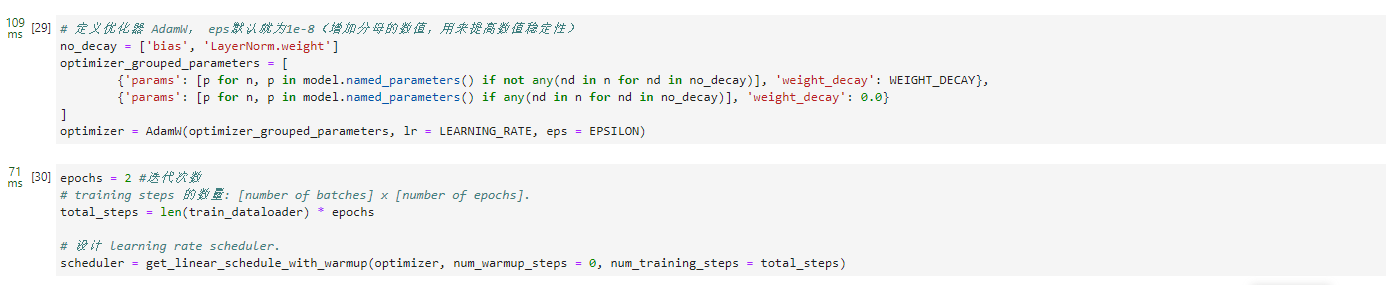
optimizer = AdamW(optimizer_grouped_parameters, lr = LEARNING_RATE, eps = EPSILON)
epochs = 2 #迭代次数
# training steps 的数量: [number of batches] x [number of epochs].
total_steps = len(train_dataloader) * epochs
# 设计 learning rate scheduler.
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps = 0, num_training_steps = total_steps)
1.3.5.3 定义模型训练
# 定义模型训练
def train(model, optimizer):
t0 = time.time() # 记录当前时刻
avg_loss, avg_acc = [],[]
# 开启训练模式
model.train()
for step, batch in enumerate(train_dataloader):
# 每隔40个batch 输出一下所用时间.
if step % 40 == 0 and not step == 0:
elapsed = format_time(time.time() - t0)
print(' Batch {:>5,} of {:>5,}. Elapsed: {:}.'.format(step, len(train_dataloader), elapsed))
# 从batch中取数据,并放到GPU中
b_input_ids, b_input_mask, b_labels = batch[0].long().to(device), batch[1].long().to(device), batch[2].long().to(device)
output = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask, labels=b_labels)
loss, logits = output[0], output[1]
avg_loss.append(loss.item())
acc = binary_acc(logits, b_labels)
avg_acc.append(acc)
optimizer.zero_grad()
loss.backward()
clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
scheduler.step()
avg_loss = np.array(avg_loss).mean()
avg_acc = np.array(avg_acc).mean()
return avg_loss, avg_acc

1.3.5.3 定义模型评估
# 定义模型评估
def evaluate(model):
avg_acc = []
#表示进入测试模式
model.eval()
with torch.no_grad():
for batch in test_dataloader:
# 从batch中取数据,并放到GPU中
b_input_ids, b_input_mask, b_labels = batch[0].long().to(device), batch[1].long().to(device), batch[2].long().to(device)
# 前向传播,得到output
output = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask)
# 统计当前batch的acc
acc = binary_acc(output[0], b_labels)
avg_acc.append(acc)
# 统计平均acc
avg_acc = np.array(avg_acc).mean()
return avg_acc

1.3.5.4 训练 & 评估
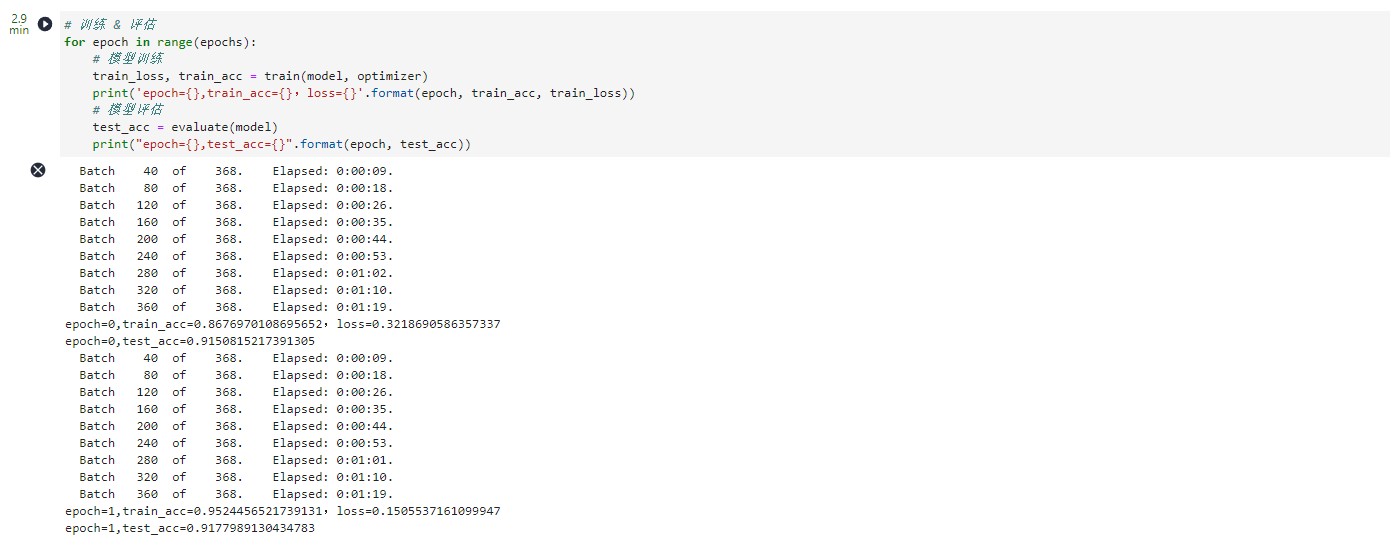
# 训练 & 评估
for epoch in range(epochs):
# 模型训练
train_loss, train_acc = train(model, optimizer)
print('epoch={},train_acc={},loss={}'.format(epoch, train_acc, train_loss))
# 模型评估
test_acc = evaluate(model)
print("epoch={},test_acc={}".format(epoch, test_acc))
1.3.6 预测
def predict(sen):
# 将sen 转换为id
input_id = convert_text_to_token(tokenizer, sen)
# print(input_id)
# 放到tensor中
input_token = torch.tensor(input_id).long().to(device) #torch.Size([128])
# 统计有id的部分,即为 1(mask),并且转换为float类型
atten_mask = [float(i>0) for i in input_id]
# 将mask放到tensor中
attention_token = torch.tensor(atten_mask).long().to(device) #torch.Size([128])
# 转换格式 size= [1,128], torch.Size([128])->torch.Size([1, 128])否则会报错
attention_mask = attention_token.view(1, -1)
output = model(input_token.view(1, -1), token_type_ids=None, attention_mask=attention_mask)
return torch.max(output[0], dim=1)[1]
label = predict('掏钱看这部电影,才是真正被杀猪盘了。。。')
print('好评' if label==1 else '差评')
label = predict('我觉得挺不错的。在中国看来算是最好的科幻大片了.毕竟国产。支持一下!')
print('好评' if label==1 else '差评')
label = predict('但是影片制作“略显”粗糙。包括但不限于演员演技拉胯,剧情尴尬,情节设计不合理。期待值最高的王千源完全像没睡醒,全片无论扮演什么身份或处于什么场景,表情就没变过。身体力行的告诉了我们,演员最重要不是演什么像什么,而是演什么就换什么衣服。除了人物身份的切换是靠换衣服外和张光北演对手戏完全就像是在看着提词器念台词,俩下对比尴尬到都能扣出个三室一厅。女配“陈茜”和“刘美美”一个没看到“孤身入虎穴”的作用在哪里,一个则是完全没必要出现。随着故事的递进加情节设计的不合理导致整片完全垮掉。或者你把俩女配的情节递进处理好了也行,但是很显然,导演完全不具备这种能力。不仅宏观叙事的能力差,主题把控的能力也欠缺。看似这个电影是宣传反诈,实则是披着反诈的外衣,上演了正派和反派间弱智般的“强强”对决。就以反诈题材来说做的都不如b站up主录制的几分缅北诈骗集团的小视频更有警示意义。我们搞反诈宣传的目的不就是为了避免群众上当受骗,同时告诉大家警惕国外高薪工作,不去从事诈骗活动吗?当然我要吐槽的包括但不限于以上这些,麻烦各位导演在拍偏主旋律电影的时候不要用类似于本片抓捕大boos时说的:“现在中国太强大了,怎么怎么地类似的台词了,把这份荣誉留给吴京吧!最后,本片唯一的亮点就是王迅和前三分之一节奏感还不错。哎,特价买的票以为我赚了,没想到是我被“杀猪盘了”。')
print('好评' if label==1 else '差评')

2.ModelArts Pro情感分析工作流
2.1 ModelArts Pro是什么
ModelArts Pro 是为企业级AI应用打造的专业开发套件。基于华为云的先进算法和快速训练能力,提供预置工作流和模型,提升企业AI应用的开发效率,降低开发难度。同时,支持客户自主进行工作流编排,快速实现应用的开发、共享和发布,共建开放生态,实现普惠行业AI落地。
华为云企业级AI 应用开发套件 ModelArts Pro,加速行业AI 落地
ModelArts Pro将算法专家的积累和行业专家的知识沉淀在相应的套件和“行业工作流”(Workflow)中,实现AI能力的复用。
自然语言套件帮助文档:https://support.huaweicloud.cn/usermanual-modelartspro/modelartspro_01_0037.html
2.2 ModelArts Pro的前提准备
登录ModelArts Pro平台:https://console.huaweicloud.cn/mapro/
模型训练选择自然语言处理套件
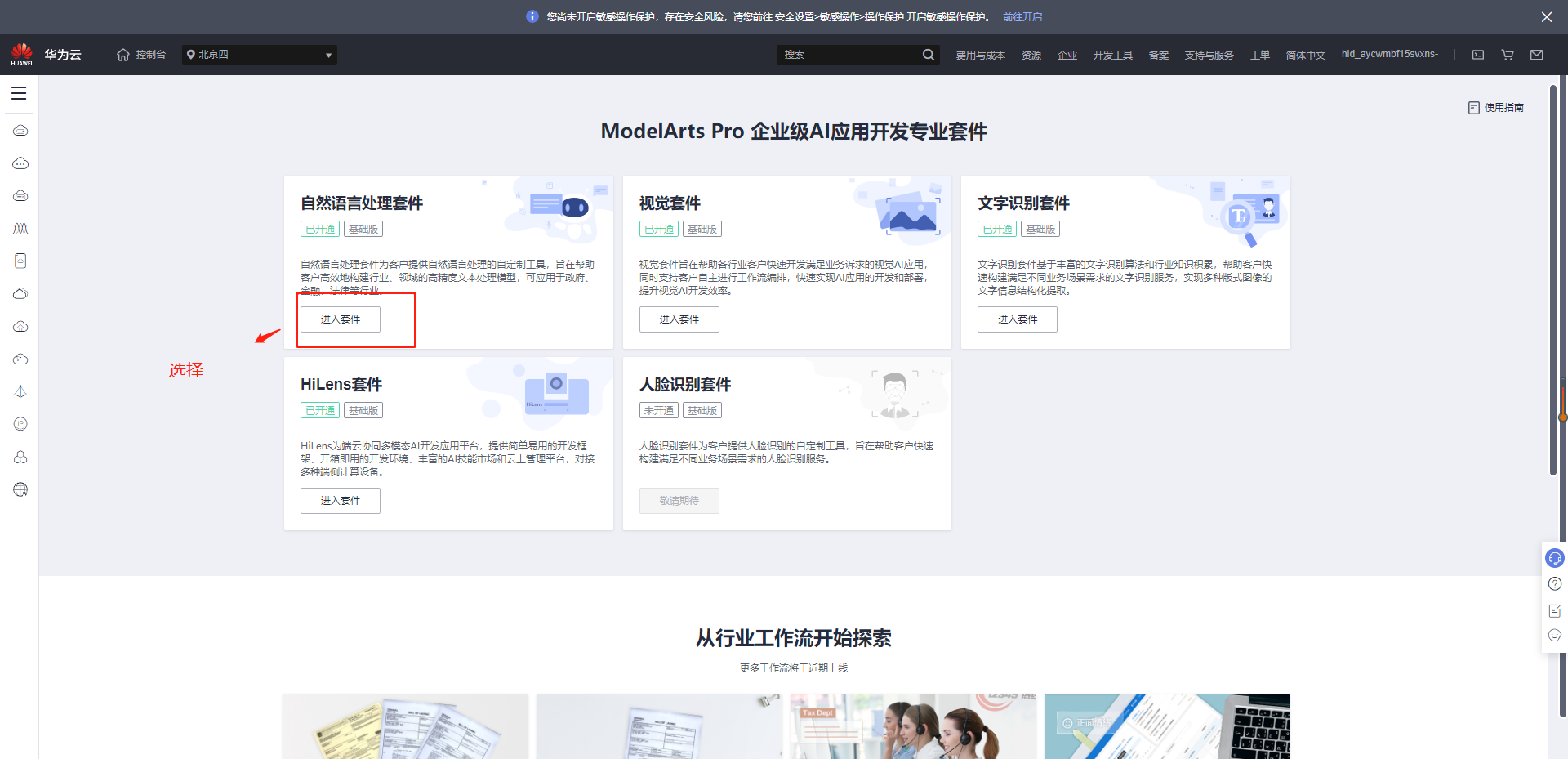
2.3 ModelArts Pro的使用
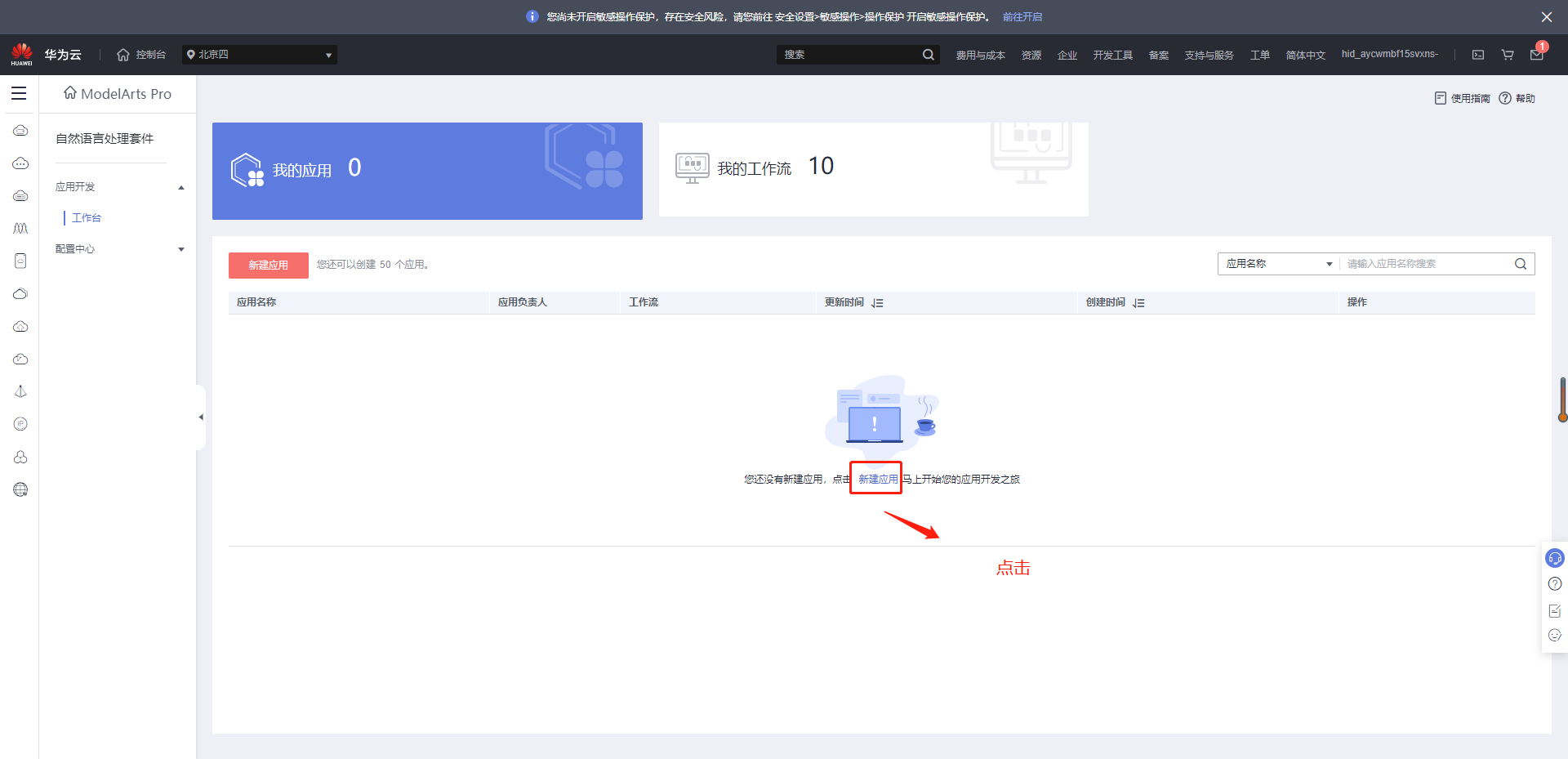
1、情感分析工作流,新建应用
2、填写相关信息点击确定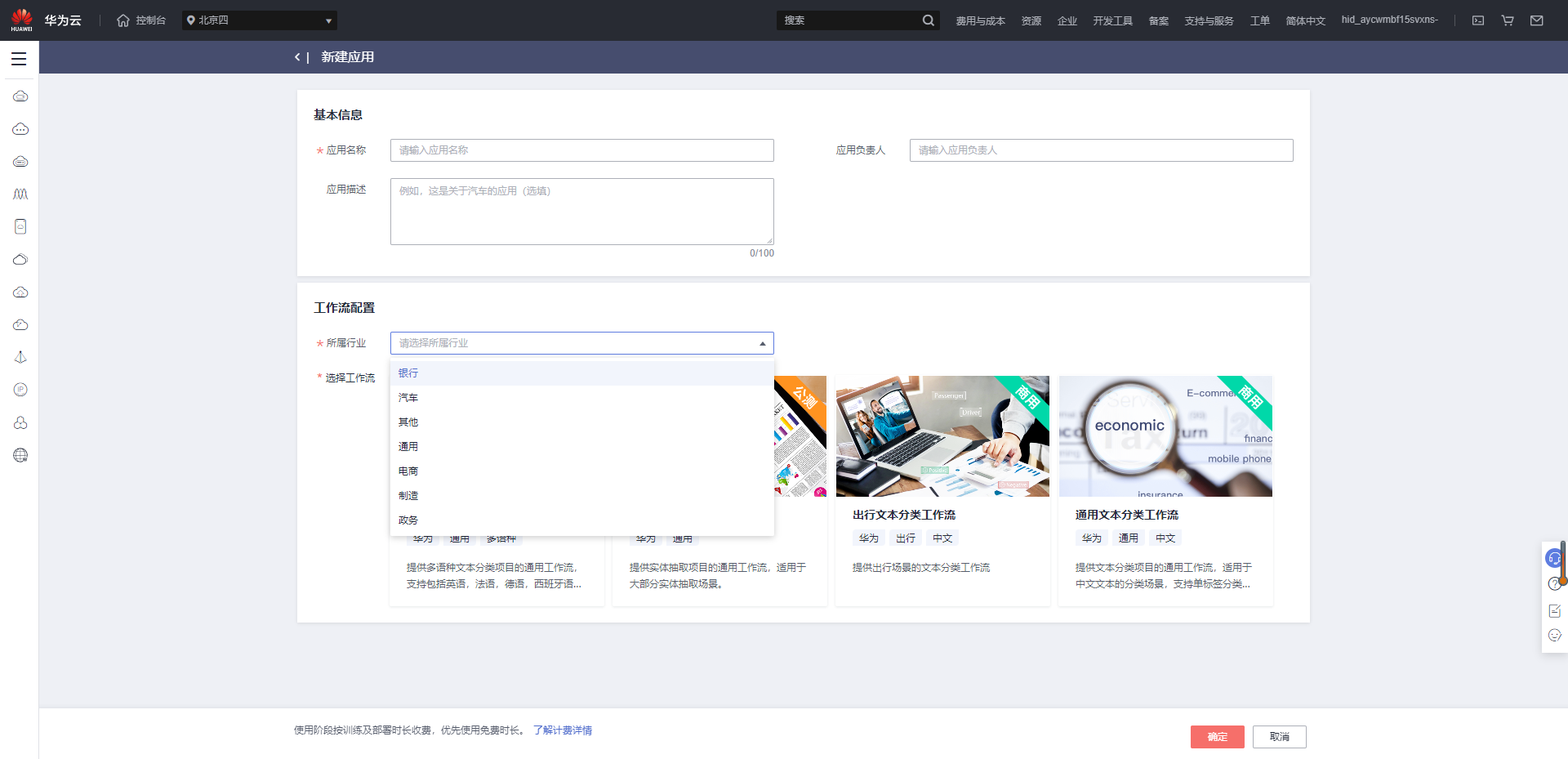
3、创建数据集,构建标注工作
数据集主要有数据选择=》模型训练=》模型评估=》服务部署
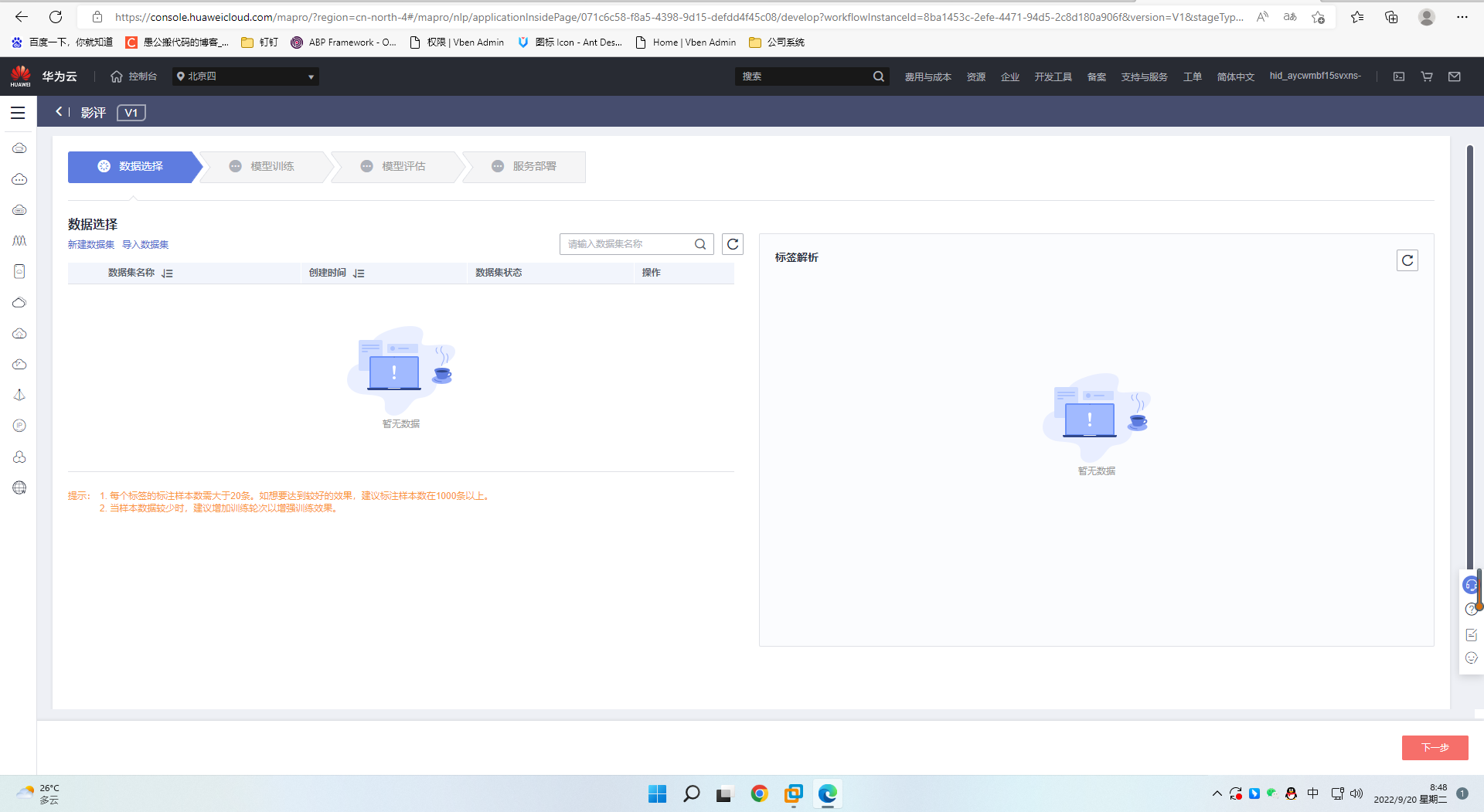
4、数据选择界面如图
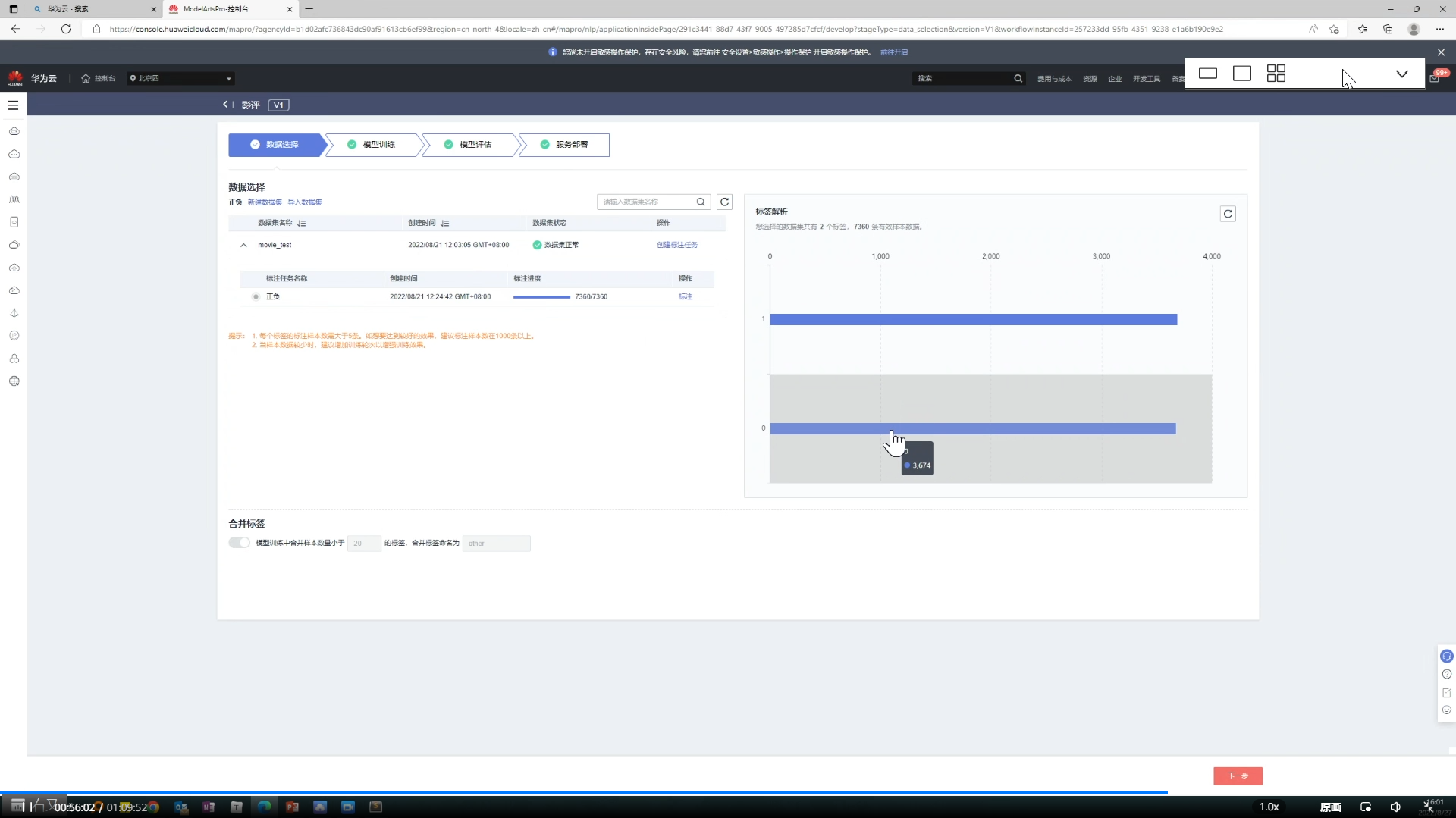
5、模型训练过程可以看到训练详情
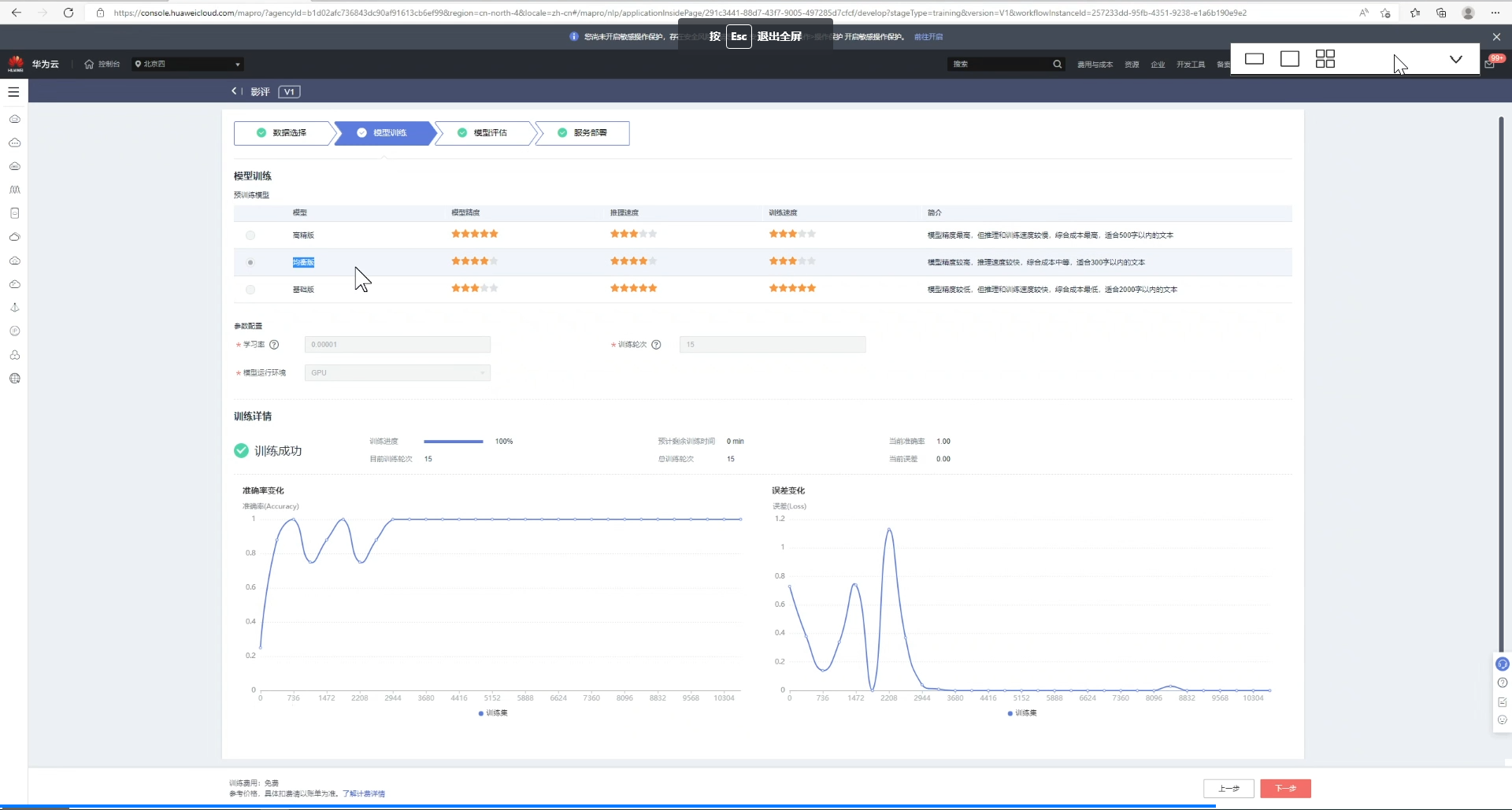
6、训练完成后,进行模型评估
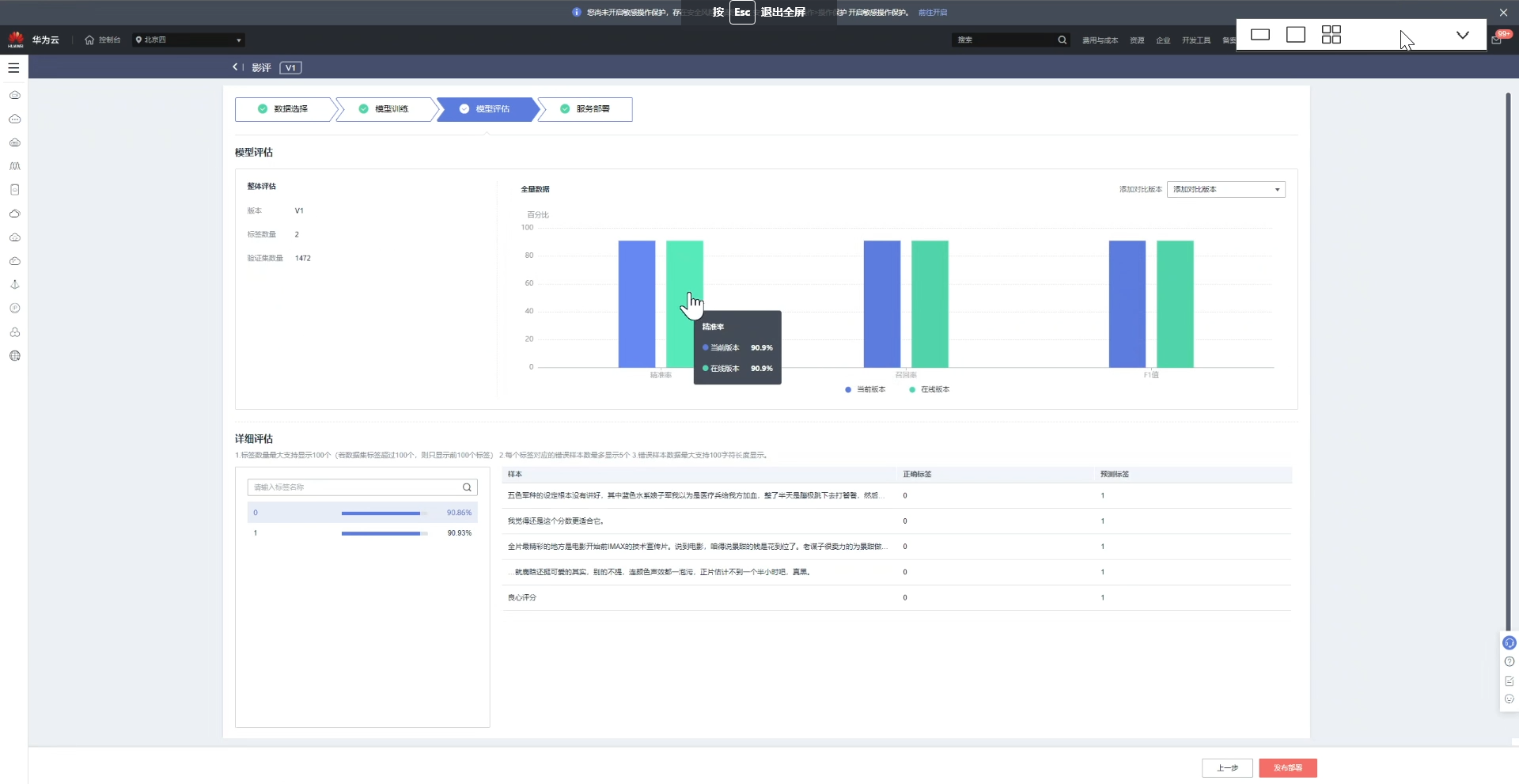
7、在线部署
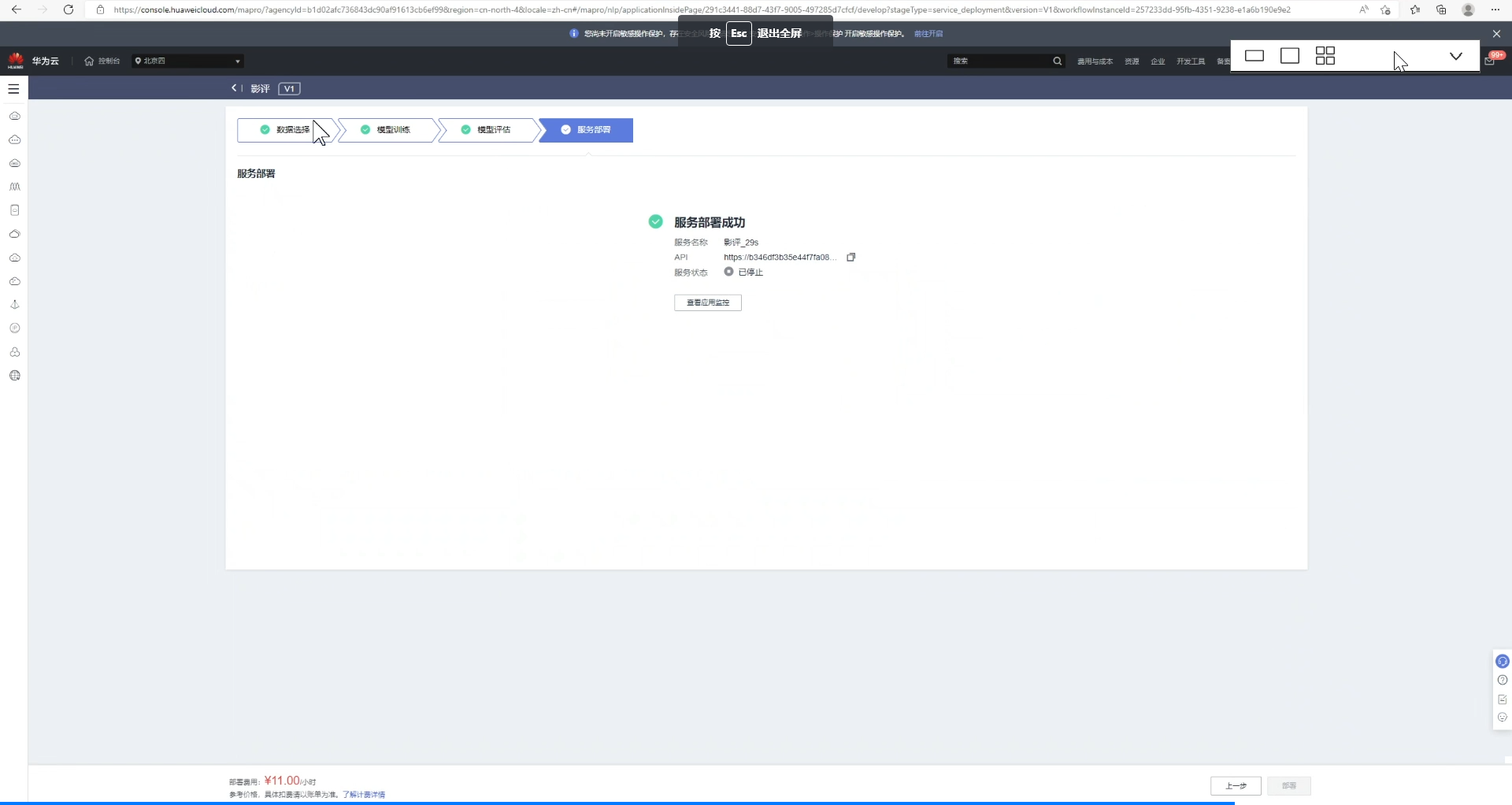
8、推理测试
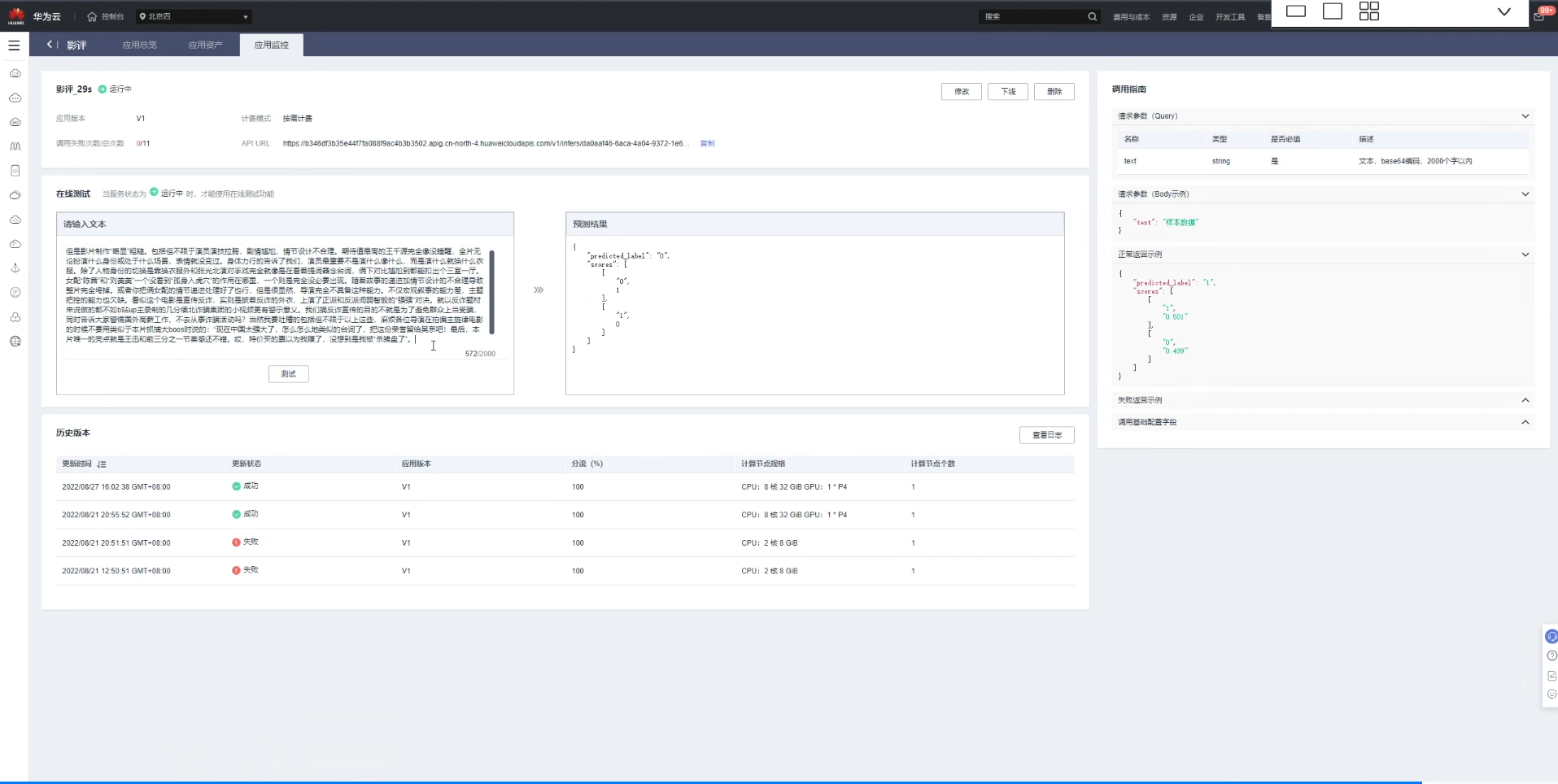
总结
本文着重介绍了:Word Embedding、BERT原理、Transformer原理、Project:BERT中文电影评论正负情感分析、使用ModelArts Pro快速上手自定义主题情感分析。
本文一步步实操了电影评论正负情感分析流程,明白了电影评论是分析情感是如何处理的,了解了很多相关的概念的知识,收获满满。而ModelArts Pro提供完整的工作流应用可以快速部署成API服务,满足实际业务的需求。
本文整理自华为云社区【内容共创】活动第20期。
查看活动详情:https://bbs.huaweicloud.cn/blogs/374925
相关任务详情:任务10.“情感专家”在线分析影评情感基调

- 点赞
- 收藏
- 关注作者
评论(0)