Python基础——Visual Studio版本——第五章 文件I/O


![]()
📋前言📋
💝博客:【红目香薰的博客_CSDN博客-计算机理论,2022年蓝桥杯,MySQL领域博主】💝
✍本文由在下【红目香薰】原创,首发于CSDN✍
🤗2022年最大愿望:【服务百万技术人次】🤗
第五章 文件I/O
需要升级环境的执行即可
pip3 config set global.index-url https://repo.huaweicloud.cn/repository/pypi/simple
pip3 config list
pip3 install --upgrade pip
目录
1、Python os.chmod() 方法
path -- 文件名路径或目录路径。
flags -- 可用以下选项按位或操作生成, 目录的读权限表示可以获取目录里文件名列表, ,执行权限表示可以把工作目录切换到此目录 ,删除添加目录里的文件必须同时有写和执行权限 ,文件权限以用户id->组id->其它顺序检验,最先匹配的允许或禁止权限被应用。
权限列表
stat.S_IXOTH: 其他用户有执行权0o001
stat.S_IWOTH: 其他用户有写权限0o002
stat.S_IROTH: 其他用户有读权限0o004
stat.S_IRWXO: 其他用户有全部权限(权限掩码)0o007
stat.S_IXGRP: 组用户有执行权限0o010
stat.S_IWGRP: 组用户有写权限0o020
stat.S_IRGRP: 组用户有读权限0o040
stat.S_IRWXG: 组用户有全部权限(权限掩码)0o070
stat.S_IXUSR: 拥有者具有执行权限0o100
stat.S_IWUSR: 拥有者具有写权限0o200
stat.S_IRUSR: 拥有者具有读权限0o400
stat.S_IRWXU: 拥有者有全部权限(权限掩码)0o700
stat.S_ISVTX: 目录里文件目录只有拥有者才可删除更改0o1000
stat.S_ISGID: 执行此文件其进程有效组为文件所在组0o2000
stat.S_ISUID: 执行此文件其进程有效用户为文件所有者0o4000
stat.S_IREAD: windows下设为只读
stat.S_IWRITE: windows下取消只读添加一个test.txt文本文件用作测试
![]()
修改权限编码——只读权限
import os
import stat
#只读
os.chmod("test.txt", stat.S_IRUSR)修改只读权限
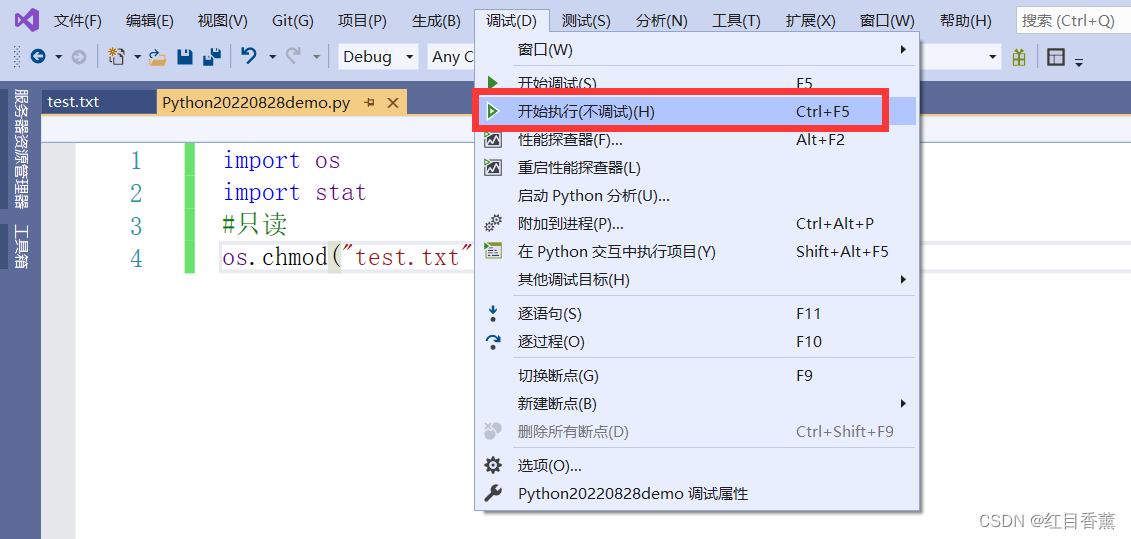
![]()
只读提示
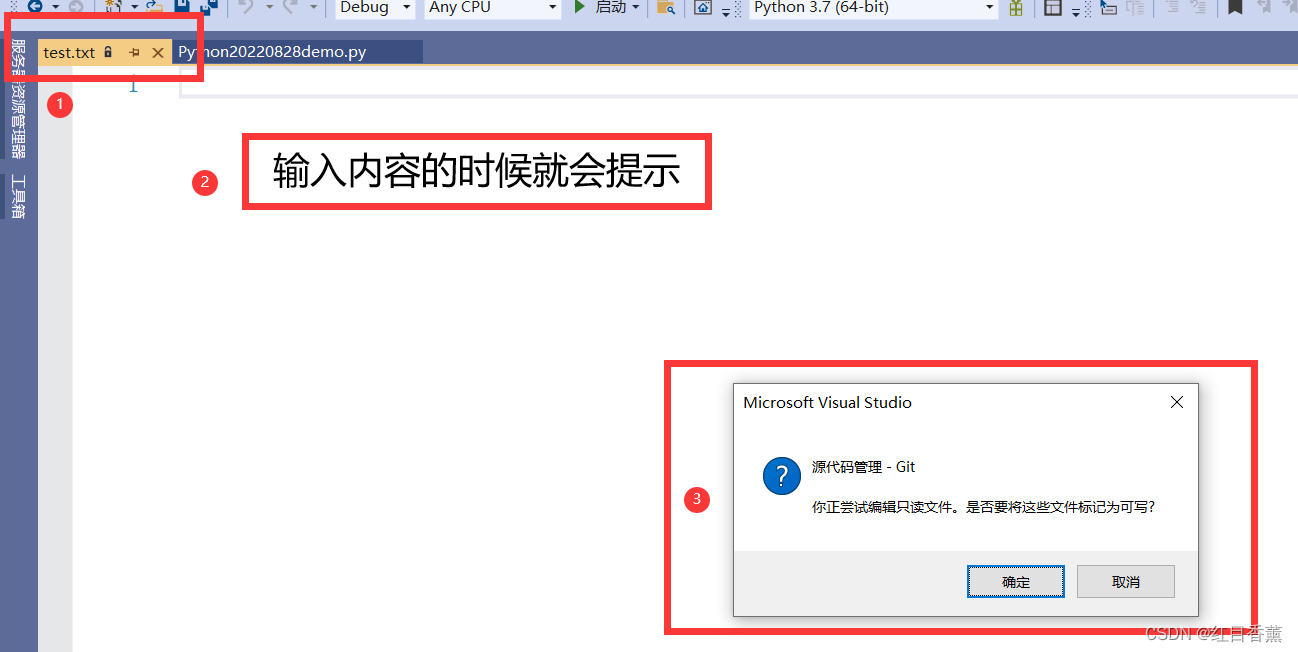
![]()
修改回全部权限
import os
import stat
#全部权限
os.chmod("test.txt", stat.S_IRWXU)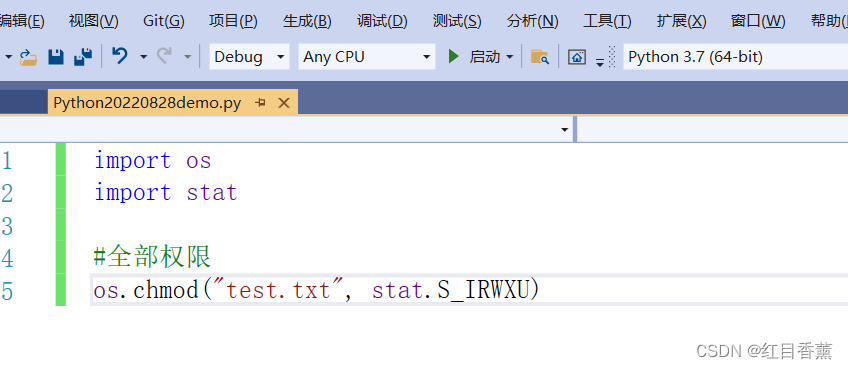
![]()
执行
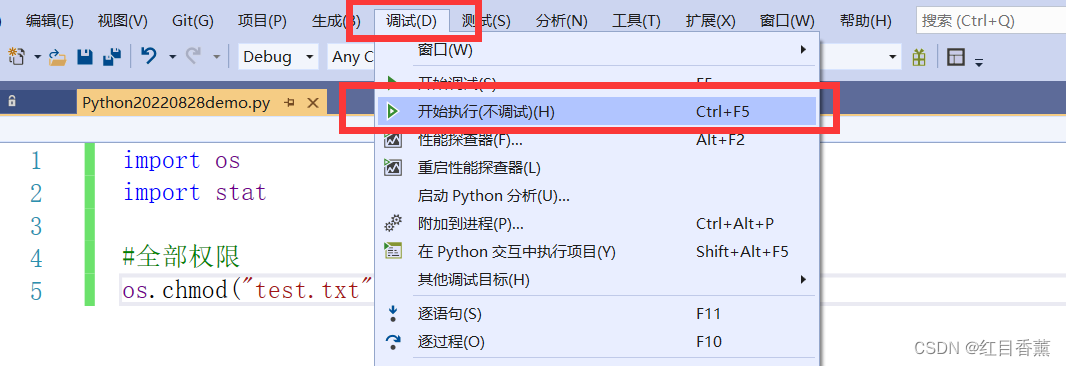
![]()
写入测试
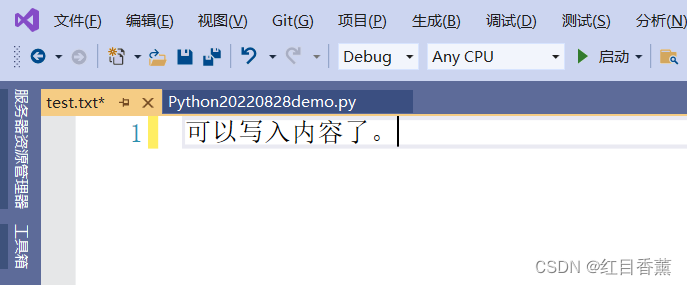
![]()
可以看到能写内容了,权限测试完毕。
2、OS
Python程序使用自带的os模块操作目录,os模块包含的函数见下表。
| 方法 |
描述 |
| os.getcwd() |
获取当前工作目录,即当前Python脚本工作的目录路径 |
| os.listdir() |
返回指定目录下的所有文件和目录名 |
| os.remove() |
用来删除一个文件 |
| os.removedirs(r"c:\python") |
删除多个目录 |
| os.path.isfile() |
判断给出的路径是否是一个文件 |
| os.path.isdir() |
检验给出的路径是否是一个目录 |
| os.path.dirname() |
获取路径名 |
| os.path.basename() |
获取文件名 |
| os.path.split() |
返回一个路径的目录名和文件名 |
| os.path.splitext() |
分离扩展名 |
| os.path.basename() |
获取文件名 |
| os.rename(oldFileName,newFileName) |
重命名 |
| os.makedirs(r"c:\python\test") |
创建多级目录 |
| os.mkdir("test") |
创建单个目录 |
| os.chmod(file) |
修改文件权限与时间戳 |
| os.exit() |
终止当前进程 |
| os.path.getsize(filename) |
获取文件大小 |
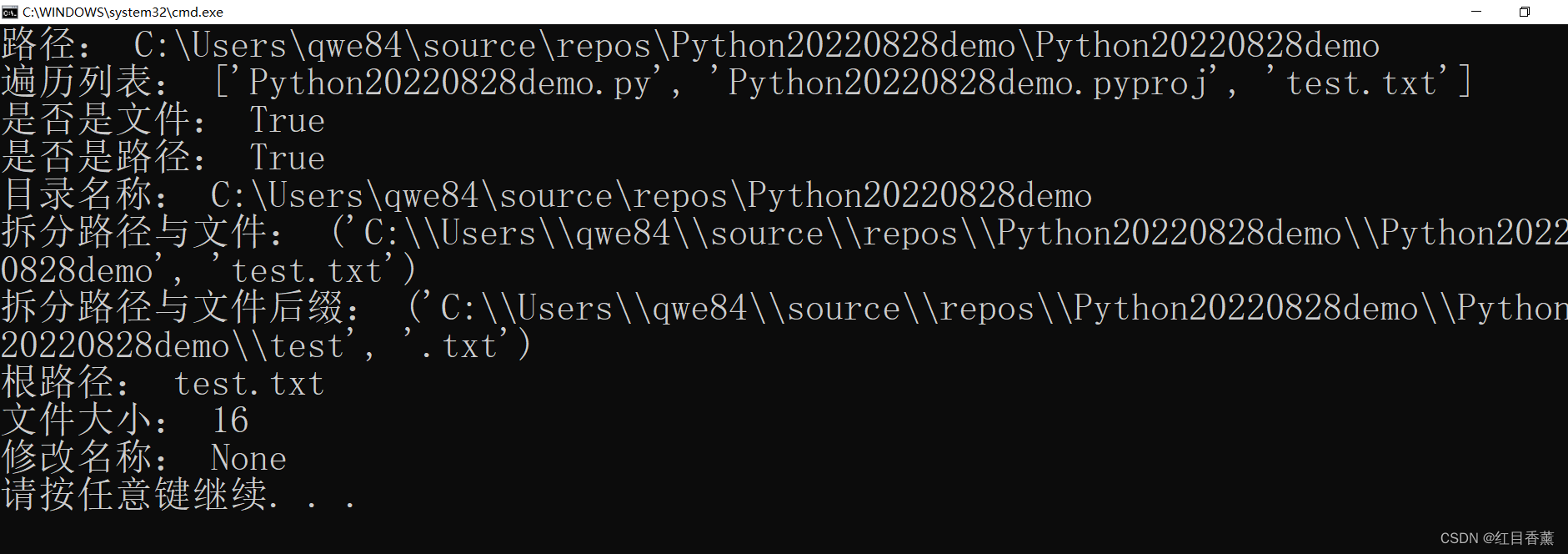
我写了个绝对路径的测试:
import os
dirUrl = os.getcwd()
url = r"C:\Users\qwe84\source\repos\Python20220828demo\Python20220828demo\test.txt"
print("路径:",dirUrl)
print("遍历列表:",os.listdir())
print("是否是文件:",os.path.isfile(url))
print("是否是路径:",os.path.isdir(dirUrl))
print("目录名称:",os.path.dirname(dirUrl))
print("拆分路径与文件:",os.path.split(url))
print("拆分路径与文件后缀:",os.path.splitext(url))
print("根路径:",os.path.basename(url))
print("文件大小:",os.path.getsize(url))
print("修改名称:",os.rename("test.txt", "./utest.txt"))修改名称是没有返回值的,没有返回值的内容输出的时候显示【None】
![]()
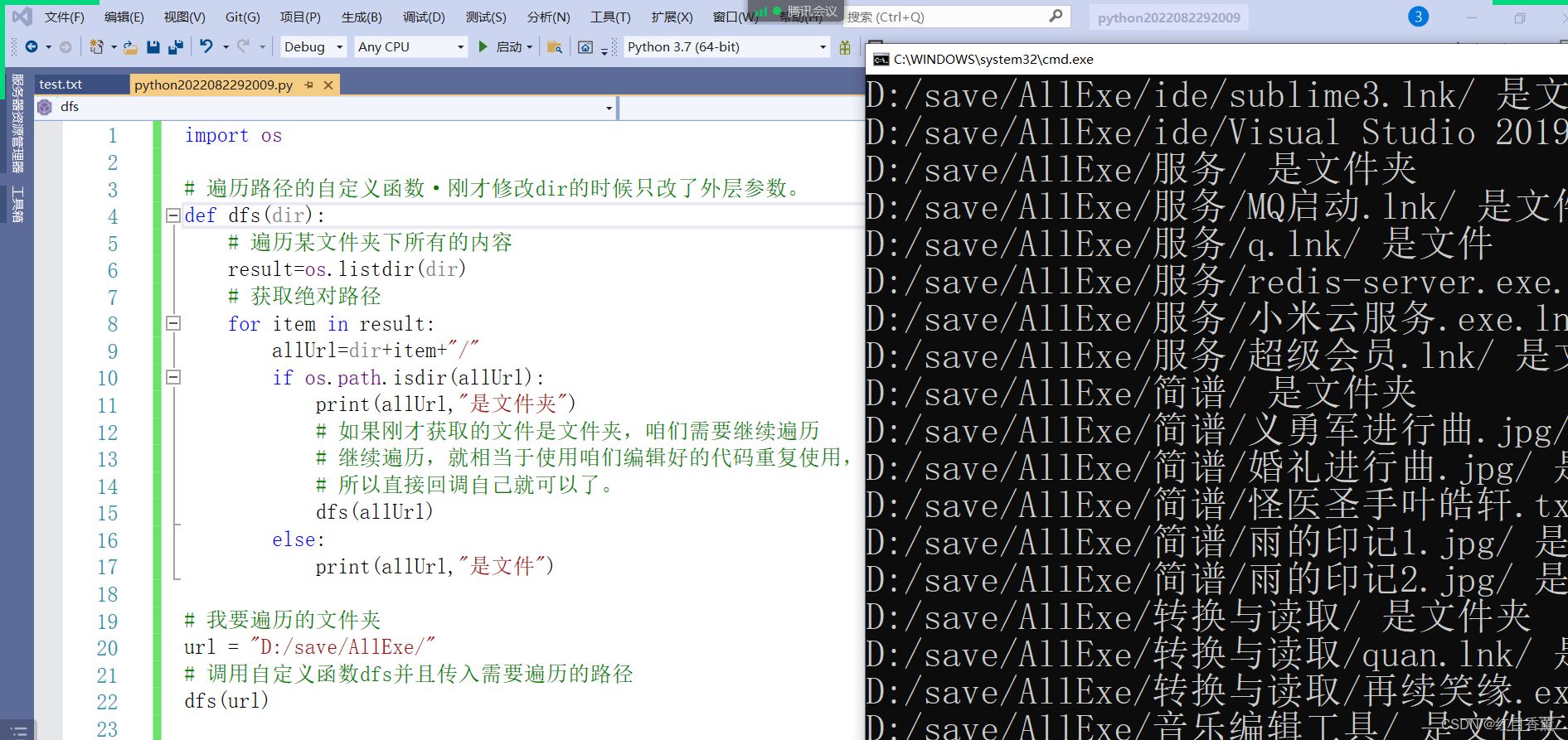
3、遍历文件夹
import os
# 遍历路径的自定义函数·刚才修改dir的时候只改了外层参数。
def dfs(dir):
# 遍历某文件夹下所有的内容
result=os.listdir(dir)
# 获取绝对路径
for item in result:
allUrl=dir+item+"/"
if os.path.isdir(allUrl):
print(allUrl,"是文件夹")
# 如果刚才获取的文件是文件夹,咱们需要继续遍历
# 继续遍历,就相当于使用咱们编辑好的代码重复使用,
# 所以直接回调自己就可以了。
dfs(allUrl)
else:
print(allUrl,"是文件")
# 我要遍历的文件夹
url = "D:/save/AllExe/"
# 调用自定义函数dfs并且传入需要遍历的路径
dfs(url)
![]()
4、文件读取
语法:
文件对象名 = open(file_name [, access_mode][, buffering])
参数说明:
file_name:该参数指要访问的文件名称对应的字符串
access_mode:决定了打开文件的模式,包括只读、写入和追加等
buffering:buffering的值被设为0,则不会寄存;buffering的值取1,访问文件时会寄存行。
模式列表:
| 模式 |
描述 |
| r |
以只读方式打开文件。文件的指针将会放在文件的开头,这是默认模式 |
| rb |
以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头,这是默认模式 |
| r+ |
打开一个文件用于读写。文件指针将会放在文件的开头 |
| rb+ |
以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头 |
| w |
打开一个文件只用于写入。如该文件已存在,则将其覆盖。如该文件不存在,创建新文件 |
| w+ |
打开一个文件用于读写。如该文件已存在,则将其覆盖。如该文件不存在,创建新文件 |
| a |
打开一个文件用于追加。如该文件已存在,文件指针将会放在文件的结尾,即新的内容将会被写入到 已有内容之后。如该文件不存在,创建新文件进行写入 |
| a+ |
打开一个文件用于读写。如该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。 如该文件不存在,创建新文件用于读写 |
| ab+ |
以二进制格式打开一个文件用于追加。如该文件已存在,文件指针将会放在文件的结尾。 如该文件不存在,创建新文件用于读写 |
文件对象操作列表
| file.closed |
如果文件已被关闭,返回True,否则返回False |
| file.mode |
返回被打开文件的访问模式 |
| file.name |
返回文件的名称 |
| file.softspace |
如果用print输出后,必须接一个空格符,即返回false,否则返回true |
读取示例:
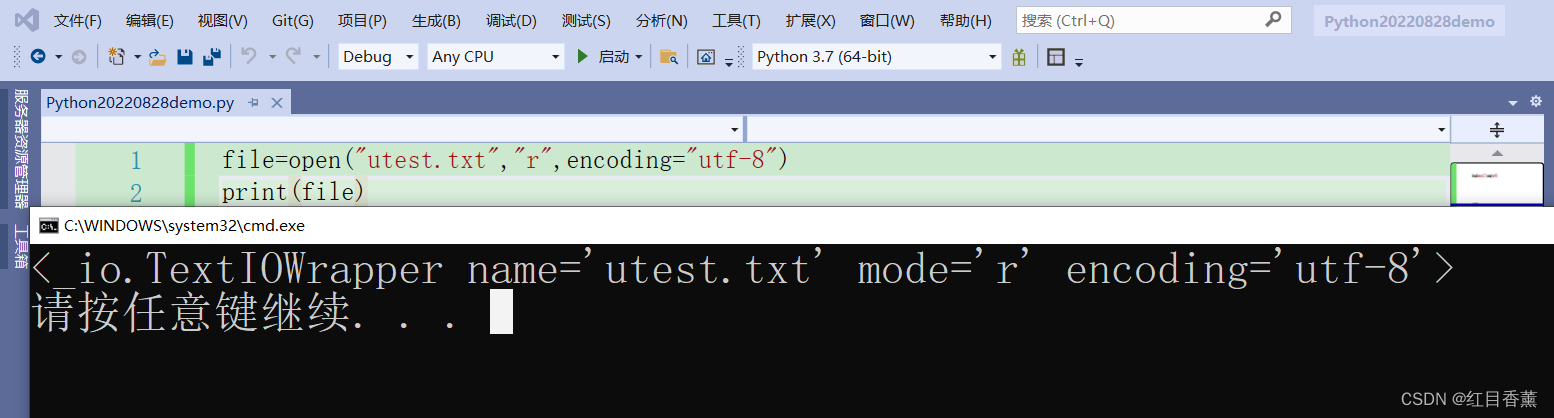
![]()
使用read进行读取
read是有()的,如果没有添加括号则会爆出以下的错误提示
built-in method readline of _io.TextIOWrapper object at 0x000001E8D5B6BC88

正确编码测试:
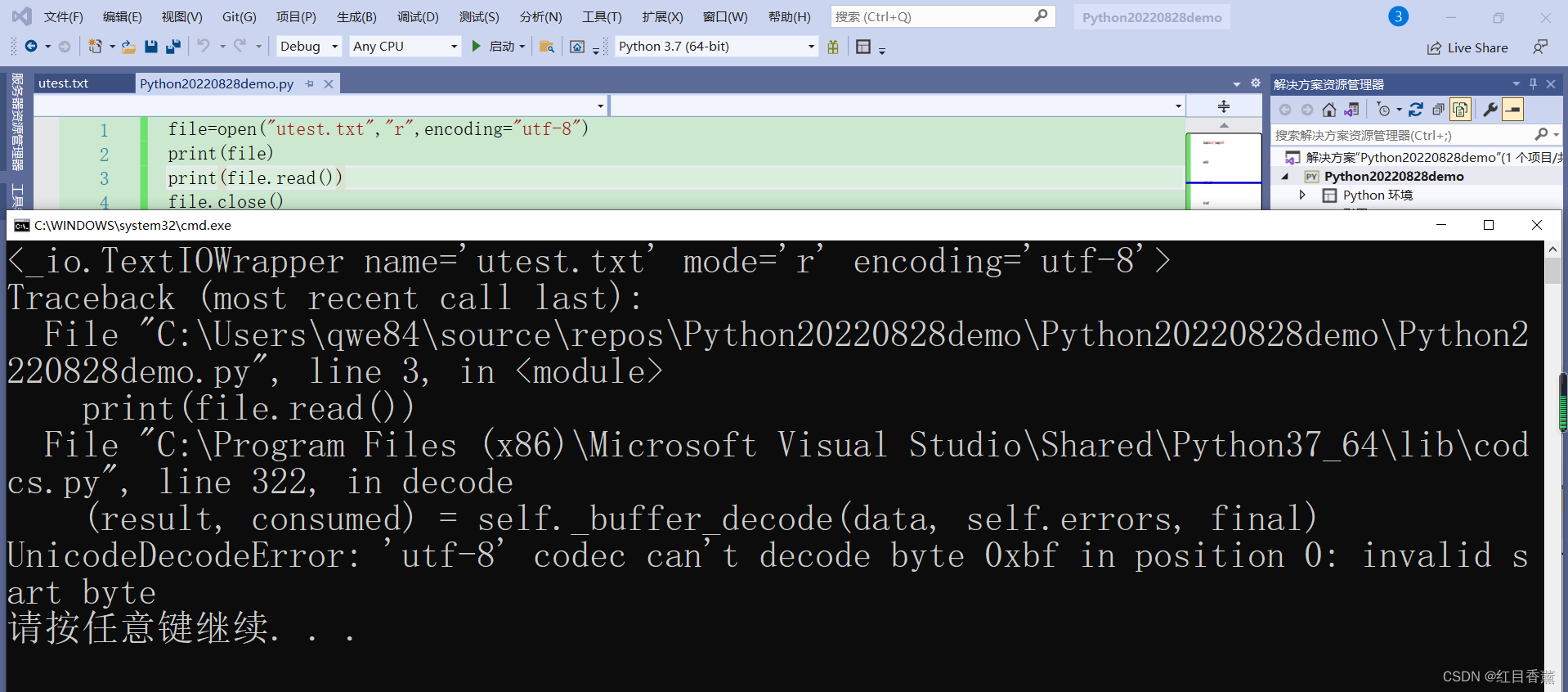
![]()
一般我们读取文件都使用utf-8的模式,但是很多默认的文件格式需要【gbk】的方式进行读取,例如咱们如果没有单独修改文件的编码模式我们需要通过gbk的方式进行读取,如果我们修改文件编码格式utf-8就可以使用utf-8进行读取了。
修改步骤
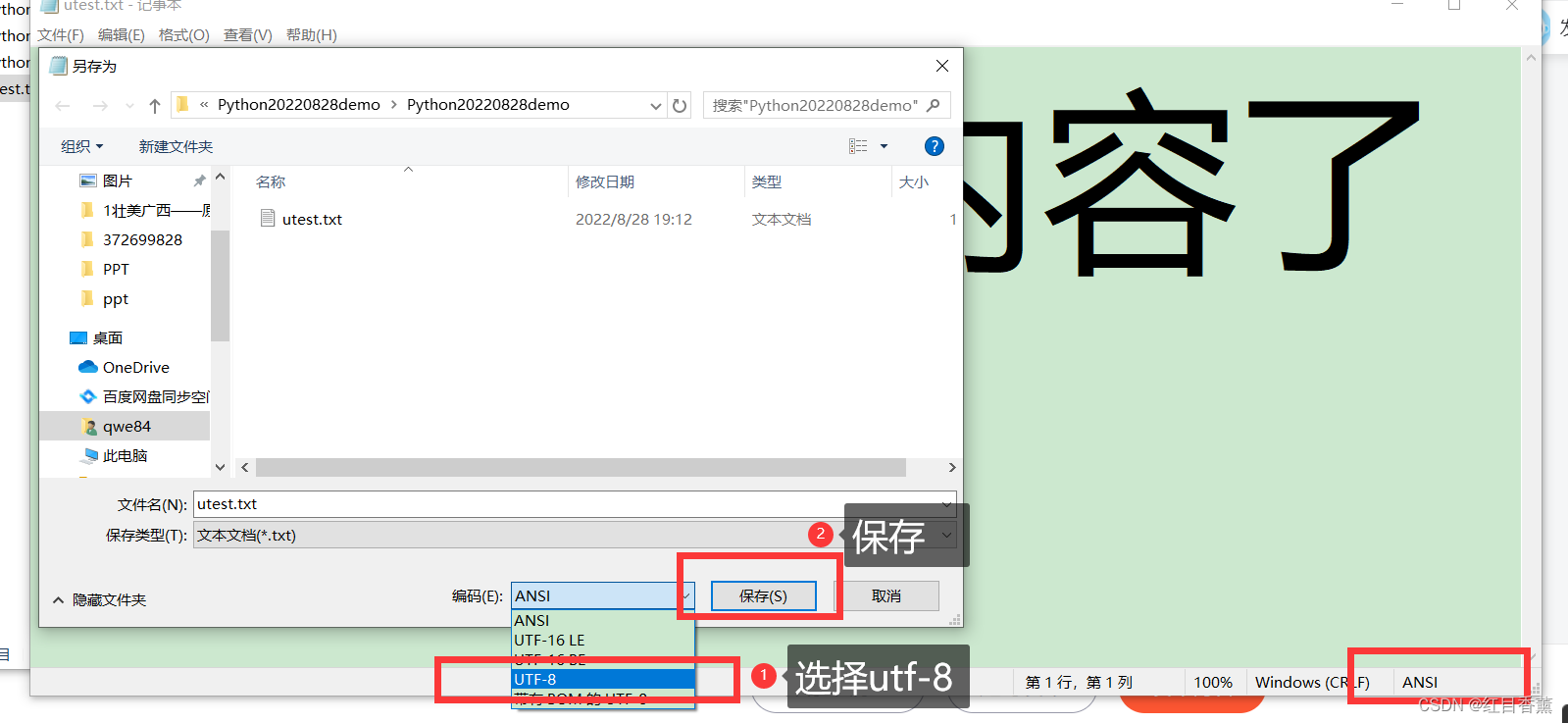
![]()
读取测试
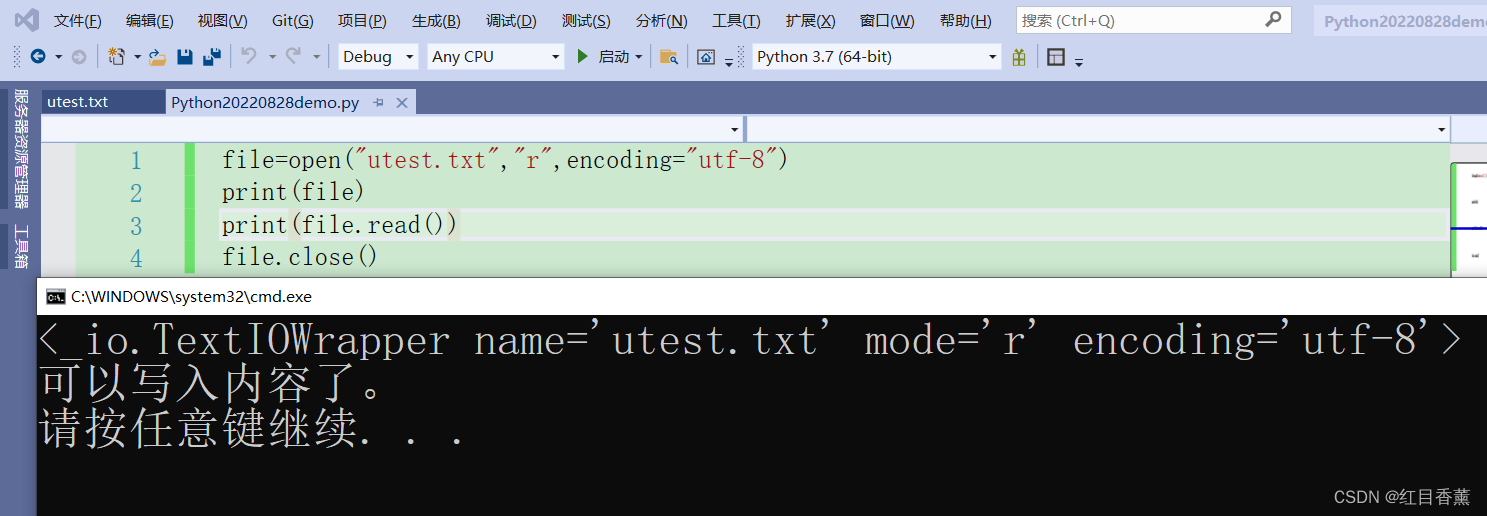
![]()
写入示例:
import os
path = os.getcwd() +"\\"+ "utest.txt"
file = open(path, "w+",encoding="utf-8")
file.write("有情人终成眷属。")
file.close()
这里使用的是w+,会替换内容,如果使用【a+】就会变成累加
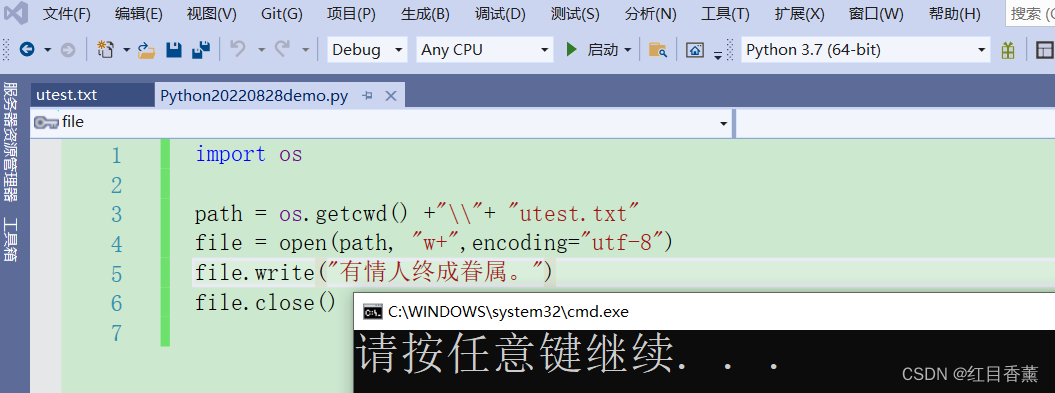
![]()
5、JSON序列化与反序列化
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:
对比示例:
| JSON类型 | Python类型 |
|---|---|
| {} | dict |
| [] | list |
| "string" | str |
| 1234.56 | int或float |
| true/false | True/False |
| null | None |
Python内置的json模块提供了非常完善的Python对象到JSON格式的转换。我们先看看如何把Python对象变成一个JSON:
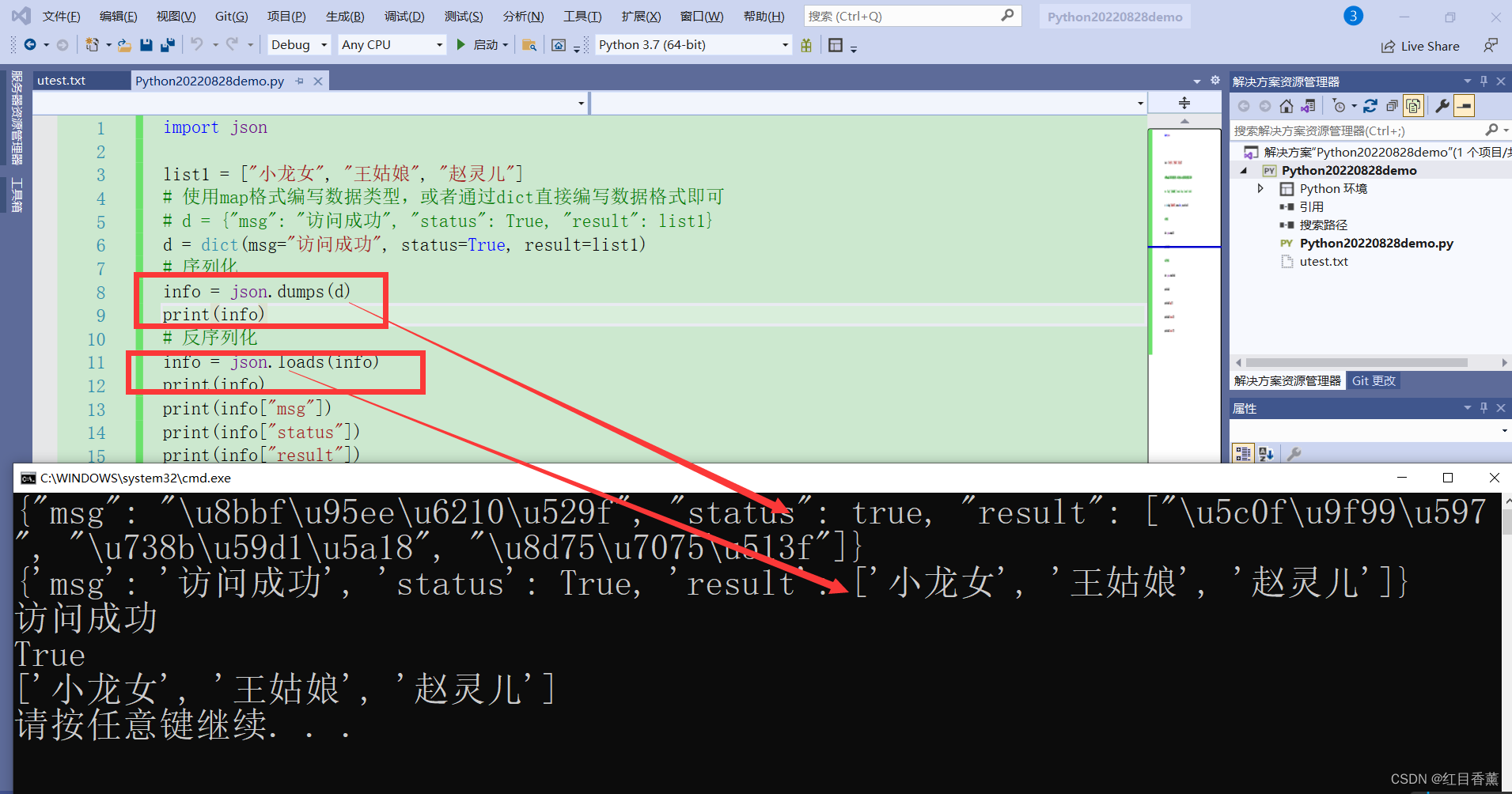
序列化示例1:dict(map)
import json
list1 = ["小龙女", "王姑娘", "赵灵儿"]
# 使用map格式编写数据类型,或者通过dict直接编写数据格式即可
# d = {"msg": "访问成功", "status": True, "result": list1}
d = dict(msg="访问成功", status=True, result=list1)
# 序列化
info = json.dumps(d)
print(info)
# 反序列化
info = json.loads(info)
print(info["msg"])
print(info["status"])
print(info["result"])从以上的实验中可以看到json序列化与反序列化的过程。
![]()
6、文件I/O(XML)
XML虽然比JSON复杂,在Web中应用也不如以前多了,不过仍有很多地方在用,所以,有必要了解如何操作XML。
XML(Extensible Markup Language,可扩展标记语言)与JSON数据格式类似,用于提供数据表述格式,适用于不同应用程序间的数据交换。 XML是一套定义语义标记的规则,同时也是用于定义其他标识语言的元标识语言。 Python有三种解析XML的方式,分别为SAX、DOM以及ElementTree。
现阶段主要是对XML做读取操作:
XML结构示例:
<?xml version="1.0" encoding="utf-8" ?>
<users>
<user>
<id>1</id>
<userName>admin</userName>
<passWord>123456</passWord>
<introduce>管理员</introduce>
</user>
<user>
<id>2</id>
<userName>likes</userName>
<passWord>123456</passWord>
<introduce>爱好</introduce>
</user>
<user>
<id>2</id>
<userName>王语嫣</userName>
<passWord>123456</passWord>
<introduce>琅嬛福地,神仙姐姐。</introduce>
</user>
</users>读取示例:
from xml.dom import minidom as getDom
# 获取xml操作文件信息
dom = getDom.parse("text.xml")
# 获取dom元素
root = dom.documentElement
# 根节点名称
print(root.nodeName)
# 根据dom元素获取根节点下所有的一级子节点
lists = root.getElementsByTagName("user")
# 遍历一级子节点的过程中便可以获取数据
for u in lists:
print(u.getElementsByTagName("id")[0].firstChild.data)
print(u.getElementsByTagName("userName")[0].firstChild.data)
print(u.getElementsByTagName("passWord")[0].firstChild.data)
print(u.getElementsByTagName("introduce")[0].firstChild.data)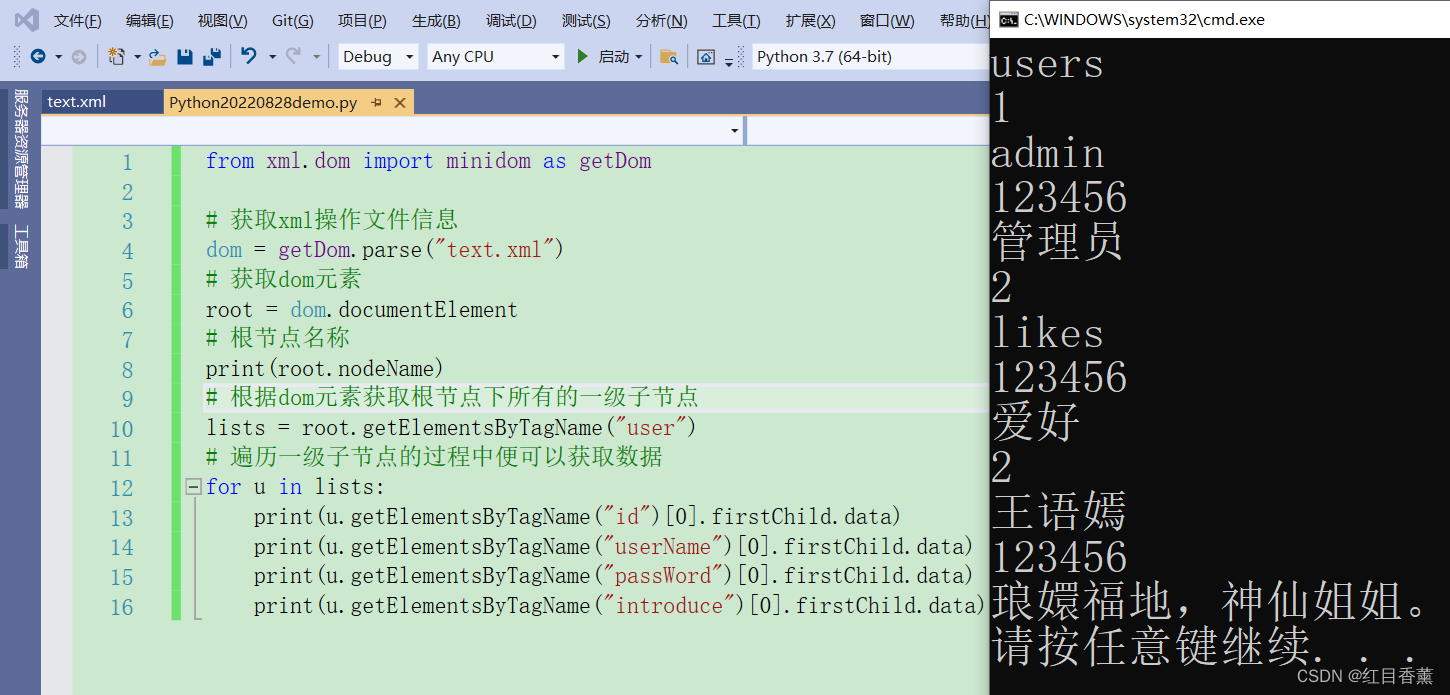
![]()
7、CSV前言
CSV(Comma-Separated Values,中文逗号分隔值或字符分隔值)是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用,也应用于程序之间转移表格数据。
CSV并不是一种单一的、定义明确的格式,泛指具有以下特征的任何文件: 纯文本,使用某个字符集,如ASCII、Unicode、EBCDIC或GB2312。 由记录组成(典型的是每行一条记录)。 每条记录被分隔符分隔为字段(典型分隔符有逗号、分号或制表符;有时分隔符可以包括可选的空格)。 每条记录都有同样的字段序列。
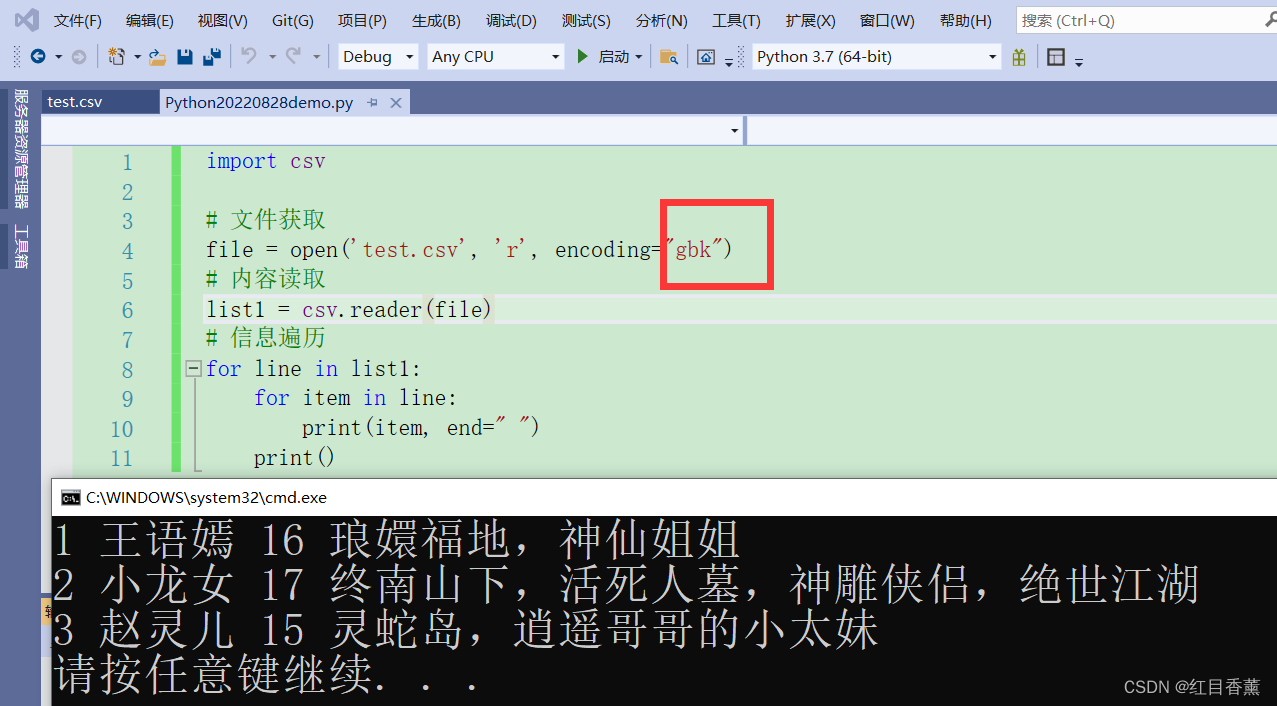
数据格式
1 王语嫣 16 琅嬛福地,神仙姐姐
2 小龙女 17 终南山下,活死人墓,神雕侠侣,绝世江湖
3 赵灵儿 15 灵蛇岛,逍遥哥哥的小太妹未修改编码格式就是gbk的格式
![]()
写入操作:
import csv
# 文件获取
file = open('test.csv', 'w+', encoding="gbk")
# 写入操作
writer = csv.writer(file)
# 按照行写入
writer.writerow(['1', '王语嫣', '16', "琅嬛福地,神仙姐姐"])
data = [('2','小龙女', '17', '终南山下,活死人墓,神雕侠侣,绝世江湖'),
('3','赵灵儿', '15', '灵蛇岛,逍遥哥哥的小太妹')]
# 写入多行记录
writer.writerows(data)
# 刷新文件
file.flush()
# 关闭文件流
file.close()8、EXCEL操作
Python读写Excel文档需要安装和使用xlrd模块,Excel文件写入需要使用xlwt模块。
写入XLS
这里用到的包是:【import xlwt】
需要进行下载:【pip install xlwt】
我这安装过了啊。
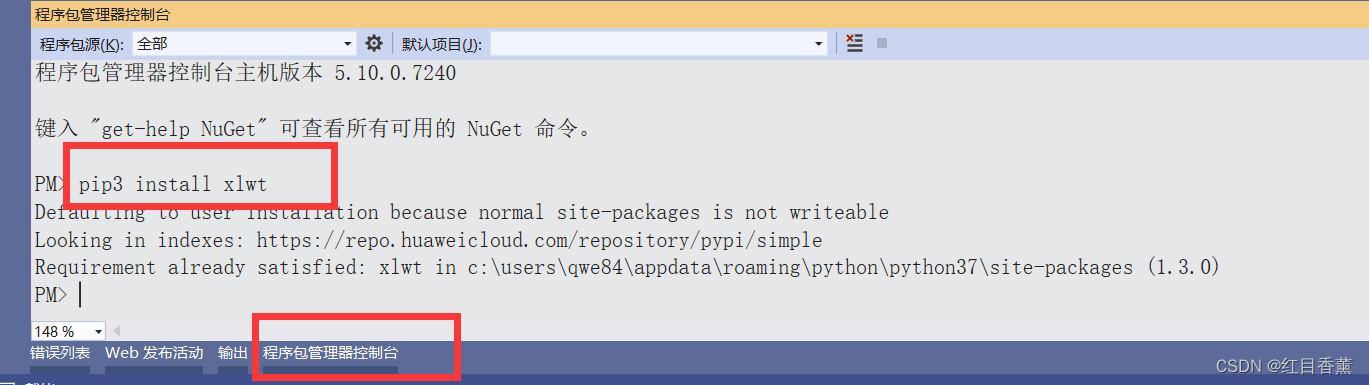
![]()
执行完成后发现有test.xls文件
import xlwt
# 创建内容的样式对象,包括字体样式以及数字的格式
wb = xlwt.Workbook()
ws = wb.add_sheet('Sheet1') # 添加一个sheet
# 需要将中文通过u""的形式转换为unicode编码
data = [[u"编号", u"姓名", u"年龄", u"简介"],
[1, u"王语嫣", 16, u"琅嬛福地,神仙姐姐"],
[2, u"小龙女", 17, u"活死人墓,冰山美人"],
[3, u"赵灵儿", 31, u"灵蛇岛上,戚戚艾艾"]
]
for i in range(0, data.__len__()): # 循环遍历每一行
for j in range(0, data[i].__len__()): # 循环遍历第i行的每一列
ws.write(i, j, data[i][j])
wb.save("test.xls")
![]()
读取XLS
这里用到的包是:【import xlrd】
需要进行下载:【pip install xlrd】
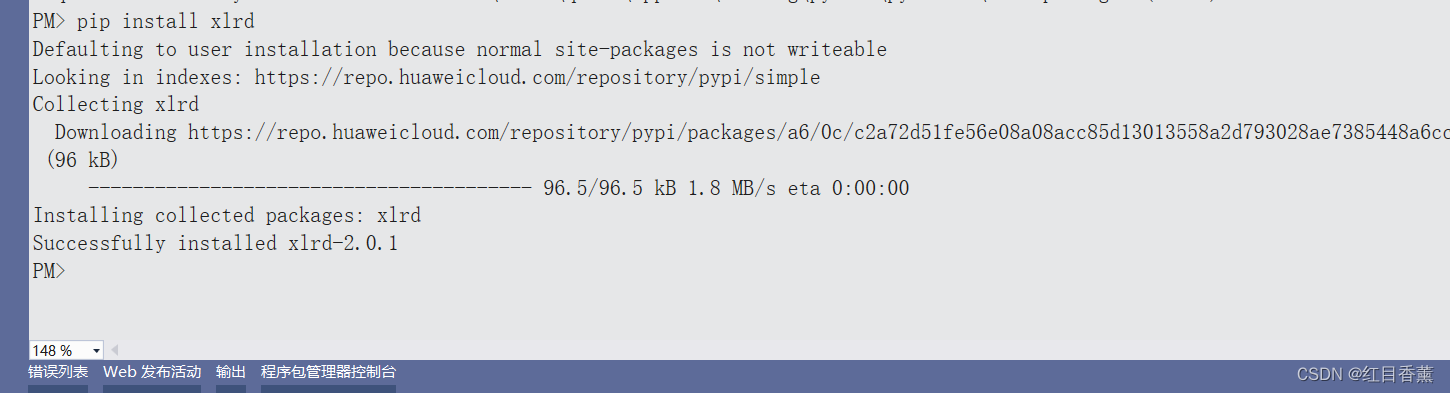
![]()
import xlrd
workbook = xlrd.open_workbook('test.xls') # 打开Excel文件读取数据
print(workbook.sheet_names()) # 获取所有sheet
# sheet2 = workbook.sheet_names()[0] #第一种方式,根据下标获取
sheet = workbook.sheet_by_index(0) # 第二种方式,根据sheet索引获取sheet对象,索引从0开始
sheet = workbook.sheet_by_name('Sheet1') # 第三种方式,根据sheet名称获取sheet对象
print(sheet.name, sheet.nrows, sheet.ncols) # sheet的名称、行数和列数
# 获取整行和整列的值(数组)
rows = sheet.row_values(2) # 获取第三行内容
cols = sheet.col_values(2) # 获取第三列内容
print(str(rows), '\n', cols)
# 获取单元格内容
print(sheet.cell(1, 0).value, end=" ")
print(sheet.cell_value(1, 0), end=" ")
print(sheet.row(1)[0].value, end=" ")
print(sheet.cell(1, 0).ctype) # 获取单元格内容的数据类型
print("\n--------------------------------------\n")
# 遍历
for row in sheet:
print(row[0], row[1], row[2], row[3])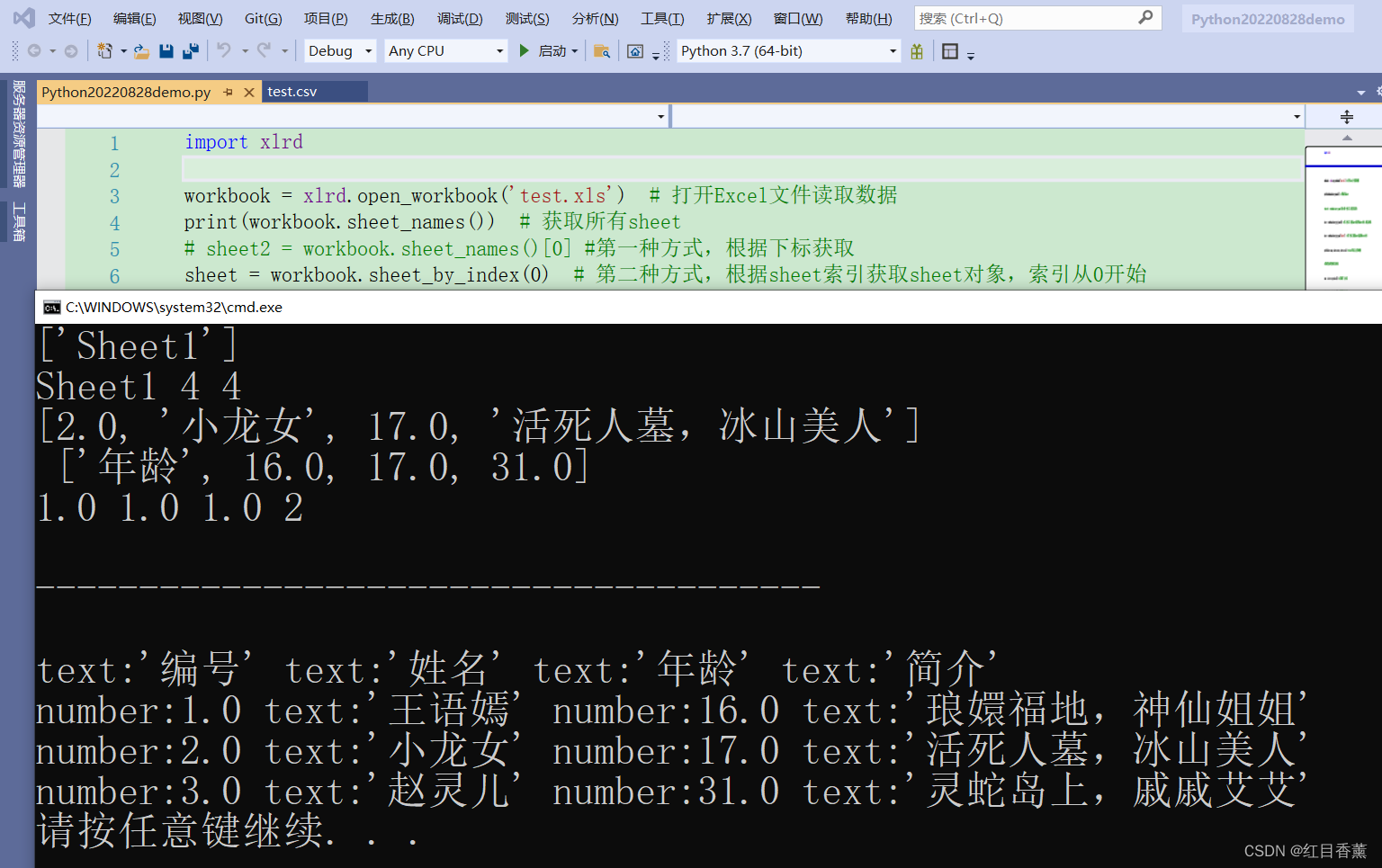
![]()
9、try异常处理
当我们认为某些代码可能会出错时,就可以用try来运行这段代码,如果执行出错,则后续代码不会继续执行,而是直接跳转至错误处理代码,即except语句块,执行完except后,如果有finally语句块,则执行finally语句块,至此,执行完毕。
语法:
try:
执行代码
except:
发生异常后执行的代码
else:
如果没有异常执行的代码示例:
try:
print('try...')
r = 10 / 0
print('result:', r)
except ZeroDivisionError as e:
print('except:', e)
finally:
print('finally...')
print('end')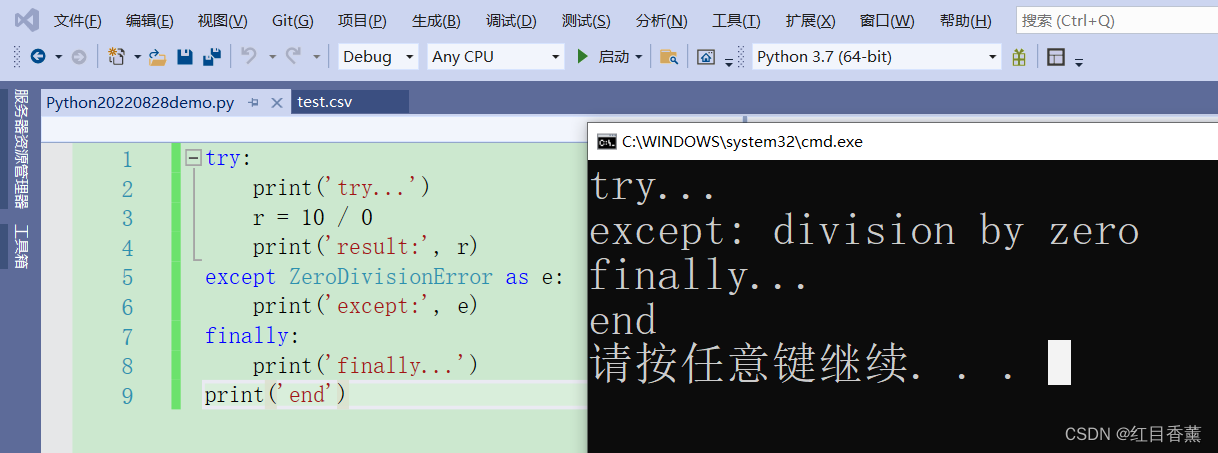
![]()
到这里Python的I/O处理就讲解完毕了。

- 点赞
- 收藏
- 关注作者
评论(0)