使用Jupyter可视化查询语句的语法成分--以图查询语言Cypher为例

查询语言是用于从数据库或信息系统中查询数据的计算机语言,使用查询语言可以很方便地在数据库中完成各类数据管理以及查询操作。在关系数据库中常用的查询语言是SQL,在图数据库管理系统中,常用的查询语言有Cypher、Gremlin、SPARQL等。
当数据管理系统收到一条查询语句时,会对这条查询语句进行一些理解和解释,最终会翻译为一系列可以执行的步骤来处理数据。其中“语法解析”和“词法解析”是计算机理解查询语句的第一步。而词法和语法的解析依赖于一定的文法规则,对这些文法规则进行学习和可视化,可以学习查询语言的各个语法成分,加深对查询语言的了解。

通常词法&语法解析器可以由一些工具进行生成,例如常见的flex/bison(c/c++), yacc(c/c++), antlr(java)、javacc(java)、Parboiled(scala)等。这些工具往往以规则文件作为输入,输出一个语法解析器。本文的最终目标是:通过一个已生成的语法解析器解析某条查询语句,对解析到的语法成分进行可视化。
在查询语言的选择上,考虑到华为图引擎GES对接了Cypher、Gremlin两大主流图查询语言,其中Cypher查询语言有公开的文法规则,所以以Cypher为例; 在生成工具方面,由于只有少数工具可以生成python的解析代码,这里使用antlr4作为语法解析器生成工具。
环境准备
注:本文对应的notebook链接为:https://developer.huaweicloud.cn/develop/aigallery/notebook/detail?id=9ea7f844-2a05-49d0-b117-1260f65ef87d,相关代码可以直接在notebook上运行。
首先从OpenCypher官网下载cypher的文法规则,从Antlr的官网下载antlr工具包。
wget https://s3.amazonaws.com/artifacts.opencypher.org/M18/Cypher.g4
wget https://github.com/antlr/website-antlr4/blob/gh-pages/download/antlr-4.8-complete.jar
pip install antlr4-python3-runtime==4.8这里简单介绍一下语法规则,一条语法规则定义了语句中的各个部分如何被解释,下面展示了Match子句的解释规则:一个Match子句,必须包含一个单词MATCH和一个Pattern(MATCH SP? oC_Pattern),MATCH和Pattern间可能有空格(SP),MATCH和Pattern的前部可能有一个OPTIONAL单词(( OPTIONAL SP )?),后部可能有一个Where语法成分(( SP? oC_Where )?)。关于antlr的细节,可以查看华为云相关博文介绍:Antlr4简明使用教程, 推荐一款优秀的语法解析工具—Antlr4
oC_Match
: ( OPTIONAL SP )? MATCH SP? oC_Pattern ( SP? oC_Where )? ;下面代码可以生成cypher查询语言python版本的语法解析器。
java -cp antlr-4.8-complete.jar org.antlr.v4.Tool -visitor -package cypher -Dlanguage=Python3 Cypher.g4如果你正在使用notebook,且notebook环境中没有java,也可以通过下列代码下载已经生成好的语法解析器。
import moxing as mox
mox.file.copy('obs://obs-aigallery-zc/GES/ges4jupyter/beta/cypher-generated-parser.zip', 'cypher-generated-parser.zip')!unzip cypher-generated-parser.zip语法树生成 & 可视化
对文法规则的可视化,网上已有诸多案例,例如OpenCypher官网提供了Cypher文法的可视化结果,可以点击此处进入查看。另外网上也有一部分网站,可以输入文法规则,返回可视化结果。例如在网站https://www.bottlecaps.de/convert/上, 可以输入包括antlr、bison、javacc在内的诸多文法规则,而后生成文法规则的可视化图表。例如将Cypher.g4文法文件输入这个网站,可以获得的文法规则截选如下。
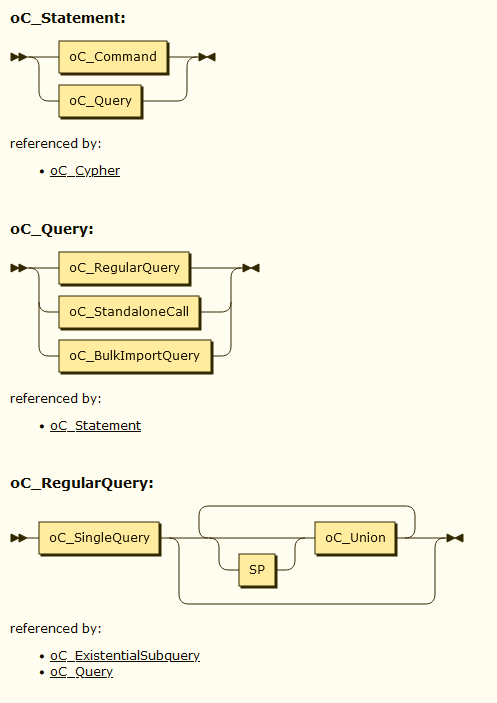
这里给出了oC_Statement、oC_Query、oC_RegularQuery三条规则的解释,例如对oC_Statement而言,其可以由一个oC_Command或者一个oC_Query构成;而一个oC_RegularQuery,则可以由一个oC_SingleQuery,以及0到多个oC_Union构成。这些文法规则的可视化给出了文法的定义,却未提供可视化某条语句解析结果的能力。可视化语句的解析结果目前只能依赖antlr的插件,但是antlr未提供jupyter侧的可视化工具。下面本文试图在jupyter侧可视化一条查询语句的语法解析路径。
首先我们写一个解析查询语句的函数,用来生成语法解析器的解析结果。下列代码是一个经典的antlr解析语句的流程,通过构造词法解析器(lexer)、单词流(stream)、语法解析器(parser)来完成整个初始化过程,最终parser只需要调用文法中的规则名,即可使用规则来生成语法树结构。
from CypherLexer import CypherLexer
from CypherParser import CypherParser
from antlr4 import *
def get_ast(statement):
reader = InputStream(statement)
lexer = CypherLexer(reader)
stream = CommonTokenStream(lexer)
parser = CypherParser(stream)
return parser.oC_Statement()而后输入一条查询语句,并调用ast函数,代码会返回解析后的对象。
ast_tree = get_ast('match (n) return n limit 10')在获得语法树之后,可以从语法树中提取关键语法成分,而后进行可视化。相关代码已经封装为了工具包,可以直接下载使用。其中可视化工具使用的是vis.js。
import moxing as mox
mox.file.copy('obs://obs-aigallery-zc/GES/ges4jupyter/beta/viz_ast_parser.py', 'viz_ast_parser.py')
mox.file.copy('obs://obs-aigallery-zc/GES/ges4jupyter/beta/viz_ast_parser.html', 'viz_ast_parser.html')from viz_ast_parser import *
def beautify_name(name):
return name.replace('OC_', '').replace('Context', '').replace('Impl', '')
vizAstParser = VizAstParser(beautify_name)
vizAstParser.vis_ast(get_ast('match (n) return n limit 10'))
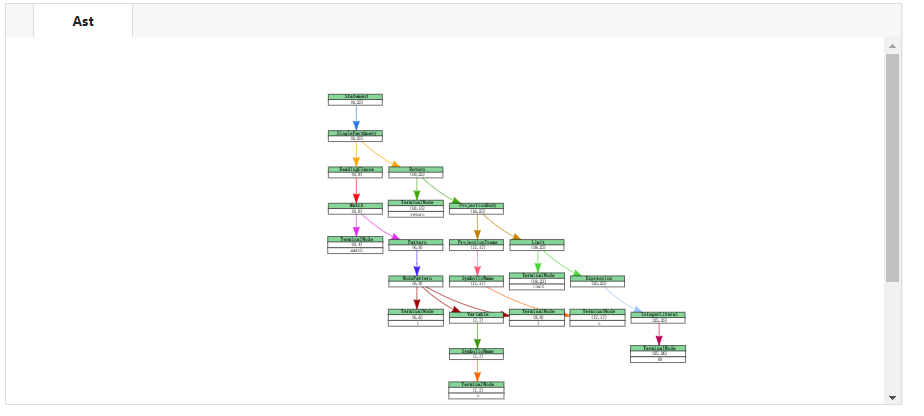
通过可视化可以看到:即使是一条简单的语句也有丰富的语法结构,这样的层次结构,计算机也更容易理解和解析。
备注:
1.工具中的相关代码不仅可以用来可视化cypher语言的语法成分, 其他可以用antlr生成python解析器的语言,该工具也可以提供JupyterLab上的可视化支持。
2. 本文对应的notebook链接为:https://developer.huaweicloud.cn/develop/aigallery/notebook/detail?id=9ea7f844-2a05-49d0-b117-1260f65ef87d,相关代码可以直接在notebook上运行。

- 点赞
- 收藏
- 关注作者
评论(0)