NumPy 与 Python 内置列表计算标准差的区别

1 什么是 Numpy
NumPy,是 Numerical Python 的简称,用于高性能科学计算和数据分析的基础包,像数学科学工具(pandas)和框架(Scikit-learn)中都使用到了 NumPy 这个包。
NumPy 中的基本数据结构是 ndarray 或者 N 维数值数组,在形式上来说,它的结构有点像 Python 的基础类型——Python列表。
但本质上,这两者并不同,可以看到一个简单的对比。
我们创建两个列表,当我们创建好了之后,可以使用 + 运算符进行连接:
list1 = [i for i in range(1,11)]
list2 = [i**2 for i in range(1,11)]
print(list1+list2)
# [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
列表中元素的处理感觉像对象,不是很数字,不是吗? 如果这些是数字向量而不是简单的数字列表,您会期望 + 运算符的行为略有不同,并将第一个列表中的数字按元素添加到第二个列表中的相应数字中。
接下来看一下 Nympy 的数组版本:
import numpy as np
arr1 = np.array(list1)
arr2 = np.array(list2)
arr1 + arr2
# array([ 2, 6, 12, 20, 30, 42, 56, 72, 90, 110])
通过 numpy 的 np.array 数组方法实现了两个列表内的逐个值进行相加。
我们通过 dir 函数来看两者的区别,先看 Python 内置列表 list1 的内置方法:

再用同样的方法看一下 arr1 中的方法:
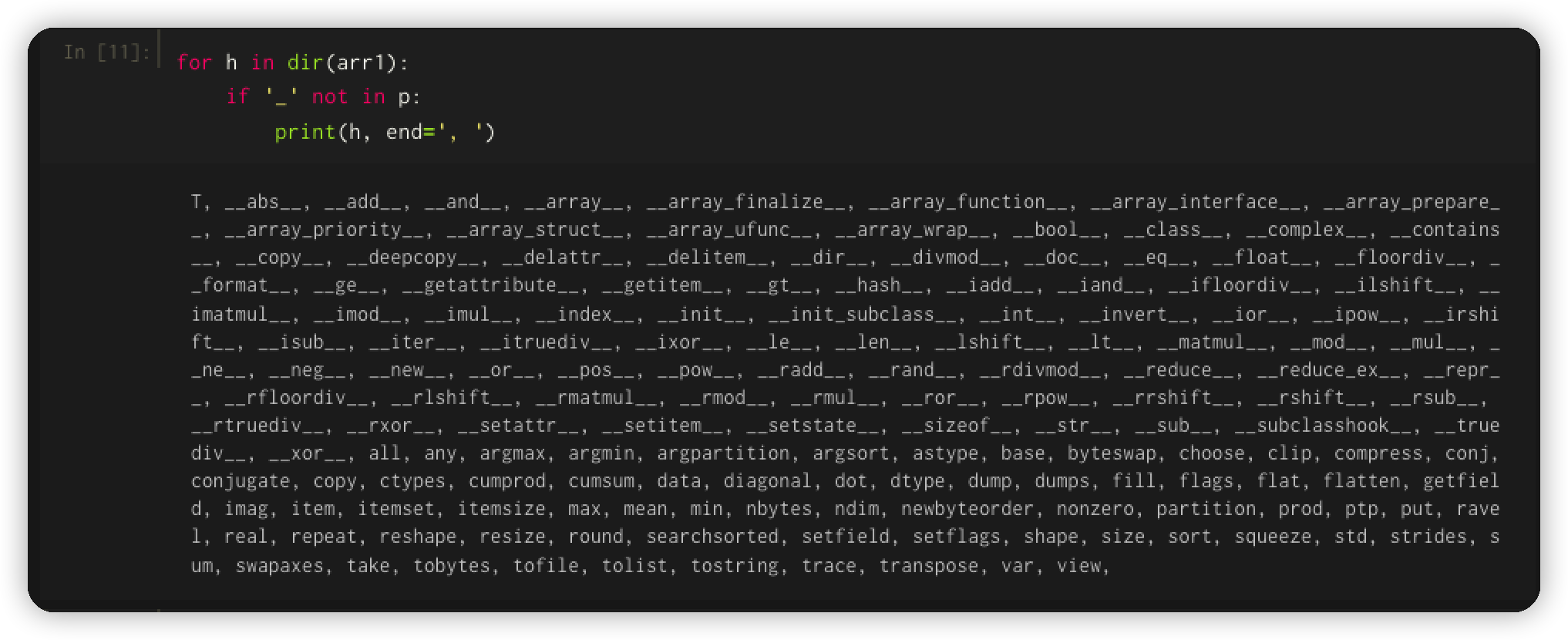
NumPy 数组对象还有更多可用的函数和属性。 特别要注意诸如 mean、std 和 sum 之类的方法,因为它们清楚地表明重点关注使用这种数组对象的数值/统计计算。 而且这些操作也很快。
2 NumPy 数组和 Python 内置计算对比
NumPy 的速度要快得多,因为它的矢量化实现以及它的许多核心例程最初是用 C 语言(基于 CPython 框架)编写的。 NumPy 数组是同构类型的密集排列的数组。 相比之下,Python 列表是指向对象的指针数组,即使它们都属于同一类型。 因此,我们得到了参考局部性的好处。
许多 NumPy 操作是用 C 语言实现的,避免了 Python 中的循环、指针间接和逐元素动态类型检查的一般成本。 特别是,速度的提升取决于您正在执行的操作。 对于数据科学和 ML 任务,这是一个无价的优势,因为它避免了长和多维数组中的循环。
让我们使用 @timing 计时装饰器来说明这一点。 这是一个围绕两个函数 std_dev 和 std_dev_python 包装装饰器的代码,分别使用 NumPy 和内置 Python 代码实现列表/数组的数值标准差计算。
3 函数计算时间装饰器
我们可以使用 Python 装饰器和 functools 模块的 wrapping 来写一个 时间装饰器 timing:
def timing(func):
@wraps(func)
def wrap(*args, **kw):
begin_time = time()
result = func(*args, **kw)
end_time = time()
print(f"Function '{func.__name__}' took {end_time-begin_time} seconds to run")
return result
return wrap4 标准差计算公式
然后利用这个时间装饰器来看 Numpy 数组和 Python 内置的列表,然后计算他们的标准差,公式如图:
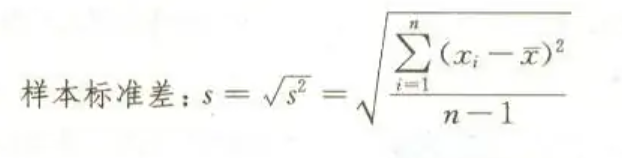
-
定义 Numpy 计算标准差的函数
std_dev(),numpy模块中内置了标准差公式的函数a.std(),我们可以直接调用 -
列表计算公式方法需要按照公式一步一步计算:
-
先求求出宗和
s -
然后求出平均值
average -
计算每个数值与平均值的差的平方,再求和
sumsq -
再求出
sumsq的平均值sumsq_average -
得到最终的标准差结果
result
代码如下:
from functools import wraps
from time import time
import numpy as np
from math import sqrt
def timing(func):
@wraps(func)
def wrap(*args, **kw):
begin_time = time()
result = func(*args, **kw)
end_time = time()
# print(f"Function '{func.__name__}' with arguments {args},keywords {kw} took {end_time-begin_time} seconds to run")
print(f"Function '{func.__name__}' took {end_time-begin_time} seconds to run")
return result
return wrap
@timing
def std_dev(a):
if isinstance(a, list):
a = np.array(a)
s = a.std()
return s
@timing
def std_dev_python(lst):
length = len(lst)
s = sum(lst)
average = s / length
sumsq = 0
for i in lst:
sumsq += (i-average)**2
sumsq_average = sumsq/length
result = sqrt(sumsq_average)
return result运行结果,最终可以看到 1000000 个值得标准差的值为 288675.13459,而 Numpy 计算时间为 0.0080 s,而 Python 原生计算方式为 0.2499 s:
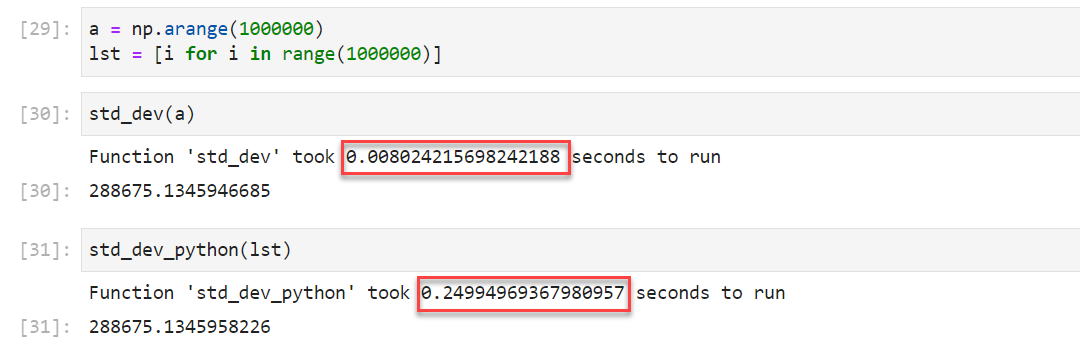
由此可见,Numpy 的方式明显更快。
5 总结
NumPy 是专门针对数组的操作和运算进行了设计,所以数组的存储效率和输入输出性能远优于Python中的嵌套列表,数组越大,NumPy的优势就越明显。
NumPy 还提供了一系列让人眼前一亮的函数,可以用于高级数据科学和机器学习的数值数组和矩阵,今后我们再一一进行探索和学习!

- 点赞
- 收藏
- 关注作者
评论(0)