【云驻共创】openLooKeng,一款面向海量、跨DC的大数据分析利器

本文介绍的内容包括四部分,第一部分是openLooKeng是什么,第二部分是 openLooKeng的典型应用场景。第三部分是openLooKeng的架构解析和关键特性,第四部分是关于openLooKeng 的开源策略以及伙伴的帮助计划。
华为云产品链接:
1. openLooKeng是什么
1.1 openLooKeng打破数据和应用壁垒,快速实现数据价值
首先我们在介绍 openLooKeng之前,我们大致的介绍一下当前大数据面临的一些困难。然后主要是困难就是包括左边的三个方面。第一个就是我们看到的我现在一个很典型的场景,就是很典型的问题,就带大数据的。在大数据中心里面,我们都会有很多的引擎,比如说有OLTP的、 OLAP 的,同时有 hadoop 还有 noSQL 的,然后不同的引擎又有不同的语法。然后通常我们还要面临的是跨地域的一个访问。所以说总结起来就有三个部分的困难。一个就是用数难,对于我们面临的开发的组件越多,老开发语言越多,这样的话导致的开发成本越高。但是说我们要从不同的数据语言中,如果进行关联分析的话,我们需要掌握的语言会很多。
第二个问题就是找树难,找树难一个典型特性是数据比较分散,然后管理复杂,流动性差,查询效率也低。第三部分就是数据的取数难,跨源分析通常需要数据的半天效率不高。通常我们在进行分析的时候要从一个数据源导到另一个数据源,这样的话导致数据存在多份拷贝,然后数据迁移的效率有部分也很低。而openLooKeng的出现就是为了打破数据壁垒,然后快速实现数据的价值。openLooKeng有三个比较典型的特征,就是用数极简,找数极速,取数高效。在下面的 App 中灰着重的讲述这几份方面。然后用数极简的话,第一个方面就说的是在openLooKeng我们提供一个统一的简化的接口,就是 SQL 语言,然后找数取数的话就是我们会在openLooKeng里面利用了很多的增强特性来提高数据的查询速度。然后取数高效,就是我数据在分析的时候不需要搬迁,我们可以实现一个跨源跨域以及跨数据中心的一个联合的查询,从而实现快速的查找数据。
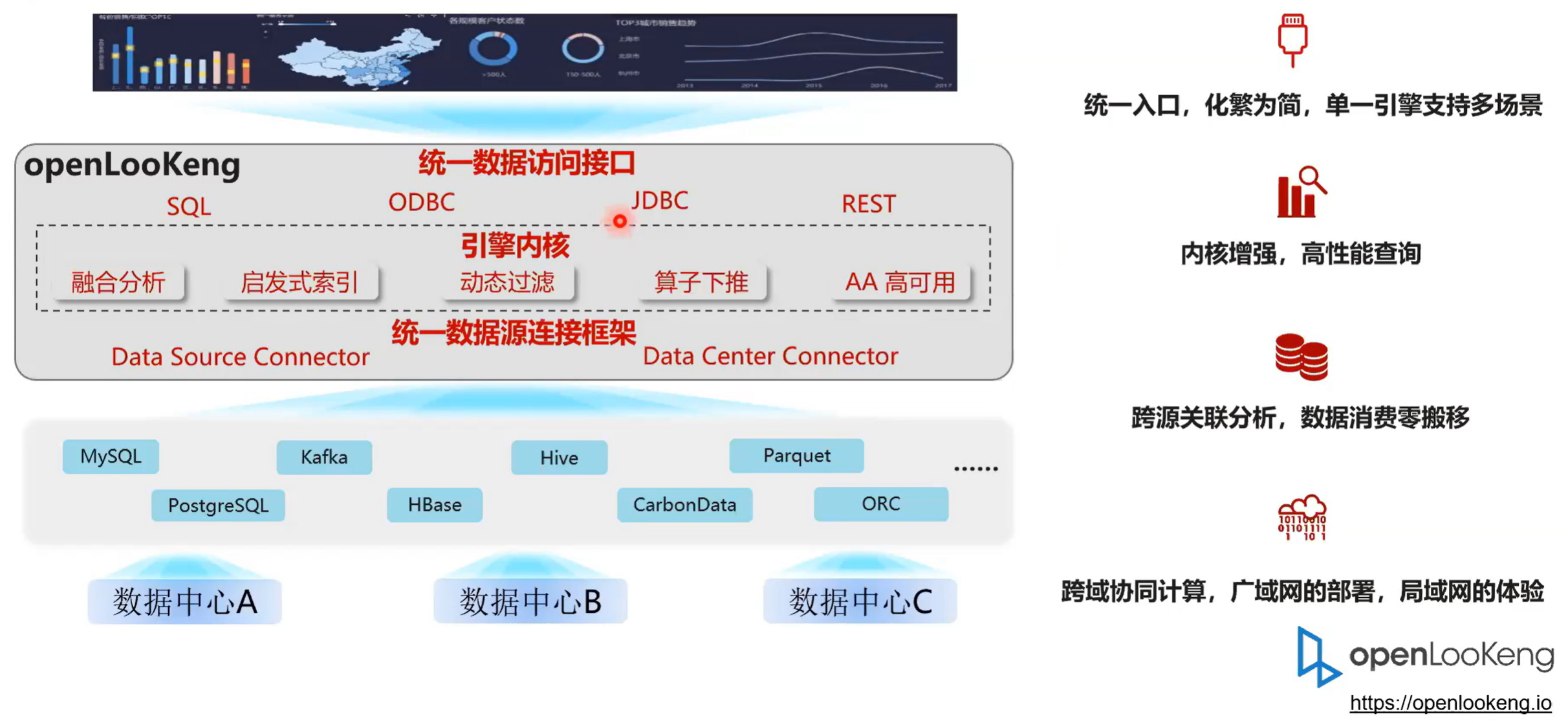
1.2 openLooKeng统一高效的数据虚拟化引擎,让大数据变简单
openLooKeng用一句话来说就是openLooKeng 是一个跨域的高效的虚拟化查询引擎。它主要是分为三个部分,第一部分就是统一接口层,向外接口的话,我们向上层次提供 2003 兼容的SQL语法。然后中间一层是内核引擎层在内核引擎层我们做了很多的优化,比如说启发式索引动态过滤算子下推以及包括一些企业级特性AA的高可用以及权限的控制。
第三部分就是数据源层,openLooKeng提供了一个抽象的数据源框架 data connect framework ,这样的话针对的不同的数据源,我们只要复写它提供的一些接口,就可以简单高效的把数据源接入到 openLooKeng引擎里面来。当前 openLooKeng支持的数据源应该有二十种,然后重新开发一种数据源也是非常简单的。同时我们也实现了一个跨 DC 的 connect 也就是说我们通过openLooKeng的 DC connect 可以去访问另一个openLooKeng集群,这样的话我们形成一个跨域的级联的分析。总体整体来说就是说 openLooKeng有四个特点。第一个就是同一路口化环为点,单一引擎支持多场景。然后第二部分就是内核增强,高性能查询。第三部分就是跨源关联分析,数据消费零搬迁。
然后第四部分就是我们提供了一个的 DC connect 实现跨域的协同分析、广域网的部署、局域网的体验。我们在 DC connect 里面实现了多重的优化,包括数据压缩、断点续传以及算子下推,从而实现在 DC connect 性能跨域访问性能的增强。
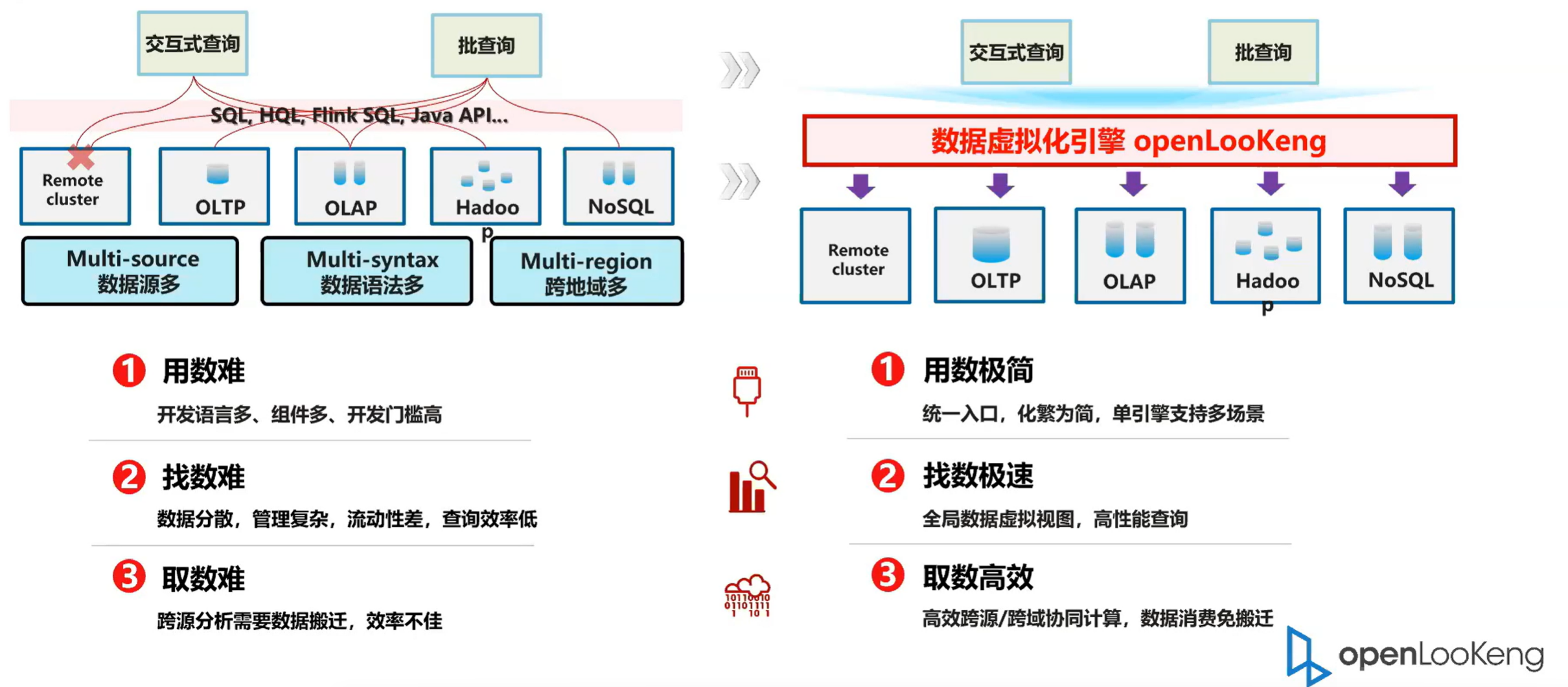
2.3 openLooKeng:统一高效的数据虚拟化引擎
我们接下来看一下就是openLooKeng在大数据一个整体的解决方案中的一个位置。我们可以看到就是openLooKeng属于一个在引擎层的位置,它属于数据查询的一个组件。但是相比于 Spark Hive 参数来看的话,它处于一个更高的层次,因为它下层可以接的数据源就包括了 MySQL hive, hbase 等。而底层的硬件设备是可以支持 Kunpeng和X86 都是可以的。然后上层openLooKeng的上层就是 ISV 的大数据解决方案,这个大数据解决方案可以是数据中台等的解决方案。再上层就是我们的数据使能层。数据使能层就包括数据开发的工具、调度工具,然后再上层就是我们的应用。比如说我们典型的五大应用,政府、金融、安频、互联网、电力加三大运营商。
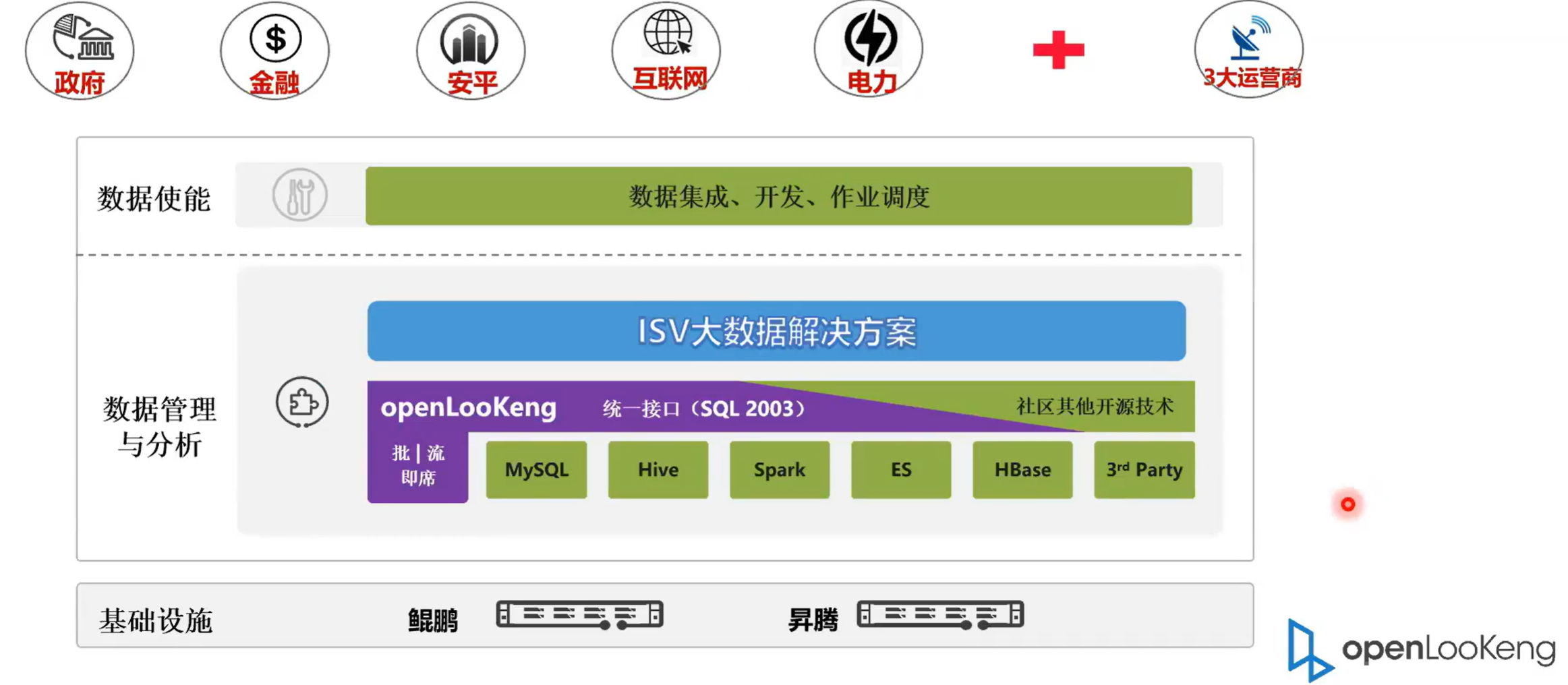
2. openLooKeng的典型应用场景
2.1 openLooKeng面对行业应用四大场景持续发力
openLooKeng面临的四大场景,也就是openLooKeng跟主要发力的四大场景。第一个就是单引擎覆盖交互式的场景。然后现在一个比较典型特征就是比如说我要进行一个数据分析的话,首先数据是导到 Hive 里面,然后经过 ETL 的过程导到一个专题数据库里面,这样的话就有两个烟串,两份数据管理复杂查询数据搬迁的效率也差。
那这是第一个场景,通过openLooKeng的话,我们可以使用它的域跨源能力实现数据关联分析。第二个就是大数据实时数据实时分析场景,这个主要是通过openLooKeng的 Kafka connector 这种数据兼容能力,可以实现数据实时的录入,然后实时的对数据进行分析。第三个的就是引擎接口,就是实现一个跨域跨源的数据分析,比如说我的底程有 Hive 和 mpb 数据源,由于这两种数据源它的本身的接口是不一样的,Hive使用的是 Hsql ,然后MPPDB所是使用的是标准的 SQL ,他们在分析的时候由于他们俩的接口不一样,然后需要写不同的语言对他的数据进行一个读取,然后在上层的平台进行一个关联分析,然后下面的几个应用场景也是在实在实际中用到的一个场景。第一个就是 OPPO 跟的用 OPPO 跟去替换 Hive 或者 Spark 目标的场景是这样子的,交互场景目的是为了分析人员提供或是为数据分析人员提供更方便快捷的机器查询能力,性能的要求是很高的,通常是秒级查询。这个是在我司应用的一个场景,他开当前的话之前他们用的是 Hive 然后中间的有一个比较明显特征是中间结果落盘次数比较多,然后调度效率低。而通过使用 open 螺根然后同时以使用了 open 螺根的启发式索引、执行计划、cache等一些技术。然后还有一个比较典型的特征是 OPPO 跟本来是基于一个内存的全 pipeline 的一个数执行模式,这样的时候数据是没有落盘的,最终效率是提高了两至十倍。这是一个在我市应用的一个场景。然后第二个就是融合分析的场景,就统一 SQL 跨源融合分析。我们看就是下沉有三个数据源,一个是 Hive 一个是 hbase 一个是 ES 这样话通过以前的话就你可要通过不同通过他们各自的 connect client 把它的数据拉取上来,然后通过一块源的综合分析程序来实现一个关联分析。那么的话这个一个就是你的开发成本很高,然后你的效率也很低。就很完美的解决这个问题。
然后第四个场景就是一个跨域的协同分析的场景。现在的跨如果需要两个 DC 之间需要做一个关联分析,首先比如说我 DC 1 要访问 DC 2 的数据到 dcr,需要把数据放到前置机上,然后通过共享交互平台的方式把数据传送给 DC 1,这样的话肯定是不能做到一个T+0准确的分析。通常的话是一个T+ 1 的分析模式。那通过openLooKeng的跨域的 disconnector 就可以实现一个跨域的实时分析。
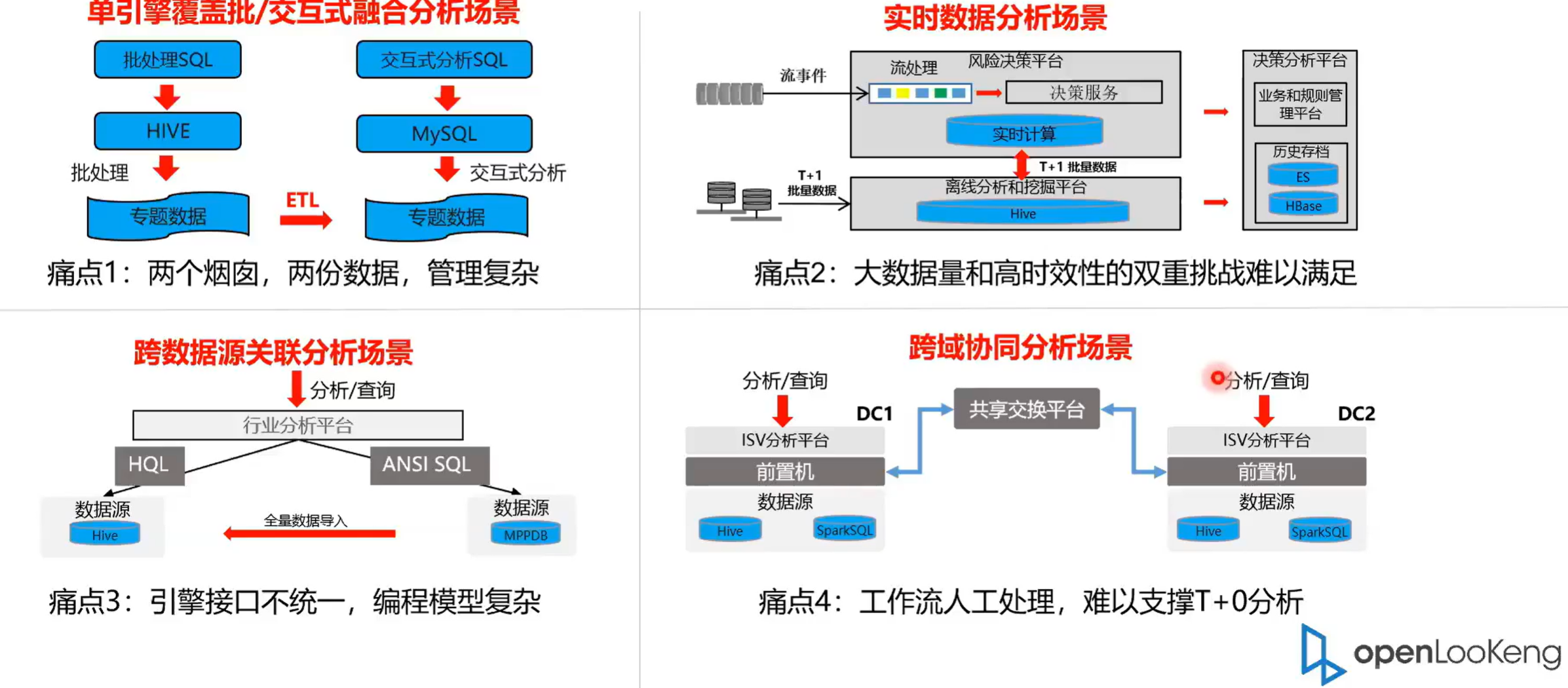
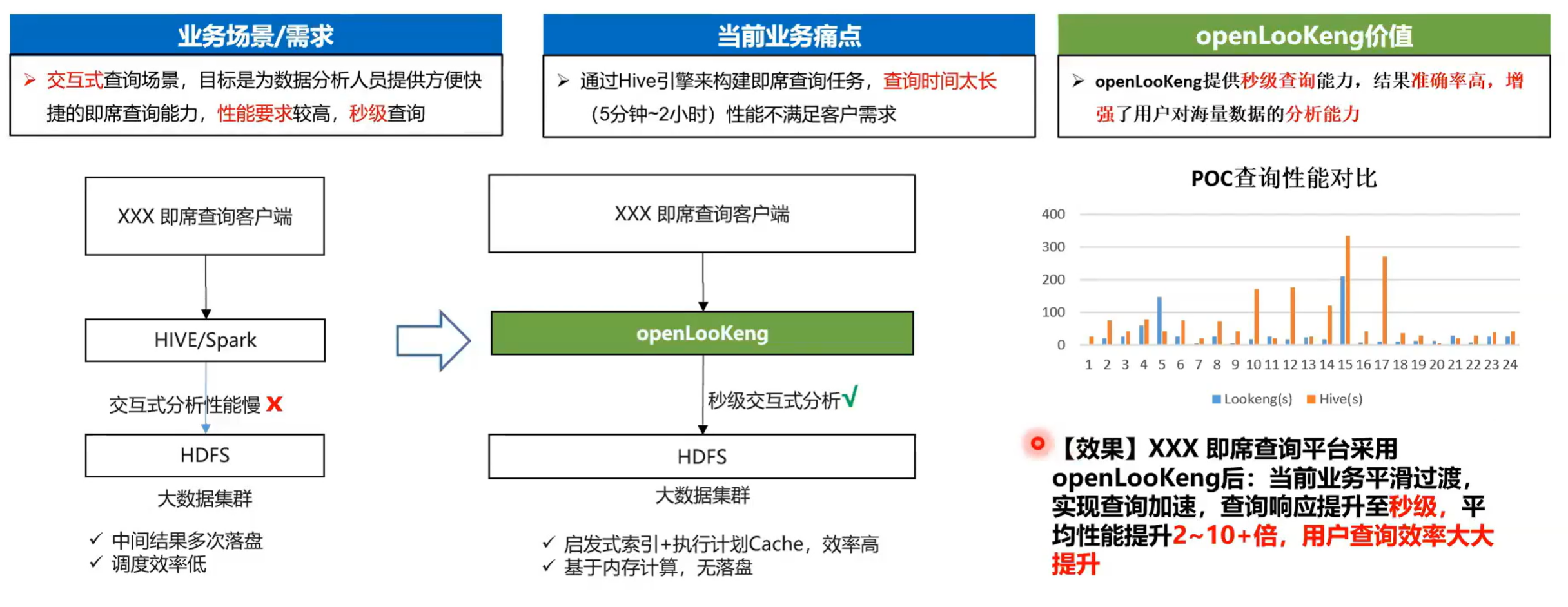
2.2 即席服务提供秒级查询能力
下面的几个应用场景也是在实际中用到的场景。第一个就是用openLooKeng去替换 Hive 或者 Spark 目标的场景,交互场景目的是为了分析人员提供或是为数据分析人员提供更方便快捷的机器查询能力,性能的要求是很高的,通常是秒级查询。这个是在我司应用的一个场景,当前的话之前用的是 Hive 然后中间的有一个比较明显特征是中间结果次数比较多,然后调度效率低。而通过使用openLooKeng启发式索引、执行计划、cache等一些技术。然后还有一个比较典型的特征是openLooKeng本来是基于一个内存的全 pipeline 的一个执行模式,这样数据是没有落盘的,最终效率是提高了两至十倍。这是一个在我司应用的一个场景。然后第二个就是融合分析的场景,就统一 SQL 跨源融合分析。我们看就是下面有三个数据源,一个是 Hive ,一个是 hbase ,一个是 ES 这样话通过以前的话就你可要通过不同通过他们各自的 connect client 把它的数据拉取上来,然后通过一跨源的综合分析程序来实现一个关联分析。那么的话这个一个就是你的开发成本很高,然后你的效率也很低。
然后通过openLooKeng的跨源分析能力,我们可以通过增加新的 connector 把数据源数据接入到openLooKeng引擎里面来。发一个 connector 只需要一人/月的成本。如果说很熟悉的话,通常两个礼拜就好了。
然后通过这种模式,同时openLooKeng又是一个标准的 mppDB架构的一个分析引擎,通过它的统一的北向接口,南向的抽象 connect 的访问模式,就可以把数据实现一个跨源的融合分析场景。一个很典型特征就是它可通过一个统一的 SQL 2003 的接口,屏蔽了异构数据源访问差异,简化应用程序开发提高点,极大的提升了开发效率。然后就是一个高性能提供百毫秒级的一个分析能力。
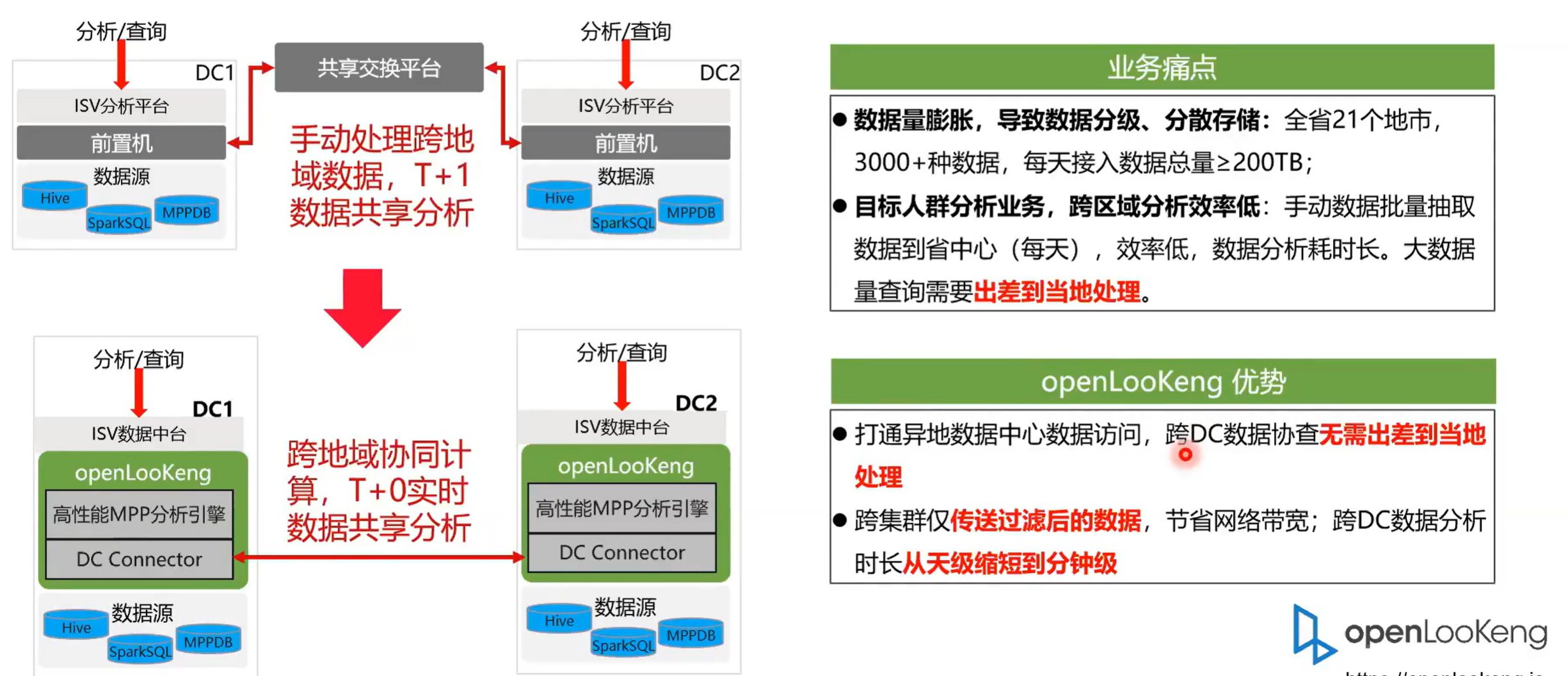
2.3 融合分析:跨DC联合查询,更强的数据分析能力
第三个场景就是跨 DC 的融合关联分析。之前的话都是一个手动处理的一个模式,然后它是 T +1 的一个数据分析能力。然后通过openLooKeng的 DC connect 我们可以实现的一个 T +0 的实时的共享分析能力。那比如说他当前的新的一个业务痛点就是数据量膨胀,导致数据分级分散,存储各省二十一个地市 3000 多的数据源,每天接入的数据总量大于 200 TB ,分析目标人群,分析业务跨域分析效率低。
通常的话我们是需要把数据手动的导入到需要访问它的一个DC 里面去通openLooKeng的 DC connect ,无需人工的去搬运数据,然后同时通过openLooKeng DC connect 提供的比如说算子下断点续传以及数据压缩并行传输等特点来提升跨域的一个访问能力,把之前的从天级别的分析速度提高到分钟级的一个分析能力。
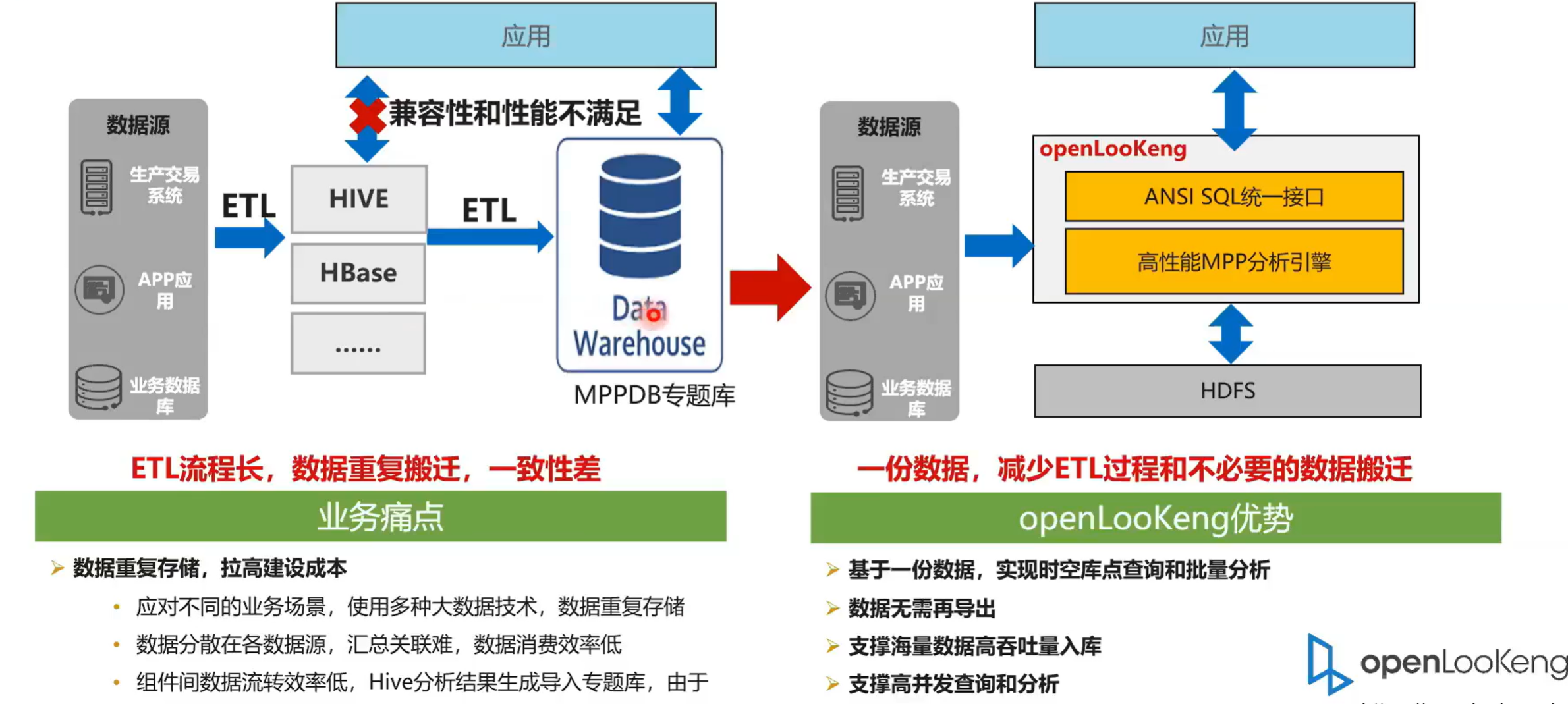
2.4 融合分析:一份数据,节约存储成本
以前有一个典型的流程就是生产数据经,首先是流到 Hive 或者是流到其他系统,然后再流到一个专题的数据库里面。比如说 Oracle 、mppdb这种的话,一个典型的特征就是 ETL 流程长,数据重复搬迁,一致性差。同时有个很大的业务痛点就是提拉高了建设成本。
然后通过openLooKeng引擎我们也看到就是数据只需要录到一个数据源中,然后通过openLooKeng的跨源跨域的分析能力,这样的话数据在数据源中只会存在一部分,也存在一份数据,减少了 ETL 过程和不必要的数据的搬迁。
3. openLooKeng架构解析和关键特性
下面一张图就是显示了openLooKeng的一个典型的架构。首先openLooKeng是一个典型的mppdb 的结构。你它是由 coordinator 和 worker 组成的, coordinator 是负责接收应用层来的 SQL 然后经过他的执行优化再通过他的调度把任务调度到 worker 上去执行。同时每个 worker 是负责整个 SQL 的一部分的数据。然后底层的数据源通过 data connect framework 的方式接入到数据源里面来。然后 data connect framework 提供了两个很重要的接口。一个就是分片的机制就是你要告诉 connector 数据是怎么分片的,从而实现了分布式并行处理的一个能力。第二个就是告诉我数据是怎么读取的。其实 connector 就是要告诉引擎就数据是怎么分片的。
第二个就是数据是怎么从你的数据源里面读取的。比如说我拿一个很简单的例子,拿 Hive 举例的话,就是它首先会告它的 support manager 就是我们的分片的管理的一个模块,它会告诉openLooKeng引擎我的数据按照DFS block 的大小来调度它。通常一个 block 可能会比较大,可能会按照四分之一个 block 也就是 32 道或者是 60 道的单位来进行一个调度。引擎告诉 worker 在执行的时候怎么去获取这个数据。然后针对于 Hive 数据源的话,它其实就是通过访问文件的方式。首先它会从 HMS 去获取它的元数据,获取它元数据之后就知道它存储在 Hive 哪个地方。这样的话 worker 在执行的时候就会去用 three reader 去解析这个 strip ,然后 strip就解析里面的 strap,这样的话就是可以对数据进行一个分析。图中另外还显示了一个就是跨 DC 的能力。
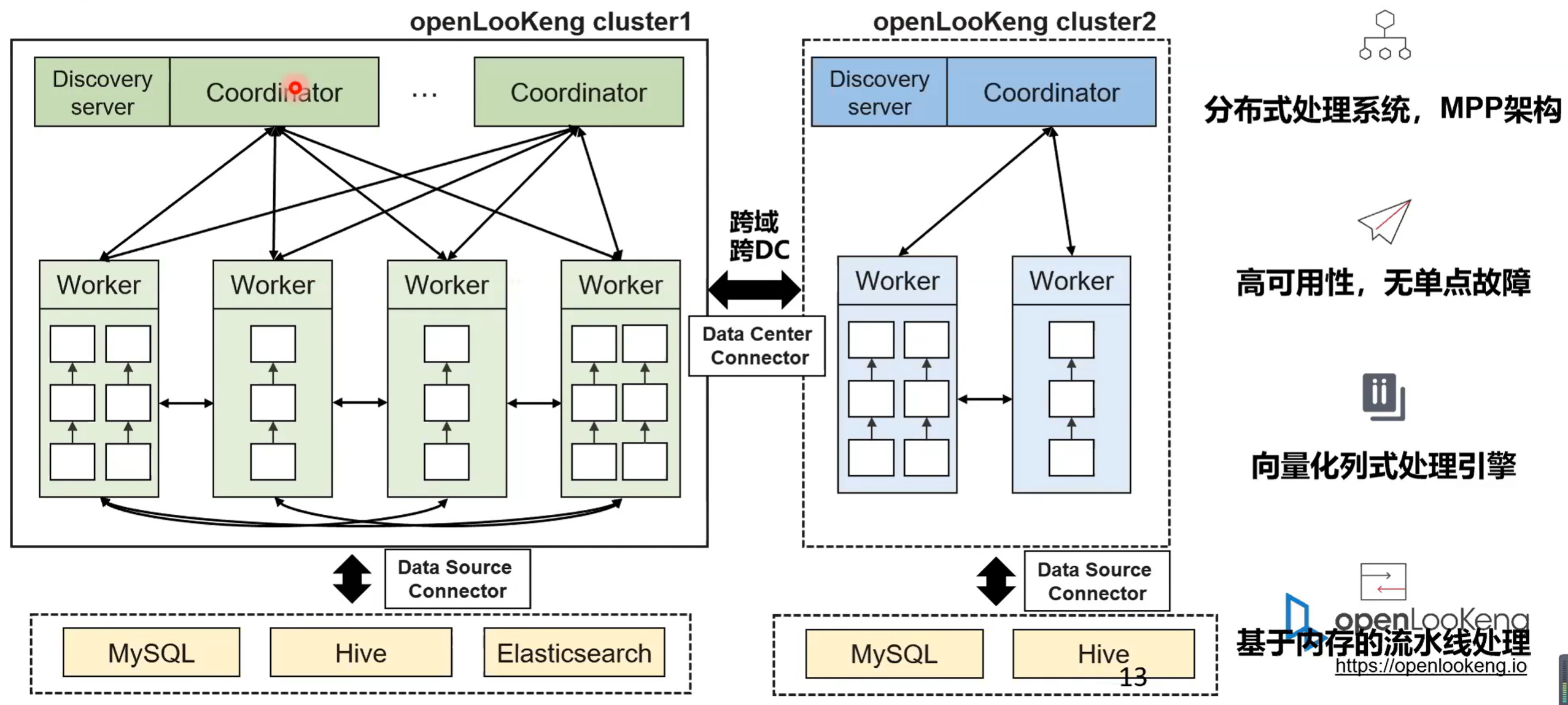
DC connector 走的是 JDBC 的方案,openLooKeng是一个典型的 MPP 架构,高可用无,单点无单点故障。因为之前 codinator 是单节点的,现在我们已经实现了 codinator 一个双活的特性。然后openLooKeng是一个向量化的存储引擎,是基于内存的流水线处理。相比于 Spark 的话,它是一个基于内存的完全的 pipeline 的一个处理引擎,这也是openLooKeng相比于 Spark 性能有提升的一个重要的原因。
3.1 openLooKeng关键技术概览
openLooKeng重要特征,一个就是索引。索引的会创建一个外置索引,我们提供了 create index 等命令,让用户去根据需要去创建比如说 mini max brow failed bitmap 以及 B +树这种索引。然后在数据读取的时候,我们会去用这用索引去过滤分片,同时也可以用这种索引去获取。
另外一个是动态过滤。在左右表作用的时候,通过把右表的列建立一个 felt 去过滤左表的数据,这种效果其实特别的明显。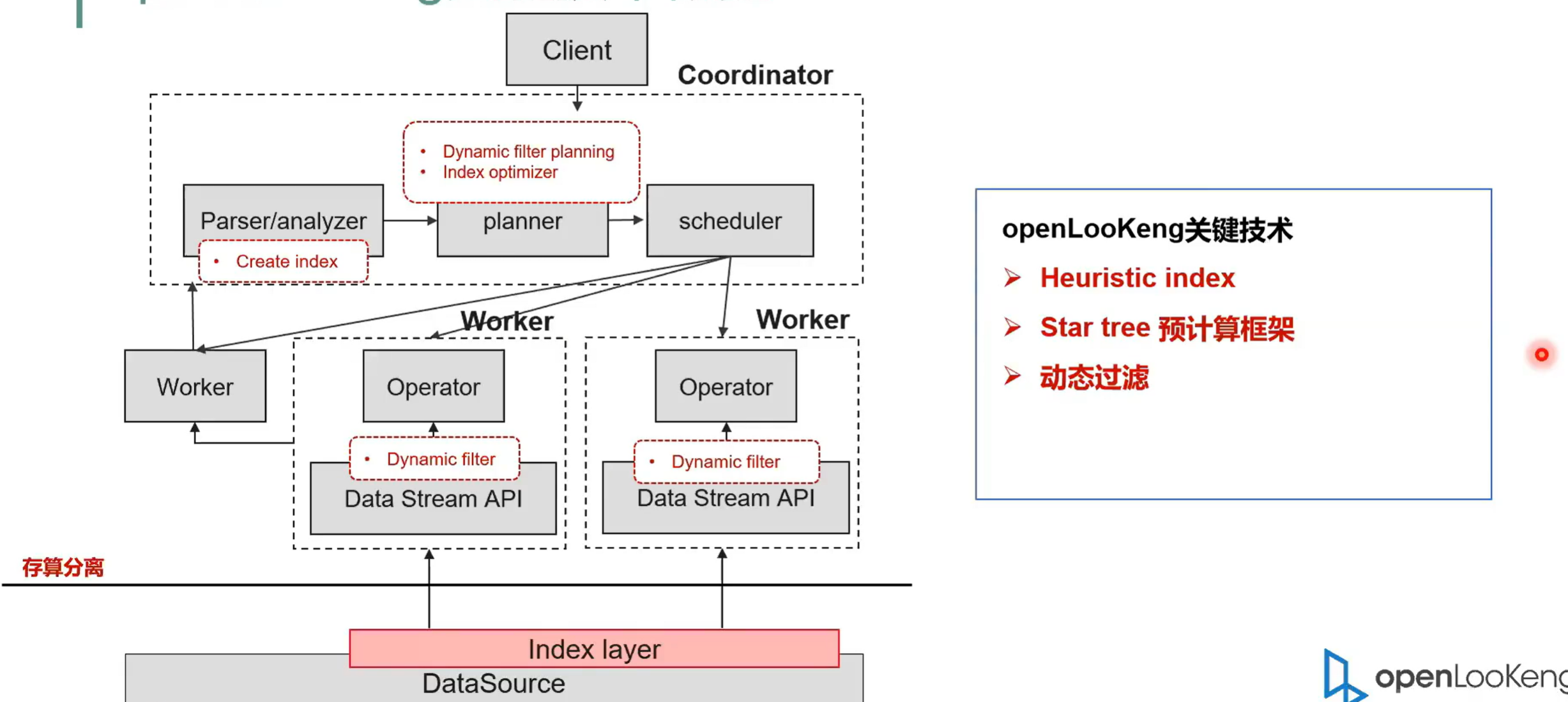
3.2 高性能:对标PrestoSql*,源自开源,领先开源
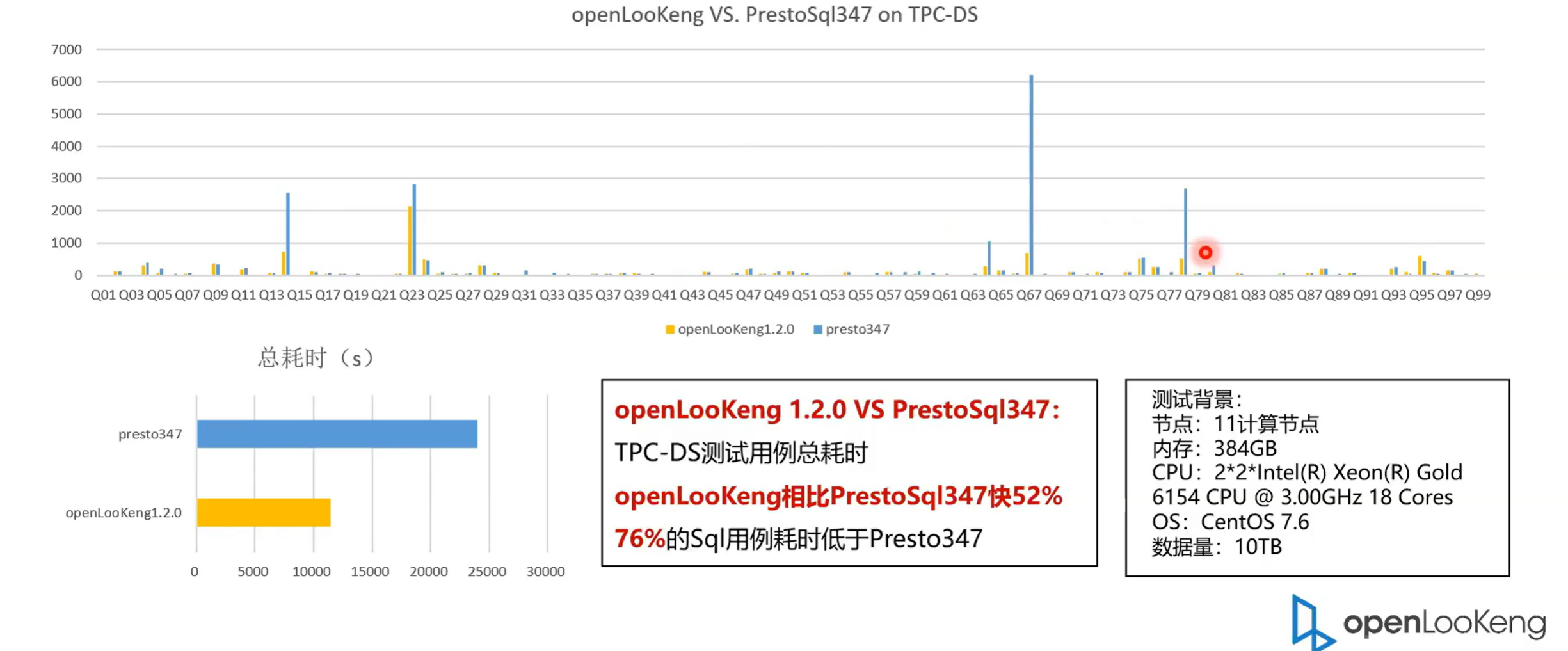
openLooKeng引擎相对与其他引擎的一个性能的优势,对标的是 PrestoSql,源自开源,领先开源。我们当前是用的是十一个节点,每个节点是有238 G 的内存,CPU 的特征列在上面,大家可以仔细看一下,然后测试的数据集是 10 TB 的。我们首先我们可以看一下整体的耗时。 openLooKeng 是用了大概 11,000 多。然后是然后 PrestoSq 347 是用了将近24,00。也就说openLooKeng 1.2 相对于 PrestoSql 347提高了52%,其中有 76% 的 SQL 用时使用率是低于 PrestoSql 347的。可以看到一些典型的,就有有一些 SQL 是体现的很明显的。
3.3 高性能:对标impala*,性能领先
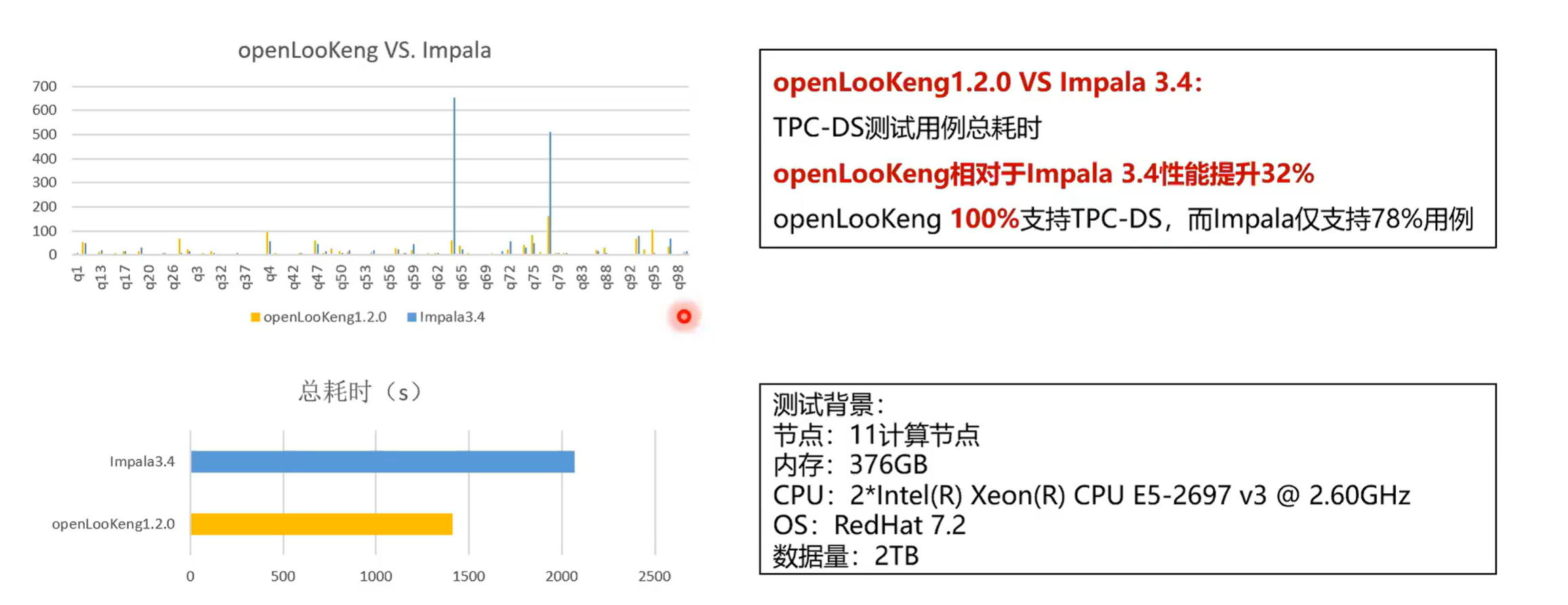
第二个就是对标impala,可以看到它整个的环境还是和之前一样。是十一个节点,内存稍微小一点,数据量是2 TB。首先看一下它的整个的延时openLooKeng 大概在 1400 秒,然后impala是在 2100 多秒。openLooKeng 是对 tpc-ds 是 100% 的支持的,impala它仅仅是支持了78%,它有一些算子是不支持的。
3.4 高性能:对标spark 2.3.2
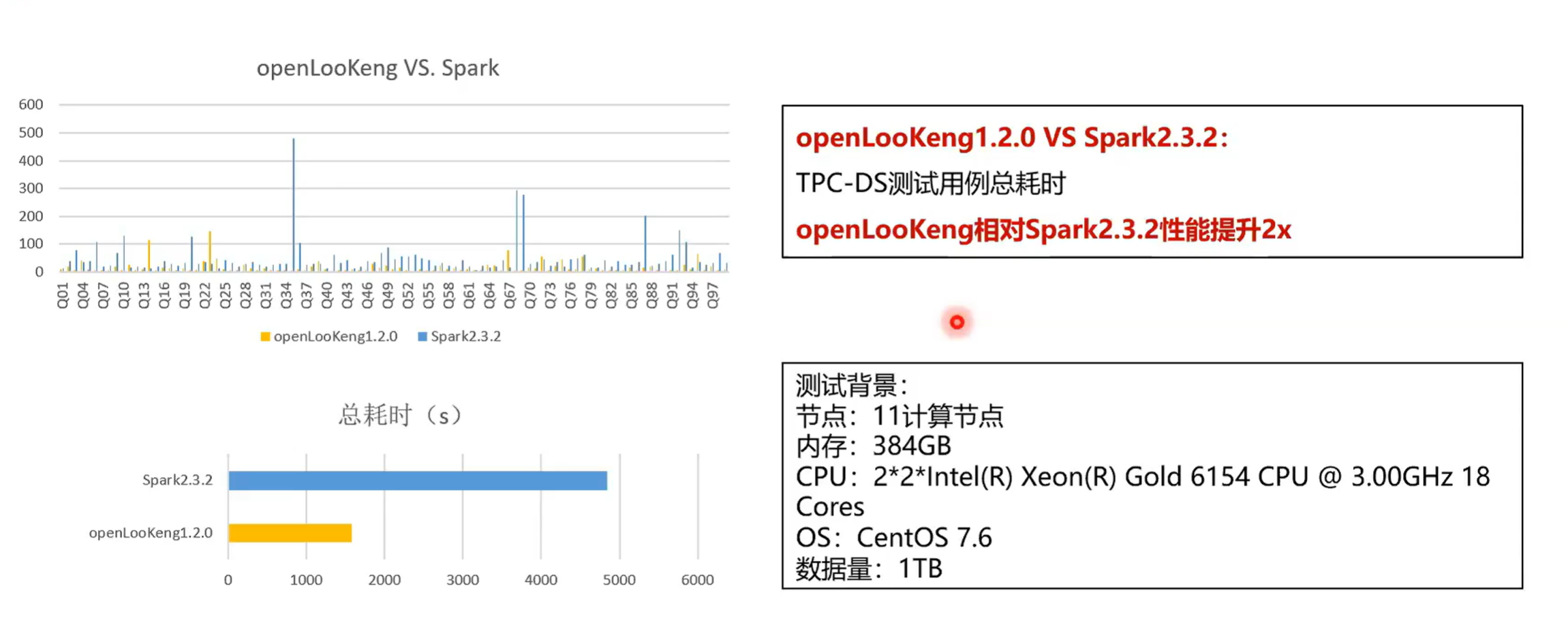
再看一下对标 Spark2.3.2,是同一个数据集群,然后测试数据集是 1 TB。openLooKeng 的用时大概是 1600 秒,然后 Spark 用时大概是在 4700s。其实相对于 Spark 的话openLooKeng 相当于有两倍的性能提升,其实这个性能提升还是很好理解的,因为本身 Spark 它是一个基于 stage ,然后每个 stage要等待上一个 stage 所有的 task 执行完。
3.5 OmniRuntime: the Foundation for High-Performance Data Analytics
openLooKeng当前正在做的一些优化,runtime 就是现在针对于所有引擎就是做一个 CA comment big data ,简单来说就是一个 native 的 code 键的一个执行环境,用于减少CPU 指令。
看到整体的之前的话,相对于之前的话我们有优势的话就是之前PrestoSql spark Hive它都自己在做这种 local optimization ,然后我们的目标是实现一个统一的,就是可以供所有人应用的一个 big data 的 runtime 。
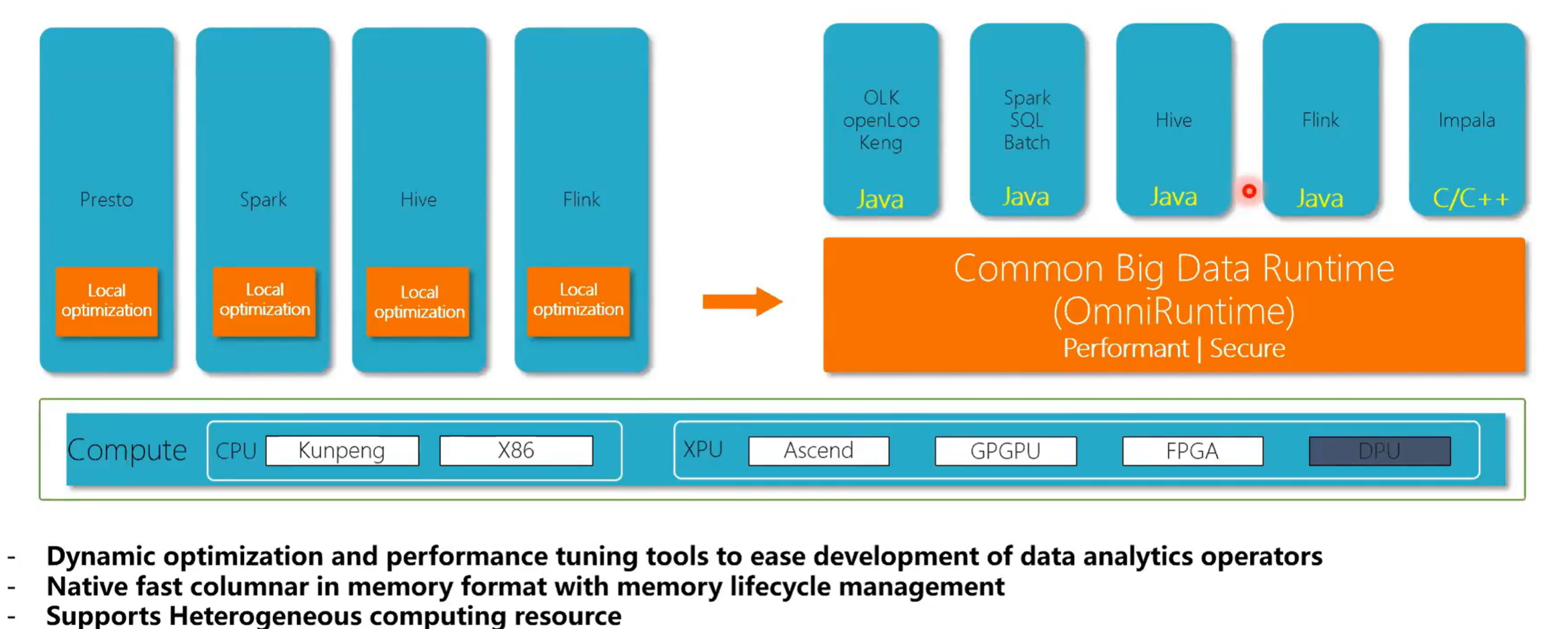
3.6 OmniRuntime:Analytics Operator Ecosystem
OmniRruntime 主要也就是包含有四个部分,然后一个就是Omni flex ,第二个部分就是 Omni operator ,第三个部分就是Omnicache ,然后第四部分是Omni change,在这里主要是介绍一下Omni vector 还有 Omni operator ,Omni vector就是在内存中的一个数据存储格式,就是数据在内存中是怎么表示的。Omni operator就是我们用 C++重新写了一个算子。
Omni cache 现在还正在设计,omni change 是一个兼容 RDMA 和 TCP 的一个传输传输方式。
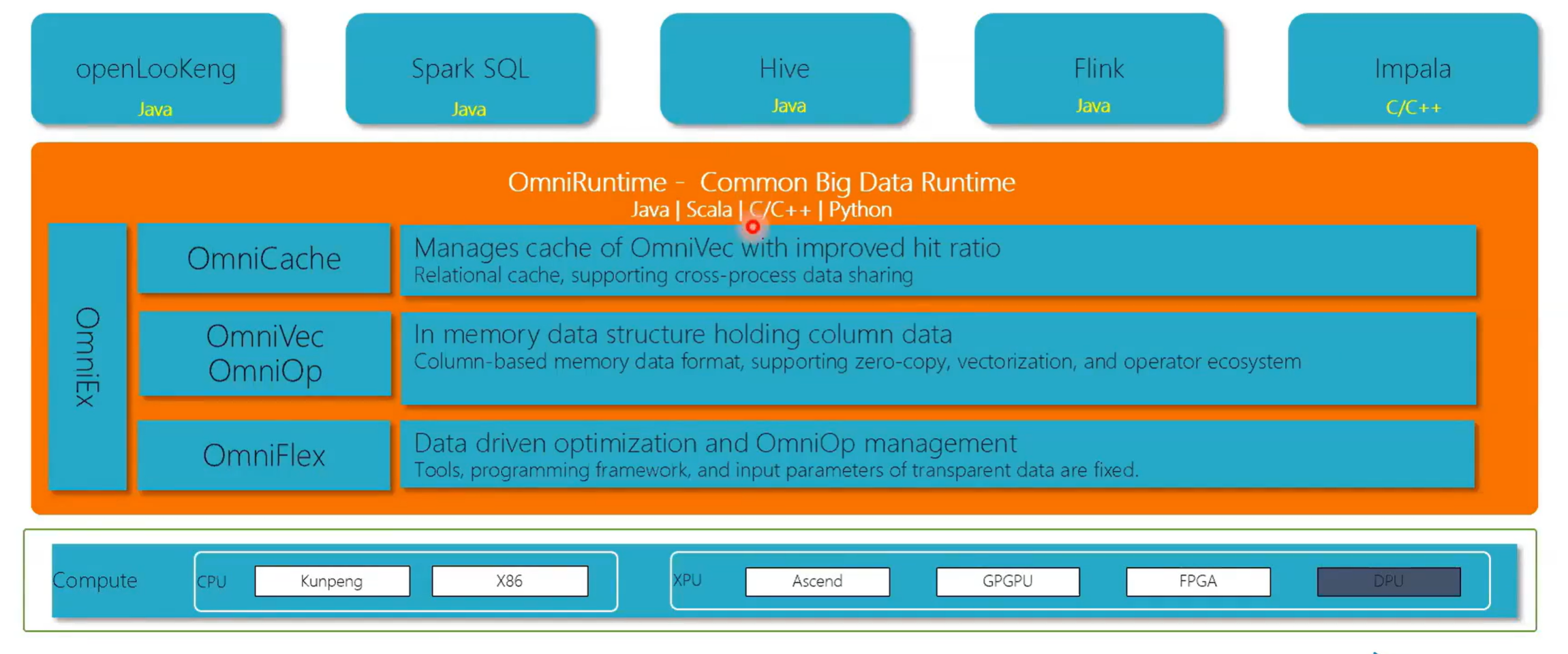
3.7 OmniRuntime: Performance Evaluation
首先是从 operator 级别,然后是端到端的一个性能提升,可以看得出来就是在算子级别,OmniRuntime:提升的还是特别的明显的。举个例子,就是 filter hash X 其他都是有数倍的提升,最大的提升可能有 10 倍,但是单个算子在整个的 SQL 中的占比会比较少。比如说整个 SQL 中 hash贡献只占了20%,那最多也就是提升 20% 。我们可以看一下单个就是针对于端到端的一个性能提升, tbch 的Q1,可以看在一并发和四并发以及十发的时候,它大概都有 30% 左右的一个提升。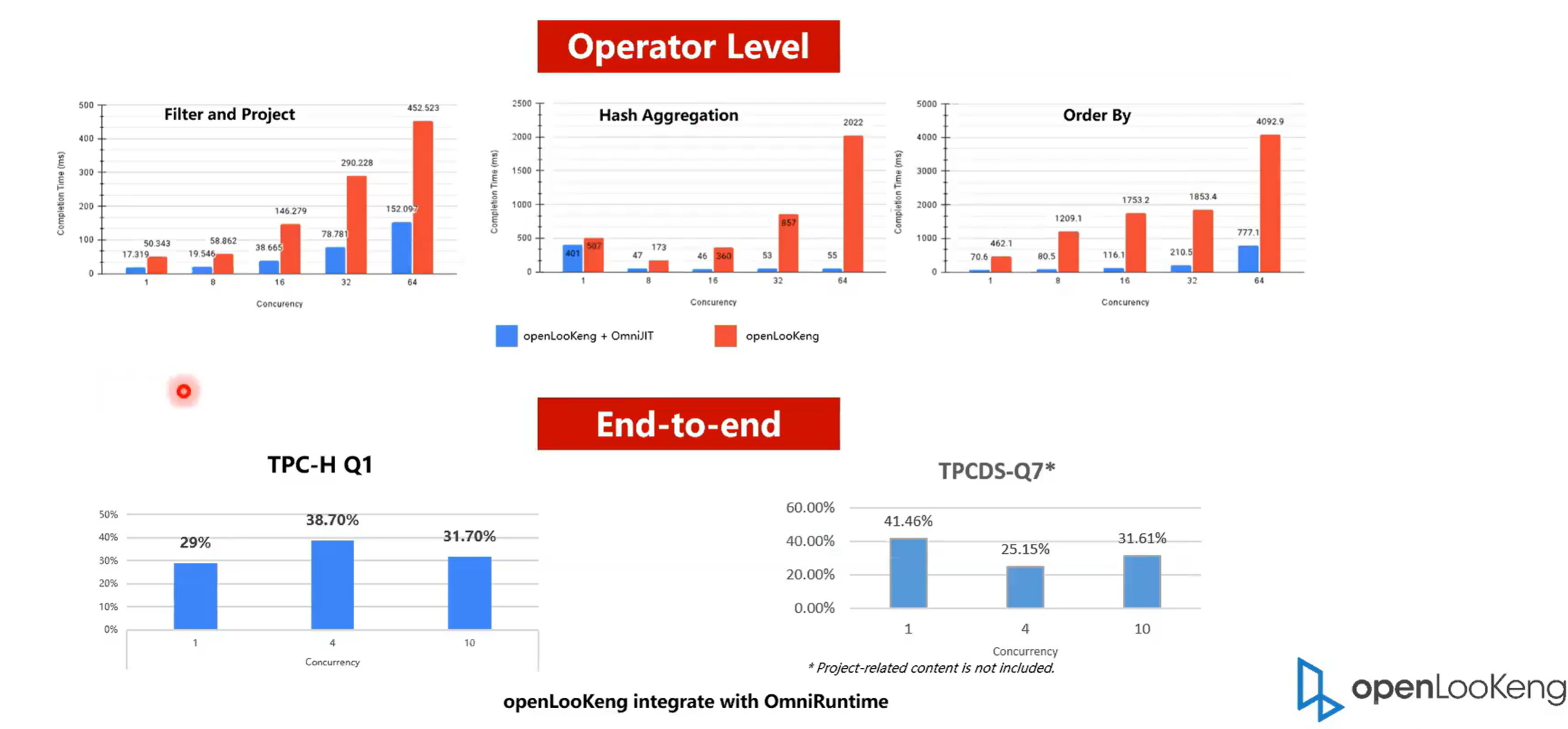
3.8大数据OmniData算子
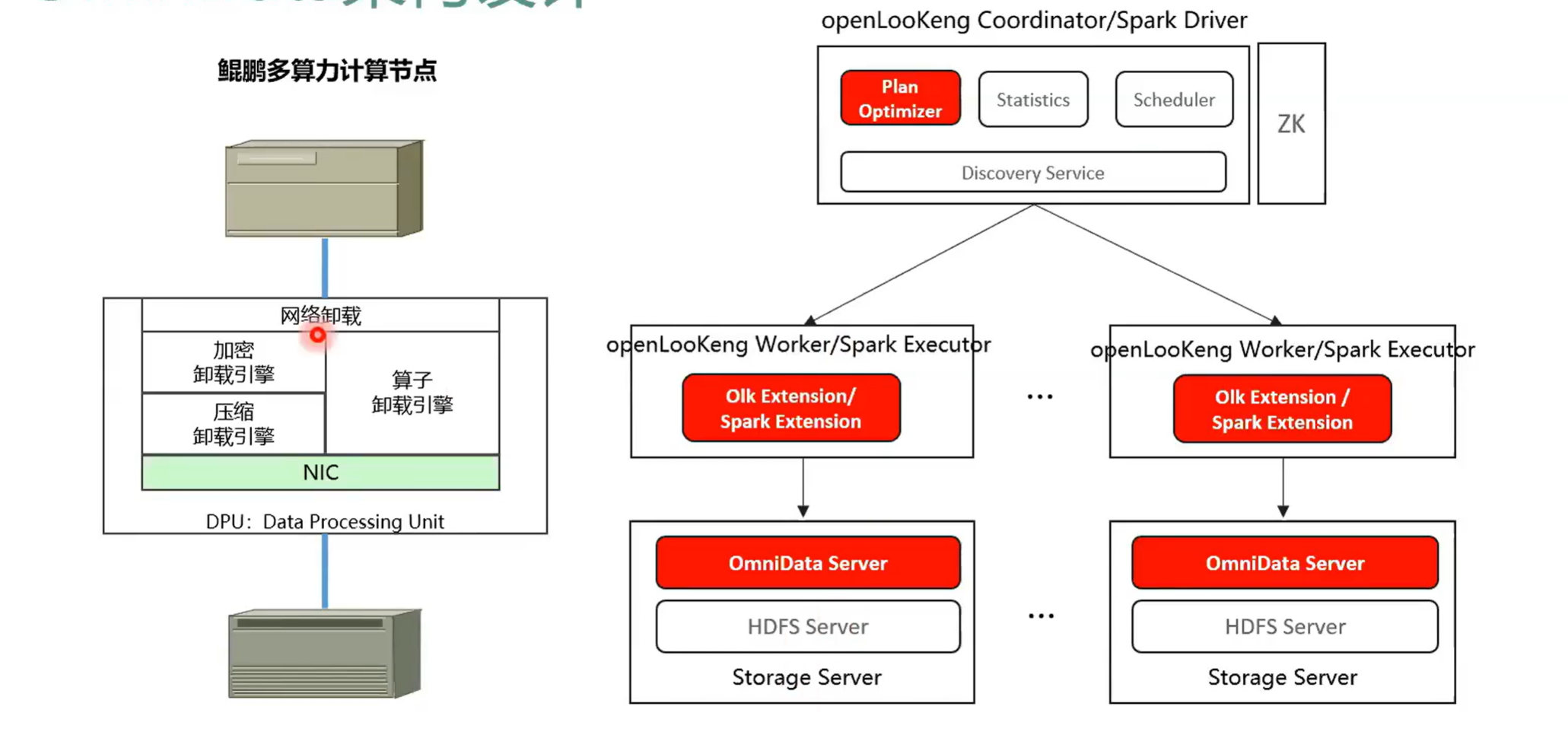
下面介绍是OmniData数据计算,就是比如说我们现在要做一个数据分析,通常我要去分析一个表,然后通常我们会带那种过滤条件,然后我从下拿 8 亿行的数据,然后通过OmniData推到数据存储端去计算。原理就是一个 NTP 的数据计算的一个原理,就把数据的把算子把能够推的算子推到进数据端去执行。然后我们可以看到它最终上来的数据只有 78.7 万行,然后执行时间从之前的 3800 多秒下降到了 2084 秒,这个是在我司的一个真实的案例。
ominta 本身的一个目的就是把算子以及它的加解密以及它的解压缩这些算子推到存储团存,推到存储的 CPU 或者是 DPU 上去。因为现在 DPU 也其实一个很火的概念,大家很多公司都在做,然后就是把用多就是用多出来的算力减少,从而减少那个 C 现在以 CPU 为 CPU sentry 的那种结构模式,架构模式 of 缓解 CPA 的压力,本身 DPU 上可能还会带有那种解压缩或者是加解密的引擎,从而我们是应用上硬件的能力来加速整个 SQL 的执行。这样的话我们可以看出在右图我们可以看出是以它的一个整体的架构。我在这里画的是一个纯算分离的场景,就是在 open log 它是由 coinator 就是这个框和 worker 这两个组件组成,然后存储端是 HDFS 集群。然后我们可以看的就是我们红色的部分代表我们的一个修改我们增加了一个 omindata server 这个 omedata server 其实就是用来管做算子下推的。然后同时我们会在执行计划层做一些修改。因为我们现在的需要把算子下推到 admin data sever 里面去。所以我们在执行计划优化的时候会去识别哪些算子能够适合下推。比如说我们会根据算子的选择率,把算子选择率就是把算子最终的选择选,把算子选择率低的推到面对实验我去。比如说之前我这个表是 100 万行,我过滤之后只有 1 万行,选择率就特别适合推送到数据端去执行。
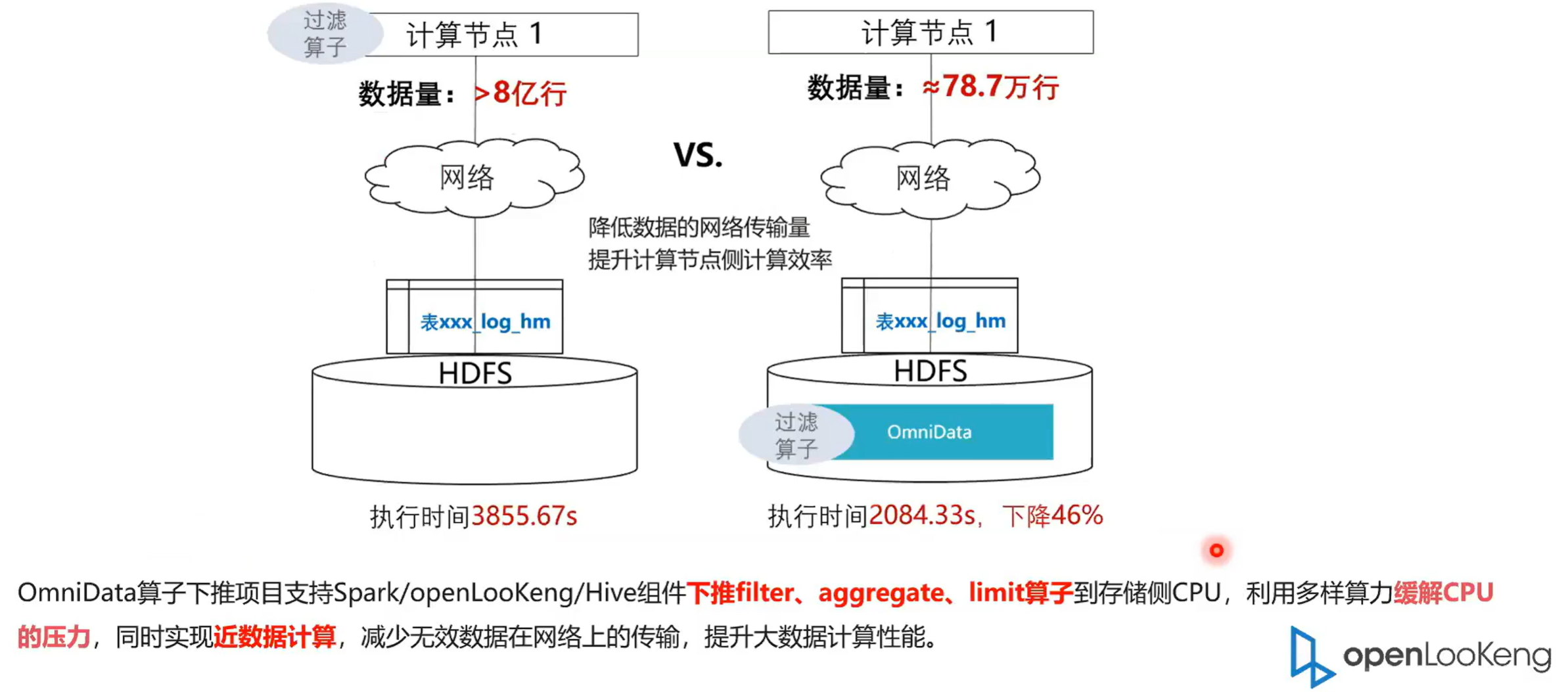
3.9 OminData架构设计
OminData本身的一个目的就是把算子以及它的加解密以及它的解压缩这些算子推到存储的 CPU 或者是DPU 上去。从而减少现在以 CPU 为 结构的模式,本身 DPU 上可能还会带有那种解压缩或者是加解密的引擎,从而我们是应用上硬件的能力来加速整个 SQL 的执行。
这部分已经产品化了,然后在鲲鹏的 support 网站上已经发布了。一个很简单的总结就是openLooKeng下推项目前就是一个同时支持 Spark Hive 组件下推 来缓解 CPU 压力,实现净数据计算,减少数无效数据在网络上传输,从而提升整个大数据。
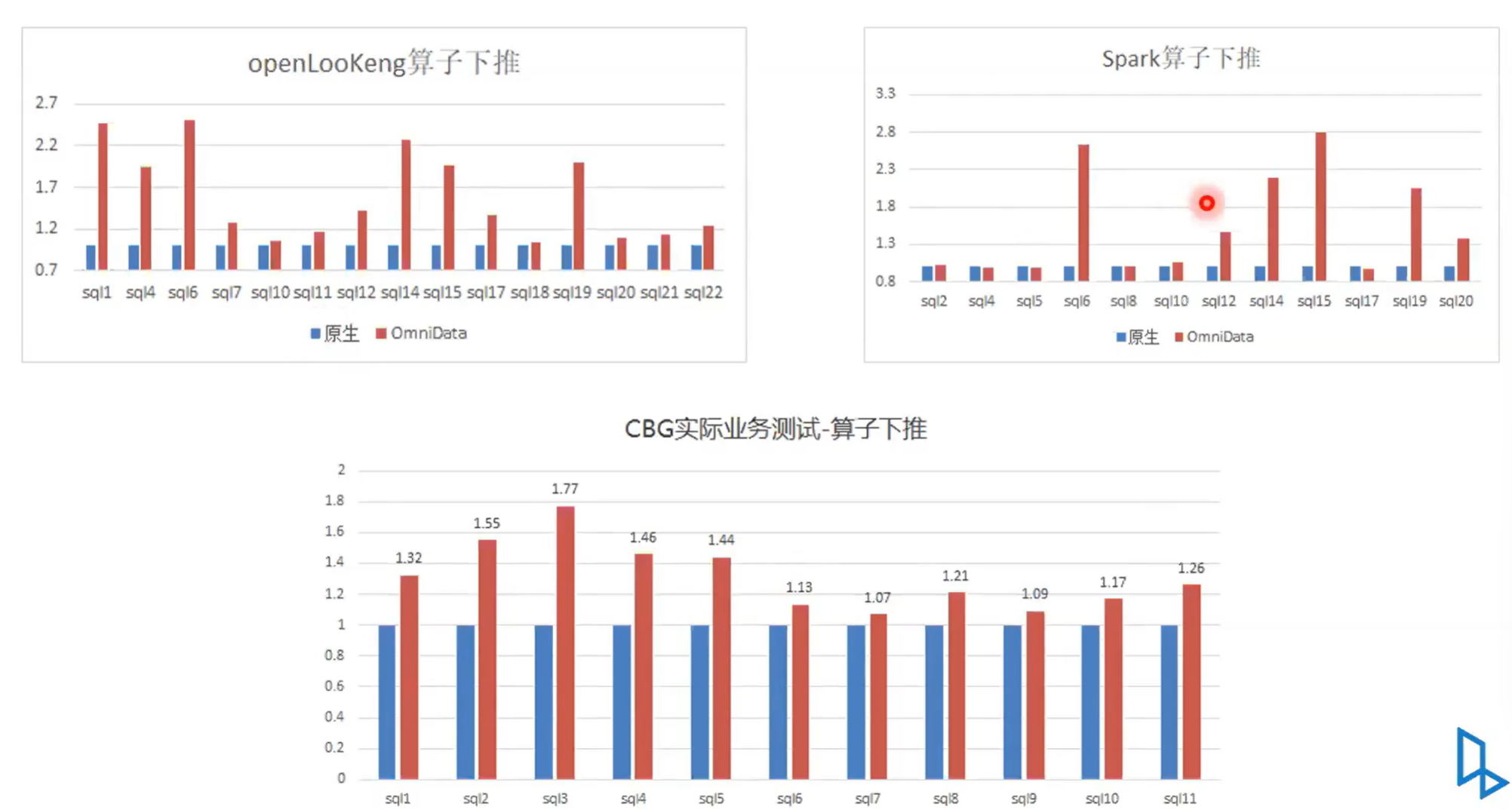
3.10 OmniData: Performance Evaluation
接下来我们可以看一下就是OmniData性能,左侧是openLooKeng引擎,右侧是 Spark 引擎,然后这个是在 实际业务上测出来的。我们可以看出整体上提升的效果还是挺明显。无论是 Spark 引擎还是openLooKeng引擎。接下来是在实际的业务中一个性能测试,性能是归一化的。
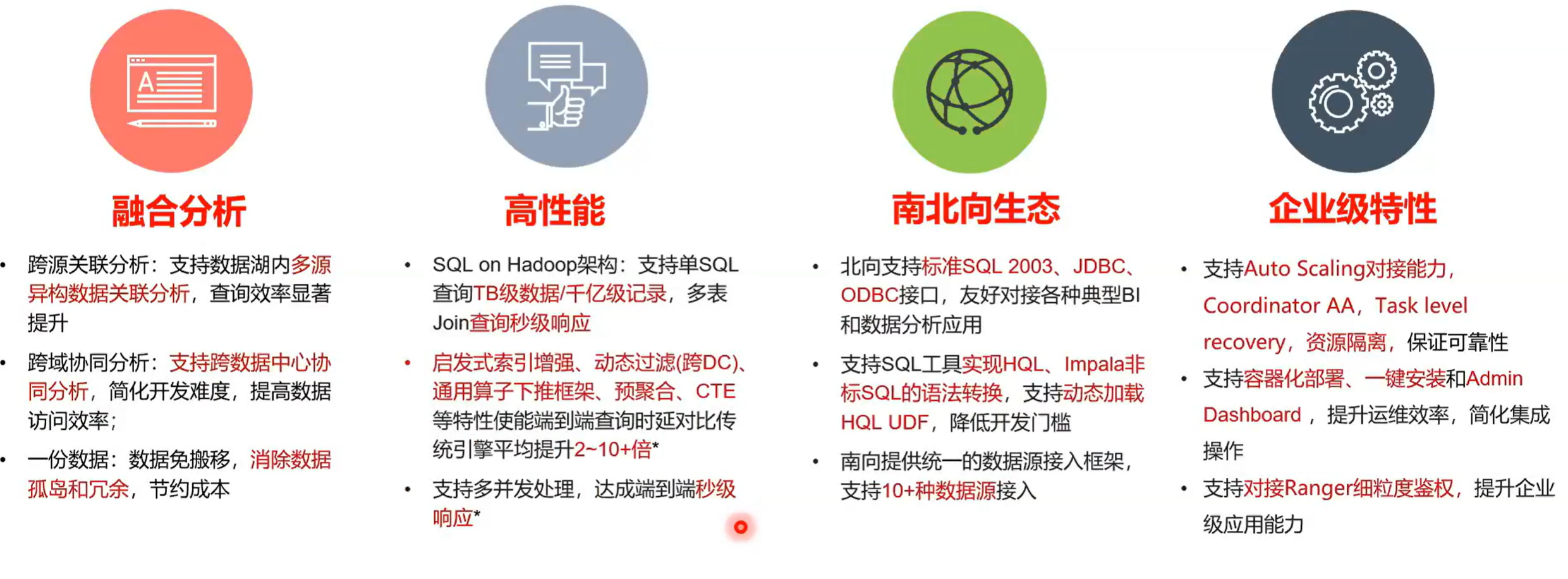
3.11 openLooKeng的四大优势
总结一下就是 openLooKeng有四大优势,一个就是融合风险,就是跨源,还有一个就是跨域。然后第三个就是一份数据,而第二个部分就是高性能。通过我们新增的一些特性,比如说动态过滤、启发式索引算子下推聚合 cte 等特性,从而提升 SQL 查询端到端的时延大概提升两到十倍。
第三个部分就是南北向生态向北向统提供一个统一的访问层,就是 SQL 阶段 SQL 2003 的一个语法。然后向南向提供了一个 connect framework 可以实现解数据的快速接入。
第四部分就是企业级的特性,就包括 autoscanning ,autoscanning 就是 worker 的动态伸缩,我们会根据 worker 的繁忙程度来动拓来动态的升增加或者减少。然后第二部分就是 coordinator 的 AA 就是实现了 coordinator 的双活,任一个 connect都可以接受任务,下发任务到 worker ,然后第三个就是 task level 的 recover 就是任务级别的恢复。第四个就是资源隔离。
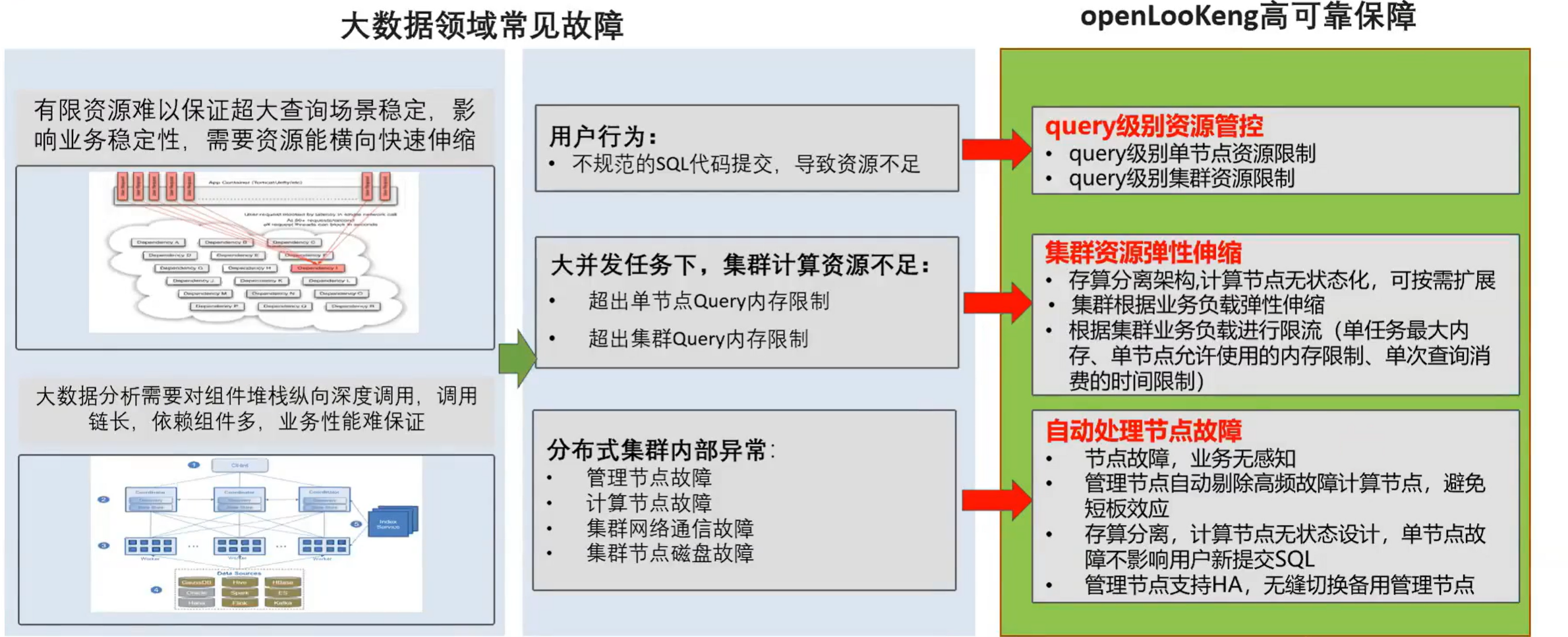
3.12 高可用:坚如磐石般的“数据库”体验
openLooKeng在故障域的处理主要是分为三部分,一个是 query 级别的资源控制。就是可以对单条 query 的使用的资源进行一个控制。第二个就是集群资源弹性伸缩,,因为openLooKeng 的 worker 是一个无状态的,可以实现按需的动态扩动态的扩展或者是收缩,第三部分就是自动化的处理节点故障,然后节点故障是业务感知的。
4. openLooKeng开源策略及伙伴帮助计划
接下来给大家介绍的是 openLooKeng一个开源的策略以及伙伴帮助计划。
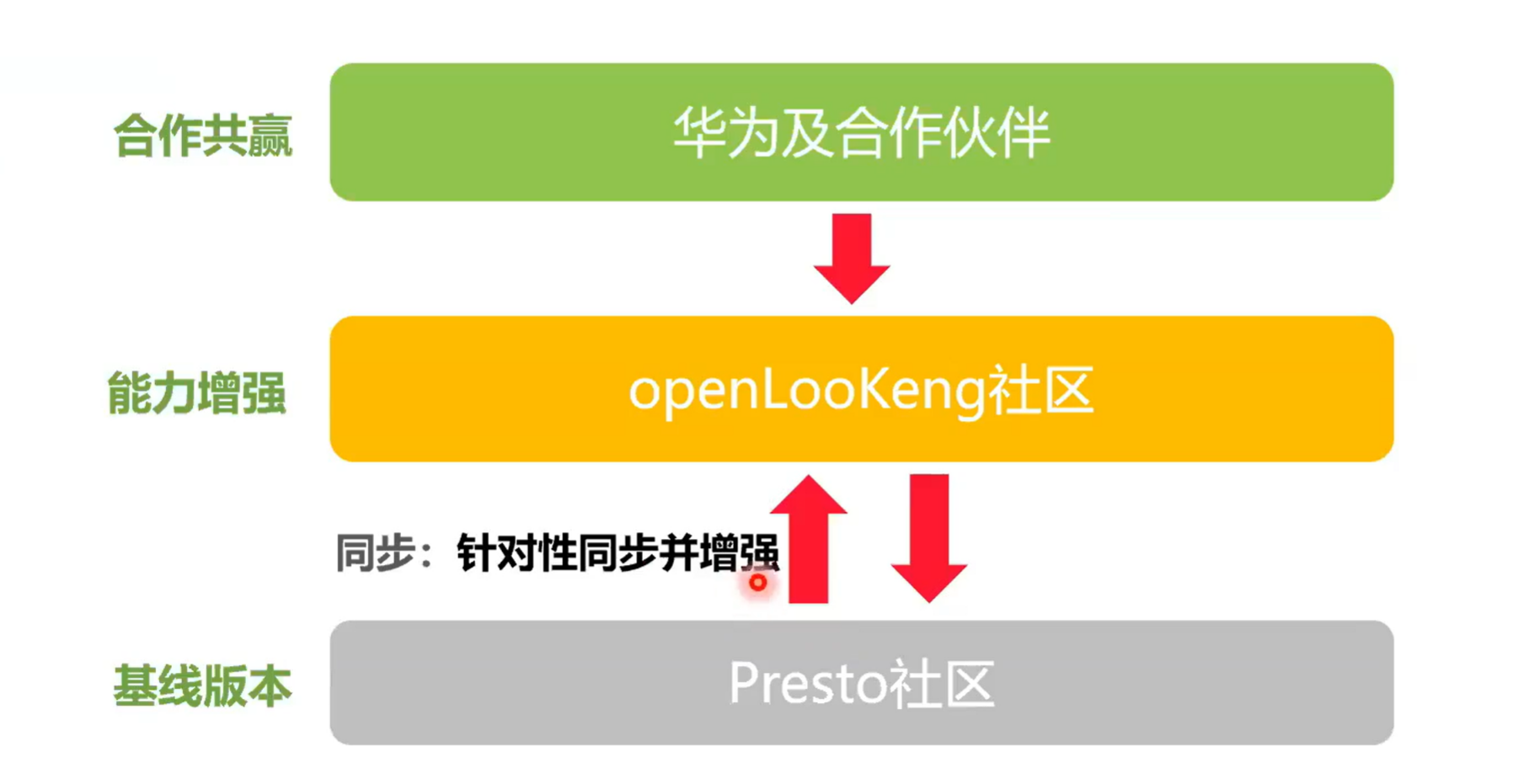
4.1 openLooKeng社区与Presto社区关系
openLooKeng和 Presto社区的一个关系是同针对一些大颗粒的特性会同步过来。同时会做一个能力的提升。我们是基于开源,然后就是超越开源,就是从基线版本会做一些很多的性能提升,实现能力的增强。同时如果有新的大颗粒的出现,我们会把社区的大颗粒特性根据需要。比如这个需求这个特性是很有必要的,我们会移植过来。然后第二部分就是其实也可以看到是社区也在应用openLooKeng的一些新的特性。而第三就是和合作伙伴实现一个合作共赢的一个目的。
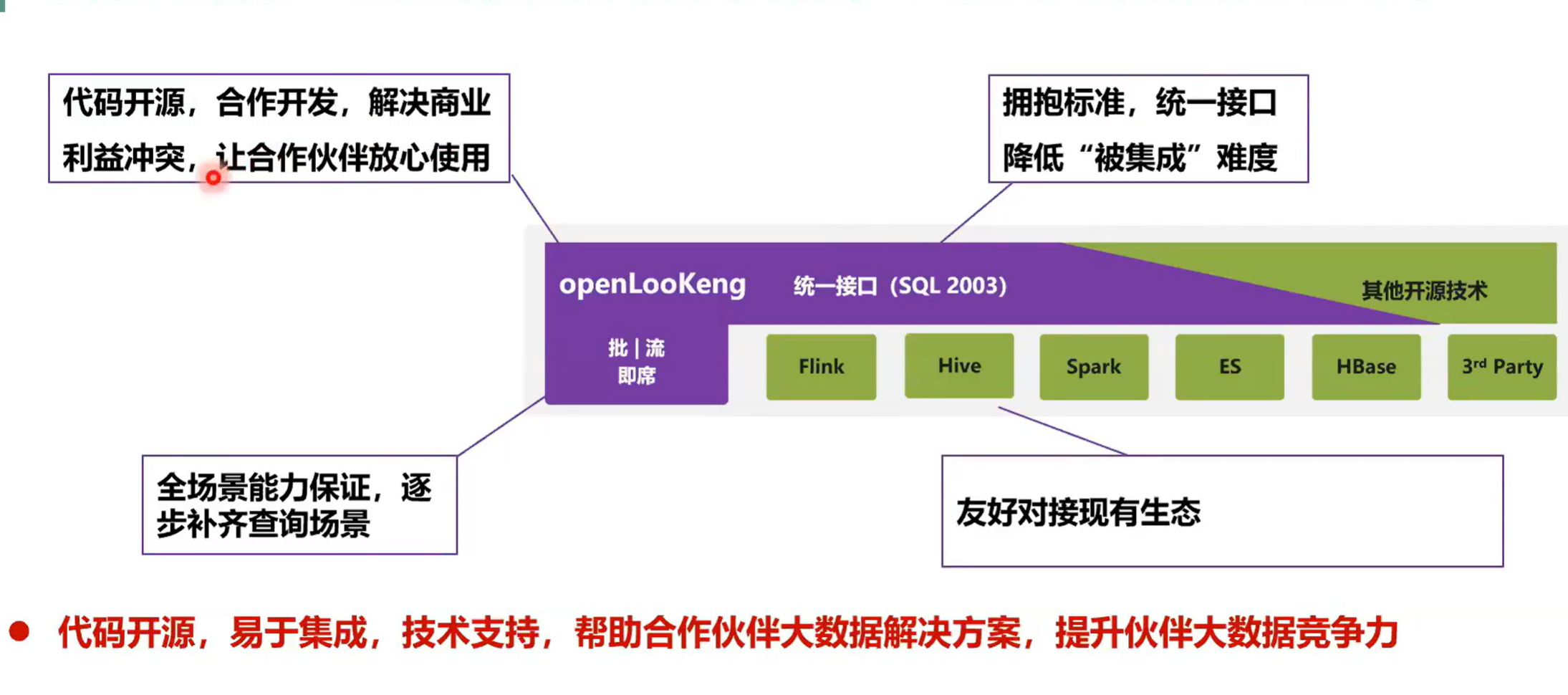
然后开源的一个策略就是持续使能伙伴共建大数据繁荣生态,第一个方面就是代码开源,合作开发,解决商业利益冲突,让合作伙伴放心使用。当前我们太原都是开发开放在那个 DT 上面,任何都可以去下载或者是通过 TPR 的方式给社区提做出贡献。
第三部分是拥抱标准,统一接口,降低被集成的难度。openLooKeng提供了一个 SQL 2003 的一个接口,就是估计大家使用 SQL 比较简单,然后大家都习惯于使用 SQL 来进行一个数据分析。然后第二部分就是全场景的能力。第三个就是全场景能力的一个保证,逐步补齐查询场景,第四部分就是友好对接现有生态。比如说现现有生现有的数据源中,我可以对它实现一个灵活的访问。+
总结就是代码开源,易于集成技术支持,帮助合作伙伴大数据解决方案,提升伙伴的大数据竞争力。
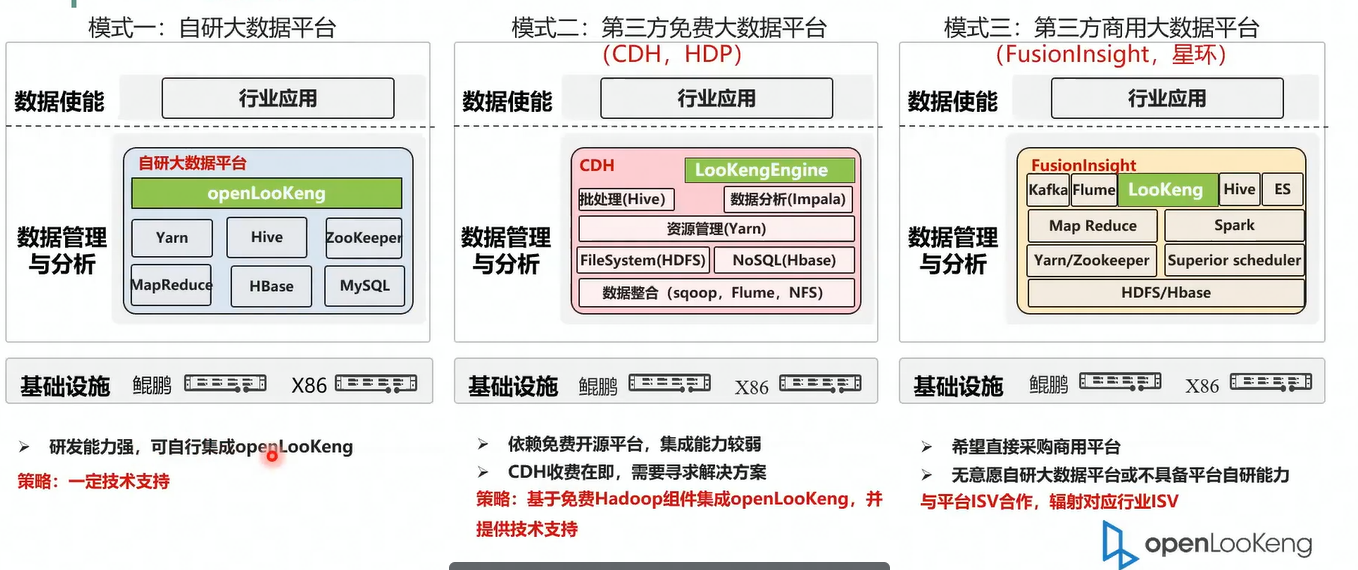
4.2 ISV对接模式
然后我们可以看一下 SV 的三个对接方式。第一种是自研的大数据平台,这种方式的话就是需要手动的去集成 OPPO 跟这样的话需要的 SV 能力状态的要求能力,能力的要求状态会比较高,它需要自行的去集成openLooKeng引擎,当然我们一定会给予基础知识。然后第二步就是基于现有的免费大数据平台,比如说 CDH 去集成openLooKeng引擎这个的相对来说就会相对来说比较简单一点,因为它本首先它的底层的组件都是一个开源的通过开源的组件构建出来的。然后本身openLooKeng也是开源的,然后底层的组件也都是基开源的。
第三个就是商业发行版,比如说华为公司与平台 ISV 合作,辐射对应行业ISV ,这三种模式我们都会提供比较大提供很大的技术支持。
华为测试会持续投入openLooKeng社区,使能数据伙伴,同时会在高校或是线下展开一系列的活动,让大家去更好的去了解openLooKeng。

5. 总结
本文介绍的openLooKeng是一种"开箱即用"的引擎,支持在任何地点(包括地理上的远程数据源)对任何数据进行原位分析。它通过SQL 2003接口提供了所有数据的全局视图。openLooKeng具有高可用性、自动伸缩、内置缓存和索引支持,为企业工作负载提供了所需的可靠性。
openLooKeng用于支持数据探索、即席查询和批处理,具有100+毫秒至分钟级的近实时时延,而无需移动数据。openLooKeng还支持层次化部署,使地理上远程的openLooKeng集群能够参与相同的查询。利用其跨区域查询计划优化能力,涉及远程数据的查询可以达到接近“本地”的性能。
本文参与华为云社区【内容共创】活动第17期。
https://bbs.huaweicloud.cn/blogs/358780
任务15:openLooKeng ,一款面向海量、跨 DC 的大数据分析利器

- 点赞
- 收藏
- 关注作者
评论(0)