网络智能运维助力运维效率提升

作者:童琳
云服务数量的增长,带来了开发效率提升、运维成本降低等巨大价值,极大提升用户的便捷性,牵引着越来越多的传统业务都在向公有云转移。网络作为连接万物的基础,其稳定性对云上业务至关重要。Cloudscope公有云运维产品因云而生,其中的网络运维服务从设计之初瞄准网络运维自治能力,沉淀了从数据底座、监控告警、诊断分析、自动化能力展开的等一系列网络领域的平台能力,为公有云业务稳定性保驾护航。
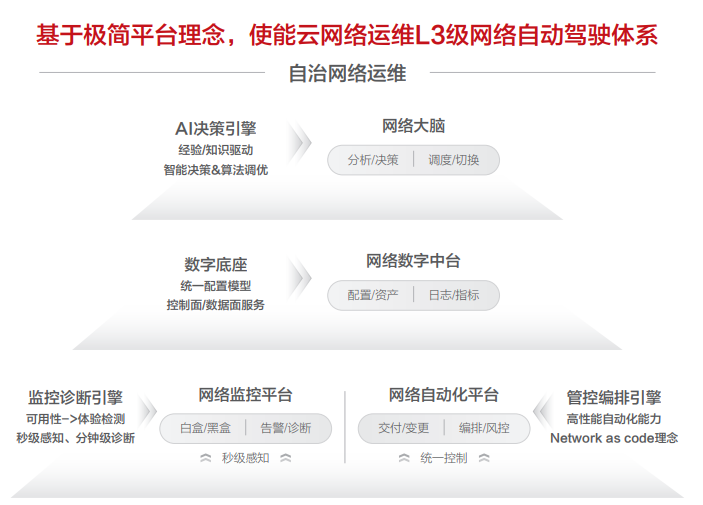
网络自治打造智能运维技术之巅
网络监控平台:监控系统作为云的眼睛,其敏锐度、视野广度都非常重要,故障慢发现1min可能对上面运行的业务来讲损失都是巨大的。对于故障,发现不是最终目的,而是要快速恢复来降低MTTR,快速高效的故障诊断有利于故障的快速恢复;
网络自动化平台:业务发展过程中存在着大量的网络交付、变更、优化整改等场景,人工 vs 自动化不仅仅是效率问题,交付时间越短意味着库存可以压缩的越低,最终节省了大量成本。在自动化平台中我们构建了一套安全可信的自动化编排引擎,上面可以承载了网络交付、变更、自愈以及诊断等任务可以编排的场景;
网络数字中台:数字化程度决定了运维、运营团队的运作效率,无处不在的流程、故障warroom需要完善、实时准确的数字化来支撑问题分析、决策动作,在华为云我们构建了丰富的的数字化能力来支撑不同场景的业务;
网络大脑:网络大脑是整个网络运维平台的核心,其中承载了大量的AI算法库、知识经验库,在运行过程会结合数字中台的配置、监控、状态等数据进行分析决策,通过自动化平台实现故障切换、自动隔离、路径调度等智能化场景能力;
以数据驱动业务,沉淀孪生网络数字中台
为了支撑网络运维业务的快速发展,我们分层、分领域来构建数据的平台化能力,将不同类型数据存储在不同介质中来满足业务场景化需求,例如监控数据以时序数据库为主、OLAP关系型数据(多维实时聚合场景)为辅,资源、配置数据则使用关系型数据和文档型数据库存储,数据间的关联关系、拓扑等数据保存到图数据库中,方便迭代遍历操作。
资源库是网络运维的基础,其涵盖了基础设施网络的设备、链路,也包含虚拟化网络的集群、实例对象等,为了维护这些数据的实时性和准确性,在其上有一套完整的交付、巡检验收、入库、维修、下线等流程系统来支撑资源的生命周期管理;
规划库用来指导网络交付建设,作为网络运行的基线配置库,包括广域网基线、数据中心基线、设备级配置基线等,一旦现网配置偏离基线配置将进行告警,并尝试有限程度的自动修复;
现实库顾名思义代表着现网,我们定位为生产环境网络运行配置的真实反应,为了让数据格式高度统一,针对不同厂商设备我们进行了统一建模抽象,然后通过周期全量采集、叠加事件驱动实时触发来保证关键配置的准确性,这样上层各种自动化工具就不需要频繁去查询底层设备的配置;
转发库涵盖了网络流量转发的核心表项,在流量路径分析、网络仿真、验证方面起着至关重要作用,目前受限于传统设备的技术和性能约束,一般只能按照天级来采集。当然,像BGP这种路由表我们是可以通过BMP这些协议来进行实时采集。
状态库之所以独立出来建设,是考虑到状态的实时性、准确性非常关键,无论是变更场景、还是故障隔离场景,如果状态判断有误,可能会触发更进大的故障;另一方面,核心状态库使用频率也非常高,目前我们已经把业务故障自动化处理高度依赖的接口、协议等状态优先构建完成了;
监控库是网络监控系统采集上来的数据合集,其中包含了采集的白盒指标、黑盒拨测等时序数据,这些数据用来支撑告警、诊断分析等场景化能力;
日志库对监控系统采集的日志进行格式化处理,便于各种场景消费使用,设备日志有设备以及协议运行过程中的关键事件,应用日志有云服务运行关键日志、以及访问的DNS、Ngnix等日志数据,这些数据在分析一些故障时候非常有用。

用确定性监控方案,应对不确的网络故障
一方面云上应用对网络性能诉求越来越高,从视屏业务<1ms诉求,到实时游戏<10ms,再到自动驾驶<1ms诉求等,要求网络监控频率越来越高;另一方面,云上网络服务软件快速迭代演进过程中会引入各种不确定性BUG和故障,对监控覆盖面提出了更高挑战;最后,云上网络流量路径复杂,给网络及链路的全路径监控和诊断带来了新的难题;
面对重重挑战,我们必须构建一套覆盖全面的监控体系能力,从基础设施层到云网络服务,再到上层应用对网络的体验的感知,都需要进行精确测量,确保覆盖完备性。
传统的白盒指标监控需要按照故障进行分类,提炼监控项,在网络不同层级关注不同指标,有助于确定故障的根因,因此每一层需要单独构建自己的白盒监控体系。例如物理网络层面需要对交换机、路由器、防火墙、波分、专线、互联网出口等进行详细监控;网络服务层则需要对各种网络服务产品、虚拟网关/集群、租户实例指标进行监控覆盖;应用层直接面向最终内部或外部服务,需要感知流量互访的质量和体验,例如内部RDS数据库的访问延时、EIP的带宽/延时等;

但如今云服务软件快速迭代、特性急剧增加、新服务层出不穷,白盒case by case的监控方案容易有遗漏的监控点,因此我们又构建了黑盒监控作为补充方案。我们针对Internet网络构建了全球运营商质量拨测平台,持续监测全球重点ISP和城市到华为云各站点的实时访问质量;针对基础设施网络层,自研高性能探针构建了分层pingmesh体系,来覆盖尽可能多的物理链路,每月可发现数十起网络微突发;针对网络服务层,构建了overlay层面的黑盒拨测系统,以最小的租户资源成本来尽可能全面的覆盖虚拟化网关/集群转发性能,也为虚拟化软件发布变更提供了实施监控的保障。
即使有了传统白盒及黑盒监控,还有一类问题难以监控到,就是局部流或者单条流访问丢包或延时增大的情况,因为传统白盒的监控粒度优先、黑盒拨测无法覆盖所有流,很可能无法感知。因此在华为云我们又构建了全流监控能力,利用分布式主机的计算能力,结合智能网卡对TCP的5元组流进行质量测量,快速发现流级异常。
除了监控能力之外,告警能力也非常重要,既要高的召回率,也要高的准确率。对于监控的各类数据,我们的告警利用了非常多的算法能力,除了离线训练和在线计算之外,也结合了部分人工经验,例如在日志告警中,算法挖掘的知识图谱结合了人工经验,使得日志根因告警准确率高达90%;另外对于黑盒监控类拨测告警,数据和网络拓扑关联分析,形成交叉精准定界能力;
在网络诊断领域,除了传统的自动化流统、抓包手段自外,还提供了报文头染色能力,该染色报文在经过路径每一个虚拟网关的时候,虚拟网关会上报该报文的出入端口信息、时间戳、五元组等信息,如果发生丢包还会直接上报丢包的根因,这将大大提升网络问题的定界或定位效率。
打造安全可信,开放高效的自动化体系
成熟的自动化能力可以大量节省人力成本、提升效率,也能避免人工失误,保障稳定性。我们将网络从交付、转维、验收、运维、优化等所有工作都冗余的状态引到自动化体系中来了,以此来支撑资源、配置等数据的全生命周期流转。
在自动化平台中,核心构建1个通道、4大引擎,支撑多种变更、自愈、验收等多种业务场景。
1个通道指的是管控通道,一个是为了支撑现网配置的实时纳管,需要高性能的采集通道,并订阅关键事件来感知配置实时变化;另一个是南向控制通道,用于支撑操作类自动化指令的高效下发;
4大引擎包括了模型管理、编排引擎、风控引擎、调度引擎。其中模型引擎是驱动网络变更的基座,基于Iac理念,我们自研的抽象统一配置模型映射到数据中台的规划库和现实库,以此来指导现网自动化变更;编排引擎则秉承一切操作均可编写未runbook的思想,开放编排能力给运维/交付使用者,能快速沉淀各类自动化操作场景;风控引擎是自动化平台的看护者,能自动识别变更依赖、依据影响分析来分步执行控制变更爆炸半径,再结合变更实时监控,遇到异常自动暂停或回滚变更,未来结合变更验证/仿真来做到事情预防分析;调度引擎则提供了一套优先级调度框架,来确保变更、巡检、故障处理之间任务的优先级控制,以及确保不出现冲突。

化繁为简,构建极简AI+智能网络
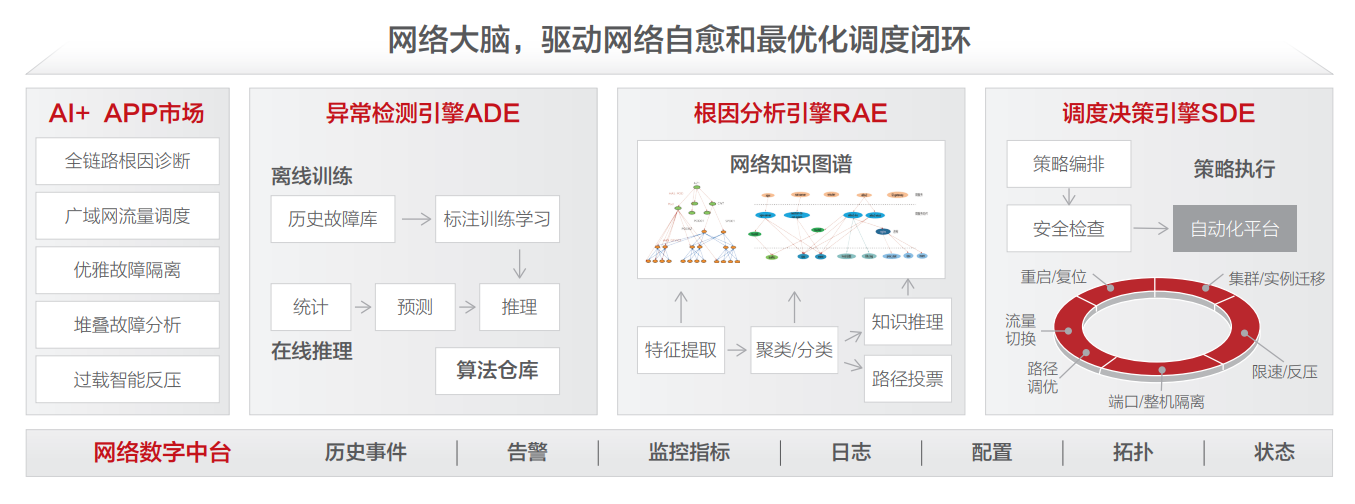
随着网络监控、自动化能力增强,带来了效率的巨大提升,但我们无法真正做到无人值守。网络大脑依托于网络数字中台,结合先进的算法能力,瞄准网络L5级自动驾驶最终方向演进,逐步实现无人运维。
网络大脑由3大核心引擎加上智能化APP应用市场组成,平台聚焦3大核心引擎模块的构建,同时开放编排能力来给运维快速孵化智能化APP,目前已经孵化5大类场景,每大类场景内部还细分子场景,并通过引擎的内核驱动来不断优化APP的性能和安全性。例如广域网流量调度APP,因为加持了秒级监控、以及多维矩阵定界算法,使得大规模运营商故障最快能在分钟级完成切换;过载智能反压APP,针对于各类共享网关,能精确识别过载的实例,同时内置安全阈值控制,以尽可能小的风险来代价来实现精准快速的过载控制。

下面简单介绍一下3大引擎的核心功能:
异常检测引擎(ADE):本质是由算法库的集合构成,但其中各项参数经过了数年的积累和调优,不仅能同时应对各类型指标,也能兼顾不同的业务特征。例如,对于白盒时序数据来讲,会结合周期性变化、容量基线、水位等来进行综合异常检测;对于内存等指标,会加入缓慢的内存泄漏检测逻辑;日志类指标,则会结合人工经验,叠加训练出的依赖关系图谱实现root casue告警;光模块等故障则会应用一些机器学习的预测性算法,提前发现并规避隐患。
根因分析引擎(RAE):以异常检测为输入,但是会结合网络拓扑、网元配置、知识推理逻辑等来进行更加精确的故障根因推导,对于大规模故障场景,能将千级的告警在5min内压缩成为一个根因告警,协助运维人员快速聚焦到故障服务或者单元。例如,pingmesh告警结合自研的路径还原算法,能快速定界到一组交换机,同时结合这一组交换机的其他KPI、日志指标根据更加详细的根因推荐;
调度决策引擎(SDE):是最终的控制单元,对于有业务影响的告警,最终需要触发恢复执行过程,可能是故障的端口自动隔离、也可能是迁移一个资源实例、也可能做流量的调度/绕行。但是如何保障执行过程不引入二次故障,或者执行怎样的策略才能将影响降低到最小,是一个非常有挑战的工作。例如,在流量切换过程中,我们会首先分析当前故障的影响程度,同时查看备选线路的网络质量,也会check状态、容量等水位等多个指标,综合进行判断,最终执行的过程就是通过调用自动化平台api进行控制,自动化平台内部的执行脚本也会有一些逻辑判断,确保不会引入新的故障。

- 点赞
- 收藏
- 关注作者
评论(0)