【云驻共创】云享读书会《SQL优化核心思想》


一、SQL优化基础
SQL优化必懂概念
- Cardinality
Cardinality represents the number of rows in a row set. Here, the row set can be a base table, a view, or the result of a join or GROUP BY operator.
Cardinality表示一个结果集的数据量大小,可以对应执行计划中某一步返回的数据量。

-
NDV
NDV(唯一值数)是指列的唯一值数量。
某个列唯一键(Distinct_Keys)的数量叫做基数。比如性别列,该列只有男女之分,所以这一列基数是2。主键列的基数等于表的总行数。
组合索引、函数索引也会计算对应的NDV。 -
Cost
Cost表示优化器计算出来的SQL执行代价,优化器通过Cost的大小选择最优的执行计划,Cost的绝对值没有太大的意义。
直方图(HISTOGRAM)
- 为什么要用直方图?
直方图是用来帮助CBO在对NDV很低、数据分布不均衡的列进行Rows估算的时候,可以得到更精准的Rows。
当列出现在where条件中,列的选择性小于%1并且该列没有收集过直方图,这样的列就应该收集直方图。
对没有出现在 where条件中的列收集直方图没有意义,浪费数据库资源。
- 直方图记录吧什么数据?
执行图是把每个列的分组数据记录到数据字典中:select owner, count(*) from test group by owner;
当NDV小于桶数时,为频率直方图,否则为高度直方图。
1)NDV比较小,重复值比较多,查询的值实际不存在
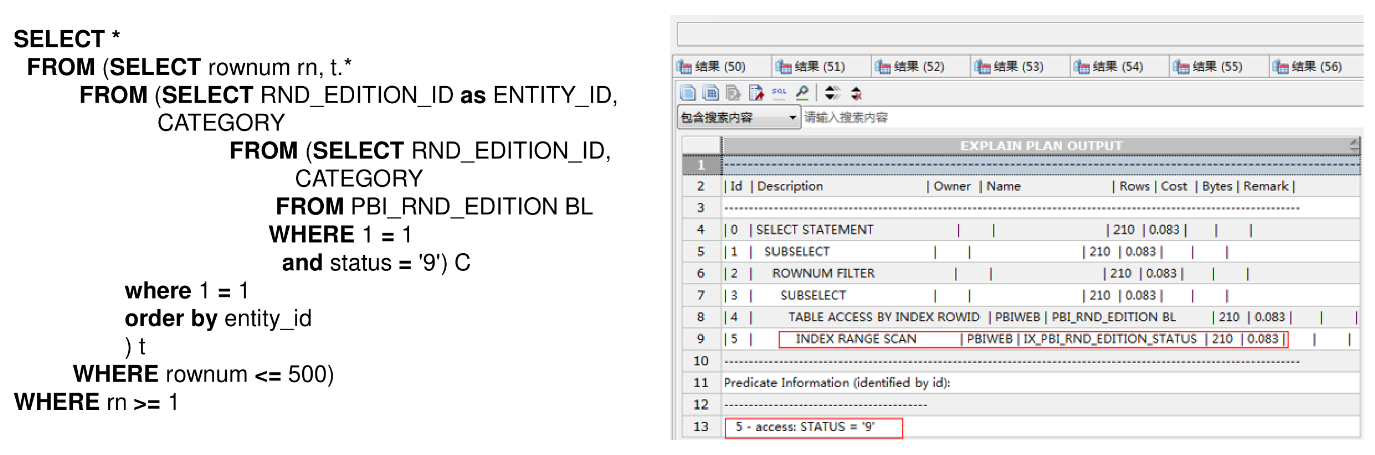
SQL > select CATEGORY, count(*) from PBI_EDITION t group by CATEGORY;

虽然查询的是一个不存在的值,优化器估计的Rows不是0,而是1/NDV(不同数据库实现可能不同)
2)如果使用绑定参数
如果支持变量窥视,可以根据实际参数值生成执行计划,否则一般按照1/NDV估计。Oracle对应特性为自适应游标共享。
3)当NDV很高时
由于直方图的桶数有限(一般为256个),当NDV很高,数据又不均衡,可能估算的 值与实际情况差距较大。
思考
-
什么样的列必须要索引?
当一个列出现在where条件中,该列没有创建索引并且选择性大于20%,那么该列就必须创建索引,从而提高SQL的查询性能。当然,表如果只有几百条数据,那么就不用创建索引了。 -
什么样的列需要收集直方图?
当列出现在where条件中,列的选择性小于1%并且该列没有收集过直方图,这样列就应该收集直方图。注意,千万不能对没有出现在where条件中的列收集直方图。对没有出现在where条件中的列收集直方图完全是做无用功,浪费数据库资源。 -
执行计划中Rows是真的吗?
执行计划里面的Rows是假的。执行计划中的Rows是根据统计信息以及一些数据公式计算出来的。
在做SQL优化的时候,经常需要做的工作就是帮助CBO计算出比较准确的Rows。注意:我们说的是比较准确的Rows。CBO是无法得到精确的Rows的,因为对表收集统计信息的时候,统计信息一般都不会按照100%的标准采样收集,即使按照100%的标准采样收集了表的统计信息,表中的数据也随时在发生变更。另外计算Rows的数学公式目前也是有缺陷的,CBO永远不可能计算得到精确的Rows。
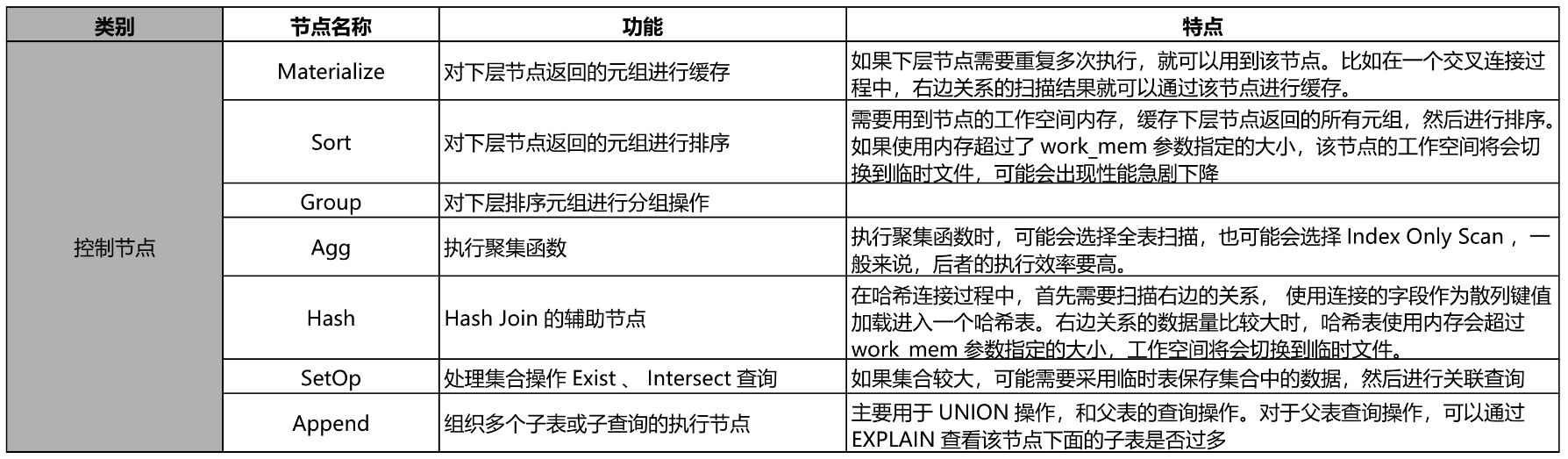
回表:TABLE ACCESS BY INDEX ROWID
- 什么事回表?
当对一个列创建索引之后,索引回包含该列的键值以及键值对应行所在的rowid。通过索引中记录的rowid访问表中的数据就叫回表。
如果只访问索引列或者使用组合索引可以避免回表。 - 回表的重要性
回表一般事单块读,回表次数太多会严重影响SQL性能,如果回表次数太多,就不应该走索引扫描了,应该直接走圈表扫描。
在进行SQL优化的时候,一定要注意回表次数!特别是要注意回表的物理I/O次数!


索引返回多少数据,回表就要回多少次,每次回表都是单块读(因为一个rowid对应一个数据块)。
在Oracle中,一个索引页中的多次回表如果对应同一个数据块算一次逻辑读。
- 小技巧
SQLPLUS的参数arraysize表示Oracle服务器每次传输多少行数据到客户端,默认为15.如果一个块有150行数据,那么这个块就会被读10次,因为每次只传输15行数据到客户端,逻辑读会被放大。设置了arraysize=5000之后,就不会发生一个块被读n次的问题了。

聚集因子(CLUSTERING FACTOR)
- 什么是聚集因子
聚集因子表示一个索引对应数据在表中的顺序性,它的大小介于表的块数和表行数之间。
如果聚集因子与块数接近,说明表的数据基本上是有序的,而且其顺序基本于索引顺序一样,回表只需要读少量的数据块就能完成。
如果聚集因子与表记录数接近,说明表的数据和索引顺序差异很大,回表会读取更多的数据块。 - 聚集因子如何计算
首先我们比较2,3对应的ROWID是否在同一个数据块,如果在同一个数据块,Clustering Factor +0;如果不在同一个数据块,那么Clustering Factor值加1.然后我们比较3,4对应的ROWID是否在同一个数据块上,如果在,则Clustering Factor值不变;若果不在同一个数据块,那么Clustering Factor值加1.像上面步骤一样,一直这样有序地比较下去,知道比较完索引中的最后一个键值。根据算法我们知道集群因子介于表的块数和表行数之间。 - 聚集因子的影响
聚集因子只会影响索引范围扫描(INDEX RANGE SCAN)以及索引全扫描(INDEX FULL SCAN),因为只有这两种索引扫描方式会有大量数据回表。
扫描同样的数据量,通过不同的索引性能差距可能很大,聚集因子是一个重要因素。 - 如果降低聚集因子的影响
1)重建表,按照某个索引列的顺序
2)通过组合索引避免回表
3)使用Oracle的cluster table
4)增大buffer cache将大部分数据缓存到内存或者使用内存表
统计信息
- 什么是统计信息
收集统计信息是为了让优化器选择最佳执行计划,以最少的代价(成本)查询出表中的数据。
统计信息主要分为表的统计信息、列的统计信息、索引的统计信息、系统的统计信息、数据字典的统计信息以及动态性能视图基表的统计信息。 - 统计信息的内容
表的统计信息主要包含表的总行数(num_rows)、表的块数(blocks)以及行平均长度(avg_row_len)。
列的统计信息主要包含列的NDV、列中的空值数量以及列的数据分布情况(直方图)。
索引的统计信息主要包含索引blevel(索引高度-1)、叶子块的个数(leaf_blocks)以及聚集因子(clustering_factor). - 收集统计信息重要参数设置
Granularity :表示收集统计信息的粒度,该选项只对分区表生效,默认为 AUTO ,表示让 Oracle 根据分区类型自己判断如何收集分区表的统计信息。
stimate _ percent :表示采样率,范围是0.000001~100。一般情况下,为了确保统计信息比较准确,建议采样率不低于30%。
method_ opt :用于控制收集直方图策略。 method _ opt =>‘ for all columns size 1表示所有列都不收集直方图。 method _ opt => for all columns size auto '表示对出现在 where 条中的列自动判断是否收集直方图。
no_invalidate :表示共享池中涉及到该表的游标是否立即失效,默认值为 DBMSSTATS . AUTO _ INVALIDATE ,表示让 Oracle 自己决定是否立即失效。我们建议将 no _ invalidate参数设置为FALSE,立即失效。
Degree:表示收集统计信息的并行度,默认为 NULL 。如果表没有设置 degree ,收集统计信息的时候后就不开并行;如果表设置了 degree ,收集统计信息的时候就按照表的degree 来开并行.
Cascade:表示在收集表的统计信息的时候,是否级联收集索引的统计信息,默认值为 DBMS _ STATS . AUTO _ CASCADE ,表示让 Oracle 自己判断是否级联收集索引的统计信。我们一般将其设置为 TRUE ,在收集表的统计信息的时候,级联收集索引的统计信息.
统计信息的过期
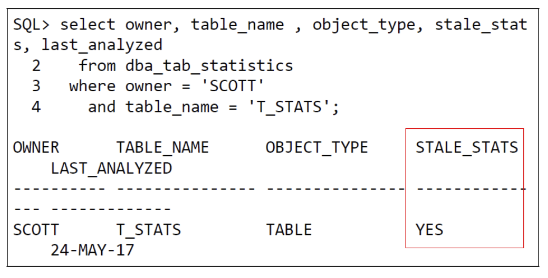
- 如何查询统计信息是否陈旧?
当stale_stats=YES,表示统计信息已经陈旧,需要重新收集。 - 什么情况下统计信息状态变为陈旧?
用户对表做DML操作时,内存中会记录每个表增删改的数量。
如果累计增删改的数量超过一定的比例(一般10%),统计信息状态变为陈旧。
如果重新收集统计信息,user_tab_modifications数据会清零,stale_stats会变更为NO。
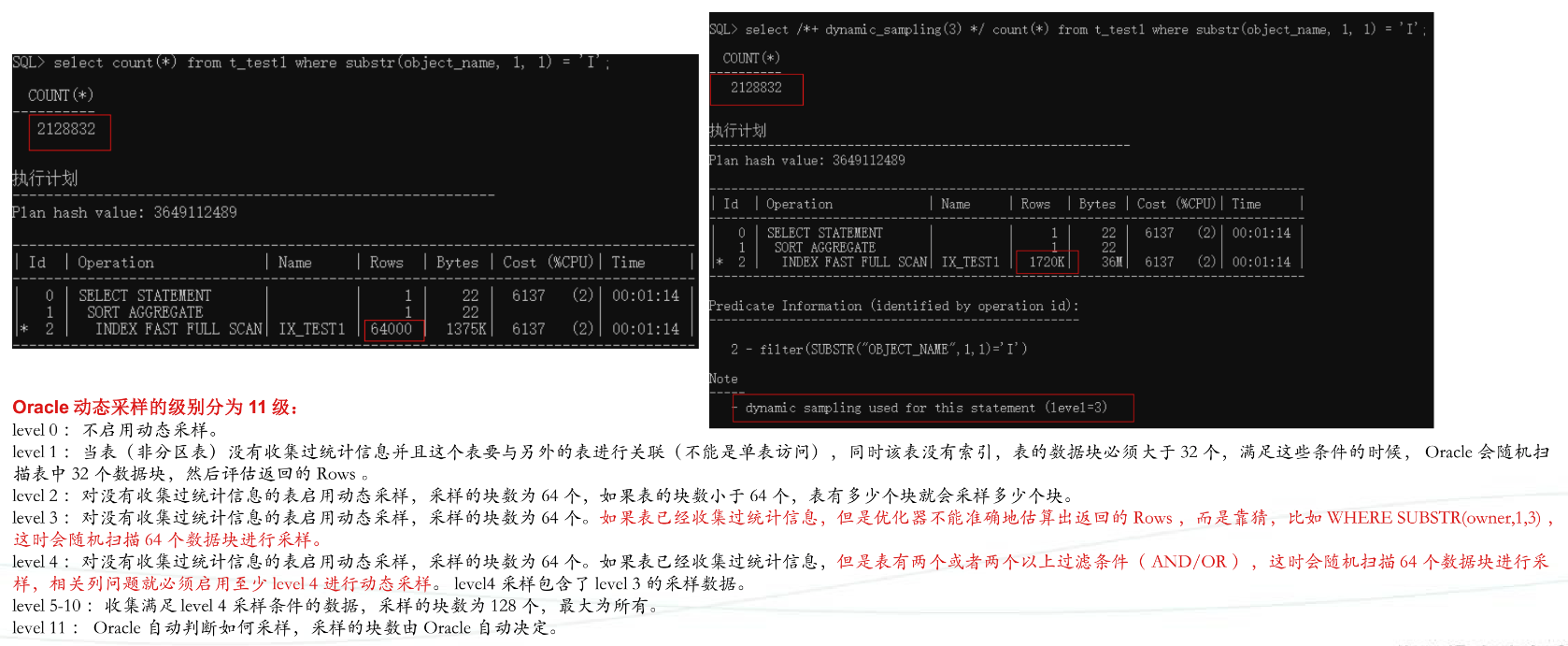
动态采样
如果一个表从来没收集过统计信息,默认情况下 Oracle会对表进行动态采样(Level=2)以便优化器估算出较为准确的Rows,动态采样的最终目的就是为了让优化器能够评估出较为准确的Rows。
执行计划中dynamic sampling used for this statement(level=2)表示启用了动态采样,level表示采样级别,默认情况下采样级别为2.
- 什么时候需要启用动态采样呢?
当系统中有全局临时表,就需要使用动态采样,因为全局临时表无法收集统计信息,我们建议对全局临时表至少启用 level 4进行采样。
当执行计划中表的 Rows 估算有严重偏差的时,例如相关列问题,或者两表关联有多个连接列,关联之后 Rows 算少,或者是 where 过滤条件中对列使用了 substr 、 instr 、 like ,又或者是 where 过滤条件中有非等值过滤,或者 group by 之后导致 Rows 估算错误,此时我们可以考虑使用动态采样,同样,我们建议动态采样至少设置为 level 4。
在数据仓库系统中,有些报表 SQL 是采用 Obiee / SAP BO / Congnos 自动生成的,此类 SQL 一般都有几十行甚至几百行, SQL 的过滤条件一般也比较复杂,有大量的 AND 和 OR 过滤条件,同时也可能有大量的 where 子查询过滤条件, SQL 最终返回的数据量其实并不多。对于此类 SQL ,如果 SQL 执行缓慢,有可能是因为 SQL 的过滤条件太复杂,从而导致优化器不能估算出较为准确的 Rows 而产生了错误的执行计划。我们可以考虑启用动态采样 level 6观察性能是否有所改善,我们曾利用该方法优化了大量的报表 SQL。
不要在系统级更改动态采样级别,默认为2就行,如果某个表需要启用动态采样,直接在 sQL 语句中添加 HINT 即可。
Oracle获取执行计划
-
Autotrace
-
Explain plan
explain plan for SQL 语句;
Select * from table(dbms_xplan.display);

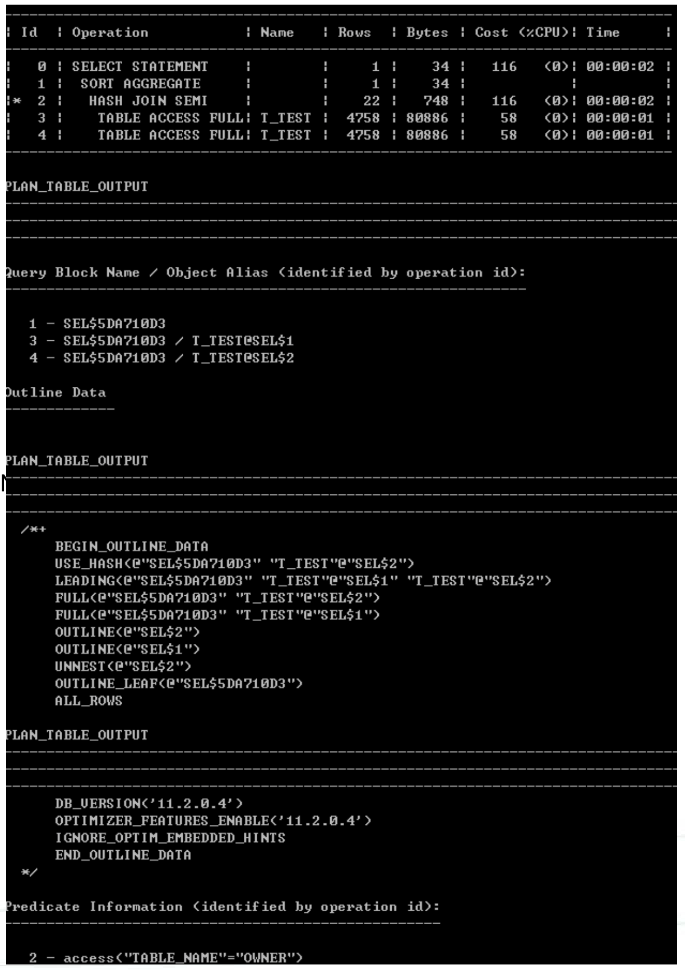
Select * from table(dbms_xplan.display(NULL, NULL, ‘advanced-projection’));
高级执行计划比普通执行计划多了Query BlockName / Object Alias 和 Outline Data。
Query Block Name 表示查询块名称,ObjectAlias表示对象别名。Outline Data表示SQL内部的HINT.
一条SQL语句可能会包含多个子查询,每个子查询在执行计划内部就是一个Query Block。
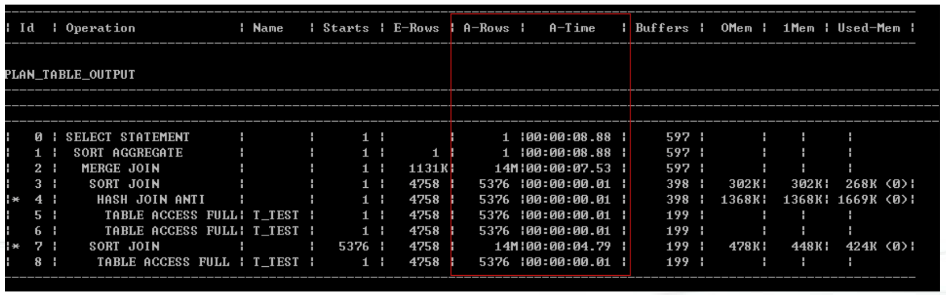
- 查询带有A-TIME的 执行计划
alter session set statistics_level = all;或者在SQL语句中添加hint:/*+gather_plan_statistics */ select * from table(dbms_xplan.display_cursor(null, null, ;Allstate last;));
执行计划
-
谓词
过滤谓词(filter):过滤条件,不影响访问路径,只起过滤作用访问谓词(access):索引扫描条件,影响访问路径 -
“*”号
表示这一步有过滤谓词
TABLE ACCESS BY INDEX ROWID 前面有“*”号,表示回表再过滤。回表再过滤说明数据没有在索引中过滤干净。
当TABLE ACCESS BY INDEX ROWID 前面有“”号时,可以将“”号下面的过滤条件包含在索引中,这样可以减少回表次数,提升查询性能。
- 提问:怎么快速找到执行计划的入口?
回答:我们可以利用光标移动大法,先将光标放在Id=0这一步,然后一直向下向右移动光标,直到找到没有儿子的Id,这个Id就是执行计划的入口。 - 提问:怎么判断时哪个表与哪个表进行关联的?
回答:我们先找到表在执行计划中的Id,然后看这个Id(或者是这个Id的父亲)与谁对齐(利用光标上下移动),它与谁对齐,就与谁进行关联。
访问路径
-
什么是访问路径?
访问路径指的是通过哪种扫描方式获取数据,比如全表扫描、索引扫描或者直接通过ROWID获取数据。 -
TABLE ACCESS FULL
TABLE ACCESS FULL 表示全表扫描,一般情况下多是块读,HINT:FULL(表名、别名),绕过buffer cache,这个时候全表扫描的等待事件也是direct path read。一般情况下,不适合TP场景,会增加物理读,建议禁用该特征。
alter session set “_serial_direct_read”=false;
- 全表扫描是什么扫描数据的?
Oracle最小的存储单元是块(block),物理上连续的块组成区(extent),区又组成了段(segment)。对于非分区表,如果表中没有clob/blob字段,那么一个表就是一个段。
全表扫描,其实就是扫描表中所有格式化过的区。因为区里面的数据块在物理上是连续的,所以全表扫描可以多块读。全表扫描不能跨区扫描,因为区与区之间的块物理上不一定是连续的。对于分区表,如果表中没有clob/blob字段,一个分区就是一个段,分区表扫描方式与非分区表扫描方式是一样的。
如果表中有部分块已经缓存在buffer cache中,在进行全表扫描的时候,扫描到已经被缓存的块所在区时,就会引起I/O不能扫描1MB数据。
如果表正在发生大事务,在进行全表扫描的时候,还会从undo读取部分数据。从undo读取数据是单块读,这种情况下全表扫描效率非常地下。因此,建议使用批量游标的方式处理大事务。
-
TABLE ACCESS BY USER ROWID
表示直接用ROWID获取数据,单块读。该访问路径在Oracle所有的访问路径中性能最好的。 -
TABLE ACCESS BY ROWID RANGE
表示ROWID范围扫描,多块读。因为同一块里面的ROWID是连续的,同一个EXTENT里面的ROWID也是连续的,所以可以多块读。 -
TABLE ACCESS BY INDEX ROWID
表示回表,单块读。 -
INDEX UNIQUE SCAN
表示索引唯一扫描,单块读。因为对唯一索引或者对主键列进行等值查找,CBO能确保最多只返回1行数据,所以可以走索引唯一扫描。 -
INDEX RANGE SCAN
表示索引范围扫描,单块读,返回的数据是有序的(默认升序)。HINT:INDEX(表名/别名 索引名)。对唯一索引或者主键进行范围查找,对非唯一索引进行等值查找,范围查找,就会发生INDEX RANGE SCAN。等待时间为db file sequential read. -
INDEX RANGE SCAN DECENDING
表示索引降序范围扫描,,从右往左扫描,返回的数据是降序显示的。 -
INDEX FULL SCAN
表示索引全扫描,单块读,返回的数据是有序的(默认升序)。HINT:INDEX(表名/别名 索引名)。索引全扫描会扫描索引中所有的叶子块(从左往右扫描),如果索引很大,会产生严重性能的问题(因为是单块读)。等待事件为db file sequential read. 一般用在分页查询或者Top N查询时规避排序。 -
INDEX FAST FULL SCAN
表示索引快速全扫描,多块读。HINT:INDEX_FFS(表名/别名 索引名)。当需要从表中查询大量数据但是只只需要获取表中部分列的数据,我们可以利用索引快速全扫描代替全表扫描来提升性能。索引快速全扫描方式与全表扫描方式是一样的,都是按区扫描,所以它可以多块读,可以并行扫描。等待事件为db file scattered read,如果是并行扫描,等待事件为direct path read. -
INDEX FULL SCAN (MIN/MAX)
表示索引最小/最大值扫描、单块读,该访问路径发生在SELECT MAX(COLUMN)FROM TABLE或者SELECT MIN(COLUMN)FROM TABLE等SQL语句中。INDEX FULL SCAN(MIN/MAX)只会访问“索引高度”个索引块,其性能与INDEX UNIQUESCAN一样。
在Oracle中,不要同时查询最大值和最小值:
select max(object_id), min(object_id) from t;
-
INDEX SKIP SCAN
表示索引跳跃扫描,单块读。返回的数据是有序的(默认升序)。HINT:INDEX_SS (表名/别名 索引名)。当组合索引的引导列(第一个列)没有在where条件中,并且组合索引的引导列/前几个列的基数很低,where过滤条件对组合索引中非引导列进行过滤的时候就会发生索引跳跃扫描,等待事件为db file sequential read. -
单独读与多块读
从磁盘1次读取1个块到buffer cache就叫单块读,从磁盘1次读取多个块到buffer cache就叫多块读。如果数据块都已经缓存在buffer cache中,那就不需要物理I/O了,没有物理I/O也就不存在单块读与多块读。 -
为甚有时候索引扫描比全表扫描更慢?

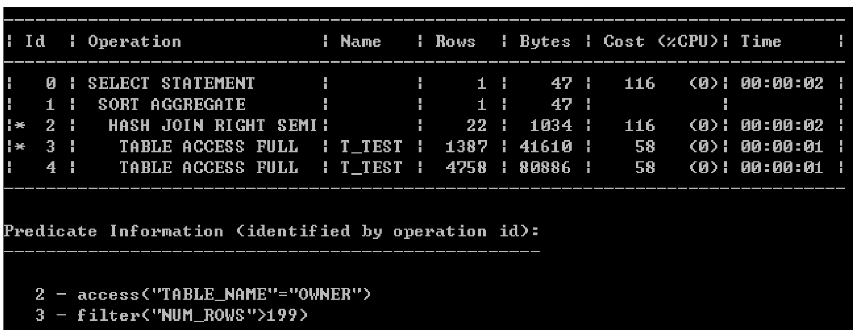
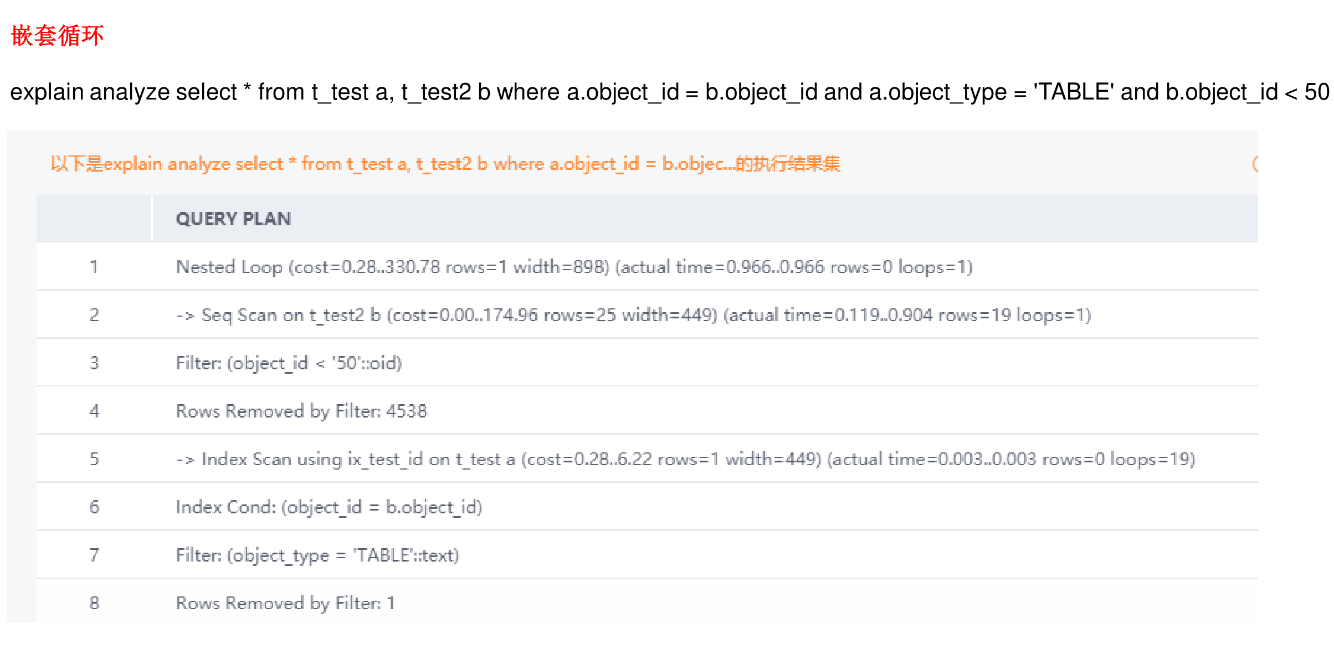
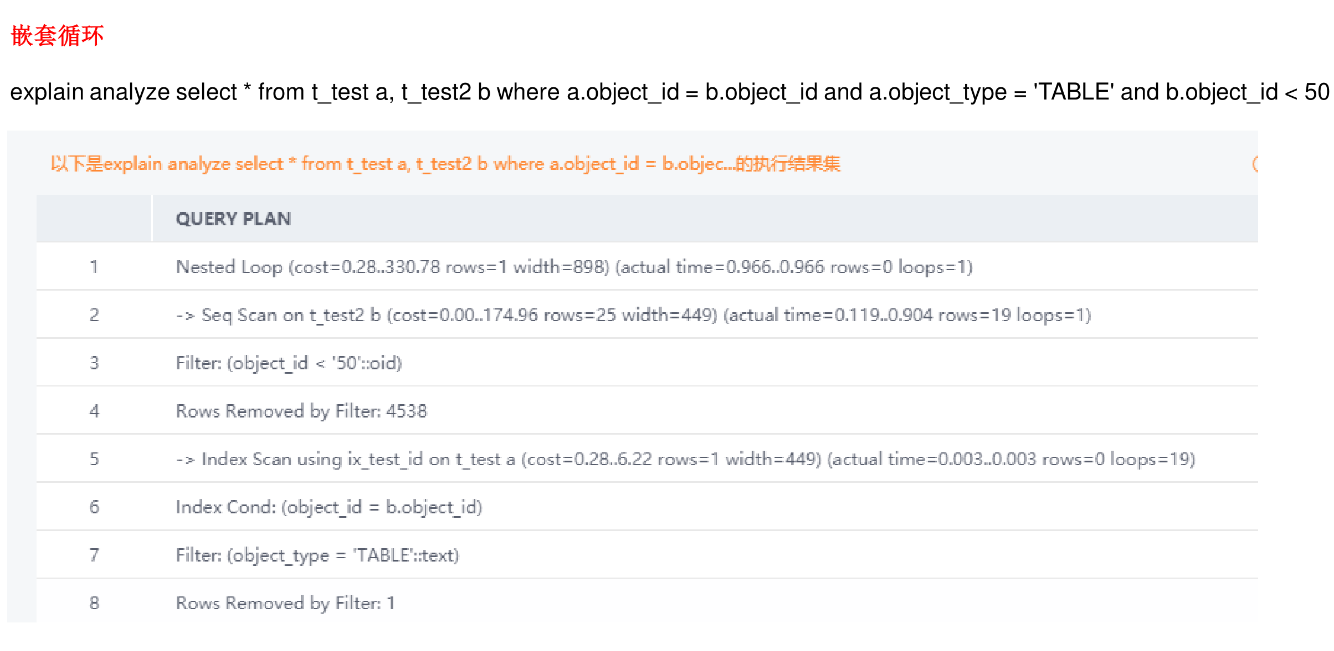
PG执行计划 - 案列解读

执行计划 - 参数解释 - 1
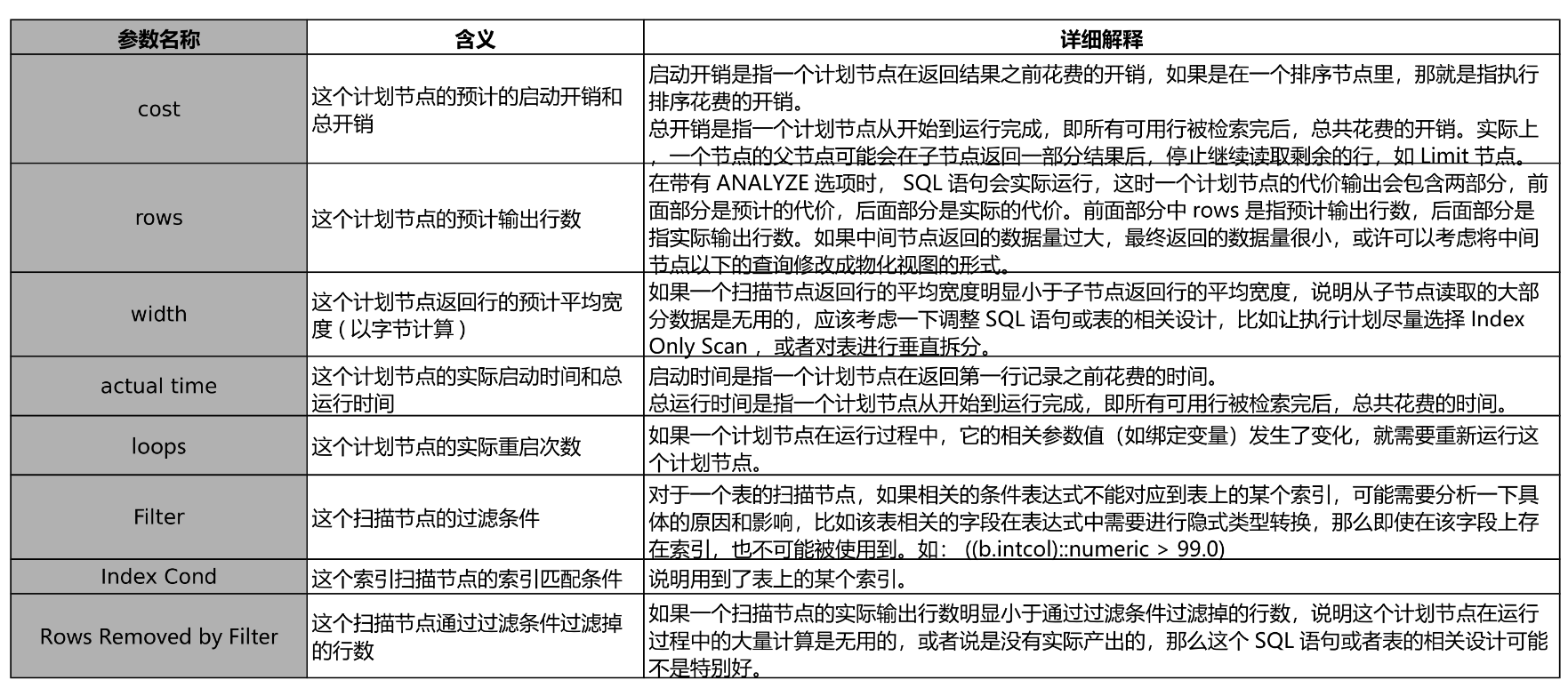
执行计划 - 参数解释 - 2
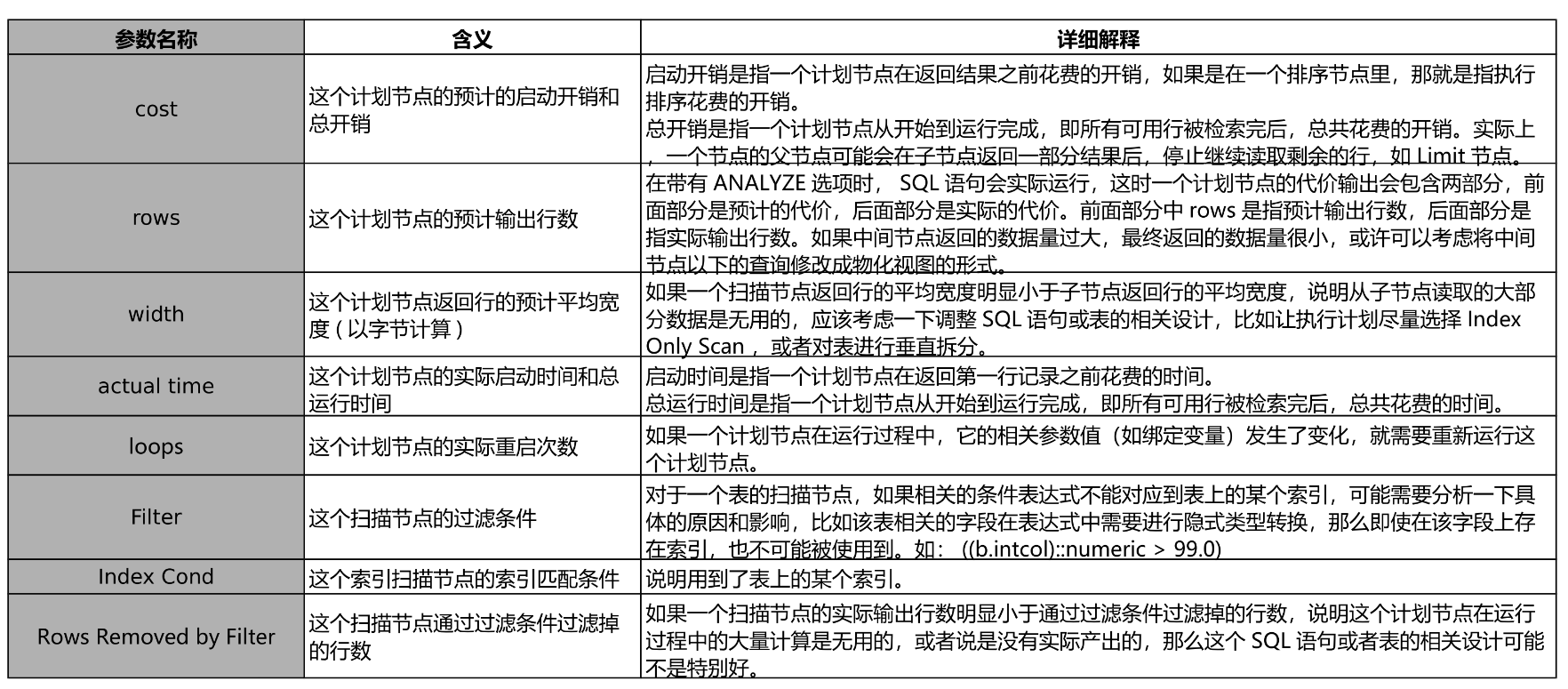
执行计划 - 计划节点 - 1
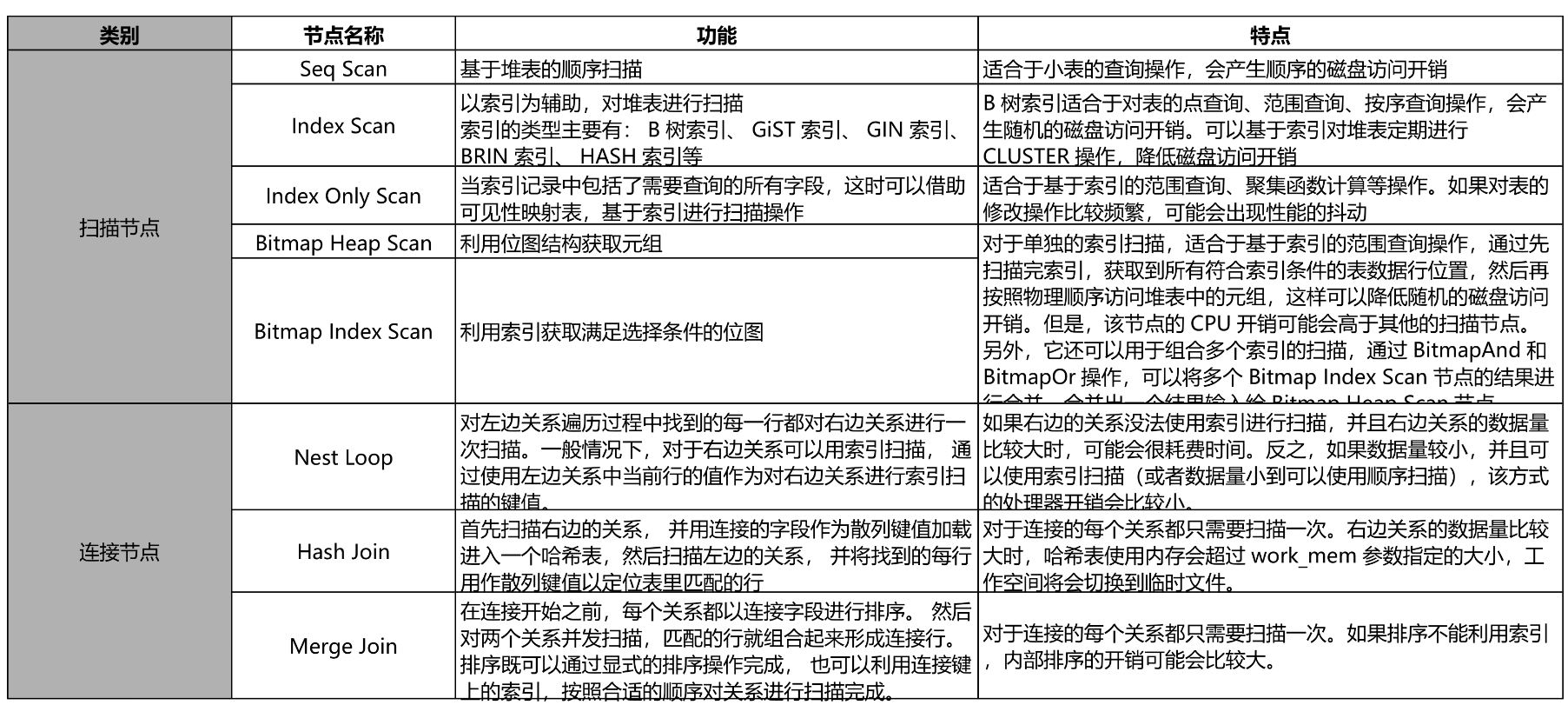
执行计划 - 计划节点 - 2
二、优化多表连接

嵌套循环
- 嵌套循环的算法
驱动表返回一行数据,通过连接列传值给被驱动表,驱动表返回多少行,被驱动表就要被扫描多少次。
在执行计划中,离NESTED LOOPS关键字最近的表就是驱动表。
- 嵌套循环使用场景
驱动表应该返回少量数据,关联条件的索引命中的数据必须很少。
嵌套循环被驱动表必须走索引。如果嵌套循环被驱动表必须走索引。如果嵌套循环被驱动表的连接列没包含在索引中,那么被驱动表就只能走全表扫描,而且是反复多次全表扫描。当被驱动表很大的时候,SQL就执行不出结果。嵌套循环被驱动表走索引只能走INDEXUNIQUE SCAN或者INDEX RANGE SCAN。
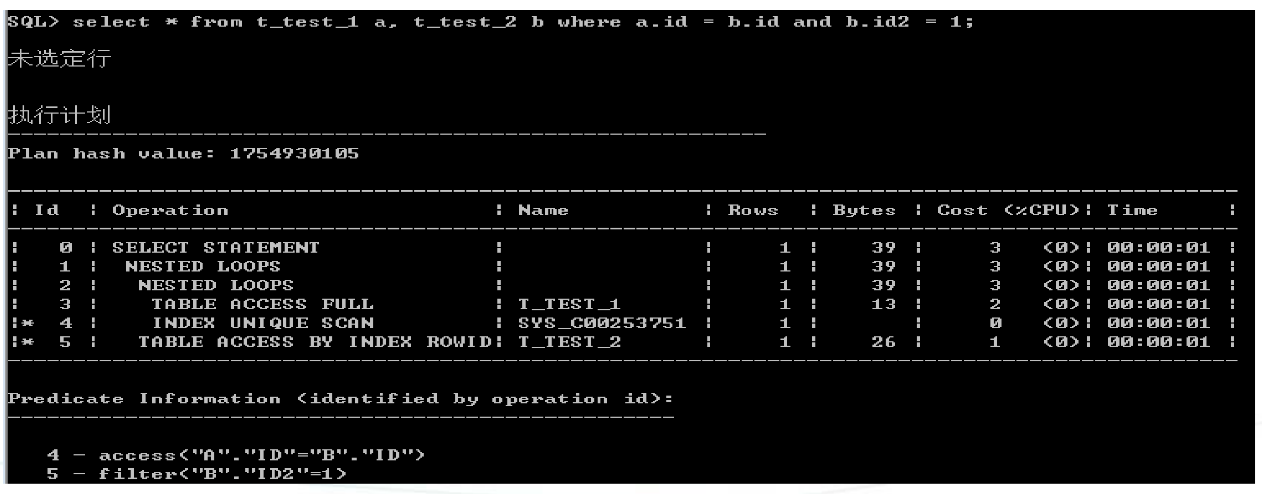
- 外联结使用嵌套循环
当两表使用外连接进行关联,如果执行计划是走全套循环,那么这时无法更改驱动表,驱动表会被固定为主表。思考为什么?
为什么外连接的从表有过滤条件变成内连接呢?
因为外连接的从表有过滤条件已经排除了从表与主表没有关联上显示NULL的情况。
-
嵌套循环的提示
use_nl(d,e)表示让两表走嵌套循环,在书写hinte时候,如果表有别名, hiNt一定要使用别名,否则hint生效:如果表没有别名, hinte就直接使用表名。 -
提问:两表关联走不走NL是看两个表关联之后返回的数据量多少?还是看驱动表返回的数据量多少?
回答:如果两个表是1:N关系,驱动表为1,被驱动表为N并且M很大,这时即使驱动表返回数据量很少,也不能走嵌套循环,因为两表关联之后返回的数据量会很多。所以判断两表关联是否应该走NL应该直接查看两表关联之后返回的数据量,如果两表关联之后返回的数据量少,可以走NL:返回的数量多,应该走HASH连接。
此外,还需要关注被驱动表的过滤条件和是否需要回表。 -
提问:大表是否可以当嵌套循环(NL)驱动表?
回答:可以,如果大表过滤之后返回的数据量很少就可以当NL驱动表 -
提问: select* from a,b where a.id-b.id;如果a100条数据, b100万行数据,a5b1:n系,n很低,应该怎么优化SQL?
回答:因为a5b1:N系,n低,我们可以在b连接列(id)上创建索引,让a5b嵌套循环(anlb),这样b会被扫描100次,但是每次扫描
表的时候走的是d列的索引(范围扫描)。
Hash连接
- HASH连接的算法
两表等值关联,返回大量数据,将较小的表选为驱动表,将驱动表的“select和join”读入PGA的work area,然后对驱动表的连接列进行hashi算生成hash table,当驱动表的所有数据完全读入PGA的work areaz后,再读取被驱动表(被驱动表不需要读入PGA的workarea),对被驱动表的连接列也进行hashi算,然后到PGA的work area探测hash table,找到数据就关联上,没找到数据就没关联上。 - HASH连接的适用场景
哈希连接只支持等值连接,
哈希连接的适用场景就是嵌套循环的不适用场景,即两表连接条件关联的结果集比较大。
Used-Mem示hASHi接消耗了多少PGA,当驱动表太大、PGA能完全容纳驱动表时,驱动表就会溢出到临时表空间,进而产生磁盘HASHi接, 这时候HASHi接性能会严重下降。嵌套循环不需要消耗PGA.
-
思考:怎么优化HASH连接?
回答:因为HASHi接需要将驱动表的select和join放入PGA,所以,我们应该尽量避免书写select * from.语句,将需要的列放在select list, 这样可以减少驱动表对PGA的占用,避免驱动表被溢出到临时表空间,从而提升查询性能。
-
外连接的HASH
对于左外连接,Oracle会选择小表为hash表(执行计划上面的表)
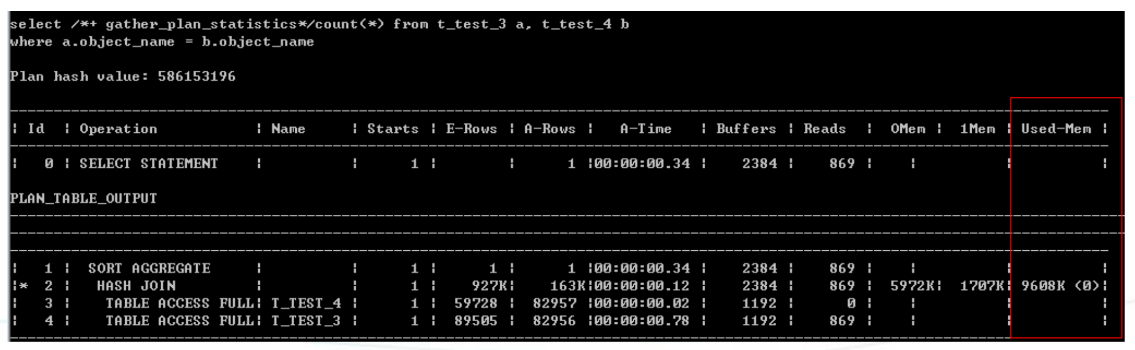
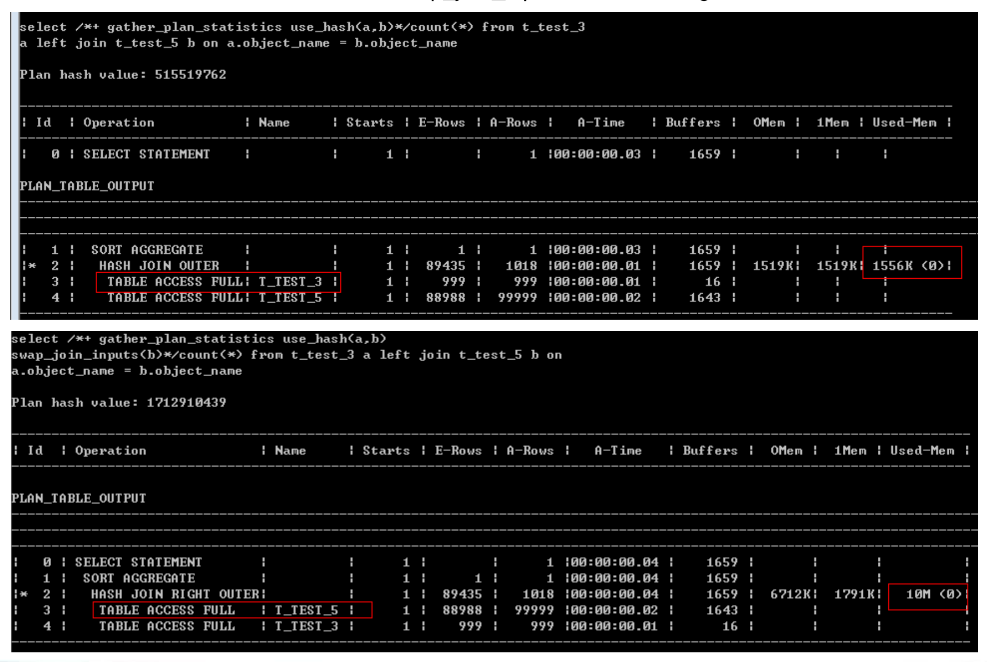
Oracle如果想改变hash表,需要使用swap_join_inputs提示(leading不起作用)。
排序合并连接(SORT MERGE JOIN)
- 适用场景
排序合并连接主要用于处理两表非等值关联,比如>,>=,<,<=,<>,但是不能用于instr,substr,like, regexp_ like联,instr, substr,like.regexp_like联只能走嵌套循环。
如果两表是等值关联,一般不建议走排序合并连接。因为排序合并连接需要将两个表放入PGA,而haShi接只需要将驱动表放入PGA,排序合并连接与hASHi接相比,需要耗费更多的PGA
- 算法介绍
排序合并连接的算法:两表关联,先对两个表根据连接列进行排序,将较小的表作为驱动表,然后从驱动表中取出连接列的值,到已经排好序的被驱动表中匹配数据,如果匹配上数据,就关联成功。驱动表返回多少行,被驱动表就要被匹配多少次,这个匹配的过程类似嵌套循环,但是嵌套循环是从被驱动表的索引中匹配数据,而排序合并连接是在内存中(PGA的workarea)匹配数据。
1.Both relations are sorted on the join attributes.
2.Then, both relations are scanned in the order of the join attributes. Tuples that satisfy the join condition are merged to form the result relation.
- 思考:怎么优化排序合并连接?
回答:如果两表关联是等值关联,走的是排序合并连接,我们可以将表连接方式改为HASH连接。如果两表关联是非等值关联,比如>,>=,<,<=,<>,这时我们应该先从业务上入手,尝试将非等值关联改写为等值关联,因为非等值关联返回的结果集“类似”于笛卡儿积,当两个表都比较大的时候,非等值关联返回的数据量相当“恐怖”。如果没有办法将非等值关联改写为等值关联,我们可以考虑增加两表的限制条件,将两个表数据量缩小。
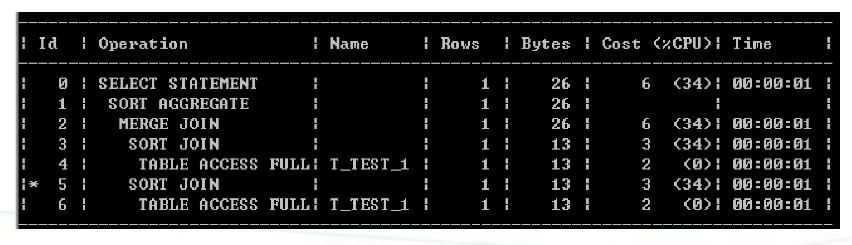
笛卡儿连接(CARTESIAN JOIN)
- 什么是笛卡儿连接
两个表关联没有连接条件的时候会产生笛卡儿积,这种表连接方式就叫笛卡儿连接。
执行计划中MERGE JOIN CARTESIAN表示笛卡儿连接。
在多表关联的时候,两个表没有直接关联条件,但是优化器错误地把某个表返回的RoWs算为1行(注意必须是1行),这个时候也可能发生笛卡儿连接。
- 思考:当执行计划中有笛卡儿连接应该怎么优化呢?
首先应该检查表是否有关联条件,如果表没有关联条件,那么应该询问开发与业务人员为何表没有关联条件,是否为满足业务需求而故意不写关联条件。其次应该检查离笛卡儿连接最近的表是否真的返回1行数据,如果返回行数真的只有1行,那么走笛卡儿连接是没有问题的,如果返回行数超过1行,那就需要检查为什么Rows 估算错误,同时要纠正错误的Rows.纠正错误的Rowsz后,优化器就不会走笛卡儿连接了。我们可以使用HINT /+opt param("optimizer mjc enabled,false/禁止笛卡儿连接。
标量子查询(SCALAR SUBQUERY)

半连接(SEMI JOIN)
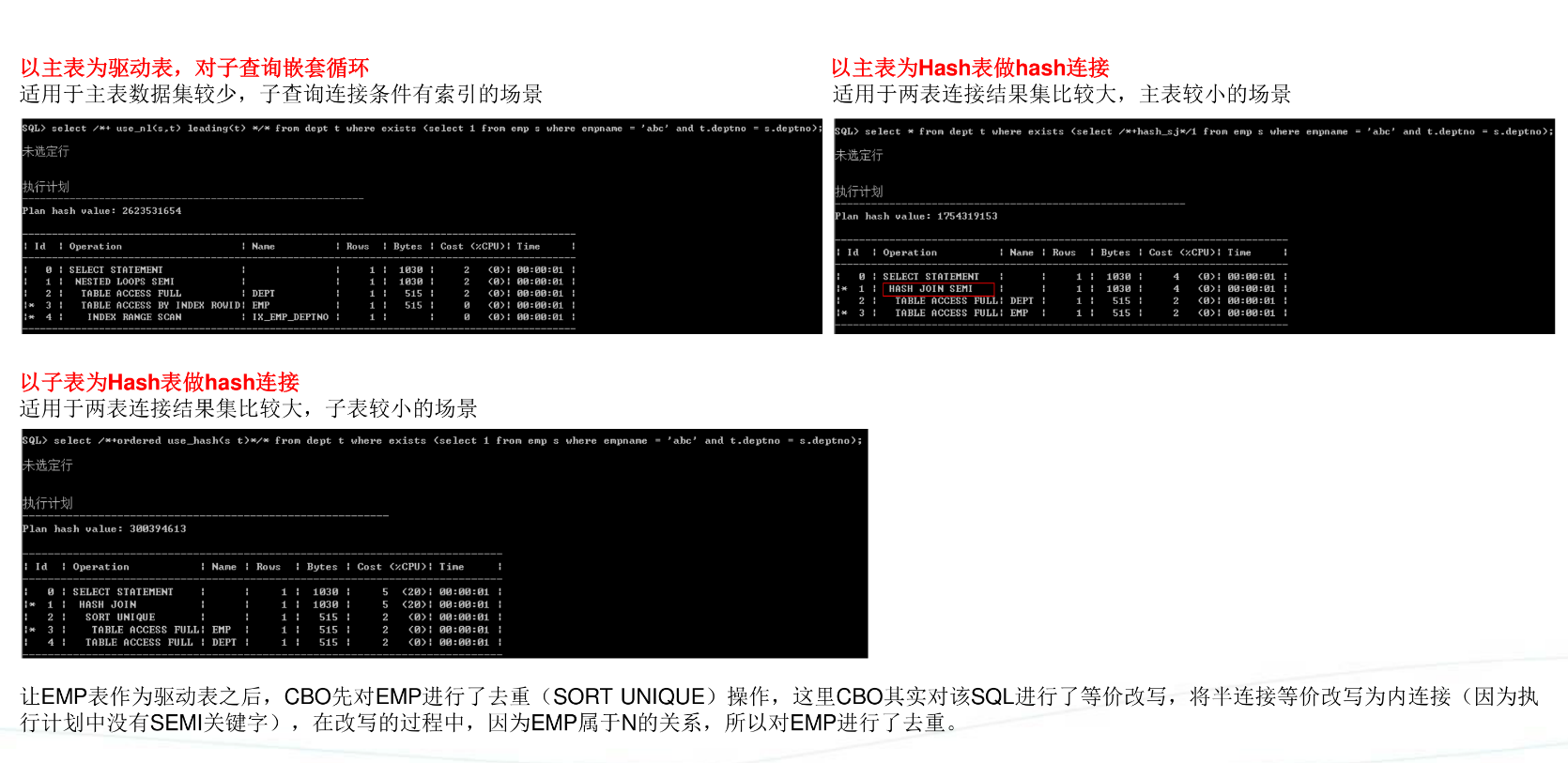
反连接(ANTI JOIN)
-
什么是反连接?
两表关联只返回主表的数据,而且只返回主表与子表没关联上的数据,这种连接就叫反连接。反连接一般指not in和no exists.
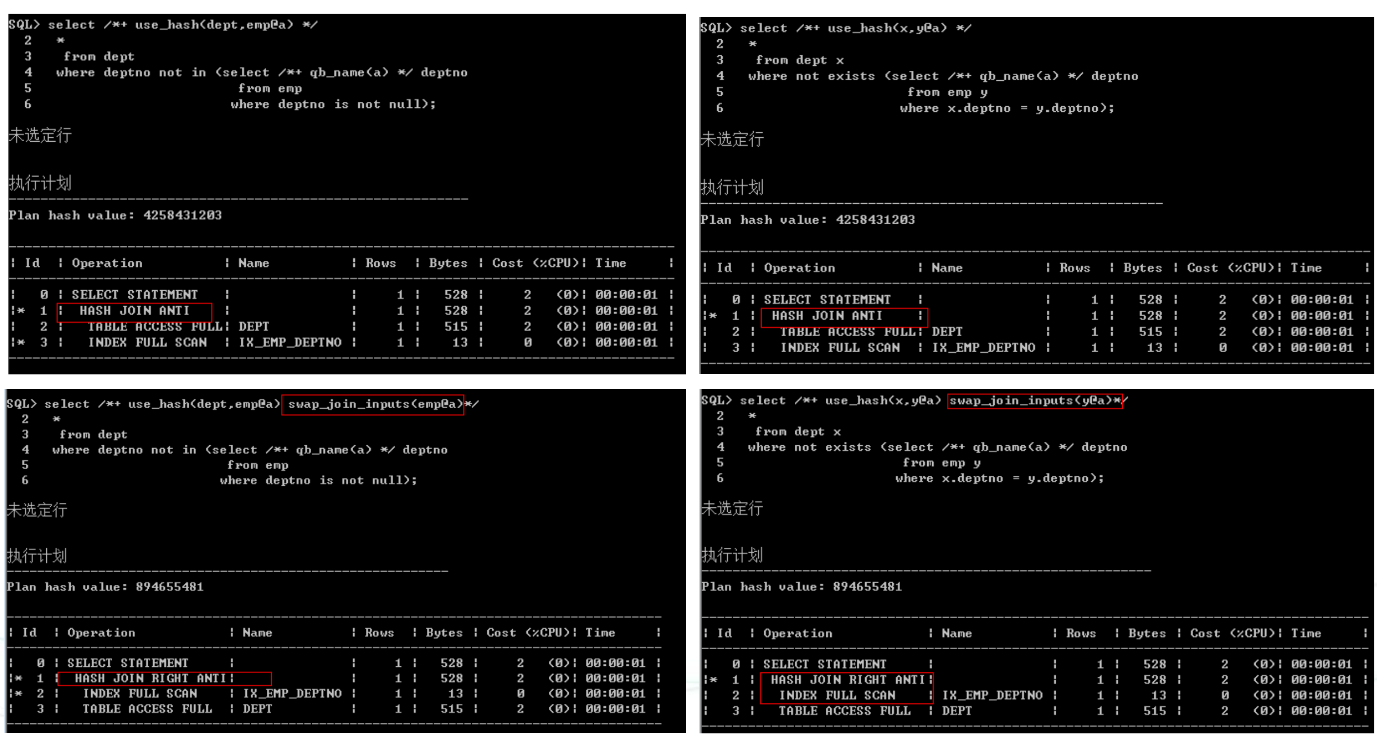
SQL>selectfrom dept where deptno not in (select deptno from emp)
SQL>selectfrom dept where not exists(select null from emp where dept.deptno = emp.deptno); -
not innot exists区别
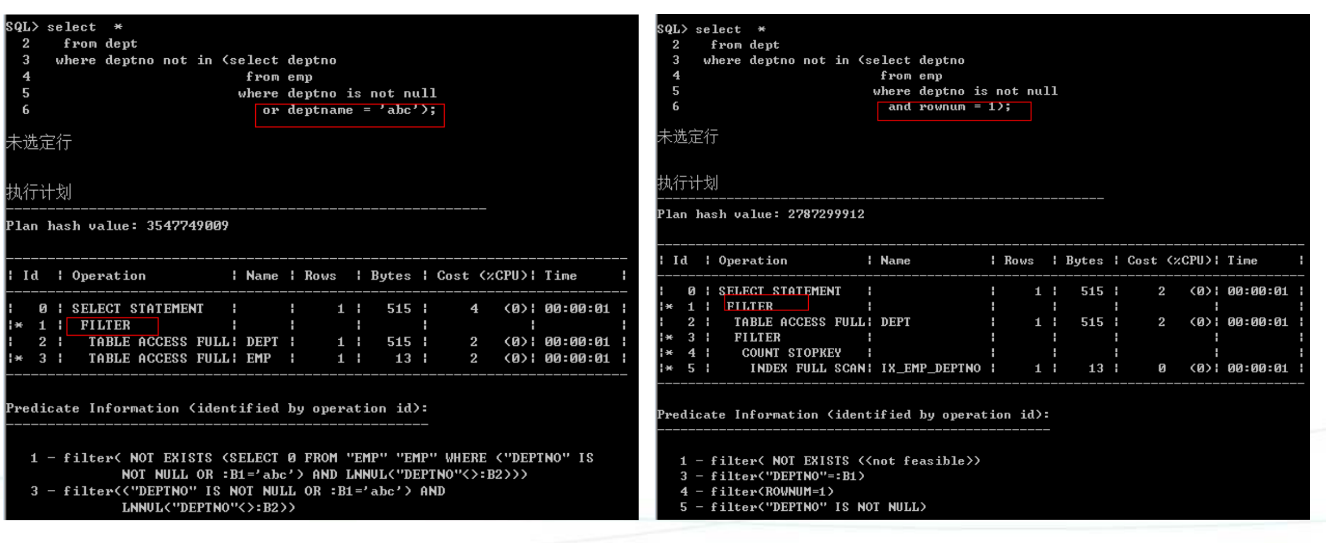
not in话,只要子查询中有一个null,结果就为空,而not exists会,说明not ini为null未知的,可以等于任意数。
将not exists价改写为not in时候,要注意null一般情况下,如果反连接采用not in法,我们需要在where件中剔除null. -
not innot exists 执行计划
1)嵌套循环
Not in指定is not null 者有非空约束,注意:驱动表必须是主表
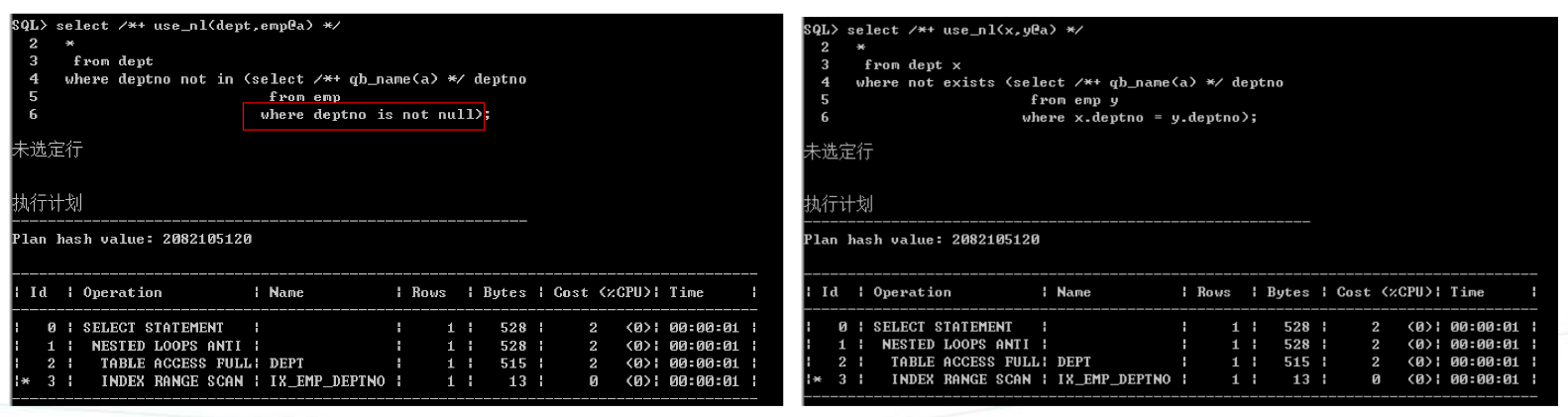
2)hash连接
Not in要指定is not null或者有非空约束,否则可能会很慢,如果想改变hash表,可以使用提示swap_join_inputs
子查询无法展开
- 什么叫子查询展开以及为什么要展开
SELECT*FROM sales WHERE cust_id IN(SELECT cust_id FROM customers);
就是优化器将嵌套的子查询展开成一个等价的join,然后去优化这个join。上面的预计,不展开的情形是,从sales表中获取的每一条数据,都要代入子查询进行匹配。一般情况下效率都是比较低的。展开结果可能是sales表和customers表做一个hash join semi,从而提高效率。因为转换为join后可以从访问路径、连接方法、连接顺序等方法优化整个查询。
PG的执行计划
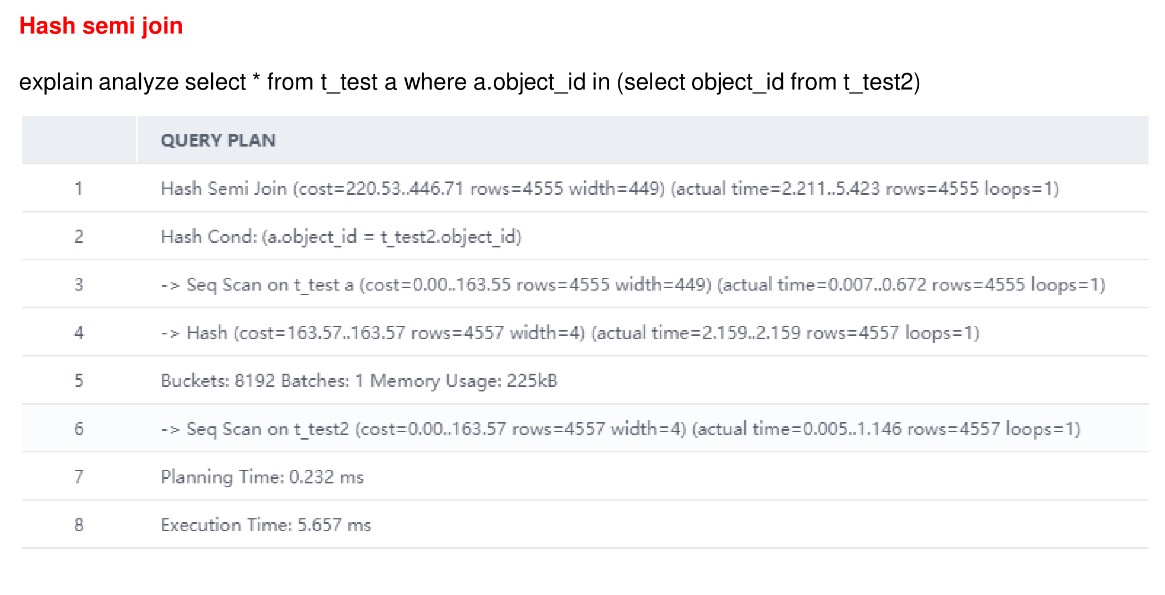
三、查询变换和优化技巧

Oracle的Cost计算公式

-
单块读耗时
IO寻找寻址耗时+块大小/IO传输速度,典型的估算值:10+8K/4K = 12ms -
多块读耗时
IO寻道寻址耗时+db_file_multiblock_count*块大小/IO传输速度,如果db_multiblock_count配置16,则多块读耗时42ms -
CPU
评估出的CPU占用/CPU主频/1000,该值一般比IO耗时低得多 -
全表扫描Cost评估
全表扫描没有单块读,CPU耗时可以忽略,它的cost约等于多块读的cost
全表扫描的多块读次数 = Block数量 / db_file_multiblock_count,由于IO中断和多个extent不连续,实际值会略大。
- 索引范围扫描Cost评估
索引范围扫描没有多块读,CPU耗时可以忽略,它的Cost约等于单块读cost
索引范围扫描单块读的次数 = blevel + celiling(leaf_block * effective index selectivity) + celiling(clustering_factor * effective table selectivity)
包括三部分:索引层高-1,需要扫描的索引块的个数,需要回表的次数,其中主要部分是需要回表的次数。
-
优化器何时选择全表扫描,何时选择索引扫描?
就是比较走全表扫描的总耗时与走索引扫描的总耗时,哪个快就选哪个。 -
IO代价的变化
全表扫描成本计算公式是在Oracle9i(2000年左右)开始引入的,当时的IO设备性能远远落后于现在(磁盘阵列),随着SSD的出现,寻道寻址时间已经可以忽略不计,磁盘阵列的性能已有大幅提升,因此认为在现代的IO设备中,单块读与多块读耗时几乎可以认为一样的。 -
SQL优化的核心思想
就是想方设法减少SQL的物理IO次数(不管是单块读次数还是多块读次数)
即使有缓存,减少块的扫描次数也可以降低CPU的占用。
查询变换:子查询非嵌套

视图合并(消除)

谓词下推
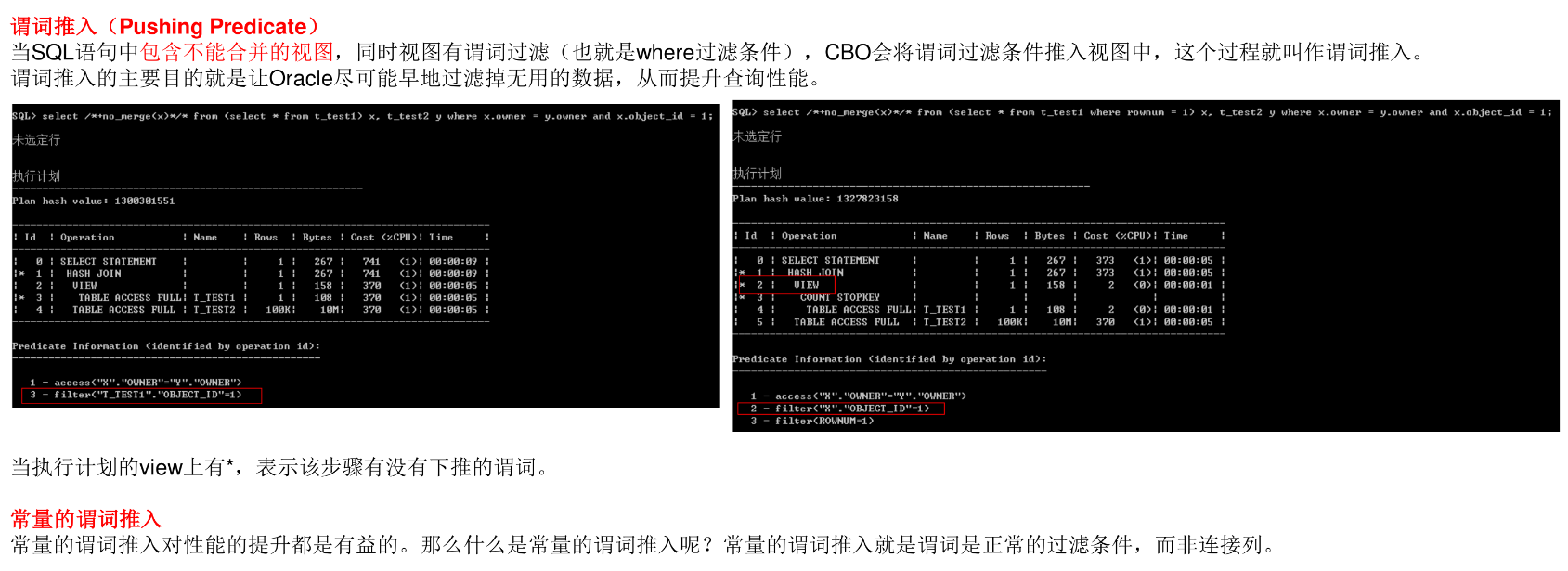
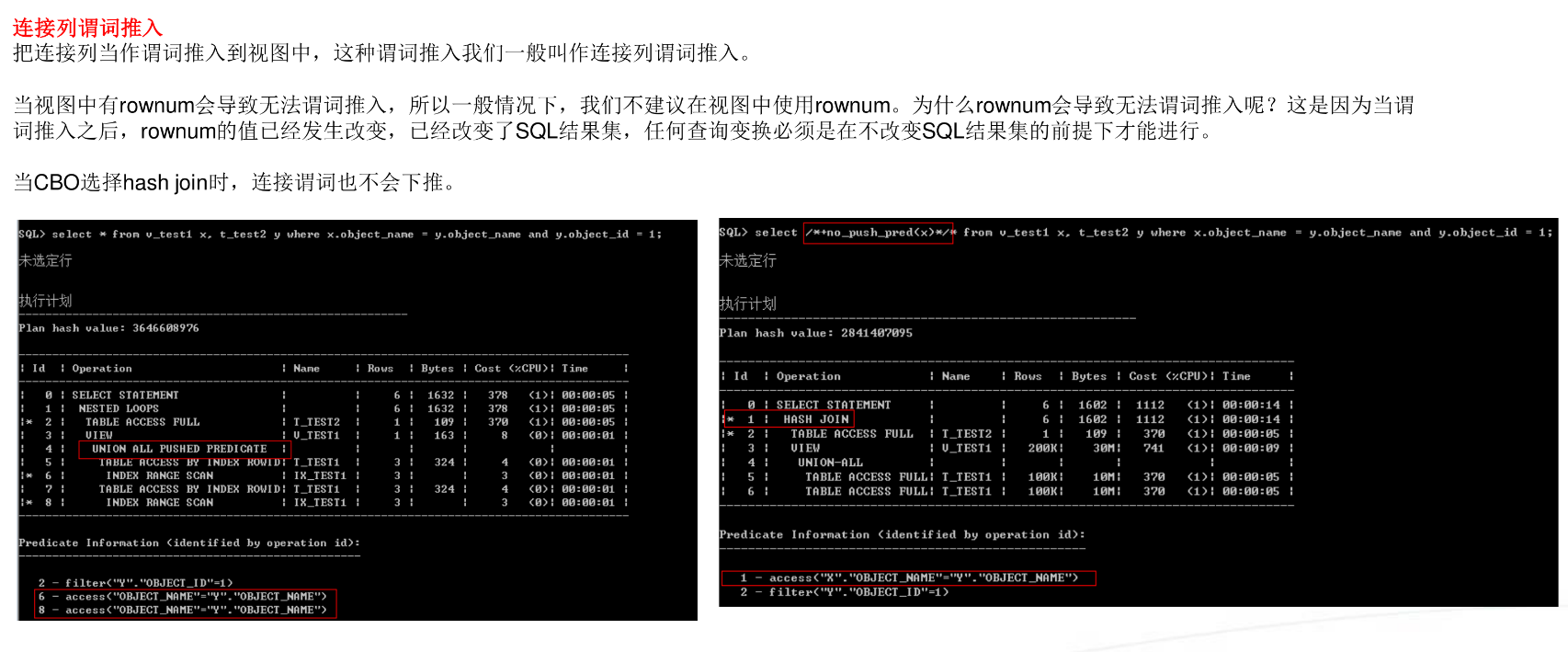
调优技巧
-
查看真实的基数(Rows)
执行计划中的Rows是假的,是CBO根据统计信息和数学公式估算出来的,所以在看执行计划的时候,一定要注意桥套循环驱动表的Rows是否估算准确,同时也要注意执行计划的入口Rows是否算错。因为一旦嵌套循环驱动表的Rows估算错误,如果执行计划的入口Rows估算错误,那执行计划也就不用看了,后面全错。 -
使用UNION代替OR
当SQL语句中同时有or和子查询,这种情况下子查询无法展开(unnest),只能走FILTER。遇到这种情况我们可以将SQL改写为union,从而消除FILTER。

分页查询
- 分页查询通过index full scan消除排序
分页查询一般需要排序后取前N条数据,并且大部分查询是查询第一页。如下:
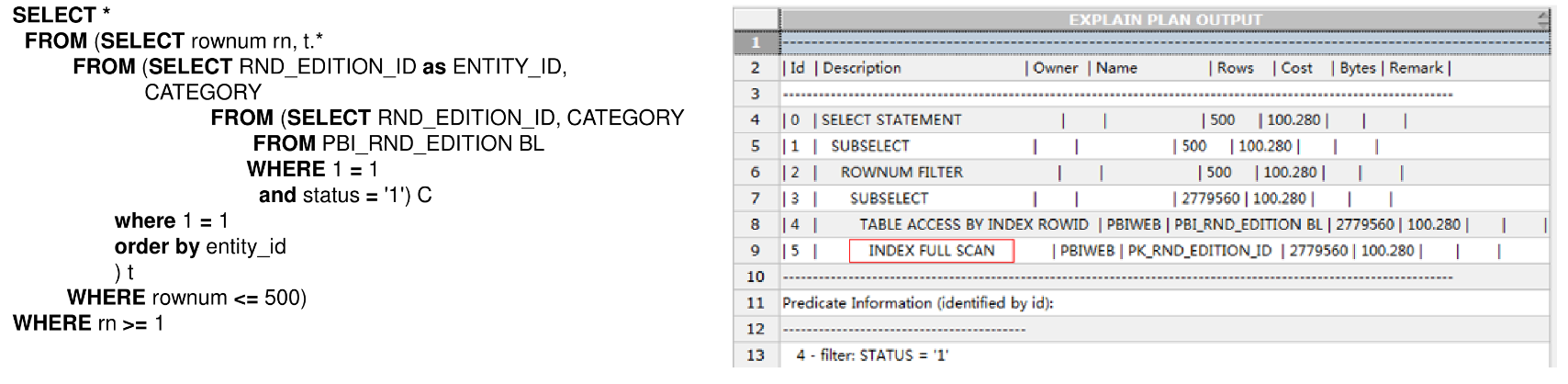
需要注意前提条件:表中大部分数据是目标数据,如果不是的话这样查询效率是不高的,例如,有一个精确的查询条件OLD_NO=12345,那么就不合适了。
-
分页查询通过组合
有的时候,只使用排序列来消除排序性能还不够理想,需要使用过滤列+排序列的组合索引来消除排除,例如下面的例子:
-
多表连接消除排序
对于主表(需要排序的表)来说,这个关联的表相当于一个过滤条件,同样也只有大部分的数据满足查询条件的情况下可以通过index full scan来消除排序。要求以排序表为驱动表,两表嵌套循环。
分页语句ye中也不能有distinct、group by、max、min、avg、union all等关键字。因为当分页语句中有这些关键字,我需要等表关联完或者数据都跑完了之后再来分页,这样性能很差。
分页查询遇到union all
如果分页查询的数据来自两张表,并且集jie’guo很大,同时还需要全局排序,那么就不好优化了,例如下面:

这个例子无法通过索引消除排序,提升性能,需要改造业务表,将两张表合并。为了减小对原有代码的冲击,若数据变化不大,可增加一张表作为两张表的合集。
从第一页翻到最后一页
有的分页查询场景是需要把所有数据处理一边,如果按照普通分页查询场景效率会比较低。因为传统的分页查询使用limit或rownum来限制要扫描的数据,当查询第一页时,实际扫描到第一页即可终止;当查询第二页时,就需要扫描当前两页的数据。这样会导致越往后查询需要扫描的数据越多,而实际返回的数据是一样的,所以有很多重复扫描,做了大量的无用功。

分区表+多值的分页查询
有的场景需要对范围分区表做分页查询,即排序后取Top N,如下:

分区表+多值的分页查询
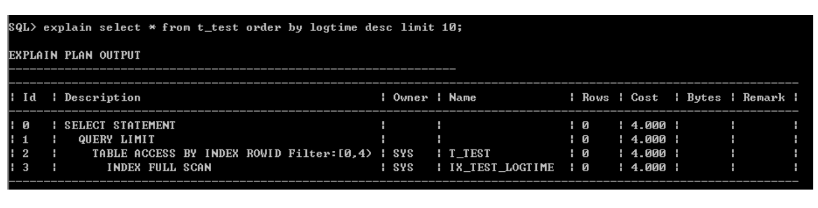
1)安装分区字段倒序取Top 10数据
从执行计划看,走logtime的索引是可以消除排序的,虽然高斯不支持倒序索引,仍然可以消除倒叙排序。如果是组合排序,并且同时有正序和倒序,那么就无法消除了。
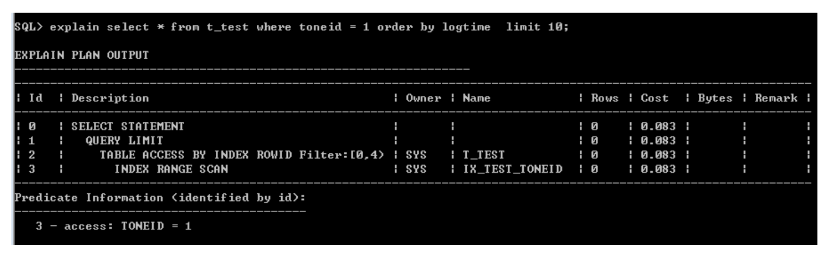
2)有过滤条件,同时按照分区字段倒序取Top 10数据
从执行计划看,走(toneid,logtime)的组合索引也是可以消除排序。
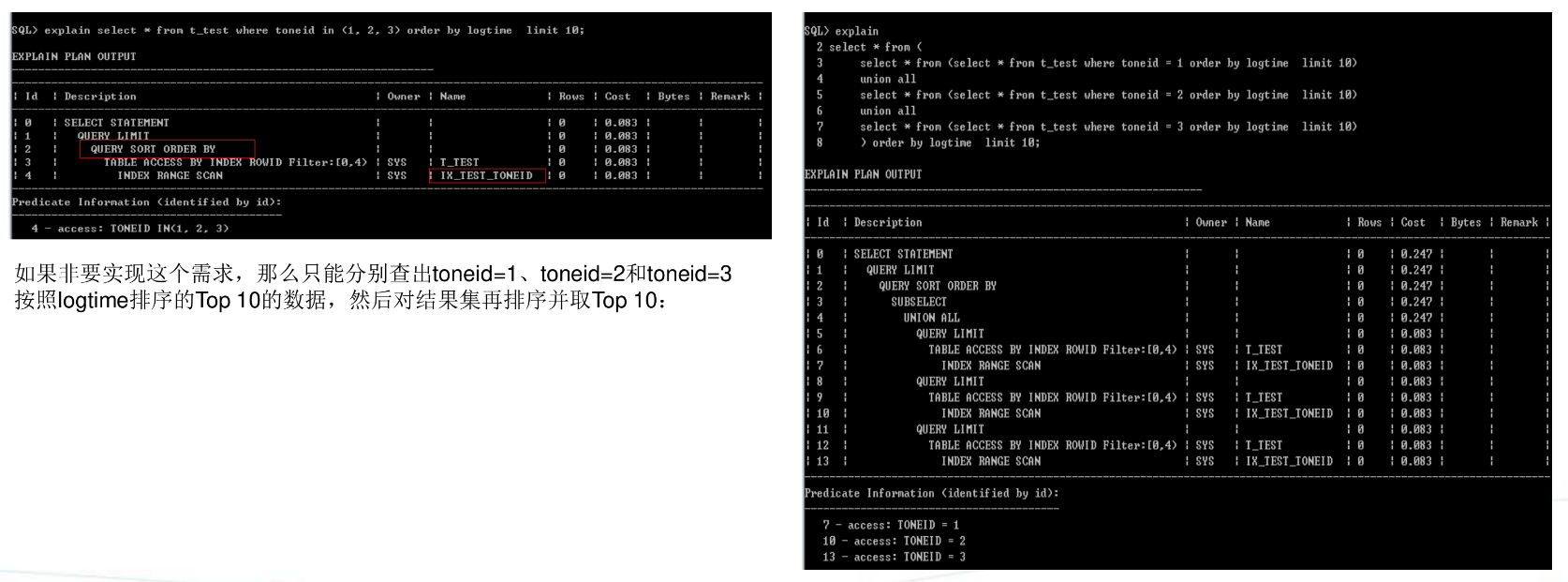
3)过滤条件是多值,同时安装分区字段倒序取Top 10数据
这种情况,走(toneid,logtime)是无法消除排序的,这是索引结构决定的,因为索引是按照toneid,logtime两个列的拼接值排序的,当查询条件是toneid in(1,2,3),实际是分别查询toneid=1、toneid=2、toneid=3,那么得到的结果无法直接获取按照logtime排序的Top 10的数据。多值无法查询用组合索引规避排序跟分区表没有关系,即使是普通表也是如此。
大表关联
-
使用并行提示
大表连接,小表和大表连接但结果集很大,这两种情况一般是使用hash join。
为了提升性能,可以使用并行,多个工作进程并发扫描大表。 -
两个超大表人工分区
超大表为了避免PGA不够,可以使用人工分析的方式
1)对连接列增加一个伪列,例如ora_hash(object_id, 4),把object_id哈希为0,1,2,3,4
2)使用这个伪列对两个表分区
3)分别对每个分区做hash join
select *
from p1, p2
where p1,.object_id=p2.object_id
and p1.hash_value=0
and p2.hash_value=0;
DBLINK优化
select * from a@dblink, b where a.id=b.id;
默认情况下,会将远端表a的数据传输到本地,然后再进行关联;

远端表a很大,对数据进行传输会耗费大量的时间,本地表b表很小,而且a和b关联之后返回数据量很少,我们可以将本地表b传输到远端,再远端进行关联,然后再将结果集传回本地,这时需要使用hint: driving_site
select /* + driving_site(a)/ from a@dblink, b where a.id = b.id;
select * from a@dblink, b where a.id=b.id;
默认情况下,会将远端表a的数据传输到本地,然后再进行关联;

远端表a很大,对数据进行传输会耗费大量时间,本地表b表很小,而且a和b关联之后返回数据量很少,我们可以将本地表b传输到远端,在远端进行关联,然后再将结果传回本地,这时需要使用hint:driving_site
select /* + driving_site(a) / from a@dblink, b where a.id = b.id;

对表进行ROWID切片,然后开启多个窗口同时执行SQL,这样既能加快执行速度,还能减少对UNDO的占用。
Oracle 提供一个内置函数DBMS_ROWID.ROWID_CREATE()用于生成ROWID。对于一个非分区表,一个表就是一个段(Segment),段是由多个区组成,每个区里面的块物理上是连续的。因此,我们可以根据数据字典DBA_EXTENTS,DBA_OBJECT关联,然后再利用生成ROWID的内置函数人工生成ROWID。

四、SQL优化实战案例

组合索引优化案例
-
问题现象
前台用户抱怨卡了一天,出现大量read by other session等待。 -
问题SQL
SELECT * FROM PRODDTA.F4111
WHERE((ILDCT = :1 AND ILFRTO = :2 AND ILMCU = :3 AND ILDOC = :4))
ORDER BY ILUKID ASC -
原因分析:
该SQL走的是ILMCU这个列的索引。
该表较大,表中一共有2510 970行数据。
ILMCU = :3的参数值是SF10,命中142万行数据。
这个错误的执行计划会导致产生大量的单独块。
并发时会产生read by other session的等待。
1)选择人的索引不合适
2)统计信息不准确导致选择了错误的索引
- 优化方案:
建立组合索引
Create index idx_F4111_docdctilmcufrto on F4111
(ILDOC, ILDCT, ILMCU, ILFRTO)online nologging;
如果A条件命中140万数据,B条件命中10万条数据,但是A和B组合条件只命中100条件数据,并且都是等值条件,那么应该创建A,B的组合索引。
直方图优化案例
-
问题现象
某个SQL执行了两个小时未完成。 -
问题 SQL
-
原因分析:
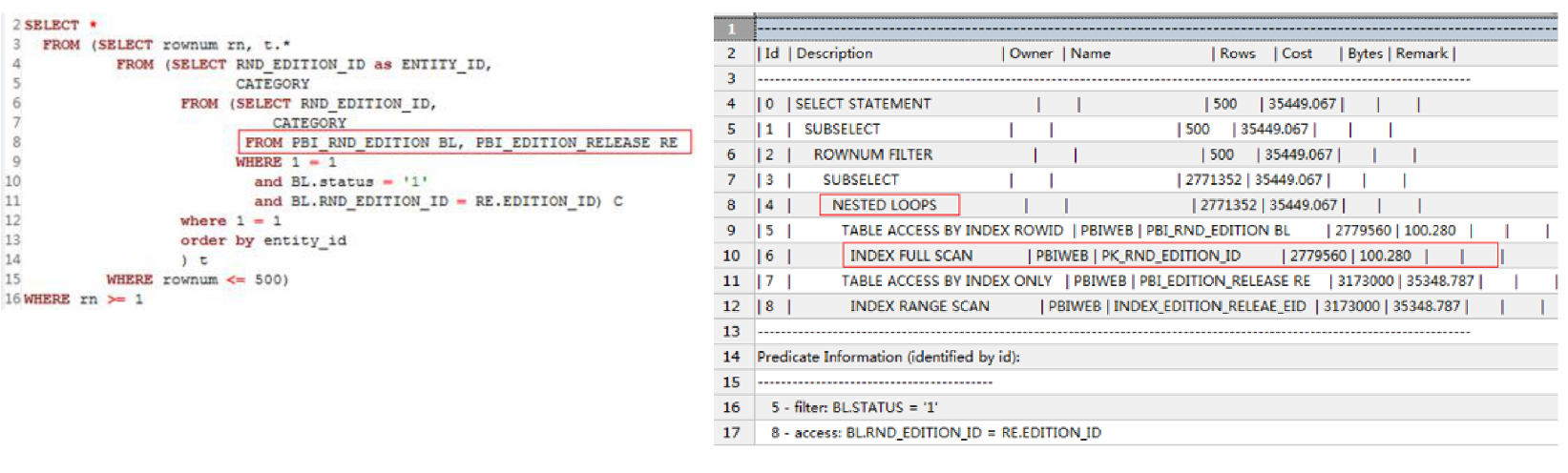
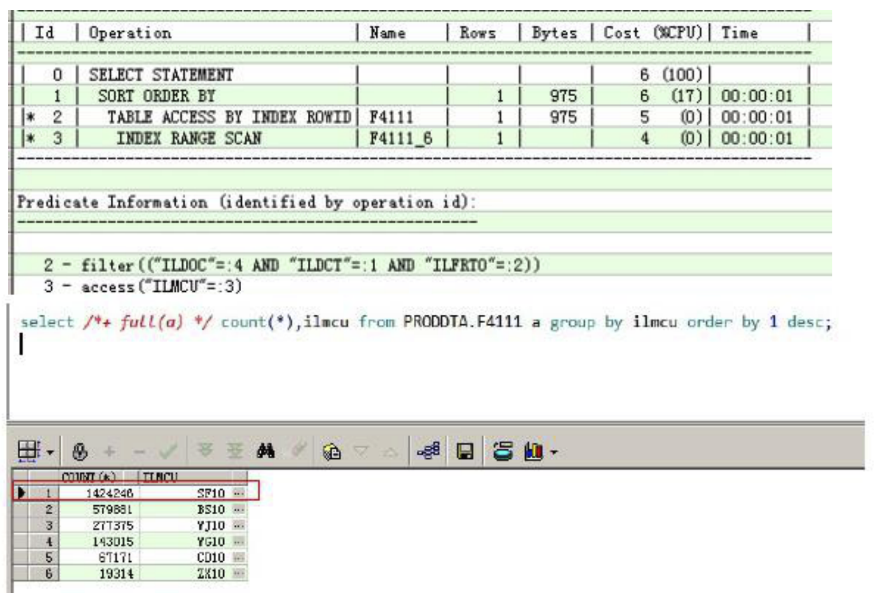
Id=4是执行计划的入口,它是嵌套循环的驱动表。CBO估算Id=4返回2967行数据。对于嵌套循环,我们首先要检查驱动表返回的真实行数是否与估算的行数有较大偏差。OPT_REF_UOM_TEMP_SDIM的总行数是2137706. “UOM”.”RELTV_CURR_QTY”=1实际返回946432行数据。


驱动表实际上返回了94万行数据,与估算的2967相差巨大。嵌套循环中,驱动表返回多少行数据,被驱动表就会被扫描多少次,这里被驱动表会被扫描94万次,这就解释了为什么SQL执行了两个小时还没执行成功。显然执行计划是错误的,应该走HASH连接。
统计信息中表总行数2160000行数据,与真实的行数(2137706)十分接近,这说明表的统计信息没有问题。RELTV_CURR_QTY列的基数等于728,没有直方图(HISTOGRAM=NONE)。为什么Id=4会估计返回2967行数据呢?正是因为RELTV_CURR_QTY列基数太低,而且没有收集直方图,CBO认为该数据分布是均衡的,导致再估算Rows的时候,直接以表总行数/列基数=216000/728=2967来进行估算。
- 优化方案
对RELTV_CURR_QTY列收集直方图。
嵌套循环内表的索引必须包含连接列
-
问题现象
AWR中的Top SQL -
问题SQL
-
原因分析
注意内表走了index skip scan,一般是不应该出现的。检查该索引的定义,没有包含连接列int_id
CREATE INDEX “HBRMW6”.”RMS_LOCALNET_POS_PUL”ON”HBRM W6”.”RMS_LOCALNET_POS”(“PRO_TASK_ID”, “STATEFLAG”)

嵌套循环内表的索引一定要包含连接列,如果只有过滤条件的索引就不应该选择嵌套循环,因为内表同样的数据要被扫描很多遍,不如选择hash join。
- 优化方案
在连接列上创建索引。
优化SQL需要注意表与表之间关系
-
问题现象
SQL执行不完 -
问题 SQL
-
原因分析
主查询中就是tb_trans与tab进行关联。tab一共返回6000多行数据,可以1秒内出结果,tb_trans有两亿条数据。执行计划中,tab作为嵌套循环驱动表,tb_trans作为嵌套循环被驱动表,也符合嵌套循环关联原则,小表驱动大表,大表走索引。 -
优化方案
因为被驱动表tb_trans与tab是几十万比1的关系,这时就不能走嵌套循环了,只能走HASH连接,于是使用HINT:use_hash(aa,bb)优化SQL,最终该SQL可以在1小时左右执行完毕。如果开启并查询可以更快。
INDEX FAST FULL SCAN优化案例
-
问题现象
某SQL最慢的时候要执行40分钟,最快的时候只需要几秒至十来秒就可以执行完毕。 -
问题SQL
-
原因分析
SYS_ACTIVATION_SDK_IOS_IDX1的索引列是(game_id, create_time, idfa)
T1返回11799条数据,T2返回1251009.性能问题出在T2的索引扫描上。 -
优化方案

- 书中给的方案是让T2走INDEX FAST FULL SCAN,最终该SQL可以在1分钟内执行完毕。
- 嵌套扫描其实也可以的,需要调整索引为(game_id, idfa, create_time),T2有三个条件:CREATE_TIME<TRUNC(sysdate) - 1 AND T2.GAME_ID = 153 AND T1.IDFA = T2.IDFA. 由于IDFA的重复度很高,为了避免在索引中做过滤,必须把三个列都加到索引中,由于CREATE_TIME不是等值查询,所以必须在最后。
分页语句优化案例
-
问题现象
分页查询没有消除排序,性能较差。 -
问题SQL
-
优化方案

- 分页语句只能对一个表的列进行排序。该SQL排序列来自f和os,并且显示的时候只有f表的数据。因此我们建议去掉os表的排序字段。
- 排序列来自f表,需要对f表创建索引,因为过滤条件是等值访问,我们可以把过滤条件放在前面,排序列放在后面,于是创建如下索引。
Create index idx_f_inf on inf_b2c_djwlzt_f(warehouse, is_send, create_dtm_loc); - 强制f表与os走嵌套循环,同时让f表作为嵌套循环驱动表,走刚才创建的索引。(非必要)
- 内表的连接列必须有索引:create index STATUSCODE_IDX on ORDERSTATUS(STATUSCODE);

ORDER BY 取别名列优化案例
-
问题现象
分页查询没有消除排序,性能较差。 -
问题 SQL
-
原因分析
SQL语句中order by的列crtd_dt在select中进行了to_char格式化,格式化之后取别名,但别名居然和列名一样。正因别名和列名一样,才导致无法消除SORT ORDER BY。 -
优化方案
重新起个别名to_char(npai.CRTD_DT, ‘yyyy-mm-dd hH24:mi:ss’) as CRTD_DT1.

半连接反向驱动主表案例
-
问题SQL
-
原因分析
子查询返回一个人开房的房号记录,共返回63行。该SQL就是查与某人相同的房间号的他人记录。LY_T_CHREC表有两亿条记录。
该SQL主表LY_T_CHREC有两亿条数据,没有过滤条件,IN子查询过滤之后返回63行数据,关联列是房间号(GCODE)。LY_T_CHREC应该是存放开房记录数据,GCODE列基数应该比较高。 -
优化方案
小表与大表关联,如果大表连接列基数比较高,可以走嵌套循环,让小表驱动大表,大表走连接列的索引。这里小表就是IN子查询,大表就是主表,我们让IN子查询作为NL驱动表。



树形查询优化案例
-
问题SQL
-
原因分析
执行计划中Id=7的谓词过滤中有绑定变量:B1,但是 SQL语句中并没有绑定变量。大家是否记得5.5讲到的:B1传值。执行计划中,Id=7谓词有绑定变量,这说明Id=7与Id=8一样,要被多次扫描。 -
优化方案
对于树形查询,很难通过 SQL改写减少start with子查询中表被多次扫描,所以只能想办法减少被扫描的体积。

标量子查询优化案例
-
问题 SQL
-
原因分析
该 SQL有7个标量子查询,在5.5中,标量子查询类似桥套循环,如果主表返回数据很多并且主表连接列基数很高,会导致子查询被多次扫描。该SQL竟然有7个标量子查询,而且每个标量子查询除了过滤条件不一样,其他都一样,显然我们可以将标量子查询等价改写为外连接,从而优化 SQL。 -
优化方案


五、SQL优化实战案例进阶

关联更新优化案例
-
问题SQL
UP DATE OPT_ACCT_FDIM A
SET ACCT_SKID = (SELECT ACCT_SKID
FROM OPT_ACCT_FDIM_BKP B
WHERE A.ACCT_ID = B.ACCT_ID); -
原因分析
UPDATE后面跟子查询类似嵌套循环,它的算法与标量子查询,Filter一模一样。也就是说OPT_ACCT_FDIM表相当于嵌套循环的驱动表,OPT_ACCT_FDIM_BKP相当于嵌套循环的被驱动表,那么这里表OPT_ACCT_FDIM_BKP就会被扫描20多万次。 -
优化方案
1)使用merge,可以以OPT_ACCT_FDIM_BKP为驱动表做嵌套循环,可以hash join,还可以并行

2)通过PLSQL方式
根据rowid更新;如果要更新的数据非常多,最好按照rowid排序;可以控制批量提交数量;使用BULK COKKECT 和 FORALL更新。
把你脑袋当CBO
-
问题SQL
-
原因分析
-
优化方案
最终添加如下HINT:/* +leading(a4) use_nl(a4,a3) use_nl(a3, a2) */
最终该SQL只需0.188秒 就能出结果,逻辑读从最开始的2539 920下降到14770。


扩展统计信息优化案例
-
原因分析
这个执行计划有两个问题
1)嵌套循环的内表不应该走全表扫描
2)执行计划Id=11,优化器评估返回5行数据,但是实际上返回了11248行数据,这导致后续表连接方式全采用了嵌套循环。 -
优化方案
1)根据过滤条件创建索引从而让NL被驱动表走索引
2)Id=11是两个表中两个列关联的结果集,优化器一般对多个列进行Rows估算的时候通常容易算错,于是对Id=11中两个表的连接列收集了扩展统计信息。 -
什么是扩展统计信息?
oracle11g在统计信息收集方面增加了扩展统计信息的特征,它可以收集一个表中相关列的统计信息,也可以收集函数表达式上的统计信息。使选择率,成本的估计更加准确。
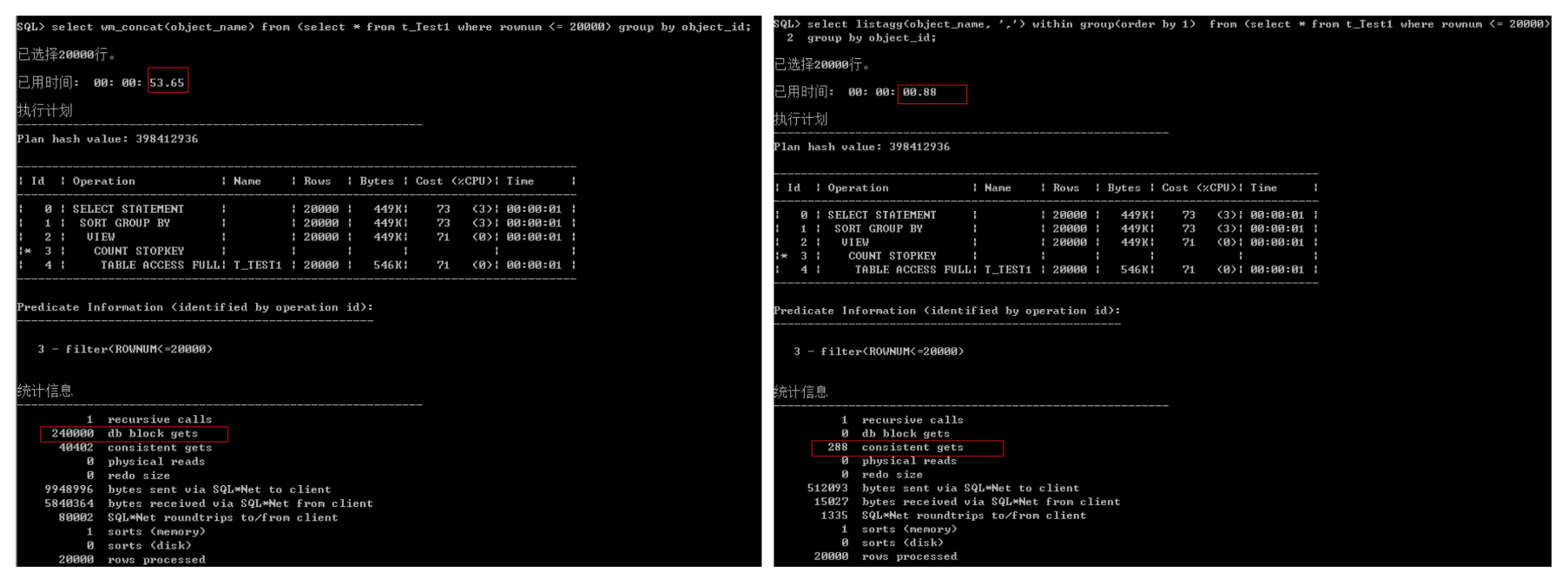
使用LISGAGG分析函数优化WM_CONCAT
- 原因分析
wm_concat返回的是CLOB类型,性能比较差,尽量使用Listagg代替。
子查询非嵌套优化案例
-
问题SQL
-
原因分析
1)执行计划中Id=12有TO_NUMBER(“TPF”.”RECEIV_STATUS”)=1,开发人员少写了引号,这可能导致SQL不走索引。

2)SQL语句中有个in子查询,并且子查询中有固化子查询关键子start with,in 子查询中有固化子查询关键字,子查询可以开展(unnest)。这个in子查询只返回1行数据,where子查询unnest之后,一般都会打乱执行计划。
- 优化方案
1)tpf.receiv_status = ‘1’增加引号以便可以走索引。
2)对子查询添加了HINT:NO_UNNEST,让子查询不展开,从而不去干扰执行计划;如果不想天开HINT,我们可以将in改成exists,因为子查询中有固化子查询关键字,这是SQL不能展开,会自动走Filter,也能达到添加HINT:NO_UNNEST的效果,但是,这并不是说exists比in性能好。
滥用外连接导致无法谓词推入
-
问题SQL
-
原因分析
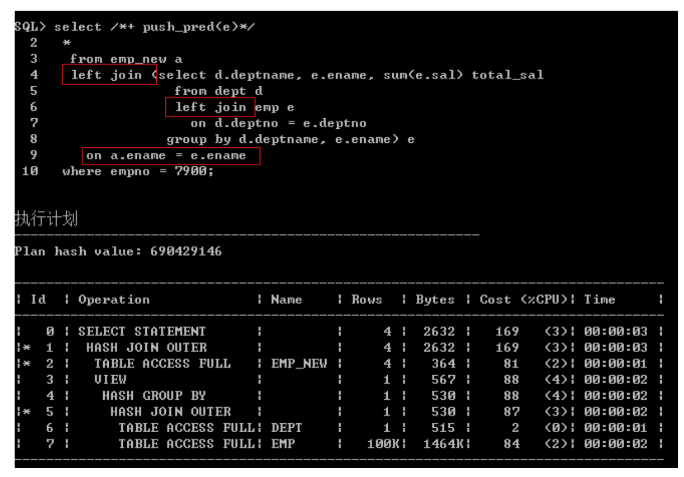
- 当视图中表关联是外连接,而且视图与其他表关联作为外连接从表,视图连接来自试图里面放的从表,此时不能谓词推入。
- 如果将外面的left join’改为inner join,a.ename = e.ename可以下推,此时内层实际也变成了inner join。
- 如果将内层的left join改为inner join,a.ename = e.ename可以下推。

使用CARDINALITY优化SQL
-
问题SQL
-
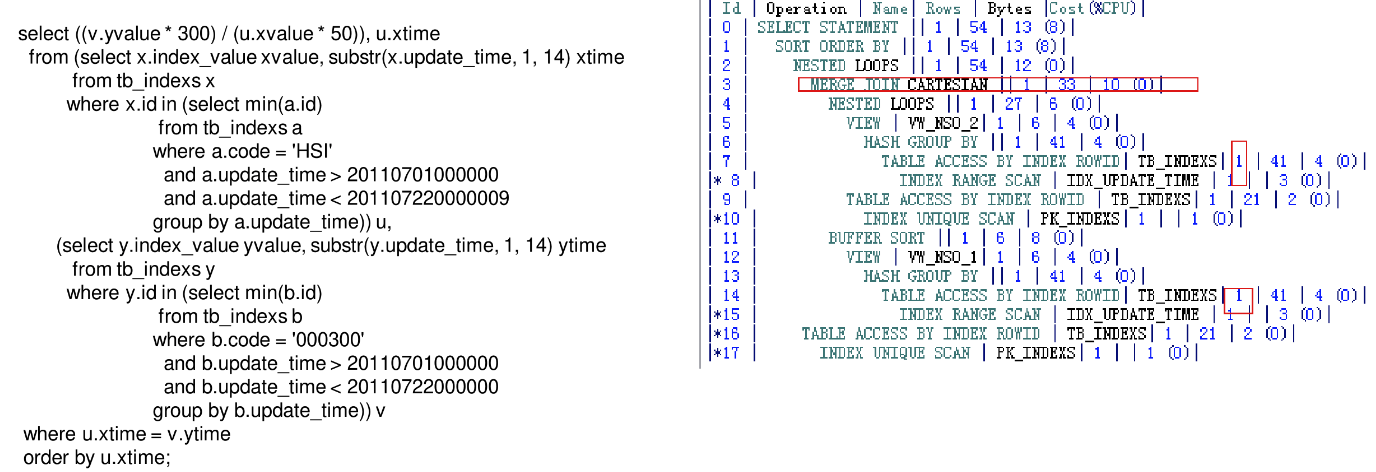
原因分析
执行计划中,Id=3是笛卡尔积,这就是为什么该SQL执行不出结果,为什么产生笛卡尔积呢?因为执行计划中所有的步骤Rows都估计返回为1行数据,
所以优化器选择人笛卡尔积连接。
为什么优化器会评估Id=8返回1行数据呢?这是因为字段UPDATE_TIME被设计为了NUMBER类型,而实际上UPDATA_TIME应该是DATE类型,同时where条件中还有一个选择性较低的过滤条件,优化器估算返回的行数等于表的总行数与UPDATE_TIME的选择性、CODE的选择性的乘积。 -
优化后的 SQL
-
怎么才可以让优化器知道正是Rows呢?我们可以使用HINT:CARDINALITY。/+cardinality(a 10000) /表示指定a表有1万行数据。/ + cardinality(@a 10000)/表示指定queryblock a 有1万行数据。或者使用动态采样,或者直接指定正确的连接方式。
SQL审核规则
-
外键没创建索引的表
建议在外键列上创建索引,外键列不创建索引容易导致死锁。级联删除的时候,外键列没有索引会导致表被全表扫描。 -
需要收集直方图的列
当余个表比较大,列选择性低于5%,而且列出现在where条件中,为了防止优化器Rows出现较大偏差,我们需要收集直方图。 -
必须创建索引的列
当一个表比较大,列选择性超过20%,列出现where条件中并且没有创建索引,我们可以对该列创建索引从而提升SQL查询性能。 -
抓出表被多次反复调用SQL
在开发过程中,我们应该避免在同一个SQL语句中对同一个表多次访问。我们可以通过下面SQL抓出同一个 SQL语句中对某个表进行多次扫描的SQL。 -
抓出走了FILTER的SQL
当where子查询没能unnest,执行计划中就会出现FILTER,对于此类SQL,我们应该在上线之前对其进行改写,避免执行计划中出现FILTER。 -
抓出返回行数较多的嵌套循环SQL
两表关联返回少量数据应该走嵌套循环,如果返回大量数据,应该走HASH连接,或者是排序合并连接。如果一个SQL语句返回行数较多(大于1万行),SQL的执行计划在最后几步(Id<=5)走了嵌套循环,我们可以判定该执行计划中的嵌套循环是有问题的,应该走HASH连接。 -
抓出NL被驱动表走了全表扫描的SQL
嵌套循环的被驱动表应该走索引。 -
抓出走了TABLE ACCESS FULL 的SQL
如果一个大表走了全表扫描,会严重影响SQL性能。 -
抓出走了INDEX FULL SCAN的SQL
INDEX FULL SCAN会扫描索引中所有的叶子块,单块读。如果索引很大,执行计划中出现了INDEX FULL SCAN,这时SQL会出现严重的性能问题。 -
抓出走了INDEX SKIP SCAN的SQL
当执行计划中出现了 INDEX SKIP SCAN,通常说明需要额外添加一个索引。 -
抓出索引被哪些SQL引用
有时开发人员可能会胡乱建立一些索引,但是这些索引在数据块中可能并不会被任何一个SQL使用。这样的索引会增加维护成本,我们可以将其删掉。 -
抓出走了笛卡尔积的 SQL
当两表没有关联条件的时候就会走笛卡尔积,当Rows被估算为1的时候,也可能走笛卡尔积连接。 -
抓出走了错误的排序合并连接的SQL
排序合并连接一般用于非等值关联,如果两表是等值关联,我们建议使用HASH连接代替排序合并连接,因为HASH连接只需要将驱动表放入PGA中,而排序合并连接要么是将两个表放入PGA中,要么是将一个表放入PGA中,另外一个表走INDEX FULL SCAN,然后回表。如果两表是等值关联并且两表比较大,这时应该走HASH连接而不是排序合并连接。 -
抓出走了低选择性索引的 SQL
如果一个搜呀选择性很低,说明列数据分布不平衡。当SQL走了数据分布不均衡列的索引,很容易走错执行计划,此时我们应该检查SQL语句中是否有其他过滤条件,如果有其他过滤条件,可以考虑建立组合索引,将选择性高的列作为引导列。 -
抓出可以创建组合索引的SQL(回表再过来选择性高的列)
回表次数太多会严重影响SQL性能。让执行计划中发生了回表再过滤字段的选择性比较高,我们可以将过来字段包含再索引中避免回表再过过滤。从而减少回表次数,提升查询性能。 -
抓出可以创建组合索引的 SQL(回表只访问少数字段)
回表次数太多会严重影响SQL性能。当SQL走索引回表只访问表中少部分字段,我们可以将这些字段与过滤条件组合起来建立为一个组合索引,这样就能避免会表,从而提升查询性能。
本文参与华为云社区【内容共创】活动第17期。
https://bbs.huaweicloud.cn/blogs/358780
任务29:云享读书会《SQL优化核心思想》

- 点赞
- 收藏
- 关注作者
评论(0)