华为云原生Kubernetes之运行Volcano高性能作业的深度使用和实践【与云原生的故事】

【摘要】 Volcano是CNCF下基于Kubernetes的容器批量计算平台,那么,Volcano到底是什么?Volcano有哪些特性?Volcano的系统架构和应用场景有哪些?如何安装Volcano?如何使用Volcano CRD资源?Kubernetes 运行作业时有哪些问题,该怎么解决?以及Volcano具体应用场景的如何实践操作?带着这些问题,我们一起去一探究竟,玩转Volcano!
一、Volcano 简介
① 什么是 Volcano ?
- Volcano 是 CNCF 下首个也是唯一的基于 Kubernetes 的容器批量计算平台,主要用于高性能计算场景,提供了机器学习、深度学习、生物信息学、基因组学及其他大数据应用所需要而 Kubernetes 当前缺失的一系列特性。
- Volcano 提供高性能任务调度引擎、高性能异构芯片管理、高性能任务运行管理等通用计算能力,通过接入 AI、大数据、基因、渲染等诸多行业计算框架服务终端用户。
- Volcano 针对计算型应用提供了作业调度、作业管理、队列管理等多项功能,主要特性包括:
-
- 丰富的计算框架支持:通过 CRD 提供了批量计算任务的通用 API,通过提供丰富的插件及作业生命周期高级管理,支持 TensorFlow,MPI,Spark 等计算框架容器化运行在 Kubernetes 上;
-
- 高级调度:面向批量计算、高性能计算场景提供丰富的高级调度能力,包括成组调度,优先级抢占、装箱、资源预留、任务拓扑关系等;
-
- 队列管理:支持分队列调度,提供队列优先级、多级队列等复杂任务调度能力。
② Volcano 的特性
- Volcano 支持各种调度策略,包括 Gang-scheduling、Fair-share scheduling、Queue scheduling、Preemption scheduling、Topology-based scheduling、Reclaims、Backfill、Resource Reservation 等,得益于可扩展性的架构设计,Volcano 支持用户自定义 plugin 和 action 以支持更多调度算法;
- Volcano 提供了增强型的 Job 管理能力以适配高性能计算场景,如多 pod 类型job、增强型的异常处理、可索引 Job;
- Volcano 提供了基于多种架构的计算资源的混合调度能力:如 x86、ARM、鲲鹏、昇腾、GPU;
- Volcano 已经支持几乎所有的主流计算框架:Spark、TensorFlow、PyTorch、Flink、Argo、MindSpore、PaddlePaddle、OpenMPI、Horovod、mxnet、Kubeflow、KubeGene、Cromwell 等。
③ Volcano 的系统架构
- Volcano 与 Kubernetes 天然兼容,并为高性能计算而生,它遵循 Kubernetes 的设计理念和风格,如下所示:
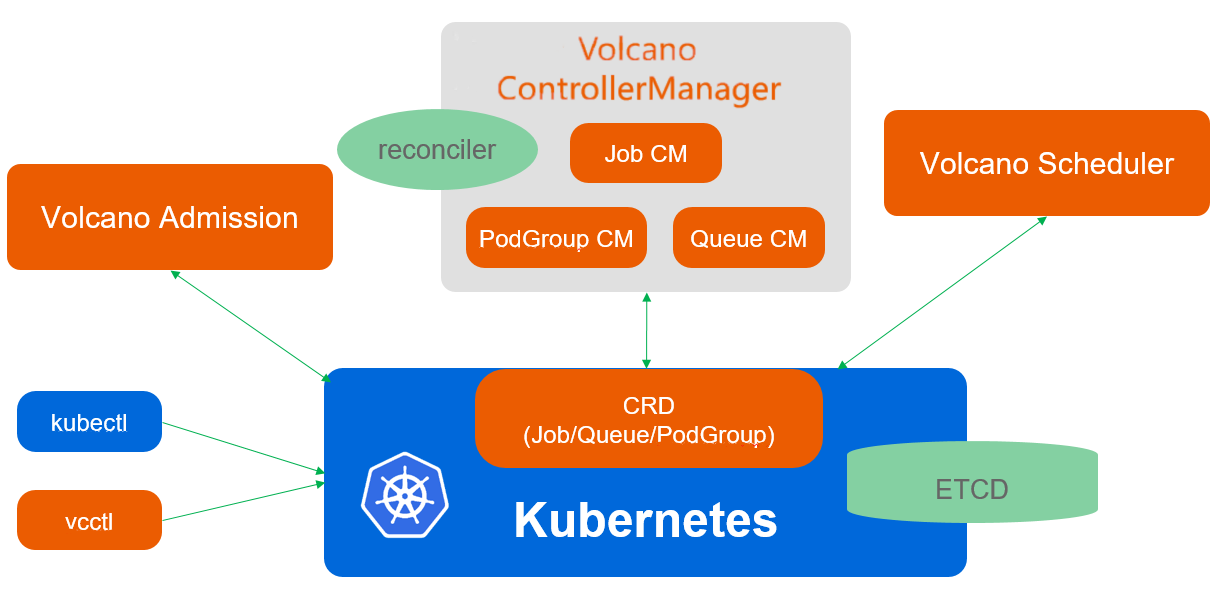
- Volcano 由 scheduler、controllermanager、admission 和 vcctl 组成:
-
- Scheduler Volcano scheduler 通过一系列的 action 和 plugin 调度Job,并为它找到一个最适合的节点,与 Kubernetes default-scheduler 相比,Volcano 与众不同的地方是它支持针对 Job 的多种调度算法;
-
- Controllermanager Volcano controllermanager 管理 CRD 资源的生命周期,它主要由 Queue ControllerManager、 PodGroupControllerManager、 VCJob ControllerManager 构成;
-
- Admission Volcano admission 负责对 CRD API 资源进行校验;
-
- Vcctl Volcano vcctl 是 Volcano 的命令行客户端工具。
④ Volcano 的应用场景
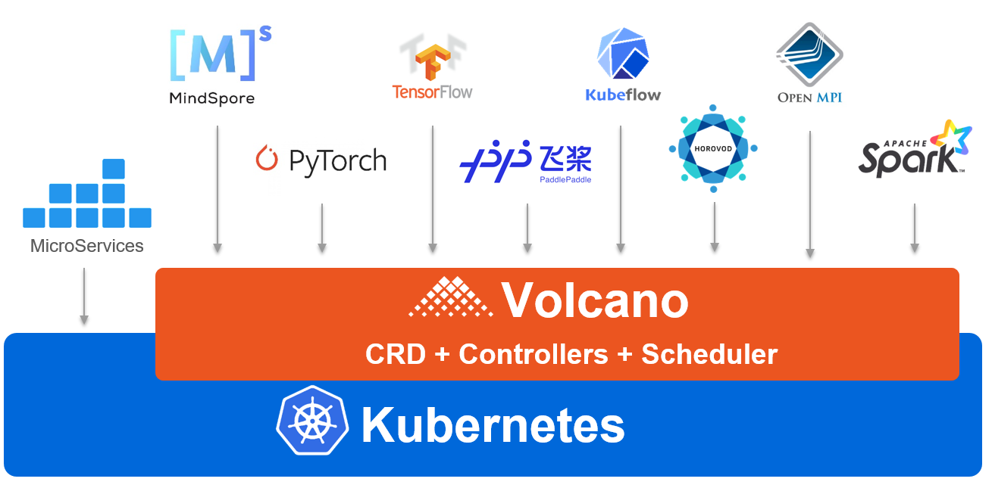
⑤ Volcano 的安装
(A)通过 Deployment Yaml 安装
- Deployment Yaml 安装方式支持 x86_64/arm64 两种架构,在 kubernetes 集群上,执行如下的 kubectl 指令:
For x86_64:
kubectl apply -f https://raw.githubusercontent.com/volcano-sh/volcano/master/installer/volcano-development.yaml
For arm64:
kubectl apply -f https://raw.githubusercontent.com/volcano-sh/volcano/master/installer/volcano-development-arm64.yaml
- 也可以将 master 替换为指定的标签或者分支(比如 release-1.5 分支表示最新的 v1.5.x 版本,v1.5.1 标签表示 v1.5.1 版本)以安装指定的 Volcano 版本。
(B)通过源代码安装
- 如果没有 kubernetes 集群,可以选择在 github 下载 volcano 源代码压缩包,解压后运行 volcano 的安装脚本,这种安装方式暂时只支持 x86_64 平台:
# git clone https://github.com/volcano-sh/volcano.git
# tar -xvf volcano-{Version}-linux-gnu.tar.gz
# cd volcano-{Version}-linux-gnu
# ./hack/local-up-volcano.sh
(C)通过 Helm 安装
- 在集群中下载 Helm,可以根据以下指南安装 Helm:[https://helm.sh/docs/intro/](安装 Helm)(仅当使用 Helm 模式进行安装时需要)。
- 如果想使用 Helm 部署 Volcano,请先确认已经在集群中安装了 Helm。
- 创建一个新的命名空间:
# kubectl create namespace volcano-system
namespace/volcano-system created
- 使用 Helm 进行安装:
# helm install helm/chart/volcano --namespace volcano-system --name volcano
NAME: volcano
LAST DEPLOYED: Tue Jul 23 20:07:29 2019
NAMESPACE: volcano-system
STATUS: DEPLOYED
RESOURCES:
==> v1/ClusterRole
NAME AGE
volcano-admission 1s
volcano-controllers 1s
volcano-scheduler 1s
==> v1/ClusterRoleBinding
NAME AGE
volcano-admission-role 1s
volcano-controllers-role 1s
volcano-scheduler-role 1s
==> v1/ConfigMap
NAME DATA AGE
volcano-scheduler-configmap 2 1s
==> v1/Deployment
NAME READY UP-TO-DATE AVAILABLE AGE
volcano-admission 0/1 1 0 1s
volcano-controllers 0/1 1 0 1s
volcano-scheduler 0/1 1 0 1s
==> v1/Job
NAME COMPLETIONS DURATION AGE
volcano-admission-init 0/1 1s 1s
==> v1/Pod(related)
NAME READY STATUS RESTARTS AGE
volcano-admission-b45b7b76-84jmw 0/1 ContainerCreating 0 1s
volcano-admission-init-fw47j 0/1 ContainerCreating 0 1s
volcano-controllers-5f66f8d76c-27584 0/1 ContainerCreating 0 1s
volcano-scheduler-bb4467966-z642p 0/1 Pending 0 1s
==> v1/Service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
volcano-admission-service ClusterIP 10.107.128.208 <none> 443/TCP 1s
==> v1/ServiceAccount
NAME SECRETS AGE
volcano-admission 1 1s
volcano-controllers 1 1s
volcano-scheduler 1 1s
==> v1beta1/CustomResourceDefinition
NAME AGE
podgroups.scheduling.sigs.dev 1s
queues.scheduling.sigs.dev 1s
NOTES:
Thank you for installing volcano.
Your release is named volcano.
For more information on volcano, visit:
https://volcano.sh/
- 验证 Volcano 组件的状态:
# kubectl get all -n volcano-system
NAME READY STATUS RESTARTS AGE
pod/volcano-admission-5bd5756f79-p89tx 1/1 Running 0 6m10s
pod/volcano-admission-init-d4dns 0/1 Completed 0 6m10s
pod/volcano-controllers-687948d9c8-bd28m 1/1 Running 0 6m10s
pod/volcano-scheduler-94998fc64-9df5g 1/1 Running 0 6m10s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/volcano-admission-service ClusterIP 10.96.140.22 <none> 443/TCP 6m10s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/volcano-admission 1/1 1 1 6m10s
deployment.apps/volcano-controllers 1/1 1 1 6m10s
deployment.apps/volcano-scheduler 1/1 1 1 6m10s
NAME DESIRED CURRENT READY AGE
replicaset.apps/volcano-admission-5bd5756f79 1 1 1 6m10s
replicaset.apps/volcano-controllers-687948d9c8 1 1 1 6m10s
replicaset.apps/volcano-scheduler-94998fc64 1 1 1 6m10s
NAME COMPLETIONS DURATION AGE
job.batch/volcano-admission-init 1/1 28s 6m10s
⑥ 使用 Volcano CRD 资源
- 创建一个名为 “test” 的自定义队列:
# cat <<EOF | kubectl apply -f -
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: test
spec:
weight: 1
reclaimable: false
capability:
cpu: 2
EOF
- 创建一个名为 “job-1” 的 Volcano Job:
# cat <<EOF | kubectl apply -f -
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: job-1
spec:
minAvailable: 1
schedulerName: volcano
queue: test
policies:
- event: PodEvicted
action: RestartJob
tasks:
- replicas: 1
name: nginx
policies:
- event: TaskCompleted
action: CompleteJob
template:
spec:
containers:
- command:
- sleep
- 10m
image: nginx:latest
name: nginx
resources:
requests:
cpu: 1
limits:
cpu: 1
restartPolicy: Never
EOF
- 检查自定义 job 的状态:
# kubectl get vcjob job-1 -oyaml
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
creationTimestamp: "2022-05-18T12:59:37Z"
generation: 1
managedFields:
- apiVersion: batch.volcano.sh/v1alpha1
fieldsType: FieldsV1
fieldsV1:
f:spec:
.: {}
f:minAvailable: {}
f:policies: {}
f:queue: {}
f:schedulerName: {}
manager: kubectl
operation: Update
time: "2022-05-18T12:59:37Z"
- apiVersion: batch.volcano.sh/v1alpha1
fieldsType: FieldsV1
fieldsV1:
f:spec:
f:tasks: {}
f:status:
.: {}
f:minAvailable: {}
f:running: {}
f:state:
.: {}
f:lastTransitionTime: {}
f:phase: {}
manager: vc-controller-manager
operation: Update
time: "2022-05-18T12:59:45Z"
name: job-1
namespace: default
resourceVersion: "850500"
selfLink: /apis/batch.volcano.sh/v1alpha1/namespaces/default/jobs/job-1
uid: 215409ec-7337-4abf-8bea-e6419defd688
spec:
minAvailable: 1
policies:
- action: RestartJob
event: PodEvicted
queue: test
schedulerName: volcano
tasks:
- name: nginx
policies:
- action: CompleteJob
event: TaskCompleted
replicas: 1
template:
spec:
containers:
- command:
- sleep
- 10m
image: nginx:latest
name: nginx
resources:
limits:
cpu: 1
requests:
cpu: 1
status:
minAvailable: 1
running: 1
state:
lastTransitionTime: "2022-05-18T12:59:45Z"
phase: Running
- 检查名为 ”job-1“ 的 PodGroup 的状态:
# kubectl get podgroup job-1 -oyaml
apiVersion: scheduling.volcano.sh/v1beta1
kind: PodGroup
metadata:
creationTimestamp: "2022-05-18T12:59:37Z"
generation: 5
managedFields:
- apiVersion: scheduling.volcano.sh/v1beta1
fieldsType: FieldsV1
fieldsV1:
f:metadata:
f:ownerReferences:
.: {}
k:{"uid":"215409ec-7337-4abf-8bea-e6419defd688"}:
.: {}
f:apiVersion: {}
f:blockOwnerDeletion: {}
f:controller: {}
f:kind: {}
f:name: {}
f:uid: {}
f:spec:
.: {}
f:minMember: {}
f:minResources:
.: {}
f:cpu: {}
f:queue: {}
f:status: {}
manager: vc-controller-manager
operation: Update
time: "2022-05-18T12:59:37Z"
- apiVersion: scheduling.volcano.sh/v1beta1
fieldsType: FieldsV1
fieldsV1:
f:status:
f:conditions: {}
f:phase: {}
f:running: {}
manager: vc-scheduler
operation: Update
time: "2022-05-18T12:59:45Z"
name: job-1
namespace: default
ownerReferences:
- apiVersion: batch.volcano.sh/v1alpha1
blockOwnerDeletion: true
controller: true
kind: Job
name: job-1
uid: 215409ec-7337-4abf-8bea-e6419defd688
resourceVersion: "850501"
selfLink: /apis/scheduling.volcano.sh/v1beta1/namespaces/default/podgroups/job-1
uid: ea5b4f87-b750-440b-a41a-5c9944a7ae43
spec:
minMember: 1
minResources:
cpu: "1"
queue: test
status:
conditions:
- lastTransitionTime: "2022-05-18T12:59:38Z"
message: '1/0 tasks in gang unschedulable: pod group is not ready, 1 minAvailable.'
reason: NotEnoughResources
status: "True"
transitionID: 606145d1-660f-4e01-850d-ed556cebc098
type: Unschedulable
- lastTransitionTime: "2022-05-18T12:59:45Z"
reason: tasks in gang are ready to be scheduled
status: "True"
transitionID: 57e6ba9e-55cc-47ce-a37e-d8bddd99d54b
type: Scheduled
phase: Running
running: 1
- 检查队列 “test” 的状态:
# kubectl get queue test -oyaml
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
creationTimestamp: "2022-05-18T12:59:30Z"
generation: 1
managedFields:
- apiVersion: scheduling.volcano.sh/v1beta1
fieldsType: FieldsV1
fieldsV1:
f:spec:
.: {}
f:capability: {}
f:reclaimable: {}
f:weight: {}
manager: kubectl
operation: Update
time: "2022-05-18T12:59:30Z"
- apiVersion: scheduling.volcano.sh/v1beta1
fieldsType: FieldsV1
fieldsV1:
f:spec:
f:capability:
f:cpu: {}
f:status:
.: {}
f:running: {}
f:state: {}
manager: vc-controller-manager
operation: Update
time: "2022-05-18T12:59:39Z"
name: test
resourceVersion: "850474"
selfLink: /apis/scheduling.volcano.sh/v1beta1/queues/test
uid: b9c9ee54-5ef8-4784-9bec-7a665acb1fde
spec:
capability:
cpu: 2
reclaimable: false
weight: 1
status:
running: 1
state: Open
二、Kubernetes 运行作业的问题分析及解决方案
① 报错 cannot allocate memory 或者 no space left on device,修复 Kubernetes 内存泄露问题
(A)问题描述和分析
- 当 Kubernetes 集群运行日久以后,有的 Node 无法再新建 Pod,并且出现如下错误,当重启服务器之后,才可以恢复正常使用,查看 Pod 状态的时候会出现以下报错:
applying cgroup … caused: mkdir …no space left on device
或者在 describe pod 的时候出现 cannot allocate memory
- 这时候 Kubernetes 集群可能就存在内存泄露的问题,当创建的 Pod 越多的时候内存会泄露的越多越快。具体查看是否存在内存泄露:
cat /sys/fs/cgroup/memory/kubepods/memory.kmem.slabinfo
当出现 cat: /sys/fs/cgroup/memory/kubepods/memory.kmem.slabinfo: Input/output error 则说明不存在内存泄露的情况
如果存在内存泄露会出现
slabinfo - version: 2.1
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
(B)解决方案
- 可以考虑关闭 runc 和 kubelet 的 kmem,因为升级内核的方案改动较大,此处不采用。
- kmem 导致内存泄露的原因:内核对于每个 cgroup 子系统的的条目数是有限制的,限制的大小定义在 kernel/cgroup.c #L139,当正常在 cgroup 创建一个 group 的目录时,条目数就加 1。
- 我们遇到的情况就是因为开启 kmem accounting 功能,虽然 cgroup 的目录删除,但是条目没有回收,这样后面就无法创建 65535 个 cgroup。也就是说,在当前内核版本下,开启 kmem accounting 功能,会导致 memory cgroup 的条目泄漏无法回收。
(C)具体实现
- 需要重新编译 runc:
-
- 配置 go 语言环境:
wget https://dl.google.com/go/go1.12.9.linux-amd64.tar.gz
tar xf go1.12.9.linux-amd64.tar.gz -C /usr/local/
写入 bashrc
vim ~/.bashrc
export GOPATH="/data/Documents"
export GOROOT="/usr/local/go"
export PATH="$GOROOT/bin:$GOPATH/bin:$PATH"
export GO111MODULE=off
验证
source ~/.bashrc
go env
-
- 下载 runc 源码:
mkdir -p /data/Documents/src/github.com/opencontainers/
cd /data/Documents/src/github.com/opencontainers/
git clone https://github.com/opencontainers/runc
cd runc/
git checkout v1.0.0-rc9 # 切到 v1.0.0-rc9 tag
-
- 编译:
安装编译组件
sudo yum install libseccomp-devel
make BUILDTAGS='seccomp nokmem'
编译完成之后会在当前目录下看到一个runc的可执行文件,等kubelet编译完成之后会将其替换
- 编译 kubelet:
-
- 下载 Kubernetes 源码:
mkdir -p /root/k8s/
cd /root/k8s/
git clone https://github.com/kubernetes/kubernetes
cd kubernetes/
git checkout v1.15.3
-
- 制作编译环境的镜像 Dockerfile 如下:
FROM centos:centos7.3.1611
ENV GOROOT /usr/local/go
ENV GOPATH /usr/local/gopath
ENV PATH /usr/local/go/bin:$PATH
RUN yum install rpm-build which where rsync gcc gcc-c++ automake autoconf libtool make -y \
&& curl -L https://studygolang.com/dl/golang/go1.12.9.linux-amd64.tar.gz | tar zxvf - -C /usr/local
-
- 在制作好的 go 环境镜像中来进行编译 kubelet:
docker run -it --rm -v /root/k8s/kubernetes:/usr/local/gopath/src/k8s.io/kubernetes build-k8s:centos-7.3-go-1.12.9-k8s-1.15.3 bash
cd /usr/local/gopath/src/k8s.io/kubernetes
# 编译
GO111MODULE=off KUBE_GIT_TREE_STATE=clean KUBE_GIT_VERSION=v1.15.3 make kubelet GOFLAGS="-tags=nokmem"
- 替换原有的 runc 和 kubelet:
-
- 将原有 runc 和 kubelet 备份:
mv /usr/bin/kubelet /home/kubelet
mv /usr/bin/docker-runc /home/docker-runc
-
- 停止 Docker 和 kubelet:
systemctl stop docker
systemctl stop kubelet
-
- 将编译好的 runc 和 kubelet 进行替换:
cp kubelet /usr/bin/kubelet
cp kubelet /usr/local/bin/kubelet
cp runc /usr/bin/docker-runc
-
- 检查 kmem 是否关闭前需要将此节点的 Pod 杀掉重启或者重启服务器,当结果为 0 时成功:
cat /sys/fs/cgroup/memory/kubepods/burstable/memory.kmem.usage_in_bytes
-
- 是否还存在内存泄露的情况:
cat /sys/fs/cgroup/memory/kubepods/memory.kmem.slabinfo
② Kubernetes 证书过期问题的解决
(A)问题分析
- 出现 Kubernetes API 无法调取的现象,使用 kubectl 命令获取资源均返回如下报错:
Unable to connect to the server: x509: certificate has expired or is not yet valid
- 可以猜测 Kubernetes 集群的证书过期,使用命令排查证书的过期时间:
kubeadm alpha certs check-expiration
(B)问题解决
- 由于使用 kubeadm 部署的 Kubernetes 集群,所以更新起证书也是比较方便的,默认的证书时间有效期是一年,集群的 Kubernetes 版本是 1.15.3版本是可以使用以下命令来更新证书的,但是一年之后还是会到期,这样就很麻烦,所以需要了解一下 Kubernetes 的证书,然后来生成一个时间很长的证书,这样就可以不用去总更新证书:
kubeadm alpha certs renew all --config=kubeadm.yaml
systemctl restart kubelet
kubeadm init phase kubeconfig all --config kubeadm.yaml
然后将生成的配置文件替换,重启 kube-apiserver、kube-controller、kube-scheduler、etcd 这 4 个容器即可
- 另外 kubeadm 会在控制面板升级的时候自动更新所有证书,所以使用 kubeadm 搭建得集群最佳的做法是经常升级集群,这样可以确保集群保持最新状态并保持合理的安全性。但是对于实际的生产环境我们可能并不会去频繁得升级集群,所以这个时候就需要去手动更新证书:
首先在/etc/kubernetes/manifests/kube-controller-manager.yaml文件加入配置
spec:
containers:
- command:
- kube-controller-manager
# 设置证书有效期为10年
- --experimental-cluster-signing-duration=87600h
- --client-ca-file=/etc/kubernetes/pki/ca.crt
- 修改完成后 kube-controller-manager 会自动重启生效,然后需要使用下面的命令为 Kubernetes 证书 API 创建一个证书签名请求,如果设置例如 cert-manager 等外部签名者,则会自动批准证书签名请求(CSRs)。否者,必须使用 kubectl certificate 命令手动批准证书,以下 kubeadm 命令输出要批准的证书名称,然后等待批准发生。如下所示,通过调用 Kubernetes 的 API 来实现更新一个 10 年的证书:
kubeadm alpha certs renew all --use-api --config kubeadm.yaml &
- 需要将全部 pending 的证书全部批准,还不能直接重启控制面板的几个组件,这是因为使用 kubeadm 安装的集群对应的 etcd 默认是使用的 /etc/kubernetes/pki/etcd/ca.crt 这个证书进行前面的,而上面用命令 kubectl certificate approve 批准过后的证书是使用的默认的 /etc/kubernetes/pki/ca.crt 证书进行签发的,因此需要替换 etcd 中的 CA 机构证书:
# 先拷贝静态Pod资源清单
cp -r /etc/kubernetes/manifests/ /etc/kubernetes/manifests.bak
vi /etc/kubernetes/manifests/etcd.yaml
......
spec:
containers:
- command:
- etcd
# 修改为CA文件
- --peer-trusted-ca-file=/etc/kubernetes/pki/ca.crt
- --trusted-ca-file=/etc/kubernetes/pki/ca.crt
......
volumeMounts:
- mountPath: /var/lib/etcd
name: etcd-data
- mountPath: /etc/kubernetes/pki # 更改证书目录
name: etcd-certs
volumes:
- hostPath:
path: /etc/kubernetes/pki # 将 pki 目录挂载到etcd中去
type: DirectoryOrCreate
name: etcd-certs
- hostPath:
path: /var/lib/etcd
type: DirectoryOrCreate
name: etcd-data
......
- 由于 kube-apiserver 要连接 etcd 集群,因此也需要重新修改对应的 etcd ca 文件:
vi /etc/kubernetes/manifests/kube-apiserver.yaml
......
spec:
containers:
- command:
- kube-apiserver
# 将etcd ca文件修改为默认的ca.crt文件
- --etcd-cafile=/etc/kubernetes/pki/ca.crt
......
- 除此之外还需要替换 requestheader-client-ca-file 文件,默认是 /etc/kubernetes/pki/front-proxy-ca.crt 文件,现在也需要替换成默认的 CA 文件,否则使用聚合 API,比如安装 metrics-server 后执行 kubectl top 命令就会报错:
cp /etc/kubernetes/pki/ca.crt /etc/kubernetes/pki/front-proxy-ca.crt
cp /etc/kubernetes/pki/ca.key /etc/kubernetes/pki/front-proxy-ca.key
- 这样就得到了一个 10 年证书的 Kubernetes 集群,还可以通过重新编译 kubeadm 来实现一个 10 年证书。
三、Volcano 容器在气象行业 HPC 高性能计算场景的应用
① 什么是 HPC ?
- HPC 是 High Performance Computing(高性能计算)的缩写,平时提到的 HPC,一般指代高性能计算机群(HPCC),它将大量的计算机软件/硬件整合起来,将大的计算作业分解成一个个小部分,通过并行计算的方式加以解决。HPC 高性能计算在 CAE 仿真、动漫渲染、物理化学、石油勘探、生命科学、气象环境等领域有广泛的应用。
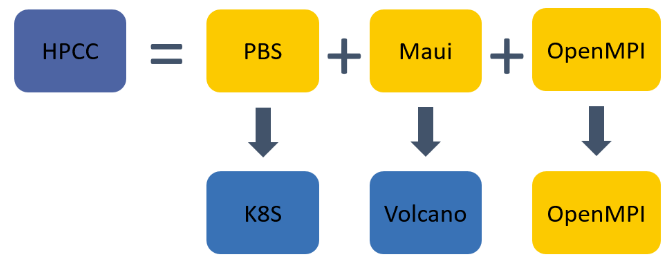
- 一般来说,高性能计算集群(HPCC)包含如下部分:
-
- PBS:Protable Batch System,资源管理器,负责管理集群中所有节点的资源,除了 PBS 意外,常用的资源管理系统还有 Slurm,LSF 等;
-
- Maui:第三方任务调度器,支持资源预留,支持各种复杂的优先级策略,支持抢占机制等,资源管理器中内置了默认的任务调取器,但功能往往比较简单;
-
- OpenMPI:上层通信环境,兼顾通信库,编译,分布式启动任务的功能。

- PBS 和 Maui 对于用户来说是完全透明的,用户只需要按照 PBS 提供的方式提交作业即可,不需要了解内部细节,而 OpenMPI 则需要用户进行相关了解,来编写能够并行计算的应用。
- 以 mpirun -np 4 ./mpi_hello_world 为例介绍 mpi 作业是如何运行的:
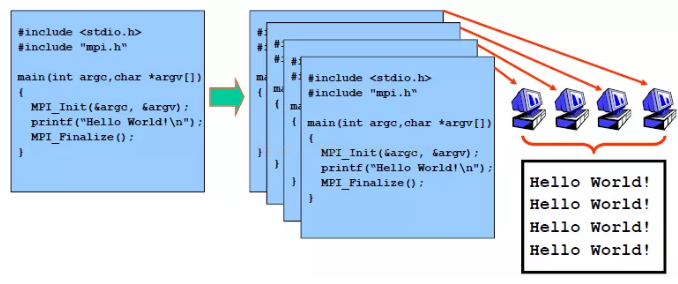
- 说明:
-
- 调用 openmpi 或者其他 mpi 的库来编写源代码,示例就是输出 hello world 字符串;
-
- 使用支持 MPI 的编译器来编译出可执行程序 mpi_hello_world;
-
- 将 mpi_hello_world 分发到各个节点,也可以通过共享文件系统来实现对 mpi_hello_world 的访问;
-
- 运行 mpirun 来并行执行 mpi_hello_world。
② 什么是 WRF ?
- WRF 是 Weather Research and Forecasting Model(天气研究和预报模型)的简称,是一种比较常见的 HPC 应用,WRF 是一种中尺度数值天气预报系统,设计用于大气研究和业务预报应用,可以根据实际的大气条件或理想化的条件进行模拟。
- 由于 WRF 包含多个模块,因此处理流程可能不尽相同,这里仅以 WPS 和 WRF 这两个模块为例介绍一下完整的 WRF 流程:
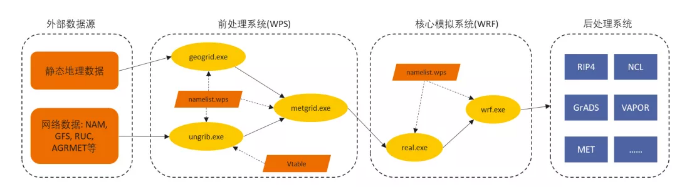
- 外部数据源:包含静态地理数据,网络数据等,静态地理数据可以理解为某区域内的地理信息,例如山川,河流,湖泊,森林等等。网络数据是某区域内的气象环境数据,例如气温,风速风向,空气湿度,降雨量等。
- 前处理系统 WRF Pre-processing System:前处理系统用于载入地理和气象数据,对气象数据进行插值,为 WRF 提供输入数据,该部分包含 3 个程序:
-
- geogrid.exe:定义模型投影、区域范围,嵌套关系,对地表参数进行插值,处理地形资料和网格数据;
-
- ungrib.exe:从 grib 数据中提取所需要的气象参数;
-
- metgrid.exe:将气象参数插值到模拟区域。
- 核心模拟系统(WRF):核心模拟系统对前处理系统生成的气象信息进行模拟和预报,是 WRF 的核心模块,该部分包含 2 个程序:
-
- real.exe:初始化实际气象数据;
-
- wrf.exe:模拟及预报结果;
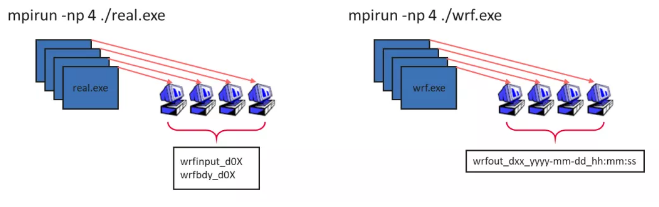
- real.exe 和 wrf.exe 可以通过 mpi 并行运算来提升计算速度,如下所示,wrfinput_d0X 和 wrfbdy_d0X 为 real.exe 的运算结果,wrf.exe 以该结果为输入进行模拟演算,生成最终的气象模拟结果 wrfout_dxx_yyyy-mm-dd_hh:mm:ss,并由后处理系统进行验证展示:
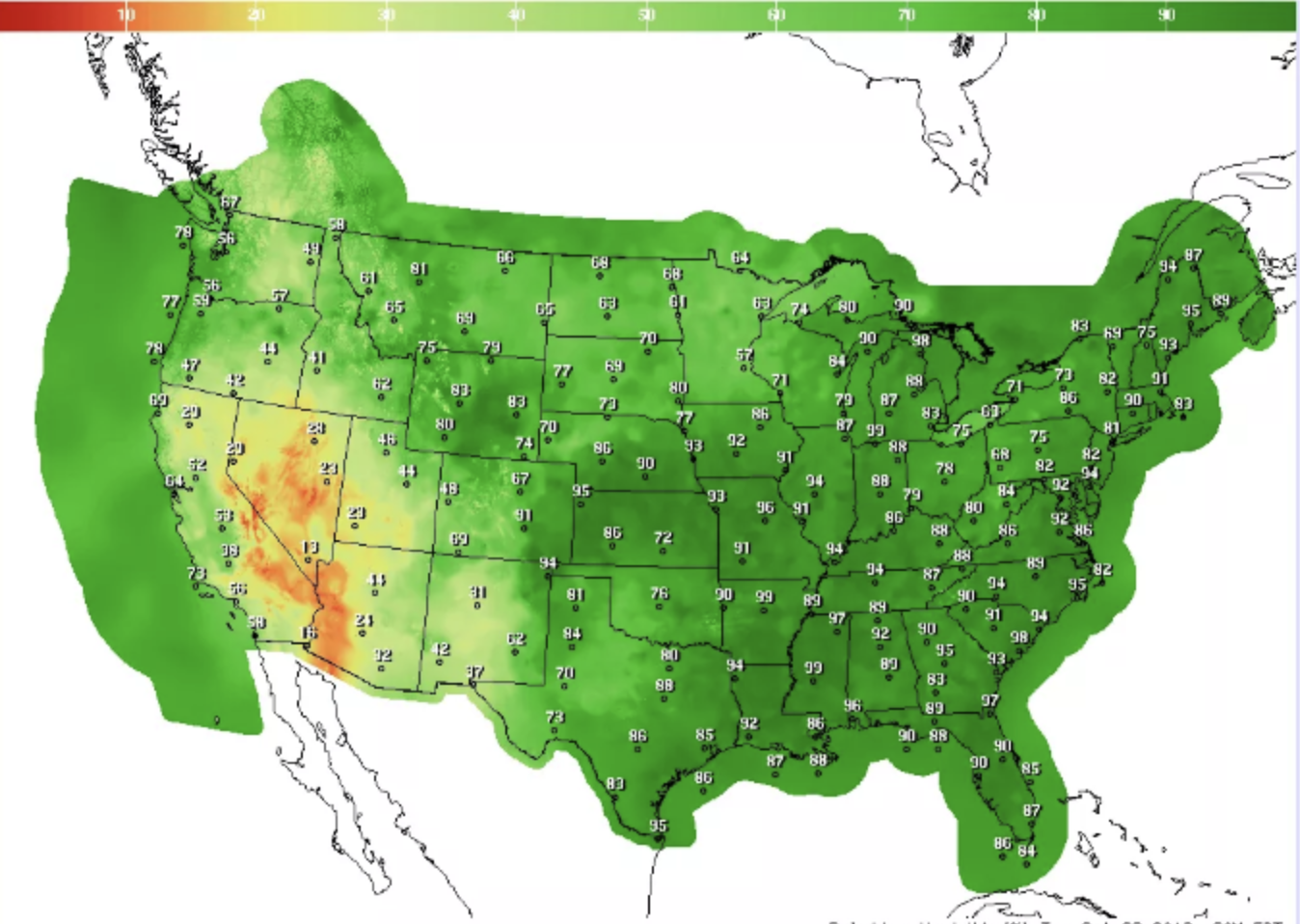
- 后处理系统用来验证和显示核心模拟系统的计算结果,主要由各种第三方图像和验证工具组成。如下所示展示 Conus 2.5km 算例中各个地区相对湿度的模拟预报结果,Conus 2.5km 是指美国本土气象数据,分辨率为 2.5km(将整个区域分成一个个 2.5km2.5km2.5km 的方格,每个方格中的气象信息被认为是完全一致的):
③ HPC Volcano
- 如下所示,一个 HPCC 包括资源管理器,调度器和 mpi 并行计算库三部分,其中资源管理器由 Kubernetes 负责,调度器由 Volcano 负责:
- 在 Kubernetes+Volcano 环境中运行 HPC 应用,本质上就是在容器中运行 HPC 作业,示意图如下:
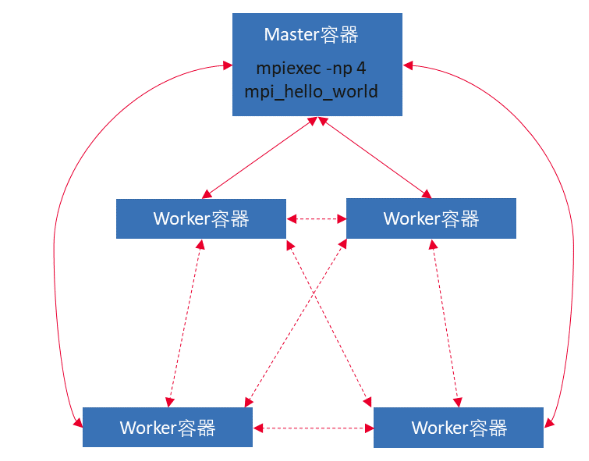
- 将运行的容器分为 Master 容器和 Worker 容器两种,Master 容器负责启动 mpirun/mpiexec 命令,Worker 容器负责运行真正的计算作业。因此 Volcano 为了支持 MPI 作业运行,添加了如下功能:
-
- Volcano job 支持定义多个 pod 模板,能够同时定义 master pod 和 worker pod;
-
- 支持 Gang scheduling,保证作业中所有的 pod 能够同时启动;
-
- Master/Worker pod 内部主机 IP 映射;
-
- Master/Workerpod 之间 ssh 免密登录;
-
- 作业生命周期管理。
- Volcano mpi 作业配置 mpi_sample.yaml:
apiVersion: batch.Volcano.sh/v1alpha1
kind: Job
metadata:
name: mpi-job
labels:
# 根据业务需要设置作业类型
"Volcano.sh/job-type": "MPI"
spec:
# 设置最小需要的服务 (小于总replicas数)
# 这里等于mpimaster和mpiworker的总数
minAvailable: 3
# 指定调度器为Volcano
schedulerName: Volcano
plugins:
# 提供 ssh 免密认证
ssh: []
# 提供运行作业所需要的网络信息,hosts文件,headless service等
svc: []
# 如果有pod被 杀死,重启整个作业
policies:
- event: PodEvicted
action: RestartJob
tasks:
- replicas: 1
name: mpimaster
# 当 mpiexec 结束,认为整个mpi作业结束
policies:
- event: TaskCompleted
action: CompleteJob
template:
spec:
# Volcano的信息会统一放到 /etc/Volcano 目录下
containers:
# master容器中
# 1. 启动sshd服务
# 2. 通过/etc/Volcano/mpiworker.host获取mpiworker容器列表
# 3. 运行mpirun/mpiexec
- command:
- /bin/sh
- -c
- |
MPI_HOST=`cat /etc/Volcano/mpiworker.host | tr "\n" ","`;
mkdir -p /var/run/sshd; /usr/sbin/sshd;
mpiexec --allow-run-as-root --host ${MPI_HOST} -np 2 mpi_hello_world;
image: Volcanosh/example-mpi:0.0.1
imagePullPolicy: IfNotPresent
name: mpimaster
ports:
- containerPort: 22
name: mpijob-port
workingDir: /home
resources:
requests:
cpu: "100m"
memory: "1024Mi"
limits:
cpu: "100m"
memory: "1024Mi"
restartPolicy: OnFailure
imagePullSecrets:
- name: default-secret
- replicas: 2
name: mpiworker
template:
spec:
containers:
# worker容器中只需要启动sshd服务
- command:
- /bin/sh
- -c
- |
mkdir -p /var/run/sshd; /usr/sbin/sshd -D;
image: Volcanosh/example-mpi:0.0.1
imagePullPolicy: IfNotPresent
name: mpiworker
ports:
- containerPort: 22
name: mpijob-port
workingDir: /home
resources:
requests:
cpu: "100m"
memory: "2048Mi"
limits:
cpu: "100m"
memory: "2048Mi"
restartPolicy: OnFailure
imagePullSecrets:
- name: default-secret
- 提交 mpi Volcano job:
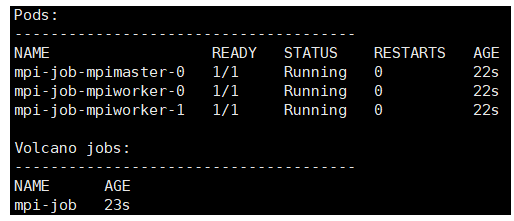
- 作业执行完毕:
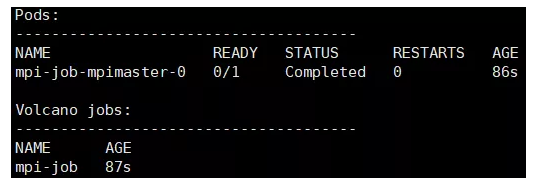
- 查看 master pod 的结果:

- 通过上述执行结果可以看出,在作业执行结束后,Volcano 只清理 worker pod,保留 master pod,这样用户 kubectl 命令获取执行结果。
- 此外,由于网络构建可能会出现延迟,在作业运行开始时,master pod 会出现连接 worker pod 失败的情况。对于这种情况,Volcano 会自动重启 master pod,保证作业能够正确运行。
- 通过以上示例,可以看出 Volcano 想要运行 WRF 作业的话,理论上需要将其中的 mpi_hello_world 替换为 real.exe/wrf.exe,此外,用户还需要进行如下准备:
-
- 自建 docker images,包含完整的 WRF 运行环境;
-
- 将计算所需要的数据(原生数据或者中间结果数据)挂载到相应的容器中。
- 这样就能在 Kubernetes+Volcano 上运行气象模拟作业。
四、附录
- 本文正在参与【与云原生的故事】有奖征文火热进行中:https://bbs.huaweicloud.cn/blogs/345260 。

【版权声明】本文为华为云社区用户原创内容,未经允许不得转载,如需转载请自行联系原作者进行授权。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)