【云驻共创】通俗易懂篇:贝叶斯网络和它的应用

【云驻共创】通俗易懂篇:贝叶斯网络和它的应用
本篇我们将讲到一个新名词,它叫贝叶斯网络,可能刚接触的小伙伴会以为是和某个网络原理相关,实际上它也只能算得上是一种模型,也称为概率图型模型。我们可以用这个模型来解释生活中的大部分事物。
目录:
1、如何理解贝叶斯网络?
2、贝叶斯算法在生活中的小应用
(1). 拼写纠正实例
(2). 垃圾邮件过滤
3、贝叶斯网络
一、如何理解贝叶斯网络?
在文章开头我们就提到,它是一种模型,也还有其他的叫法,比如信念网络或者有向无环图模型,这些叫法都说为了更好的理解。
简单点说,贝叶斯网络是和概率相关的,最初叫贝叶斯方法,是贝叶斯在他生前为解决一个“逆概”问题所写的一篇文章。虽然这篇文章的价值在他死之后才被人们给发掘出来,但这并不妨碍他成名。【说法来自于百度】
至于什么是逆概,我想大家按照表面意思也能够知道肯定和正概相关,那么这里就给大家说说什么是正概,什么是逆概:
打个比方,我们在一个不透明的袋子里装满N个白球和M个黑球,然后去伸手摸白球或者黑球的概率是多大,这就叫正概;相反,逆概就是我们不知道里面白球和黑球的数量,然后我们去摸K个球,观察取出来的球色,再在此基础上猜测袋子里面黑白球的比例。
会不会感觉这听上去有些玄乎,那么我们接下来再举一个例子:
假设一个班上男女比例是6:4,然后男生都是短头发,女生有一半是短头发,另一半是长头发。
举个正向概率的例子:我们随机选取一个学生,ta是长头发或者短头发的概率是多少?
逆向概率:我们看到一个短头发的学生,你只能看见ta是短头发,无法看见ta是男生或者女生,那么你能推断出ta是女生的概率有多大吗?
如果不能,那就跟着小编来推导一下吧:假设班上总人数为H
短头发的男生为:H*P(男生)*P(短头发|男生)
To:P(男生)是指班上男生的概率为百分之六十;P(短头发|男生)这里是指条件概率,即男生在短头发的条件下概率是多少,当然我们很容易知道是百分之百。
短头发的女生为:H*P(女生)*P(短头发|女生)
To:P(女生)是指班上女生的概率为百分之四十;P(短头发|女生)这里是指条件概率,即女生在短头发的条件下概率是多少,当然我们很容易知道是百分之五十。
按照我们一开始提出来的问题,即求解在短头发的人里面有多少女生?
根据上面的条件可知:
短头发的总数为:P1=H*P(男生)*P(短头发|男生)+H*P(女生)*P(短头发|女生)
P(女生|短头发)=H*P(女生)*P(短头发|女生)/短头发总数= H*P(女生)*P(短头发|女生)/P1
然后我们进行化简可得:
P(女生|短头发)=P(女生)*P(短头发|女生)/P(短头发)
有没有一种似曾相识的感觉,没错,下面这个公式我们在高中也学过,上面的问题解决总结下来也就是用这个公式来解决的。
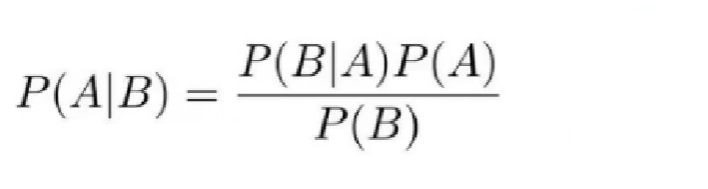
二、贝叶斯算法在生活中的小应用
1.拼写纠正实例
提到大数据大家可能都会感到恐惧,因为它仿佛在默默的总结我们的一切,然后根据我们的想法推给我们一些我们想看到的东西,其实这背后也是算法的魅力。就好像都是一个人,根据你的选择看到的东西给你一步一步的缩小你的圈子,然后就只会看到你想看到的,这也是我们说到大数据让我们感到恐惧的地方。
那么这和拼写纠正有什么关系呢,实际上有着相似的东西。假设你在手机里输入了tha,那么大概率不同手机的人所得到的单词不是一样的,即使你是使用相同的手机在相同的输入法中,也会得到不同的结果。
好,那么问题来了,为什么会这样呢?实际上这里有个叫用户习惯,它会将你经常使用的某个单词放在最显眼的位置,也就是放在第一个位置。这样听起来可能你会想到和概率统计有关,实际上还有另外一种,比如你是想输入the的,结果输入tha,那么软件该怎么判断呢?软件会想用户到底是需要输入什么单词呢?这里我们用到概率为P(猜测输入的单词|实际输入的单词),比如就有P1=(the|tha) P2=(that|tha)…
假设用户实际输入的单词为W(W为观测数据),猜测的单词为c
那么就会有P1(c1|W),P2(c2|W),P3(c3|W)…
统一为:P(c|W)
则根据贝叶斯公式可得:P(c|W)=P(c)*P(W|c)/P(W)
To:对于不同的具体猜测c1,c2,c3,我们可以知道P(W)都是一样的,所以在比较P(c1|W)和P(c2|W)时这个常数是可以忽略的。
P(c|W)和P(c)*P(W|c)是正相关
To:P(c)是指的先验概率,之前说贝叶斯函数的思想和普通函数的思想是有一定的不同的,比如我们抛一枚硬币,抛了十次都是正面朝上,那么下一次抛出一定会是正面吗,这是按照统计概率或者参数分布所产生出来的猜想,那么按照贝叶斯的方法就会想到硬币无论你抛多少次的正面,它正面和反面的概率都不会变,是1/2。
按照贝叶斯的思想,它会认为你抛十次都是正面的数据和它下一次抛是正面根本没有关系,它所关注的是它之前已经验证过的东西,即“先验概率“。
对于给定的W,一个猜测是好是坏,取决于”猜测本身的先验概率”和“这个猜测生成我们观测到的数据的可能性大小“。
那么回到这里,我们可以看到如果用户输入的是tha,那么在巨大的词库中,the和that出现的概率谁会更大一点呢,这里假设是the,那么这里the的先验概率就要比that的先验概率大。
按照贝叶斯的方法计算:P(c)*P(W|c),P(c)是特定的先验概率。
也就是说,按照上面的例子,用户输入的是tha,当一般的统计无法做出判决时,先验概率这时候就站出来了,它就会根据the的先验概率大,即确定用户想输入的是the。
2.垃圾邮件过滤
平时我们在生活中会收到一些邮件,那么我们如何判断它是一封垃圾邮件呢?最简单的方法肯定是用眼睛看,那么我们这里以贝叶斯的思想来看待这个事件。
我们用E来表示收到的这封邮件,E用N个单词组成,我们用c+来表示垃圾邮件,c-表示正常邮件。
P(c+|E)=P(c+)*P(E|c+)/P(E)
P(c-|E)=P(c-)*P(E|c-)/P(E)
上面的概率式子中,P(c+)和P(c-)表示先验概率。
在代码实现的时候,对于两个概率的比较,我们会将后面的P(E)约掉,然后将两个概率的式子等号两边分别加上对数,再进行展开化简。
至于为什么会加上对数再进行求解,我们知道在一封邮件中会有很多个单词,假设d为单词,那么会有d1,d2,d3…也就会有P(E|c+)=P(d1,d2,d3…dn|c+),P(d1,d2,d3…dn|c+)也可以表示为P(d1|c+)*P(d2|c+)*P(d3|c+)*…*P(dn|c+)。可以看到这里我们都是算的乘法,当n个概率相乘后,我们可以知道这个数会非常麻烦,那么我们便可以用到对数这个方法。在这里我们还会提到另外一种思想,叫朴素贝叶斯。简单来说,朴素贝叶斯是基于贝叶斯定理与特征条件独立假设的分类方法。
三、贝叶斯网络
上面大致简述完贝叶斯的思想后,我们便来看看贝叶斯网络到底是个啥。
贝叶斯网络也被叫做信度网络,是贝叶斯方法的扩展,是到目前为止不确定知识表达和推理领域最有效的理论之一。
一个贝叶斯网络是由一个有向无环图和条件概率表组成。
我们可以用有向无环图和一组随机变量表示它们的条件关系:
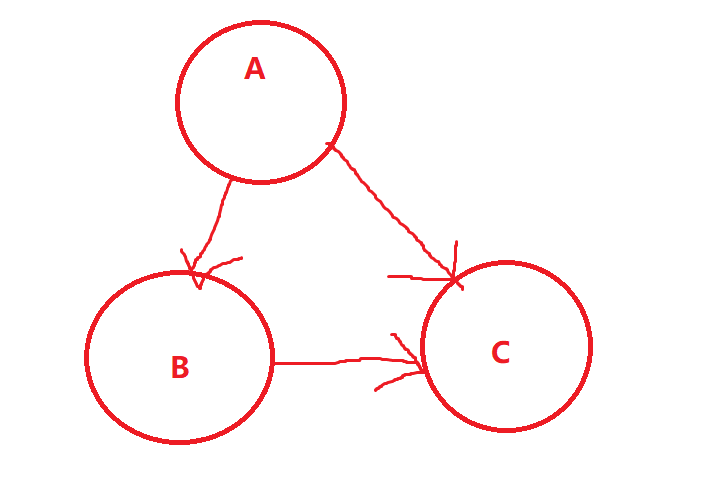
表示为:P(A,B,C)=P(C|A,B)*P(B|A)*P(A)
到这里和贝叶斯相关的思想和应用就介绍得差不多啦,有想法一起交流的可以在评论区评论哦~
注:部分思想来源于网络
本文整理自华为云社区【内容共创】活动第15期。
查看活动详情:https://bbs.huaweicloud.cn/blogs/345822
任务30: 怎么通俗易懂地解释贝叶斯网络和它的应用?

- 点赞
- 收藏
- 关注作者
评论(0)