用少打一局和平精英的时间,来学习C语言中核心知识

@TOC
博主介绍
🌊 作者主页:苏州程序大白
🌊 作者简介:🏆CSDN人工智能域优质创作者🥇,苏州市凯捷智能科技有限公司创始之一,目前合作公司富士康、歌尔等几家新能源公司
💬如果文章对你有帮助,欢迎关注、点赞、收藏(一键三连)和C#、Halcon、python+opencv、VUE、各大公司面试等一些订阅专栏哦
💅 有任何问题欢迎私信,看到会及时回复
前言
最近看下时间又要到面试季节,所以又回过头来回顾一下 C 语言的一些知识,无论何时我觉得 C 语言都是值得学习的计算机语言,它里面蕴含着很多基础的知识。
整数在计算机中的表示
计算机中最终都是二进制的形式表示,二进制的每一位称为 bit, bit 是二进制数的最小单位, 8个 bit 为一个字节。另外在某些单片机中还存在半字节(4 bit)的概念。
原码表示法
特点:最高位为符号位,对于人来说很直观,对计算机来说比较麻烦。

如上图:六和负六二进制位相加结果为 10001100 ,转换为十进制为 12 ,这个明显不是我们想要的结果,所以对于计算机而言原码表示的二进制数无法直接相加来计算结果,计算过程比较麻烦。
补码表示法
由于上面原码表示法对于计算机而言计算过程比较麻烦,所以引入了补码表示二进制数。
特点:最高位为符号位,当符号位为 0 的时候和原码表示相同,当符号位为 1 的时候绝对值按位取反加 1。

-
第一步:
-6的绝对值为6,6的二进制为0000 0110。 -
第二步:按位取反为
1111 1001。 -
第三步:加
1为1111 1010可以看到符号位还是1。 -
这个时候我们来用补码算一下六加负六就会发现二进制结果为
0000 0110 + 1111 1010 = 1 0000 0000发现成了9 位数,最高位溢出被丢掉,所以最终结果为0000 0000。
地址与字节对齐
C语言可以直接对存储器地址进行访问(大部分经过操作系统访问的是逻辑地址、部分嵌入式系统可以访问到物理地址)。
一般对于32位系统而言,一次可以访问1字节、2字节或者4字节。当访问单个字节的时候不存在任何问题、而当每次访问多个字节的时候就有字节对齐问题了,所访问的起始地址必须满足N个字节的倍数,否则可能造成访问性能问题和错误。
字符编码
ASCII编码
我们知道,计算机内部,所有信息最终都是一个二进制值。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从0000 0000到1111 1111。
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为ASCII 码,一直沿用至今。ASCII 码一共规定了128个字符的编码,比如空格SPACE是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的一位统一规定为0。
ISO/IEC8859
由于ASCII编码是一个美国国家标准,并不是国际标准,所以后来国际化组织将它标准化定义为ISO/IEC646标准,两者内容没啥区别。
对于英文国家来说ASCII码完全够用了,但是对于希腊、拉丁语等国家就不够用了,所以国际化组织对ISO/IEC646进行了扩展,形成了ISO/IEC8859标准。后来又不够用了就在8859的基础上引入了8859-n(n从1到16),每一种都支持了一定数量的不同字母集。
中文编码
上面编码解决了大部分国家编码问题,然而中国比较特殊,所以我们国家就自己定义了一套字符编码GB2312使用两个字节表示一个汉字,后来又出现了GBK主要扩展了对繁体字的支持。
Unicode标准
虽然各个国家都有了自己所兼容的编码方式,但是问题是他们之间不是完全兼容的,大部分编码基本都兼容ASCII码(前127位),所以编码解析器就可能解析出错形成乱码。为了解决全球编码互通问题,所以出现了Unicode标准。Unicode标准几乎涵盖了所有编码字符集,它可以表示所有字符。
UTF-8编码
上面我们说到了Unicode,似乎到目前所有的编码问题都已经解决,遗憾的是Unicode并不完美,Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。这样就造成了一个问题,出现了Unicode的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示 Unicode。这个时候随着互联网的普及,强烈要求出现一个统一的编码方式。UTF-8就是在互联网上使用最广的一种Unicode的实现方式。其他实现方式还包括 UTF-16(字符用两个字节或四个字节表示)和 UTF-32(字符用四个字节表示),不过在互联网上基本不用。
大端和小端
内存是一个连续的存储空间,当我们要存放一段数据的时候可以有两个方向存放方式,这个方向的最小单位为字节(因为字节为计算机中数据传输的最小单位),也可以理解为字节存放的顺序。

例如我们从内存地址 0x1000 开始存放数据 0x04030201 ,一般桌面处理器及移动设备都是小端字节序,通信设备中用大端字节序的比较普遍。
内存补齐与对齐
typedef struct MemAlign
{
char a[18];
double b;
char c;
int d;
short e;
}MemAlign;
上面结构体占用内存并不是 18 + 8 + 1 + 4 + 2 = 33, sizeof(MemAlign)函数得出结果为40。结果为什么是这样,这就存在这一个内存补齐和对齐问题。

上图是以4字节为对齐基准的,假设内存开始地址为0的位置,由于char数组占用了18个字节,不是4的倍数,所以需要补齐,其他同理。
浮点数
IEEE浮点表示
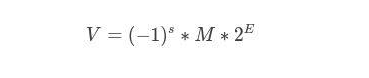
将浮点数的位表示划分为三个字段:
-
(-1)^s表示符号位,当s=0,V为整数;s=1,V为负数; -
M表示有效数字,1≤M<2; -
2^E表示指数位。
比如 -0.5 可以表示为 s=1, M=1.0, E=-1。
32位的单精度浮点数,最高1位是符号位s,接着的8位是指数E,剩下的23位是有效数字M。
| 符号s | 指数E | 尾数M |
|---|---|---|
| 1bit | 8bit | 23bit |
64位的双精度浮点数,最高1位是符号位s,接着的11位是指数E,剩下的52位为有效数字M。
| 符号s | 指数E | 尾数M |
|---|---|---|
| 1bit | 11bit | 52bit |
有效数字M:
-
1≤M<2,也即M可以写成1.xxxxx的形式,其中xxxxx表小数部分。 -
计算机内部保存
M时,默认这个数第一位总是1,所以舍去。只保存后面的xxxxx部分,节省一位有效数字。
指数E(阶码):
-
E为无符号整数。E为8位,范围是0~255;E为11位,范围是0~2047。 -
因为科学计数法中的
E是可以出现负数的,所以IEEE 754规定E的真实值必须再减去一个中间数(偏移值),127或1023。
以float f = 8.25f 为例二进制形式为:
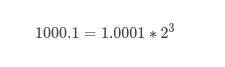
8.25f 的在内存中的存储情况为:
浮点数影响CPU的计算效率,但是对于现在的CPU基本都有浮点数处理器,所以和整型在速度上的差距缩小了,但是需要注意的是在一些类似于单片机这种处理器中未必有浮点数处理器。
指针
指针是C语言的灵活,指针(指针变量)代表了一个地址变量。
*号在C语言中既可以是乘法,也可以表示指针变量和取值运算。
int a = 123;
int *p = &a; //指向a变量的地址
int c = *p; //取p所指向地址的值赋给c变量
多级指针
int a = 123;
int *b = &a; //b保存的是a的地址
int **c = &b; //c保存的是b指针的地址
int ***d = &c;
int e = ***d; //e的值是123
函数指针
上面基本数据类型指针保存的就是这个变量的内存地址,同样的函数指针也是保存的这个函数机器码的字节地址。
声明函数指针:
void (*funP)(int); //声明函数指针
void myFun(int x); //声明函数
int main(){
myFun(100); //调用函数
funP=&myFun; //将myFun函数的地址赋给funP变量
(*funP)(200); //通过函数指针变量来调用函数
}
myFun的函数名与funP函数指针都是一样的,即都是函数指针。myFun函数名是一个函数指针常量,而funP是函数数指针变量。
内联函数
在C语言中,如果一些函数被频繁调用,不断地有函数入栈,即函数栈,会造成栈空间或栈内存的大量消耗。
inline函数声明符声明的函数是内联函数,内联函数是对C语言编译器的暗示,建议编译器对该函数的调用尽可能的快。
inline void fun(int x, int y){
//...
}
inline只适合涵数体内代码简单的函数数使用,不能包含复杂的结构控制语句例如while、switch,并且内联函数本身不能是直接递归函数(自己内部还调用自己的函数)。内联函数实际上是复制为代价换取时间(空间换时间)。
结构体
定义
struct point{ //定义了一个点
int x;
int y;
}
结构体实际上是定义一种新的数据类型,上面的point相当于这个类型的名称。定义此类型的变量 struct{ ... } x, y, z;,也可以通过下面方式声明变量。
struct point pt;
初始化结构体可以在声明变量的时候struct point pt = {100, 120},也可以通过结构体名.成员的方式。
struct Rect{ //定义一个矩形,矩形是由两个坐标决定的
struct point point1;
struct point point2;
}
结构体和函数
下面定义了一个名字为makepoint的函数,返回值为struct point类型,这个函数里面对结构体进行了创建和赋值。
struct point makepoint(int x, int y){
struct point temp;
temp.x = x;
temp.y = y;
return temp;
}
同样的我们也可以将函数参数声明为结构体类型。
联合
联合的声明方式和结构体很类似:
//联合
union{
int i;
double d;
} u;
//结构体
struct {
int i;
double d;
} s;
结构体的成员存储在不同的内存地址中,而联合的成员存储在同一内存地址中。

编译器只为联合的最大成员分配足够的空间,联合的成员在这个空间内彼此覆盖,上面的 i 和 d 就有相同的地址。
联合只能给第一个成员赋初始值,如下:
union{
int i;
double d;
} u = {0};
在C99特性中,可以指定给其他成员初始化(不一定是第一个成员)。
union{
int i;
double d;
} u = {.d = 10.0 };
枚举
我们知道 boolean 可以表示两种状态,如果多余两种状态我们可以使用枚举表示,当然也可以用int来代表,但是从名字上不够明显,可以采用宏定义的方式如下:
#define Color int
#define RED 1
#define GREEN 2
#define BLUE 3
Color color;
//...
color = RED;
上面的方式是一种 int 类型表示多种状态的改进,但是还不如枚举直观。
enum {RED, GREEN, BLUE} c1, c2;
也可以写成:
enum Color {RED, GREEN, BLUE};
enum Color c1, c2;
当然也可以使用 typedef 定义为类型名:
typedef enum {RED, GREEN, BLUE} Color;
Color c1, c2;
系统内部默认会把枚举和常量作为整数来处理,所以默认会赋 0, 1, 2, ... 值给枚举,等价于下面:
enum Color {RED = 1, GREEN = 2, BLUE = 3}
当然你可以显式的指定枚举的值,它们也可以具有相同的值,也可以指定一个值,后面的会递增。
enum Color {RED = 6, GREEN = 6, BLUE = 6}
C语言允许把枚举和普通整型混合使用,如下:
int i;
enum {RED, GREEN, BLUE} c1;
i = RED;
c1++;
i = c1 + 1;
宏定义
C语言中的宏定义类似于起一个别名,一般习惯将宏定义写成全大写字母。
#define M (x*3+x*5) //宏定义 M 为这段表达式的别名
int main(){
int x = 10;
int b = 2*M; //b = 2 * (10 * 3 + 10 * 5)
}
上面的宏定义属于无参数的宏定义, 也可以给宏定义带参数。
#define M(s1, s2) (x*s1+x*s2)
int main(){
int x = 10;
int b = 2*M(1, 2); //b = 2 * (10 * 1 + 10 * 2)
}
当我们调用函数的时候通常会有一些额外开销,简单重复的函数我们可以用宏定义来处理(现在完全可以用内联函数替代),实现空间换时间。
当然,既然宏定义是一种别名,当然了也可以对类型重命名:
#define BOOL int
另外有一个比较特殊的符号, ## 是粘合符,例如:
#define MK_ID(n) i##n
int MK_ID(1), MK_ID(2), MK_ID(3);
//对应 int i1, i2, i3
和宏定义对应的是 #undef , 如果出现 #undef 则关闭该宏定义。
#define BOOL int
//...
#undef BOOL
// 注意,这里不能再使用宏定义 BOOL
条件编译
条件编译时常用的指令:#if、#else、#elif、#endif。其一般形式为:
#if constant
//Statement sequence
#elif constant1
//Statement sequence
#elif constant2
//Statement sequence
#else
//Statement sequence
#endif
还有一种情况我们会判断是否定义过某个标识符,使用ifdef或者ifndef。
#ifdef 标识符
程序段1
#else
程序段2
#endif
变量作用域
把函数体内声明的变量叫局部变量,函数被调用时自动分配,函数执行完后自动回收。
int sum_fun(int n, int m){
int sum = 0;
sum = n + m;
return sum;
}
在局部变量前声明 static 可以使局部变量变成静态存储,静态存储拥有永久存储单元,但是对其他函数式不可见的。
int sum_fun(int n, int m){
static int sum = 0;
sum = n + m;
return sum;
}
外部(相对函数体)变量和 static 变量一样具有永久存储(静态存储),唯一不同就是拥有文件作用域,在同一个文件类可见。
程序块 { } 中的变量存储期限自动的,进入程序块时候变量分配存储,退出程序块时回收分配的空间。也就是说变量具有块作用域。
动态内存分配
C语言通常的数据结构是固定大小的,有时候我们需要向数组中添加事先不知道长度的数据,这个时候就要用到动态内存分配了。动态内存分配主要用于字符串、数组、结构体。
在 stdlib.h中包含如下三个内存分配函数:
-
malloc函数:分配内存块,但不对内存进行初始化。 -
calloc函数:分配内存块,并对内存块清零。 -
realloc函数:调整已经分配的内存块大小。
这几个函数都会返回void * 类型,是一个通用指针(不指向具体地址的指针),它表示的是一个内存地址。空指针使用宏定义 NULL 来表示。
char *p;
p = (char *)malloc(8);
if(p == NULL){
//分配内存失败
}

realloc 可以对给定的指针所指的空间进行扩大或者缩小,无论是扩张或是缩小,原有内存的中内容将保持不变。当然,对于缩小,则被缩小的那一部分的内容会丢失。realloc并不保证调整后的内存空间和原来的内存空间保持同一内存地址.相反,realloc返回的指针很可能指向一个新的地址。
char *p, *q;
p = (char *)malloc(8);
q = p;
p = (char *)realloc(p, 8);
printf("p=0x%x/n", p);
printf("q=0x%x/n", q);
输出结果发现 realloc 后内存地址不变,但是将上面代码的 第 4 行的 8 改为 1000 后发现内存地址发生了变化。
悬空指针问题
free 函数会释放 p 所指向的内存块,但是如果忘记了 p 已经被释放则可能会造成修改未知的内存。
char *p = (char *)malloc(8);
//....
free(p);
//....
strcpy(p, "abc");
链表
链表是存储数据的一种结构。
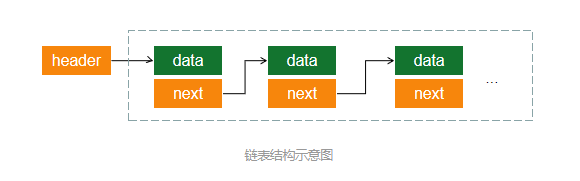
header为这个链表的头指针,第一个数据结点为头结点,有的链表实现头结点不存放有效数据,而是从下一个结点开始存放有效数据,这样做可以方便操作链表。
结构体定义:
//定义蛇体链表的结构体类型
typedef struct Snake{
size_t x; //行
size_t y; //列
struct Snake *next;
} Snake, *pSnake;
结点定义:
struct Node{
int data;
struct Node *pNext;
}
创建多个结点:
//首先创建头结点并让header指向它
header = (pSnake)malloc(sizeof(Snake));
header->next = NULL;
//创建临时指针(表示目前的最后一个结点)
pSnake cur = head;
for(int i = 0; i < 3; i++){
//给第 i+1 个节点分配内存空间
struct Node *pNew = (struct Node *)malloc(sizeof(struct Node));
if(NULL == pNew){
exit(-1);
}
cur->next = pNew; //临时指针指向新结点
pNew->data = 10 + i;
pNew->next = NULL;
cur = cur->next;
}
预处理
C语言在编译前预处理器会做一步预处理,来将宏定义(#define)和头文件(#include)所在位置替换成实际的值或头文件。

例如下面代码:
#include <stdio.h>
#define SIZE 20
int main(void)
{
int a = SIZE + 3;
return 0;
}
预处理结束后的样子如下(使用 gcc -E test.c 查看):
//从stdio.h中引入的行(很多)
int main(void)
{
int a = 20 + 3;
return 0;
}
预处理的指令都是以 # 号开头,例如 #include,#define 和条件编译指令 ``#if, #ifdef, #ifndef, #elif, #else, #endif。
预处理命令不需要在一行的行首,只要它之前有空白字符就可以,总在换行符处结束指令,除非使用\来延续指令。
#define DISK_CAPACITY (SIDES * \
TRACKS_PER_SIDE * \
SECTORS_PER_TARCK * \
BYTES_PER_SECTOR)
预处理的注释如下:
#define SIZE 20 /* 尺寸定义 */
另外值得一提的是头文件 #include 存在两种形式,一种是 <> 括号, 另一种是 "" 双引号:
#include <stdio.h> /* 直接查找系统目录 */
#include "hot.h" /* 查找当前工作目录,然后再查找系统目录 */
VisualStudio Code编辑器
目前对我来说VisualStudio Code是我经常使用的编辑器,所以我在一开始就想使用它来学习C语言。
- 第一步:安装C/C++插件:

-
第二步:下载mingw64库
-
第三步:配置环境变量
MINGW_HOME : D:\Soft\mingw64
Path : %MING_HOME%\bin
- 第四步:配置C/C++插件的
c_cpp_properties.json,添加mingw的include路径。
在 VSCode 命令面板(Ctrl+Shift+P)中输入 >C/Cpp: Edit Configuration... 会自动生成 .vscode/c_cpp_properties.json 工作区配置文件,内容如下:
{
"configurations": [
{
"name": "Win32",
"includePath": [
"${workspaceFolder}/**",
"D:\\Soft\\mingw64\\include"
],
"defines": [
"_DEBUG",
"UNICODE",
"_UNICODE"
],
"intelliSenseMode": "msvc-x64"
}
],
"version": 4
}
注意配置第 7 行的 include 路径。
- 第五步:安装
Code Runner 插件,方便编译运行代码。
#include <stdio.h>
int main(int argc, char const *argv[])
{
printf("helloworld");
return 0;
}
点击右上角三角形运行按钮
[Running] cd "d:\tempProject\" && gcc test.c -o test && "d:\tempProject\"test
helloworld
[Done] exited with code=0 in 0.95 seconds

- 点赞
- 收藏
- 关注作者
评论(0)