微软行星云计算Planetary Computer——从 STAC API 读取数据

行星计算机使用STAC对我们托管的数据集进行编目。我们提供了一个STAC API端点,可用于按空间和时间搜索我们的数据集。本快速入门将向您展示如何使用我们的 STAC API 和开源库搜索数据。
首先,您需要安装pystac-client库。您可以通过 pip 安装它:
> pip install pystac-client
首先,我们将使用 pystac-client 打开我们的 STAC API:
from pystac_client import Client
catalog = Client.open("https://planetarycomputer.microsoft.com/api/stac/v1")这为我们提供了一个可以抓取或搜索的STAC 目录。目录包含我们索引的每个数据集的STAC 集合(这还不是行星计算机托管的数据的整体)。我们在这里列出了可用的集合 ID 和标题:
# 这里获取子目录,然后利用for循环分别打印出来
collections = catalog.get_children()
for collection in collections:
print(f"{collection.id} - {collection.title}")集合具有有关它们包含的STAC 项目的信息。例如,在这里我们查看可用于Landsat 8 Collection 2 Level 2数据的波段:
#获取Landsat影像
landsat = catalog.get_child("landsat-8-c2-l2")
#遍历所有影像,然后波段这里一般要用“eo:”作为选择波段的前缀
#这里选择我们分别要获取的信息,波段名称,描述,和分辨率
for band in landsat.extra_fields["summaries"]["eo:bands"]:
name = band["name"]
description = band["description"]
common_name = "" if "common_name" not in band else f"({band['common_name']})"
ground_sample_distance = band["gsd"]
print(f"{name} {common_name}: {description} ({ground_sample_distance}m resolution)")我们可以使用 API 来搜索在特定时间与某个区域重叠的图像。这里我们使用了 2020 年 12 月微软主园区周围的一个区域:这里对于python有一个缺点就是我们没法直接在线圈出我们所需要的地方,就像GEE在线的JavaScript中的编辑界面上,这一点多少有点不方便。没法随意选择任意地点的位置。
area_of_interest = {
"type": "Polygon",
"coordinates": [
[
[-122.27508544921875, 47.54687159892238],
[-121.96128845214844, 47.54687159892238],
[-121.96128845214844, 47.745787772920934],
[-122.27508544921875, 47.745787772920934],
[-122.27508544921875, 47.54687159892238],
]
],
}
time_range = "2020-12-01/2020-12-31"
#这里可以看出影像集合的搜索给出的代码是:landsat-8-c2-l2
search = catalog.search(
collections=["landsat-8-c2-l2"], intersects=area_of_interest, datetime=time_range
)搜索将 STAC 项作为PySTAC对象返回给我们:
items = list(search.get_items())
for item in items:
print(f"{item.id}: {item.datetime}")打印结果:
LC08_L2SP_046027_20201229_02_T2:2020-12-29 18:55:56.738265+00:00
LC08_L2SP_047027_20201220_02_T2:2020-12-20 19:02:09.878796+00:00
LC08_L2SP_046027_20201213_02_T2:2020-12-13 18:56:00.096447+00:00
LC08_L2SP_047027_20201204_02_T1:2020-12-04 19:02:11.194486+00:00
我们可以使用eo扩展程序按云量对项目进行排序。我们将抓取低云度的项目:
selected_item = sorted(items, key=lambda item: item.properties["eo:cloud_cover"])[0]我们可以使用eo扩展程序按云量对项目进行排序。我们将抓取低云量的影像:
selected_item = sorted(items, key=lambda item: item.properties["eo:cloud_cover"])[0]我们可以通过以下方式查看我们的项目可用的影像信息:
for asset_key, asset in selected_item.assets.items():
print(f"{asset_key:<25} - {asset.title}")打印结果

在这里,我们检查thumbnail资产:
import json
thumbnail_asset = selected_item.assets["thumbnail"]
print(json.dumps(thumbnail_asset.to_dict(), indent=2)){
的“href”: “https://landsateuwest.blob.core.windows.net/landsat-c2/level-2/standard/oli-tirs/2020/047/027/LC08_L2SP_047027_20201204_20210313_02_T1/LC08_L2SP_047027_20201204_20210313_02_T1_thumb_small.jpeg”,
“类型” : "image/jpeg",
"title": "thumbnail"
}
您可以看到缩略图的 URL 包含在资产信息中。但是,我们将无法直接使用 URL:
import requests
#获取链接
requests.get(thumbnail_asset.href)但是这里无法显示,显示错误
<响应 [404]>
这是因为 Plantary 计算机使用 Azure Blob 存储SAS 令牌来访问我们的数据,这使我们能够在任何地方免费向任何人提供数据,同时对数据集的出口量保持一定的控制。
要获取访问令牌,您可以使用 Planetary Computer's Data Authentication API。
您还可以使用行星计算机包生成令牌并签署资产 HREF 以供访问。您可以通过 pip 安装
> pip install planetary-computer
import planetary_computer as pc
signed_href = pc.sign(thumbnail_asset.href)我们可以使用 PIL 来渲染图像:
from PIL import Image
from urllib.request import urlopen
Image.open(urlopen(signed_href))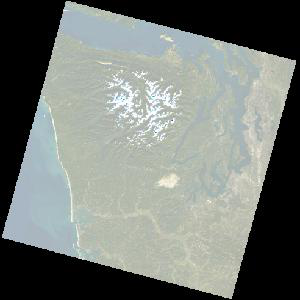
文章来源: blog.csdn.net,作者:此星光明2021年博客之星云计算Top3,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_31988139/article/details/122017743

- 点赞
- 收藏
- 关注作者
评论(0)