Ceph分布式存储性能调优(六)【与云原生的故事】

【摘要】
目录
Ceph分布式存储性能调优
一、系统配置调优
1、设置磁盘的预读缓存
2、设置系统的进程数量
3、调整CPU性能
4、优化网络参数
二、Ceph集群优化配置
1、Ceph的主要配置参数
2、优化配置示例
三、调优最佳实践
1、MON建议
2、OSD建议
3、RBD建议
4、对象网关建议
5...

Ceph分布式存储性能调优
一、系统配置调优
1、设置磁盘的预读缓存
echo "8192" > /sys/block/sda/queue/read_ahead_kb2、设置系统的进程数量
echo 4194303 > /proc/sys/kernel/pid_max3、调整CPU性能
注意: 虚拟机和部分硬件 CPU 可能不支持调整。
1 ) 确保安装了内核调整工具:
yum -y install kernel-tools2)调整为性能模式
可以针对每个核心做调整:
echo performance > /sys/devices/system/cpu/cpu${i}/cpufreq/scaling_governor
或者通过 CPU 工具进行调整:
cpupower frequency-set -g performance
支持五种运行模式调整:
performance :只注重效率,将 CPU 频率固定工作在其支持的最高运行频率上,该模式是对系统高性能的最大追求。powersave :将 CPU 频率设置为最低的所谓 “ 省电 ” 模式, CPU 会固定工作在其支持的最低运行频率上,该模式是对系统低功耗的最大追求。userspace :系统将变频策略的决策权交给了用户态应用程序,并提供相应接口供用户态应用程序调节CPU 运行频率使用。ondemand : 按需快速动态调整 CPU 频率, 一有 cpu 计算量的任务,就会立即达到最大频率运行,等执行完毕就立即回到最低频率。conservative : 它是平滑地调整 CPU 频率,频率的升降是渐变式的 , 会自动在频率上下限调整,和ondemand 模式的主要区别在于它会按需渐进式分配频率,而不是一味追求最高频率 . 。
3)部分硬件可能不支持,调整会出现如下错误:
[root@CENTOS7-1 ~]# cpupower frequency-set -g performance
Setting cpu: 0
Error setting new values. Common errors:
- Do you have proper administration rights? (super-user?)
- Is the governor you requested available and modprobed?
- Trying to set an invalid policy?
- Trying to set a specific frequency, but userspace governor is not available,
for example because of hardware which cannot be set to a specific frequency
or because the userspace governor isn't loaded?
4、优化网络参数
修改配置文件:
vi /etc/sysctl.d/ceph.conf配置内容:
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
执行生效:
sysctl -p /etc/sysctl.d/ceph.conf二、Ceph集群优化配置
1、Ceph的主要配置参数
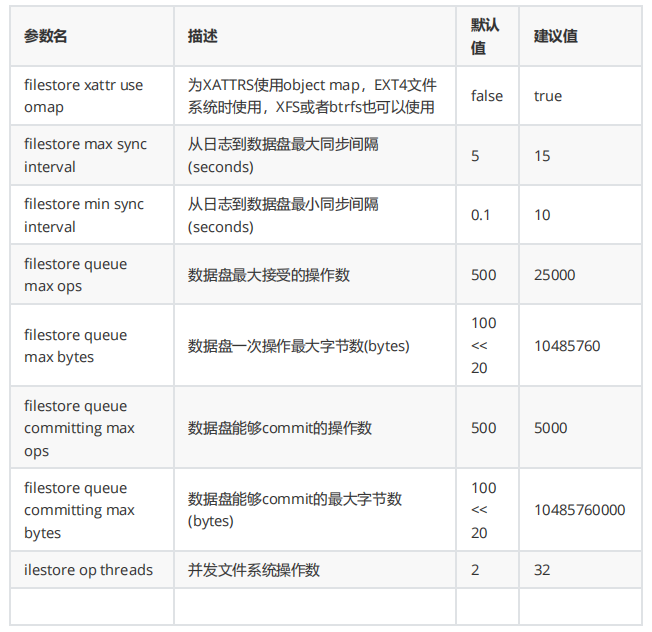
FILESTORE 配置参数:
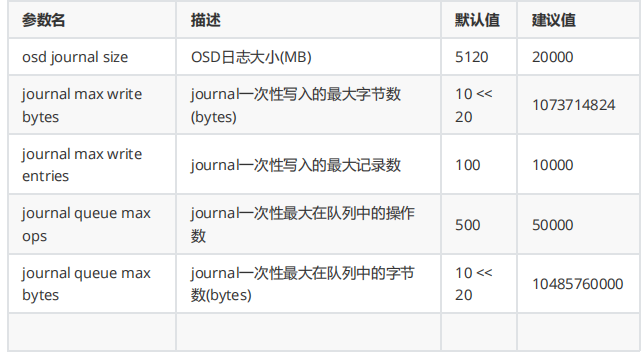
journal 配置参数:
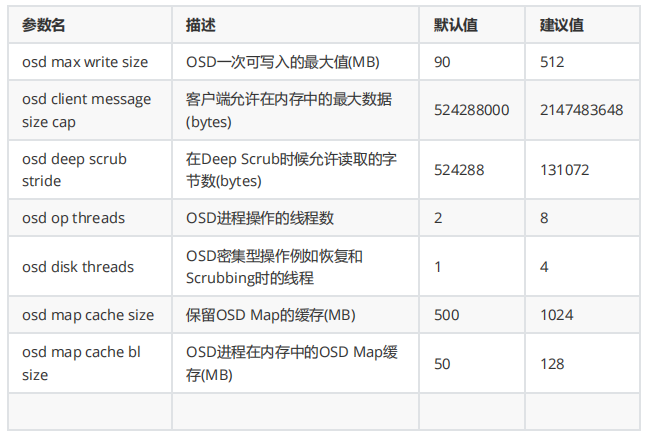
osd config tuning 配置参数:
osd - recovery tuning 配置参数:
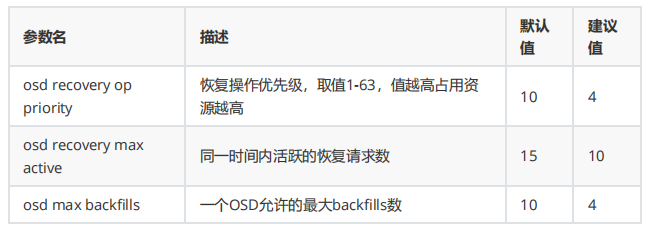
osd - client tuning 配置参数:
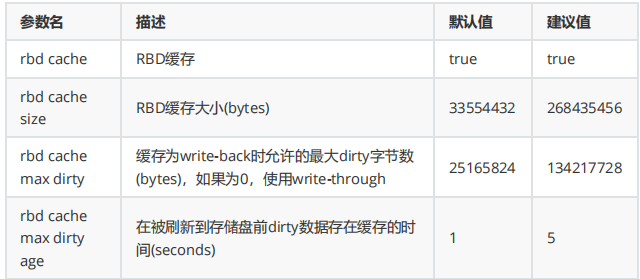
2、优化配置示例


三、调优最佳实践
1、MON建议
Ceph 集群的部署必须要正确规划, MON 性能对集群总体性能至关重要。 MON 通常应位于专用节点上。为确保正确仲裁,MON 的数量应当为奇数。
2、OSD建议
每一 个 Ceph OSD 都具有日志。 OSD 的日志和数据可能会放置于同一存储设备上。当写操作提交至 PG 中所有 OSD 的日志后,标志写操作已经完成。因此,更快的日志性能可以改进响应时间。
在典型的部署中, OSD 使用延迟较高的传统机械硬盘。为最大化效率, Ceph 建议将单独的低延迟SSD 或 NVMe 设备用于 OSD 日志。 管理员必须谨慎,不可将过多 OSD 日志放在同一设备上,因为这可能会成为性能瓶颈。应考虑以下SSD 规格的影响:
- 受支持写入次数的平均故障间隔时间 (MTBF)
- IOPS 能力 (Input/Output Operations Per Second),每秒的读写次数
- 数据传输速率
- 总线/SSD 耦合能力
Red Hat 建议每个 SATA SSD 设备不超过 6 个 OSD 日志,或者每个 NVMe 设备不超过 12 个 OSD日志。
3、RBD建议
RBD 块设备上的工作负载通常是 I/O 密集型负载,例如在 OpenStack 中虚拟机上运行的数据库。对于 RBD , OSD 日志应当位于 SSD 或 NVMe 设备上。对于后端存储,可以根据用于支持 OSD 的存储技术(即 NVMe SSD 、 SATA SSD 或 HDD ),提供不同的服务级别。
4、对象网关建议
Ceph 对象网关上的工作负载通常是吞吐密集型负载。如果是音频和视频资料,可能会非常大。不过,bucket 索引池可能会显示更多的 I/O 密集型工作负载模式。管理员应当将这个池存储在 SSD设备上。
Ceph 对象网关为每个 bucket 维护一个索引, Ceph 将这一索引存储在一个 RADOS 对象中。当bucket 不断增长, 数量巨大时(超过 100,000 个),索引性能会降低(因为只有一个 RADOS 对象参与所有索引操作)。
为此, Ceph 可以在多个 RADOS 对象或者是分片 中保存大型索引。管理员可以通过在ceph.conf 配置文件中设置 rgw_override_bucket_index_max_shards 配置参数来启用这项功能。此参数的建议值是 bucket 中预计对象数量除以 100,000 。
5、CephFs建议
存放目录结构和其他索引的元数据池可能会成为 CephFS 的瓶颈。可以将 SSD 设备用于这个池。每一个CephFS 元数据服务器 (MDS) 会维护一个内存中缓存,用于索引节点等不同种类的项目。Ceph 使用 mds_cache_memory_limit 配置参数限制这一缓存的大小。其默认值以绝对字节数表示,等于 1 GB ,可以在需要时调优。
ceph osd map cephfs_data test_ceph
ceph osd lspools
rados ls -p default.rgw.buckets.data
【与云原生的故事】有奖征文火热进行中:https://bbs.huaweicloud.cn/blogs/345260

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)