elasticsearch中文分词器详解(九)

1.es安装中文分词器
官网:https://github.com/medcl/elasticsearch-analysis-ik
1.1.安装中文分词器
安装中文分词器的要求:
1.分词器的版本要与es的版本一直
2.所有es节点都需要安装中文分词器
3.安装完分词器需要重启
1.在线安装
[root@elasticsearch ~/soft]# cd /usr/share/elasticsearch/bin/
[root@elasticsearch /usr/share/elasticsearch/bin]# ./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.6.0/elasticsearch-analysis-ik-6.6.0.zip
2.离线安装
[root@elasticsearch ~/soft]# cd /usr/share/elasticsearch/bin/
[root@elasticsearch /usr/share/elasticsearch/bin]# cd /usr/share/elasticsearch/plugins/
[root@elasticsearch /usr/share/elasticsearch/plugins]# mkdir ik
[root@elasticsearch /usr/share/elasticsearch/plugins]# cd ik
将分词器的包扔到服务器上
[root@elasticsearch /usr/share/elasticsearch/plugins/ik]# unzip elasticsearch-analysis-ik-6.6.0.zip
[root@elasticsearch /usr/share/elasticsearch/plugins/ik]# rm -rf elasticsearch-analysis-ik-6.6.0.zip
3.任何方式安装的分词器都需要重启
[root@elasticsearch ~]# systemctl restart elasticsearch
另一种安装中文分词器方法
[root@elasticsearch ~]# /usr/share/elasticsearch/bin/elasticsearch-plugin install file:///root/elasticsearch-analysis-ik-6.6.0.zip
重启的时候在日志里会显示导入了分词器插件
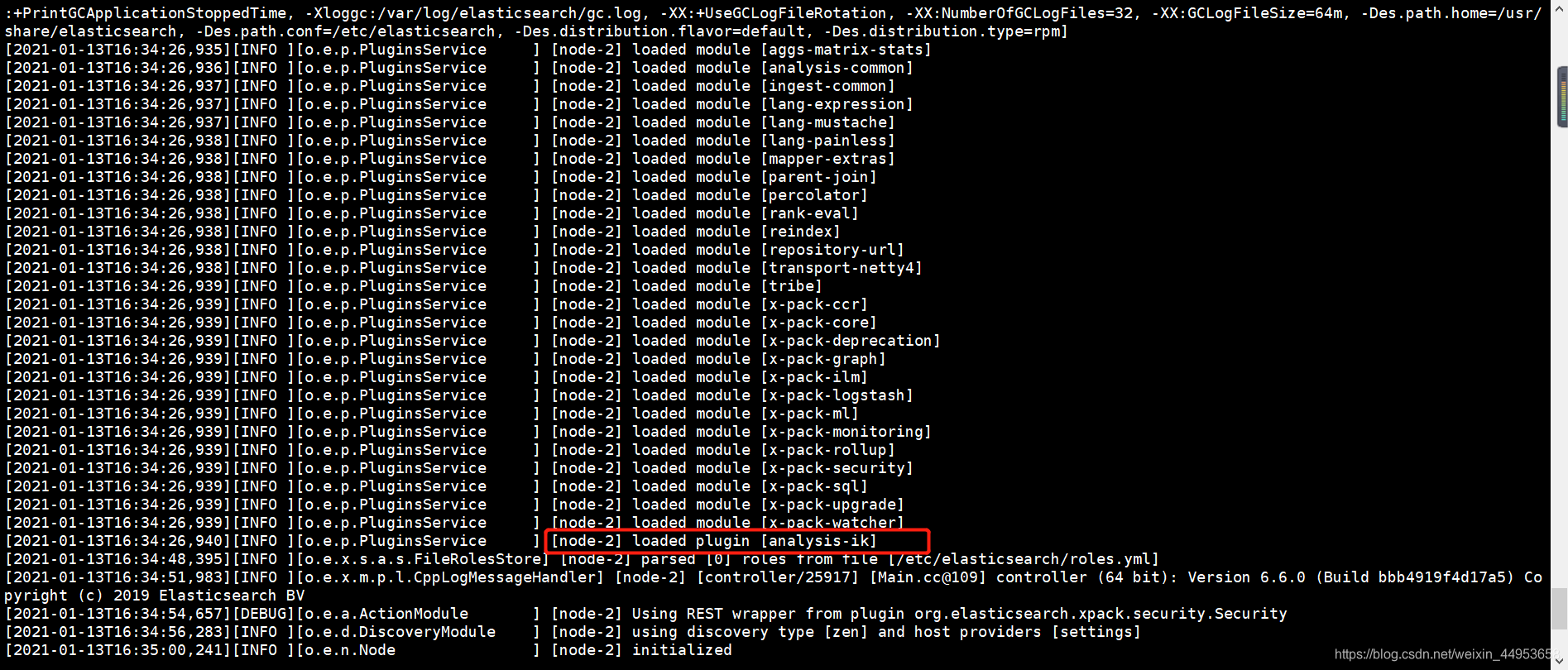
1.2.开启kibana的api查询功能
开启kibana的api查询功能之后就可以在kibana上执行curl交互式时传输的一些指令,并且kibana会把我们的curl命令自动转换成kibana自己的命令类型
点击Dev tools—get to work
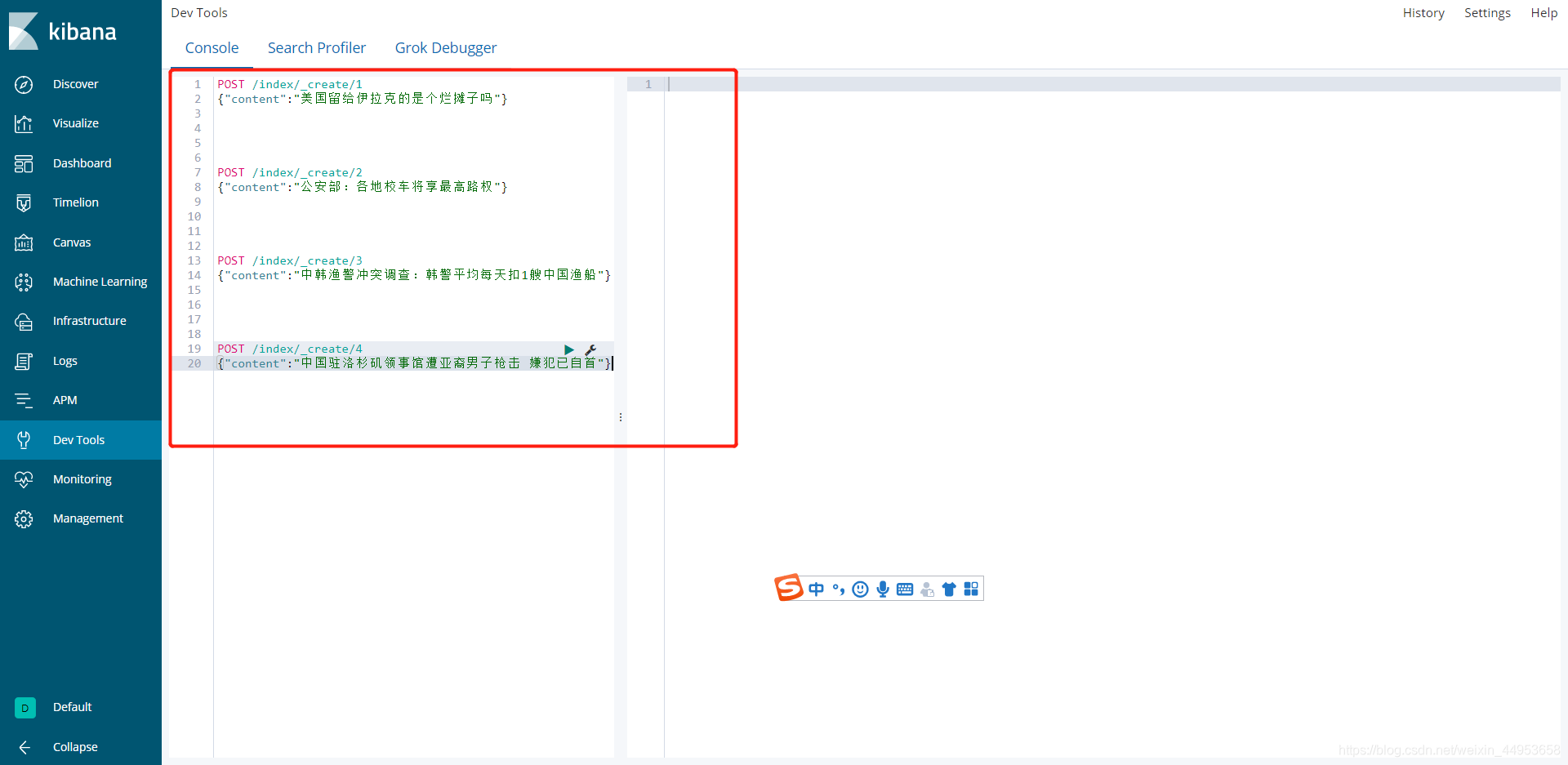
在这里就可以执行各种curl命令,当curl命令粘贴到这里时自动回变成kibana自己的格式,可以全选中一并执行,也可以单个执行,并且即使刷新页面,里面的命令也不会丢失
2.没有使用中文分词器查询中文高亮词显示的效果
来看一下索引没有设置中文分词器之前查询包含某个汉字显示高亮的效果
2.1.建一个xinwen索引并插入几条中文数据
在xinwen索引中插入几条中文数据
curl -XPOST http://localhost:9200/xinwen/create/1 -H 'Content-Type:application/json' -d'
{"content":"美国留给伊拉克的是个烂摊子吗"}
'
curl -XPOST http://localhost:9200/xinwen/create/2 -H 'Content-Type:application/json' -d'
{"content":"公安部:各地校车将享最高路权"}
'
curl -XPOST http://localhost:9200/xinwen/create/3 -H 'Content-Type:application/json' -d'
{"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"}
'
curl -XPOST http://localhost:9200/xinwen/create/4 -H 'Content-Type:application/json' -d'
{"content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"}
直接将curl命令复制到kibana的Dev tools里执行比较方便
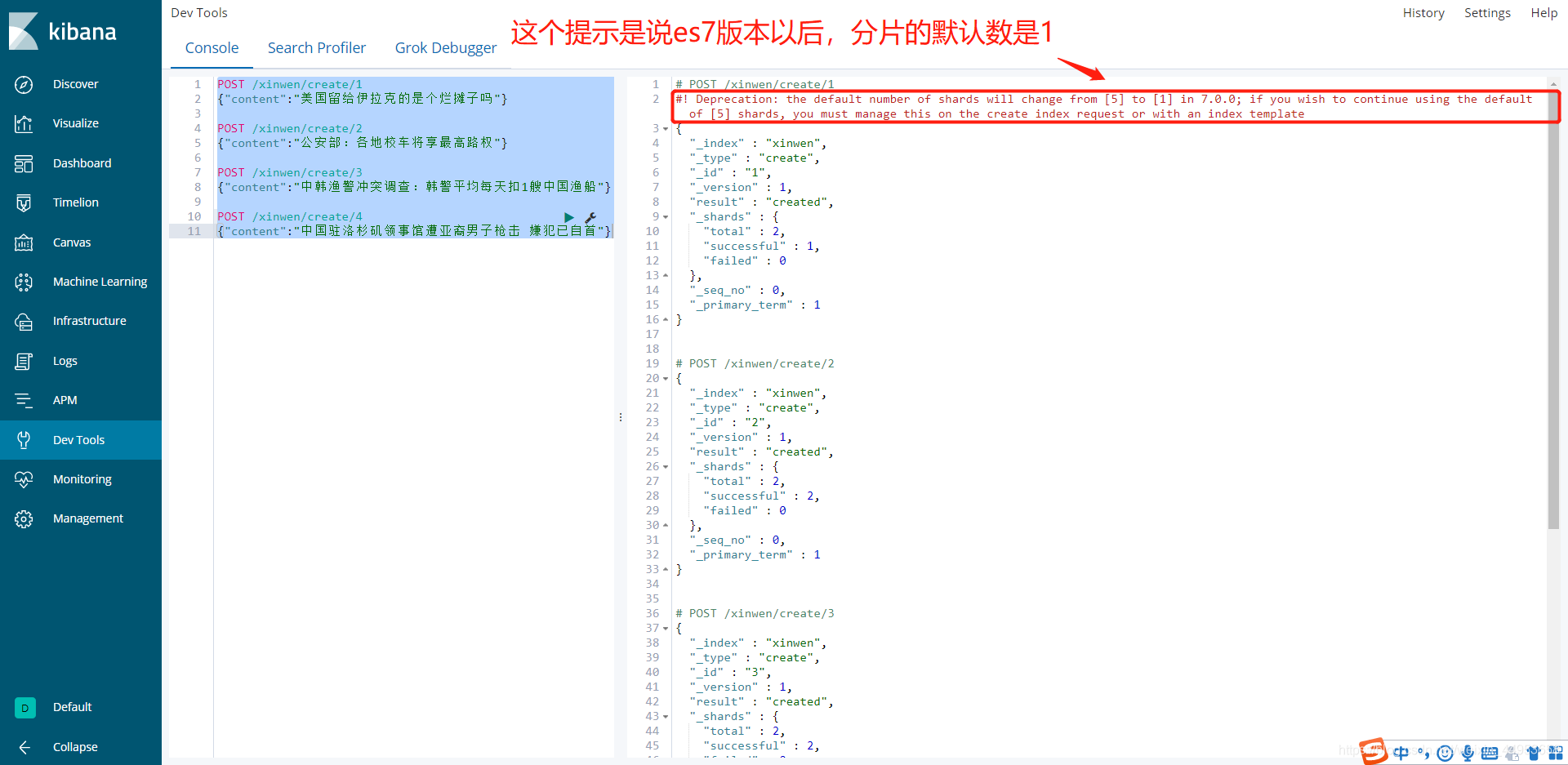
2.2.查看es-head是否能查到数据
已经可以查到数据

2.3.查询包含中国这个词并显示高亮
查询一下包含中国这两个汉字并显示高亮,在没有使用中文分词器之前,es只是按字去搜索,也就是我们查询中国这个词,只要数据中包含"中"和"国"这两个字任意一个都会被显示出来
curl -XPOST http://localhost:9200/xinwen/_search -H 'Content-Type:application/json' -d'
{
"query" : { "match" : { "content" : "中国" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"], #前--高亮
"post_tags" : ["</tag1>", "</tag2>"], #后---高亮,前后高亮是指只把关键字高亮
"fields" : {
"content" : {}
}
}
}
根据输出的结果可以明显的看出,不使用中文分词器之前,只是按某一个字去搜索,而不是按词去搜索,哪个数据出现我们要搜索的词位置最靠前就优先显示
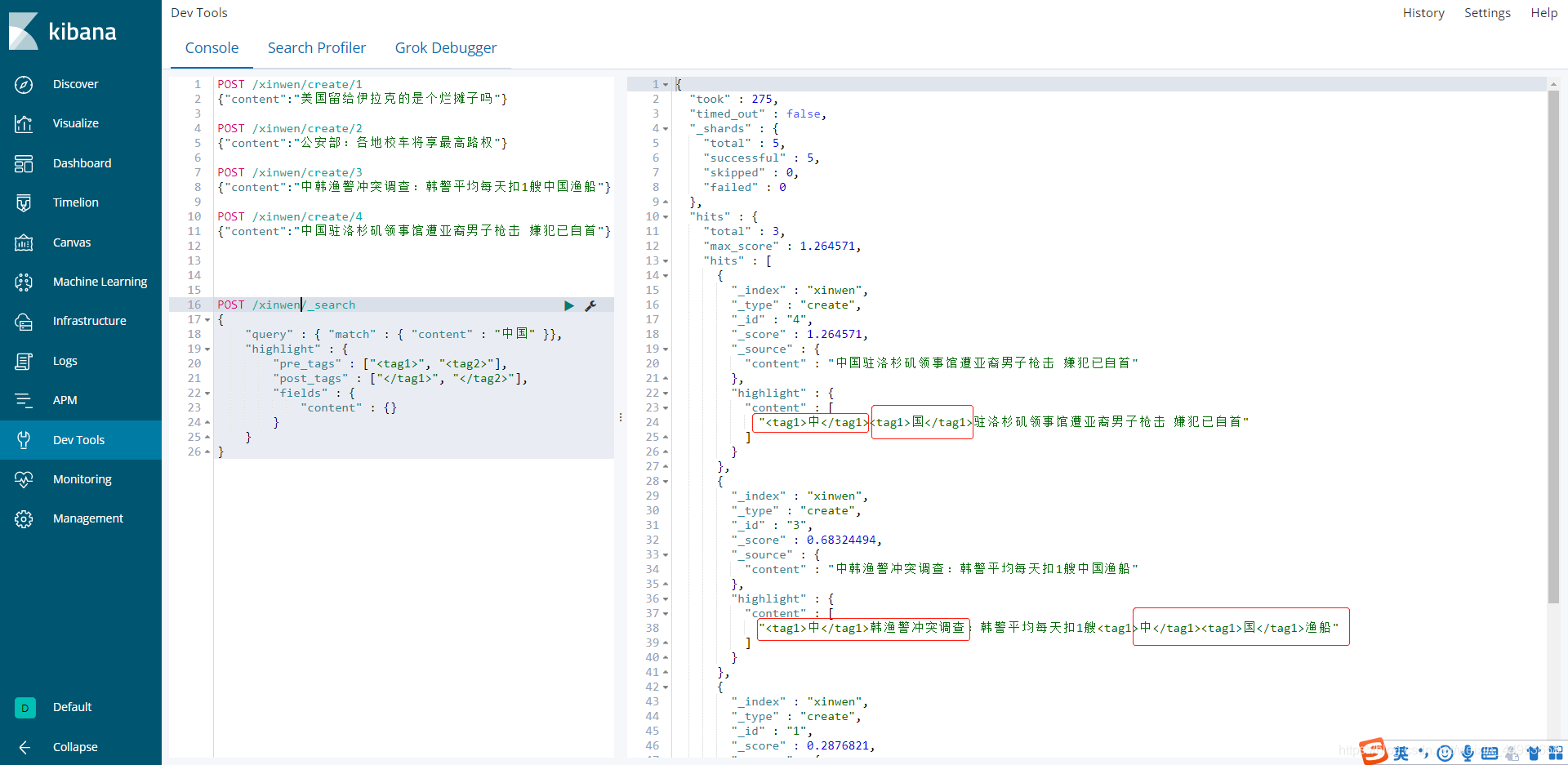
3.使用中文分词器之后查询中文高亮词显示效果
本次验证一下使用了中文分词器之后的明显变化
注意:使索引支持中文分词器的时,要先把索引创建出来,然后在创建索引映射,最后在插入数据,否则索引映射会创建失败
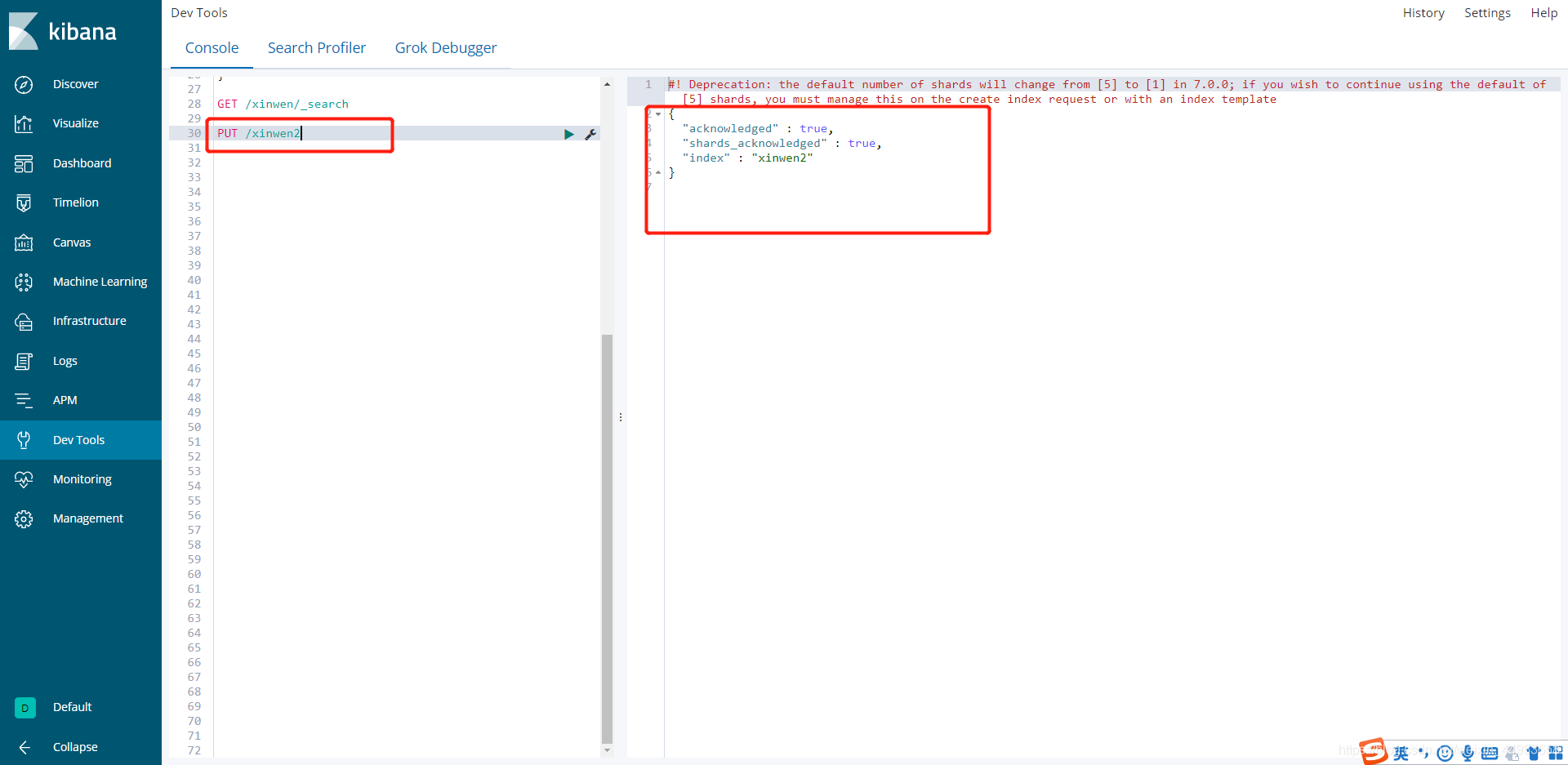
3.1.创建xinwen2索引
curl -XPUT http://localhost:9200/index
使用kibana的Dev tools非常方便,创建一个索引直接就是PUT /索引名
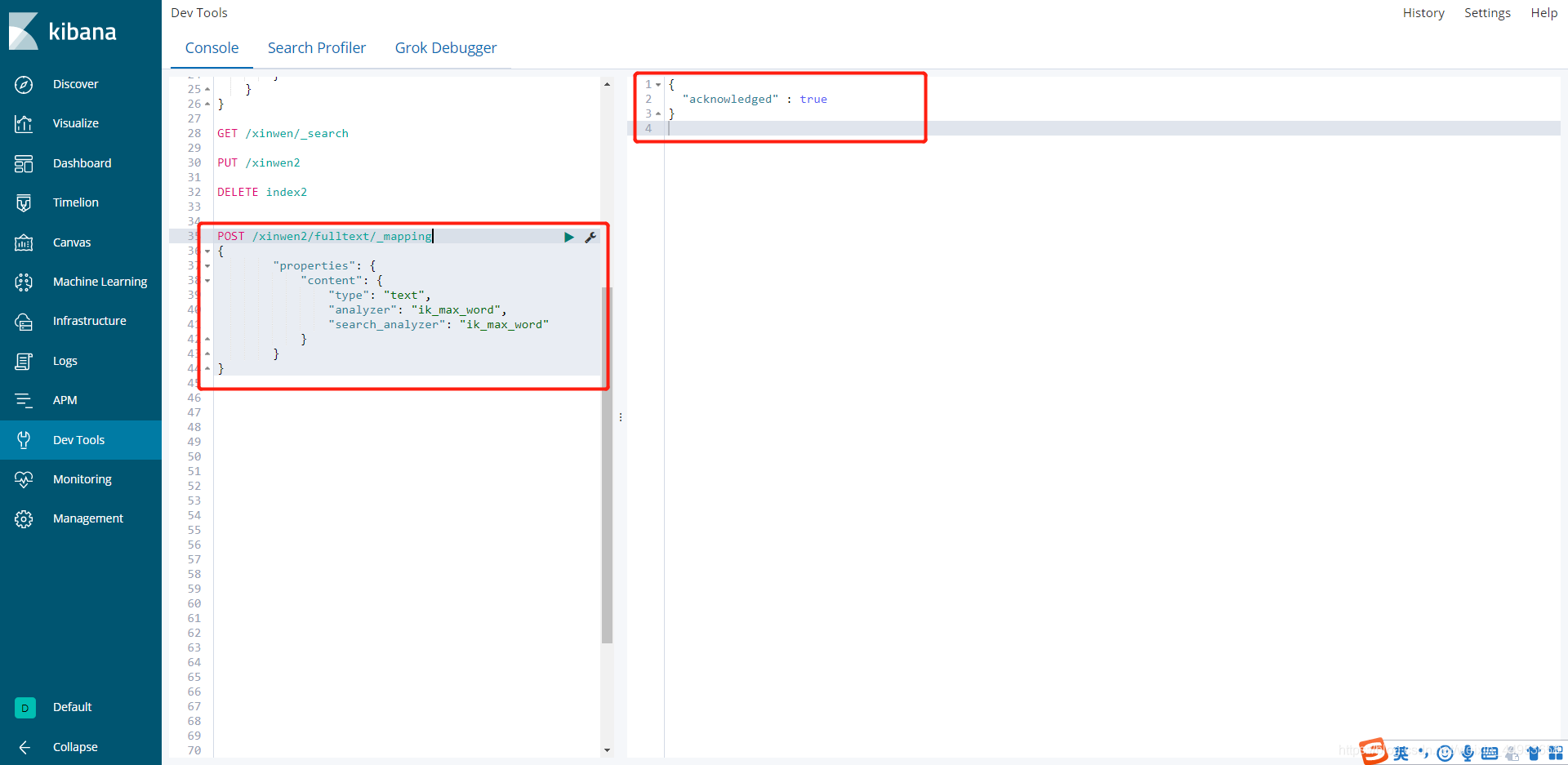
3.2.创建xinwen2索引映射
这一步主要是在索引中增加中文分词器
ik_max_word 和 ik_smart 什么区别?
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query;
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询。
一般还使用ik_max_word这个比较多,毕竟词多就是强
curl -XPOST http://localhost:9200/xinwen2/fulltext/_mapping -H 'Content-Type:application/json' -d'
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}'
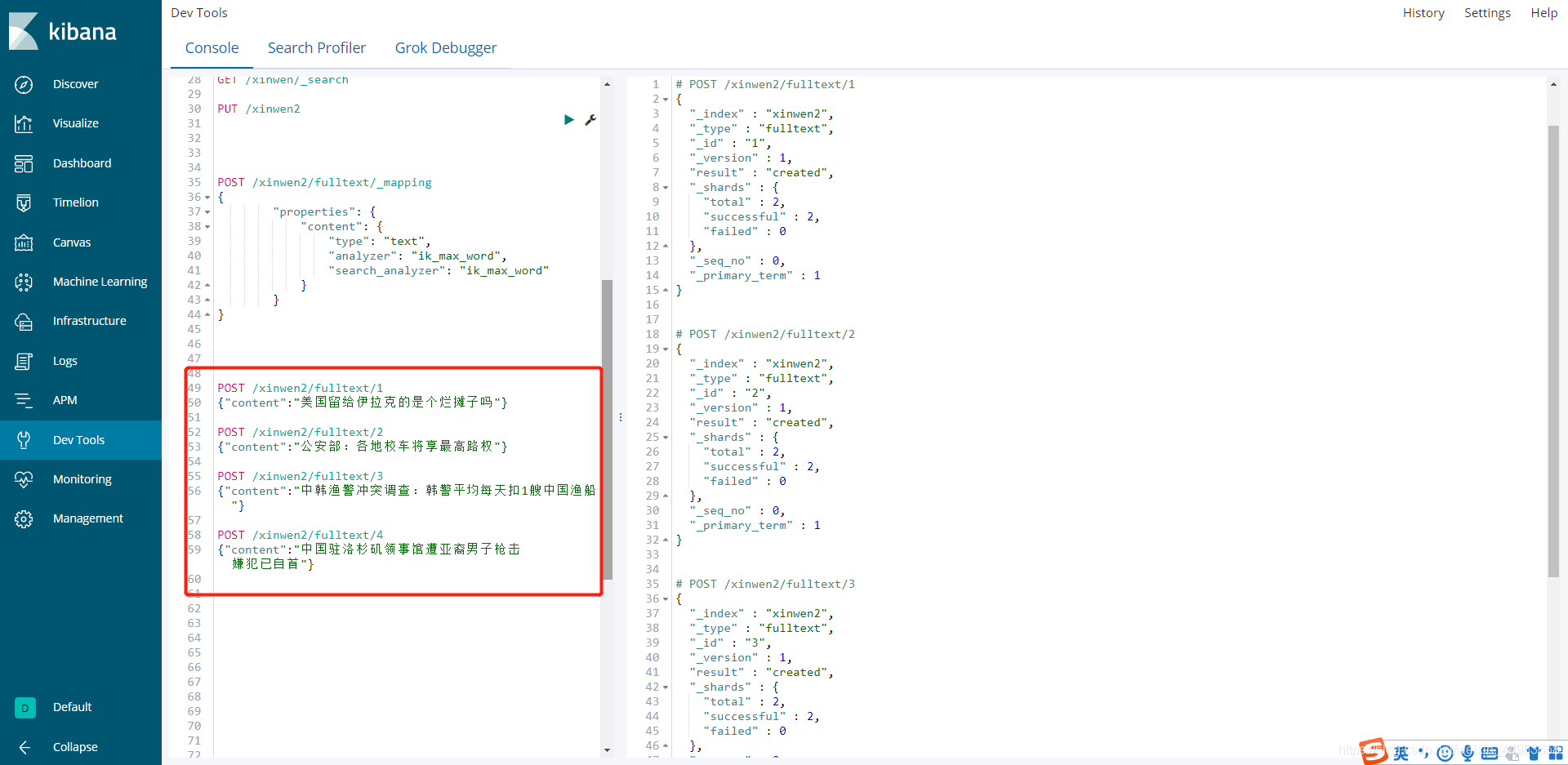
3.3.在xinwen2中插入中文数据
curl -XPOST http://localhost:9200/xinwen2/fulltext/1 -H 'Content-Type:application/json' -d'
{"content":"美国留给伊拉克的是个烂摊子吗"}
'
curl -XPOST http://localhost:9200/xinwen2/fulltext/2 -H 'Content-Type:application/json' -d'
{"content":"公安部:各地校车将享最高路权"}
'
curl -XPOST http://localhost:9200/xinwen2/fulltext/3 -H 'Content-Type:application/json' -d'
{"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"}
'
curl -XPOST http://localhost:9200/xinwen2/fulltext/4 -H 'Content-Type:application/json' -d'
{"content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"}
3.4.在es-head上查看所有是否已经支持中文分词器
点击索引—信息—索引信息
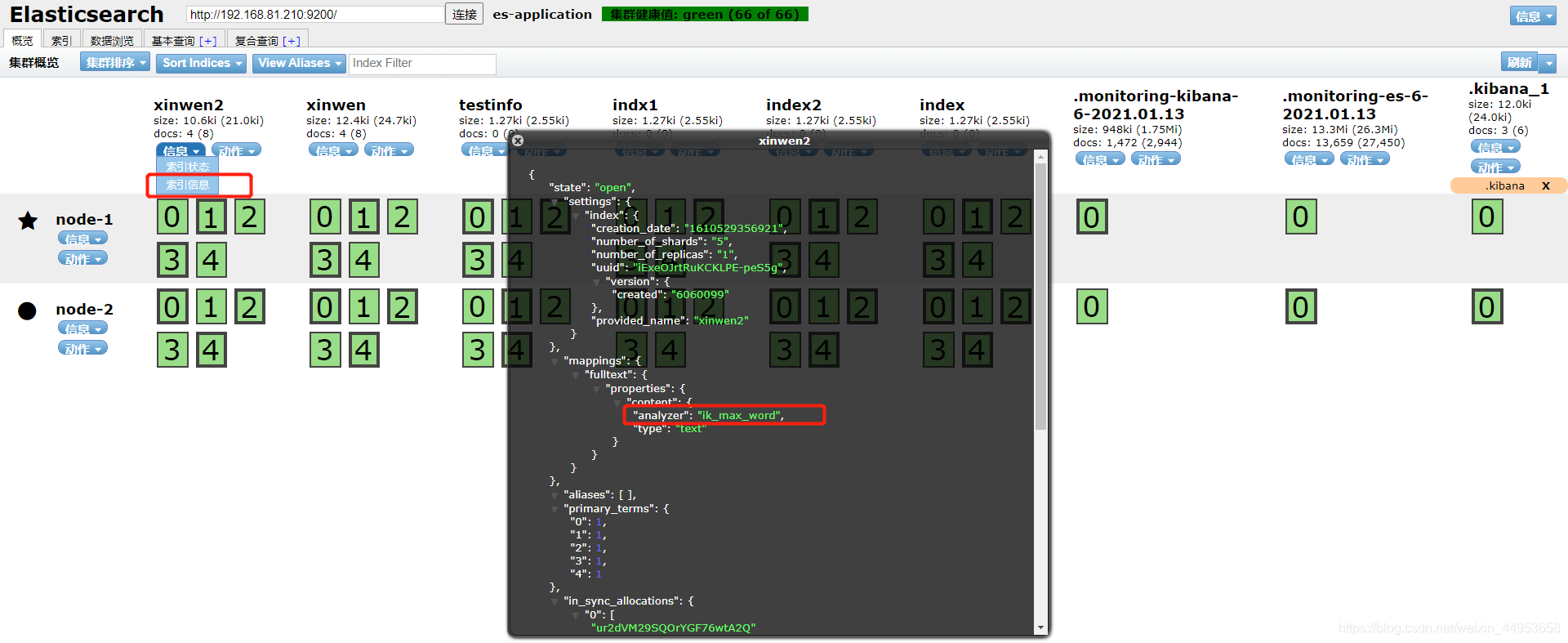
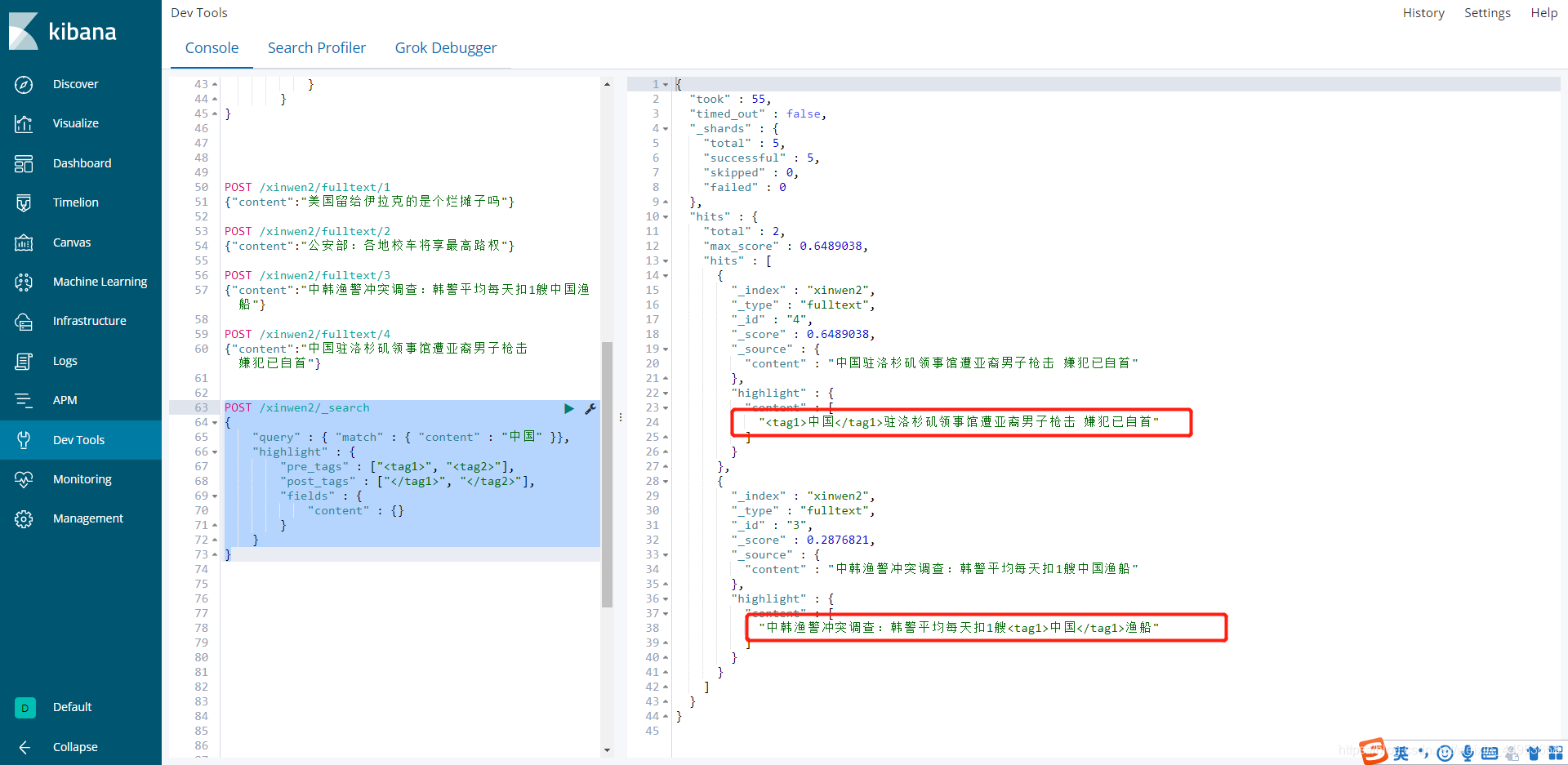
3.5.查询包含中国这个词并显示高亮
curl -XPOST http://localhost:9200/xinwen2/_search -H 'Content-Type:application/json' -d'
{
"query" : { "match" : { "content" : "中国" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}'
执行完可以看到这次已经是以词进行搜索了,上次没有使用分词器之前查询是按字搜索的,使用了分词器之后就是按词进行搜索
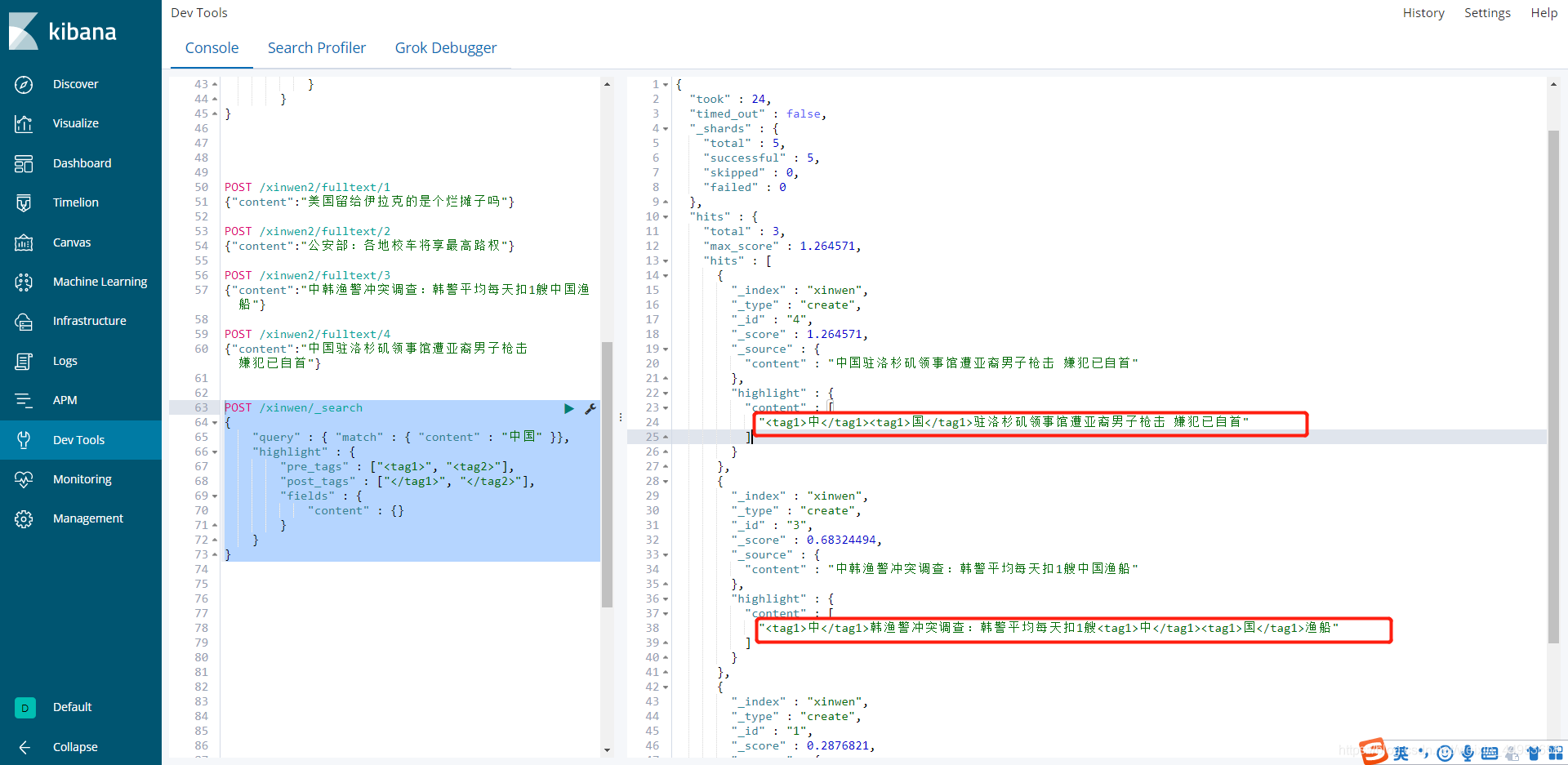
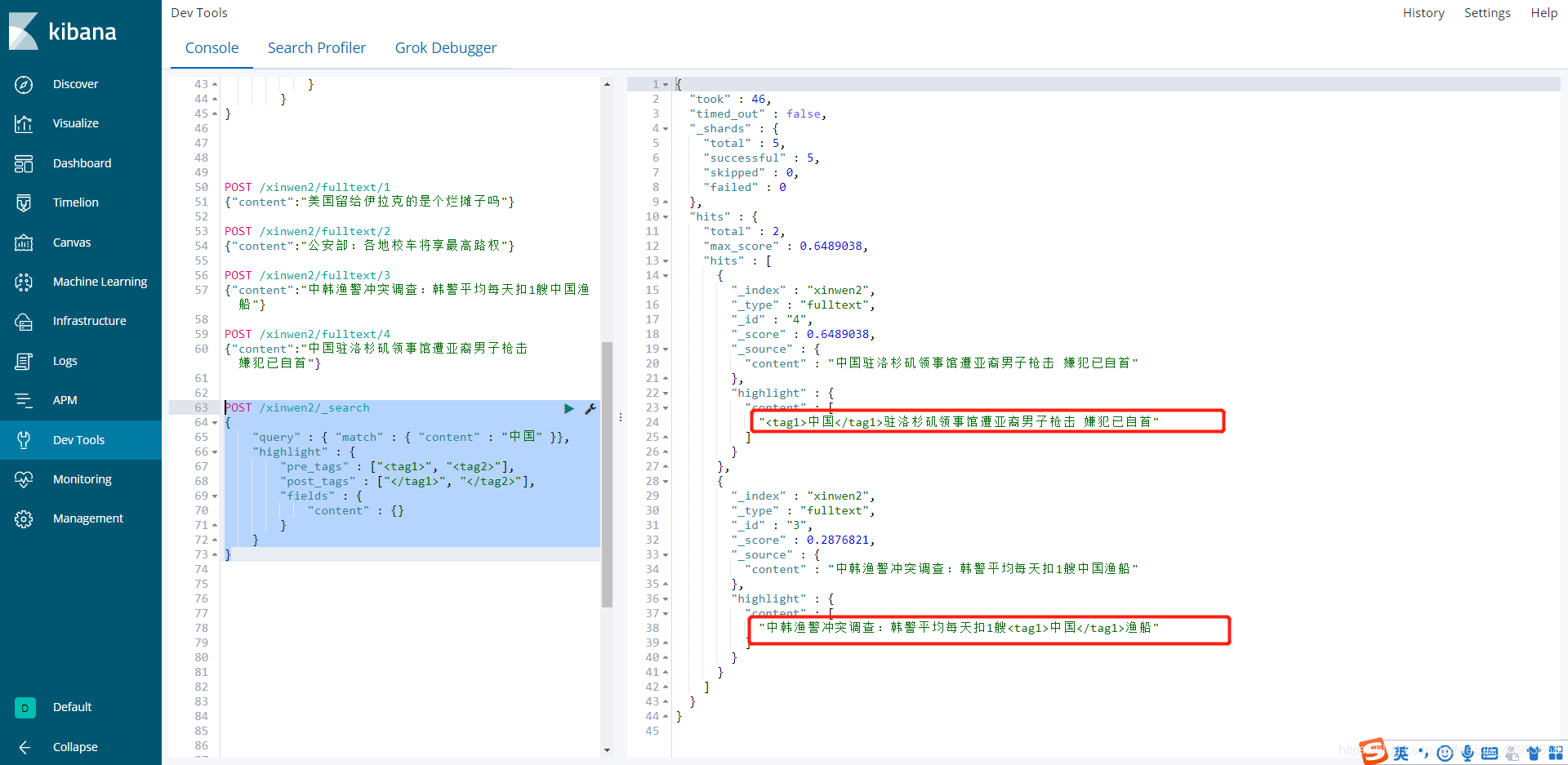
4.使用中文分词器前后对比结论
没有使用中文分词器之前搜索"中国"这个词,搜索出来的结果就是只要包含中、国任意一个字都会被搜索出来,显然不是我们想要的需求,并且数据展示杂乱
使用了中文分词器之后,他会把我们搜索的中国当成一个词,只有数据中包含中国这个词才会被显示
文章来源: jiangxl.blog.csdn.net,作者:Jiangxl~,版权归原作者所有,如需转载,请联系作者。
原文链接:jiangxl.blog.csdn.net/article/details/117220535

- 点赞
- 收藏
- 关注作者
评论(0)