部署ELK+Kafka+Filebeat日志收集分析系统

ELK+Kafka+Filebeat日志系统
文章目录
1.环境规划
| IP地址 | 部署的服务 | 主机名 |
|---|---|---|
| 192.168.81.210 | es+kafka+zookeeper+kibana+logstash | elk-1 |
| 192.168.81.220 | es+kafka+zookeeper | elk-2 |
| 192.168.81.230 | es+kafka+zookeeper+nginx+filebeat | elk-3 |
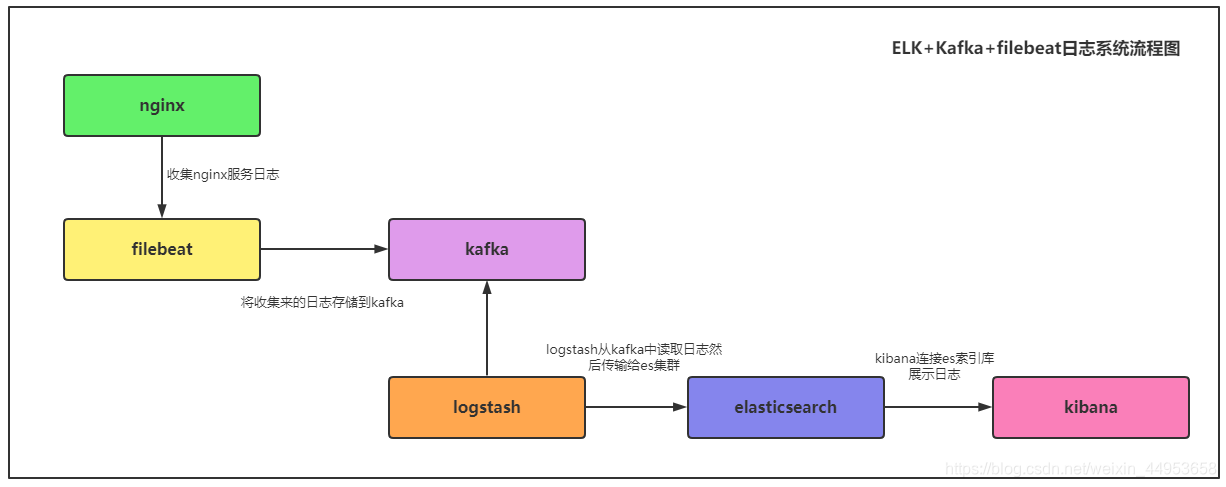
日志系统架构图
nginx—>filebeat—>kafka—>logstash—>elasticsearch—>kibana
2.部署elasticsearch集群
2.1.配置es-1节点
1.下载elasticsearch7.6
[root@elk-1 ~]# wget https://mirrors.huaweicloud.cn/elasticsearch/7.6.0/elasticsearch-7.6.0-x86_64.rpm
[root@elk-1 ~/soft]# rpm -ivh elasticsearch-7.6.0-x86_64.rpm
2.编辑配置文件,配置集群模式
[root@elk-1 ~]# vim /etc/elasticsearch/elasticsearch.yml
cluster.name: elk-application
node.name: elk-1
path.data: /data/elasticsearch
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true
network.host: 192.168.81.210,127.0.0.1
http.port: 9200
cluster.initial_master_nodes: ["elk-1"]
discovery.zen.ping.unicast.hosts: ["192.168.81.210","192.168.81.220","192.168.81.230"]
discovery.zen.fd.ping_timeout: 120s
discovery.zen.fd.ping_retries: 6
discovery.zen.fd.ping_interval: 30s
http.cors.enabled: true
http.cors.allow-origin: "*"
3.创建数据目录
[root@elk-1 ~]# mkdir /data/elasticsearch/ -p
[root@elk-1 ~]# chown -R elasticsearch.elasticsearch /data/elasticsearch/
4.配置内存锁定
[root@elk-1 ~]# mkdir /etc/systemd/system/elasticsearch.service.d/
[root@elk-1 ~]# vim /etc/systemd/system/elasticsearch.service.d/override.conf
[Service]
LimitMEMLOCK=infinity
5.启动elasticsearch
[root@elk-1 ~]# systemctl daemon-reload
[root@elk-1 ~]# systemctl start elasticsearch
[root@elk-1 ~]# systemctl enable elasticsearch
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
2.2.配置es-2节点
只是配置文件中node.name和network.host不同,其他操作方式一致
[root@elk-2 ~]# vim /etc/elasticsearch/elasticsearch.yml
cluster.name: elk-application
node.name: elk-2
path.data: /data/elasticsearch
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true
network.host: 192.168.81.220,127.0.0.1
http.port: 9200
cluster.initial_master_nodes: ["elk-1"]
discovery.zen.ping.unicast.hosts: ["192.168.81.210","192.168.81.220","192.168.81.230"]
discovery.zen.fd.ping_timeout: 120s
discovery.zen.fd.ping_retries: 6
discovery.zen.fd.ping_interval: 30s
http.cors.enabled: true
http.cors.allow-origin: "*"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2.3.配置es-3节点
只是配置文件中node.name和network.host不同,其他操作方式一致
[root@elk-2 ~]# vim /etc/elasticsearch/elasticsearch.yml
cluster.name: elk-application
node.name: elk-3
path.data: /data/elasticsearch
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true
network.host: 192.168.81.230,127.0.0.1
http.port: 9200
cluster.initial_master_nodes: ["elk-1"]
discovery.zen.ping.unicast.hosts: ["192.168.81.210","192.168.81.220","192.168.81.230"]
discovery.zen.fd.ping_timeout: 120s
discovery.zen.fd.ping_retries: 6
discovery.zen.fd.ping_interval: 30s
http.cors.enabled: true
http.cors.allow-origin: "*"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2.4.使用es-head插件查看集群状态

3.部署kibana
1.下载kibana rpm包
[root@elk-1 ~]# rpm -ivh kibana-7.6.0-x86_64.rpm
2.配置kibana
[root@elk-1 ~]# vim /etc/kibana/kibana.yml
server.port: 5601
server.host: "192.168.81.210"
server.name: "elk-application"
elasticsearch.hosts: ["http://192.168.81.210:9200"]
i18n.locale: "zh-CN"
[root@elk-1 ~]# systemctl restart kibana
[root@elk-1 ~]# systemctl enable elasticsearch
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
kibana部署成功
4.部署zookeeper
4.1.配置zookeeper-1节点
1.下载软件
[root@elk-1 ~]# wget http://archive.apache.org/dist/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
2.解压并移动zookeeper
[root@elk-1 ~]# tar xf soft/zookeeper-3.4.13.tar.gz -C /data/
[root@elk-1 ~]# mv /data/zookeeper-3.4.13/ /data/zookeeper
3.创建数据目录和日志目录
[root@elk-1 ~]# mkdir /data/zookeeper/{data,logs}
4.准备配置文件
[root@elk-1 ~]# cd /data/zookeeper/conf
[root@elk-1 /data/zookeeper/conf]# cp zoo_sample.cfg zoo.cfg
[root@elk-1 /data/zookeeper/conf]# vim zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper/data
DataLogDir=/data/zookeeper/logs
clientPort=2181
server.1=192.168.81.210:2888:3888
server.2=192.168.81.220:2888:3888
server.3=192.168.81.230:2888:3888
5.生成节点id文件
#节点id只能保护数字
[root@elk-1 /data/zookeeper]# echo 1 > /data/zookeeper/data/myid
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
4.2.配置zookeeper-2节点
与zookeeper-1节点只有配置文件和节点id文件有点不同,其余全一样
[root@elk-2 /data/zookeeper/conf]# cat zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper/data
DataLogDir=/data/zookeeper/logs
clientPort=2181
server.1=192.168.81.210:2888:3888
server.2=192.168.81.220:2888:3888
server.3=192.168.81.230:2888:3888
[root@elk-2 /data/zookeeper/conf]# echo 2 > /data/zookeeper/data/myid
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
4.3.配置zookeeper-3节点
[root@elk-3 /data/zookeeper/conf]# cat zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper/data
DataLogDir=/data/zookeeper/logs
clientPort=2181
server.1=192.168.81.210:2888:3888
server.2=192.168.81.220:2888:3888
server.3=192.168.81.230:2888:3888
[root@elk-3 /data/zookeeper/conf]# echo 3 > /data/zookeeper/data/myid
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
4.4.启动所有节点
zookeeper集群必须保证有两个节点存活,也就是说必须同时要启动两个节点,否则集群将启动不成功,因此要都修改好配置文件后,再统一启动
[root@elk-1 /data/zookeeper]# ./bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/zookeeper/bin/../conf/zoo.cfg
Mode: follower
[root@elk-2 /data/zookeeper]# ./bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/zookeeper/bin/../conf/zoo.cfg
Mode: follower
[root@elk-3 /data/zookeeper]# ./bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/zookeeper/bin/../conf/zoo.cfg
Mode: leader
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
5.部署kafka
注意:不要使用kafka2.11版本,有严重的bug,filebeat无法写入数据到kafka集群,写入的协议版本不同,存在问题
5.1.配置kafka-1节点
1.下载二进制包
[root@elk-1 ~]# wget https://archive.apache.org/dist/kafka/2.0.0/kafka_2.11-2.0.0.tgz
2.安装kafka
[root@elk-1 ~/soft]# tar xf kafka_2.13-2.4.0.tgz -C /data/
[root@elk-1 ~]# mv /data/kafka_2.13-2.4.0 /data/kafka
3.修改配置文件
[root@elk-1 ~]# cd /data/kafka
[root@elk-1 /data/kafka]# vim config/server.properties
broker.id=1
listeners=PLAINTEXT://192.168.81.210:9092
host.name=192.168.81.210
advertised.listeners=PLAINTEXT://192.168.81.210:9092
advertised.host.name=192.168.81.210
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kafka/data
num.partitions=3
delete.topic.enable=true
auto.create.topics.enable=true
replica.fetch.max.bytes=5242880
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=3
message.max.byte=5242880
log.cleaner.enable=true
log.retention.hours=48
log.segment.bytes=1073741824
log.retention.check.interval.ms=15000
zookeeper.connect=192.168.81.210:2181,192.168.81.220:2181,192.168.81.230:2181
zookeeper.connection.timeout.ms=60000
group.initial.rebalance.delay.ms=0
4.创建数据目录
[root@elk-3 ~]# mkdir /data/kafka/data
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
5.2.配置kafka-2节点
只是配置文件不同,其余与kafka-1节点操作一致
配置文件需要改的地方:broker.id改成2,表示第二个节点 listeners host.name advertised.listeners advertised.host.name改成本机ip地址
[root@elk-2 /data/kafka]# cat config/server.properties
broker.id=2
listeners=PLAINTEXT://192.168.81.220:9092
host.name=192.168.81.220
advertised.listeners=PLAINTEXT://192.168.81.220:9092
advertised.host.name=192.168.81.220
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kafka/data
num.partitions=3
delete.topic.enable=true
auto.create.topics.enable=true
replica.fetch.max.bytes=5242880
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=3
message.max.byte=5242880
log.cleaner.enable=true
log.retention.hours=48
log.segment.bytes=1073741824
log.retention.check.interval.ms=15000
zookeeper.connect=192.168.81.210:2181,192.168.81.220:2181,192.168.81.230:2181
zookeeper.connection.timeout.ms=60000
group.initial.rebalance.delay.ms=0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
5.3.配置kafka-3节点
只是配置文件不同,其余与kafka-1节点操作一致
配置文件需要改的地方:broker.id改成3,表示第三个节点 listeners host.name advertised.listeners advertised.host.name改成本机ip地址
[root@elk-3 /data/kafka]# cat config/server.properties
broker.id=3
listeners=PLAINTEXT://192.168.81.230:9092
host.name=192.168.81.230
advertised.listeners=PLAINTEXT://192.168.81.230:9092
advertised.host.name=192.168.81.230
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kafka/data
num.partitions=3
delete.topic.enable=true
auto.create.topics.enable=true
replica.fetch.max.bytes=5242880
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=3
message.max.byte=5242880
log.cleaner.enable=true
log.retention.hours=48
log.segment.bytes=1073741824
log.retention.check.interval.ms=15000
zookeeper.connect=192.168.81.210:2181,192.168.81.220:2181,192.168.81.230:2181
zookeeper.connection.timeout.ms=60000
group.initial.rebalance.delay.ms=0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
5.4.启动kafka
[root@elk-1 ~]# /data/kafka/bin/kafka-server-start -daemon /data/kafka/config/server.properties
[root@elk-2 ~]# /data/kafka/bin/kafka-server-start -daemon /data/kafka/config/server.properties
[root@elk-3 ~]# /data/kafka/bin/kafka-server-start -daemon /data/kafka/config/server.properties
- 1
- 2
- 3
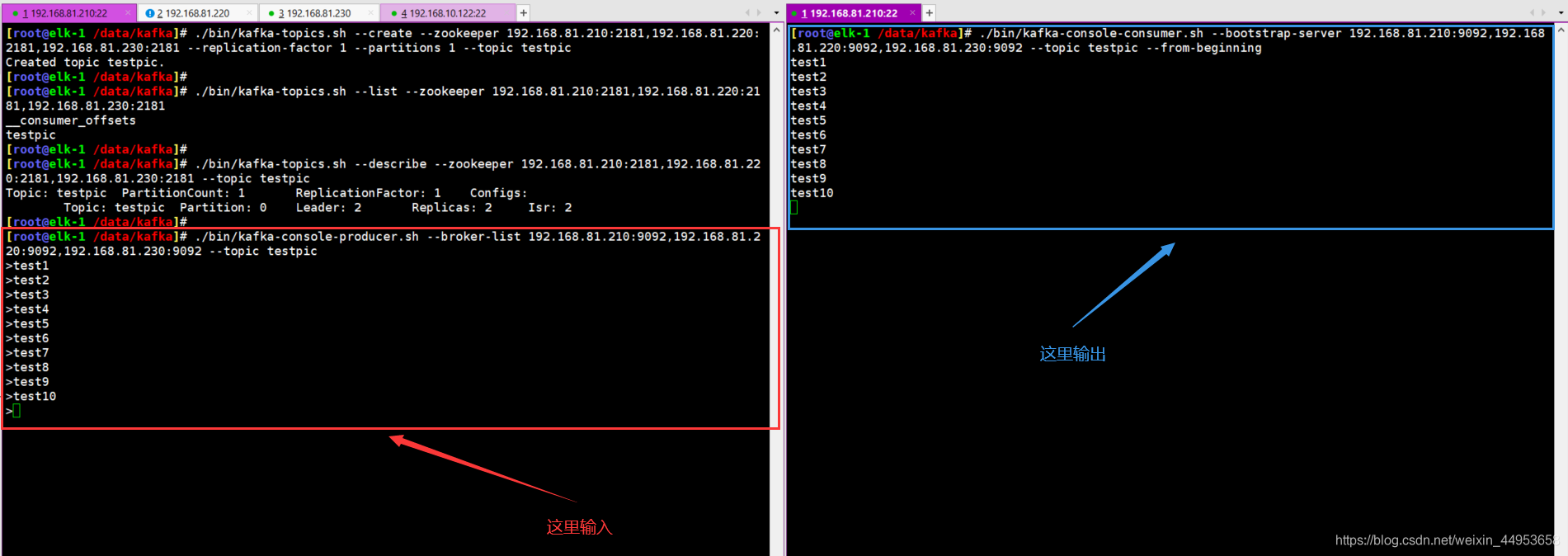
6.测试kafka与zookeeper连接
kafka能够产生数据并消费,整个集群就可以使用了
1.创建一个topic
[root@elk-1 /data/kafka]# ./bin/kafka-topics.sh --create --zookeeper 192.168.81.210:2181,192.168.81.220:2181,192.168.81.230:2181 --replication-factor 1 --partitions 1 --topic testpic
Created topic "testpic".
2.查看topic
[root@elk-1 /data/kafka]# ./bin/kafka-topics.sh --list --zookeeper 192.168.81.210:2181,192.168.81.220:2181,192.168.81.230:2181
testpic
3.查看topic的描述信息
[root@elk-1 /data/kafka]# ./bin/kafka-topics.sh --describe --zookeeper 192.168.81.210:2181,192.168.81.220:2181,192.168.81.230:2181 --topic testpic
4.使用kafka-console-producer控制台生产数据
[root@elk-1 /data/kafka]# ./bin/kafka-console-producer.sh --broker-list 192.168.81.210:9092,192.168.81.220:9092,192.168.81.230:9092 --topic testpic
>test1
>test2
>test3
>test4
>test5
>test6
>test7
>test8
>test9
>test10
5.使用kafka-console-consumer控制台消费数据
[root@elk-1 /data/kafka]# ./bin/kafka-console-consumer.sh --bootstrap-server 192.168.81.210:9092,192.168.81.220:9092,192.168.81.230:9092 --topic testpic --from-beginning
test1
test2
test3
test4
test5
test6
test7
test8
test9
test10
#删除一个topic
[root@elk-1 /data/kafka]# ./bin/kafka-topics.sh --delete --zookeeper 192.168.81.210:2181 --topic testpic
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
7.配置filebeat收集nginx、tomcat日志并存储到kafka中
7.1.安装并配置nginx服务
1.安装nginx
[root@elk-3 ~]# yum -y install nginx
2.配置nginx日志格式
[root@elk-3 ~]# vim /etc/nginx/nginx.conf
http {
··············
log_format main '{"时间":"$time_iso8601",'
'"客户端外网地址":"$http_x_forwarded_for",'
'"客户端内网地址":"$remote_addr",'
'"状态码":$status,'
'"传输流量":$body_bytes_sent,'
'"跳转来源":"$http_referer",'
'"URL":"$request",'
'"浏览器":"$http_user_agent",'
'"请求响应时间":$request_time,'
'"后端地址":"$upstream_addr"}';
access_log /var/log/nginx/access.log main;
··············
}
2.启动nginx
[root@elk-3 ~]# systemctl start nginx
[root@elk-3 ~]# systemctl enable nginx
4.访问产生日志查看效果
[root@elk-3 ~]# curl 127.0.0.1
[root@elk-3 ~]# tail /var/log/nginx/access.log
{"时间":"2021-07-12T11:29:33+08:00","客户端外网地址":"-","客户端内网地址":"127.0.0.1","状态码":200,"传输流量":4833,"跳转来源":"-","URL":"GET / HTTP/1.1","浏览器":"curl/7.29.0","请求响应时间":0.000,"后端地址":"-"}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
7.2.安装tomcat服务
[root@elk-3 ~]# tar xf apache-tomcat-8.5.12.tar.gz -C /data/
[root@elk-3 ~]# mv /data/apache-tomcat-8.5.12/ /data/tomcat
[root@elk-3 ~]# /data/tomcat/bin/startup.sh
Using CATALINA_BASE: /data/tomcat
Using CATALINA_HOME: /data/tomcat
Using CATALINA_TMPDIR: /data/tomcat/temp
Using JRE_HOME: /usr
Using CLASSPATH: /data/tomcat/bin/bootstrap.jar:/data/tomcat/bin/tomcat-juli.jar
Tomcat started.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
7.3.安装filebeat服务
[root@elk-3 ~]# rpm -ivh filebeat-7.6.0-x86_64.rpm ```
- 1
7.4.配置filebeat收集应用日志并存储到kafka
1.配置filebeat
[root@elk-3 ~]# vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log #类型为log
enabled: true
paths: #指定日志所在的路径
- /var/log/nginx/access.log
json.keys_under_root: true #支持json格式的日志输出
json.overwriite_keys: true
fields: #在日志中增加一个字段,字段为log_topic,值为nginx_access,logstash根据带有这个字段的日志存储到指定的es索引库
log_topic: nginx-access
tail_files: true #开启日志监控,从日志的最后一行开始收集
- type: log
enabled: true
paths:
- /data/tomcat/logs/catalina.out
multiline.pattern: '^20' #收集tomcat错误日志,从第一个20到下一个20之间的日志整合在一行中显示
multiline.negate: true
multiline.match: after
fields:
log_topic: tomcat-cata
tail_files: true
output.kafka: #输出到kafka系统
enabled: true
hosts: ["192.168.81.210:9092","192.168.81.220:9092","192.168.81.230:9092"] #kafka的地址
topic: '%{[fields][log_topic]}' #指定将日志存储到kafka集群的哪个topic中,这里的topic值是引用在inputs中定义的fields,通过这种方式可以将不同路径的日志分别存储到不同的topic中
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000
2.启动filebeat
[root@elk-3 ~]# systemctl start filebeat
[root@elk-3 ~]# systemctl enable filebeat
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
7.5.产生程序日志数据观察数据是否存储kafka
1.产生程序日志
1.产生nginx日志
[root@elk-3 ~]# ab -n 1000 -c 100 http://127.0.0.1/index.html
2.产生tomcat日志
[root@elk-3 ~]# /data/tomcat/bin/shutdown.sh
[root@elk-3 ~]# /data/tomcat/bin/startup.sh
- 1
- 2
- 3
- 4
- 5
- 6
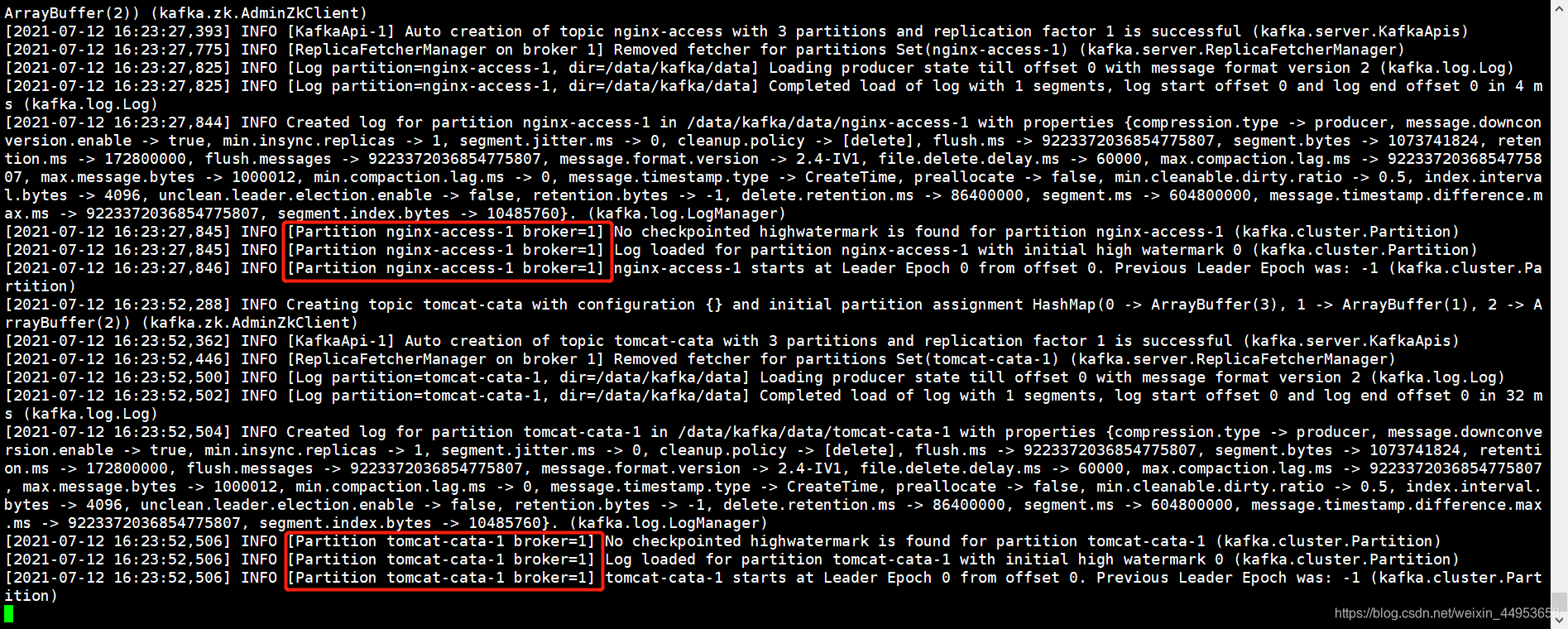
2.观察kafka中是否创建对应的topic
[root@elk-1 /data/kafka]# ./bin/kafka-topics.sh --list --zookeeper 192.168.81.210:2181,192.168.81.220:2181,192.168.81.230:2181
__consumer_offsets
nginx-access
testpic
tomcat-cata
#nginx-access以及tomcat-cata的topic已经创建成功
- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.观察kafka日志的输出
[root@elk-1 /data/kafka]# tail -f logs/kafkaServer.out
- 1
8.配置logstash从kafka中读取数据并存储到es集群
部署logstash,配置logstash从kafka中读取topic数据并存储到es集群
8.1.部署logstash服务
1.安装logstash
[root@elk-3 ~]# rpm -ivh logstash-7.6.0.rpm
- 1
- 2
8.2.配置logstash从kafka读取数据存储到es集群
[root@elk-3 ~]# cat /etc/logstash/conf.d/in_kafka_to_es.conf
#从kafka中读取日志数据
input { #数据源端
kafka { #类型为kafka
bootstrap_servers => ["192.168.81.210:9092,192.168.81.220:9092,192.168.81.230:9092"] #kafka集群地址
topics => ["nginx-access","tomcat-cata"] #要读取那些kafka topics
codec => "json" #处理json格式的数据
auto_offset_reset => "latest" #只消费最新的kafka数据
}
}
#处理数据,去掉没用的字段
filter {
if[fields][log_topic] == "nginx-access" { #如果log_topic字段为nginx-access则进行以下数据处理
json { #json格式数据处理
source => "message" #source等于message的
remove_field => ["@version","path","beat","input","log","offset","prospector","source","tags"] #删除指定的字段
}
mutate { #修改数据
remove_field => ["_index","_id","_type","_version","_score","referer","agent"] #删除没用的字段
}
}
if[fields][log_topic] == "tomcat-cata" { #如果log_topic字段为tomcat-cata
grok { #解析格式
match => {
"message" => "(?<时间>20[0-9]{2}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2}) \[(?<线程名称>[^\s]{0,})\] (?<日志等级>\w+) (?<类名称>[^\s]{0,}) (?<日志详情>[\W\w]+)" #将message的值增加上一些格式
}
}
mutate { #修改数据
remove_field => ["_index","_id","_type","_version","_score","referer","agent"] #删除没用的字段
}
}
}
#数据处理后存储es集群
output { #目标端
if[fields][log_topic] == "nginx-access" { #如果log_topic的字段值为nginx-access就存到下面的es集群里
elasticsearch {
action => "index" #类型为索引
hosts => ["192.168.81.210:9200","192.168.81.220:9200","192.168.81.230:9200"] #es集群地址
index => "nginx-access-%{+YYYY.MM.dd}" #存储到es集群的哪个索引里
codec => "json" #处理json格式的解析
}
}
if[fields][log_topic] == "tomcat-cata" { #如果log_topic的字段值为tomcat-cata就存到下面的es集群里
elasticsearch {
action => "index" #类型为索引
hosts => ["192.168.81.210:9200","192.168.81.220:9200","192.168.81.230:9200"] #es集群地址
index => "tomcat-cata-%{+YYYY.MM.dd}" #存储到es集群的哪个索引里
codec => "json" #处理json格式的解析
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
8.3.启动logstash并观察日志
[root@elk-3 ~]# nphup /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/in_kafka_to_es.conf &
- 1
观察日志的输出,已经从nginx-access、tomcat-cata topic中读取了数据并存到了es集群中
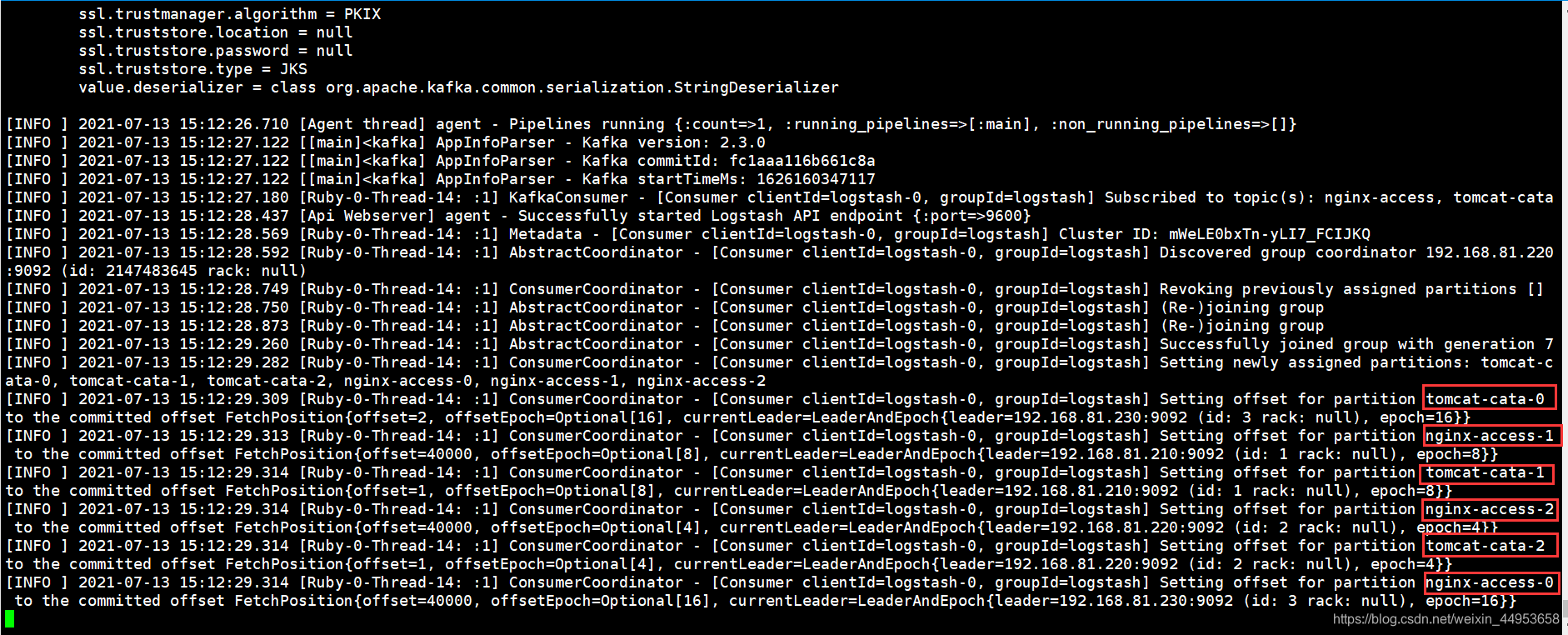
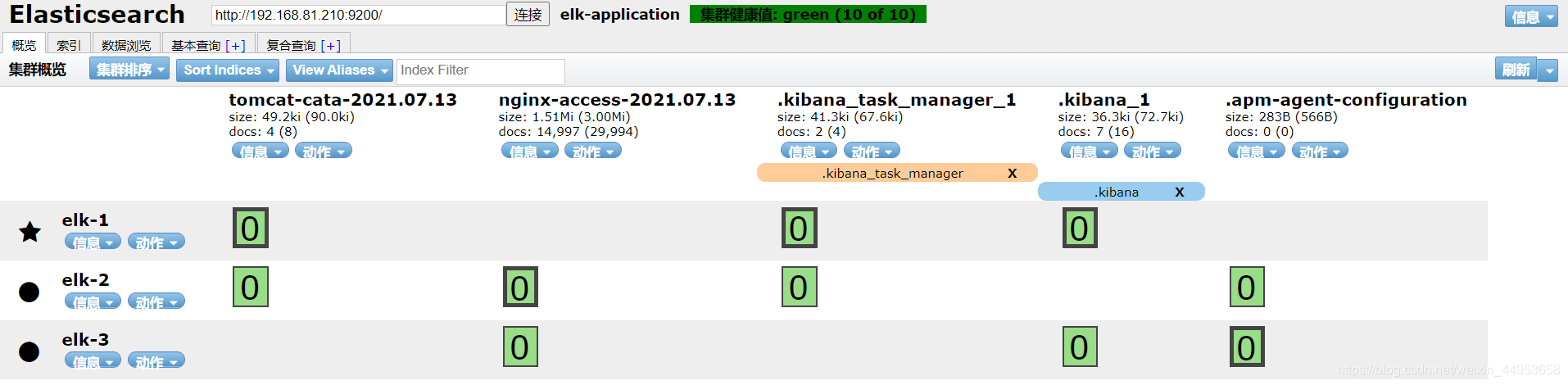
8.4.查看elasticsearch集群是否增加了对应的索引库
es集群已经生成了tomcat-cata以及nginx-access索引库
到此为止logstash已经成功从kafka集群读取到日志数据,然后传入到elasticsearch集群不同的索引库
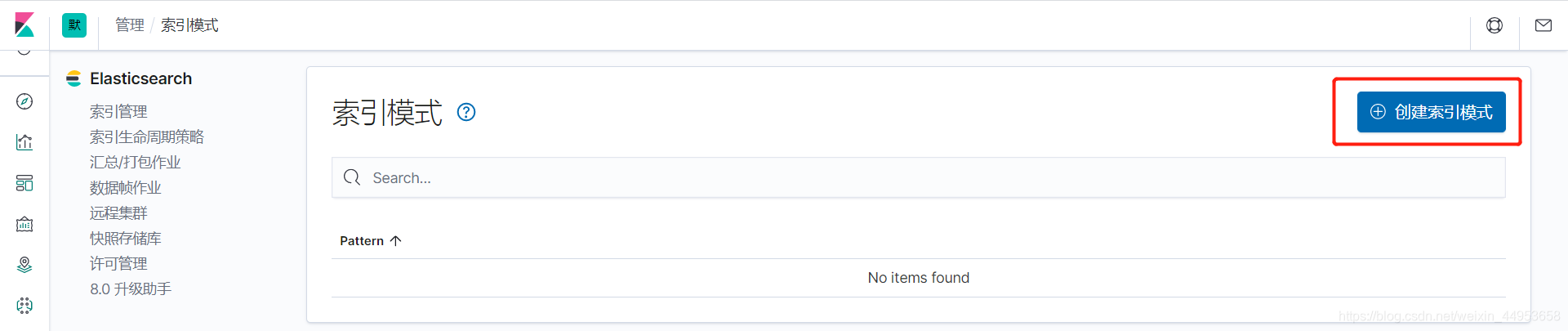
9.在kibana上关联elasticsearch索引库浏览日志数据
9.1.在kibana上添加nginx-access索引模式
1)点击创建索引
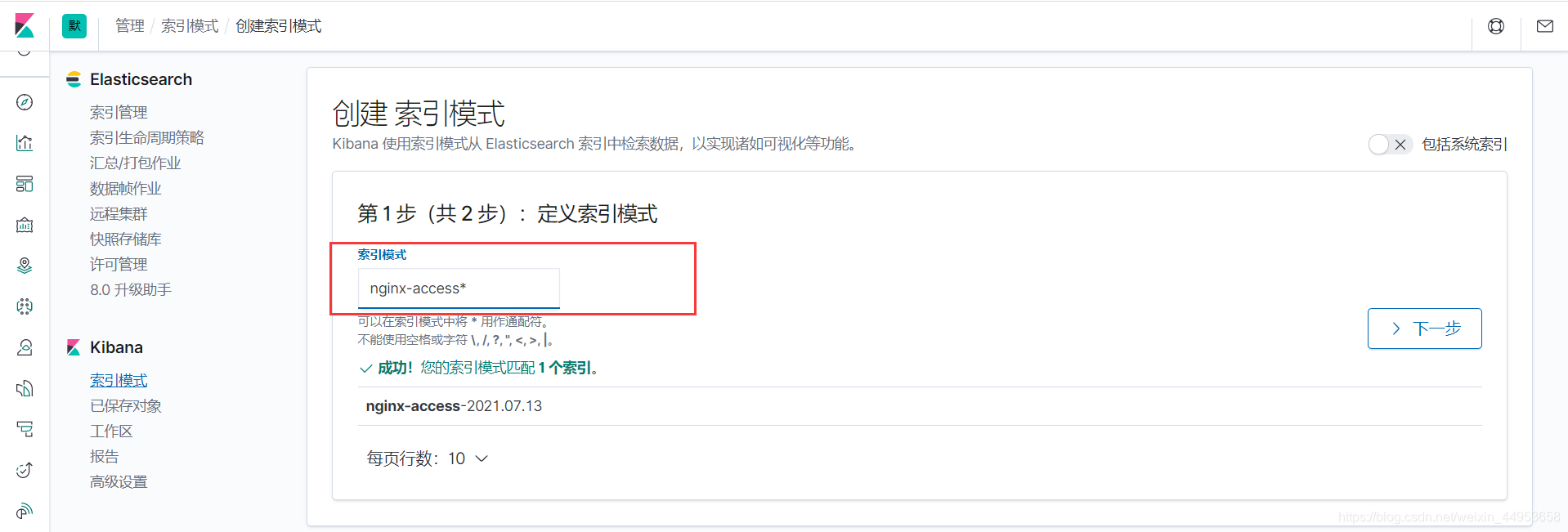
2)填写索引名
采用通配符的方式,填写完点击下一步完成创建即可
3)添加一个时间筛选字段
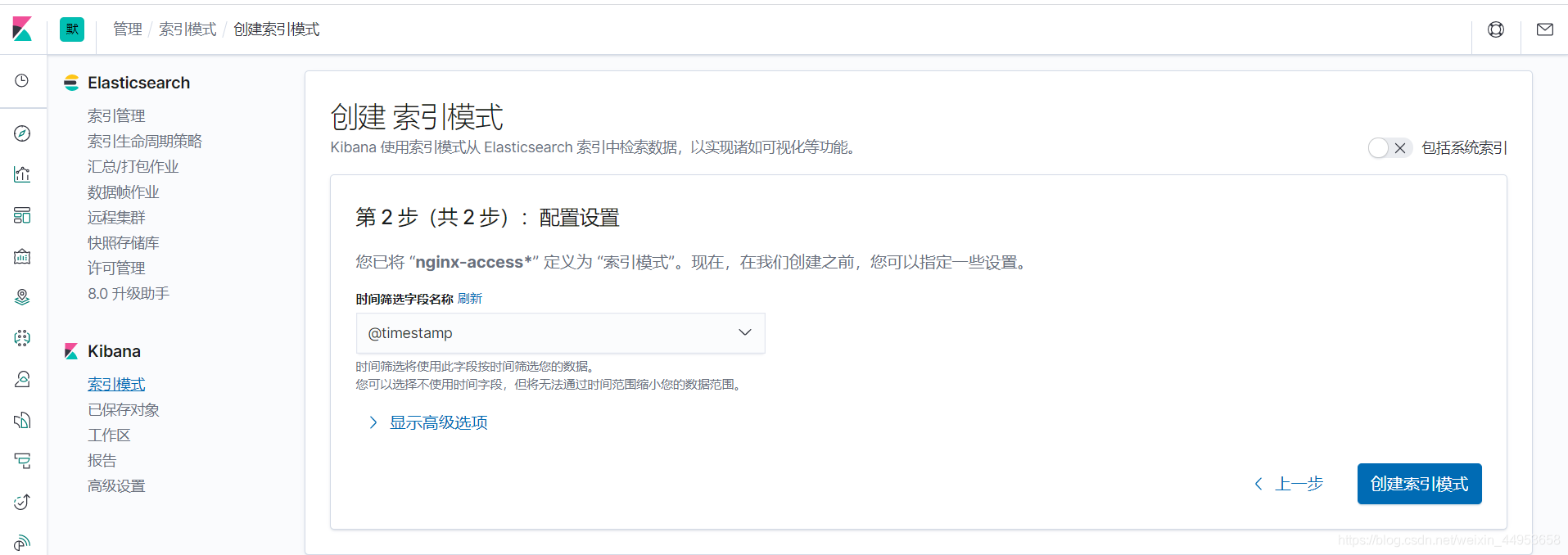
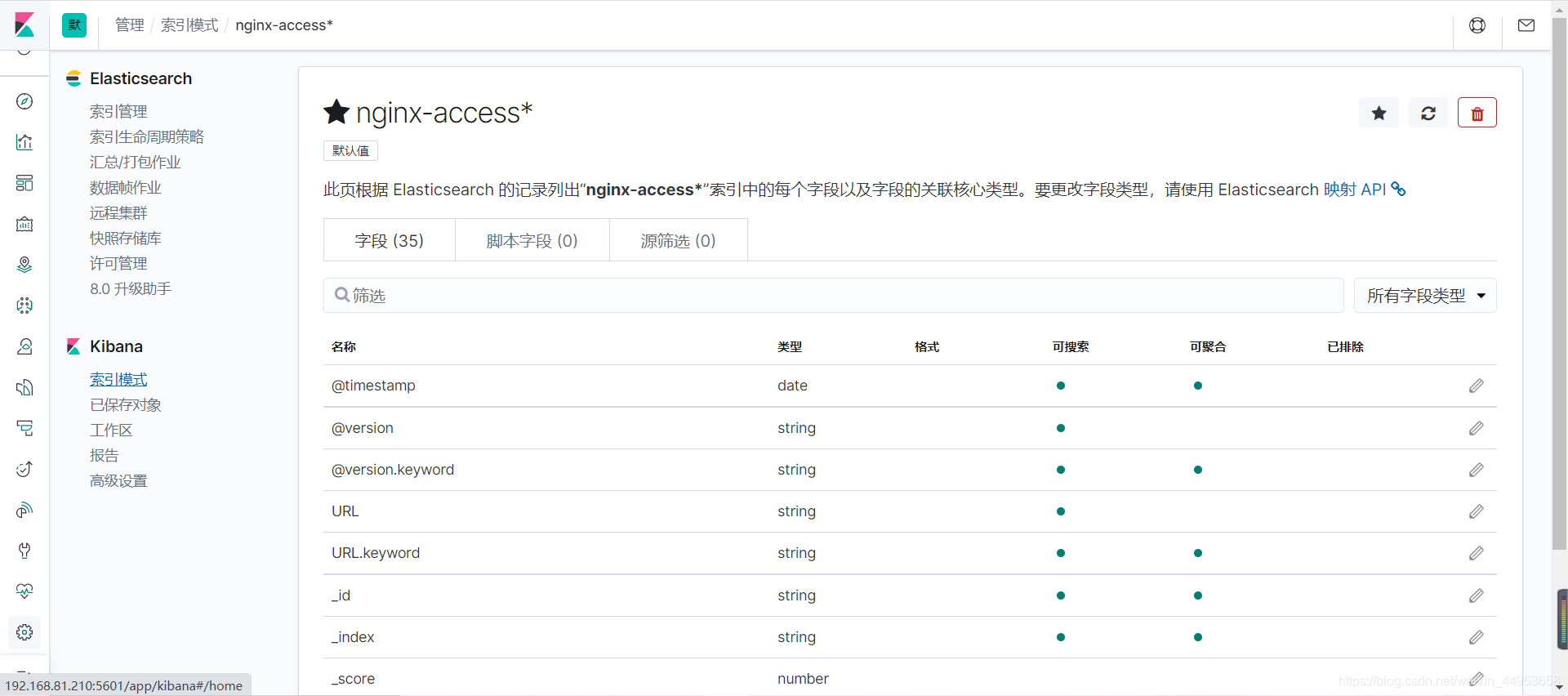
4)创建成功
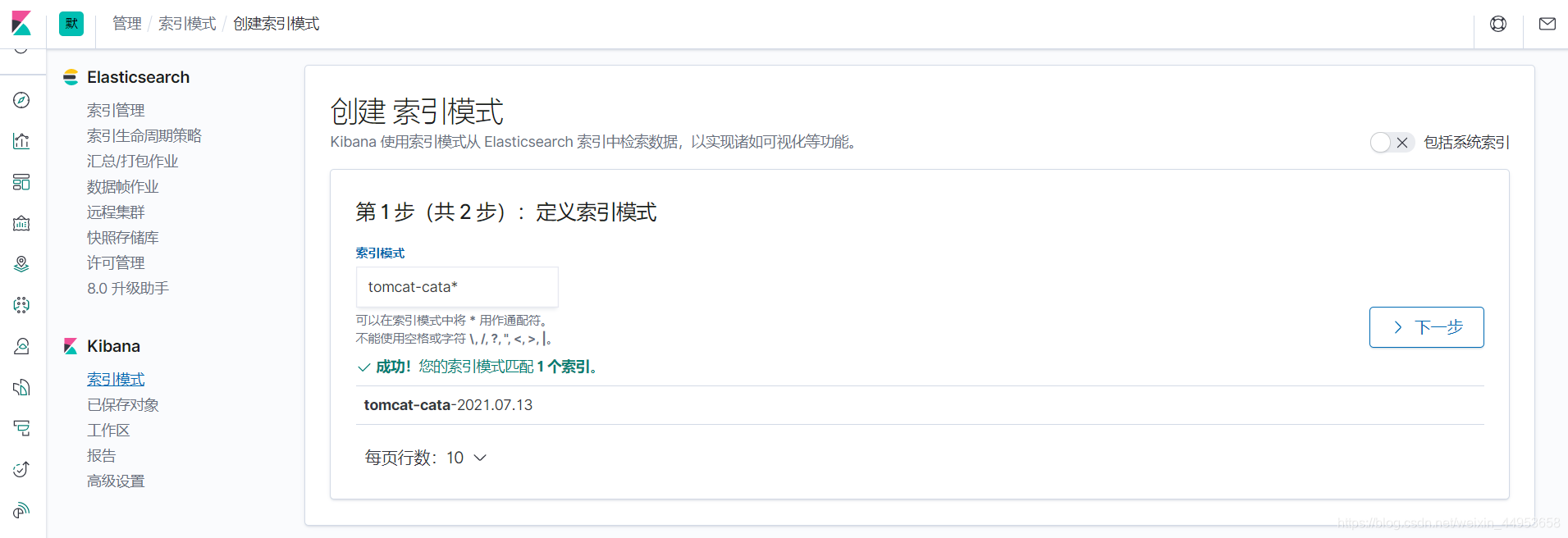
9.2.同样方法添加tomcat-cata索引模式
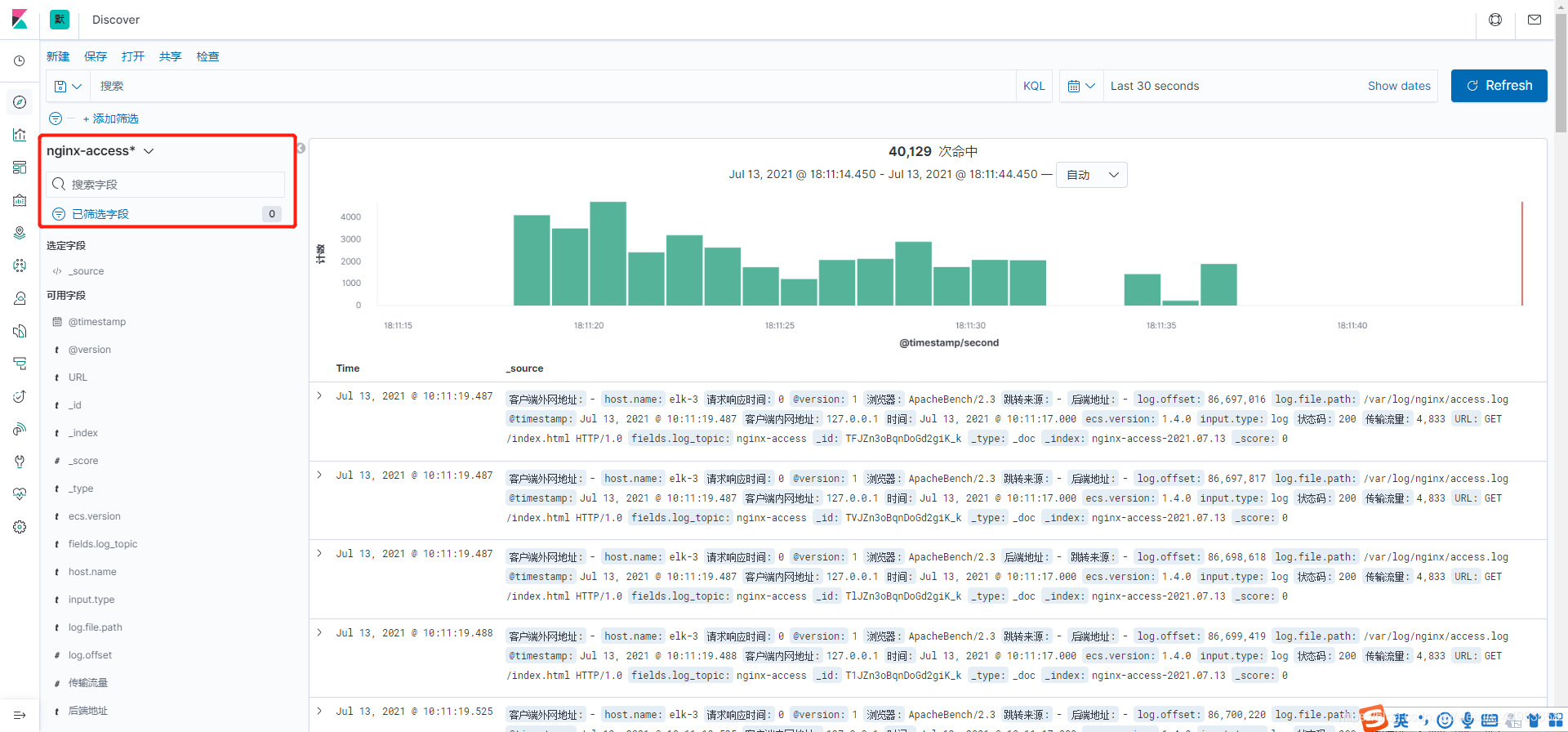
9.3.查询nginx-access索引日志数据
9.4.查看tomcat-cata索引日志数据
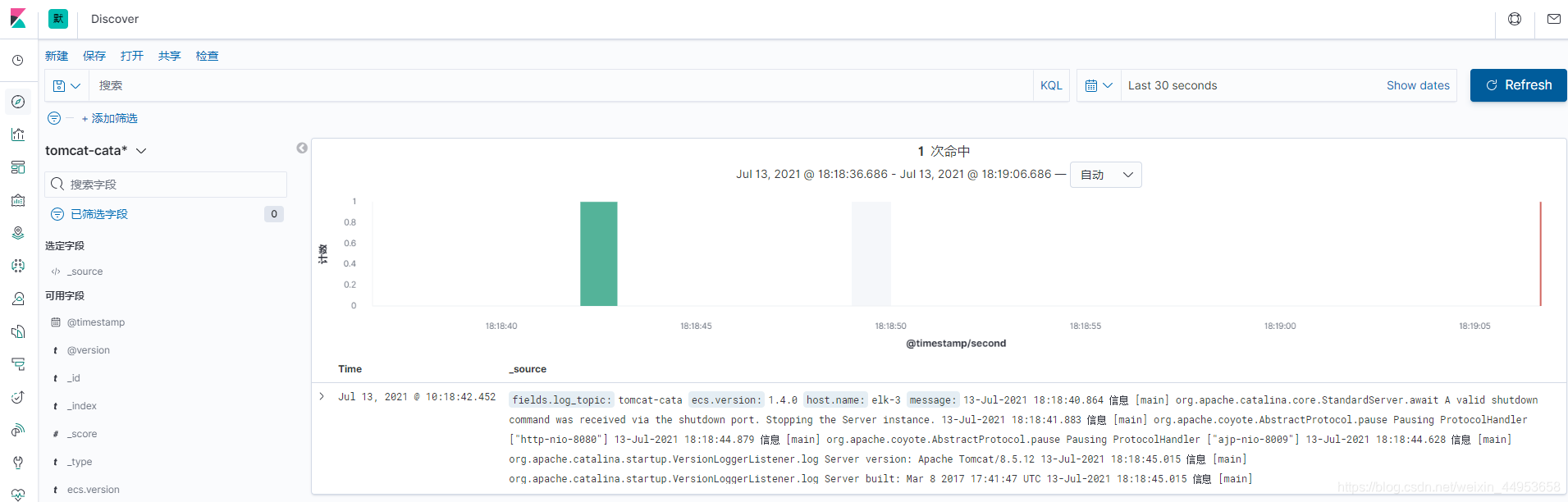
10.报错合集
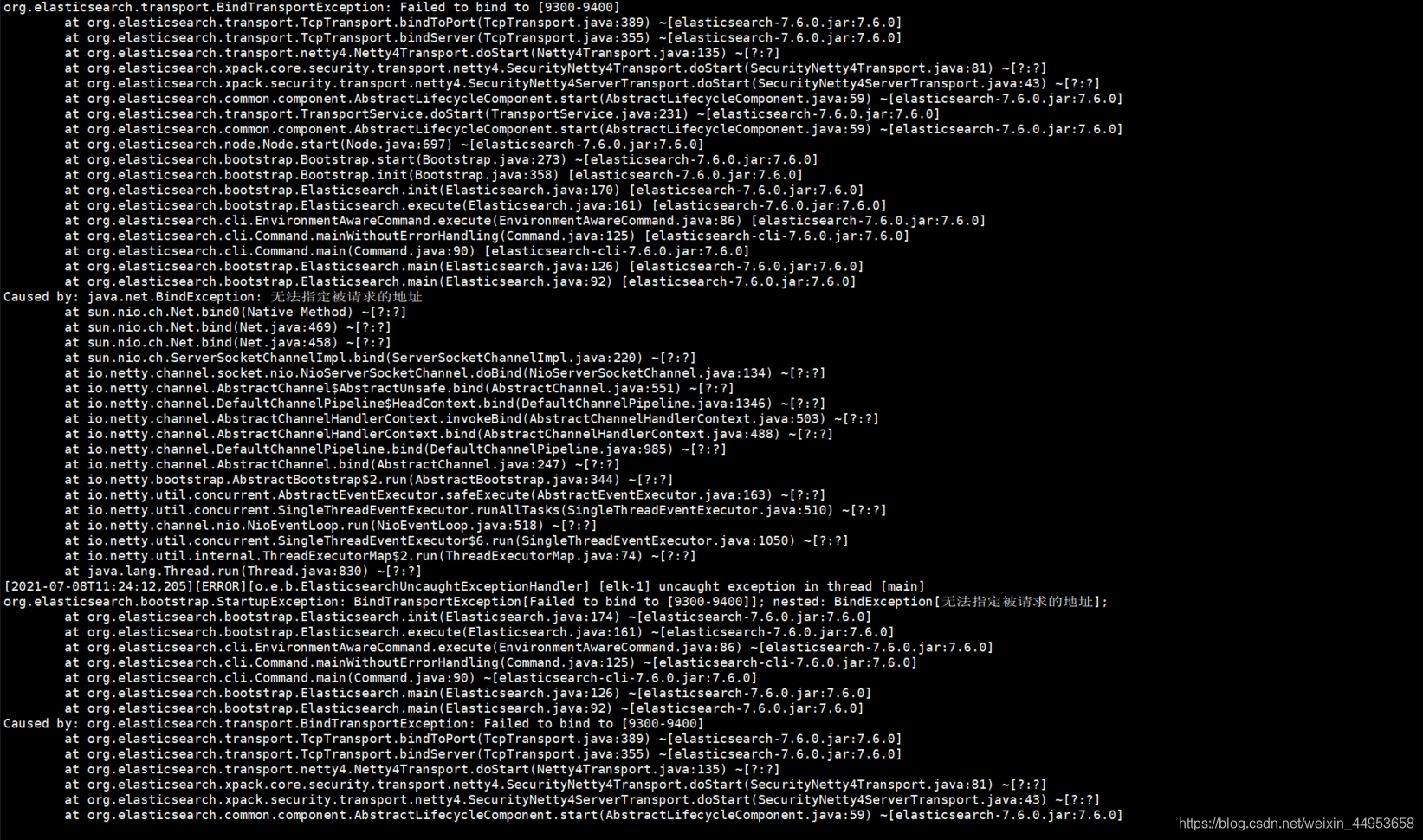
10.1.es启动时报错无法指定被请求的地址
报错内容如下
解决方法:仔细检查配置文件,肯定是某个地址配置错了,我的就是监听地址的ip写错了
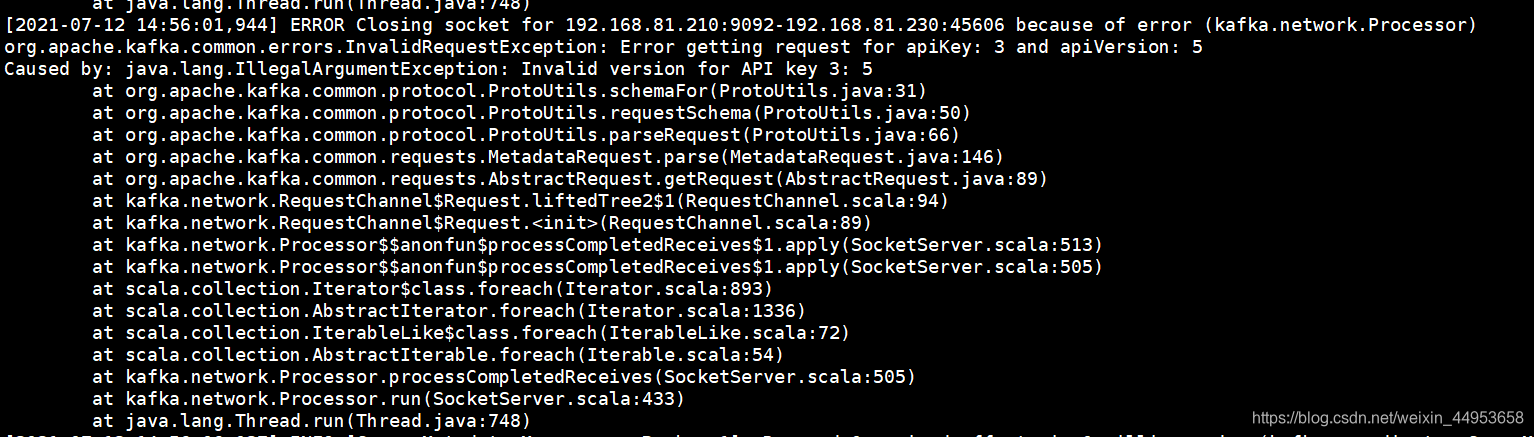
10.2.filebeat写入数据到kafka api版本报错
报错如下:
分析解决思路:初步判定为kafka2.11版本问题导致的,换成2.13问题解决
文章来源: jiangxl.blog.csdn.net,作者:Jiangxl~,版权归原作者所有,如需转载,请联系作者。
原文链接:jiangxl.blog.csdn.net/article/details/119733673

- 点赞
- 收藏
- 关注作者
评论(0)